Introduzione
L'industria musicale è diventata più popolare e il modo in cui le persone ascoltano la musica sta cambiando a macchia d'olio. Lo sviluppo dei servizi di streaming musicale ha aumentato la domanda di sistemi automatici di classificazione e raccomandazione della musica. Spotify, uno dei principali siti di streaming musicale al mondo, ha milioni di abbonati e un enorme catalogo di brani. Tuttavia, affinché i clienti possano vivere un'esperienza musicale personalizzata, Spotify deve consigliare brani che si adattano alle loro preferenze. Spotify utilizza algoritmi di apprendimento automatico per guidare e classificare la musica in base al genere.

Fonte: www.analyticsvidhya.com
Questo progetto si concentrerà sul problema della classificazione del genere multiclasse di Spotify, in cui scarichiamo il set di dati da Kaggle.
Goal – Questo progetto mira a sviluppare un modello che classifica il genere in grado di prevedere con precisione il genere di una traccia musicale su spotify.
obiettivi formativi
- Indagare il legame tra i generi musicali su Spotify e le loro caratteristiche acustiche.
- Creare un modello di classificazione basato sulle caratteristiche uditive per prevedere il genere di una determinata canzone.
- Per indagare la distribuzione di vari generi musicali Spotify nel set di dati.
- Pulire e preelaborare i dati per prepararli alla modellazione.
- Per valutare le prestazioni del modello di categorizzazione e migliorarne l'accuratezza.
Questo articolo è stato pubblicato come parte di Blogathon sulla scienza dei dati.
Sommario
Prerequisiti
Prima di iniziare l'implementazione, dobbiamo installare e importare alcune delle librerie. Le librerie elencate di seguito sono obbligatorie:
Pandas: una libreria per la manipolazione e l'analisi dei dati.
NumPy: Un pacchetto di calcolo scientifico utilizzato per i calcoli di matrici.
matplotlib: una libreria di plottaggio per il linguaggio di programmazione Python.
Snato: una libreria di visualizzazione dei dati basata su matplotlib.
Impara: una libreria di apprendimento automatico per la creazione di modelli per la classificazione
TensorFlow: una popolare libreria open source per la creazione e l'addestramento di modelli di deep learning.
Per installarli, eseguiamo questo comando.
!pip install pandas !pip install numpy
!pip install matplotlib
!pip install seaborn
!pip install sklearn
!pip install tensorflowPipeline di progetto
Pre-elaborazione dei dati: pulisci e preelabora il set di dati "genres_v2" per prepararlo per l'apprendimento automatico.
Feature Engineering: Estrai caratteristiche significative dai file audio che ci aiuteranno ad addestrare il nostro modello.
Selezione del modello: Valuta diversi algoritmi di machine learning per trovare il modello con le migliori prestazioni.
Modello di formazione: addestra il modello selezionato sul set di dati preelaborato e ne valuta le prestazioni.
Distribuzione del modello: distribuisci il modello addestrato in un'applicazione online in grado di consigliare brani musicali su Spotify in base alle preferenze dell'utente
Quindi, iniziamo a fare un po' di codice.
Progetto
Innanzitutto, dobbiamo scaricare il set di dati. Puoi scaricare il set di dati da Kaggle. Dobbiamo importare le librerie necessarie per eseguire i nostri compiti.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn import preprocessing
from sklearn import metrics
import numpy as np
import tensorflow as tf
from tensorflow import keras
from sklearn.decomposition import PCA, KernelPCA, TruncatedSVD
from sklearn.manifold import Isomap, TSNE, MDS
import random
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis, QuadraticDiscriminantAnalysis
import warnings warnings.simplefilter("ignore")Carica il set di dati
Carichiamo il set di dati utilizzando panda read_csv e il set di dati contiene 42305 righe e 22 colonne ed è composto da oltre 18000 tracce.
data = pd.read_csv("Desktop/genres_v2.csv")
data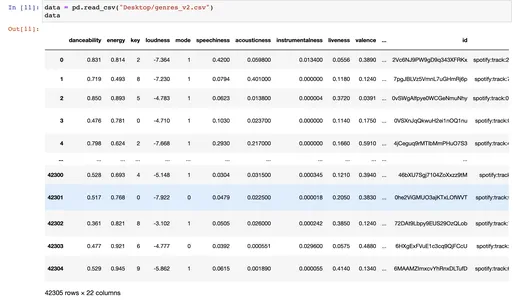
Esplorare i dati
Uso il metodo "iloc" per selezionare le righe e le colonne che formano un frame di dati in base alle loro posizioni di indice intero. Sto scegliendo le prime 20 colonne del df.
data.iloc[:,:20] # this is for the first 20 columns data.iloc[:,20:] # this is for the 21st column data.info()Quando chiami data.info(), stamperà le seguenti informazioni:
- Il numero di righe e colonne nel frame di dati.
