ארגונים בחרו לבנות עליהם אגמי נתונים שירות אחסון פשוט של אמזון (Amazon S3) במשך שנים רבות. אגם נתונים הוא הבחירה הפופולרית ביותר עבור ארגונים לאחסן את כל הנתונים הארגוניים שלהם שנוצרו על ידי צוותים שונים, על פני תחומים עסקיים, מכל הפורמטים השונים, ואפילו במהלך ההיסטוריה. לפי מחקר, החברה הממוצעת רואה את נפח הנתונים שלה גדל בקצב העולה על 50% בשנה, בדרך כלל מנהלת בממוצע 33 מקורות נתונים ייחודיים לניתוח.
צוותים מנסים לעתים קרובות לשכפל אלפי עבודות מבסיסי נתונים יחסיים עם אותה דפוס חילוץ, טרנספורמציה וטעינה (ETL). יש מאמץ רב בשמירה על מצבי התפקיד ובתזמון משרות בודדות אלו. גישה זו עוזרת לצוותים להוסיף טבלאות עם מעט שינויים וגם שומרת על מצב התפקיד במינימום מאמץ. זה יכול להוביל לשיפור עצום בציר הזמן של הפיתוח ולמעקב אחר העבודות בקלות.
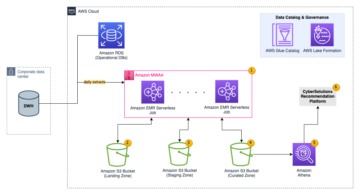
בפוסט זה, אנו מראים לך כיצד לשכפל בקלות את כל מאגרי הנתונים הרלוונטיים שלך לתוך אגם נתונים עסקה באופן אוטומטי עם עבודת ETL אחת באמצעות Apache Iceberg ו דבק AWS.
ארכיטקטורת הפתרונות
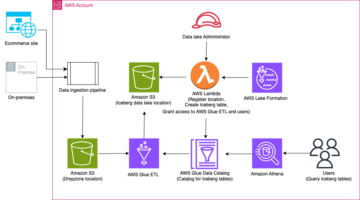
אגמי נתונים הם מאורגן בדרך כלל שימוש בדלי S3 נפרדים עבור שלוש שכבות של נתונים: השכבה הגולמית המכילה נתונים בצורתו המקורית, שכבת השלב המכילה נתונים מעובדים ביניים אופטימליים לצריכה, ושכבת האנליטיקה המכילה נתונים מצטברים עבור מקרי שימוש ספציפיים. בשכבה הגולמית, טבלאות בדרך כלל מאורגנות על סמך מקורות הנתונים שלהן, ואילו טבלאות בשכבת השלב מאורגנות על סמך התחומים העסקיים שאליהם הם שייכים.
פוסט זה מספק א AWS CloudFormation תבנית הפורסת עבודת דבק AWS שקוראת נתיב Amazon S3 עבור מקור נתונים אחד של שכבת אגם הנתונים הגולמית, ומכניסה את הנתונים לטבלאות Apache Iceberg בשכבת הבמה באמצעות תמיכה ב-AWS Glue עבור מסגרות אגם נתונים. התפקיד מצפה שטבלאות בשכבה הגולמית יהיו בנויות בצורה שירות העברת מסדי נתונים של AWS (AWS DMS) קולט אותם: סכימה, ואז טבלה, ואז קבצי נתונים.
פתרון זה משתמש חנות פרמטרים של מנהל מערכות AWS עבור תצורת טבלה. עליך לשנות פרמטר זה ולציין את הטבלאות שברצונך לעבד וכיצד, כולל מידע כגון מפתח ראשי, מחיצות והדומיין העסקי המשויך. העבודה משתמשת במידע זה כדי ליצור באופן אוטומטי מסד נתונים (אם הוא עדיין לא קיים) לכל תחום עסקי, ליצור את טבלאות Iceberg ולבצע את טעינת הנתונים.
לבסוף, אנו יכולים להשתמש אמזונה אתנה כדי לשאול את הנתונים בטבלאות Iceberg.
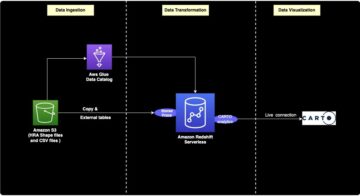
התרשים הבא ממחיש ארכיטקטורה זו.

ליישום זה יש את השיקולים הבאים:
- לכל הטבלאות ממקור הנתונים חייב להיות מפתח ראשי כדי להיות משוכפל באמצעות פתרון זה. המפתח הראשי יכול להיות עמודה בודדת או מפתח מורכב עם יותר מעמודה אחת.
- אם אגם הנתונים מכיל טבלאות שאינן זקוקות להעלאות או שאין להן מפתח ראשי, אתה יכול לא לכלול אותן מתצורת הפרמטרים וליישם תהליכי ETL מסורתיים כדי להטמיע אותם לתוך אגם הנתונים. זה מחוץ לתחום הפוסט הזה.
- אם יש מקורות נתונים נוספים שצריך להטמיע, אתה יכול לפרוס ערימות CloudFormation מרובות, אחת כדי לטפל בכל מקור נתונים.
