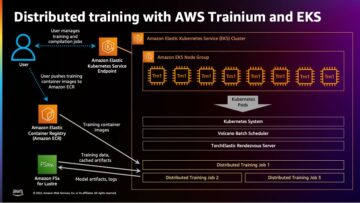
Nella visione artificiale, la segmentazione semantica è il compito di classificare ogni pixel in un'immagine con una classe da un insieme noto di etichette in modo tale che i pixel con la stessa etichetta condividano determinate caratteristiche. Genera una maschera di segmentazione delle immagini di input. Ad esempio, le immagini seguenti mostrano una maschera di segmentazione di cat .
 |
 |
Nel mese di novembre 2018, Amazon Sage Maker ha annunciato il lancio dell'algoritmo di segmentazione semantica SageMaker. Con questo algoritmo, puoi addestrare i tuoi modelli con un set di dati pubblico o il tuo set di dati. I set di dati di segmentazione delle immagini più diffusi includono il set di dati COCO (Common Objects in Context) e le classi di oggetti visivi PASCAL (PASCAL VOC), ma le classi delle loro etichette sono limitate e potresti voler addestrare un modello su oggetti target che non sono inclusi nel set di dati pubblici. In questo caso, puoi usare Amazon SageMaker verità fondamentale per etichettare il tuo set di dati.
In questo post, mostro le seguenti soluzioni:
- Utilizzo di Ground Truth per etichettare un set di dati di segmentazione semantica
- Trasformare i risultati da Ground Truth nel formato di input richiesto per l'algoritmo di segmentazione semantica integrato di SageMaker
- Utilizzo dell'algoritmo di segmentazione semantica per addestrare un modello ed eseguire l'inferenza
Etichettatura dei dati di segmentazione semantica
Per costruire un modello di apprendimento automatico per la segmentazione semantica, dobbiamo etichettare un set di dati a livello di pixel. Ground Truth ti dà la possibilità di utilizzare annotatori umani Amazon Mechanical Turk, fornitori di terze parti o la tua forza lavoro privata. Per saperne di più sulla forza lavoro, fare riferimento a Crea e gestisci la forza lavoro. Se non vuoi gestire da solo il personale addetto all'etichettatura, Amazon SageMaker Ground Truth Plus è un'altra grande opzione come nuovo servizio di etichettatura dei dati chiavi in mano che consente di creare rapidamente set di dati di addestramento di alta qualità e ridurre i costi fino al 40%. Per questo post, ti mostro come etichettare manualmente il set di dati con la funzione di segmentazione automatica Ground Truth e l'etichettatura crowdsource con una forza lavoro Mechanical Turk.
Etichettatura manuale con Ground Truth
A dicembre 2019, Ground Truth ha aggiunto una funzione di segmentazione automatica all'interfaccia utente di etichettatura della segmentazione semantica per aumentare la produttività dell'etichettatura e migliorare la precisione. Per ulteriori informazioni, fare riferimento a Segmentazione automatica degli oggetti durante l'esecuzione dell'etichettatura della segmentazione semantica con Amazon SageMaker Ground Truth. Con questa nuova funzionalità, puoi accelerare il processo di etichettatura sulle attività di segmentazione. Invece di disegnare un poligono aderente o utilizzare lo strumento pennello per catturare un oggetto in un'immagine, disegna solo quattro punti: nei punti più in alto, più in basso, più a sinistra e più a destra dell'oggetto. Ground Truth prende questi quattro punti come input e utilizza l'algoritmo Deep Extreme Cut (DEXTR) per produrre una maschera aderente attorno all'oggetto. Per un tutorial sull'utilizzo di Ground Truth per l'etichettatura della segmentazione semantica delle immagini, fare riferimento a Segmentazione semantica dell'immagine. Quello che segue è un esempio di come lo strumento di segmentazione automatica genera automaticamente una maschera di segmentazione dopo aver scelto i quattro punti estremi di un oggetto.