- Il nome di ogni colonna, il relativo tipo di dati e il numero di valori non nulli in quella colonna.
- Il numero totale di valori non nulli nel frame di dati.
- L'utilizzo della memoria di DataFrame.
data.nunique() # number of unique values in our data set.Pulizia dei dati
Qui, vogliamo pulire i nostri dati rimuovendo le colonne non necessarie che non aggiungono alcun valore alla previsione.
df = data.drop(["type","type","id","uri","track_href","analysis_url","song_name", "Unnamed: 0","title", "duration_ms", "time_signature"], axis =1)
df
Abbiamo rimosso alcune colonne che non aggiungono alcun valore a questo particolare problema e messo axis = 1, dove rilascia le colonne anziché le righe. Stiamo nuovamente chiamando il Data Frame per vedere il nuovo Data Frame con informazioni utili.
Il df. Il metodo describe() genera statistiche descrittive di un frame di dati Pandas. Fornisce un riepilogo della tendenza centrale e della dispersione e della forma della distribuzione di un set di dati.
Dopo aver eseguito questo comando, puoi vedere tutte le statistiche descrittive del Data Frame, come std, mean, median, percentile, min e max.
df.describe()Per visualizzare un riepilogo di un DataFrame o una Serie Pandas, utilizzare la funzione df.info(). Fornisce informazioni sul set di dati come il numero di righe e colonne, i tipi di dati di ciascuna colonna, il numero di valori non nulli in ciascuna colonna e l'utilizzo della memoria del set di dati.
df.info()
df["genre"].value_counts()
ax = sns.histplot(df["genre"]) genera un istogramma della distribuzione dei valori in un DataFrame Pandas denominato colonna "genre" di df. Questo codice può essere utilizzato per visualizzare la frequenza di alcuni generi Spotify in un set di dati musicali.
ax = sns.histplot(df["genre"])
_ = plt.xticks(rotation=90)
_ = plt.title("Genres")Il codice seguente elimina o elimina tutte le righe in un DataFrame Pandas in cui il valore nella colonna "genre" è uguale a "Pop". L'indice del DataFrame viene quindi reimpostato sull'intervallo in cui inizia con 0. Infine, calcola la matrice di correlazione delle colonne rimanenti del DataFrame.
Questo codice aiuta a studiare un set di dati eliminando le righe non necessarie e trovando correlazioni tra le variabili rimanenti.
df.drop(df.loc[df['genre']=="Pop"].index, inplace=True)
df = df.reset_index(drop = True)
df = df.corr()Il seguente codice sns. heatmap (df, cmap='coolwarm, annot=True) plt. show() genera una heatmap che rappresenta la matrice di correlazione di un Pandas DataFrame df.
Questo codice aiuta a trovare e visualizzare la forza e la direzione delle correlazioni tra le variabili in un set di dati. La codifica a colori della mappa di calore rende facile vedere quali coppie di variabili sono altamente correlate e quali no.
sns.heatmap(df, cmap='coolwarm', annot=True ) plt.show()12pythonIl codice seguente seleziona un sottoinsieme di colonne in un Pandas DataFrame df denominato x, che contiene tutte le colonne dall'inizio del DataFrame, inclusa la colonna "tempo". Quindi sceglie il "genere" del DataFrame come variabile di destinazione e lo assegna a y.
La variabile x rappresenta un DataFrame Pandas con un sottoinsieme delle colonne originali e la variabile y rappresenta una serie Pandas con i valori della colonna "genere".
I metodi x.unique() e y.unique() recuperano rispettivamente i valori univoci nelle variabili x e y. Queste routine possono essere utili per determinare il numero di valori univoci nelle variabili di un set di dati.
x = df.loc[:,:"tempo"]
y = df["genre"]
x y
x.unique()
y.unique()Non sto dando tutte le immagini. Puoi controllare il taccuino in basso.
