מבוא
מכונת התמיכה הווקטורית החד-קלאסית (SVM) היא גרסה של ה-SVM המסורתי. הוא מותאם במיוחד לאיתור חריגות. מטרתו העיקרית היא לאתר מקרים החורגים באופן ניכר מהתקן. בניגוד לקונבנציונאלי למידת מכונה מודלים המתמקדים בסיווג בינארי או רב-מעמדי, ה-SVM החד-מחלקה מתמחה בזיהוי חריגים או חידושים בתוך מערכי נתונים. במאמר זה תלמדו כיצד מכונת תמיכה וקטורית חד-מעמדית (SVM) שונה מ-SVM מסורתית. תלמד גם כיצד פועל OC-SVM וכיצד ליישם אותו. תלמד גם על ההיפרפרמטרים שלו.
מטרות למידה
- להבין חריגות
- למד על SVM מחלקה אחת
- הבן במה זה שונה מ-Support Vector Machine (SVM)
- היפרפרמטרים של OC-SVM ב-Sklearn
- כיצד לזהות חריגות באמצעות OC-SVM
- השתמש במקרים של SVM מחלקה אחת
תוכן העניינים
הבנת חריגות
אנומליות הן תצפיות או מקרים החורגים באופן משמעותי מההתנהגות הרגילה של מערך נתונים. סטיות אלו יכולות להתבטא בצורות שונות, כגון חריגים, רעש, שגיאות או דפוסים בלתי צפויים. חריגות הן לרוב מרתקות מכיוון שהן עשויות לייצג תובנות חשובות. הם עשויים לספק תובנות כגון זיהוי עסקאות הונאה, זיהוי תקלות בציוד או חשיפת תופעות חדשות. זיהוי חריגים וחידושים מזהים חריגות ותצפיות חריגות או לא שכיחות.
גם לקרוא: מדריך מקצה לקצה לזיהוי אנומליות
SVM מחלקה אחת
מבוא לתמיכה במכונות וקטוריות (SVMs)
תמיכה במכונות וקטוריות (SVMs) הן פופולריות אלגוריתם למידה מפוקח למשימות סיווג ורגרסיה. SVMs פועלים על ידי מציאת ה-Hyperplane האופטימלי המפריד בין מחלקות שונות במרחב התכונה תוך מקסום המרווח ביניהן. היפר-מישור זה מבוסס על תת-קבוצה של נקודות נתוני אימון הנקראות וקטורי תמיכה.
SVM מחלקה אחת לעומת SVM מסורתי
- SVM מחלקה אחת מייצגים גרסה של אלגוריתם SVM המסורתי המשמש בעיקר למשימות חריגות וזיהוי חידושים. בניגוד ל-SVMs מסורתיים, המטפלים במשימות סיווג בינארי, SVM מחלקה אחת מתאמן באופן בלעדי על נקודות נתונים ממחלקה אחת, המכונה מחלקת היעד. SVM מחלקה אחת שואפת ללמוד פונקציית גבול או החלטה המכילה את מחלקת היעד במרחב התכונות, תוך מודל יעיל של ההתנהגות הרגילה של הנתונים.
- מערכות SVM מסורתיות שואפות למצוא גבול החלטה שממקסם את המרווח בין מחלקות שונות, המאפשר סיווג אופטימלי של נקודות נתונים חדשות. מצד שני, One-Class SVM מבקש למצוא גבול המקיף את מחלקת היעד תוך מזעור הסיכון של הכללת חריגים או מופעים חדשים מחוץ לגבול זה.
- SVMs מסורתיים דורשים נתונים מסומנים עם מופעים ממספר מחלקות, מה שהופך אותם מתאימים למשימות סיווג מפוקחות. לעומת זאת, One-Class SVM מאפשר יישום בתרחישים שבהם רק נתונים ממחלקת היעד זמינים, מה שהופך אותו למתאים היטב למשימות זיהוי חריגות וזיהוי חידושים ללא פיקוח.
מידע נוסף: סיווג מחלקה אחת באמצעות תמיכה במכונות וקטוריות
שניהם שונים בניסוחי השוליים הרכים שלהם ובאופן השימוש בהם:
(שוליים רכים ב-SVM משמשים כדי לאפשר מידה מסוימת של סיווג שגוי)
SVM מחלקה אחת שואפת לגלות היפר-מישור עם שוליים מקסימליים בתוך מרחב התכונה על ידי הפרדת הנתונים הממופים מהמקור. במערך נתונים Dn = {x1, . . . , xn} עם xi ∈ X (xi הוא תכונה) ו-n ממדים:
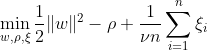
משוואה זו מייצגת את ניסוח הבעיה הראשוני עבור OC-SVM, כאשר w הוא מישור ההיפר המפריד, ρ הוא ההיסט מהמקור, ו-ξi הם משתנים רפויים. הם מאפשרים רווח רך אך מענישים הפרות ξi. היפרפרמטר ν ∈ (0, 1] שולט בהשפעת משתנה ה-slack ויש להתאים אותו בהתאם לצורך. המטרה היא למזער את הנורמה של w תוך ענישה על סטיות מהשוליים. יתרה מכך, זה מאפשר לשבריר מהנתונים נופלים בשוליים או בצד הלא נכון של המישור.