Etichettatura in crowdsourcing con una forza lavoro Mechanical Turk
Se si dispone di un set di dati di grandi dimensioni e non si desidera etichettare manualmente centinaia o migliaia di immagini, è possibile utilizzare Mechanical Turk, che fornisce una forza lavoro umana su richiesta e scalabile per completare lavori che gli esseri umani possono svolgere meglio dei computer. Il software Mechanical Turk formalizza le offerte di lavoro alle migliaia di lavoratori disposti a svolgere un lavoro frammentario a loro piacimento. Il software recupera anche il lavoro svolto e lo compila per te, il richiedente, che paga i lavoratori per un lavoro soddisfacente (solo). Per iniziare con Mechanical Turk, fare riferimento a Introduzione ad Amazon Mechanical Turk.
Crea un lavoro di etichettatura
Quello che segue è un esempio di un lavoro di etichettatura Mechanical Turk per un set di dati di tartarughe marine. Il set di dati delle tartarughe marine proviene dalla competizione Kaggle Rilevamento facciale di tartarughe marinee ho selezionato 300 immagini del set di dati a scopo dimostrativo. La tartaruga marina non è una classe comune nei set di dati pubblici, quindi può rappresentare una situazione che richiede l'etichettatura di un enorme set di dati.
- Sulla console di SageMaker, scegli Lavori di etichettatura nel pannello di navigazione.
- Scegli Crea lavoro di etichettatura.
- Inserisci un nome per il tuo lavoro.
- Nel Impostazione dei dati di input, selezionare Configurazione automatica dei dati.
Questo genera un manifest di dati di input. - Nel Posizione S3 per i set di dati di input, immettere il percorso per il set di dati.

- Nel Categoria di attivitàscegli Immagine.
- Nel Selezione attività, selezionare Segmentazione semantica.

- Nel Tipi di lavoratori, selezionare Amazon Mechanical Turk.
- Configura le impostazioni per il timeout dell'attività, il tempo di scadenza dell'attività e il prezzo per attività.

- Aggiungi un'etichetta (per questo post,
sea turtle), e fornire istruzioni per l'etichettatura. - Scegli Creare.

Dopo aver impostato il lavoro di etichettatura, puoi controllare l'avanzamento dell'etichettatura sulla console SageMaker. Quando è contrassegnato come completato, puoi scegliere il lavoro per controllare i risultati e utilizzarli per i passaggi successivi.

