“Un grammo di prevenzione vale un chilo di cure” recita il vecchio detto, ricordandoci che è più facile impedire che qualcosa accada piuttosto che riparare il danno dopo che si è verificato.
Nell’era dell’intelligenza artificiale (AI), questo proverbio sottolinea l’importanza di evitare potenziali trappole, come l’overfitting, attraverso tecniche come la regolarizzazione.
In questo articolo, scopriremo la regolarizzazione partendo dai suoi principi fondamentali fino alla sua applicazione utilizzando Sci-kit Learn (Machine Learning) e Tensorflow (Deep Learning) e saremo testimoni del suo potere di trasformazione con set di dati del mondo reale confrontando questi risultati. Iniziamo!
La regolarizzazione è un concetto fondamentale nell'apprendimento automatico e nel deep learning che mira a impedire l'adattamento eccessivo dei modelli.
L'overfitting si verifica quando un modello apprende troppo bene i dati di addestramento. La situazione mostra che il tuo modello è troppo bello per essere vero.
Vediamo come si presenta il sovradattamento.
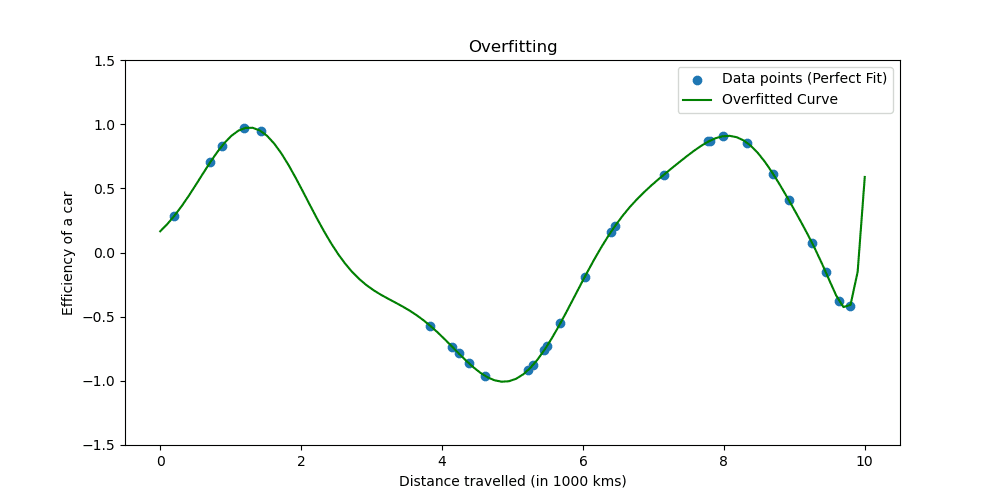
Le tecniche di regolarizzazione regolano il processo di apprendimento per semplificare il modello, garantendo che funzioni bene sui dati di addestramento e si generalizzi bene ai nuovi dati. Esploreremo due modi ben noti per farlo.
Nell'apprendimento automatico, la regolarizzazione viene spesso applicata a modelli lineari, come la regressione lineare e logistica. In questo contesto, le forme di regolarizzazione più comuni sono:
- Regolarizzazione L1 (regressione Lazo)
- Regolarizzazione L2 (regressione Ridge)
Regolarizzazione del lazo incoraggia il modello a utilizzare solo le caratteristiche più essenziali consentendo ad alcuni valori di coefficiente di essere esattamente pari a zero, il che può essere particolarmente utile per la selezione delle caratteristiche.