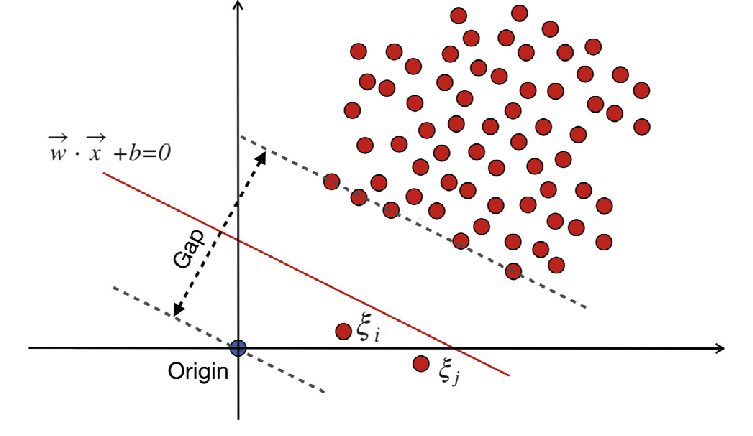
WX + b =0 הוא גבול ההחלטה, ומשתני הרפוי מענישים סטיות.
מכונות וקטור תמיכה מסורתיות (SVM)
מכונות וקטור תמיכה מסורתיות (SVM) משתמשות בניסוח השוליים הרכים לשגיאות סיווג שגוי. או שהם משתמשים בנקודות נתונים שנופלות בשוליים או בצד הלא נכון של גבול ההחלטה.
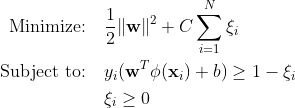
איפה:
w הוא וקטור המשקל.
b הוא מונח ההטיה.
ξi הם משתני רפיון המאפשרים אופטימיזציה של שוליים רכים.
C הוא פרמטר ההסדרה השולט על ההחלפה בין מקסום המרווח לבין מזעור טעות הסיווג.
ϕ(xi) מייצג את פונקציית מיפוי התכונות.
ב-SVM המסורתי, שיטת למידה מפוקחת המסתמכת על תוויות מחלקות להפרדה משלבת משתנים רפויים כדי לאפשר רמה מסוימת של סיווג שגוי. המטרה העיקרית של SVM היא להפריד נקודות נתונים של מחלקות נפרדות באמצעות גבול ההחלטה WX + b = 0. הערך של משתני slack משתנה בהתאם למיקום נקודות הנתונים: הם מוגדרים ל-0 אם נקודות הנתונים ממוקמות מעבר לשוליים. אם נקודת הנתונים נמצאת בתוך השוליים, משתני הרפיון נעים בין 0 ל-1, ומשתרעים מעבר לשוליים הנגדיים אם הם גדולים מ-1.
הן SVMs מסורתיות והן SVMs מחלקה אחת עם ניסוחי שוליים רכים שואפות למזער את הנורמה של וקטור המשקל. ובכל זאת, הם שונים ביעדים שלהם ובאופן שבו הם מתמודדים עם טעויות סיווג שגוי או חריגות מגבול ההחלטה. SVM מסורתיים מייעלים את דיוק הסיווג כדי למנוע התאמת יתר, בעוד ש-SVM מחלקה אחת מתמקדים במודלים של מחלקת היעד ושליטה בשיעור החריגים או מופעים חדשים.
גם לקרוא: מדריך AZ לתמיכה במכשיר וקטור
היפרפרמטרים חשובים ב-SVM מחלקה אחת
- nu: זהו היפרפרמטר קריטי ב- One-Class SVM, השולט בשיעור החריגים המותרים. הוא קובע גבול עליון לשבריר שגיאות האימון וגבול תחתון לשבריר וקטורי התמיכה. זה בדרך כלל נע בין 0 ל-1, כאשר ערכים נמוכים יותר מרמזים על מרווח קשיח יותר ועשויים ללכוד פחות חריגים, בעוד שערכים גבוהים יותר מתירנים. ערך ברירת המחדל הוא 0.5.
- גרעין: פונקציית הקרנל קובעת את סוג גבול ההחלטה שה-SVM משתמש בו. האפשרויות הנפוצות כוללות 'ליניארי', 'rbf' (פונקציית בסיס רדיאלית גאוסית), 'פולי' (פולינום) ו'סיגמואיד'. הליבה 'rbf' משמשת לעתים קרובות מכיוון שהיא יכולה ללכוד ביעילות קשרים מורכבים לא ליניאריים.
- גמא: זהו פרמטר עבור היפר-מטוסים לא ליניאריים. הוא מגדיר כמה השפעה יש לדוגמא אימון בודדת. ככל שערך הגמא גדול יותר, כך יש להשפיע על דוגמאות אחרות קרובות יותר. פרמטר זה ספציפי לקרנל RBF ומוגדר בדרך כלל ל-'auto', אשר ברירת המחדל היא 1 / n_features.