- עבודת הדבק של AWS נועדה לעבד נתונים בשני שלבים: הטעינה הראשונית שפועלת לאחר ש-AWS DMS מסיימת את משימת הטעינה המלאה, והעומס המצטבר שפועל לפי לוח זמנים שמחיל קבצי לכידת נתונים שינויים (CDC) שנלכדו על ידי AWS DMS. עיבוד מצטבר מתבצע באמצעות an סימניה לעבודת דבק של AWS.
יש תשעה שלבים להשלמת הדרכה זו:
- הגדר נקודת קצה מקור עבור AWS DMS.
- פרוס את הפתרון באמצעות AWS CloudFormation.
- סקור את משימת השכפול של AWS DMS.
- לחלופין, הוסף הרשאות להצפנה ופענוח או תצורת אגם AWS.
- סקור את תצורת הטבלה ב-Parameter Store.
- בצע טעינת נתונים ראשונית.
- בצע טעינת נתונים מצטברים.
- עקוב אחר צריכת הטבלה.
- תזמן טעינת נתוני אצווה מצטברים.
תנאים מוקדמים
לפני שתתחיל את המדריך הזה, אתה כבר צריך להכיר את Iceberg. אם אתה לא, אתה יכול להתחיל על ידי שכפול טבלה בודדת לפי ההוראות ב הטמע UPSERT מבוסס CDC באגם נתונים באמצעות Apache Iceberg ו-AWS Glue. בנוסף, הגדר את הדברים הבאים:
הגדר נקודת קצה מקור עבור AWS DMS
לפני שניצור את משימת ה-AWS DMS שלנו, עלינו להגדיר נקודת קצה מקור שתתחבר למסד הנתונים של המקור:
- במסוף AWS DMS, בחר נקודות קצה בחלונית הניווט.
- לבחור צור נקודת קצה.
- אם מסד הנתונים שלך פועל על Amazon RDS, בחר בחר מופע RDS DB, ולאחר מכן בחר את המופע מהרשימה. אחרת, בחר את מנוע המקור וספק את מידע החיבור או דרך מנהל סודות AWS או באופן ידני.
- בעד מזהה נקודת קצה, הזן שם עבור נקודת הקצה; לדוגמה, source-postgresql.
- לבחור צור נקודת קצה.
פרוס את הפתרון באמצעות AWS CloudFormation
צור ערימת CloudFormation באמצעות התבנית המסופקת. השלם את השלבים הבאים:
- לבחור עריכת השקה:

- לבחור הַבָּא.
- ספק שם מחסנית, כגון
transactionaldl-postgresql. - הזן את הפרמטרים הנדרשים:
- DMSS3EndpointIAMRoleARN - תפקיד IAM ARN עבור AWS DMS לכתוב נתונים לתוך Amazon S3.
- ReplicationInstanceArn – מופע שכפול AWS DMS ARN.
- S3BucketStage – שם הדלי הקיים המשמש לשכבת הבמה של אגם הנתונים.
- S3BucketGlue – שם הדלי S3 הקיים לאחסון סקריפטים של AWS Glue.
- S3BucketRaw – שם הדלי הקיים המשמש לשכבה הגולמית של אגם הנתונים.
- SourceEndpointArn – נקודת הקצה של AWS DMS ARN שיצרת קודם לכן.
- סורנסנאם - המזהה השרירותי של מקור הנתונים לשכפול (לדוגמה,
postgres). זה משמש להגדרת נתיב S3 של אגם הנתונים (שכבה גולמית) שבו הנתונים יאוחסנו.
- אל תשנה את הפרמטרים הבאים:
- SourceS3BucketBlog - שם הדלי שבו מאוחסן סקריפט AWS Glue שסופק.
- SourceS3BucketPrefix – שם הקידומת של הדלי שבו מאוחסן סקריפט AWS Glue שסופק.
- לבחור הַבָּא פעמיים.
- בחר אני מאשר ש- AWS CloudFormation עשוי ליצור משאבי IAM עם שמות מותאמים אישית.
- לבחור צור ערימה.
לאחר כ-5 דקות, ערימת CloudFormation נפרסת.
סקור את משימת השכפול של AWS DMS
פריסת AWS CloudFormation יצרה עבורך נקודת קצה יעד של AWS DMS. בגלל שתי הגדרות ספציפיות של נקודות קצה, הנתונים ייקלטו כפי שאנו צריכים אותם ב-Amazon S3.
- במסוף AWS DMS, בחר נקודות קצה בחלונית הניווט.
- חפש ובחר את נקודת הקצה שמתחילה בה
dmsIcebergs3endpoint. - סקור את הגדרות נקודת הקצה:
DataFormatמוגדר כ-parquet.TimestampColumnNameיוסיף את העמודהlast_update_timeעם תאריך יצירת הרשומות באמזון S3.

הפריסה גם יוצרת משימת שכפול AWS DMS שמתחילה ב dmsicebergtask.
- לבחור משימות שכפול בחלונית הניווט וחפש את המשימה.
אתה תראה ש סוג משימה מסומן כ עומס מלא, שכפול מתמשך. AWS DMS תבצע טעינה מלאה ראשונית של נתונים קיימים, ולאחר מכן תיצור קבצים מצטברים עם שינויים שבוצעו במסד הנתונים של המקור.
