מודלים של שפה גדולה בקוד פתוח (LLMs) הפכו פופולריים, ומאפשרים לחוקרים, מפתחים וארגונים לגשת למודלים אלה כדי לטפח חדשנות וניסויים. זה מעודד שיתוף פעולה מקהילת הקוד הפתוח כדי לתרום לפיתוחים ולשיפור של LLMs. LLMs בקוד פתוח מספקים שקיפות לארכיטקטורת המודל, תהליך ההכשרה ונתוני ההדרכה, מה שמאפשר לחוקרים להבין כיצד המודל פועל ולזהות הטיות פוטנציאליות ולטפל בחששות אתיים. LLMs אלה בקוד פתוח מייצרים דמוקרטיזציה של בינה מלאכותית גנרית על ידי הפיכת טכנולוגיית עיבוד שפה טבעית מתקדמת (NLP) לזמינה למגוון רחב של משתמשים כדי לבנות יישומים עסקיים קריטיים למשימה. GPT-NeoX, LLaMA, Alpaca, GPT4All, Vicuna, Dolly ו-OpenAssistant הם חלק מה-LLMs הפופולריים בקוד פתוח.
OpenChatKit הוא LLM בקוד פתוח המשמש לבניית יישומי צ'אט בוט למטרות כלליות ומיוחדות, ששוחרר על ידי Together Computer במרץ 2023 תחת רישיון Apache-2.0. מודל זה מאפשר למפתחים לקבל יותר שליטה על התנהגות הצ'אט בוט ולהתאים אותו ליישומים הספציפיים שלהם. OpenChatKit מספק קבוצה של כלים, בוט בסיסי ואבני בניין לבניית צ'אטבוטים מותאמים אישית וחזקים. מרכיבי המפתח הם כדלקמן:
- LLM מכוון הוראות, מכוון לצ'אט מה-GPT-NeoX-20B של EleutherAI עם למעלה מ-43 מיליון הוראות בחישוב 100% פחמן שלילי. ה
GPT-NeoXT-Chat-Base-20Bהמודל מבוסס על מודל GPT-NeoX של EleutherAI, והוא מכוון עדין עם נתונים המתמקדים באינטראקציות בסגנון דיאלוג. - מתכוני התאמה אישית כדי לכוונן את המודל כדי להשיג דיוק גבוה במשימות שלך.
- מערכת אחזור הניתנת להרחבה המאפשרת לך להגדיל את תגובות הבוט עם מידע ממאגר מסמכים, API או מקור מידע אחר המתעדכן בזמן אמת.
- מודל ניהול, מכוון מ-GPT-JT-6B, שנועד לסנן לאילו שאלות הבוט מגיב.
הקנה המידה והגדלים של מודלים של למידה עמוקה מציבים מכשולים לפריסה מוצלחת של מודלים אלה ביישומי בינה מלאכותית. כדי לעמוד בדרישות לאחביות נמוכה ותפוקה גבוהה, זה הופך להיות חיוני להשתמש בשיטות מתוחכמות כמו מקביליות מודל וקונטיזציה. בהיעדר מיומנות ביישום של שיטות אלה, משתמשים רבים נתקלים בקשיים בהתחלת אירוח של מודלים גדולים עבור מקרי שימוש בינה מלאכותית.
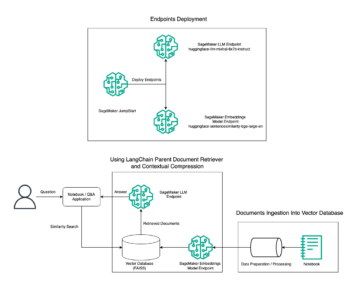
בפוסט זה, אנו מראים כיצד לפרוס דגמי OpenChatKit (GPT-NeoXT-Chat-Base-20B and GPT-JT-Moderation-6B) דגמים על אמזון SageMaker באמצעות DJL Serving וספריות מקבילות במודל קוד פתוח כמו DeepSpeed ו-Hugging Face Accelerate. אנו משתמשים ב-DJL Serving, שהוא פתרון הגשה מודל אוניברסלי בעל ביצועים גבוהים המופעל על ידי ספריית ג'אווה עמוקה (DJL) שהיא אגנוסטית לשפת תכנות. אנו מדגימים כיצד ספריית Hugging Face Accelerate מפשטת פריסה של דגמים גדולים למספר GPUs, ובכך מפחיתה את העומס של הפעלת LLMs בצורה מבוזרת. בואו נתחיל!