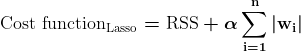
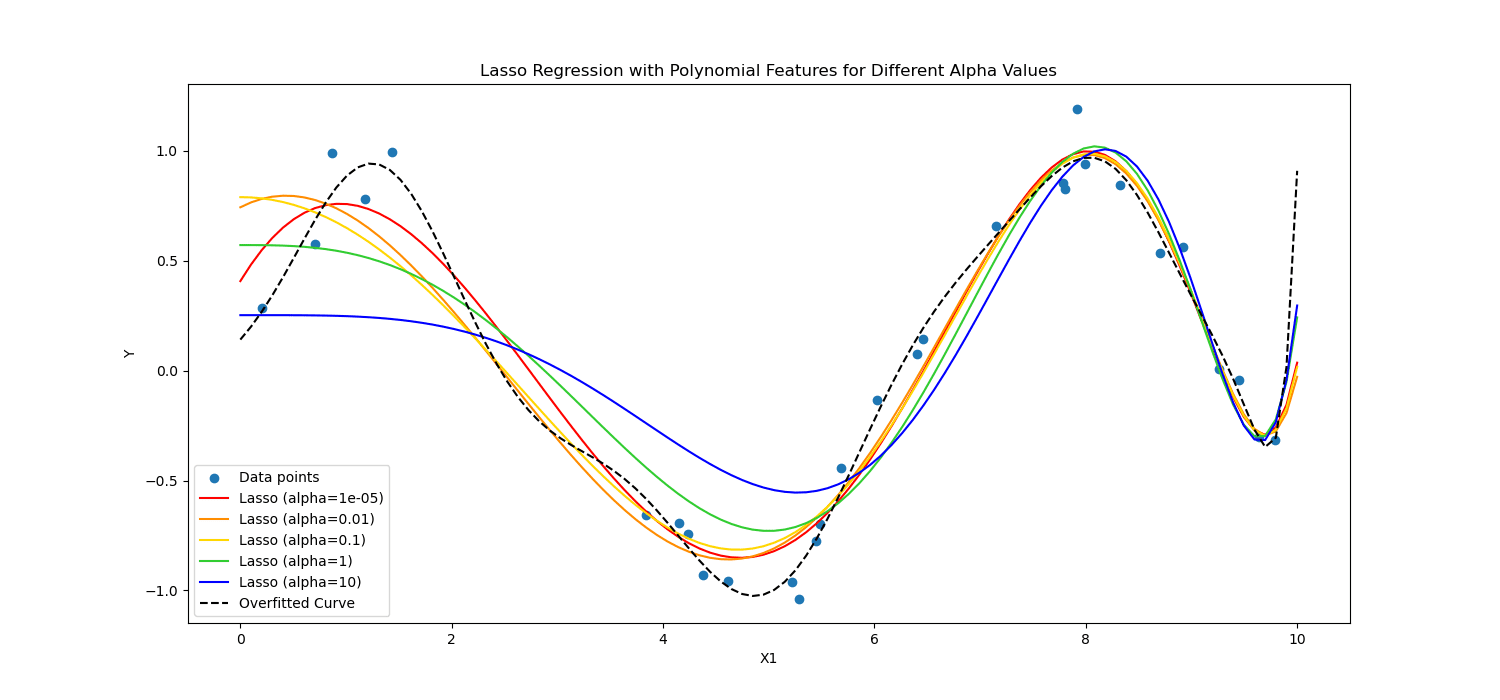
D'altro canto, Regolarizzazione della cresta scoraggia i coefficienti significativi penalizzando il quadrato dei loro valori.