על כללי מיפוי בכרטיסייה, ישנם שני סוגים של כללים:
- כלל בחירה עם שם סכימת המקור וטבלאות שיוכנסו ממסד הנתונים של המקור. כברירת מחדל, הוא משתמש במסד הנתונים לדוגמה שסופק בדרישות המוקדמות,
dms_sample, וכל הטבלאות עם מילת המפתח %. - שני כללי טרנספורמציה הכוללים בקבצי היעד באמזון S3 את שם הסכימה ושם הטבלה כעמודות. זה משמש את עבודת ה- AWS Glue שלנו כדי לדעת לאילו טבלאות תואמים הקבצים באגם הנתונים.
למידע נוסף על איך להתאים אישית את זה עבור מקורות הנתונים שלך, עיין ב כללי בחירה ופעולות.

בואו נשנה כמה תצורות כדי לסיים את הכנת המשימה שלנו.
- על פעולות בתפריט, בחר שינוי.
- ב הגדרות משימה סעיף, תחת עצור את המשימה לאחר סיום הטעינה המלאה, בחר עצור לאחר החלת שינויים בקובץ השמור.
בדרך זו, נוכל לשלוט בעומס הראשוני וביצירת הקבצים המצטברים בשני שלבים שונים. אנו משתמשים בגישה הדו-שלבית הזו כדי להפעיל את עבודת הדבק של AWS פעם אחת בכל שלב.
- תַחַת יומני משימות, בחר הפעל את יומני CloudWatch.
- לבחור שמור.
- המתן כדקה אחת עד שסטטוס משימת העברת מסד הנתונים יופיע בתור מוכן.
הוסף הרשאות להצפנה ופענוח או יצירת אגם
לחלופין, אתה יכול להוסיף הרשאות להצפנה ופענוח או להיווצרות אגם.
הוסף הרשאות הצפנה ופענוח
אם דלי ה-S3 שלך המשמשים לשכבות הגולמיות והשלבים מוצפנים באמצעות שירות ניהול מפתח AWS (AWS KMS) מפתחות מנוהלים על ידי לקוחות, עליך להוסיף הרשאות כדי לאפשר לעבודת הדבק של AWS לגשת לנתונים:
הוסף הרשאות Lake Formation
אם אתה מנהל הרשאות באמצעות Lake Formation, עליך לאפשר לעבודת AWS Glue שלך ליצור את מסדי הנתונים והטבלאות של הדומיין שלך באמצעות תפקיד IAM GlueJobRole.
- הענק הרשאות ליצירת מסדי נתונים (להנחיות, עיין יצירת מסד נתונים).
- הענק הרשאות SUPER ל-
defaultמאגר מידע. - הענק הרשאות מיקום נתונים.
- אם אתה יוצר מסדי נתונים באופן ידני, הענק הרשאות לכל מסדי הנתונים ליצור טבלאות. מתייחס הענקת הרשאות טבלה באמצעות קונסולת Lake Formation ושיטת המשאב הנקראת or הענקת הרשאות קטלוג נתונים בשיטת LF-TBAC לפי מקרה השימוש שלך.
לאחר השלמת השלב המאוחר יותר של ביצוע טעינת הנתונים הראשונית, הקפד להוסיף גם הרשאות לצרכנים לבצע שאילתות בטבלאות. תפקיד התפקיד יהפוך לבעלים של כל הטבלאות שנוצרו, ואז מנהל אגם הנתונים יוכל לבצע מענקים למשתמשים נוספים.
סקור את תצורת הטבלה ב-Parameter Store
עבודת AWS Glue שמבצעת את הטמעת הנתונים בטבלאות Iceberg משתמשת במפרט הטבלה המסופק ב- Parameter Store. השלם את השלבים הבאים כדי לסקור את מאגר הפרמטרים שהוגדר עבורך באופן אוטומטי. במידת הצורך, שנה בהתאם לצרכים שלך.
- במסוף הפרמטרים, בחר הפרמטרים שלי בחלונית הניווט.
מחסנית CloudFormation יצרה שני פרמטרים:
iceberg-configעבור תצורות עבודהiceberg-tablesעבור תצורת טבלה
- בחר את הפרמטר קרחונים-שולחנות.
מבנה JSON מכיל מידע שבו משתמש AWS Glue כדי לקרוא נתונים ולכתוב את טבלאות Iceberg בדומיין היעד:
- חפץ אחד לכל שולחן – שם האובייקט נוצר באמצעות שם הסכימה, נקודה ושם הטבלה; לדוגמה,
schema.table. - מפתח ראשי – יש לציין זאת עבור כל טבלת מקור. אתה יכול לספק עמודה בודדת או רשימה של עמודות מופרדות בפסיקים (ללא רווחים).
- partitionCols - אפשרות זו מחלקת עמודות עבור טבלאות יעד. אם אינך רוצה ליצור טבלאות מחולקות, ספק מחרוזת ריקה. אחרת, ספק עמודה בודדת או רשימה מופרדת בפסיקים של עמודות לשימוש (ללא רווחים).