Trasformazione del set di dati
Dopo aver ottenuto l'output da Ground Truth, puoi utilizzare gli algoritmi integrati di SageMaker per addestrare un modello su questo set di dati. Innanzitutto, è necessario preparare il set di dati etichettato come interfaccia di input richiesta per l'algoritmo di segmentazione semantica di SageMaker.
Canali dati di input richiesti
La segmentazione semantica di SageMaker prevede che il tuo set di dati di addestramento venga archiviato Servizio di archiviazione semplice Amazon (Amazon S3). Il set di dati in Amazon S3 dovrebbe essere presentato in due canali, uno per train e uno per validation, utilizzando quattro directory, due per le immagini e due per le annotazioni. Le annotazioni dovrebbero essere immagini PNG non compresse. Il set di dati potrebbe anche avere una mappa delle etichette che descrive come vengono stabilite le mappature delle annotazioni. In caso contrario, l'algoritmo utilizza un valore predefinito. Per inferenza, un endpoint accetta immagini con un image/jpeg tipo di contenuto. Quella che segue è la struttura richiesta dei canali dati:
Ogni immagine JPG nel treno e nelle directory di convalida ha un'immagine di etichetta PNG corrispondente con lo stesso nome in train_annotation ed validation_annotation directory. Questa convenzione di denominazione aiuta l'algoritmo ad associare un'etichetta all'immagine corrispondente durante l'addestramento. Il treno, train_annotation, convalida e validation_annotation i canali sono obbligatori. Le annotazioni sono immagini PNG a canale singolo. Il formato funziona fintanto che i metadati (modalità) nell'immagine aiutano l'algoritmo a leggere le immagini di annotazione in un intero senza segno a 8 bit a canale singolo.
Output dal lavoro di etichettatura Ground Truth
Gli output generati dal lavoro di etichettatura Ground Truth hanno la seguente struttura di cartelle:
Le maschere di segmentazione vengono salvate in s3://turtle2022/labelturtles/annotations/consolidated-annotation/output. Ogni immagine di annotazione è un file .png che prende il nome dall'indice dell'immagine di origine e dall'ora in cui l'etichettatura dell'immagine è stata completata. Ad esempio, le seguenti sono l'immagine di origine (Image_1.jpg) e la relativa maschera di segmentazione generata dalla forza lavoro di Mechanical Turk (0_2022-02-10T17:41:04.724225.png). Si noti che l'indice della maschera è diverso dal numero nel nome dell'immagine di origine.
 |
 |
Il manifest di output del processo di etichettatura è in /manifests/output/output.manifest file. È un file JSON e ogni riga registra una mappatura tra l'immagine di origine e la relativa etichetta e altri metadati. La seguente riga JSON registra una mappatura tra l'immagine di origine mostrata e la sua annotazione:
L'immagine di origine si chiama Image_1.jpg e il nome dell'annotazione è 0_2022-02-10T17:41: 04.724225.png. Per preparare i dati come formati di canale dati richiesti dell'algoritmo di segmentazione semantica di SageMaker, è necessario modificare il nome dell'annotazione in modo che abbia lo stesso nome delle immagini JPG di origine. E dobbiamo anche dividere il set di dati in train ed validation directory per le immagini sorgente e le annotazioni.
Trasforma l'output da un lavoro di etichettatura Ground Truth nel formato di input richiesto
Per trasformare l'output, completare i seguenti passaggi:
- Scarica tutti i file dal processo di etichettatura da Amazon S3 in una directory locale:
- Leggi il file manifest e cambia i nomi dell'annotazione con gli stessi nomi delle immagini di origine:
- Suddividi il treno e i set di dati di convalida:
- Crea una directory nel formato richiesto per i canali dati dell'algoritmo di segmentazione semantica:
- Sposta il treno e le immagini di convalida e le relative annotazioni nelle directory create.
- Per le immagini, utilizzare il seguente codice:
- Per le annotazioni, utilizzare il codice seguente:
- Carica i set di dati del treno e della convalida e i relativi set di dati di annotazione su Amazon S3:
Formazione del modello di segmentazione semantica di SageMaker
In questa sezione, esamineremo i passaggi per addestrare il tuo modello di segmentazione semantica.
Segui il quaderno di esempio e imposta i canali dati
Puoi seguire le istruzioni in L'algoritmo di segmentazione semantica è ora disponibile in Amazon SageMaker per implementare l'algoritmo di segmentazione semantica nel set di dati etichettato. Questo campione taccuino mostra un esempio end-to-end che introduce l'algoritmo. Nel quaderno imparerai come addestrare e ospitare un modello di segmentazione semantica utilizzando la rete completamente convoluzionale (FCN) algoritmo utilizzando il Set di dati Pascal VOC per allenamento. Poiché non ho intenzione di addestrare un modello dal set di dati Pascal VOC, ho saltato il passaggio 3 (preparazione dei dati) in questo notebook. Invece, ho creato direttamente train_channel, train_annotation_channe, validation_channele validation_annotation_channel utilizzando le posizioni S3 in cui ho archiviato le mie immagini e annotazioni:
Regola gli iperparametri per il tuo set di dati nello stimatore SageMaker
Ho seguito il taccuino e ho creato un oggetto estimatore SageMaker (ss_estimator) per addestrare il mio algoritmo di segmentazione. C'è una cosa che dobbiamo personalizzare per il nuovo set di dati ss_estimator.set_hyperparameters: dobbiamo cambiare num_classes=21 a num_classes=2 (turtle ed background), e ho anche cambiato epochs=10 a epochs=30 perché 10 è solo a scopo dimostrativo. Quindi ho usato l'istanza p3.2xlarge per l'addestramento del modello impostando instance_type="ml.p3.2xlarge". La formazione completata in 8 minuti. Il migliore MIoU (Mean Intersection over Union) di 0.846 si ottiene all'epoca 11 con a pix_acc (la percentuale di pixel nell'immagine che sono classificati correttamente) di 0.925, che è un risultato abbastanza buono per questo piccolo set di dati.
Risultati dell'inferenza del modello
Ho ospitato il modello su un'istanza ml.c5.xlarge a basso costo:
Infine, ho preparato un set di test di 10 immagini di tartarughe per vedere il risultato dell'inferenza del modello di segmentazione addestrato:
Le immagini seguenti mostrano i risultati.