Il codice fornito genera una griglia di grafici di distribuzione che consentono agli utenti di visualizzare la distribuzione dei valori su più colonne in un set di dati. Scoperta di modelli, tendenze e valori anomali nei dati mostrando la distribuzione dei valori in ogni colonna. Questi sono utili e vantaggiosi per l'analisi esplorativa dei dati e per trovare errori o imprecisioni preziosi e potenziali in un set di dati.
k=0
plt.figure(figsize = (40,30))
for i in x.columns: plt.subplot(4,4, k + 1) sns.distplot(x[i]) plt.xlabel(i, fontsize=24) k +=1Qui, stiamo tracciando per ogni x_columns, usando il ciclo for.
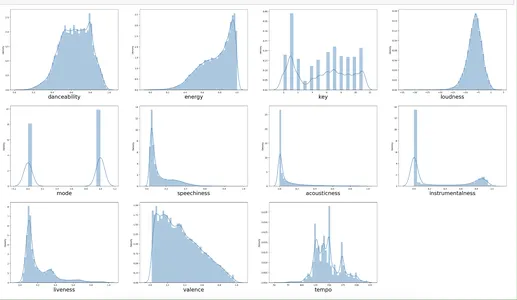
Modello di formazione
Il codice seguente divide un set di dati in sottoinsiemi di addestramento e test. Divide casualmente le variabili di input e le variabili di destinazione in gruppi di addestramento dell'80% e test del 20%. Le statistiche descrittive dei dati di addestramento vengono quindi emesse per facilitare l'esplorazione dei dati e l'identificazione di possibili problemi.
xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size= 0.2, random_state=42, shuffle = True)
xtrain.columns
xtrain.describe()Qui stiamo dividendo i dati in addestramento e test (dimensione = 20%) e stiamo usando la funzione describe per vedere le statistiche descrittive.
La funzione MinMaxScaler() del modulo sklearn.preprocessing viene utilizzata per eseguire il ridimensionamento delle funzionalità. Memorizza i nomi delle colonne dei dati di addestramento nella variabile ol. L'oggetto scaler viene quindi utilizzato per adattare e convertire i dati xtrain durante la modifica dei dati xtest.
Infine, i dati alternativi xtrain e xtest vengono convertiti in dataframe panda con i nomi delle colonne originali (col). Questo è un passaggio fondamentale nella pre-elaborazione e nella standardizzazione dei dati per i modelli di machine learning.
ol = xtrain.columns scalerx = MinMaxScaler() xtrain = scalerx.fit_transform(xtrain)
xtest = scalerx.transform(xtest) xtrain = pd.DataFrame(xtrain, columns = col)
xtest = pd.DataFrame(xtest, columns = col)Qui usiamo il MinMaxScaler, principalmente per ridimensionare e normalizzare i dati.
Quanto segue ci permette di vedere le statistiche descrittive di xtrain e xtest.
xtrain.describe() xtest.describe()La funzione LabelEncoder() del pacchetto sklearn.preprocessing viene utilizzata per codificare le etichette. Utilizza le routine fit transform() e transform() per codificare le variabili di destinazione della categoria (ytrain e ytest) in valori numerici.
I dati di addestramento e test per le variabili di input (x) e target (y) vengono quindi concatenati. Le etichette numeriche vengono quindi trasformate inversamente nei loro valori di categoria originali (y train, y test e y org).
Successivamente, utilizziamo il metodo np.unique(), che restituisce le singole categorie nei dati di addestramento.
Infine, l'utilizzo della libreria seaborn genera un grafico heatmap per illustrare la relazione tra le caratteristiche di input. Questa è una fase critica quando esaminiamo e prepariamo i dati per i modelli di apprendimento automatico.
le = preprocessing.LabelEncoder()
ytrain = le.fit_transform(ytrain)
ytest = le.transform(ytest) x = pd.concat([xtrain, xtest], axis = 0)
y = pd.concat([pd.DataFrame(ytrain), pd.DataFrame(ytest)], axis = 0) y_train = le.inverse_transform(ytrain)
y_test = le.inverse_transform(ytest)
y_org = pd.concat([pd.DataFrame(y_train), pd.DataFrame(y_test)], axis = 0) np.unique(y_train) csvax = sns.heatmap(xtrain.corr()).set(title = "Correlation between Features")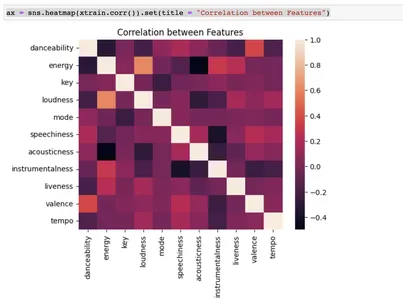
PCA è un popolare approccio di riduzione della dimensionalità che può aiutare a ridurre la complessità di grandi set di dati e aumentare le prestazioni dei modelli di apprendimento automatico.
