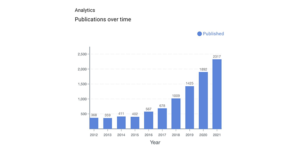
עם שיא גבוה מתוך 9034 עבודות מחקר שהוגשו ל-AAAI 2021 ושיעור קבלה של 21%, הוצגו בכנס בסך הכל 1692 מאמרים. כרגיל, ה פרסי מאמרים מצטיינים ומכובדים ניתנו למסמכים המדגימים את הסטנדרטים הגבוהים ביותר בתרומה טכנית ובתערוכה. כמובן שבכנס הוצגו עוד מאמרים רבים ששווים את תשומת לבכם.
כדי לעזור לך להישאר מודע לפריצות הדרך הבולטות של מחקר AI, ריכזנו כמה ממאמרי המחקר המעניינים ביותר של AAAI 2021 שהוצגו על ידי גוגל, עליבאבא, Baidu וצוותי מחקר מובילים אחרים.
אם תרצה לדלג מסביב, להלן העיתונים שהצגנו:
- Informer: Beyond Efficient Transformer עבור חיזוי סדרת זמן ברצף ארוך
- TabNet: למידה טבלאית קשובה לפירוש
- הדרכה של מסווג מופעים במיליון כיוונים ללימוד ייצוג חזותי ללא פיקוח
- ERNIE-ViL: ייצוגי חזון-שפה משופרים בידע באמצעות גרפי סצנה
- למידה של ייצוג גרפים חיקוי מחוזק עבור פרופיל משתמש בנייד: פרספקטיבה של אימון נגדי
אם תוכן חינוכי מעמיק זה שימושי עבורך, הירשם לרשימת התפוצה של מחקרי AI שלנו להתריע כשאנחנו משחררים חומר חדש.
מאמרי המחקר המובילים של AAAI 2021
1. Informer: Beyond Efficient Transformer עבור חיזוי סדרת זמן ברצף ארוך, מאת Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang
תקציר מקורי
יישומים רבים בעולם האמיתי דורשים חיזוי של סדרות זמן ברצף ארוך, כגון תכנון צריכת חשמל. חיזוי רצף זמן ארוך (LSTF) דורש יכולת חיזוי גבוהה של המודל, שהיא היכולת ללכוד צימוד תלות מדויק לטווח ארוך בין פלט לקלט ביעילות. מחקרים אחרונים הראו את הפוטנציאל של Transformer להגדיל את יכולת החיזוי. עם זאת, ישנן מספר בעיות חמורות עם Transformer שמונעות ממנו להיות ישים ישירות ל-LSTF, כגון מורכבות זמן ריבועית, שימוש גבוה בזיכרון, ומגבלה אינהרנטית של ארכיטקטורת המקודד-מפענח. כדי לטפל בבעיות אלה, אנו מתכננים מודל יעיל מבוסס שנאי עבור LSTF, בשם Informer, עם שלושה מאפיינים בולטים: (i) a probSparse מנגנון קשב עצמי, אשר משיג O(L היכנס L) במורכבות הזמן ובשימוש בזיכרון, ויש לו ביצועים דומים על יישור התלות של רצפים. (ii) זיקוק הקשב העצמי מדגיש את תשומת הלב השולטת על ידי הפחתת קלט שכבה מדורגת בחצי, ומטפל ביעילות ברצפי קלט ארוכים במיוחד. (iii) מפענח הסגנון הגנרטיבי, למרות שהוא פשוט מבחינה קונספטואלית, מנבא את רצפי סדרות הזמן הארוכות בפעולה אחת קדימה ולא דרך צעד אחר צעד, מה שמשפר באופן דרסטי את מהירות ההסקה של תחזיות ברצף ארוך. ניסויים נרחבים בארבעה מערכי נתונים בקנה מידה גדול מוכיחים כי Informer עולה בהרבה על שיטות קיימות ומספקת פתרון חדש לבעיית LSTF.
