Quando sei limitato all'ASCII, come puoi rappresentare cose più complesse come emoji o caratteri non latini? Una risposta è Punycode, che è un modo per rappresentare i caratteri Unicode in ASCII. Tuttavia, anche se tecnicamente potresti codificare i pezzi grezzi di Unicode in caratteri, come Base64, c'è un problema. Il Domain Name System (DNS) generalmente richiede che i nomi host non facciano distinzione tra maiuscole e minuscole, quindi se digiti HACKADAY.com, HackADay.com o semplicemente hackaday.com, tutto va nello stesso posto.
[UN. Costello] presso l'Università della California, Berkley propose l'idea di Punycode in RFC 3492 nel marzo 2003. Delinea un semplice algoritmo in cui tutti i caratteri ASCII regolari vengono estratti e bloccati su un lato con un separatore in mezzo, in questo caso, un trattino. Quindi i caratteri Unicode vengono codificati e bloccati alla fine della stringa.
Innanzitutto, il punto di codice numerico e la posizione nella stringa vengono moltiplicati insieme. Quindi il numero viene codificato come a Base 36 (az e 0-9) intero a lunghezza variabile. Ad esempio, un saluto e il greco per ringraziare, “Ehi, ciao" diventa “Ehi, -mxahn5algcq2″. Allo stesso modo, la bellissima città di Monaco diventa mnchen-3ya.
Come potresti notare nell'esempio greco, non c'è nulla che aiuti il decodificatore a sapere quali caratteri base 36 appartengono a quale simbolo Unicode originale. Grazie agli interi di lunghezza variabile, ogni cifra significativa è riconoscibile, poiché esistono soglie per quali numeri possono essere codificati. Una macchina a stati finiti viene in soccorso. La RFC fornisce uno pseudocodice esemplificativo che delinea l'algoritmo. È piuttosto intelligente, poiché utilizza un pregiudizio che cambia man mano che la decodifica procede. Poiché è sempre crescente, è una funzione monotona con alcune proprietà intelligenti.
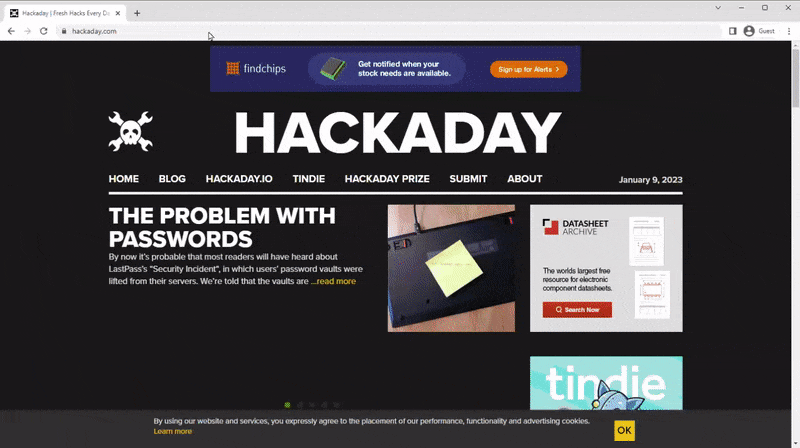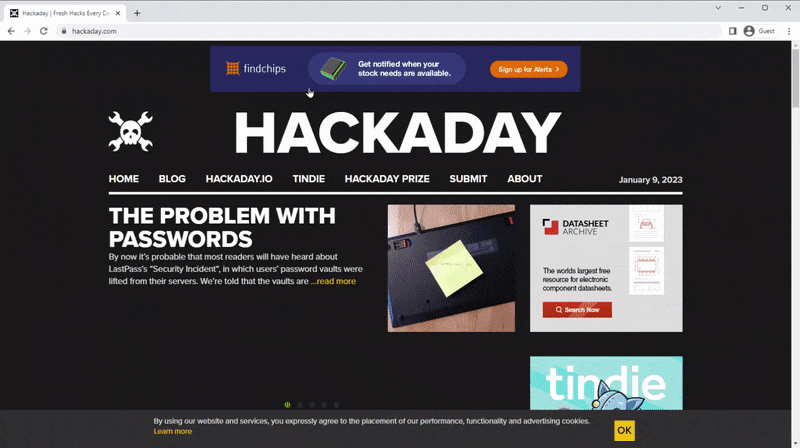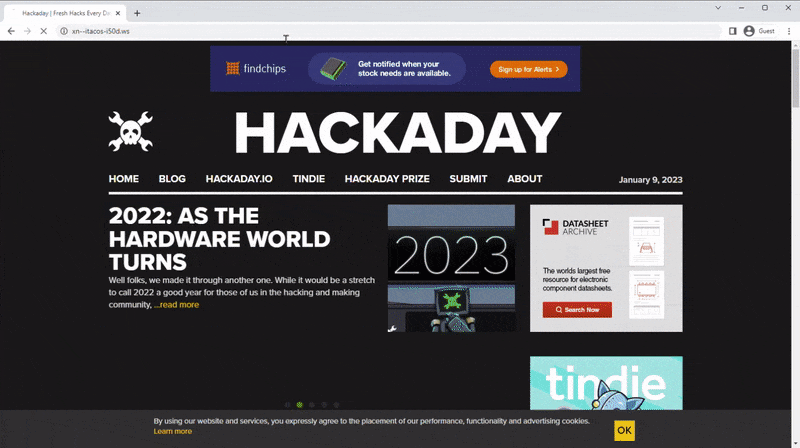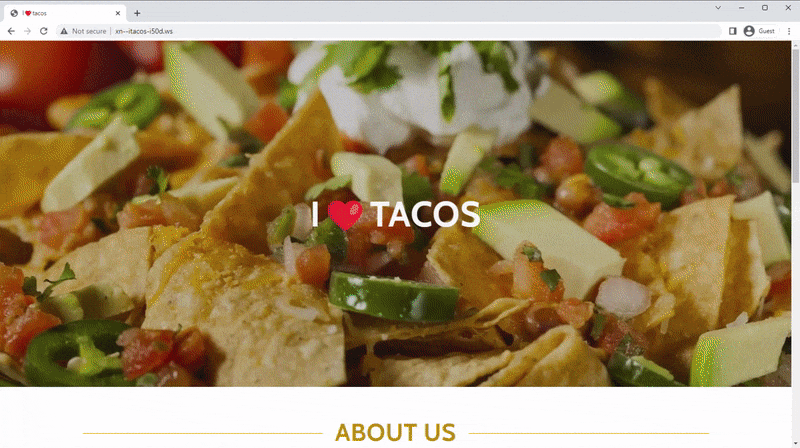
