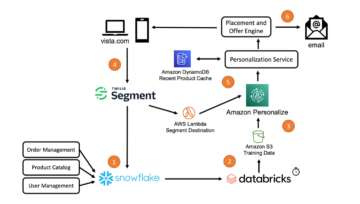
אמזון SageMaker הוא שירות למידת מכונה (ML) מנוהל במלואו. עם SageMaker, מדעני נתונים ומפתחים יכולים לבנות ולאמן מודלים של ML במהירות ובקלות, ולאחר מכן לפרוס אותם ישירות בסביבה מתארחת מוכנה לייצור. הוא מספק מופע מחברת כתיבה משולב של Jupyter לגישה קלה למקורות הנתונים שלך לחקירה וניתוח, כך שלא תצטרך לנהל שרתים. זה גם מספק נפוץ אלגוריתמים של ML המותאמים לרוץ ביעילות מול נתונים גדולים במיוחד בסביבה מבוזרת.
מסקנות בזמן אמת של SageMaker היא אידיאלית עבור עומסי עבודה שיש להם דרישות בזמן אמת, אינטראקטיביות עם זמן אחזור נמוך. עם מסקנות בזמן אמת של SageMaker, אתה יכול לפרוס נקודות קצה של REST המגובות על ידי סוג מופע מסוים עם כמות מסוימת של מחשוב וזיכרון. פריסת נקודת קצה של SageMaker בזמן אמת היא רק הצעד הראשון בדרך לייצור עבור לקוחות רבים. אנחנו רוצים להיות מסוגלים למקסם את הביצועים של נקודת הקצה כדי להשיג יעד עסקאות בשנייה (TPS) תוך עמידה בדרישות השהייה. חלק גדול באופטימיזציה של ביצועים להסקת מסקנות הוא לוודא שאתה בוחר את סוג המופע המתאים וספירה כדי לגבות נקודת קצה.
פוסט זה מתאר את השיטות המומלצות לבדיקת עומס של נקודת קצה של SageMaker כדי למצוא את התצורה הנכונה למספר המופעים והגודל. זה יכול לעזור לנו להבין את דרישות המופע המינימלי המוגדר כדי לעמוד בדרישות האחזור וה-TPS שלנו. משם, אנו צוללים כיצד תוכל לעקוב ולהבין את המדדים והביצועים של נקודת הקצה של SageMaker באמצעות אמזון CloudWatch מדדים.
תחילה אנו מבססים את הביצועים של המודל שלנו במופע בודד כדי לזהות את ה-TPS שהוא יכול להתמודד עם דרישות האחזור המקובלות שלנו. לאחר מכן אנו מבצעים אקסטרפולציה של הממצאים כדי להחליט על מספר המקרים שאנו צריכים על מנת לטפל בתעבורת הייצור שלנו. לבסוף, אנו מדמים תעבורה ברמת הייצור ומגדירים בדיקות עומס עבור נקודת קצה של SageMaker בזמן אמת כדי לוודא שנקודת הקצה שלנו יכולה להתמודד עם העומס ברמת הייצור. כל ערכת הקוד עבור הדוגמה זמינה בהמשך מאגר GitHub.
סקירה כללית של הפיתרון
עבור פוסט זה, אנו פורסים אימון מראש חיבוק פייס דגם DistilBERT מ חיבוק Face Hub. מודל זה יכול לבצע מספר משימות, אך אנו שולחים מטען ספציפי לניתוח סנטימנטים וסיווג טקסט. עם מטען מדגם זה, אנו שואפים להשיג 1000 TPS.
