Amazon Kendra è un servizio di ricerca intelligente facile da usare che ti consente di integrare le funzionalità di ricerca con le tue applicazioni in modo che gli utenti possano trovare informazioni archiviate in fonti di dati come Servizio di archiviazione semplice Amazon , OneDrive e Google Drive; applicazioni come SalesForce, SharePoint e Service Now; e database relazionali come Servizio di database relazionale Amazon (Amazon RDS). L'utilizzo dei connettori Amazon Kendra ti consente di sincronizzare i dati da più repository di contenuti con il tuo indice Amazon Kendra. Quando gli utenti finali pongono domande in linguaggio naturale, Amazon Kendra utilizza algoritmi di machine learning (ML) per comprendere il contesto e restituire le risposte più pertinenti.
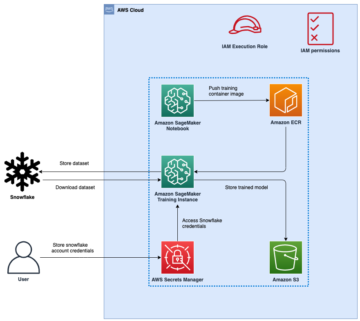
Il connettore S3 di Amazon Kendra supporta l'indicizzazione dei documenti e dei metadati associati archiviati in un bucket S3. Accade spesso che tu voglia assicurarti che le applicazioni in esecuzione all'interno di un VPC abbiano accesso solo a specifici bucket S3 e in molti casi la connessione non deve attraversare Internet per raggiungere gli endpoint pubblici. Molti clienti, tuttavia, possiedono più bucket S3, alcuni dei quali sono accessibili tramite Endpoint VPC per Amazon S3. In questo post, descriviamo come utilizzare il connettore Amazon Kendra S3 aggiornato con supporto VPC per l'utilizzo di endpoint VPC.
Questo post fornisce i passaggi per aiutarti a creare un motore di ricerca aziendale su AWS utilizzando Amazon Kendra collegando i documenti archiviati in un bucket S3 accessibile solo dall'interno di un VPC. Per ulteriori informazioni, vedere migliorare la ricerca aziendale con Amazon Kendra. Il post mostra anche come configurare il connettore per Amazon S3 e come configurare il modo in cui l'indice si sincronizza con l'origine dati quando il contenuto dell'origine dati cambia.
Panoramica della soluzione
Ci sono tre principali miglioramenti al Connettore Amazon Kendra S3 :
- Supporto VPC – Il connettore ora supporta l'utilizzo del tuo Cloud privato virtuale di Amazon (Amazon VPC). Ora puoi connetterti in modo sicuro ad Amazon S3 utilizzando Endpoint VPC per Amazon S3 specificando la connessione VPC, la sottorete e i gruppi di sicurezza.
- Due modalità di sincronizzazione: Quando pianifichi la sincronizzazione di un'origine dati in Amazon S3 su un indice Amazon Kendra, ora puoi scegliere di eseguire la modalità di sincronizzazione completa o la modalità di sincronizzazione dei documenti nuovi, modificati ed eliminati. Nella modalità di sincronizzazione completa, ogni volta che la sincronizzazione viene eseguita, analizza gli oggetti in ogni cartella nel percorso principale che è stato configurato per eseguire la scansione e reinserisce tutti i documenti. L'aggiornamento completo consente di reimpostare l'indice senza la necessità di eliminare e creare una nuova origine dati. Nella modalità di sincronizzazione dei documenti nuovi, modificati ed eliminati, ogni volta che viene eseguito il processo di sincronizzazione, elabora solo gli oggetti che sono stati aggiunti, modificati o eliminati dall'ultima ricerca per indicizzazione. Le ricerche per indicizzazione incrementali possono ridurre il tempo di esecuzione e i costi se utilizzate con set di dati che aggiungono regolarmente nuovi oggetti alle origini dati esistenti.
- Modelli di inclusione ed esclusione aggiuntivi per i documenti: oltre ai prefissi, stiamo introducendo modelli per l'inclusione o l'esclusione di documenti dall'indice. Due tipi di pattern supportati sono glob in stile Unix o tipi di file. Ora puoi aggiungere un modello di espressione regolare per includere cartelle specifiche o escludere cartelle, tipi di file o file specifici dall'origine dati. Ciò può essere utile per repository di dati condivisi che contengono contenuti appartenenti a diverse categorie, classificazioni e tipi di file.