מערכת שליפה ניתנת להרחבה
מערכת אחזור הניתנת להרחבה היא אחד המרכיבים המרכזיים של OpenChatKit. זה מאפשר לך להתאים אישית את תגובת הבוט בהתבסס על בסיס ידע של תחום סגור. למרות ש-LLMs מסוגלים לשמור על ידע עובדתי בפרמטרי המודל שלהם ויכולים להשיג ביצועים יוצאי דופן במשימות NLP במורד הזרם כשהם מכוונים עדין, היכולת שלהם לגשת ולחזות ידע בתחום סגור במדויק נשארת מוגבלת. לכן, כאשר מוצגות בפניהם משימות עתירות ידע, הביצועים שלהם סובלים מזה של ארכיטקטורות ספציפיות למשימה. אתה יכול להשתמש במערכת האחזור של OpenChatKit כדי להגדיל את הידע בתגובות שלהם ממקורות ידע חיצוניים כמו ויקיפדיה, מאגרי מסמכים, ממשקי API ומקורות מידע אחרים.
מערכת האחזור מאפשרת לצ'אט בוט לגשת למידע עדכני על ידי השגת פרטים רלוונטיים בתגובה לשאילתה ספציפית, ובכך מספקת את ההקשר הדרוש למודל כדי ליצור תשובות. כדי להמחיש את הפונקציונליות של מערכת אחזור זו, אנו מספקים תמיכה לאינדקס של מאמרי ויקיפדיה ומציעים קוד לדוגמה המדגים כיצד להפעיל ממשק API של חיפוש באינטרנט לצורך אחזור מידע. על ידי מעקב אחר התיעוד שסופק, אתה יכול לשלב את מערכת האחזור עם כל מערך נתונים או API במהלך תהליך ההסקה, מה שמאפשר לצ'אטבוט לשלב נתונים מעודכנים דינמית בתגובותיו.
מודל מתינות
מודלים של ניהול חשובים ביישומי צ'טבוט כדי לאכוף סינון תוכן, בקרת איכות, בטיחות המשתמש וסיבות משפטיות ותאימות. מתינות היא משימה קשה וסובייקטיבית, ותלויה רבות בתחום של אפליקציית הצ'טבוט. OpenChatKit מספק כלים לניהול אפליקציית הצ'אטבוט ולנטר הודעות טקסט קלט עבור כל תוכן לא הולם. מודל המתינות מספק קו בסיס טוב שניתן להתאים ולהתאים לצרכים השונים.
ל-OpenChatKit יש מודל ניהול של 6 מיליארד פרמטרים, GPT-JT-Moderation-6B, שיכול להנחות את הצ'אט בוט כדי להגביל את הקלטים לנושאים המנוהלים. למרות שלדגם עצמו יש מתינות מובנית, TogetherComputer הכשיר א GPT-JT-Moderation-6B דגם עם Ontocord.ai's מערך נתונים של ניהול OIG. מודל זה פועל לצד הצ'אט בוט הראשי כדי לבדוק שגם קלט המשתמש וגם התשובה מהבוט אינם מכילים תוצאות בלתי הולמות. אתה יכול גם להשתמש בזה כדי לזהות שאלות מחוץ לדומיין לצ'אטבוט ולעקוף כאשר השאלה אינה חלק מהדומיין של הצ'אטבוט.