Con i dati di input x, l'algoritmo utilizza PCA per ridurre al minimo il numero di caratteristiche a due parti che spiegano la variazione. Il set di dati ridotto viene mostrato su un grafico a dispersione 2D, con punti colorati dalle etichette delle classi in y. Ciò aiuta a visualizzare la divisione di alcune classi nello spazio ridotto delle funzionalità.
pca = PCA(n_components=2)
x_pca = pca.fit_transform(x, y)
plot_pca = plt.scatter(x_pca[:,0], x_pca[:,1], c=y)
handles, labels = plot_pca.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("PCA 1")
plt.ylabel("PCA 2")
_ = plt.title("PCA")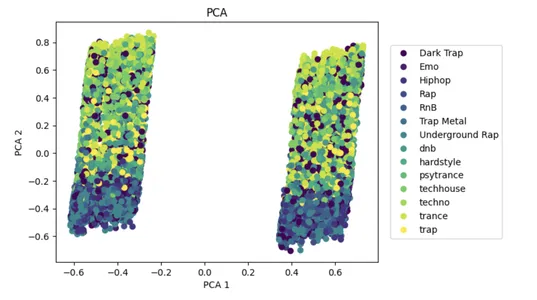
t-SNE è un popolare approccio di riduzione della dimensionalità non lineare che può aiutare a ridurre la complessità di grandi set di dati e migliorare le prestazioni dei modelli di apprendimento automatico.
L'utilizzo di t-Distributed Stochastic Neighbor Embedding (t-SNE) sui dati di input x riduce il numero di caratteristiche nello spazio ad alta dimensione a 2D mantenendo la somiglianza tra i punti dati.
Un grafico a dispersione 2D mostra il set di dati ridotto, con punti colorati in base alle etichette della classe y. Aiuta a visualizzare la divisione di alcune classi nello spazio ridotto delle funzionalità.
tsne = TSNE(n_components=2)
x_tsne = tsne.fit_transform(x, y)
plot_tsne = plt.scatter(x_tsne[:,0], x_tsne[:,1], c=y)
handles, labels = plot_tsne.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("T-SNE 1")
plt.ylabel("T-SNE 2")
_ = plt.title("T-SNE")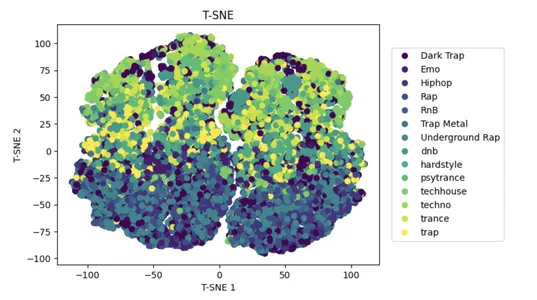
SVD è un popolare approccio di riduzione della dimensionalità che può aiutare a ridurre la complessità di grandi set di dati e aumentare le prestazioni dei modelli di apprendimento automatico.
Il codice seguente applica SVD (Singular Value Decomposition) ai dati di input x con n componenti=2, riducendo il numero di caratteristiche di input a due che spiegano la maggior varianza nei dati. Il set di dati ridotto viene quindi mostrato su un grafico a dispersione 2D, con i punti colorati in base alle etichette della classe y.
Ciò facilita la visualizzazione della divisione di più classi nello spazio ridotto delle funzionalità e il grafico a dispersione viene creato con lo strumento matplotlib.
svd = TruncatedSVD(n_components=2)
x_svd = svd.fit_transform(x, y)
plot_svd = plt.scatter(x_svd[:,0], x_svd[:,1], c=y)
handles, labels = plot_svd.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("Truncated SVD 1")
plt.ylabel("Truncated SVD 2")
_ = plt.title("Truncated SVD")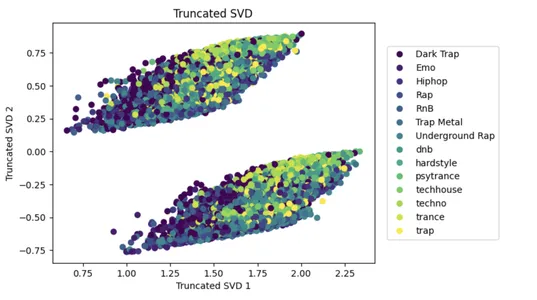
LDA è un popolare approccio di riduzione della dimensionalità che può aumentare le prestazioni del modello di apprendimento automatico diminuendo l'influenza delle informazioni irrilevanti.