Prerequisiti
Per questa procedura dettagliata, è necessario disporre dei seguenti prerequisiti:
Crea e configura il tuo repository di documenti
Prima di poter creare un indice in Amazon Kendra, devi caricare i documenti in un bucket S3. Questa sezione contiene le istruzioni per creare un bucket S3, ottenere i file e caricarli nel bucket. Dopo aver completato tutti i passaggi di questa sezione, disponi di un'origine dati che Amazon Kendra può utilizzare.
- Sulla Console di gestione AWS, nell'elenco Regione, scegli Stati Uniti orientali (Virginia settentrionale) o qualsiasi altra regione a tua scelta Amazon Kendra è disponibile in.
- Scegli Servizi.
- Sotto Archiviazionescegli S3.
- Sulla console Amazon S3, scegli Crea un secchio.
- Sotto Configurazione generale, Fornire le seguenti informazioni:
- Per Nome secchio, entrare
kendrapost-{your account id}. - Per Regione, scegli la stessa regione che utilizzi per distribuire il tuo indice Amazon Kendra (questo post utilizza
us-east-1). - Sotto Impostazioni secchio, per Blocca l'accesso pubblico, lascia tutto con i valori predefiniti.
- Per Nome secchio, entrare
- Sotto impostazioni avanzate, lascia tutto con i valori predefiniti.
- Scegli Crea un secchio.
- Scaricare AWS_Whitepaper.zip e decomprimere i file.
- Sulla console Amazon S3, seleziona il bucket che hai appena creato e scegli Caricare.
- Carica le cartelle
Best Practices,Databases,GeneraleMachine Learningdal file decompresso.
All'interno del tuo bucket, ora dovresti vedere quattro cartelle.
Aggiungi un'origine dati
A fonte di dati è una posizione in cui sono archiviati i documenti per l'indicizzazione. Puoi sincronizzare automaticamente le origini dati con un indice Amazon Kendra per assicurarti che le ricerche riflettano correttamente i documenti nuovi, aggiornati o eliminati nei repository di origine.
Dopo aver completato tutti i passaggi in questa sezione, avrai un'origine dati collegata ad Amazon Kendra. Per ulteriori informazioni, vedere Aggiunta di documenti da un'origine dati.
Prima di continuare, assicurati che la creazione dell'indice sia completa e che l'indice sia visualizzato come Attivo. Per ulteriori informazioni, vedere Creazione di un indice.
- Sulla console Amazon Kendra, vai al tuo indice (per questo post,
kendra-blog-index). - Sulla
kendra-blog-indexpagina, scegli Aggiungi origini dati.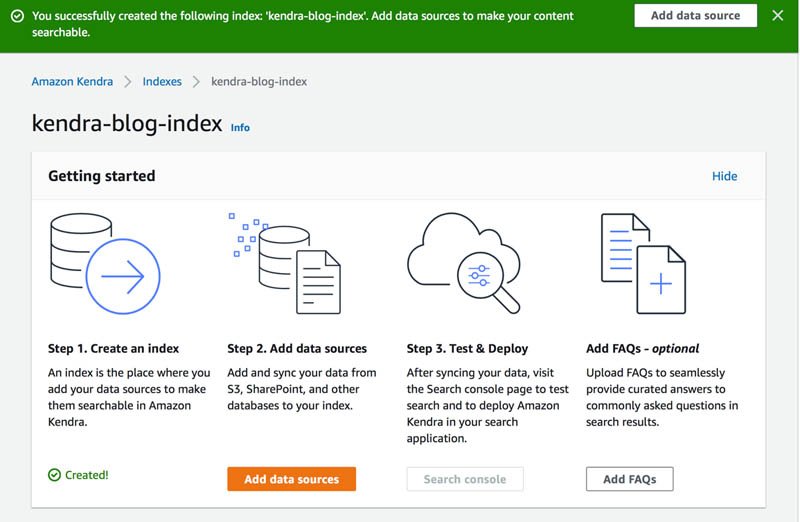
- In Amazon S3, scegli Aggiungi connettore.

Per ulteriori informazioni sulle diverse origini dati supportate da Amazon Kendra, consulta Aggiunta di documenti da un'origine dati.