- פרמטרי ליבה (תואר, coef0): פרמטרים אלה מיועדים לגרעיני פולינום וסיגמואידים. 'תואר' הוא דרגת פונקציית הליבה הפולינומית, ו-'coef0' הוא האיבר הבלתי תלוי בפונקציית הליבה. כוונון פרמטרים אלה עשוי להיות נחוץ להשגת ביצועים מיטביים.
- טול: זה קריטריון העצירה. האלגוריתם נעצר כאשר פער הדואליות קטן מהסובלנות. זה פרמטר השולט בסובלנות עבור קריטריון העצירה.
עיקרון העבודה של SVM חד מחלקה
פונקציות ליבה ב-SVM מחלקה אחת
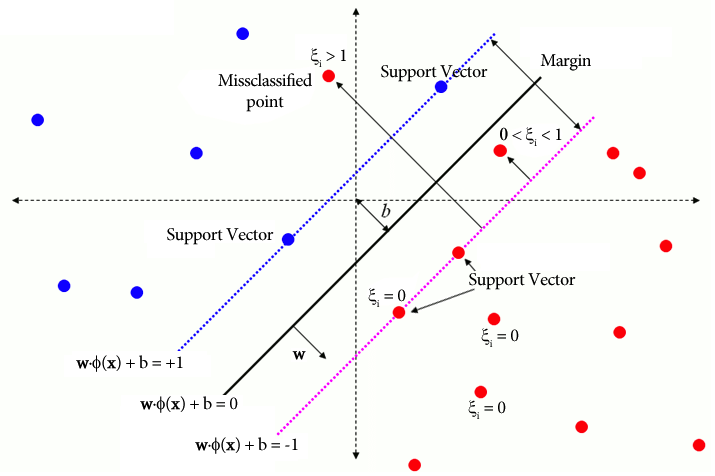
פונקציות ליבה ממלאות תפקיד מכריע ב- One Class SVM על ידי כך שהן מאפשרות לאלגוריתם לפעול במרחבי תכונה בעלי ממדים גבוהים יותר מבלי לחשב במפורש את הטרנספורמציות. ב-SVM מחלקה אחת, כמו ב-SVMs מסורתיים, נעשה שימוש בפונקציות ליבה למדידת הדמיון בין זוגות של נקודות נתונים במרחב הקלט. פונקציות ליבה נפוצות בשימוש ב- One-Class SVM כוללות גרעינים גאוסיים (RBF), פולינומיים וסיגמואידים. גרעינים אלה ממפים את מרחב הקלט המקורי למרחב בעל ממדים גבוהים יותר, שבו נקודות נתונים הופכות להפרדה ליניארית או מציגות דפוסים ברורים יותר, מה שמקל על הלמידה. על ידי בחירת פונקציית ליבה מתאימה וכוונון הפרמטרים שלה, One-Class SVM יכול ללכוד ביעילות קשרים מורכבים ומבנים לא ליניאריים בנתונים, ולשפר את יכולתו לזהות חריגות או חריגות.
במקרים בהם הנתונים אינם ניתנים להפרדה ליניארית, כגון בעת התמודדות עם דפוסים מורכבים או חופפים, מכונות וקטור תמיכה (SVMs) יכולות להפעיל ליבה של Radial Basis Function (RBF) כדי להפריד חריגים משאר הנתונים ביעילות. ליבת RBF הופכת את נתוני הקלט למרחב תכונה בעל מימד גבוה יותר שניתן להפריד טוב יותר.
וקטורי שוליים ותמיכה
הרעיון של וקטורי שוליים ותמיכה ב- One-Class SVM דומה לזה שב-SVM המסורתיים. השוליים מתייחסים לאזור שבין גבול ההחלטה (היפר-מישור) לנקודות הנתונים הקרובות ביותר מכל מחלקה. ב- One-Class SVM, השוליים מייצגים את האזור שבו נמצאות רוב נקודות הנתונים השייכות למחלקת היעד. מקסום השוליים חיוני עבור SVM מחלקה אחת מכיוון שהוא עוזר להכליל היטב נקודות נתונים חדשות ומשפר את חוסנו של המודל. וקטורי תמיכה הם נקודות הנתונים השוכנות על השוליים או בתוכם ותורמות להגדרת גבול ההחלטה.
ב- One-Class SVM, וקטורי תמיכה הם נקודות הנתונים ממחלקת היעד הקרובה ביותר לגבול ההחלטה. וקטורי תמיכה אלה ממלאים תפקיד משמעותי בקביעת הצורה והכיוון של גבול ההחלטה, ולפיכך, בביצועים הכוללים של מודל SVM מחלקה אחת. על ידי זיהוי וקטורי התמיכה, One-Class SVM לומד ביעילות את הייצוג של מחלקת היעד במרחב התכונות ובונה גבול החלטה המקיף את רוב נקודות הנתונים תוך מזעור הסיכון של הכללת חריגים או מופעים חדשים.
כיצד ניתן לזהות חריגות באמצעות SVM מחלקה אחת?