הסיכום שלנו
ארכיטקטורות השנאים הנוכחיות אינן יעילות עבור חיזוי סדרות זמן ברצף ארוך (LSTF), שבו מודל צריך ללמוד תלות ארוכת טווח של קלט-פלט וגם להציע מהירויות הסקה שאפשריות לניבוי שלבים נוספים לעתיד (למשל, 480 נקודות עבור שיאי טמפרטורה לשעה במשך 20 ימים). כדי להפוך את הארכיטקטורה לאפשרית עבור תשומות עוקבות ארוכות, המחברים הציעו את כנראה תשומת לב עצמית דלילה מנגנון עם O(L היכנס L) מורכבות ולא O(L2) מורכבות, איפה L הוא אורך הרצף. שיטת זיקוק עצמי מוצעת לקנה מידה של הרשת ביעילות לדיוק טוב יותר, עם O((2 − ε)L היכנס L) מורכבות במקום ה O(J · L2) המורכבות של שנאי רגיל, איפה J הוא מספר שכבות השנאים. מפענח בסגנון גנרטיבי מותאם להגברת מהירויות ההסקה בהשוואה לחיזוי צעד אחר צעד של כל נקודה בפלט. השיטה המוצעת מתפקדת טוב יותר מהשיטות הקיימות בחמישה מערכי נתונים בעולם האמיתי עבור משימות כולל חיזוי ETT (טמפרטורת שנאי חשמל), ECL (עומס צורך חשמל) ומזג אוויר.

מה רעיון הליבה של המאמר הזה?
- כנראה תשומת לב עצמית דלילה מוצע לנצל את הדלילות או התפלגות הזנב הארוך של הסתברויות תשומת לב עצמית, כאשר רק כמה משקלי תשומת לב של שאילתות מפתח מניעים את רוב החישוב. ProbSparse משיג O(L היכנס L) מורכבות, משתפרת O(L2).
- כדי להגדיל את המודל על ידי ערימת שכבות שנאים, המחברים הציעו טכניקת זיקוק עצמי תוך שימוש בפעולות קונבולציה ו-max pooling כך שגודל הפלט של השכבה הנוכחית, כלומר גודל הקלט של השכבה הבאה, קטן מגודל הקלט של השכבה הנוכחית. זה משיג O((2 − ε)L היכנס L) מורכבות, לעומת O(J · L2) עבור רובואי כללי.
- לבסוף, כדי להפוך את מהירויות ההסקה לניתנות להרחבה, מוצע מפענח בסגנון גנרטיבי לחזות מספר נקודות לעתיד במעבר אחד קדימה.
מה הישג המפתח?
- השיטה המוצעת משיגה ביצועים מעולים על חמישה מערכי נתונים בעולם האמיתי עבור חיזוי סדרת זמן של רצף ארוך הן חד משתנים והן מרובי משתנים עבור משימות כגון חיזוי ETT (טמפרטורת שנאי חשמל), ECL (עומס צורך חשמל) ומזג אוויר.
מה קהילת AI חושבת?
- העיתון קיבל את פרס הנייר המצטיין ב-AAAI 2021.
מהם יישומים עסקיים אפשריים?
- ניתן להשתמש בגישה המוצעת כדי לחזות רצפים ארוכים, כולל צריכת אנרגיה, מדדי מזג אוויר, מחירי מניות וכו'.
היכן ניתן להשיג קוד יישום?
- היישום המקורי של PyTorch של מאמר זה זמין ב- GitHub.
2. TabNet: למידה טבלאית קשובה לפירוש, מאת סרקן או. אריק ותומס פפיסטר
תקציר מקורי
אנו מציעים ארכיטקטורת למידת נתונים טבלאית קנונית בעלת ביצועים גבוהים וניתנת לפירוש, TabNet. TabNet משתמשת בתשומת לב רציפה כדי לבחור מאילו תכונות לנמק בכל שלב החלטה, מה שמאפשר פרשנות ולמידה יעילה יותר כאשר כושר הלמידה משמש לתכונות הבולטות ביותר. אנו מדגימים ש-TabNet מתעלה על גרסאות אחרות של רשתות עצביות ושל עצי החלטות במגוון רחב של מערכי נתונים טבלאיים שאינם רווי ביצועים ומניב ייחוס תכונות הניתנות לפירוש בתוספת תובנות לגבי התנהגות המודל העולמי. לבסוף, בפעם הראשונה למיטב ידיעתנו, אנו מדגימים למידה בפיקוח עצמי עבור נתונים טבלאיים, ומשפרים משמעותית את הביצועים עם למידת ייצוג ללא פיקוח כאשר נתונים ללא תווית יש בשפע.