פרוס נקודת קצה בזמן אמת
פוסט זה מניח שאתה מכיר כיצד לפרוס מודל. מתייחס צור את נקודת הקצה שלך ופרוס את המודל שלך כדי להבין את הפנימיות מאחורי אירוח נקודת קצה. לעת עתה, אנו יכולים להצביע במהירות על הדגם הזה ב-Hugging Face Hub ולפרוס נקודת קצה בזמן אמת עם קטע הקוד הבא:
בואו נבדוק את נקודת הקצה שלנו במהירות עם מטען המטען לדוגמה שבו אנו רוצים להשתמש לבדיקת עומס:

שים לב שאנו מגבים את נקודת הקצה באמצעות סינגל ענן מחשוב אלסטי של אמזון (Amazon EC2) מופע מסוג ml.m5.12xlarge, המכיל 48 vCPU ו-192 GiB של זיכרון. מספר ה-vCPUs הוא אינדיקציה טובה לזמן שבו המופע יכול להתמודד. באופן כללי, מומלץ לבדוק סוגי מופעים שונים כדי לוודא שיש לנו מופע שיש לו משאבים שמנוצלים כראוי. כדי לראות רשימה מלאה של מופעי SageMaker ועוצמת המחשוב התואמת שלהם להסקה בזמן אמת, עיין ב תמחור SageMaker של אמזון.
מדדים למעקב
לפני שנוכל להיכנס לבדיקת עומסים, חיוני להבין אילו מדדים לעקוב אחר כדי להבין את פירוט הביצועים של נקודת הקצה של SageMaker. CloudWatch הוא כלי הרישום העיקרי שבו משתמש SageMaker כדי לעזור לך להבין את המדדים השונים שמתארים את הביצועים של נקודת הקצה שלך. אתה יכול להשתמש ביומני CloudWatch כדי לנפות באגים בקריאת נקודות הקצה שלך; כל הצהרות הרישום וההדפסה שיש לך בקוד ההסקה שלך נלכדות כאן. למידע נוסף, עיין ב איך Amazon CloudWatch עובד.
ישנם שני סוגים שונים של מדדים ש-CloudWatch מכסה עבור SageMaker: מדדי מופע ברמת המופע ומדדי פנייה.
מדדים ברמת המופע
קבוצת הפרמטרים הראשונה שיש לקחת בחשבון היא המדדים ברמת המופע: CPUUtilization ו MemoryUtilization (עבור מופעים מבוססי GPU, GPUUtilization). ל CPUUtilization, ייתכן שתראה אחוזים מעל 100% בהתחלה ב-CloudWatch. חשוב להבין עבור CPUUtilization, הסכום של כל ליבות המעבד מוצג. לדוגמה, אם המופע מאחורי נקודת הקצה שלך מכיל 4 מעבדי vCPU, פירוש הדבר שטווח השימוש הוא עד 400%. MemoryUtilization, לעומת זאת, הוא בטווח של 0-100%.
באופן ספציפי, אתה יכול להשתמש CPUUtilization כדי לקבל הבנה מעמיקה יותר אם יש לך מספיק או אפילו עודף של חומרה. אם יש לך מופע לא מנוצל (פחות מ-30%), אתה עשוי להקטין את סוג המופע שלך. לעומת זאת, אם אתה נמצא בסביבות 80-90% ניצול, יועיל לבחור מופע עם מחשוב/זיכרון רב יותר. מהבדיקות שלנו, אנו מציעים ניצול של 60-70% מהחומרה שלך.
מדדי הזמנה
כפי שמוצע מהשם, מדדי הזמנה הם המקום שבו נוכל לעקוב אחר זמן האחזור מקצה לקצה של כל פניה לנקודת הקצה שלך. אתה יכול לנצל את מדדי ההתקשרות כדי ללכוד ספירת שגיאות ואיזה סוג של שגיאות (5xx, 4xx וכן הלאה) שנקודת הקצה שלך עשויה להיתקל בה. חשוב מכך, אתה יכול להבין את התמוטטות ההשהיה של שיחות נקודות הקצה שלך. אפשר לתפוס הרבה מזה ModelLatency ו OverheadLatency מדדים, כפי שמודגם בתרשים הבא.