Il codice seguente esegue l'analisi discriminante lineare (LDA) sui dati di input x con n componenti=2, che riduce il numero di funzionalità di input a due discriminanti lineari che massimizzano la divisione tra le diverse classi nei dati.
Il set di dati ridotto viene quindi mostrato su un grafico a dispersione 2D, con i punti colorati in base alle etichette della classe y. Ciò aiuta a visualizzare la divisione di alcune classi nello spazio ridotto delle funzionalità.
lda = LinearDiscriminantAnalysis(n_components=2)
x_lda = lda.fit_transform(x, y.values.ravel())
plot_lda = plt.scatter(x_lda[:,0], x_lda[:,1], c=y)
handles, labels = plot_lda.legend_elements()
lg = plt.legend(handles, list(np.unique(y_org)), loc = 'center right', bbox_to_anchor=(1.4, 0.5))
plt.xlabel("LDA 1")
plt.ylabel("LDA 2")
_ = plt.title("Linear Discriminant Analysis")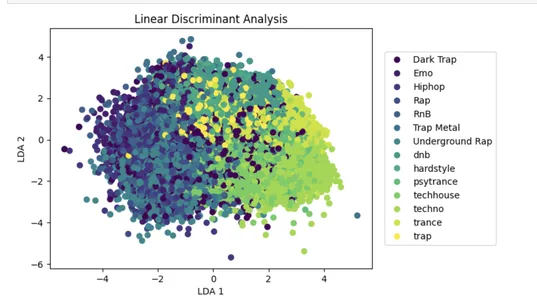
Il codice seguente sostituisce alcuni valori in una colonna Data Frame denominata "genre" con il nuovo deal "Rap". Nello specifico, sostituisce i valori "Trap Metal", "Underground Rap", "Emo", "RnB" ecc., con "Rap". Ciò è utile per raggruppare i generi sotto un unico nome per l'analisi o la modellazione.
df = df.replace("Trap Metal", "Rap")
df = df.replace("Underground Rap", "Rap")
df = df.replace("Emo", "Rap")
df = df.replace("RnB", "Rap")
df = df.replace("Hiphop", "Rap")
df = df.replace("Dark Trap", "Rap")Il codice seguente genera un istogramma utilizzando la libreria seaborn per illustrare la distribuzione del "genere" variabile nel set di dati di input df. La figura è stata ruotata di 80 gradi per migliorare la visibilità delle etichette dell'asse x. “Genres” è un titolo.
ax = sns.histplot(df["genre"])
_ = plt.xticks(rotation=80)
_ = plt.title("Genres")Il codice fornito rimuove le righe dal Data Frame. Nello specifico, elimina le righe con una frequenza di 0.85 in cui il valore della colonna del genere è "Rap", utilizzando un generatore di numeri casuali.
Le righe da scartare vengono salvate in un elenco di righe scartate prima di essere rimosse dal Data Frame utilizzando la funzione drop. Il codice quindi stampa un istogramma dei restanti valori di genere con la funzione seaborn plot e modifica il titolo e la rotazione delle etichette dell'asse x con i metodi title e xticks di matplotlib.
rows_drop = []
for i in range(len(df)): if df.iloc[i]['genre'] == 'Rap': if random.random()<0.85: rows_drop.append(i)
df.drop(index = rows_drop, inplace=True) ax = sns.histplot(df["genre"])
_ = plt.xticks(rotation=80)
_ = plt.title("Genres")Il codice fornito preelabora i dati. Il primo passaggio consiste nel suddividere i dati di input in set di addestramento e test utilizzando la funzione di suddivisione del test del treno della libreria Sklearn.
Quindi regola le caratteristiche numeriche nei dati forniti utilizzando la funzione MinMaxScaler dallo stesso pacchetto. Il codice codifica la variabile di destinazione della categoria utilizzando la funzione LabelEncoder del modulo di pre-elaborazione.
