Bruce Warrington tramite Unsplash
Il motivo per cui i modelli di machine learning in generale stanno diventando più intelligenti è dovuto alla loro dipendenza dall'utilizzo di dati etichettati per aiutarli a discernere tra due oggetti simili.
Tuttavia, senza questi set di dati etichettati, incontrerai grossi ostacoli durante la creazione del modello di machine learning più efficace e affidabile. I set di dati etichettati durante la fase di addestramento di un modello sono importanti.
Il deep learning è stato ampiamente utilizzato per risolvere compiti come la visione artificiale utilizzando l'apprendimento supervisionato. Tuttavia, come per molte cose nella vita, ha delle restrizioni. La classificazione supervisionata richiede un'elevata quantità e qualità di dati di addestramento etichettati per produrre un modello robusto. Ciò significa che il modello di classificazione non può gestire classi non viste.
E sappiamo tutti quanta potenza di calcolo, riqualificazione, tempo e denaro sono necessari per addestrare un modello di deep learning.
Ma un modello può ancora essere in grado di discernere tra due oggetti senza aver utilizzato i dati di addestramento? Sì, si chiama apprendimento a colpo zero. L'apprendimento a colpo zero è la capacità di un modello di essere in grado di completare un'attività senza aver ricevuto o utilizzato alcun esempio di addestramento.
Gli esseri umani sono naturalmente in grado di apprendere a colpo zero senza doversi impegnare molto. I nostri cervelli memorizzano già dizionari e ci consentono di differenziare gli oggetti osservando le loro proprietà fisiche grazie alla nostra attuale base di conoscenze. Possiamo usare questa base di conoscenza per vedere le somiglianze e le differenze tra gli oggetti e trovare il collegamento tra di loro.
Ad esempio, supponiamo di voler costruire un modello di classificazione delle specie animali. Secondo Il nostro mondo nei dati, nel 2.13 sono state calcolate 2021 milioni di specie. Pertanto, se vogliamo creare il modello di classificazione più efficace per le specie animali, avremmo bisogno di 2.13 milioni di classi diverse. Saranno necessari anche molti dati. I dati di alta quantità e qualità sono difficili da trovare.
Quindi, in che modo l'apprendimento a colpo zero risolve questo problema?
Poiché l'apprendimento zero-shot non richiede che il modello abbia appreso i dati di addestramento e come classificare le classi, ci consente di fare meno affidamento sulla necessità del modello di dati etichettati.
Quanto segue è ciò di cui dovranno essere costituiti i tuoi dati per procedere con l'apprendimento zero-shot.
Classi viste
Questo è costituito dalle classi di dati che sono state utilizzate in precedenza per addestrare un modello.
Classi invisibili
Questo è costituito dalle classi di dati che NON sono state utilizzate per addestrare un modello e il nuovo modello di apprendimento zero-shot si generalizzerà.
Informazioni ausiliarie
Poiché i dati nelle classi invisibili non sono etichettati, l'apprendimento zero-shot richiederà informazioni ausiliarie per apprendere e trovare correlazioni, collegamenti e proprietà. Questo può essere sotto forma di incorporamenti di parole, descrizioni e informazioni semantiche.
Metodi di apprendimento a colpo zero
L'apprendimento a colpo zero viene tipicamente utilizzato in:
- Metodi basati su classificatori
- Metodi basati su istanze
stage
L'apprendimento zero-shot viene utilizzato per creare modelli per classi che non si addestrano utilizzando dati etichettati, pertanto richiede queste due fasi:
1. Formazione
La fase di formazione è il processo del metodo di apprendimento che cerca di acquisire quanta più conoscenza possibile sulle qualità dei dati. Possiamo vedere questo come la fase di apprendimento.
2. Inferenza
Durante la fase di inferenza, tutta la conoscenza appresa dalla fase di formazione viene applicata e utilizzata per classificare gli esempi in un nuovo insieme di classi. Possiamo vedere questo come la fase di fare previsioni.
Come funziona?
La conoscenza delle classi viste sarà trasferita alle classi invisibili in uno spazio vettoriale ad alta dimensione; questo è chiamato spazio semantico. Ad esempio, nella classificazione delle immagini lo spazio semantico insieme all'immagine subirà due passaggi:
1. Spazio di incorporamento comune
È qui che vengono proiettati i vettori semantici ei vettori della caratteristica visiva.
2. Massima somiglianza
Qui è dove le caratteristiche vengono confrontate con quelle di una classe invisibile.
Per aiutare a comprendere il processo con le due fasi (addestramento e inferenza), applichiamole nell'uso della classificazione delle immagini.