אל האני ModelLatency מדד לוכד את הזמן שלוקח מסקנות בתוך מיכל הדגם מאחורי נקודת קצה של SageMaker. שימו לב שמיכל הדגם כולל גם כל קוד או סקריפטים מותאם אישית של הסקה שהעברתם להסקת הסקה. יחידה זו נלכדת במיקרו-שניות כמדד הזמנה, ובדרך כלל אתה יכול לצייר גרף של אחוזון על פני CloudWatch (p99, p90 וכן הלאה) כדי לראות אם אתה עומד בזמן האחזור היעד שלך. שים לב שמספר גורמים יכולים להשפיע על זמן האחזור של המודל והמיכל, כגון:
- סקריפט מסקנות מותאם אישית – בין אם יישמת קונטיינר משלך ובין אם השתמשת בקונטיינר מבוסס SageMaker עם מטפלי מסקנות מותאמים אישית, שיטת העבודה הטובה ביותר היא ליצור פרופיל של הסקריפט שלך כדי לתפוס כל פעולות שמוסיפות באופן ספציפי זמן רב לזמן האחזור שלך.
- פרוטוקול תקשורת – שקול חיבורי REST לעומת gRPC לשרת הדגם בתוך מיכל הדגם.
- אופטימיזציות של מסגרת מודל – זה ספציפי למסגרת, למשל עם TensorFlow, ישנם מספר משתני סביבה שאתה יכול לכוונן שהם ספציפיים ל-TF Serving. הקפד לבדוק באיזה קונטיינר אתה משתמש ואם יש אופטימיזציות ספציפיות למסגרת שאתה יכול להוסיף בתוך הסקריפט או כמשתני סביבה להחדרת הקונטיינר.
OverheadLatency נמדד מרגע קבלת הבקשה של SageMaker ועד שהיא מחזירה תגובה ללקוח, בניכוי חביון המודל. חלק זה נמצא במידה רבה מחוץ לשליטתך ונופל תחת הזמן שלוקח תקורה של SageMaker.
חביון מקצה לקצה בכללותו תלוי במגוון גורמים ואינו בהכרח הסכום של ModelLatency ועוד OverheadLatency. לדוגמה, אם הלקוח שלך עושה את InvokeEndpoint קריאת API דרך האינטרנט, מנקודת המבט של הלקוח, זמן האחזור מקצה לקצה יהיה אינטרנט + ModelLatency + OverheadLatency. ככזה, כאשר בודקים עומסים של נקודת הקצה שלך על מנת למדוד במדויק את נקודת הקצה עצמה, מומלץ להתמקד במדדי נקודת הקצה (ModelLatency, OverheadLatency, ו InvocationsPerInstance) כדי לסמן במדויק את נקודת הקצה של SageMaker. ניתן לבודד בנפרד כל בעיה הקשורה לאחזור מקצה לקצה.
כמה שאלות שכדאי לקחת בחשבון לגבי זמן אחזור מקצה לקצה:
- איפה הלקוח שקורא לנקודת הקצה שלך?
- האם יש שכבות מתווך בין הלקוח שלך לבין זמן הריצה של SageMaker?
קנה מידה אוטומטי
אנחנו לא מכסים קנה מידה אוטומטי בפוסט הזה באופן ספציפי, אבל זה שיקול חשוב על מנת לספק את המספר הנכון של מופעים בהתבסס על עומס העבודה. בהתאם לדפוסי התנועה שלך, אתה יכול לצרף א מדיניות קנה מידה אוטומטי לנקודת הקצה של SageMaker. ישנן אפשרויות קנה מידה שונות, כגון TargetTrackingScaling, SimpleScaling, ו StepScaling. זה מאפשר לנקודת הקצה שלך להרחיב ולהרחיק באופן אוטומטי על סמך דפוס התנועה שלך.