Di conseguenza, i set di addestramento e test vengono preelaborati prima di essere uniti in un singolo set di dati che l'algoritmo di machine learning può elaborare.
x = df.loc[:,:"tempo"]
y = df["genre"] xtrain, xtest, ytrain, ytest = train_test_split(x, y, test_size= 0.2, random_state=42, shuffle = True) col = xtrain.columns
scalerx = MinMaxScaler() xtrain = scalerx.fit_transform(xtrain)
xtest = scalerx.transform(xtest) xtrain = pd.DataFrame(xtrain, columns = col)
xtest = pd.DataFrame(xtest, columns = col)
le = preprocessing.LabelEncoder()
ytrain = le.fit_transform(ytrain)
ytest = le.transform(ytest) x = pd.concat([xtrain, xtest], axis = 0)
y = pd.concat([pd.DataFrame(ytrain), pd.DataFrame(ytest)], axis = 0) y_train = le.inverse_transform(ytrain)
y_test = le.inverse_transform(ytest)
y_org = pd.concat([pd.DataFrame(y_train), pd.DataFrame(y_test)], axis = 0) Questo codice crea due callback di arresto anticipato per l'addestramento del modello, uno basato sulla perdita di convalida e l'altro sull'accuratezza della convalida. L'API sequenziale di Keras crea un modello NN con vari livelli collegati utilizzando la funzione di attivazione ReLU, la normalizzazione batch e la regolarizzazione del dropout. Il riepilogo del modello è stampato sulla console.
Il livello di output finale emette le probabilità di classe utilizzando la funzione di attivazione softmax. Il riepilogo del modello è stampato sulla console.
early_stopping1 = keras.callbacks.EarlyStopping(monitor = "val_loss", patience = 10, restore_best_weights = True)
early_stopping2 = keras.callbacks.EarlyStopping(monitor = "val_accuracy", patience = 10, restore_best_weights = True) model = keras.Sequential([ keras.layers.Input(name = "input", shape = (xtrain.shape[1])), keras.layers.Dense(256, activation = "relu"), keras.layers.BatchNormalization(), keras.layers.Dropout(0.2), keras.layers.Dense(128, activation = "relu"), keras.layers.Dense(128, activation = "relu"), keras.layers.BatchNormalization(), keras.layers.Dropout(0.2), keras.layers.Dense(64, activation = "relu"), keras.layers.Dense(max(ytrain)+1, activation = "softmax")
]) model.summary()Il seguente blocco di codice utilizza Keras per compilare e addestrare un modello di rete neurale. Il modello è un modello sequenziale con più strati densi con funzione di attivazione relu, normalizzazione batch e regolarizzazione dropout. "Sparse categorical cross entropy" è la funzione di perdita utilizzata. Allo stesso tempo, "Adam" è l'ottimizzatore. Il modello viene addestrato per 100 epoche, con callback che terminano in anticipo in base alla perdita di convalida e all'accuratezza.
model.compile(optimizer = keras.optimizers.Adam(), loss = "sparse_categorical_crossentropy", metrics = ["accuracy"]) model_history = model.fit(xtrain, ytrain, epochs = 100, verbose = 1, batch_size = 128, validation_data = (xtest, ytest), callbacks = [early_stopping1, early_stopping2])I dati di addestramento vengono inviati come xtrain e ytrain, mentre i dati di convalida vengono inviati come xtest e ytest. La cronologia di addestramento del modello viene salvata nella variabile della cronologia del modello.
print(model.evaluate(xtrain, ytrain)) print(model.evaluate(xtest, ytest))Il codice seguente genera un grafico utilizzando matplotlib; sull'asse x, abbiamo l'epoca, e sull'asse y, abbiamo l'entropia incrociata categoriale sparsa.
plt.plot(model_history.history["loss"])
plt.plot(model_history.history["val_loss"])
plt.legend(["loss", "validation loss"], loc ="upper right")
plt.title("Train and Validation Loss")
plt.xlabel("epoch")
plt.ylabel("Sparse Categorical Cross Entropy")
plt.show()Come sopra, ma qui stiamo tramando tra l'epoca e l'esattezza.
plt.plot(model_history.history["accuracy"])
plt.plot(model_history.history["val_accuracy"])
plt.legend(["accuracy", "validation accuracy"], loc ="upper right")
plt.title("Train and Validation Accuracy")
plt.xlabel("epoch")
plt.ylabel("Accuracy")
plt.show()Il seguente codice ypred, che prevede il xtest.
ypred = model.predict(xtest).argmax(axis=1)Il codice seguente valuta le metriche di classificazione su test e ypred, dove possiamo vedere la precisione, il richiamo e il punteggio F1. Sulla base dei valori, possiamo procedere con il nostro modello.
cf_matrix = metrics.confusion_matrix(ytest, ypred) _ = sns.heatmap(cf_matrix, fmt=".0f", annot=True) _ = plt.title("Confusion Matrix")Infine, eseguiamo il modello Evaluation.