- Nel Specificare i dettagli dell'origine dati sezione, per Nome dell'origine dati, accedere
aws_white_paper. - Nel Descrizione, accedere
AWS White Paper documentation. - Scegli Avanti.
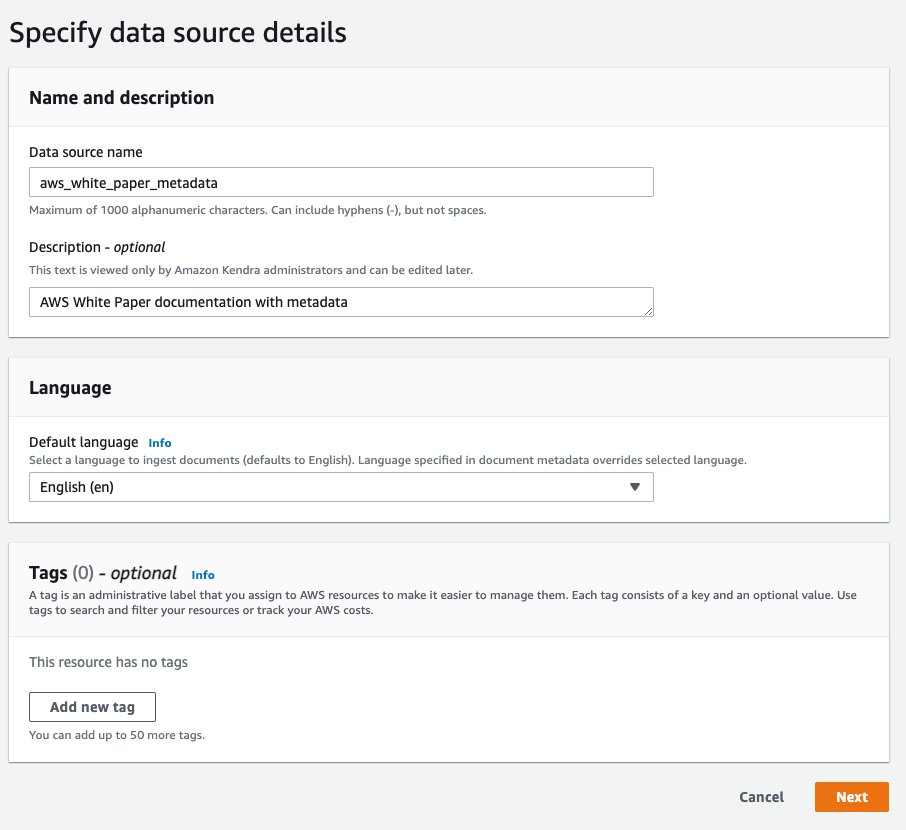
Ora crei un file Gestione dell'identità e dell'accesso di AWS (IAM) per Amazon Kendra.
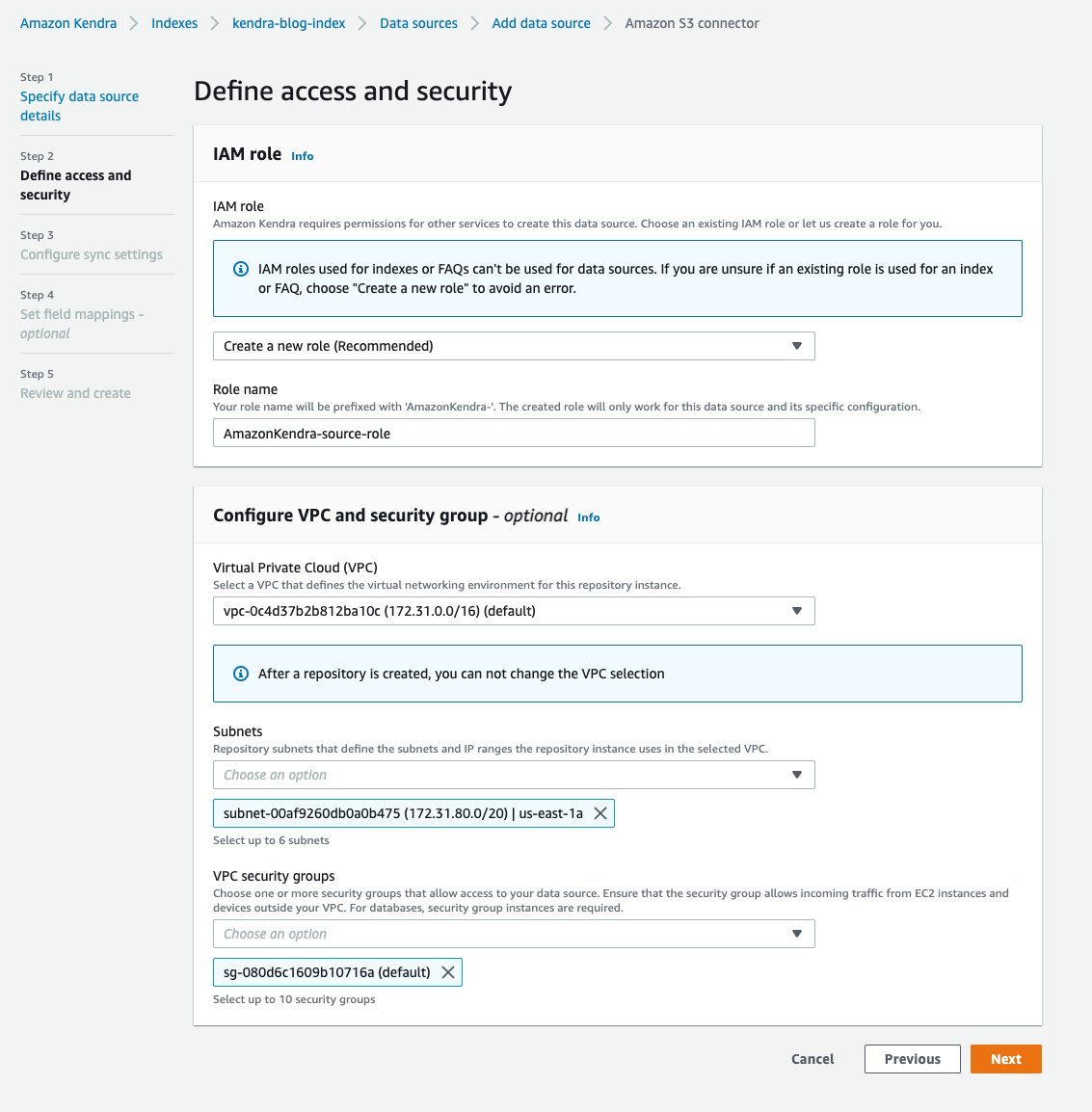
- Nel Definisci accesso e sicurezza pagina, per Ruolo IAM sezione, scegliere Crea un nuovo ruolo.
- Per Nome ruolo, inserisci
source-role(il nome del tuo ruolo è preceduto daAmazonKendra-). - Nel Configura VPC e sicurezza sezione, scegli il tuo VPC, e inserisci il tuo Sottoreti e gruppi di sicurezza VPC.
Per ulteriori informazioni sulla connessione di Amazon Kendra al tuo Amazon Virtual Private Cloud, consulta Configurazione di Amazon Kendra per l'utilizzo di un VPC.
- Scegli Avanti.
- Nel Configura le impostazioni di sincronizzazione pagina, per Immettere la posizione dell'origine dati, inserisci il bucket S3 che hai creato:
kendrapost-{your account id}. - Lasciare Posizione della cartella del prefisso dei file di metadati vuoto.
Per impostazione predefinita, i file di metadati sono archiviati nella stessa directory dei documenti. Se si desidera posizionare questi file in una cartella diversa, è possibile aggiungere un prefisso. Per ulteriori informazioni, vedere Metadati del documento Amazon S3.
- Nel Seleziona la chiave di decodifica, lascialo deselezionato.
- Nel Configurazione aggiuntiva, puoi aggiungere un modello per includere o escludere determinate cartelle o file. Per questo post, mantieni i valori predefiniti.
- Nel Modalità di sincronizzazione scegliere Sincronizzazione di documenti nuovi, modificati o eliminati.
- Nel Frequenzascegli Esegui su richiesta.
Questa fase definisce la frequenza con cui l'origine dati viene sincronizzata con l'indice Amazon Kendra.
- Scegli Avanti.