- אם ברצונך להשתמש במקור נתונים משלך, השתמש בקוד ה-JSON הבא והחלף את הטקסט ב-CAPS מהתבנית שסופקה. אם אתה משתמש במקור הנתונים לדוגמה שסופק, שמור על הגדרות ברירת המחדל:
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- לבחור שמור את השינויים.
בצע טעינת נתונים ראשונית
כעת, לאחר שהקונפיגורציה הנדרשת הסתיימה, אנו בולעים את הנתונים הראשוניים. שלב זה כולל שלושה חלקים: הטמעת הנתונים ממסד הנתונים היחסי של המקור לתוך השכבה הגולמית של אגם הנתונים, יצירת טבלאות Iceberg בשכבת הבמה של אגם הנתונים, ואימות תוצאות באמצעות Athena.
הטמעת נתונים בשכבה הגולמית של אגם הנתונים
כדי להטמיע נתונים ממקור הנתונים הרלוונטיים (PostgreSQL אם אתה משתמש בדוגמה שסופקה) אל אגם הנתונים העסקאות שלנו באמצעות Iceberg, בצע את השלבים הבאים:
- במסוף AWS DMS, בחר משימות העברת מסדי נתונים בחלונית הניווט.
- בחר את משימת השכפול שיצרת וב- פעולות בתפריט, בחר הפעל מחדש / המשך.
- המתן כ-5 דקות לסיום משימת השכפול. אתה יכול לעקוב אחר הטבלאות שנבלעו ב- סטָטִיסטִיקָה לשונית של משימת השכפול.

לאחר מספר דקות, המשימה מסתיימת עם ההודעה הטעינה המלאה הושלמה.
- בקונסולת Amazon S3, בחר את הדלי שהגדרת כשכבה הגולמית.
תחת הקידומת S3 שהוגדרה ב-AWS DMS (לדוגמה, postgres), אתה אמור לראות היררכיה של תיקיות עם המבנה הבא:
- סכימה
- שם טבלה
LOAD00000001.parquetLOAD0000000N.parquet
- שם טבלה

אם דלי ה-S3 שלך ריק, בדוק פתרון בעיות של משימות הגירה בשירות העברת מסדי נתונים של AWS לפני הפעלת עבודת הדבק של AWS.
צור והטמע נתונים בטבלאות Iceberg
לפני הפעלת העבודה, הבה ננווט בסקריפט של עבודת AWS Glue שסופקה כחלק מחסנית CloudFormation כדי להבין את ההתנהגות שלה.
- במסוף AWS Glue Studio, בחר מקומות תעסוקה בחלונית הניווט.
- חפש את העבודה שמתחילה בה
IcebergJob-וסיומת של שם מחסנית CloudFormation שלך (לדוגמה,IcebergJob-transactionaldl-postgresql). - בחר את העבודה.

סקריפט העבודה מקבל את התצורה הדרושה מ-Parameter Store. הפונקציה getConfigFromSSM() מחזיר תצורות הקשורות לעבודה כגון דלי מקור ויעד מהמקום שבו יש לקרוא ולכתוב את הנתונים. המשתנה ssmparam_table_values מכיל מידע הקשור לטבלה כמו תחום הנתונים, שם הטבלה, עמודות המחיצה והמפתח הראשי של הטבלאות שיש להטמעה. ראה את הקוד הבא של Python:
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']הסקריפט משתמש בשם קטלוגי שרירותי עבור Iceberg המוגדר כ-my_catalog. זה מיושם ב-AWS Glue Data Catalog באמצעות תצורות Spark, כך שפעולת SQL המצביעה על my_catalog תיושם בקטלוג הנתונים. ראה את הקוד הבא:
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
הסקריפט חוזר על הטבלאות המוגדרות ב-Parameter Store ומבצע את ההיגיון לזיהוי אם הטבלה קיימת ואם הנתונים הנכנסים הם עומס ראשוני או ביטול:
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')אל האני initialLoadRecordsSparkSQL() הפונקציה טוענת נתונים ראשוניים כאשר אין עמודת פעולה בקבצי S3. AWS DMS מוסיף עמודה זו רק לקובצי נתוני פרקט המיוצרים על ידי השכפול הרציף (CDC). טעינת הנתונים מתבצעת באמצעות הפקודה INSERT INTO עם SparkSQL. ראה את הקוד הבא:
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
כעת אנו מפעילים את עבודת ה- AWS Glue כדי להטמיע את הנתונים הראשוניים בטבלאות Iceberg. מחסנית CloudFormation מוסיפה את --datalake-formats פרמטר, הוספת ספריות Iceberg הנדרשות לעבודה.
- לבחור הפעל עבודה.
- לבחור Job Runs כדי לפקח על המצב. המתן עד שהסטטוס יהיה ההפעלה הצליחה.
אמת את הנתונים שנטענו
כדי לאשר שהעבודה עיבדה את הנתונים כצפוי, בצע את השלבים הבאים:
- במסוף אתנה בחר עורך שאילתה בחלונית הניווט.
- לאמת
AwsDataCatalogנבחר כמקור הנתונים. - תַחַת מסד נתונים, בחר את תחום הנתונים שברצונך לחקור, על סמך התצורה שהגדרת במאגר הפרמטרים. אם אתה משתמש במסד הנתונים לדוגמה שסופק, השתמש ב
sports.
