Immagine dell'autore
Supervisionato è una sottocategoria dell'apprendimento automatico in cui il computer apprende dal set di dati etichettato contenente sia l'input che l'output corretto. Cerca di trovare la funzione di mappatura che mette in relazione l'input (x) con l'output (y). Puoi considerarlo come insegnare a tuo fratello o tua sorella minore come riconoscere i diversi animali. Mostrerai loro alcune immagini (x) e dirai loro come si chiama ogni animale (y). Dopo un certo tempo impareranno le differenze e saranno in grado di riconoscere correttamente la nuova immagine. Questa è l’intuizione di base dietro l’apprendimento supervisionato. Prima di andare avanti, diamo uno sguardo più approfondito al suo funzionamento.
Come funziona l'apprendimento supervisionato?
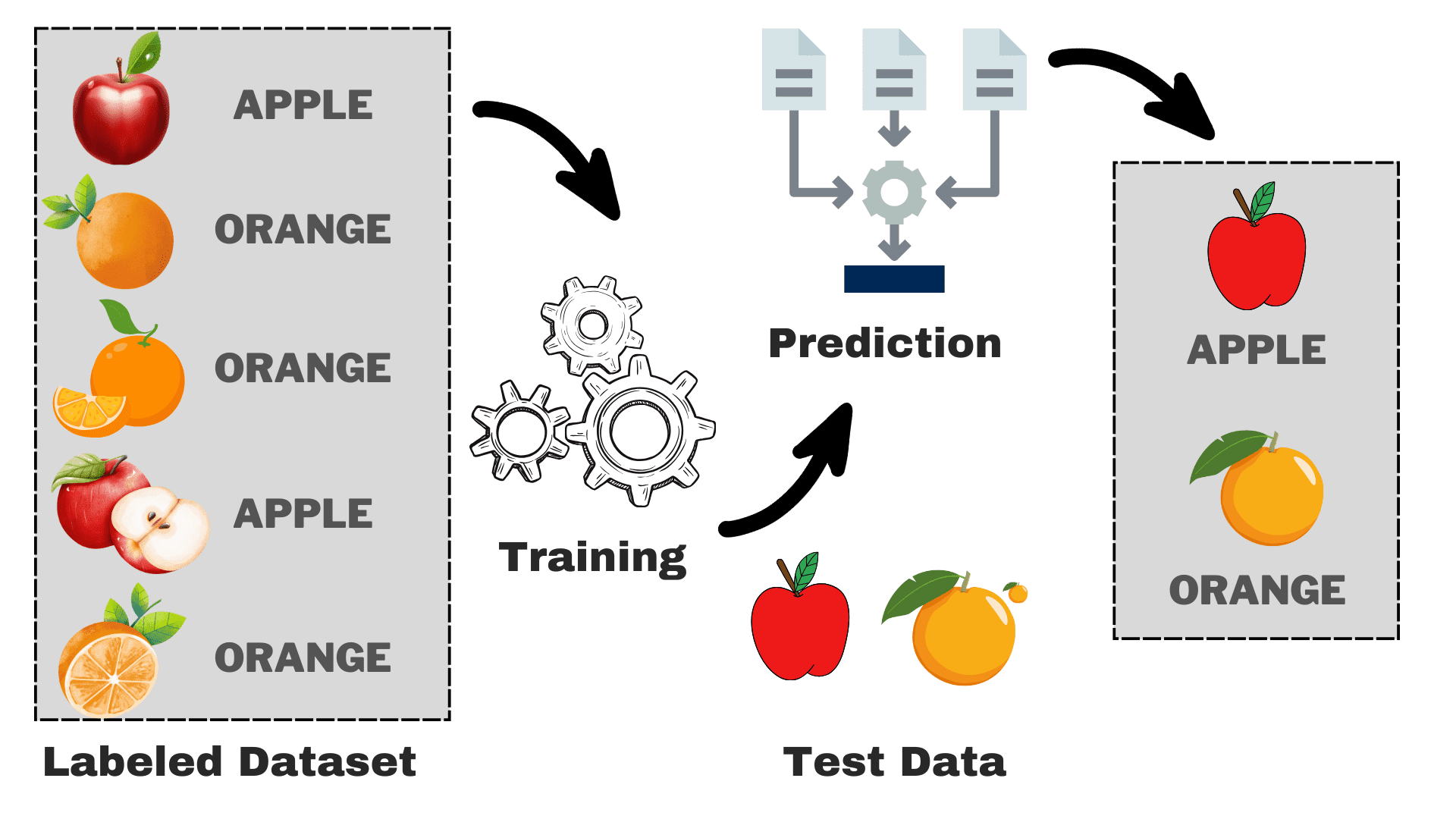
Immagine dell'autore
Supponiamo di voler costruire un modello in grado di distinguere tra mele e arance in base ad alcune caratteristiche. Possiamo suddividere il processo nelle seguenti attività:
- Raccolta dei dati: Raccogli un set di dati con immagini di mele e arance e ciascuna immagine viene etichettata come "mela" o "arancia".