Le maschere di segmentazione delle tartarughe marine sembrano accurate e sono contento di questo risultato addestrato su un set di dati di 300 immagini etichettato dai lavoratori di Mechanical Turk. Puoi anche esplorare altre reti disponibili come rete di analisi delle scene piramidali (PSP) or DeepLab-V3 nel quaderno di esempio con il tuo set di dati.
ripulire
Elimina l'endpoint quando hai finito per evitare di incorrere in costi continui:
Conclusione
In questo post, ho mostrato come personalizzare l'etichettatura dei dati di segmentazione semantica e l'addestramento del modello utilizzando SageMaker. Innanzitutto, puoi impostare un lavoro di etichettatura con lo strumento di segmentazione automatica o utilizzare una forza lavoro Mechanical Turk (oltre ad altre opzioni). Se hai più di 5,000 oggetti, puoi anche utilizzare l'etichettatura automatica dei dati. Quindi trasformi gli output del tuo lavoro di etichettatura Ground Truth nei formati di input richiesti per il training di segmentazione semantica integrato di SageMaker. Successivamente, puoi utilizzare un'istanza di calcolo accelerato (come p2 o p3) per addestrare un modello di segmentazione semantica con quanto segue taccuino e distribuire il modello in un'istanza più conveniente (come ml.c5.xlarge). Infine, puoi rivedere i risultati dell'inferenza sul tuo set di dati di test con poche righe di codice.
Inizia con la segmentazione semantica di SageMaker etichettatura dei dati ed modello di formazione con il tuo set di dati preferito!
L'autore
 Kara Yang è un Data Scientist in AWS Professional Services. È appassionata di aiutare i clienti a raggiungere i loro obiettivi di business con i servizi cloud AWS. Ha aiutato le organizzazioni a creare soluzioni ML in diversi settori come quello manifatturiero, automobilistico, della sostenibilità ambientale e aerospaziale.
Kara Yang è un Data Scientist in AWS Professional Services. È appassionata di aiutare i clienti a raggiungere i loro obiettivi di business con i servizi cloud AWS. Ha aiutato le organizzazioni a creare soluzioni ML in diversi settori come quello manifatturiero, automobilistico, della sostenibilità ambientale e aerospaziale.
- Coinsmart. Il miglior scambio di bitcoin e criptovalute d'Europa.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. ACCESSO LIBERO.
- Criptofalco. Radar Altcoin. Prova gratuita.
- Fonte: https://aws.amazon.com/blogs/machine-learning/semantic-segmentation-data-labeling-and-model-training-using-amazon-sagemaker/
- '
- "
- 000
- 10
- 100
- 11
- 2019
- a
- Chi siamo
- accelerare
- accelerata
- preciso
- Raggiungere
- raggiunto
- operanti in
- aggiunto
- Aeronautico
- algoritmo
- Algoritmi
- Tutti
- Amazon
- ha annunciato
- Un altro
- in giro
- Associate
- Automatizzata
- automaticamente
- settore automobilistico
- disponibile
- AWS
- sfondo
- perché
- MIGLIORE
- Meglio
- fra
- costruire
- incassato
- affari
- catturare
- Custodie
- certo
- il cambiamento
- canali
- Scegli
- classe
- classi
- classificato
- Cloud
- servizi cloud
- codice
- Uncommon
- concorrenza
- completamento di una
- computer
- computer
- informatica
- fiducia
- consolle
- contenuto
- comodità
- Corrispondente
- costo effettivo
- Costi
- creare
- creato
- Clienti
- personalizzare
- dati
- scienziato di dati
- deep
- dimostrare
- schierare
- diverso
- direttamente
- disegno
- durante
- ogni
- Abilita
- da un capo all'altro
- endpoint
- entrare
- ambientale
- sviluppate
- esempio
- Tranne
- previsto
- aspetta
- esplora
- estremo
- Faccia
- caratteristica
- Nome
- seguire
- i seguenti
- formato
- da
- generato
- Obiettivi
- buono
- grigio
- grande
- contento
- aiutato
- aiutare
- aiuta
- alta qualità
- ospitato
- Come
- Tutorial
- HTTPS
- umano
- Gli esseri umani
- centinaia
- Immagine
- immagini
- realizzare
- competenze
- includere
- incluso
- Aumento
- Index
- industrie
- informazioni
- ingresso
- esempio
- Interfaccia
- intersezione
- l'introduzione di
- IT
- Lavoro
- Offerte di lavoro
- conosciuto
- Discografica
- etichettatura
- per il tuo brand
- grandi
- lanciare
- IMPARARE
- apprendimento
- Livello
- Limitato
- linea
- Linee
- Lista
- locale
- località
- posizioni
- Lunghi
- Guarda
- macchina
- machine learning
- gestire
- obbligatorio
- manualmente
- consigliato per la
- carta geografica
- mappatura
- mask
- Mascherine
- massiccio
- meccanico
- forza
- ML
- modello
- modelli
- Scopri di più
- multiplo
- nomi
- di denominazione
- Navigazione
- Rete
- reti
- GENERAZIONE
- taccuino
- numero
- Offerte
- Opzione
- Opzioni
- organizzazioni
- Altro
- proprio
- appassionato
- per cento
- esecuzione
- punti
- Poligono
- Popolare
- Preparare
- piuttosto
- prezzo
- un bagno
- processi
- produrre
- professionale
- fornire
- fornisce
- la percezione
- fini
- rapidamente
- RE
- record
- rappresentare
- necessario
- richiede
- Risultati
- recensioni
- stesso
- scalabile
- Scienziato
- MARE
- segmentazione
- selezionato
- servizio
- Servizi
- set
- regolazione
- Condividi
- mostrare attraverso le sue creazioni
- mostrato
- Un'espansione
- situazione
- piccole
- So
- Software
- Soluzioni
- dividere
- iniziato
- conservazione
- Sostenibilità
- Target
- task
- team
- test
- I
- L’ORIGINE
- cosa
- di parti terze standard
- migliaia
- Attraverso
- portata
- tempo
- Treni
- Training
- Trasformare
- unione
- uso
- convalida
- fornitori
- visione
- OMS
- Lavora
- lavoratori
- Forza lavoro
- lavori
- Trasferimento da aeroporto a Sharm