Valutazione del modello
Il codice seguente valuta le metriche di classificazione su test e ypred, dove possiamo indicare precisione, richiamo e F1score. Sulla base dei valori possiamo procedere con il nostro modello.
print(metrics.classification_report(ytest, ypred))Conclusione
In conclusione, potremmo classificare i generi musicali di Spotify con una precisione dell'88% utilizzando l'analisi e la modellazione eseguite in questo studio. Data la complessità e la soggettività nella definizione dei generi musicali, questo è un ragionevole livello di accuratezza. Tuttavia, c'è sempre un'opportunità di miglioramento e la nostra analisi presenta alcune limitazioni.
Uno svantaggio è la necessità di una maggiore diversità nel nostro set di dati, principalmente musica rap e hip-hop su Spotify. Ciò ha influenzato la nostra ricerca e modellazione a favore di generi specifici. Dobbiamo incorporare una più ampia varietà di generi musicali nel set di dati per migliorare il nostro modello.
Un'altra restrizione è la probabilità di errori umani nella classificazione dei dati, che potrebbero aver portato a discrepanze nella categorizzazione del genere. Potremmo utilizzare approcci più sofisticati, come i modelli di deep learning, per etichettare automaticamente la musica in base agli attributi uditivi per affrontare questo problema.
La nostra analisi e modellazione forniscono una solida base per la categorizzazione dei generi musicali di Spotify, ma sono necessari ulteriori studi e miglioramenti per aumentare l'accuratezza e la resilienza del modello.
Punti chiave
- Caratteristiche uditive come ritmo, ballabilità, energia e valenza possono essere distinte tra i generi musicali di Spotify.
- La pulizia e la preelaborazione dei dati sono processi critici nella preparazione dei dati per la modellazione e possono influenzare in modo significativo le prestazioni del modello.
- Gli approcci di arresto precoce, come il monitoraggio della perdita di convalida e dell'accuratezza, possono aiutare a prevenire l'overfitting del modello.
- Aumenta le dimensioni del set di dati, aggiungi funzionalità e sperimenta metodi e iperparametri alternativi per migliorare le prestazioni del modello di classificazione.
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell'autore.
Leggi Anche
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.analyticsvidhya.com/blog/2023/03/solving-spotify-multiclass-genre-classification-problem/
- 1
- 10
- 100
- 2D
- a
- sopra
- Secondo
- precisione
- con precisione
- operanti in
- Attivazione
- indirizzo
- aiuto
- AIDS
- mira
- algoritmo
- Algoritmi
- Tutti
- consente
- alternativa
- sempre
- .
- analitica
- Analisi Vidhya
- ed
- api
- Applicazioni
- approccio
- approcci
- articolo
- assistere
- gli attributi
- Audio
- Automatico
- automaticamente
- Axis
- basato
- diventare
- prima
- Inizio
- essendo
- sotto
- benefico
- fra
- Bloccare
- Costruzione
- modelli di costruzione
- chiamata
- detto
- chiamata
- catalogo
- categoria
- categorizzazione
- Categoria
- centro
- centrale
- Modifiche
- cambiando
- caratteristiche
- dai un'occhiata
- la scelta
- classe
- classi
- classificazione
- Pulizia
- codice
- codifica
- colore
- Colonna
- colonne
- complessità
- calcoli
- informatica
- conclusione
- confusione
- collegato
- consolle
- contiene
- convertire
- convertito
- Correlazione
- correlazioni
- potuto
- creare
- crea
- critico
- Cross
- Clienti
- Scuro
- dati
- analisi dei dati
- punti dati
- set di dati
- visualizzazione dati
- dataset
- affare
- deep
- apprendimento profondo
- definizione
- Richiesta
- raffigurante
- schierare
- descrivere
- determinazione
- sviluppare
- Mercato