- Selezione del modello: Dobbiamo scegliere il classificatore giusto qui, spesso noto come l'algoritmo di apprendimento automatico supervisionato giusto per il tuo compito. È come scegliere gli occhiali giusti che ti aiuteranno a vedere meglio
- Formazione del modello: Ora alimenta l'algoritmo con le immagini etichettate di mele e arance. L'algoritmo guarda queste immagini e impara a riconoscere le differenze, come il colore, la forma e la dimensione delle mele e delle arance.
- Valutazione e test: Per verificare se il tuo modello funziona correttamente, gli forniremo alcune immagini mai viste e confronteremo le previsioni con quelle reali.
L’apprendimento supervisionato può essere suddiviso in due tipologie principali:
Classificazione
Nelle attività di classificazione, l'obiettivo principale è assegnare punti dati a categorie specifiche da un insieme di classi discrete. Quando ci sono solo due possibili risultati, come “sì” o “no”, “spam” o “non spam”, “accettato” o “rifiutato”, si parla di classificazione binaria. Tuttavia, quando sono coinvolte più di due categorie o classi, come la valutazione degli studenti in base ai loro voti (ad esempio, A, B, C, D, F), diventa un esempio di problema di multiclassificazione.
Regressione
Per i problemi di regressione, stai cercando di prevedere un valore numerico continuo. Ad esempio, potresti essere interessato a prevedere i punteggi dell'esame finale in base alle tue prestazioni passate in classe. I punteggi previsti possono comprendere qualsiasi valore all'interno di un intervallo specifico, in genere da 0 a 100 nel nostro caso.
Ora abbiamo una conoscenza di base del processo complessivo. Esploreremo i popolari algoritmi di machine learning supervisionati, il loro utilizzo e come funzionano:
1. Regressione lineare
Come suggerisce il nome, viene utilizzato per attività di regressione come prevedere i prezzi delle azioni, prevedere la temperatura, stimare la probabilità di progressione della malattia, ecc. Cerchiamo di prevedere l'obiettivo (variabile dipendente) utilizzando l'insieme di etichette (variabili indipendenti). Si presuppone che abbiamo una relazione lineare tra le nostre caratteristiche di input e l'etichetta. L'idea centrale ruota attorno alla previsione della linea più adatta per i nostri punti dati riducendo al minimo l'errore tra i nostri valori effettivi e quelli previsti. Questa linea è rappresentata dall'equazione:
Dove,
- Y Risultato previsto.
- X = Caratteristica di input o matrice di caratteristiche nella regressione lineare multipla
- b0 = Intercetta (dove la linea attraversa l'asse Y).
- b1 = Pendenza o coefficiente che determina la pendenza della linea.
Stima la pendenza della linea (peso) e la sua intercetta (bias). Questa linea può essere utilizzata ulteriormente per fare previsioni. Sebbene sia il modello più semplice e utile per sviluppare le linee di base, è altamente sensibile ai valori anomali che possono influenzare la posizione della linea.