אפשרות נפוצה היא מעקב אחר יעדים, שבו אתה יכול לציין מדד CloudWatch או מדד מותאם אישית שהגדרת ולהרחיב על סמך זה. שימוש תכוף בקנה מידה אוטומטי הוא מעקב אחר InvocationsPerInstance מֶטרִי. לאחר שזיהית צוואר בקבוק ב-TPS מסוים, אתה יכול לעתים קרובות להשתמש בזה כמדד כדי להרחיק את קנה המידה למספר רב יותר של מקרים כדי להיות מסוגל להתמודד עם עומסי שיא של תעבורה. כדי לקבל פירוט מעמיק יותר של נקודות הקצה של SageMaker בקנה מידה אוטומטי, עיין ב הגדרת נקודות קצה של הסקת קנה מידה אוטומטי באמזון SageMaker.
בדיקת עומס
למרות שאנו משתמשים בלקוס כדי להציג כיצד אנו יכולים לטעון בדיקה בקנה מידה, אם אתה מנסה להתאים את הגודל הנכון למופע מאחורי נקודת הקצה שלך, SageMaker Inference Recommend היא אפשרות יעילה יותר. עם כלי בדיקת עומסים של צד שלישי, עליך לפרוס באופן ידני נקודות קצה על פני מופעים שונים. עם Inference Recommender, אתה יכול פשוט לעבור מערך של סוגי המופעים שעבורם אתה רוצה לטעון מבחן, ו- SageMaker יסתובב משרות עבור כל אחד מהמקרים הללו.
אַרְבֶּה
עבור דוגמה זו, אנו משתמשים אַרְבֶּה, כלי לבדיקת עומסים בקוד פתוח שתוכל ליישם באמצעות Python. לוקוס דומה לכלי בדיקת עומס רבים אחרים בקוד פתוח, אך יש לו כמה יתרונות ספציפיים:
- קל להתקנה – כפי שאנו מדגימים בפוסט זה, נעביר סקריפט Python פשוט שניתן לשחזר בקלות עבור נקודת הקצה והמטען הספציפיים שלך.
- מבוזר וניתן להרחבה – ארבה מבוססת אירועים ומנצלת gavt מתחת למכסת המנוע. זה מאוד שימושי לבדיקת עומסי עבודה בו זמנית והדמיית אלפי משתמשים במקביל. אתה יכול להשיג TPS גבוה עם תהליך יחיד המריץ את Locust, אבל יש לו גם א ייצור עומס מבוזר תכונה המאפשרת לך להתרחב למספר תהליכים ומכונות לקוח, כפי שנחקור בפוסט זה.
- מדדי ארבה וממשק משתמש - Locust גם לוכד זמן אחזור מקצה לקצה כמדד. זה יכול לעזור להשלים את מדדי CloudWatch שלך כדי לצייר תמונה מלאה של הבדיקות שלך. כל זה נתפס בממשק המשתמש של Locust, שבו אתה יכול לעקוב אחר משתמשים, עובדים ועוד.
כדי להבין יותר את לוקוס, בדוק את שלהם תיעוד.
התקנה של אמזון EC2
אתה יכול להגדיר את Locust בכל סביבה שתואמת לך. עבור פוסט זה, אנו מגדירים מופע EC2 ומתקין שם את Locust כדי לבצע את הבדיקות שלנו. אנו משתמשים במופע c5.18xlarge EC2. כוח המחשוב בצד הלקוח הוא גם משהו שצריך לקחת בחשבון. בזמנים שבהם נגמר לך כוח המחשוב בצד הלקוח, זה לעתים קרובות לא נתפס, ונחשב בטעות כשגיאת נקודת קצה של SageMaker. חשוב למקם את הלקוח שלך במיקום בעל כוח מחשוב מספיק שיכול להתמודד עם העומס שבו אתה בודק. עבור מופע ה-EC2 שלנו, אנו משתמשים ב-Ubuntu Deep Learning AMI, אבל אתה יכול להשתמש בכל AMI כל עוד אתה יכול להגדיר כראוי את Locust במכונה. כדי להבין כיצד להפעיל ולהתחבר למופע ה-EC2 שלך, עיין במדריך התחל עם מופעי Amazon EC2 Linux.