- Nel Imposta le mappature dei campi page, mantieni i valori predefiniti.
- Scegli Avanti.

- Sulla Rivedi e crea pagina, scegli Aggiungi origine dati.
- Torna al tuo indice Kendra.
- Scegli il tuo Fonte di dati, Quindi scegliere Sincronizza ora per sincronizzare i documenti con l'indice Amazon Kendra.

La durata di questo processo dipende dal numero di documenti indicizzati. Per questo caso d'uso, potrebbero essere necessari 15 minuti, dopodiché dovresti visualizzare un messaggio che indica che la sincronizzazione è andata a buon fine. Nella sezione Cronologia esecuzione sincronizzazione, puoi vedere che sono stati sincronizzati 40 documenti.

Il tuo indice Amazon Kendra è ora pronto per le query in linguaggio naturale. Quando esegui ricerche nel tuo indice, Amazon Kendra utilizza tutti i dati e i metadati forniti per restituire le risposte più accurate alla tua query di ricerca. Sulla console Amazon Kendra, scegli Cerca contenuto indicizzato. Nel campo della query, inizia con una query del tipo "Quale servizio AWS ha 11 nove di durabilità?"
Per ulteriori informazioni sull'esecuzione di query sull'indice, vedere Interrogazione di un indice
Sincronizza le modifiche all'origine dati per eseguire ricerche nell'indice
L'origine dati è configurata per sincronizzare tutti i dati nuovi, modificati o eliminati. Prima di poter sincronizzare l'origine dati in modo incrementale con un indice in Amazon Kendra, devi caricare nuovi documenti in un bucket S3.
- Sulla console Amazon S3, seleziona il bucket che hai appena creato e scegli Caricare.
- Carica le cartelle
SecurityedWell_Architecteddal file decompresso.
Ora puoi sincronizzare i nuovi documenti aggiunti al bucket S3:
- Sulla console Amazon Kendra, scegli Fonti dei dati e quindi seleziona la tua origine dati S3.
- Scegli Sincronizza ora.
La durata di questo processo dipende dal numero di documenti indicizzati. Per questo caso d'uso, potrebbero essere necessari 15 minuti, dopodiché dovrebbe essere visualizzato un messaggio che indica che la sincronizzazione ha avuto esito positivo.
Nel Sincronizza cronologia esecuzioni sezione, puoi vedere che 20 documenti sono stati sincronizzati.

Reindicizzare l'origine dati
In uno scenario in cui l'origine dati contiene informazioni obsolete, ora puoi reindicizzare l'origine dati senza dover eliminare e creare una nuova origine dati. Per modificare la modalità di sincronizzazione e reindicizzare l'origine dati, completare i seguenti passaggi:
- Sulla console Amazon Kendra, scegli Fonti dei dati e quindi seleziona la tua origine dati S3.
- Sulla Azioni menù, scegliere Modifica.
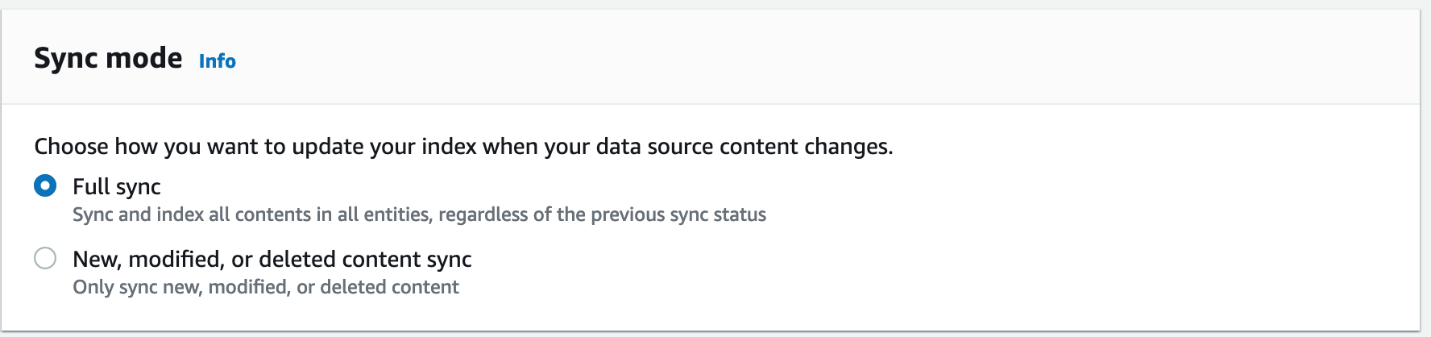
- Scegli Avanti traslocare Passaggio 3: configurare la pagina delle impostazioni di sincronizzazione.