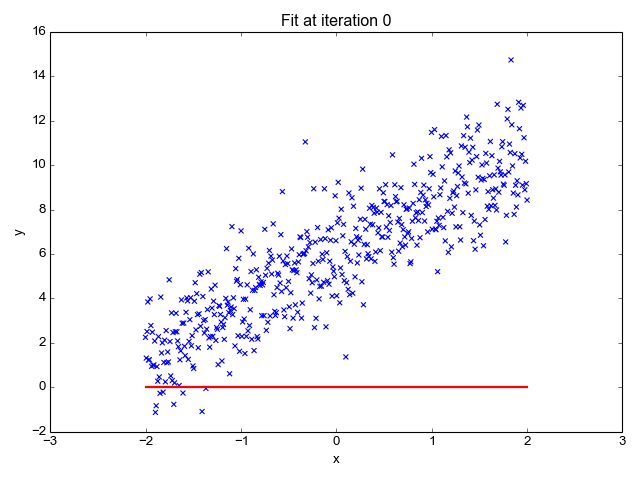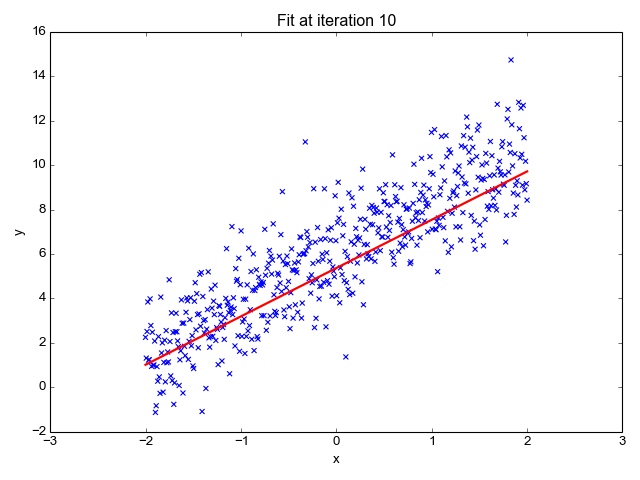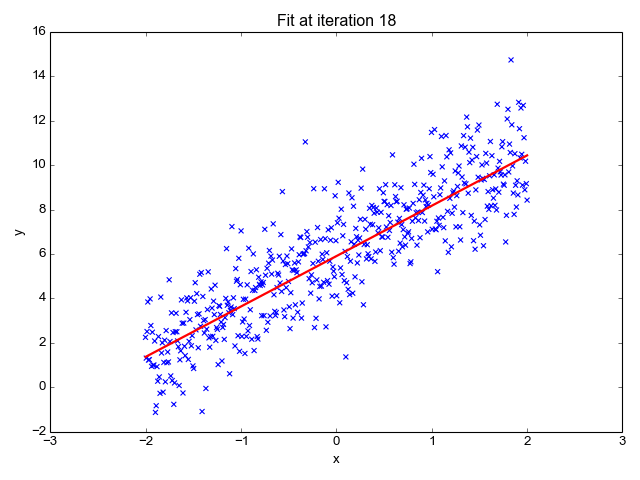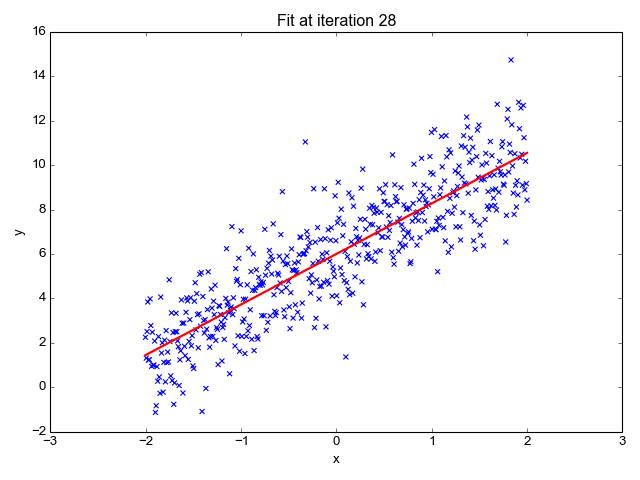
Gif su Primo.ai
2. Regressione logistica
Sebbene abbia la regressione nel nome, è fondamentalmente utilizzato per problemi di classificazione binaria. Prevede la probabilità di un risultato positivo (variabile dipendente) compresa tra 0 e 1. Fissando una soglia (solitamente 0.5), classifichiamo i punti dati: quelli con una probabilità maggiore della soglia appartengono alla classe positiva, e viceversa. La regressione logistica calcola questa probabilità utilizzando la funzione sigmoide applicata alla combinazione lineare delle caratteristiche di input specificata come:
Dove,
- P(Y=1) = Probabilità che il punto dati appartenga alla classe positiva
- X1 ,… ,Xn = Caratteristiche di ingresso
- b0,….,bn = Pesi di input che l'algoritmo apprende durante l'addestramento
Questa funzione sigmoide ha la forma di una curva simile a S che trasforma qualsiasi punto dati in un punteggio di probabilità compreso tra 0 e 1. Puoi vedere il grafico qui sotto per una migliore comprensione.