הסיכום שלנו
צוות Google Cloud AI מטפל בבעיה של יישום רשתות עצביות עמוקות עבור נתונים טבלאיים. בעוד שרשתות עצביות עמוקות זוהרות בחילוץ אוטומטי של תכונות ולמידה מקצה לקצה, היעדר הטיה אינדוקטיבית ליצירת מודלים של גבולות החלטת הפלט הרווחים בנתונים טבלאיים והיעדר ניתנות לפירוש מגבילים את האימוץ הנרחב של רשתות עצביות עמוקות עבור טבלאות. נתונים. המחברים מתכננים מנגנון קשב רציף לבחירת קבוצת משנה של תכונות לעיבוד בכל שלב. זה משפר את יעילות הלמידה ואת יכולת הפרשנות על ידי הדגמת ההיגיון בכל שלב, בדומה לעץ החלטות. בחירת התכונה נעשית עבור כל מופע כדי להגדיל את ביצועי המודל עם יותר נתונים. אימון מקדים ללא פיקוח משמש גם כדי להגביר את הביצועים עם משימה של חיזוי ערכי המסכה בשורות שונות של עמודות שונות. מודל ה-TabNet המוצע מתפקד טוב יותר או שווה לשיטות הסטנדרטיות לנתונים טבלאיים תוך ביטול שלבי בחירת הפיצ'רים ושלבי הנדסת התכונות.
מה רעיון הליבה של המאמר הזה?
- תכנון מנגנון קשב רציף שמטפל רק בתת-קבוצה של תכונות תוך מיסוך האחרות בכל שלב לפני העיבוד. זה עוזר בלמידה יעילה, שכן המודל מעבד רק תכונות בולטות, וגם עם ניתנות לפירוש, מכיוון שניתן לנתח את שלבי ההיגיון בהתבסס על התכונות שנבחרו.
- הוכח כי אימון מקדים ללא פיקוח מועיל בהגברת הביצועים של המודל על ידי חיזוי ערכי מסיכה. ביצועים מוגברים זה אינם בהישג ידם של דגמי ML מסורתיים, מכיוון שלא ניתן היה להכשיר אותם מראש בצורה ללא פיקוח.

מה הישג המפתח?
- ניסויים מראים שהשיטה המוצעת, TabNet, מתפקדת טוב או טוב יותר ממודלים טבלאיים מבוססים על חמישה מערכי נתונים בעולם האמיתי תוך התמודדות עם חששות הפרשנות.
מהם יישומים עסקיים אפשריים?
- הגישה יכולה להיות שימושית עבור כל יישום שעובד עם נתונים טבלאיים, שהוא כנראה סוג הנתונים הנפוץ ביותר ביישומי למידת מכונה בעולם האמיתי.
היכן ניתן להשיג קוד יישום?
- היישום של PyTorch של מאמר זה זמין ב- GitHub.
3. הדרכה של מסווג מופעים במיליון כיוונים ללימוד ייצוג חזותי ללא פיקוח, מאת Yu Liu, Lianghua Huang, Pan Pan, Bin Wang, Yinghui Xu, Rong Jin
תקציר מקורי
מאמר זה מציג שיטת למידה פשוטה של ייצוג חזותי ללא פיקוח עם משימת עילה של הבחנה בין כל התמונות במערך נתונים באמצעות מסווג פרמטרי ברמת המופע. המסגרת הכוללת היא העתק של מודל סיווג מפוקח, שבו מחלקות סמנטיות (למשל, כלב, ציפור וספינה) מוחלפות במזהי מופע. עם זאת, הגדלה של משימת הסיווג מאלפי תוויות סמנטיות למיליוני תוויות מופע מביאה לאתגרים ספציפיים כולל 1) חישוב softmax בקנה מידה גדול; 2) ההתכנסות האיטית עקב ביקור נדיר של דגימות מופעים; ו-3) המספר העצום של מחלקות שליליות שיכולות להיות רועשות. עבודה זו מציגה מספר טכניקות חדשות להתמודדות עם קשיים אלה. ראשית, אנו מציגים מסגרת אימון מקבילה היברידית כדי להפוך אימון בקנה מידה גדול למעשי. שנית, אנו מציגים מנגנון אתחול של תכונות גולמיות עבור משקלי סיווג, שאנו מניחים שמציע אבחנה קודמת ניגודית, למשל, ויכול להאיץ בבירור את ההתכנסות בניסויים שלנו. לבסוף, אנו מציעים להחליק את התוויות של כמה מחלקות קשות ביותר כדי להימנע מאופטימיזציה על פני זוגות שליליים דומים מאוד. למרות היותה פשוטה מבחינה רעיונית, המסגרת שלנו משיגה ביצועים תחרותיים או מעולים בהשוואה לגישות ללא פיקוח מתקדמות, כלומר SimCLR, MoCoV2 ו-PIC תחת פרוטוקול הערכה ליניארי של ImageNet ובמספר משימות חזותיות במורד הזרם, המאמת שסיווג מופעים מלא הוא טכניקת אימון מקדים חזקה למשימות ויזואליות סמנטיות רבות.