תַחַת טבלאות ותצוגות, נוכל לראות את רשימת הטבלאות שנוצרו על ידי עבודת הדבק של AWS.
- בחר בתפריט האפשרויות (שלוש נקודות) לצד שם הטבלה הראשונה, ולאחר מכן בחר תצוגה מקדימה של נתונים.
אתה יכול לראות את הנתונים נטענים לטבלאות Iceberg. 
בצע טעינת נתונים מצטברים
כעת אנו מתחילים ללכוד שינויים ממסד הנתונים היחסים שלנו ולהחיל אותם על אגם הנתונים העסקאות. גם שלב זה מחולק לשלושה חלקים: לכידת השינויים, החלתם על טבלאות Iceberg ואימות התוצאות.
ללכוד שינויים ממסד הנתונים היחסי
עקב התצורה שציינו, משימת השכפול נעצרה לאחר הפעלת שלב הטעינה המלאה. כעת אנו מתחילים מחדש את המשימה כדי להוסיף קבצים מצטברים עם שינויים בשכבה הגולמית של אגם הנתונים.
- במסוף AWS DMS, בחר את המשימה שיצרנו והרצנו לפני כן.
- על פעולות בתפריט, בחר קורות חיים.
- לבחור התחל משימה כדי להתחיל לצלם שינויים.
- כדי להפעיל יצירת קבצים חדשים באגם הנתונים, בצע הוספות, עדכונים או מחיקות בטבלאות של מסד הנתונים המקור שלך באמצעות כלי ניהול מסד הנתונים המועדף עליך. אם אתה משתמש במסד הנתונים לדוגמה שסופק, תוכל להפעיל את פקודות SQL הבאות:
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- בדף פרטי משימות AWS DMS, בחר את סטטיסטיקות טבלה לשונית כדי לראות את השינויים שנקלטו.

- פתח את השכבה הגולמית של אגם הנתונים כדי למצוא קובץ חדש המכיל את השינויים המצטברים בתוך הקידומת של כל טבלה, למשל תחת
sporting_eventקידומת.
הרשומה עם שינויים עבור sporting_event הטבלה נראית כמו צילום המסך הבא.

שים לב Op עמודה בהתחלה מזוהה עם עדכון (U). כמו כן, ערך התאריך/שעה השני הוא עמודת הבקרה שנוספה על ידי AWS DMS עם הזמן שבו השינוי נקלט.

החל שינויים על טבלאות Iceberg באמצעות דבק AWS
כעת אנו מריצים שוב את עבודת הדבק של AWS, והיא תעבד אוטומטית רק את הקבצים המצטברים החדשים מכיוון שסימניית העבודה מופעלת. בואו נסקור איך זה עובד.
אל האני dedupCDCRecords() הפונקציה מבצעת מניעת כפילויות של נתונים מכיוון שניתן ללכוד שינויים מרובים במזהה רשומה בודדת בתוך אותו קובץ נתונים ב-Amazon S3. מניעת כפילויות מתבצעת על סמך ה last_update_time עמודה שנוספה על ידי AWS DMS שמציינת את חותמת הזמן של מועד הצילום של השינוי. ראה את הקוד הבא של Python:
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDFבשורה 99, ה- upsertRecordsSparkSQL() function מבצעת את ה-upsert בצורה דומה לטעינה הראשונית, אבל הפעם עם פקודת SQL MERGE.
סקור את השינויים שהוחלו
פתח את מסוף Athena והפעל שאילתה שבוחרת את הרשומות שהשתנו במסד הנתונים של המקור. אם אתה משתמש במסד הנתונים לדוגמה שסופק, השתמש בשאילתות SQL הבאות:
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

עקוב אחר צריכת הטבלה
סקריפט העבודה של AWS Glue מקודד בפשטות טיפול בחריגות Python לתפוס שגיאות במהלך עיבוד טבלה ספציפית. סימניית העבודה נשמרת לאחר שכל טבלה מסיימת את העיבוד בהצלחה, כדי למנוע עיבוד מחדש של טבלאות אם בוצע ניסיון חוזר של הפעלת העבודה עבור הטבלאות עם שגיאות.
אל האני ממשק שורת הפקודה של AWS (AWS CLI) מספק א get-job-bookmark פקודה עבור AWS Glue המספקת תובנות לגבי מצב הסימנייה עבור כל טבלה מעובדת.
- במסוף AWS Glue Studio, בחר את עבודת ה-ETL.
- בחר את Job Runs לשונית ולהעתיק את מזהה ריצת העבודה.
- הפעל את הפקודה הבאה על מסוף המאומת עבור AWS CLI, ומחליף
<GLUE_JOB_RUN_ID>בשורה 1 עם הערך שהעתקת. אם מחסנית CloudFormation שלך לא נקראתtransactionaldl-postgresql, ספק את שם העבודה שלך בשורה 2 של התסריט:
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunבפתרון זה, כאשר עיבוד טבלה גורם לחריגה, עבודת הדבק של AWS לא תיכשל על פי ההיגיון הזה. במקום זאת, הטבלה תתווסף למערך שיודפס לאחר השלמת העבודה. בתרחיש כזה, העבודה תסומן ככשלה לאחר שתנסה לעבד את שאר הטבלאות שזוהו במקור הנתונים הגולמיים. בדרך זו, טבלאות ללא שגיאות לא יצטרכו לחכות עד שהמשתמש יזהה ופותר את הבעיה בטבלאות המתנגשות. המשתמש יכול לזהות במהירות ריצות עבודה שהיו להן בעיות באמצעות סטטוס ריצת העבודה של AWS Glue, ולזהות אילו טבלאות ספציפיות גורמות לבעיה באמצעות יומני CloudWatch להפעלת העבודה.