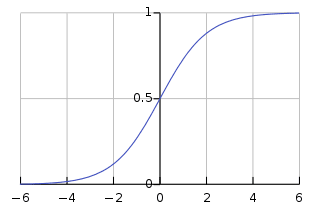
Immagine accesa wikipedia
Un valore più vicino a 1 indica una maggiore fiducia nel modello nella sua previsione. Proprio come la regressione lineare, è nota per la sua semplicità ma non possiamo eseguire la classificazione multiclasse senza modificare l'algoritmo originale.
3. Alberi decisionali
A differenza dei due algoritmi precedenti, gli alberi decisionali possono essere utilizzati sia per attività di classificazione che di regressione. Ha una struttura gerarchica proprio come i diagrammi di flusso. In ciascun nodo viene presa una decisione sul percorso in base ad alcuni valori delle caratteristiche. Il processo continua finché non raggiungiamo l'ultimo nodo che raffigura la decisione finale. Ecco alcuni termini di base di cui devi essere a conoscenza:
- Nodo radice: Il nodo superiore contenente l'intero set di dati è chiamato nodo radice. Selezioniamo quindi la caratteristica migliore utilizzando un algoritmo per dividere il set di dati in 2 o più sottoalberi.
- Nodi interni: Ciascun nodo Interno rappresenta una caratteristica specifica e una regola decisionale per decidere la successiva direzione possibile per un punto dati.
- Nodi fogliari: I nodi finali che rappresentano un'etichetta di classe sono indicati come nodi foglia.
Prevede i valori numerici continui per le attività di regressione. Man mano che la dimensione del set di dati aumenta, viene catturato il rumore che porta al sovradattamento. Questo può essere gestito eliminando l’albero decisionale. Rimuoviamo i rami che non migliorano significativamente la precisione delle nostre decisioni. Ciò aiuta a mantenere il nostro albero concentrato sui fattori più importanti e impedisce che si perda nei dettagli.
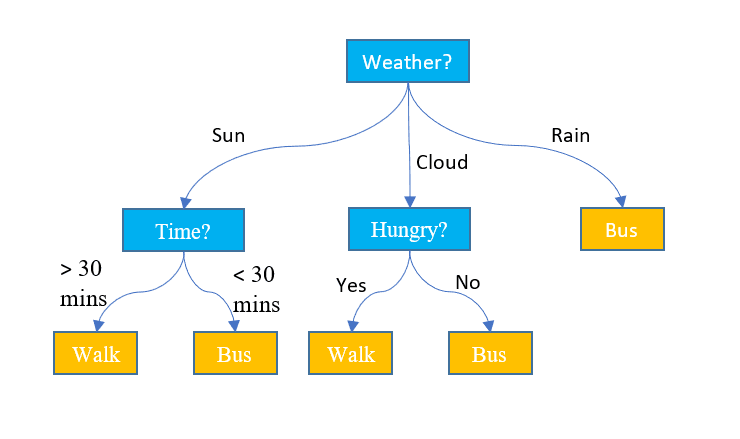
Immagine di Jake Hoare sul Displayr
4. Foresta casuale
La foresta casuale può essere utilizzata anche per le attività di classificazione e di regressione. Si tratta di un gruppo di alberi decisionali che lavorano insieme per effettuare la previsione finale. Puoi considerarlo come un comitato di esperti che prende una decisione collettiva. Ecco come funziona:
- Campionamento dei dati: Invece di prendere l’intero set di dati in una volta, prende campioni casuali tramite un processo chiamato bootstrap o bagging.
- Selezione delle caratteristiche: Per ciascun albero decisionale in una foresta casuale, ai fini del processo decisionale viene considerato solo il sottoinsieme casuale di funzionalità anziché l'insieme completo di funzionalità.