הסיכום שלנו
למידת ייצוג ללא פיקוח הוכיחה את עצמה כמועילה כאשר יש לנו הרבה נתונים אך מעט תוויות או כאשר המשימה עדיין לא מוגדרת במלואה. צוות המחקר של עליבאבא מטפל בבעיה של למידה חלקה של ייצוג ללא פיקוח ללא צורך ביצירת זוגות שליליים או פונקציות אובייקטיביות חדשות. השיטה המוצעת מתייחסת למידת ייצוג ללא פיקוח כאל משימת סיווג מפוקחת ברמת המופע, מה שמרמז שלכל התמונות מוקצית מחלקה ייחודית ו- nמודל סיווג דרך מאומן, היכן n הוא המספר הכולל של תמונות במערך הנתונים. המחברים גם הציעו טכניקות חדשות להתמודדות עם משימת הסיווג בקנה מידה גדול זה, כולל מודלים של טכניקות מקבילות לחישוב softmax, טכניקה לגרימת קוד ניגודי וטכניקה להחלקת אמיתות הקרקע של מחלקות שליליות דומות מאוד. השיטה גוברת על מודלים חדישים קודמים ללמידת ייצוג ללא פיקוח כגון SimCLR ו-PIC.

מה רעיון הליבה של המאמר הזה?
- התייחסות ללמידה של ייצוג ללא פיקוח כמשימת סיווג בקנה מידה גדול של מופעים.
- הצעת טכניקות חדשות לטיפול במשימות סיווג בקנה מידה גדול:
- הצגת מסגרת אימון מקבילה היברידית עבור מחשוב פעולת softmax במכשירים שונים;
- גרימת קוד ניגודי על ידי הצגת מנגנון אתחול של תכונות גולמיות עבור משקלי סיווג (כלומר, המשקולות מאותחלות עם תכונות המופע שחולצו על ידי הפעלת עידן היסק, כאשר המודל הוא רשת עצבית אקראית קבועה עם שכבות נורמליזציה אצווה בלבד מאומנים);
- החלקת אמיתות הקרקע של מעמדות שליליים דומים מאוד.
מה הישג המפתח?
- עבודה זו המציאה שיטה חדשה, פשוטה ויעילה ללמידת ייצוג ללא פיקוח ללא שימוש בזוגות שליליים בלמידה ניגודית ברמת הכיתה או בגדלים גדולים של אצווה כדי להפחית את דליפת הנתונים בלמידה ניגודית ברמת המופע.
מהם יישומים עסקיים אפשריים?
- ניתן להשתמש בשיטה זו כדי לאסוף תמונות ללא תווית, מה שבתורו מקל על חיפוש תמונות דומות ותיוג תמונות עבור מערכות ארכיון תמונות.
4. ERNIE-ViL: ייצוגי חזון-שפה משופרים בידע באמצעות גרפי סצנה, מאת Fei Yu, Jiji Tang, Weichong Yin, Yu Sun, Hao Tian, Hua Wu, Haifeng Wang
תקציר מקורי
אנו מציעים גישה משופרת בידע, ERNIE-ViL, המשלבת ידע מובנה המתקבל מגרפים של סצנה כדי ללמוד ייצוגים משותפים של שפת חזון. ERNIE-ViL מנסה לבנות את הקשרים הסמנטיים המפורטים (אובייקטים, תכונות של אובייקטים ויחסים בין אובייקטים) על פני חזון ושפה, החיוניים למשימות חוצות שפות חזון-שפות. תוך שימוש בגרפי סצנה של סצנות חזותיות, ERNIE-ViL בונה משימות חיזוי גרף סצינה, כלומר, משימות חיזוי אובייקט, חיזוי תכונות וחיזוי יחסים בשלב הקדם-אימון. באופן ספציפי, משימות חיזוי אלו מיושמות על ידי חיזוי צמתים מסוגים שונים בגרף הסצנה המנותח מהמשפט. לפיכך, ERNIE-ViL יכול ללמוד את הייצוגים המשותפים המאפיינים את היישורים של הסמנטיקה המפורטת על פני חזון ושפה. לאחר אימון מקדים על מערכי נתונים מיושרים לטקסט תמונה בקנה מידה גדול, אנו מאמתים את האפקטיביות של ERNIE-ViL ב-5 משימות חוצות-מודאליות במורד הזרם. ERNIE-ViL משיגה ביצועים עדכניים בכל המשימות הללו ומדרגת את המקום הראשון בטבלת ה-VCR עם שיפור מוחלט של 3.7%.