זיהוי חריגות באמצעות SVM מחלקה אחת (Support Vector Machine) באמצעות טכניקות זיהוי חידושים וזיהוי חריגים:
זיהוי חוץ
זה כרוך בזיהוי תצפיות בנתוני האימון החורגות באופן משמעותי מהשאר, הנקראים לעתים קרובות חריגים. אומדנים עבור זיהוי חריגים שואפים להתאים לאזורים שבהם נתוני האימון מרוכזים ביותר, תוך התעלמות מהתצפיות החריגות הללו.
from sklearn.svm import OneClassSVM
from sklearn.datasets import load_wine
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
from sklearn.inspection import DecisionBoundaryDisplay
# Load data
X = load_wine()["data"][:, [6, 9]] # "banana"-shaped
# Define estimators (One-Class SVM)
estimators_hard_margin = {
"Hard Margin OCSVM": OneClassSVM(nu=0.01, gamma=0.35), # Very small nu for hard margin
}
estimators_soft_margin = {
"Soft Margin OCSVM": OneClassSVM(nu=0.25, gamma=0.35), # Nu between 0 and 1 for soft margin
}
# Plotting setup
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
colors = ["tab:blue", "tab:orange", "tab:red"]
legend_lines = []
# Hard Margin OCSVM
ax = axs[0]
for color, (name, estimator) in zip(colors, estimators_hard_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Hard Margin Outlier detection (wine recognition)",
)
# Soft Margin OCSVM
ax = axs[1]
legend_lines = []
for color, (name, estimator) in zip(colors, estimators_soft_margin.items()):
estimator.fit(X)
DecisionBoundaryDisplay.from_estimator(
estimator,
X,
response_method="decision_function",
plot_method="contour",
levels=[0],
colors=color,
ax=ax,
)
legend_lines.append(mlines.Line2D([], [], color=color, label=name))
ax.scatter(X[:, 0], X[:, 1], color="black")
ax.legend(handles=legend_lines, loc="upper center")
ax.set(
xlabel="flavanoids",
ylabel="color_intensity",
title="Soft Margin Outlier detection (wine recognition)",
)
plt.tight_layout()
plt.show()

העלילות מאפשרות לנו לבחון חזותית את הביצועים של דגמי SVM מחלקה אחת באיתור חריגים במערך הנתונים של Wine.
על ידי השוואת התוצאות של דגמי SVM חד מחלקה עם שוליים קשיחים ושוליים רכים, נוכל לראות כיצד הבחירה בהגדרת השוליים (פרמטר nu) משפיעה על זיהוי חריגים.
מודל השוליים הקשים עם ערך nu קטן מאוד (0.01) מביא כנראה לגבול החלטה שמרני יותר. הוא עוטף בחוזקה את רוב נקודות הנתונים ואפשר לסווג פחות נקודות כחריגים.
לעומת זאת, מודל השוליים הרכים עם ערך nuu גדול יותר (0.35) מביא כנראה לגבול החלטה גמיש יותר. ובכך מאפשרים מרווח רחב יותר ועלול לתפוס יותר חריגים.
איתור חידושים
מצד שני, אנו מיישמים אותו כאשר נתוני האימון אינם חריגים, והמטרה היא לקבוע אם תצפית חדשה היא נדירה, כלומר שונה מאוד מתצפיות ידועות. התצפית האחרונה כאן נקראת חידוש.
import numpy as np
from sklearn import svm
# Generate train data
np.random.seed(30)