- Voto: Per la classificazione, ogni albero decisionale nella foresta casuale esprime il proprio voto e viene selezionata la classe con i voti più alti. Per la regressione, calcoliamo la media dei valori ottenuti da tutti gli alberi.
Sebbene riduca l'effetto di overfitting causato dai singoli alberi decisionali, è computazionalmente costoso. Una parola che leggerai frequentemente in letteratura è che la foresta casuale è un metodo di apprendimento d'insieme, il che significa che combina più modelli per migliorare le prestazioni complessive.
5. Supporta le macchine vettoriali (SVM)
Viene utilizzato principalmente per problemi di classificazione ma può gestire anche attività di regressione. Cerca di trovare il miglior iperpiano che separa le classi distinte utilizzando l'approccio statistico, a differenza dell'approccio probabilistico della regressione logistica. Possiamo usare la SVM lineare per i dati linearmente separabili. Tuttavia, la maggior parte dei dati del mondo reale non sono lineari e utilizziamo i trucchi del kernel per separare le classi. Analizziamo in profondità come funziona:
- Selezione dell'iperpiano: Nella classificazione binaria, SVM trova il miglior iperpiano (linea 2D) per separare le classi massimizzando il margine. Il margine è la distanza tra l'iperpiano e i punti dati più vicini all'iperpiano.
- Trucco del kernel: Per i dati linearmente inseparabili, utilizziamo un trucco del kernel che mappa lo spazio dei dati originali in uno spazio ad alta dimensionalità dove possono essere separati linearmente. I kernel comuni includono i kernel lineari, polinomiali, con funzione di base radiale (RBF) e sigmoidali.
- Massimizzazione del margine: SVM cerca anche di migliorare la generalizzazione del modello aumentando il margine di massimizzazione.
- Classificazione: Una volta addestrato il modello, è possibile effettuare previsioni in base alla sua posizione rispetto all'iperpiano.
SVM ha anche un parametro chiamato C che controlla il compromesso tra la massimizzazione del margine e il mantenimento al minimo dell'errore di classificazione. Sebbene possano gestire bene dati ad alta dimensionalità e non lineari, scegliere il kernel e l'iperparametro giusti non è così facile come sembra.
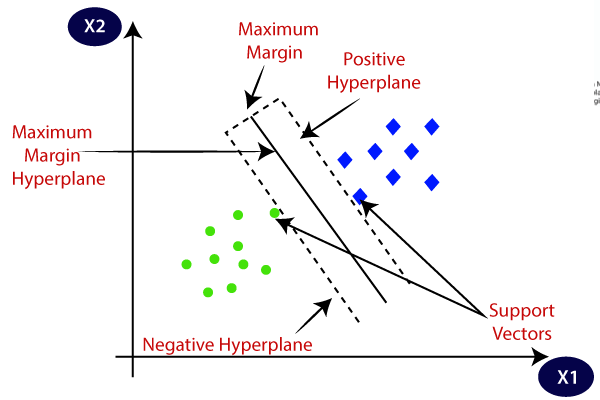
Immagine accesa Punto Java
6. k-Vicini più vicini (k-NN)
K-NN è l'algoritmo di apprendimento supervisionato più semplice utilizzato principalmente per compiti di classificazione. Non fa alcuna ipotesi sui dati e assegna al nuovo punto dati una categoria in base alla sua somiglianza con quelli esistenti. Durante la fase di training mantiene l’intero dataset come punto di riferimento. Quindi calcola la distanza tra il nuovo punto dati e tutti i punti esistenti utilizzando una metrica di distanza (distanza Eucilinedain ad esempio). Sulla base di queste distanze, identifica i K vicini più vicini a questi punti dati. Quindi contiamo la presenza di ciascuna classe nei K vicini più vicini e assegniamo la classe che appare più frequentemente come previsione finale.