הסיכום שלנו
בעבודה זו, צוות המחקר של Baidu ניסה לפתור את היישור של מושגים סמנטיים במרחב החזותי והלשוני, כך שהמודלים מבצעים ביצועים טובים יותר במשימות רב-מודאליות הדורשות חשיבה פיזית של שכל ישר (למשל, חשיבה חזותית ותשובות לשאלות חזותיות). המחברים שאפו לתת למודלים ידע מובנה יותר על הסצנות על ידי אימון מקדים של המודלים לחזות באופן מפורש אובייקטים, תכונותיהם ויחסי אובייקט-אובייקט. עם תמונה וטקסט תואם, במקום להסוות ולחזות אסימונים אקראיים בטקסט, המחברים השתמשו בניתוח גרף סצנה ובאסימונים ממוסכים שייצגו באופן ספציפי אובייקטים, תכונותיהם ויחסי אובייקט-אובייקט. המודל הוכשר מראש לחזות את האסימונים המסוכים בטקסט שניתן תמונה. הגישה שהוצגה השיגה תוצאות מתקדמות במערכי נתונים רב-מודאליים לאחזור טקסט ואחזור תמונות וכן דורגה במקום הראשון בטבלת משימות ה-VCR עם שיפור של 3.7% בהשוואה לפתרון הבא הטוב ביותר.
מה רעיון הליבה של המאמר הזה?
- בדומה למידול שפת מסכות דמוי BERT, מודלים של כיתוב תמונה מאומנים לחזות את האסימונים המסוכים בכיתוב תמונה בהינתן התמונה ואסימונים אחרים. הרעיון המרכזי של מאמר זה הוא להסוות באופן סלקטיבי את האסימונים במקום להסוות אותם באופן אקראי.
- בגישה זו, רק האסימונים המייצגים ישויות עשירות מבחינה סמנטית כגון אובייקטים, תכונות של אובייקט ויחסי אובייקט-אובייקט מוסווים. זה משיג יישור סמנטי טוב יותר בין טקסט לתמונות מכיוון שכל הלמידה מתמקדת באסימונים עשירים מבחינה סמנטית בכיתוב תמונה.

מה הישג המפתח?
- קבלת ביסוס טוב יותר של הישויות הטקסטואליות הסמנטיות במרחב החזותי.
- השגת מצבים מתקדמים מביאה לשחזור תמונה/טקסט ומשימות חשיבה חזותית של הגיון בריא.
מהם תחומי מחקר עתידיים?
- שילוב גרפים של סצנה שחולצו מתמונות באימון מקדים חוצה-מודאלי.
- שימוש ברשתות עצביות גרפיות לייצוג תמונות וטקסט.
מהם יישומים עסקיים אפשריים?
- יישור טוב יותר של מושגים סמנטיים ייתן תוצאות טובות יותר לאחזור תמונה עם טקסט, כיתוב תמונה, מענה על שאלות חזותיות וחיזוי פעולות עתידיות.