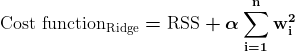
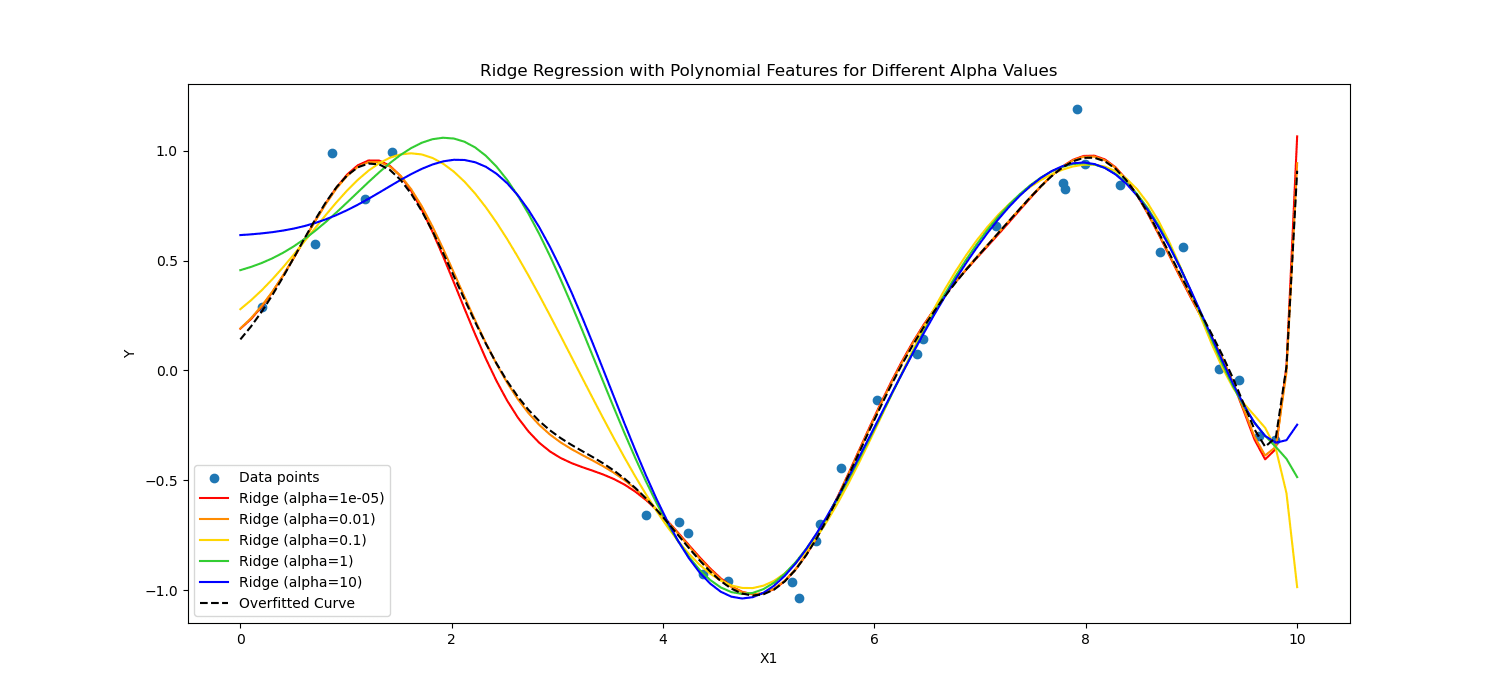
Insomma, calcolavano diversamente.
Applichiamoli ai dati del paziente cardiaco per vederne la potenza nell'apprendimento profondo e nell'apprendimento automatico.
Ora applicheremo la regolarizzazione per analizzare i dati dei pazienti cardiaci per vedere il potere della regolarizzazione. È possibile raggiungere il set di dati da qui.
Per applicare l'apprendimento automatico, utilizzeremo Scikit-learn; per applicare il deep learning, utilizzeremo TensorFlow. Iniziamo!
Regolarizzazione in Machine Learning
Scikit-learn è uno dei più popolari Librerie Python per l'apprendimento automatico che fornisce strumenti di analisi e modellazione dei dati semplici ed efficienti.
Include implementazioni di varie tecniche di regolarizzazione, in particolare per i modelli lineari.
Qui esploreremo come applicare la regolarizzazione L1 (Lasso) e L2 (Ridge).
Nel codice seguente, addestreremo la regressione logistica utilizzando le tecniche di regolarizzazione Ridge(L2) e Lasso (L1). Alla fine vedremo il resoconto dettagliato. Vediamo il codice.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
Ecco l'uscita.