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * np.random.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
# fit the model
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
n_error_outliers = y_pred_outliers[y_pred_outliers == 1].size
import matplotlib.font_manager
import matplotlib.lines as mlines
import matplotlib.pyplot as plt
from sklearn.inspection import DecisionBoundaryDisplay
_, ax = plt.subplots()
# generate grid for the boundary display
xx, yy = np.meshgrid(np.linspace(-5, 5, 10), np.linspace(-5, 5, 10))
X = np.concatenate([xx.reshape(-1, 1), yy.reshape(-1, 1)], axis=1)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
cmap="PuBu",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contourf",
ax=ax,
levels=[0, 10000],
colors="palevioletred",
)
DecisionBoundaryDisplay.from_estimator(
clf,
X,
response_method="decision_function",
plot_method="contour",
ax=ax,
levels=[0],
colors="darkred",
linewidths=2,
)
s = 40
b1 = ax.scatter(X_train[:, 0], X_train[:, 1], c="white", s=s, edgecolors="k")
b2 = ax.scatter(X_test[:, 0], X_test[:, 1], c="blueviolet", s=s, edgecolors="k")
c = ax.scatter(X_outliers[:, 0], X_outliers[:, 1], c="gold", s=s, edgecolors="k")
plt.legend(
[mlines.Line2D([], [], color="darkred"), b1, b2, c],
[
"learned frontier",
"training observations",
"new regular observations",
"new abnormal observations",
],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11),
)
ax.set(
xlabel=(
f"error train: {n_error_train}/200 ; errors novel regular: {n_error_test}/40 ;"
f" errors novel abnormal: {n_error_outliers}/40"
),
title="Novelty Detection",
xlim=(-5, 5),
ylim=(-5, 5),
)
plt.show()
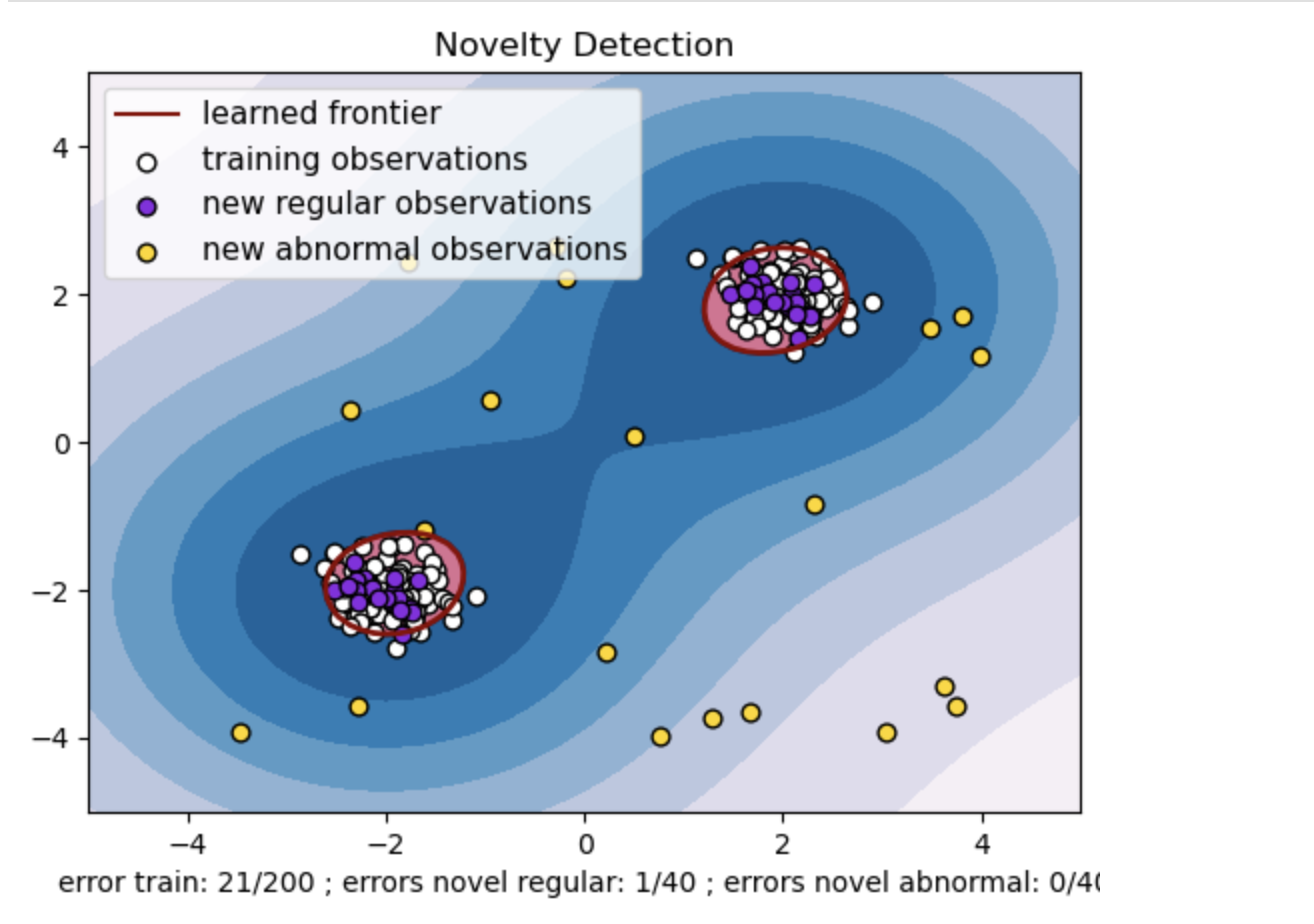
- צור מערך נתונים סינתטי עם שני אשכולות של נקודות נתונים. עשה זאת על ידי יצירתם עם התפלגות נורמלית סביב שני מרכזים שונים: (2, 2) ו-(-2, -2) עבור נתוני רכבת ובדיקה. צור באופן אקראי עשרים נקודות נתונים באופן אחיד בתוך אזור מרובע שנע בין -4 ל-4 לאורך שני הממדים. נקודות נתונים אלו מייצגות תצפיות חריגות או חריגות החורגות באופן משמעותי מההתנהגות הרגילה הנצפית ברכבת ובנתוני הבדיקה.
- הגבול הנלמד מתייחס לגבול ההחלטה שנלמד על ידי מודל ה- One-class SVM. גבול זה מפריד בין האזורים של מרחב התכונה שבהם המודל מחשיב את נקודות הנתונים כנורמליות לבין החריגות.
- שיפוע הצבע מכחול ללבן בקווי המתאר מייצג את דרגות הביטחון או הוודאות השונות שדגם ה- One-Class SVM מקצה לאזורים שונים בחלל התכונות, כאשר גוונים כהים יותר מצביעים על ביטחון גבוה יותר בסיווג נקודות נתונים כ'נורמליות'. כחול כהה מציין אזורים עם אינדיקציה חזקה של היותם 'נורמליים' בהתאם לפונקציית ההחלטה של הדגם. ככל שהצבע הופך בהיר יותר בקו המתאר, המודל פחות בטוח לגבי סיווג נקודות נתונים כ'רגילות'.