5. למידה של ייצוג גרפים חיקוי מחוזק עבור פרופיל משתמש בנייד: פרספקטיבה של אימון נגדי, מאת Dongjie Wang, Pengyang Wang, Kunpeng Liu, Yuanchun Zhou, Charles Hughes, Yanjie Fu
תקציר מקורי
במאמר זה אנו חוקרים את הבעיה של פרופיל משתמש נייד, שהוא מרכיב קריטי לכימות מאפייני המשתמשים בצנרת המודלים של ניידות אנושית. ניידות אנושית היא תהליך קבלת החלטות רציף התלוי בתחומי העניין הדינמיים של המשתמשים. עם פרופילי משתמש מדויקים, המודל החזוי יכול לשחזר בצורה מושלמת את מסלולי הניידות של המשתמשים. בכיוון ההפוך, ברגע שהמודל החזוי יכול לחקות את דפוסי הניידות של המשתמשים, גם פרופילי המשתמש הנלמדים הם אופטימליים. אינטואיציה כזו מניעה אותנו להציע מסגרת מבוססת חיקוי לפרופיל משתמש נייד על ידי ניצול למידת חיזוק, שבה הסוכן מאומן לחקות במדויק את דפוסי הניידות של המשתמשים לפרופילי משתמשים אופטימליים. באופן ספציפי, המסגרת המוצעת כוללת שני מודולים: (1) מודול ייצוג, המייצר מצב המשלב פרופילי משתמש והקשר מרחבי-זמני בזמן אמת; (2) מודול חיקוי, שבו Deep Q-network (DQN) מחקה את התנהגות המשתמש (פעולה) בהתבסס על המצב שמיוצר על ידי מודול הייצוג. עם זאת, ישנם שני אתגרים בהפעלת המסגרת בצורה יעילה. ראשית, אסטרטגיית חמדנות אפסילון ב-DQN עושה שימוש בהחלפת חקר-ניצול על ידי בחירה אקראית של פעולות עם הסתברות אפסילון. אקראיות כזו מחזירה למודול הייצוג, וגורמת לפרופילי המשתמשים הנלמדים ללא יציבים. כדי לפתור את הבעיה, אנו מציעים אסטרטגיית אימון יריבות כדי להבטיח את חוסנו של מודול הייצוג. שנית, מודול הייצוג מעדכן את פרופילי המשתמשים באופן מצטבר, המחייב שילוב ההשפעות הזמניות של פרופילי המשתמש. בהשראת זיכרון לטווח קצר (LSTM), אנו מציגים מנגנון סגור לשילוב מאפייני משתמש חדשים וישנים בפרופיל המשתמש.
הסיכום שלנו
פרופיל משתמש טוב יותר לנייד שיוכל לחזות במדויק לאן המשתמש הולך הבא יעזור בהתאמה אישית טובה יותר של תכונות ומודעות של עוזר וירטואלי עבור שירותים רלוונטיים, בין שאר מקרי השימוש. מודלים של התנהגות משתמשים מנתוני עבר והשגת פרופיל משתמש בנייד מציבים הרבה אתגרים, כולל האינטרסים הדינמיים של המשתמשים המשתנים עם הזמן והקושי לעצב את ההקשר המרחבי-זמני של ניידות בזמן אמת. עבודה זו מטפלת בבעיה של פרופיל משתמש נייד על ידי בניית סוכן המופעל על למידה חיזוקית (RL) שיכול לחקות החלטות של משתמש, כלומר לחזות את הצעדים הבאים שלו במדויק. המחברים השיגו פרופיל משתמש נייד מדויק על ידי חיזוי מדויק של התנהגות המשתמש מכיוון שכפי שפרופיל משתמש מדויק מנבא את ההתנהגות העתידית של המשתמש, חיזוי מדויק של ההתנהגות העתידית של המשתמש משיג גם פרופיל נייד מדויק. השיטה המוצעת משיגה תוצאות מעולות בהשוואה לשיטות הקיימות בשני מערכי נתונים בעולם האמיתי שנאספו מניו יורק ובייג'ין.
מה רעיון הליבה של המאמר הזה?
- כדי לחזות התנהגות משתמש עתידית, המחברים מציגים שיטת למידה חיקוי המופעלת על ידי RL המכונה למידת ייצוג חיקוי לחיזוק (RIRL). למידת חיקוי מושגת באמצעות אימון יריב שבו מחולל, הסוכן המחקה, מנבא את התנהגות המשתמש ומפלה מנסה ללמוד להבחין איזו התנהגות חוזה על ידי המחולל ואיזו מתוך הנתונים בעולם האמיתי. הסוכן המחקה חוזה את התנהגות המשתמש העתידית במדויק לאחר הכשרת המחולל והמבדיל.
- רשתות עצביות גרפיות משמשות כדי לייצג את הטבע המרחבי-זמני של התנהגות המשתמשים בנייד, וזה עדיף על קידוד זה כרצף או רק כרשימה של מקומות שביקרו בהם.
- גרסת RNN בהשראת זיכרון קצר טווח ארוך (LSTM) נוצרה ומשמשת למודל של האופי הדינמי של תחומי עניין של המשתמשים עם מנגנון שער לשמר רק את המידע הרלוונטי מהעבר. וקטור המצב עבור סוכן החיקוי RL נוצר עם ייצוגים מוריאנט RNN זה ורשתות עצביות גרפיות.