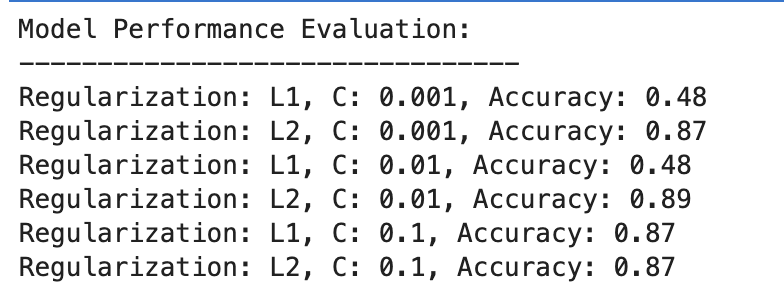
Valutiamo il risultato.
Regolarizzazione L1
- A C=0.001, la precisione è notevolmente bassa (48%). Ciò dimostra che il modello è inadeguato. Mostra troppa regolarizzazione.
- Man mano che C aumenta a 0.01, l’accuratezza rimane invariata per L1, suggerendo che il modello soffre ancora di underfitting o che la regolarizzazione è troppo forte.
- A C=0.1, l'accuratezza migliora significativamente fino all'87%, dimostrando che la riduzione della forza di regolarizzazione consente al modello di apprendere meglio dai dati.
Regolarizzazione L2
Nel complesso, la regolarizzazione L2 funziona costantemente bene, con una precisione all'87% per C=0.001 e leggermente superiore all'89% per C=0.01, per poi stabilizzarsi all'87% per C=0.1.
Ciò suggerisce che la regolarizzazione L2 è generalmente più indulgente ed efficace per questo set di dati nei modelli di regressione logistica, potenzialmente a causa della sua natura.
Regolarizzazione nel Deep Learning
Diverse tecniche di regolarizzazione vengono utilizzate nel deep learning, tra cui la regolarizzazione di L1 (Lasso) e L2 (Ridge), il dropout e l'arresto anticipato.
In questo, per ripetere ciò che abbiamo fatto prima nell'esempio di machine learning, applicheremo la regolarizzazione L1 e L2. Questa volta definiamo un elenco di valori di regolarizzazione L1 e L2.
Quindi, per tutti questi valori, formeremo e valuteremo il nostro modello di deep learning e, alla fine, valuteremo i risultati.
Vediamo il codice.
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:8} | {metrics[1]:8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
Ecco l'uscita.
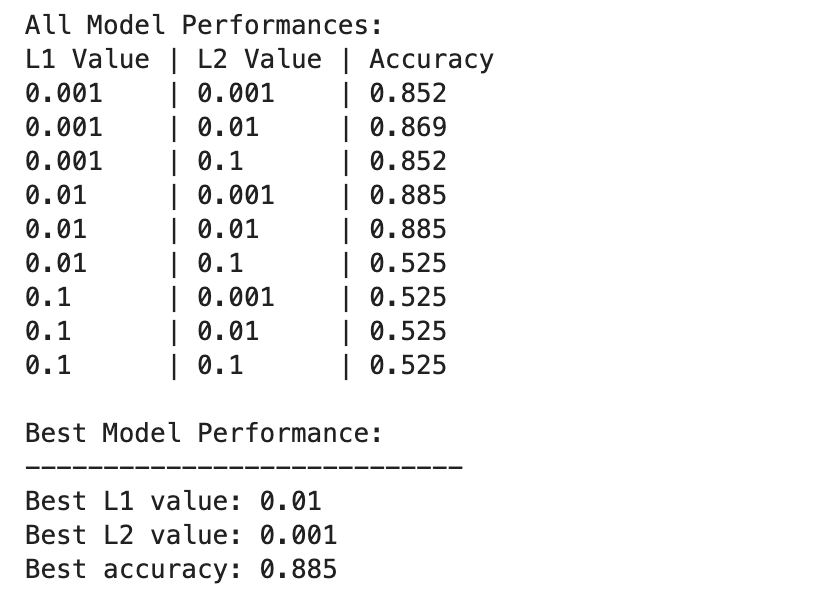
Le prestazioni del modello di deep learning variano in modo più ampio tra diverse combinazioni di valori di regolarizzazione L1 e L2.