Naturalmente, per evitare che gli URL normali vengano interpretati come codici insignificanti, gli URL hanno un piccolo prefisso speciale xn-- per far sapere al browser che si tratta di un codice. Ciò include tutti i caratteri Unicode, quindi sono validi anche gli emoji. Allora perché non puoi andarci? xn--mnchen-3ya.de? Se lo digiti nel tuo browser o fai clic sul collegamento, potresti vedere il tuo browser trasformare quella confusa zuppa di lettere in un bellissimo URL (non tutti i browser lo fanno). Il problema più grande è lo stesso Unicode.
Sebbene Unicode offra un supporto incredibile per rendere possibili e, osiamo dire, anche piuttosto semplici, le centinaia di lingue utilizzate ogni giorno sul Web, ci sono alcuni aspetti negativi. Le lettere cirilliche, di larghezza zero e altre stranezze Unicode consentono a chi ha intenzioni più nefaste di creare un dominio che, una volta reso, viene visualizzato come un sito Web noto. I certificati SSL sono validi e tutto il resto viene verificato. Il cirillico include caratteri che sembrano visivamente identici alle loro controparti latine ma sono rappresentati in modo diverso. Le opportunità per hacker e tentativi di phishing sono troppo grandi e finora i punycode non sono stati consentiti sulla maggior parte dei domini.
Ad esempio, puoi distinguere tra questi due domini?
Alcuni browser visualizzeranno il testo al passaggio del mouse come Punycode e altri lo manterranno come equivalente UTF-8. La "a" (U+0061) è stata sostituita dalla "a" cirillica (U+0430), che la maggior parte dei computer visualizza con lo stesso identico carattere.
Questo è uno Attacco omografo IDN, dove fanno affidamento sul fatto che un utente faccia clic su un collegamento tra cui non riescono a distinguere. Nel 2001, due ricercatori sulla sicurezza pubblicarono un articolo sull'argomento, registrando "microsoft.com" con caratteri cirillici come prova del concetto. In risposta, è stato consigliato ai domini di primo livello di accettare solo caratteri Unicode contenenti caratteri latini e caratteri delle lingue utilizzate in quel paese. Di conseguenza, molti dei comuni domini di primo livello con sede negli Stati Uniti non accettano affatto nomi di dominio Unicode. Almeno i caratteri non visualizzabili sono specificatamente classificati dall'ICANN, il che evita un grosso vaso di worm, ma avere caratteri visivamente identici ma diversi a livello di bit là fuori porta a confusione.