- סקריפט העבודה מיישם תכונה זו עם קוד Python הבא:
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')צילום המסך הבא מראה כיצד יומני CloudWatch נראים עבור טבלאות שגורמות לשגיאות בעיבוד.

מיושר עם ה AWS Architected Well Framework Data Analytics Lens נהלים, אתה יכול להתאים מנגנוני בקרה מתוחכמים יותר כדי לזהות ולהודיע לבעלי עניין כאשר שגיאות מופיעות בצינורות הנתונים. לדוגמה, אתה יכול להשתמש ב-an אמזון דינמו טבלת בקרה כדי לאחסן את כל הטבלאות והריצות המשימות עם שגיאות, או שימוש שירות התראה פשוט של אמזון (Amazon SNS) ל לשלוח התראות למפעילים כאשר מתקיימים קריטריונים מסוימים.
תזמן טעינת נתוני אצווה מצטברים
מחסנית CloudFormation פורסת an אמזון EventBridge כלל (מושבת כברירת מחדל) שיכול להפעיל את עבודת הדבק של AWS לפעול לפי לוח זמנים. כדי לספק לוח זמנים משלך ולאפשר את הכלל, בצע את השלבים הבאים:
- במסוף EventBridge, בחר חוקי בחלונית הניווט.
- חפש את הכלל עם קידומת השם של מחסנית CloudFormation שלך ואחריו
JobTrigger(לדוגמה,transactionaldl-postgresql-JobTrigger-randomvalue). - בחר את הכלל.
- תַחַת תכנית הכנס, בחר ערוך.
לוח הזמנים המוגדר כברירת מחדל מוגדר להפעיל כל שעה.
- ספק את לוח הזמנים שברצונך להפעיל את העבודה.
- בנוסף, אתה יכול להשתמש ב- ביטוי קרון של EventBridge בבחירה לוח זמנים דק.

- כשתסיים להגדיר את הביטוי cron, בחר הַבָּא שלוש פעמים, ולבסוף לבחור עדכון כלל כדי לשמור שינויים.
הכלל נוצר מושבת כברירת מחדל כדי לאפשר לך להפעיל תחילה את טעינת הנתונים הראשונית.
- הפעל את הכלל על ידי בחירה אפשר.
אתה יכול להשתמש ב ניטור לשונית כדי להציג קריאות כללים, או ישירות ב-AWS Glue ריצת עבודה פרטים.
סיכום
לאחר פריסת פתרון זה, ביצעת את הטמעת הטבלאות שלך באופן אוטומטי במקור נתונים יחסי אחד. ארגונים המשתמשים באגם נתונים כפלטפורמת הנתונים המרכזית שלהם צריכים בדרך כלל לטפל במספר, לפעמים אפילו בעשרות מקורות נתונים. כמו כן, יותר ויותר מקרי שימוש דורשים מארגונים ליישם יכולות טרנזקציות לאגם הנתונים. אתה יכול להשתמש בפתרון זה כדי להאיץ את האימוץ של יכולות כאלה בכל מקורות הנתונים היחסיים שלך כדי לאפשר מקרי שימוש עסקיים חדשים, אוטומציה של תהליך ההטמעה כדי להפיק יותר ערך מהנתונים שלך.
על הכותבים
 לואיס ג'ררדו באזה הוא אדריכל ביג דאטה במעבדת הנתונים של Amazon Web Services (AWS). יש לו 12 שנות ניסיון בסיוע לארגונים במגזרי הבריאות, הפיננסים והחינוך לאמץ תוכניות ארכיטקטורה ארגוניות, מחשוב ענן ויכולות ניתוח נתונים. לואיס עוזר כיום לארגונים ברחבי אמריקה הלטינית להאיץ יוזמות נתונים אסטרטגיים.
לואיס ג'ררדו באזה הוא אדריכל ביג דאטה במעבדת הנתונים של Amazon Web Services (AWS). יש לו 12 שנות ניסיון בסיוע לארגונים במגזרי הבריאות, הפיננסים והחינוך לאמץ תוכניות ארכיטקטורה ארגוניות, מחשוב ענן ויכולות ניתוח נתונים. לואיס עוזר כיום לארגונים ברחבי אמריקה הלטינית להאיץ יוזמות נתונים אסטרטגיים.
 SaiKiran Reddy Aenugu הוא ארכיטקט נתונים במעבדת הנתונים של Amazon Web Services (AWS). יש לו 10 שנות ניסיון ביישום תהליכי טעינת נתונים, טרנספורמציה והדמיה. SaiKiran עוזרת כיום לארגונים בצפון אמריקה לאמץ ארכיטקטורות נתונים מודרניות כגון אגמי נתונים ורשת נתונים. יש לו ניסיון בתחום הקמעונאות, חברות התעופה והפיננסים.