Le migliori prestazioni si osservano con L1=0.01 e L2=0.001, con una precisione dell'88.5%, che indica una regolarizzazione equilibrata che impedisce l'overfitting consentendo al tempo stesso al modello di acquisire i modelli sottostanti nei dati.
Valori di regolarizzazione più elevati, soprattutto a L1=0.1 o L2=0.1, riducono drasticamente l'accuratezza del modello al 52.5%, suggerendo che un'eccessiva regolarizzazione limita gravemente la capacità di apprendimento del modello.
Machine Learning e Deep Learning nella regolarizzazione
Confrontiamo i risultati tra Machine Learning e Deep Learning.
Efficacia della regolarizzazione: Sia nei contesti di machine learning che di deep learning, un'adeguata regolarizzazione aiuta a mitigare l'overfitting, ma un'eccessiva regolarizzazione porta all'underfitting. La forza di regolarizzazione ottimale varia, con i modelli di deep learning che richiedono potenzialmente un equilibrio più sfumato a causa della loro maggiore complessità.
Performance: Il modello di machine learning con le migliori prestazioni (L2 con C=0.01, 89% di precisione) e il modello di deep learning con le migliori prestazioni (L1=0.01, L2=0.001, 88.5% di precisione) raggiungono accuratezze comparabili, dimostrando che entrambi gli approcci possono essere efficaci regolarizzato per ottenere prestazioni elevate su questo set di dati.
Strategia di regolarizzazione: La regolarizzazione L2 sembra essere più efficace e meno sensibile alla scelta di C nei modelli di regressione logistica, mentre una combinazione di regolarizzazione L1 e L2 fornisce il miglior risultato nel deep learning, offrendo un equilibrio tra selezione delle caratteristiche e penalizzazione del peso.
La scelta e la forza della regolarizzazione dovrebbero essere attentamente calibrate per bilanciare la complessità dell’apprendimento con il rischio di overfitting o underfitting.
Nel corso di questa esplorazione, abbiamo demistificato la regolarizzazione, mostrando il suo ruolo nel prevenire l'overfitting e nel garantire che i nostri modelli si generalizzino bene ai dati invisibili.
L'applicazione di tecniche di regolarizzazione ti avvicinerà alla competenza nel machine learning e nel deep learning, consolidando il tuo set di strumenti da data scientist.
Accedi ai progetti dati e prova a regolarizzare i tuoi dati in diversi scenari, ad esempio Previsione della durata della consegna. In questo progetto di dati abbiamo utilizzato sia modelli di machine learning che di deep learning. Tuttavia, alla fine, abbiamo anche affermato che potrebbero esserci margini di miglioramento. Allora perché non provi la regolarizzazione laggiù e vedi se aiuta?
Nato Rosidi è un data scientist e nella strategia di prodotto. È anche un professore a contratto che insegna analisi ed è il fondatore di Strata Scratch, una piattaforma che aiuta i data scientist a prepararsi per le loro interviste con domande di interviste reali delle migliori aziende. Connettiti con lui su Twitter: Strata Scratch or LinkedIn.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-regularization-and-what-is-it-for
- :ha
- :È
- 001
- 01
- 1
- 2%
- 5
- 52
- a
- precisione
- Raggiungere
- operanti in
- Adam
- aggiunto
- regolare
- Dopo shavasana, sedersi in silenzio; saluti;
- AI
- mira
- Tutti
- Consentire
- consente
- lungo
- già
- anche
- an
- .