Training

Jari Hytonen tramite Unsplash
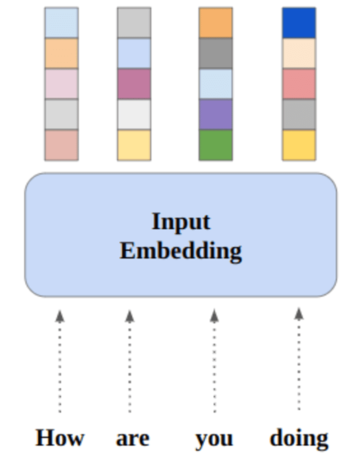
Come essere umano, se dovessi leggere il testo a destra nell'immagine sopra, presumeresti immediatamente che ci sono 4 gattini in un cestino marrone. Ma diciamo che non hai idea di cosa sia un "gattino". Assumerai che ci sia un cestino marrone con dentro 4 cose, che si chiamano "gattini". Una volta che ti imbatti in più immagini che contengono qualcosa che assomiglia a un "gattino", sarai in grado di differenziare un "gattino" dagli altri animali.
Questo è quello che succede quando usi Preformazione contrastiva linguaggio-immagine (CLIP) di OpenAI per l'apprendimento zero-shot nella classificazione delle immagini. È noto come informazioni ausiliarie.
Potresti pensare, "beh, sono solo dati etichettati". Capisco perché lo pensi, ma non lo sono. Le informazioni ausiliarie non sono etichette dei dati, sono una forma di supervisione per aiutare il modello ad apprendere durante la fase di addestramento.
Quando un modello di apprendimento zero-shot vede una quantità sufficiente di accoppiamenti immagine-testo, sarà in grado di differenziare e comprendere le frasi e il modo in cui si correlano con determinati schemi nelle immagini. Utilizzando la tecnica CLIP di "apprendimento contrastivo", il modello di apprendimento zero-shot è stato in grado di accumulare una buona base di conoscenze per poter fare previsioni sui compiti di classificazione.
Questo è un riepilogo dell'approccio CLIP in cui addestrano insieme un codificatore di immagini e un codificatore di testo per prevedere gli accoppiamenti corretti di una serie di esempi di addestramento (immagine, testo). Si prega di vedere l'immagine qui sotto:

Apprendimento di modelli visivi trasferibili dalla supervisione del linguaggio naturale
Inferenza
Una volta che il modello ha superato la fase di addestramento, dispone di una buona base di conoscenza dell'accoppiamento immagine-testo e può ora essere utilizzato per fare previsioni. Ma prima di poter iniziare subito a fare previsioni, dobbiamo impostare l'attività di classificazione creando un elenco di tutte le possibili etichette che il modello potrebbe produrre.
Ad esempio, attenendoci al compito di classificazione delle immagini sulle specie animali, avremo bisogno di un elenco di tutte le specie di animali. Ognuna di queste etichette sarà codificata, T? a T? utilizzando il codificatore di testo preaddestrato che si è verificato nella fase di addestramento.
Una volta che le etichette sono state codificate, possiamo inserire le immagini tramite il codificatore di immagini pre-addestrato. Useremo la somiglianza del coseno della metrica della distanza per calcolare le somiglianze tra la codifica dell'immagine e la codifica di ciascuna etichetta di testo.
La classificazione dell'immagine viene effettuata in base all'etichetta con la maggiore somiglianza con l'immagine. Ed è così che si ottiene l'apprendimento a colpo zero, in particolare nella classificazione delle immagini.
Scarsità di dati
Come accennato in precedenza, è difficile mettere le mani su dati di elevata quantità e qualità. A differenza degli esseri umani che possiedono già la capacità di apprendimento zero-shot, le macchine richiedono dati etichettati di input per apprendere e quindi essere in grado di adattarsi alle variazioni che possono verificarsi naturalmente.
Se guardiamo all'esempio delle specie animali, ce n'erano così tante. E poiché il numero di categorie continua a crescere in diversi domini, ci vorrà molto lavoro per tenere il passo con la raccolta di dati annotati.
Per questo motivo, l'apprendimento a colpo zero è diventato più prezioso per noi. Sempre più ricercatori sono interessati al riconoscimento automatico degli attributi per compensare la mancanza di dati disponibili.
Etichettatura dei dati
Un altro vantaggio dell'apprendimento zero-shot sono le sue proprietà di etichettatura dei dati. L'etichettatura dei dati può essere laboriosa e molto noiosa e, per questo motivo, può portare a errori durante il processo. L'etichettatura dei dati richiede esperti, come professionisti medici che stanno lavorando su un set di dati biomedici, che è molto costoso e richiede tempo.