- diverso
- direzione
- Svantaggio
- scoprire
- discrezione
- Dsiplay
- Distinto
- distribuzione
- Diversità
- Divisione
- fare
- giù
- scaricare
- Cadere
- caduto
- Gocce
- ogni
- Presto
- facile
- elimina
- energia
- epoca
- epoche
- eccetera
- valutare
- valutazione
- esperienza
- esperimento
- Spiegare
- esplorazione
- Analisi dei dati esplorativi
- estratto
- facilita
- favorire
- caratteristica
- Caratteristiche
- pochi
- figura
- File
- finale
- Trovare
- ricerca
- Nome
- in forma
- Focus
- i seguenti
- modulo
- Fondazione
- TELAIO
- Frequenza
- da
- function
- genera
- generatore
- ottenere
- Dare
- dato
- dà
- Dare
- Griglia
- Gruppo
- guida
- Maniglie
- Aiuto
- utile
- aiuta
- qui
- vivamente
- storia
- Come
- HTTPS
- umano
- Identificazione
- immagini
- implementazione
- importare
- competenze
- miglioramento
- miglioramenti
- in
- Compreso
- incorporare
- Aumento
- è aumentato
- crescente
- Index
- individuale
- industria
- influenza
- influenzato
- informazioni
- ingresso
- install
- Introduzione
- indagare
- IT
- keras
- Discografica
- per il tuo brand
- Lingua
- grandi
- strato
- galline ovaiole
- principale
- apprendimento
- Livello
- LG
- biblioteche
- Biblioteca
- limiti
- LINK
- Lista
- elencati
- caricare
- spento
- macchina
- machine learning
- fatto
- FA
- Manipolazione
- massiccio
- matplotlib
- Matrice
- max
- Massimizzare
- significativo
- Media
- Memorie
- metallo
- metodo
- metodi
- Metrica
- forza
- milioni
- ridurre al minimo
- errori
- modello
- modellismo
- modelli
- modulo
- Monitorare
- monitoraggio
- Scopri di più
- maggior parte
- multiplo
- Musica
- industria della musica
- streaming musicale
- Nome
- Detto
- nomi
- nav
- necessaria
- Bisogno
- Rete
- Neurale
- rete neurale
- New
- taccuino
- numero
- numpy
- oggetto
- ONE
- online
- open source
- Opportunità
- minimo
- i
- Altro
- Di proprietà
- Pace
- pacchetto
- coppie
- panda
- parte
- particolare
- Ricambi
- Pazienza
- modelli
- Persone
- eseguire
- performance
- Personalizzata
- Scelte
- Platone
- Platone Data Intelligence
- PlatoneDati
- punti
- pop
- Popolare
- posizioni
- possibile
- potenziale
- Precisione
- predire
- predizione
- predice
- preferenze
- Preparare
- preparazione
- prerequisiti
- prevenire
- in precedenza
- principalmente
- Stampa
- stampe
- Problema
- problemi
- processi
- i processi
- Programmazione
- progetto
- purché
- fornisce
- pubblicato
- metti
- Python
- casuale
- gamma
- rap
- piuttosto
- ragionevole
- raccomandare
- Consigli
- Ridotto
- riduce
- riducendo
- rapporto
- rimanente
- rimosso
- rimozione
- rappresenta
- necessario
- riparazioni
- elasticità
- restrizione
- colpevole
- problemi
- routine
- Correre
- running
- stesso
- scala
- Scienze
- Seaborn
- selezionato
- Serie
- Servizi
- set
- Set
- alcuni
- Forma
- mostrato
- Spettacoli
- mescolare
- significativamente
- singolo
- singolare
- Siti
- Taglia
- solido
- Soluzione
- alcuni
- sofisticato
- lo spazio
- specifico
- in particolare
- dividere
- Spotify
- Stage
- standardizzazione
- iniziato
- inizio
- statistica
- step
- sosta
- negozi
- Streaming
- servizi di streaming
- forza
- Studio
- iscritti
- tale
- SOMMARIO
- in dotazione
- SISTEMI DI TRATTAMENTO
- Target
- task
- Tempo
- tensorflow
- test
- Testing
- I
- loro
- tempo
- Titolo
- a
- Totale
- pista
- Treni
- allenato
- Training
- trasformato
- tendenze
- vero
- Tipi di
- per
- unico
- SENZA NOME
- URI
- us
- Impiego
- uso
- utenti
- utilizzare
- utilizzati
- convalida
- Prezioso
- APPREZZIAMO
- Valori
- variabili
- varietà
- vario
- Visualizza
- visibilità
- visualizzazione
- visualizzare
- quale
- while
- più ampia
- volere
- Il mondo di
- X
- zefiro