מה הישג המפתח?
- פרופיל משתמש טוב יותר בנייד על ידי חיזוי התנהגות משתמש עתידית באמצעות סוכן חיקוי המופעל על ידי RL, מאומן באופן יריב.
- תוצאות טובות יותר משיטות קיימות במספר מערכי נתונים בעולם האמיתי.
מהם יישומים עסקיים אפשריים?
- חיזוי מדויק לאן יגיע אדם אחר פותח קבוצה מעניינת של יישומים עסקיים כמו:
- המלצה על הצעות, מסעדות או שירותים על סמך המיקום;
- תכונות עוזר וירטואלי מותאמות אישית טוב יותר;
- אוטומציה של משימות שימושיות באמצעות מכשירי IoT בבית רגע לפני שהמשתמש חוזר הביתה.
נהנים מהמאמר הזה? הירשם לעדכוני מחקר AI נוספים.
נודיע לך כשנפרסם מאמרים נוספים בנושא זה.
מוצרים מקושרים
- מוּחלָט
- פעולה
- אימוץ
- מודעות
- יתרון
- AI
- ai מחקר
- Alibaba
- בין
- יישומים
- ארכיטקטורה
- סביב
- מאמר
- מאמרים
- עוזר
- מחברים
- Baidu
- בייג'ינג
- הטוב ביותר
- ציפור
- לִבנוֹת
- בִּניָן
- עסקים
- יישומים עסקיים
- קיבולת
- מקרים
- צ'ארלס
- מיון
- ענן
- קוד
- Common
- קהילה
- רְכִיב
- מחשוב
- כנס
- חיבורי
- צְרִיכָה
- תוכן
- נוֹכְחִי
- נתונים
- עסקה
- התמודדות
- עץ החלטות
- רשתות עצביות עמוקות
- עיצוב
- התקנים
- אפליה
- חינוך
- יְעִילוּת
- חשמל
- צריכת חשמל
- אנרגיה
- הנדסה
- וכו '
- הוֹצָאָה
- מאפיין
- מומלצים
- תכונות
- פיי
- בסופו של דבר
- ראשון
- firsttime
- קדימה
- מסגרת
- מלא
- עתיד
- כללי
- נתינה
- גלוֹבָּלִי
- Google Cloud
- גרף רשתות עצביות
- Halving
- כאן
- גָבוֹהַ
- עמוד הבית
- HTTPS
- היברידי
- רעיון
- תמונה
- אימג'נט
- כולל
- להגדיל
- מידע
- תובנות
- אינטואיציה
- IOT
- מכשירי יוט
- בעיות
- IT
- מפתח
- ידע
- תוויות
- שפה
- גָדוֹל
- מוביל
- לִלמוֹד
- למד
- למידה
- רשימה
- לִטעוֹן
- מיקום
- ארוך
- למידת מכונה
- הרוב
- מסכה
- ML
- סלולרי
- ניידות
- מודל
- דוגמנות
- רשת
- רשתות
- עצביים
- רשת עצבית
- רשתות עצביות
- ניו יורק
- צמתים
- הַצָעָה
- המיוחדות שלנו
- נפתח
- תפעול
- אחר
- אחרים
- פאן
- מאמר
- ביצועים
- התאמה אישית
- תכנון
- נבואה
- התחזיות
- להציג
- מיוצר
- פּרוֹפִיל
- פרופילים
- להציע
- פיטורך
- רכס
- זמן אמת
- רשום
- למידה חיזוק
- מערכות יחסים
- מחקר
- מסעדות
- תוצאות
- להפוך
- ריצה
- סולם
- דרוג
- בצורה חלקה
- חיפוש
- נבחר
- סמנטיקה
- תחושה
- שירותים
- סט
- לזרוח
- פָּשׁוּט
- מידה
- So
- לפתור
- מֶרחָב
- מְהִירוּת
- תקנים
- מדינה
- להשאר
- מניות
- אִסטרָטֶגִיָה
- מחקרים
- לימוד
- הוגש
- מערכות
- טכני
- העתיד
- המקום
- זמן
- מטבעות
- חלק עליון
- הדרכה
- מטפלת
- עדכונים
- us
- משתמשים
- וירטואלי
- עוזר וירטואלי
- חזון
- תיק עבודות
- ראוי
- wu