SaiKiran Reddy Aenugu הוא ארכיטקט נתונים במעבדת הנתונים של Amazon Web Services (AWS). יש לו 10 שנות ניסיון ביישום תהליכי טעינת נתונים, טרנספורמציה והדמיה. SaiKiran עוזרת כיום לארגונים בצפון אמריקה לאמץ ארכיטקטורות נתונים מודרניות כגון אגמי נתונים ורשת נתונים. יש לו ניסיון בתחום הקמעונאות, חברות התעופה והפיננסים.
 נרנדרה מרלה הוא ארכיטקט נתונים במעבדת הנתונים של Amazon Web Services (AWS). יש לו ניסיון של 12 שנים בתכנון והפקה של צינורות נתונים בזמן אמת ואצווה ובבניית אגמי נתונים הן בסביבות ענן והן בסביבות מקומיות. נרנדרה עוזרת כיום לארגונים בצפון אמריקה לבנות ולתכנן ארכיטקטורות נתונים חזקות, ויש לה ניסיון במגזרי הטלקום והפיננסים.
נרנדרה מרלה הוא ארכיטקט נתונים במעבדת הנתונים של Amazon Web Services (AWS). יש לו ניסיון של 12 שנים בתכנון והפקה של צינורות נתונים בזמן אמת ואצווה ובבניית אגמי נתונים הן בסביבות ענן והן בסביבות מקומיות. נרנדרה עוזרת כיום לארגונים בצפון אמריקה לבנות ולתכנן ארכיטקטורות נתונים חזקות, ויש לה ניסיון במגזרי הטלקום והפיננסים.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- אודות
- להאיץ
- גישה
- פי
- הודה
- לרוחב
- להסתגל
- הוסיף
- נוסף
- בנוסף
- מוסיף
- מנהל
- מנהל
- לְאַמֵץ
- אימוץ
- לאחר
- חברת תעופה
- תעשיות
- כְּבָר
- אמזון בעברית
- אמזונה אתנה
- אמזון RDS
- אמזון שירותי אינטרנט
- אמזון שירותי אינטרנט (AWS)
- אמריקה
- אנליזה
- ניתוח
- ו
- אנג'לס
- אַפָּשׁ
- לְהוֹפִיעַ
- בקשה
- יישומית
- מריחה
- גישה
- בערך
- ארכיטקטורה
- מערך
- המשויך
- מאומת
- אוטומטי
- אוטומטי
- באופן אוטומטי
- אוטומציה
- מְמוּצָע
- לְהִמָנַע
- AWS
- AWS CloudFormation
- דבק AWS
- מבוסס
- עטלפים
- כי
- להיות
- לפני
- התחלה
- גָדוֹל
- נתונים גדולים
- לִבנוֹת
- בונה
- בִּניָן
- עסקים
- יכול לקבל
- יכולות
- כמוסות
- ללכוד
- לכידה
- מקרה
- מקרים
- קטלוג
- היאבקות
- לגרום
- גורמים
- גורם
- ה-CDC
- מֶרכָּזִי
- מסוים
- שינוי
- שינויים
- בחירה
- לבחור
- בחירה
- נבחר
- ענן
- ענן מחשוב
- קוד
- טור
- עמודות
- חברה
- להשלים
- מחשוב
- תְצוּרָה
- תצורות
- לאשר
- מתנגש
- לְחַבֵּר
- הקשר
- שיקולים
- קונסול
- צרכנים
- צְרִיכָה
- מכיל
- להמשיך
- רציף
- לִשְׁלוֹט
- יכול
- לִיצוֹר
- נוצר
- יוצר
- יוצרים
- יצירה
- הקריטריונים
- כיום
- מנהג
- לקוח
- אישית
- נתונים
- ניתוח נתונים
- אגם דאטה
- פלטפורמת נתונים
- מסד נתונים
- מאגרי מידע
- תַאֲרִיך
- בְּרִירַת מֶחדָל
- מוגדר
- לפרוס
- פרס
- פריסה
- פריסה
- פורס
- עיצוב
- מעוצב
- תכנון
- פרטים
- זוהה
- צעצועי התפתחות
- אחר
- ישירות
- נכה
- מחולק
- לא
- תחום
- תחומים
- לא
- בְּמַהֲלָך
- כל אחד
- מוקדם יותר
- בקלות
- חינוך
- מאמץ
- או
- לאפשר
- מופעל
- מוצפן
- הצף
- נקודת קצה
- מנוע
- זן
- מִפְעָל
- סביבות
- שגיאות
- Ether (ETH)
- אֲפִילוּ
- כל
- דוגמה
- עולה
- אלא
- יוצא מן הכלל
- קיימים
- קיים
- צפוי
- מצפה
- ניסיון
- לחקור
- סיומות
- תמצית
- נכשל
- מוכר
- אופנה
- מאפיין
- מעטים
- שלח
- קבצים
- בסופו של דבר
- לממן
- כספי
- גימור
- ראשון
- בעקבות
- הבא
- לצרכנים
- טופס
- התהוות