ממשק המשתמש של Locust נגיש דרך יציאה 8089. אנו יכולים לפתוח זאת על ידי התאמת כללי קבוצת האבטחה הנכנסת שלנו עבור מופע EC2. אנחנו גם פותחים יציאה 22 כדי שנוכל SSH לתוך מופע EC2. שקול להקטין את המקור לכתובת ה-IP הספציפית שממנה אתה ניגש למופע EC2.

לאחר שהתחברת למופע ה-EC2 שלך, אנו מגדירים סביבה וירטואלית של Python ומתקינים את ה-API של Locust בקוד פתוח דרך ה-CLI:
כעת אנו מוכנים לעבוד עם Locust לבדיקת עומסים של נקודת הקצה שלנו.
בדיקת ארבה
כל בדיקות עומס ארבה מבוצעות על בסיס א קובץ ארבה שאתה מספק. קובץ ארבה זה מגדיר משימה עבור בדיקת העומס; זה המקום שבו אנו מגדירים את Boto3 שלנו קריאת API invoke_endpoint. ראה את הקוד הבא:
בקוד הקודם, התאם את הפרמטרים של קריאת נקודת הקצה להפעלת נקודת הקצה כך שיתאימו להזמנת הדגם הספציפי שלך. אנו משתמשים ב- InvokeEndpoint API באמצעות קטע הקוד הבא בקובץ Locust; זו נקודת הריצה של בדיקת העומס שלנו. קובץ הארבה בו אנו משתמשים הוא locust_script.py.
עכשיו, כשיש לנו את הסקריפט של Locust מוכן, אנחנו רוצים להריץ מבחני Locust מבוזרים כדי לבחון את המאמץ הבודד שלנו כדי לגלות כמה תעבורה המופע שלנו יכול להתמודד.
מצב מבוזר ארבה הוא קצת יותר ניואנס מבדיקת ארבה בתהליך יחיד. במצב מבוזר, יש לנו עובד ראשי אחד ומספר עובדים. העובד הראשי מדריך את העובדים כיצד להריץ ולשלוט במשתמשים במקביל ששולחים בקשה. בשלנו distributed.sh סקריפט, אנו רואים כברירת מחדל ש-240 משתמשים יחולקו על פני 60 העובדים. שימו לב שה- --headless הדגל ב-Locusst CLI מסיר את תכונת ממשק המשתמש של Locust.
./distributed.sh huggingface-pytorch-inference-2022-10-04-02-46-44-677 #to execute Distributed Locust test
אנו מפעילים תחילה את הבדיקה המבוזרת על מופע בודד המגבה את נקודת הקצה. הרעיון כאן הוא שאנחנו רוצים למקסם באופן מלא מופע בודד כדי להבין את ספירת המופעים שאנחנו צריכים כדי להשיג את היעד TPS שלנו תוך שמירה על דרישות ההשהיה שלנו. שים לב שאם אתה רוצה לגשת לממשק המשתמש, שנה את ה Locust_UI משתנה הסביבה ל-True ולקחת את ה-IP הציבורי של מופע ה-EC2 שלך ומפה את יציאה 8089 לכתובת ה-URL.
צילום המסך הבא מציג את מדדי CloudWatch שלנו.

בסופו של דבר, אנו שמים לב שלמרות שאנו משיגים תחילה TPS של 200, אנו מתחילים להבחין בשגיאות 5xx ביומני EC2 בצד הלקוח שלנו, כפי שמוצג בצילום המסך הבא.
אנחנו יכולים גם לאמת זאת על ידי התבוננות במדדים שלנו ברמת המופע, באופן ספציפי CPUUtilization.
 כאן אנו שמים לב
כאן אנו שמים לב CPUUtilization כמעט 4,800%. למופע ml.m5.12x.large שלנו יש 48 vCPUs (48 * 100 = 4800~). זה מרווה את כל המופע, מה שגם עוזר להסביר את שגיאות ה-5xx שלנו. אנו רואים גם עלייה ב ModelLatency.