- Per Modalità di sincronizzazione, seleziona Sincronizzazione completa.
- Nel Frequenzascegli Esegui su richiesta.
- Scegli Avanti.
- Nel Imposta le mappature dei campi page, mantieni i valori predefiniti.
- Scegli Avanti.
- Sulla Rivedi e crea pagina, scegli Aggiornanento.
Ora puoi sincronizzare i nuovi documenti aggiunti al bucket S3.
- Sulla console Amazon Kendra, scegli Fonti dei dati e quindi seleziona la tua origine dati S3.
- Scegli Sincronizza ora.
Nel Sincronizza cronologia esecuzioni sezione, puoi vedere che tutti i documenti sono stati sincronizzati indipendentemente dallo stato di sincronizzazione precedente nella colonna modificata.

ripulire
Per evitare di incorrere in addebiti futuri e per ripulire ruoli e criteri inutilizzati, elimina le risorse che hai creato:
- Nell'indice Amazon Kendra, scegli Indici nel pannello di navigazione.
- Seleziona l'indice che hai creato e sul Azioni menù, scegliere Elimina.
- Per confermare l'eliminazione, immettere Elimina quando richiesto e scegliere Elimina.
Aspetta di ricevere il messaggio di conferma; il processo può richiedere fino a 15 minuti.
- Sulla console Amazon S3, eliminare il bucket S3.
- Sulla console IAM, eliminare i ruoli IAM corrispondenti.
Conclusione
In questo post, hai imparato a utilizzare Amazon Kendra per distribuire un servizio di ricerca aziendale utilizzando una connessione sicura ad Amazon S3 che non richiede un gateway Internet o un dispositivo NAT (Network Address Translation). Puoi abilitare sincronizzazioni più rapide per i tuoi documenti utilizzando la modalità di sincronizzazione.
Ci sono molte funzionalità aggiuntive che non abbiamo trattato. Per esempio:
- Puoi abilitare il controllo degli accessi basato sull'utente per il tuo indice Amazon Kendra e limitare l'accesso ai documenti in base ai controlli di accesso che hai già configurato.
- Puoi mappare gli attributi degli oggetti agli attributi dell'indice di Amazon Kendra e abilitarli per il facet, la ricerca e la visualizzazione nei risultati della ricerca.
- Puoi trovare rapidamente informazioni da pagine Web (tabelle HTML) utilizzando la ricerca tabulare di Amazon Kendra
Per ulteriori informazioni su Amazon Kendra, fare riferimento Guida per sviluppatori Amazon Kendra.
Informazioni sugli autori
 Maran Chandrasekaran è Senior Solutions Architect presso Amazon Web Services e lavora con i nostri clienti aziendali. Al di fuori del lavoro, ama viaggiare.
Maran Chandrasekaran è Senior Solutions Architect presso Amazon Web Services e lavora con i nostri clienti aziendali. Al di fuori del lavoro, ama viaggiare.
 Arjun Agrawal è Software Engineer presso AWS, attualmente lavora con un team Amazon Kendra su un motore di ricerca aziendale. È appassionato di nuove tecnologie e di risoluzione dei problemi del mondo reale. Al di fuori del lavoro, ama fare escursioni e viaggiare.