- מסגרת
- החל מ-
- מלא
- פונקציה
- נוצר
- דור
- לקבל
- להעניק
- מענקים
- גדל
- לטפל
- בריאות
- עזרה
- עוזר
- היררכיה
- היסטוריה
- מחזיק
- איך
- איך
- HTML
- HTTPS
- עצום
- IAM
- מזוהה
- מזהה
- מזהה
- לזהות
- ליישם
- הפעלה
- יושם
- יישום
- מיישמים
- השבחה
- in
- לכלול
- כולל
- כולל
- נכנס
- מצביע על
- בנפרד
- מידע
- בתחילה
- יוזמות
- מוסיף
- תובנה
- למשל
- במקום
- הוראות
- ביניים
- סוגיה
- בעיות
- IT
- איטרציה
- עבודה
- מקומות תעסוקה
- ג'סון
- שמור
- מפתח
- מפתחות
- לדעת
- מעבדה
- אגם
- הלטינית
- אמריקה הלטינית
- שכבה
- שכבות
- עוֹפֶרֶת
- לִלמוֹד
- ספריות
- להגביל
- קו
- רשימה
- לִטעוֹן
- טוען
- המון
- מיקום
- נראה
- נראה
- ה
- לוס אנג'לס
- מגרש
- ראשי
- שומר
- לעשות
- הצליח
- ניהול
- מנהל
- ניהול
- באופן ידני
- רב
- מיפוי
- מסומן
- תפריט
- למזג
- הודעה
- יכול
- הֲגִירָה
- מינימום
- דקה
- דקות
- מודרני
- לשנות
- צג
- ניטור
- יותר
- רוב
- הכי פופולארי
- מספר
- שם
- שם
- שמות
- נווט
- ניווט
- צורך
- נחוץ
- צרכי
- חדש
- הבא
- צפון
- צפון אמריקה
- הודעה
- מספר
- אובייקט
- אובייקטים
- ONE
- מתמשך
- OP
- מבצע
- אופטימיזציה
- אפשרויות
- אִרְגוּנִי
- ארגונים
- מאורגן
- מְקוֹרִי
- אַחֶרֶת
- בחוץ
- שֶׁלוֹ
- בעלים
- זגוגית
- פרמטר
- פרמטרים
- חלק
- חלקים
- נתיב
- תבנית
- לבצע
- ביצוע
- מבצע
- תקופה
- הרשאות
- שלב
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- פופולרי
- הודעה
- פוסטגרסל
- פרקטיקות
- מועדף
- תנאים מוקדמים
- להציג
- יְסוֹדִי
- בעיה
- תהליך
- תהליכים
- תהליך
- מיוצר
- תוכניות
- לספק
- ובלבד
- מספק
- פיתון
- מהירות
- להעלות
- ציון
- חי
- נתונים גולמיים
- חומר עיוני
- זמן אמת
- שיא
- רשום
- להחליף
- משוכפל
- שכפול
- לדרוש
- נדרש
- משאב
- משאבים
- REST
- תוצאות
- קמעוני
- לַחֲזוֹר
- החזרות
- סקירה
- חָסוֹן
- תפקיד
- כלל
- כללי
- הפעלה
- ריצה
- אותו
- שמור
- תרחיש
- לוח זמנים
- היקף
- סקריפטים
- חיפוש
- שְׁנִיָה
- מגזרים
- ראות
- נבחר
- בחירה
- מבחר
- נפרד
- שירותים
- סט
- הצבה
- הגדרות
- צריך
- לְהַצִיג
- הופעות
- דומה
- פָּשׁוּט
- since
- יחיד
- So
- פִּתָרוֹן
- פותר
- כמה
- מתוחכם
- מָקוֹר
- מקורות
- רווחים
- לעורר
- ספציפי
- מפרט
- מפורט
- ספורט
- SQL
- לערום
- ערימות
- התמחות
- בעלי עניין
- התחלה
- החל
- החל
- התחלות
- הברית
- סטטיסטיקה
- מצב
- שלב
- צעדים
- נעצר
- אחסון
- חנות
- מאוחסן
- חנויות
- אסטרטגי
- מִבְנֶה
- מובנה
- סטודיו
- בהצלחה
- כזה
- סוּפֶּר
- תמיכה
- מערכות
- שולחן
- יעד
- המשימות
- משימות
- נבחרת
- צוותי
- טלקום
- תבנית
- מסוף
- אל האני
- המקור
- שֶׁלָהֶם
- אלפים
- שְׁלוֹשָׁה
- דרך
- זמן
- ציר זמן
- פִּי
- חותם
- ל
- כלי
- חלק עליון
- סה"כ
- מעקב
- מסורתי
- טרנזקציות
- לשנות
- טרנספורמציה
- להפעיל
- הדרכה
- סוגים
- תחת
- להבין
- ייחודי
- עדכון
- עדכונים
- להשתמש
- במקרה להשתמש
- משתמש
- משתמשים
- בְּדֶרֶך כְּלַל
- ערך
- אימות
- לצפיה
- ראיה
- כֶּרֶך
- לחכות
- מחסן
- אינטרנט
- שירותי אינטרנט
- אשר
- יצטרך
- בתוך
- לְלֹא
- עובד
- לכתוב
- כתוב
- יאמל
- שנה
- שנים
- זפירנט