- העלילה מייצגת חזותית כיצד מודל SVM חד-מחלקה יכול להבחין בין תצפיות רגילות לתצפיות חריגות. גבול ההחלטה הנלמד מפריד בין אזורי התצפיות הנורמליות והחריגות. SVM מחלקה אחת לזיהוי חידושים מוכיחה את יעילותו בזיהוי תצפיות חריגות במערך נתונים נתון.
עבור nu=0.5:
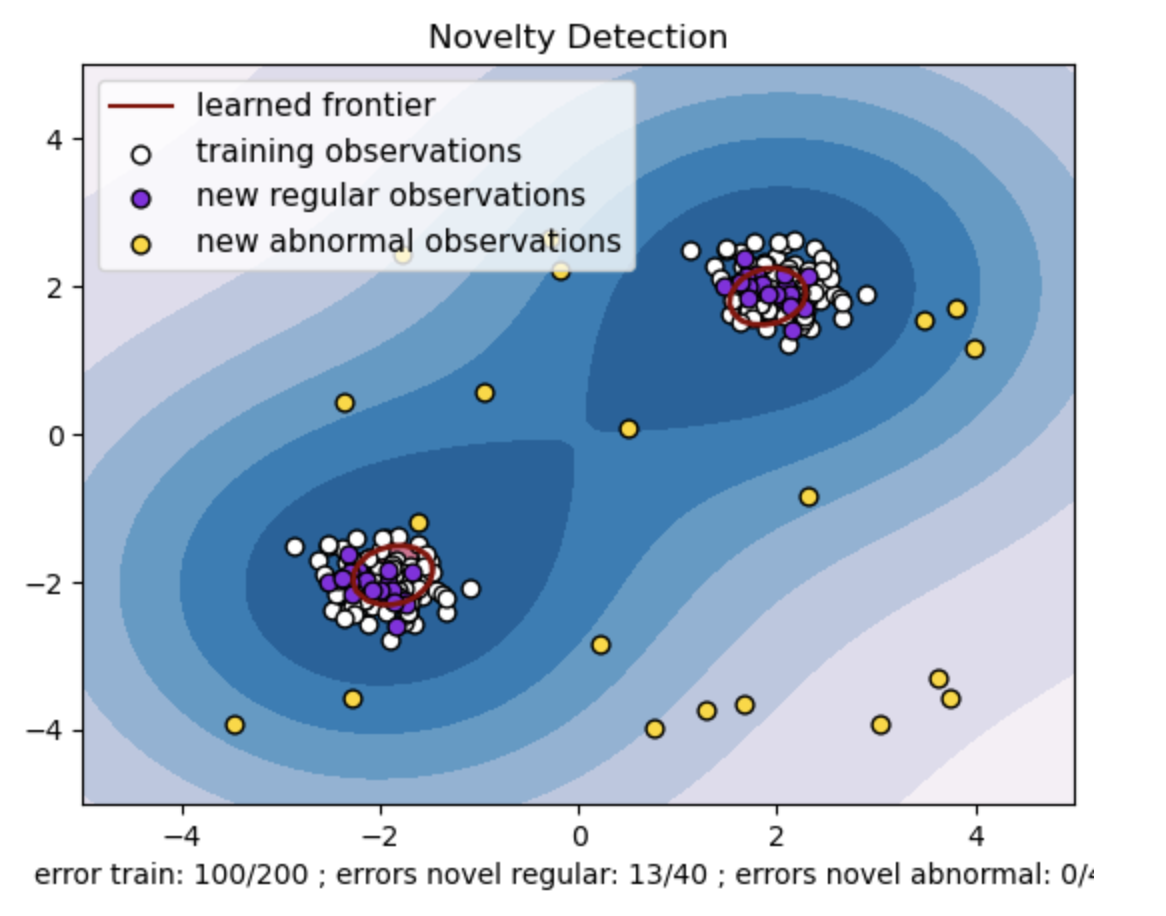
הערך "nu" ב-SVM מחלקה אחת ממלא תפקיד מכריע בשליטה על חלק החריגים הנסבל על ידי המודל. זה משפיע ישירות על יכולת המודל לזהות חריגות ובכך משפיע על החיזוי. אנו יכולים לראות שהמודל מאפשר סיווג שגוי של 100 נקודות אימון. ערך נמוך יותר של nu מרמז על מגבלה מחמירה יותר על החלק המותר של חריגים. הבחירה ב-nu משפיעה על ביצועי המודל באיתור חריגות. זה גם דורש כוונון זהיר בהתבסס על הדרישות הספציפיות של האפליקציה ומאפייני מערך הנתונים.
עבור גמא=0.5 ו-nu=0.5

ב-SVM מחלקה אחת, ההיפרפרמטר גמא מייצג את מקדם הליבה עבור הליבה 'rbf'. היפרפרמטר זה משפיע על צורת גבול ההחלטה, וכתוצאה מכך משפיע על ביצועי הניבוי של המודל.
כאשר הגמא גבוהה, דוגמה אחת לאימון מגבילה את השפעתה לסביבה הקרובה שלה. זה יוצר גבול החלטה מקומי יותר. לכן, נקודות נתונים חייבות להיות קרובות יותר לוקטורי התמיכה כדי להשתייך לאותה מחלקה.