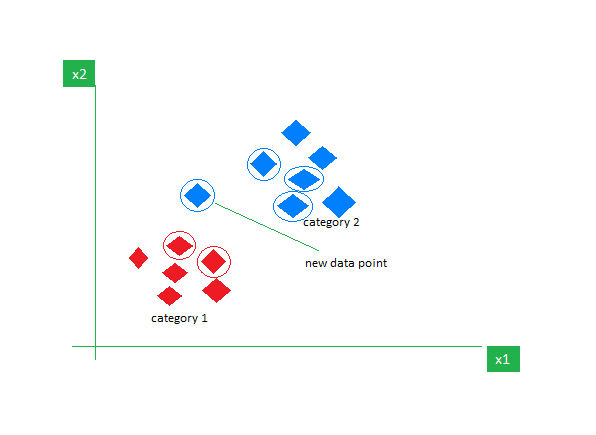
Immagine accesa Geeksfor Geeks
Scegliere il giusto valore di K richiede sperimentazione. Sebbene sia robusto per i dati rumorosi, non è adatto per set di dati di grandi dimensioni e ha un costo elevato associato a causa del calcolo della distanza da tutti i punti dati.
Concludendo questo articolo, vorrei incoraggiare i lettori a esplorare più algoritmi e provare a implementarli da zero. Ciò rafforzerà la tua comprensione di come funzionano le cose sotto il cofano. Ecco alcune risorse aggiuntive per aiutarti a iniziare:
Kanwal Mehreen è un aspirante sviluppatore di software con un vivo interesse per la scienza dei dati e le applicazioni dell'IA in medicina. Kanwal è stato selezionato come Google Generation Scholar 2022 per la regione APAC. Kanwal ama condividere le conoscenze tecniche scrivendo articoli su argomenti di tendenza ed è appassionata di migliorare la rappresentanza delle donne nell'industria tecnologica.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Automobilistico/VE, Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Grafico Prime. Migliora il tuo gioco di trading con ChartPrime. Accedi qui.
- BlockOffset. Modernizzare la proprietà della compensazione ambientale. Accedi qui.
- Fonte: https://www.kdnuggets.com/understanding-supervised-learning-theory-and-overview?utm_source=rss&utm_medium=rss&utm_campaign=understanding-supervised-learning-theory-and-overview
- :ha
- :È
- :non
- :Dove
- 1
- 100
- 2022
- a
- capace
- WRI
- sopra
- accettato
- precisione
- presenti
- aggiuntivo
- Dopo shavasana, sedersi in silenzio; saluti;
- AI
- AI in medicina
- algoritmo
- Algoritmi
- Tutti
- anche
- Sebbene il
- an
- ed
- animali
- animali
- in qualsiasi
- APAC
- apparendo
- Apple
- applicazioni
- applicato
- approccio
- SONO
- in giro
- articolo
- news
- AS
- aspirante
- associato
- assume
- ipotesi
- At
- media
- consapevole
- b
- basato
- basic
- base
- BE
- diventa
- prima
- dietro
- appartiene
- sotto
- MIGLIORE
- Meglio
- fra
- pregiudizio
- entrambi
- rami
- Rompere
- costruire
- ma
- by
- calcola
- calcolo
- detto
- Materiale
- non può
- cattura
- Custodie
- categoria
- Categoria
- ha causato
- centrale
- certo
- caratteristiche
- dai un'occhiata
- la scelta
- classe
- classi
- classificazione
- classificare
- più vicino
- collezione
- Collective
- colore
- combinazione
- combina
- comitato
- Uncommon
- confrontare
- completamento di una
- computer
- concludere
- fiducia
- considerato
- continua
- continuo
- controlli
- correggere
- correttamente
- Costo
- curva
- dati
- punti dati
- scienza dei dati
- dataset
- decide
- decisione
- Decision Making
- albero decisionale
- decisioni
- deep
- più profondo
- dipendente
- dettagli
- determina
- Costruttori
- in via di sviluppo
- differenze
- diverso
- differenziare
- direzione
- Malattia
- distanza
- distinto
- immersione
- Diviso
- effettua
- non
- don
- giù
- dovuto
- durante
- e
- ogni
- facile
- effetto
- o
- incoraggiare
- finale
- Intero
- errore
- stime
- eccetera
- Etere (ETH)
- e la
- esempio
- esistente
- costoso
- esperti
- esplora
- Fattori
- caratteristica
- Caratteristiche
- finale
- Trovate
- trova
- concentrato
- i seguenti
- Nel
- foresta
- modulo
- Avanti
- frequentemente
- da
- function
- fondamentalmente
- ulteriormente
- raccogliere
- ELETTRICA
- ottenere
- ottenere
- gif
- occhiali
- grafico
- maggiore
- Gruppo
- cresce
- maniglia
- gestito
- Avere
- Aiuto
- aiuta
- qui
- Alta
- superiore
- massimo
- vivamente
- cappuccio
- Come
- Tutorial
- Tuttavia
- HTTPS
- i
- idea
- identifica
- if
- Immagine
- immagini
- realizzare
- importante
- competenze
- miglioramento
- in
- includere
- crescente
- studente indipendente
- indica
- individuale
- industria
- influenza
- ingresso
- invece
- interesse
- interessato
- interno
- ai miglioramenti
- intuizione
- coinvolto
- IT
- SUO
- ad appena
- KDnuggets
- Acuto
- mantenere
- conservazione
- conoscenze
- conosciuto
- Discografica
- per il tuo brand
- Cognome
- principale
- IMPARARE
- apprendimento
- lasciare
- si trova
- piace
- probabilità
- linea
- letteratura
- Guarda
- SEMBRA
- perso
- ama
- macchina
- machine learning
- macchine
- fatto
- Principale
- make
- Fare
- mappatura
- Maps
- Margine
- Matrice
- massimizzando
- Maggio..