Tuttavia, le misure di mitigazione per questi tipi di attacchi vengono lentamente implementate. Come primo livello di protezione, i browser basati su Firefox e Chromium mostrano solo la versione non Punycode se tutti i caratteri provengono dalla stessa lingua. Alcuni browser convertono tutti gli URL Unicode in Punycode. Altre tecniche utilizzano il riconoscimento ottico dei caratteri (OCR) per determinare se un URL può essere interpretato in modo diverso. Al di fuori del browser, i collegamenti inviati tramite SMS o e-mail potrebbero non avere la stessa intelligenza e non lo saprai finché non li aprirai nel tuo browser. E a quel punto, è troppo tardi.
Sfide a parte, i Punycodes riusciranno a godersi il sole? Hackaday riceverà mai ☠️📅.com? Chi lo sa. Ma nel frattempo possiamo goderci una soluzione intelligente proposta nel 2003 allo spinoso problema dell'internazionalizzazione dei nomi di dominio che non abbiamo ancora del tutto risolto.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://hackaday.com/2023/01/18/punycodes-explained/
- 2001
- a
- Accetta
- algoritmo
- Tutti
- sempre
- ed
- rispondere
- in giro
- attacchi
- Tentativi
- bellissimo
- diventa
- essendo
- fra
- pregiudizio
- Maggiore
- del browser
- browser
- California
- Custodie
- certificato
- carattere
- riconoscimento del personaggio
- caratteri
- Controlli
- Città
- codice
- COM
- Uncommon
- complesso
- computer
- concetto
- confusione
- confusione
- convertire
- potuto
- nazione
- corso
- giorno
- Decodifica
- Determinare
- differenza
- diverso
- Cifra
- dns
- dominio
- Domain Name
- NOMI DI DOMINIO
- domini
- Dont
- ogni
- godere
- Equivalente
- Anche
- EVER
- ogni giorno
- qualunque cosa
- esempio
- ha spiegato
- Firefox
- Nome
- da
- function
- generalmente
- ottenere
- gif
- dà
- Go
- va
- grande
- saluto
- hacker
- avendo
- Aiuto
- librarsi
- Come
- Tuttavia
- HTTPS
- centinaia
- idea
- identico
- in
- inclusi
- crescente
- incredibile
- intenzioni
- IT
- stessa
- mantenere
- Sapere
- Lingua
- Le Lingue
- grandi
- In ritardo
- latino
- strato
- Leads
- lettera
- LINK
- Collegamento
- piccolo
- Guarda
- macchina
- Fare
- molti
- Marzo
- intanto
- messaggio
- forza
- Scopri di più
- maggior parte
- moltiplicato
- Nome
- nomi
- numero
- numeri
- OCR
- stranezze
- Offerte
- ONE
- ha aperto
- Opportunità
- riconoscimento ottico dei caratteri
- i
- Altro
- lineamenti
- al di fuori
- Carta
- phishing
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- posizione
- possibile
- piuttosto
- prevenire
- Problema
- prova
- prova del concetto
- proprietà
- proposto
- protezione
- pubblicato
- Crudo
- riconoscimento
- raccomandato
- registrazione
- Basic
- sostituito
- rappresentare
- rappresentato
- richiede
- salvataggio
- ricercatori
- risposta
- limitato
- colpevole
- Arrotolato
- rotoli
- stesso
- problemi di
- ricercatori di sicurezza
- set
- mostrare attraverso le sue creazioni
- significativa
- Allo stesso modo
- Un'espansione
- Lentamente
- So
- finora
- soluzione
- alcuni
- piuttosto
- la nostra speciale
- in particolare
- SSL
- Ancora
- lineare
- soggetto
- Dom.
- supporto
- simbolo
- sistema
- tecniche
- I
- loro
- cose
- tempo
- a
- insieme
- pure
- di livello superiore
- Trasformare
- Tipi di
- unicode
- Università
- University of California
- URL
- uso
- Utente
- Utilizzando
- versione
- sito web
- noto
- Che
- se
- quale
- while
- OMS
- wikipedia
- volere
- worm
- Trasferimento da aeroporto a Sharm
- zefiro