נראה כאילו המופע היחיד שלנו מופל ואין לו את המחשב להחזיק עומס מעבר ל-200 TPS שאנו צופים בהם. יעד ה-TPS שלנו הוא 1000, אז בואו ננסה להגדיל את ספירת המופעים שלנו ל-5. אולי זה צריך להיות אפילו יותר בהגדרת ייצור, כי ראינו שגיאות ב-200 TPS לאחר נקודה מסוימת.

אנו רואים גם ביומני Locust UI וגם ב-CloudWatch שיש לנו TPS של כמעט 1000 עם חמישה מופעים המגבים את נקודת הקצה.

 אם אתה מתחיל להיתקל בשגיאות אפילו עם הגדרת החומרה הזו, הקפד לנטר
אם אתה מתחיל להיתקל בשגיאות אפילו עם הגדרת החומרה הזו, הקפד לנטר CPUUtilization כדי להבין את התמונה המלאה מאחורי אירוח נקודות הקצה שלך. זה חיוני להבין את ניצול החומרה שלך כדי לראות אם אתה צריך להגדיל או אפילו להקטין. לפעמים בעיות ברמת מיכל מובילות לשגיאות 5xx, אבל אם CPUUtilization הוא נמוך, זה מצביע על כך שזו לא החומרה שלך אלא משהו ברמת המכולה או הדגם שעשוי להוביל לבעיות אלו (משתנה סביבה מתאים למספר העובדים שלא הוגדר, למשל). מצד שני, אם אתה שם לב שהמופע שלך נהיה רווי לחלוטין, זה סימן שאתה צריך להגדיל את צי המופעים הנוכחי או לנסות מופע גדול יותר עם צי קטן יותר.
למרות שהגדלנו את ספירת המופעים ל-5 כדי להתמודד עם 100 TPS, אנו יכולים לראות שה ModelLatency המדד עדיין גבוה. זה נובע מכך שהמקרים היו רוויים. באופן כללי, אנו מציעים לשאוף לנצל את משאבי המופע בין 60-70%.
לנקות את
לאחר בדיקת עומס, הקפד לנקות את כל המשאבים שלא תשתמש בהם דרך מסוף SageMaker או דרך delete_endpoint קריאת API של Boto3. בנוסף, הקפד לעצור את מופע ה-EC2 שלך או כל הגדרת לקוח שתצטרך כדי לא לגרור חיובים נוספים גם שם.
<br> סיכום
בפוסט זה, תיארנו כיצד תוכל לטעון את בדיקת ה-SageMaker שלך בזמן אמת. דנו גם באילו מדדים עליך להעריך בעת בדיקת עומס של נקודת הקצה שלך כדי להבין את פירוט הביצועים שלך. הקפד לבצע צ'ק אאוט SageMaker Inference Recommend כדי להבין יותר גודל נכון של מופע ועוד טכניקות אופטימיזציה של ביצועים.
על הכותבים
 מארק קארפ הוא אדריכל ML עם צוות שירות SageMaker. הוא מתמקד בסיוע ללקוחות לתכנן, לפרוס ולנהל עומסי עבודה של ML בקנה מידה. בזמנו הפנוי הוא נהנה לטייל ולחקור מקומות חדשים.
מארק קארפ הוא אדריכל ML עם צוות שירות SageMaker. הוא מתמקד בסיוע ללקוחות לתכנן, לפרוס ולנהל עומסי עבודה של ML בקנה מידה. בזמנו הפנוי הוא נהנה לטייל ולחקור מקומות חדשים.
 רם וג'יראג'ו הוא אדריכל ML עם צוות שירות SageMaker. הוא מתמקד בסיוע ללקוחות לבנות ולמטב את פתרונות ה-AI/ML שלהם ב-Amazon SageMaker. בזמנו הפנוי הוא אוהב לטייל ולכתוב.