- si intende
- medicina
- medie
- metodo
- metrico
- forza
- minimizzando
- ordine
- modello
- modelli
- Scopri di più
- maggior parte
- soprattutto
- in movimento
- multiplo
- devono obbligatoriamente:
- Nome
- vicinato
- New
- GENERAZIONE
- no
- nodo
- nodi
- Rumore
- adesso
- obiettivo
- ottenuto
- evento
- of
- di frequente
- on
- una volta
- ONE
- quelli
- esclusivamente
- or
- Arancio
- i
- nostro
- Risultato
- risultati
- produzione
- complessivo
- panoramica
- parametro
- appassionato
- passato
- sentiero
- eseguire
- performance
- fase
- scegliere
- immagine
- Immagini
- Platone
- Platone Data Intelligence
- PlatoneDati
- più
- punto
- punti
- Popolare
- posizione
- positivo
- possibile
- predire
- previsto
- previsione
- predizione
- Previsioni
- predice
- impedisce
- Prezzi
- principalmente
- primario
- probabilità
- Problema
- problemi
- processi
- progressione
- casuale
- gamma
- Rbf
- raggiungere
- Leggi
- lettori
- mondo reale
- riconoscere
- riduce
- riferimento
- di cui
- regione
- regressione
- Respinto..
- rapporto
- parente
- rimuovere
- rappresentare
- rappresentazione
- rappresentato
- rappresenta
- richiede
- Risorse
- gira
- destra
- robusto
- radice
- Regola
- s
- Studioso
- Scienze
- Punto
- punteggi
- graffiare
- vedere
- sembra
- selezionato
- prodotti
- delicata
- separato
- set
- regolazione
- Forma
- Condividi
- mostrare attraverso le sue creazioni
- significativamente
- semplicità
- sorella
- Taglia
- pendenza
- Software
- alcuni
- lo spazio
- carne in scatola
- campata
- specifico
- specificato
- dividere
- iniziato
- statistiche
- azione
- Rafforza
- La struttura
- Gli studenti
- tale
- suggerisce
- adatto
- apprendimento supervisionato
- supporto
- SVG
- T
- Fai
- prende
- presa
- Target
- Task
- task
- Insegnamento
- Tech
- industria tecnologica
- Consulenza
- dire
- terminologia
- Testing
- di
- che
- Il
- loro
- Li
- poi
- teoria
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- cose
- Pensare
- questo
- quelli
- soglia
- tempo
- a
- insieme
- top
- Argomenti
- allenato
- Training
- trasforma
- albero
- Alberi
- trend
- trucchi
- prova
- cerca
- seconda
- Tipi di
- tipicamente
- per
- e una comprensione reciproca
- a differenza di
- Impiego
- uso
- utilizzato
- utilizzando
- generalmente
- APPREZZIAMO
- Valori
- variabile
- variabili
- via
- vice
- Votazione
- voti
- volere
- Prima
- we
- peso
- WELL
- Che
- quando
- quale
- while
- volere
- con
- entro
- senza
- Donna
- donne in tecnologia
- Word
- Lavora
- lavoro
- lavorazioni
- lavori
- sarebbe
- scrittura
- X
- sì
- Tu
- Minore
- Trasferimento da aeroporto a Sharm
- zefiro