סיכום
שימוש ב-SVM מחלקה אחת לזיהוי חריגות, שימוש בזיהוי חריגים וחידושים מציע פתרון חזק בתחומים שונים. זה עוזר בתרחישים שבהם נתוני חריגות מסומנים נדירים או לא זמינים. ובכך הופך אותו לבעל ערך במיוחד ביישומים בעולם האמיתי שבהם חריגות הן נדירות ומאתגרות להגדרה מפורשת. מקרי השימוש בו משתרעים לתחומים מגוונים, כגון אבטחת סייבר ואבחון תקלות, שבהם לחריגות יש השלכות. עם זאת, בעוד ש- One-Class SVM מציג יתרונות רבים, יש צורך להגדיר את הפרמטרים ההיפר-פרמטרים בהתאם לנתונים כדי לקבל תוצאות טובות יותר, דבר שעלול לפעמים להיות מייגע.
שאלות נפוצות
א. SVM חד-מחלקה בונה היפר-מישור (או היפר-ספירה בממדים גבוהים יותר) המקופלת את נקודות הנתונים הרגילות. מישור יתר זה ממוקם כדי למקסם את המרווח בין הנתונים הרגילים לגבול ההחלטה. נקודות נתונים מסווגות כנורמליות (בתוך הגבול) או חריגות (מחוץ לגבול) במהלך בדיקה או מסקנות.
ת. SVM מחלקה אחת היא יתרון מכיוון שהוא אינו דורש נתונים מסומנים עבור חריגות במהלך האימון. זה יכול ללמוד ממערך נתונים המכיל רק מופעים רגילים, מה שהופך אותו למתאים לתרחישים שבהם חריגות נדירות ומאתגר להשיג דוגמאות מתויגות לאימון.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.analyticsvidhya.com/blog/2024/03/one-class-svm-for-anomaly-detection/
- :יש ל
- :הוא
- :לֹא
- :איפה
- 01
- 1
- 10
- 100
- 10000
- 12
- 2%
- 20
- 25
- 30
- 35%
- 4
- 40
- 5
- 6
- 9
- a
- יכולת
- לֹא נוֹרמָלִי
- אודות
- פי
- דיוק
- השגתי
- לרוחב
- מותאם
- יתרון
- יתרונות
- מושפע
- משפיע
- המטרה
- מטרות
- אַלגוֹרִיתְם
- להתיר
- מותר
- מאפשר
- מאפשר
- לאורך
- גם
- an
- ו
- גילוי חריגות
- בקשה
- יישומים
- החל
- מתאים
- ARE
- אזורים
- סביב
- מאמר
- AS
- שאל
- זמין
- לְהִמָנַע
- AXS
- b
- בננה
- מבוסס
- בסיס
- BE
- כי
- להיות
- הופך להיות
- התנהגות
- להיות
- שייכות
- הטבות
- מוטב
- בֵּין
- מעבר
- הטיה
- בינרי
- שחור
- כָּחוֹל
- שניהם
- קשור
- אבל
- by
- נקרא
- CAN
- ללכוד
- לכידה
- זהיר
- מקרים
- מרכז
- מרכזים
- מסוים
- ודאות
- אתגר
- מאפיינים
- בחירה
- בחירות
- בחירה
- בכיתה
- כיתות
- מיון
- מְסוּוָג
- מסווג
- CLF
- קרוב יותר
- הכי קרוב
- צֶבַע
- Common
- השוואה
- מורכב
- מַקִיף
- מחשוב
- מרוכז
- מושג
- אמון
- השלכות
- כתוצאה מכך
- שמרני
- רואה
- -
- בונה
- מכיל
- לעומת זאת
- לתרום
- שליטה
- בקרות
- מקובל
- יוצר
- מכריע
- אבטחת סייבר
- כהה
- כהה יותר
- נתונים
- נקודות מידע
- מערכי נתונים
- התמודדות
- החלטה
- בְּרִירַת מֶחדָל
- מחדל
- לְהַגדִיר
- מגדיר
- הגדרה
- תואר
- תלוי
- לאתר
- זוהה
- גילוי
- איתור
- לקבוע
- קובע
- קביעה
- לִסְטוֹת
- אבחון
- נבדלים
- אחר
- ממדים
- ישירות
- לגלות
- לְהַצִיג
- מתעלם
- מובהק
- לְהַבחִין
- הפצה
- שונה
- do
- עושה
- תחומים
- בְּמַהֲלָך
- e
- כל אחד
- השפעה
- יעילות
- יְעִילוּת
- מוּעֳסָק
- עוטף
- מקצה לקצה
- המשוואה
- ציוד
- שגיאה
- שגיאות
- Ether (ETH)
- דוגמה
- דוגמאות
- אך ורק
- תערוכה
- בִּמְפוּרָשׁ
- להאריך
- מאריך
- הקלה
- ליפול
- מקסים
- תקלה
- מאפיין
- פחות
- תאנה
- מציאת
- מתאים
- גמיש
- להתמקד
- מרוכז
- בעד
- צורות
- ניסוח
- ניסוחים
- שבריר
- רמאי
- חופשי
- החל מ-
- גבול
- פונקציה
- פונקציות
- נוסף
- פער
- ליצור
- יצירת
- לקבל
- נתן
- מטרה
- זהב
- יותר
- רֶשֶׁת
- מדריך
- יד
- לטפל
- קשה
- יש
- עוזר
- כאן
- גָבוֹהַ
- גבוה יותר
- איך
- איך
- אולם
- HTTPS
- i
- לזהות
- זיהוי
- if
- מיידי
- ליישם
- מרמז
- לִרְמוֹז
- לייבא
- משפר
- שיפור
- in
- לכלול
- כולל
- משלבת
- עצמאי
- מצביע על
- המציין
- סִימָן
- להשפיע
- קלט
- בתוך
- תובנות
- מקרים
- אל תוך
- כרוך
- IT
- שֶׁלָה
- jpg
- ידוע
- תוויות
- גדול יותר
- האחרון
- לִלמוֹד
- למד
- למידה
- לומד
- עזבו
- פחות
- רמה
- שקר
- קל יותר
- סביר
- גבולות
- באופן ליניארי
- קווים
- לִטעוֹן
- ממוקם
- מיקום
- להוריד
- מכונה
- מכונה
- הרוב
- עשייה
- תקלות
- מַפָּה
- מיפוי
- שולים
- שולי
- matplotlib
- max-width
- לְהַגדִיל
- מעלה
- מקסום
- מקסימום
- מאי..