רם וג'יראג'ו הוא אדריכל ML עם צוות שירות SageMaker. הוא מתמקד בסיוע ללקוחות לבנות ולמטב את פתרונות ה-AI/ML שלהם ב-Amazon SageMaker. בזמנו הפנוי הוא אוהב לטייל ולכתוב.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/best-practices-for-load-testing-amazon-sagemaker-real-time-inference-endpoints/
- 1
- 10
- 100
- 11
- 9
- a
- יכול
- מֵעַל
- קביל
- גישה
- נגיש
- גישה
- במדויק
- להשיג
- לרוחב
- תוספת
- כתובת
- לאחר
- נגד
- AI / ML
- מכוון
- תעשיות
- מאפשר
- למרות
- אמזון בעברית
- אמזון
- אמזון SageMaker
- כמות
- אנליזה
- ו
- API
- סביב
- מערך
- לצרף
- מחבר
- המכונית
- באופן אוטומטי
- זמין
- AWS
- בחזרה
- מגובה
- גיבוי
- מבוסס
- כי
- מאחור
- להיות
- בנצ 'מרק
- תועלת
- הטבות
- הטוב ביותר
- שיטות עבודה מומלצות
- בֵּין
- גוּף
- התמוטטות
- לִבנוֹת
- C + +
- שיחה
- שיחות
- יכול לקבל
- ללכוד
- לוכדת
- היאבקות
- מסוים
- שינוי
- חיובים
- לבדוק
- בכיתה
- מיון
- לקוחות
- קוד
- Common
- תואם
- לחשב
- במקביל
- לנהל
- תְצוּרָה
- לאשר
- לְחַבֵּר
- מחובר
- חיבורי
- לשקול
- התחשבות
- קונסול
- מכולה
- מכיל
- הקשר
- לִשְׁלוֹט
- תוֹאֵם
- יכול
- לכסות
- מכסה
- CPU
- לִיצוֹר
- מכריע
- נוֹכְחִי
- מנהג
- לקוחות
- נתונים
- עמוק
- למידה עמוקה
- עמוק יותר
- בְּרִירַת מֶחדָל
- מגדיר
- להפגין
- תלוי
- תלוי
- לפרוס
- פריסה
- לתאר
- מְתוּאָר
- עיצוב
- מפתחים
- אחר
- ישירות
- נָדוֹן
- לְהַצִיג
- מופץ
- לא
- לא
- מטה
- כל אחד
- בקלות
- יעיל
- יעילות
- או
- מאפשר
- מקצה לקצה
- נקודת קצה
- שלם
- סביבה
- שגיאה
- שגיאות
- חיוני
- Ether (ETH)
- אֲפִילוּ
- דוגמה
- יוצא מן הכלל
- לבצע
- התנסות
- להסביר
- חקירה
- לחקור
- היכרות
- יצוא
- מאוד
- פָּנִים
- גורמים
- פולס
- מוכר
- מאפיין
- מעטים
- שלח
- בסופו של דבר
- ראשון
- צי
- להתמקד
- מתמקד
- הבא
- פוּרמָט
- מסגרת
- תכוף
- החל מ-
- מלא
- לגמרי
- נוסף
- כללי
- בדרך כלל
- לקבל
- מקבל
- טוב
- גרף
- יותר
- קְבוּצָה
- קבוצה
- לטפל
- שמח
- חומרה
- לעזור
- עזרה
- עוזר
- כאן
- גָבוֹהַ
- מאוד
- ברדס
- המארח
- אירח
- אירוח
- איך
- איך
- HTML
- HTTPS
- טבור
- רעיון
- אידאל
- מזוהה
- לזהות
- פְּגִיעָה
- ליישם
- יושם
- לייבא
- חשוב
- in
- כולל
- להגדיל
- גדל
- מצביע על
- סִימָן
- מידע
- בהתחלה
- להתקין
- למשל
- משולב
- אינטראקטיבי
- אינטרנט
- מעורר
- IP
- כתובת IP
- מְבוּדָד