- analitica
- analizzare
- ed
- appare
- Applicazioni
- applicato
- APPLICA
- approcci
- opportuno
- SONO
- articolo
- artificiale
- intelligenza artificiale
- Intelligenza artificiale (AI)
- AS
- valutare
- At
- evitando
- Equilibrio
- balanced
- BE
- prima
- MIGLIORE
- Meglio
- fra
- tavola
- entrambi
- portare
- ma
- by
- calcolato
- Materiale
- Ultra-Grande
- catturare
- attentamente
- scegliere
- più vicino
- codice
- coefficienti
- combinazione
- combinazioni
- Uncommon
- Aziende
- paragonabile
- confrontare
- confronto
- complessità
- concetto
- Connettiti
- costantemente
- contesto
- contesti
- critico
- cura
- Corrente
- danno
- dati
- analisi dei dati
- scienziato di dati
- dataset
- deep
- apprendimento profondo
- definire
- dimostrando
- dettagliati
- dettagli
- DID
- diverso
- diversamente
- scopri
- fare
- Dont
- drasticamente
- dovuto
- durata
- Presto
- più facile
- Efficace
- in maniera efficace
- efficiente
- incoraggia
- fine
- assicurando
- equazione
- epoca
- particolarmente
- essential
- Etere (ETH)
- valutare
- valutazione
- di preciso
- esempio
- eccessivo
- esplorazione
- esplora
- caratteristica
- Caratteristiche
- Trovate
- ricerca
- Nome
- i seguenti
- Nel
- forme
- fondatore
- da
- fondamentale
- generalmente
- va
- buono
- cura
- successo
- Happening
- accade
- he
- aiutare
- aiuta
- Alta
- superiore
- lui
- storia
- Come
- Tutorial
- Tuttavia
- HTTPS
- if
- implementazioni
- importare
- importanza
- miglioramento
- migliora
- in
- inclusi
- Compreso
- Aumenta
- indica
- Intelligence
- Colloquio
- Domande di un'intervista
- interviste
- ai miglioramenti
- IT
- SUO
- KDnuggets
- keras
- l2
- Leads
- IMPARARE
- apprendimento
- impara
- meno
- lasciare
- piace
- limiti
- lineare
- Lista
- ll
- SEMBRA
- spento
- Basso
- macchina
- machine learning
- menzionato
- metrico
- Metrica
- forza
- Ridurre la perdita dienergia con una
- modello
- modellismo
- modelli
- Scopri di più
- maggior parte
- Più popolare
- molti
- Natura
- New
- segnatamente
- sfumato
- numpy
- osservato
- of
- offerta
- di frequente
- Vecchio
- on
- ONE
- esclusivamente
- ottimale
- or
- Altro
- nostro
- produzione
- ancora
- particolarmente
- paziente
- dati del paziente
- modelli
- performance
- prestazioni
- esecuzione
- esegue
- posto
- segnaposto
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- Popolare
- potenziale
- potenzialmente
- libbra
- energia
- Preparare
- prevenire
- prevenzione
- Frodi
- impedisce
- principi
- Stampa
- processi
- Prodotto
- Insegnante
- progetto
- progetti
- proverbio
- fornisce
- Domande
- raggiungere
- di rose
- mondo reale
- ridurre
- riducendo
- regressione
- ripresa
- resti
- ricordando
- riparazione
- ripetere
- rapporto
- colpevole
- Risultati
- Rischio
- Ruolo
- Prenotazione sale
- s
- detto
- Scenari
- Scienziato
- scienziati
- scikit-impara
- vedere
- prodotti
- delicata
- Set
- gravemente
- Corti
- dovrebbero
- mostra
- Spettacoli
- significativa
- significativamente
- Un'espansione
- semplificare
- situazione
- leggermente
- So
- solidificando
- alcuni
- qualcosa
- dividere
- quadrato
- Di partenza
- Ancora
- Fermare
- sosta
- Tornare al suo account
- memorizzare
- Strategia
- forza
- forte
- tale
- soffre
- suggerisce
- Target
- Insegnamento
- tecniche
- tensorflow
- Testing
- di
- che
- Il
- loro
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- Attraverso
- tempo
- a
- pure
- strumenti
- top
- Treni
- Training
- trasformativa
- vero
- prova
- sintonizzato
- seconda
- sottostante
- sottolineature
- us
- uso
- utilizzato
- utile
- utilizzando
- APPREZZIAMO
- Valori
- vario
- variare
- Ve
- modi
- we
- peso
- WELL
- noto
- Che
- Che cosa è l'
- quando
- quale
- while
- perché
- ampiamente
- volere
- con
- testimoniare
- valore
- X
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- zero