L'apprendimento a colpo zero sta diventando sempre più popolare a causa delle suddette limitazioni dei dati. Ci sono alcuni documenti che ti consiglierei di leggere se sei interessato alle sue capacità:
Nisha Aria è un Data Scientist e uno scrittore tecnico freelance. È particolarmente interessata a fornire consigli o tutorial sulla carriera in Data Science e conoscenze basate sulla teoria sulla Data Science. Desidera anche esplorare i diversi modi in cui l'Intelligenza Artificiale è/può avvantaggiare la longevità della vita umana. Una studentessa appassionata, che cerca di ampliare le sue conoscenze tecnologiche e capacità di scrittura, aiutando al contempo a guidare gli altri.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.kdnuggets.com/2022/12/zeroshot-learning-explained.html?utm_source=rss&utm_medium=rss&utm_campaign=zero-shot-learning-explained
- 2021
- a
- abilità
- capacità
- capace
- Chi siamo
- sopra
- Secondo
- Accumulare
- raggiunto
- operanti in
- adattare
- consigli
- contro
- Tutti
- consente
- già
- quantità
- ed
- animali
- animali
- applicato
- APPLICA
- approccio
- in giro
- artificiale
- intelligenza artificiale
- Automatico
- disponibile
- base
- basato
- cestino
- diventare
- diventando
- prima
- essendo
- sotto
- beneficio
- fra
- biomedico
- allargare
- costruire
- calcolato
- detto
- Può ottenere
- non può
- capace
- catturare
- Career
- categoria
- certo
- classe
- classi
- classificazione
- classificare
- Raccolta
- Venire
- completamento di una
- potenza computazionale
- Calcolare
- computer
- Visione computerizzata
- continua
- potuto
- creare
- Creazione
- Corrente
- dati
- scienza dei dati
- scienziato di dati
- dataset
- deep
- apprendimento profondo
- Dipendenza
- differenze
- diverso
- differenziare
- distanza
- domini
- durante
- ogni
- Efficace
- sforzo
- errori
- esempio
- Esempi
- costoso
- esperti
- ha spiegato
- esplora
- caratteristica
- Caratteristiche
- pochi
- Trovare
- i seguenti
- modulo
- indipendente
- da
- Generale
- ottenere
- buono
- maggiore
- Crescere
- guida
- maniglia
- Mani
- accade
- Hard
- avendo
- Aiuto
- aiutare
- Alta
- massimo
- vivamente
- Come
- Tutorial
- Tuttavia
- HTTPS
- umano
- Gli esseri umani
- idea
- Immagine
- Classificazione delle immagini
- immagini
- importante
- in
- informazioni
- ingresso
- Intelligence
- interessato
- IT
- Acuto
- mantenere
- Sapere
- conoscenze
- conosciuto
- Discografica
- etichettatura
- per il tuo brand
- Dipingere
- Lingua
- portare
- IMPARARE
- imparato
- apprendimento
- Vita
- limiti
- LINK
- Collegamento
- Lista
- longevità
- Guarda
- cerca
- SEMBRA
- lotto
- macchina
- machine learning
- macchine
- maggiore
- make
- Fare
- molti
- si intende
- medicale
- menzionato
- metodo
- metodi
- metrico
- forza
- milione
- modello
- modelli
- soldi
- Scopri di più
- maggior parte
- Naturale
- Bisogno
- New
- numero
- oggetti
- ostacoli
- si è verificato
- ONE
- OpenAI
- minimo
- Altro
- Altri
- appaiamento
- abbinamenti
- documenti
- particolarmente
- modelli
- fase
- Frasi
- Fisico
- Platone
- Platone Data Intelligence
- PlatoneDati
- per favore
- Popolare
- possibile
- energia
- predire
- Previsioni
- in precedenza
- Problema
- processi
- produrre
- Scelto dai professionisti
- proiettato
- proprietà
- fornitura
- metti
- qualità
- qualità
- quantità
- Leggi
- ragione
- ricevuto
- riconoscimento
- raccomandare
- richiedere
- richiede
- ricercatori
- restrizioni
- robusto
- Scienze
- Scienziato
- cerca
- vede
- set
- simile
- somiglianze
- abilità
- più intelligente
- So
- RISOLVERE
- qualcosa
- lo spazio
- in particolare
- Stage
- tappe
- Passi
- adesivo
- Ancora
- Tornare al suo account
- tale
- sufficiente
- SOMMARIO
- supervisione
- Fai
- prende
- Task
- task
- Tech
- Consulenza
- I
- loro
- perciò
- cose
- Pensiero
- Attraverso
- tempo
- richiede tempo
- a
- insieme
- Treni
- Training
- trasferito
- affidabili sul mercato
- esercitazioni
- tipicamente
- capire
- us
- uso
- utilizzati
- Prezioso
- via
- Visualizza
- visione
- modi
- Che
- quale
- Mentre
- OMS
- ampiamente
- volere
- senza
- Word
- Lavora
- lavoro
- sarebbe
- scrittore
- scrittura
- Trasferimento da aeroporto a Sharm
- zefiro
- Apprendimento a tiro zero