- למדוד
- שיטה
- יכול
- לצמצם
- מזעור
- מודל
- דוגמנות
- מודלים
- יותר
- רוב
- הרבה
- מספר
- צריך
- שם
- הכרחי
- צורך
- חדש
- רעש
- נוֹרמָלִי
- בייחוד
- רומן
- טרי
- רב
- יתרונות רבים
- קהות
- מטרה
- יעדים
- תצפית
- תצפיות
- להתבונן
- שנצפה
- להשיג
- of
- המיוחדות שלנו
- לקזז
- לעתים קרובות
- on
- רק
- להפעיל
- מול
- אופטימלי
- אופטימיזציה
- מטב
- or
- כָּתוֹם
- מָקוֹר
- מְקוֹרִי
- אחר
- חריג,יוצא דופן
- בחוץ
- מקיף
- זוגות
- פרמטר
- פרמטרים
- במיוחד
- דפוסי
- ביצועים
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- לְשַׂחֵק
- משחק
- עלילה
- נקודה
- נקודות
- פולינום
- מיקום
- פוטנציאל
- נבואה
- מנבא
- מתנות
- בראש ובראשונה
- יְסוֹדִי
- עקרון
- בעיה
- פרופורציה
- מוכיח
- לספק
- אקראי
- רכס
- טווחים
- טִוּוּחַ
- נדיר
- Rbf
- חומר עיוני
- עולם אמיתי
- הכרה
- Red
- מתייחס
- באזור
- אזורים
- נסיגה
- רגיל
- מערכות יחסים
- מסתמך
- לייצג
- נציגות
- מייצג
- לדרוש
- דרישות
- דורש
- מתגורר
- REST
- תוצאות
- הסיכון
- חָסוֹן
- איתנות
- תפקיד
- s
- אותו
- נדיר
- תרחישים
- לִרְאוֹת
- מחפש
- נפרד
- מפריד
- סט
- סטים
- הצבה
- התקנה
- צוּרָה
- צריך
- צד
- משמעותי
- באופן משמעותי
- דומה
- יחיד
- מידה
- רָפוּי
- קטן
- קטן יותר
- רך
- פִּתָרוֹן
- כמה
- לפעמים
- מֶרחָב
- רווחים
- מתמחה
- ספציפי
- במיוחד
- מרובע
- תֶקֶן
- עוד
- סְתִימָה
- עוצר
- מחמיר
- חזק
- מבנים
- כזה
- מַתְאִים
- בפיקוח
- למידה מפוקחת
- תמיכה
- בטוח
- סינטטי
- מותאם
- יעד
- משימות
- טכניקות
- מייגע
- טווח
- מבחן
- בדיקות
- מֵאֲשֶׁר
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- לכן
- אלה
- הֵם
- זֶה
- דרך
- כָּך
- בחוזקה
- ל
- סובלנות
- נִסבָּל
- מסורתי
- רכבת
- הדרכה
- רכבות
- עסקות
- טרנספורמציות
- התמרות
- כונון
- עשרים
- שתיים
- סוג
- בדרך כלל
- לא זמין
- נדיר
- להבין
- לא צפוי
- בניגוד
- us
- להשתמש
- מְשׁוּמָשׁ
- שימושים
- באמצעות
- בעל ערך
- ערך
- ערכים
- משתנה
- משתנים
- גִרְסָה אַחֶרֶת
- שונים
- משתנה
- וקטור
- וקטורים
- מאוד
- הפרות
- מבחינה ויזואלית
- vs
- W
- דֶרֶך..
- we
- מִשׁקָל
- טוֹב
- מה
- מתי
- אם
- אשר
- בזמן
- לבן
- רחב יותר
- יצטרך
- יַיִן
- עם
- בתוך
- לְלֹא
- תיק עבודות
- עובד
- טעות
- X
- xi
- אתה
- זפירנט