Arjun Agrawal è Software Engineer presso AWS, attualmente lavora con un team Amazon Kendra su un motore di ricerca aziendale. È appassionato di nuove tecnologie e di risoluzione dei problemi del mondo reale. Al di fuori del lavoro, ama fare escursioni e viaggiare.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/search-for-answers-accurately-using-amazon-kendra-s3-connector-with-vpc-support/
- 10
- 100
- 11
- 7
- a
- Chi siamo
- accesso
- accessibile
- Il mio account
- preciso
- con precisione
- operanti in
- aggiunto
- aggiunta
- aggiuntivo
- indirizzo
- Dopo shavasana, sedersi in silenzio; saluti;
- Algoritmi
- Tutti
- consente
- già
- Amazon
- Amazon Kendra
- Amazon RDS
- Amazon Web Services
- ed
- risposte
- applicazioni
- associato
- gli attributi
- automaticamente
- disponibile
- evitare
- AWS
- precedente
- basato
- base
- prima
- funzionalità
- Custodie
- casi
- categoria
- certo
- Modifiche
- oneri
- scegliere
- Scegli
- classificazione
- Cloud
- Colonna
- completamento di una
- completando
- Confermare
- Connettiti
- Collegamento
- veloce
- consolle
- contiene
- contenuto
- contesto
- continua
- di controllo
- controlli
- correttamente
- Corrispondente
- Costo
- coprire
- creare
- creato
- creazione
- Attualmente
- Clienti
- dati
- Banca Dati
- banche dati
- dataset
- Predefinito
- definisce
- dimostra
- dipende
- schierare
- descrivere
- Costruttori
- dispositivo
- diverso
- Dsiplay
- documento
- documenti
- non
- guidare
- durevolezza
- est
- facile da usare
- enable
- Abilita
- motore
- ingegnere
- entrare
- Impresa
- clienti aziendali
- Ricerca aziendale
- Etere (ETH)
- Ogni
- qualunque cosa
- esempio
- esistente
- Caratteristiche
- campo
- Compila il
- File
- Trovare
- i seguenti
- Frequenza
- da
- pieno
- futuro
- porta
- ottenere
- Gruppo
- avendo
- Aiuto
- Escursione
- storia
- Come
- Tutorial
- Tuttavia
- HTML
- HTTPS
- IAM
- Identità
- miglioramenti
- in
- includere
- inclusione
- Index
- informazioni
- istruzioni
- integrare
- Intelligente
- Internet
- l'introduzione di
- indipendentemente
- IT
- Lavoro
- mantenere
- Lingua
- Cognome
- IMPARARE
- imparato
- apprendimento
- Lasciare
- connesso
- Lista
- caricare
- località
- macchina
- machine learning
- Principale
- make
- gestione
- molti
- carta geografica
- Menu
- messaggio
- Metadati
- verbale
- ML
- Moda
- modalità di
- modificato
- modificare
- Scopri di più
- maggior parte
- cambiano
- multiplo
- Nome
- Naturale
- Linguaggio naturale
- Navigare
- Navigazione
- Bisogno
- Rete
- reti
- New
- numero
- oggetto
- oggetti
- Microsoft Onedrive
- al di fuori
- proprio
- vetro
- Carta
- appassionato
- sentiero
- Cartamodello
- modelli
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- Termini e Condizioni
- Post
- prerequisiti
- precedente
- un bagno
- problemi
- processi
- i processi
- fornire
- purché
- fornisce
- la percezione
- Domande
- più veloce
- rapidamente
- raggiungere
- pronto
- mondo reale
- ridurre
- riflettere
- regione
- Basic
- pertinente
- richiedere
- Risorse
- limitare
- Risultati
- ritorno
- Ruolo
- ruoli
- radice
- Correre
- running
- forza di vendita
- stesso
- scenario
- programma
- Cerca
- motore di ricerca
- Sezione
- sicuro
- in modo sicuro
- problemi di
- anziano
- servizio
- Servizi
- set
- impostazioni
- condiviso
- sharepoint
- dovrebbero
- Spettacoli
- Un'espansione
- da
- So
- Software
- Software Engineer
- Soluzioni
- Soluzione
- alcuni
- Fonte
- fonti
- specifico
- inizia a
- Stato dei servizi
- step
- Passi
- conservazione
- memorizzati
- negozi
- style
- sottorete
- sottoreti
- di successo
- tale
- supporto
- supportato
- supporti
- dati
- Fai
- team
- Tecnologia
- I
- L’ORIGINE
- loro
- tre
- tempo
- a
- Traduzione
- viaggiare
- Tipi di
- per
- capire
- unix
- non usato
- aggiornato
- us
- uso
- caso d'uso
- utenti
- Valori
- Virginia
- virtuale
- walkthrough
- sito web
- servizi web
- quale
- bianca
- white paper
- entro
- senza
- Lavora
- lavoro
- Trasferimento da aeroporto a Sharm
- zefiro
- Codice postale