- בעיות
- IT
- עצמו
- ג'סון
- גָדוֹל
- במידה רבה
- גדול יותר
- חֶבִיוֹן
- לשגר
- שכבות
- עוֹפֶרֶת
- מוביל
- למידה
- רמה
- לינוקס
- רשימה
- קְצָת
- לִטעוֹן
- המון
- מיקום
- ארוך
- הסתכלות
- מגרש
- נמוך
- מכונה
- למידת מכונה
- מכונה
- לעשות
- עשייה
- לנהל
- הצליח
- באופן ידני
- רב
- מַפָּה
- לְהַגדִיל
- אומר
- לִפְגוֹשׁ
- מפגש
- זכרון
- מטרי
- מדדים
- יכול
- מינימום
- ML
- מצב
- מודל
- מודלים
- צג
- יותר
- יותר יעיל
- מספר
- שם
- כמעט
- בהכרח
- צורך
- חדש
- מחברה
- מספר
- ONE
- לפתוח
- קוד פתוח
- תפעול
- אופטימיזציה
- מטב
- אופטימיזציה
- אפשרות
- אפשרויות
- להזמין
- אחר
- בחוץ
- שֶׁלוֹ
- לצייר
- פרמטרים
- חלק
- עבר
- עבר
- נתיב
- תבנית
- דפוסי
- שִׂיא
- לבצע
- ביצועים
- פרספקטיבה
- לבחור
- תמונה
- לְחַבֵּר
- מקום
- מקומות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- ועוד
- נקודה
- הודעה
- פוטנציאל
- כּוֹחַ
- תרגול
- פרקטיקות
- חיזוי
- יְסוֹדִי
- קופונים להדפסה
- בעיות
- תהליך
- תהליכים
- הפקה
- פּרוֹפִיל
- תָקִין
- כמו שצריך
- לספק
- מספק
- אַספָּקָה
- ציבורי
- פיתון
- שאלות
- מהירות
- רכס
- מוכן
- זמן אמת
- להבין
- מקבל
- מוּמלָץ
- באזור
- קָשׁוּר
- לבקש
- דרישות
- משאבים
- תגובה
- REST
- תוצאה
- תוצאות
- החזרות
- כללי
- הפעלה
- ריצה
- בעל חכמים
- SageMaker Inference
- סולם
- דרוג
- מדענים
- סקופינג
- סקריפטים
- שְׁנִיָה
- אבטחה
- נראה
- עצמי
- שליחה
- רגש
- שרות
- הגשה
- סט
- הצבה
- הגדרות
- התקנה
- כמה
- צריך
- הראה
- הופעות
- סִימָן
- דומה
- פָּשׁוּט
- בפשטות
- יחיד
- מידה
- קטן יותר
- So
- פתרונות
- משהו
- מָקוֹר
- מקורות
- תַפטִיר
- ספציפי
- במיוחד
- לְסוֹבֵב
- תֶקֶן
- התחלה
- החל
- הצהרות
- שלב
- עוד
- עצור
- לחץ
- לשאוף
- כזה
- מספיק
- כדלקמן
- סוּפֶּר
- תוספת
- לקחת
- לוקח
- יעד
- המשימות
- משימות
- נבחרת
- טכניקות
- מבחן
- מבחן ריצה
- בדיקות
- בדיקות
- סיווג טקסט
- אל האני
- המקור
- שֶׁלָהֶם
- צד שלישי
- אלפים
- דרך
- זמן
- פִּי
- ל
- כלי
- כלים
- Tps
- לעקוב
- מעקב
- תְנוּעָה
- רכבת
- עסקות
- נסיעה
- נָכוֹן
- הדרכה
- סוגים
- אובונטו
- ui
- תחת
- להבין
- הבנה
- יחידה
- כתובת האתר
- us
- להשתמש
- משתמשים
- לנצל
- מנוצל
- מנצל
- ניצול
- מגוון
- לאמת
- באמצעות
- וירטואלי
- מה
- אם
- אשר
- בזמן
- יצטרך
- בתוך
- תיק עבודות
- עובד
- עובדים
- היה
- כתיבה
- זפירנט