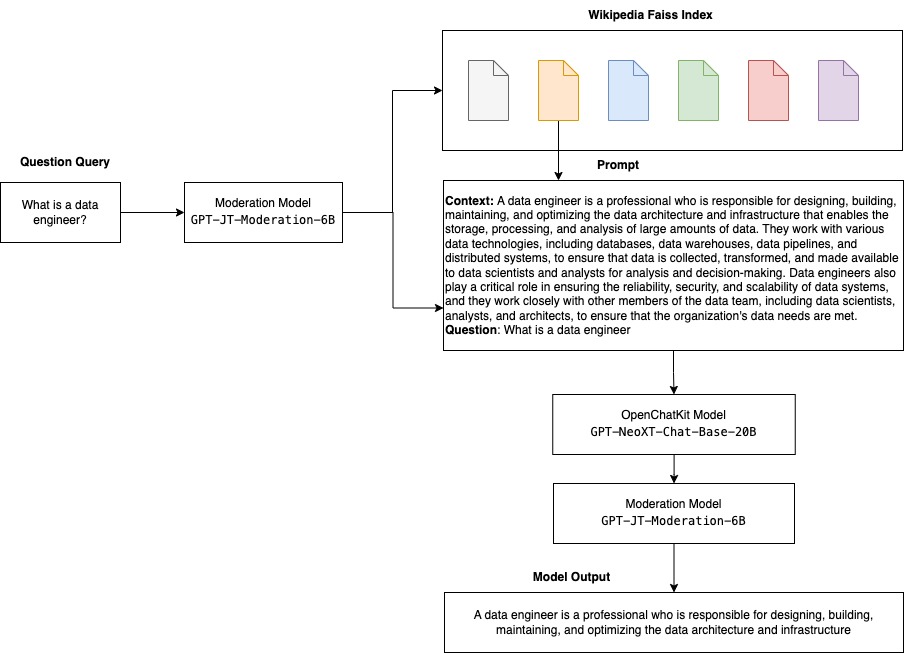
התרשים הבא ממחיש את זרימת העבודה של OpenChatKit.
מקרי שימוש במערכת אחזור ניתנת להרחבה
למרות שאנו יכולים ליישם טכניקה זו בתעשיות שונות כדי לבנות יישומי בינה מלאכותית, עבור פוסט זה אנו דנים במקרים של שימוש בתעשייה הפיננסית. ניתן להשתמש בדור מוגבר של אחזור במחקר פיננסי להפקה אוטומטית של דוחות מחקר על חברות, תעשיות או מוצרים פיננסיים ספציפיים. על ידי שליפת מידע רלוונטי מבסיסי ידע פנימיים, מארכיונים פיננסיים, מאמרי חדשות ומאמרי מחקר, תוכל להפיק דוחות מקיפים המסכמים תובנות מפתח, מדדים פיננסיים, מגמות שוק והמלצות השקעה. אתה יכול להשתמש בפתרון זה כדי לנטר ולנתח חדשות פיננסיות, סנטימנט בשוק ומגמות.
סקירת פתרונות
השלבים הבאים כרוכים בבניית צ'אטבוט באמצעות מודלים של OpenChatKit ופריסה שלהם ב- SageMaker:
- הורד את בסיס הצ'אט
GPT-NeoXT-Chat-Base-20Bדגם וארוז את חפצי הדגם שיש להעלות אליהם שירות אחסון פשוט של אמזון (אמזון S3). - השתמש במיכל של SageMaker להסקת מודל גדול (LMI), הגדר את המאפיינים והגדר קוד הסקה מותאם אישית כדי לפרוס מודל זה.
- הגדר טכניקות מקבילות של מודלים והשתמש בספריות אופטימיזציה של מסקנות במאפייני הגשת DJL. אנו נשתמש ב-Hugging Face Accelerate כמנוע להגשת DJL. בנוסף, אנו מגדירים תצורות מקבילות טנזור כדי לחלק את המודל.
- צור מודל של SageMaker ותצורת נקודת קצה, ופרוס את נקודת הקצה של SageMaker.
אתה יכול לעקוב אחריו על ידי הפעלת המחברת ב- GitHub ריפו.
הורד את מודל OpenChatKit
ראשית, אנו מורידים את מודל הבסיס של OpenChatKit. אנו משתמשים huggingface_hub ואת השימוש snapshot_download כדי להוריד את המודל, שמוריד מאגר שלם בגרסה נתונה. ההורדות מתבצעות במקביל כדי להאיץ את התהליך. ראה את הקוד הבא:
מאפייני הגשה של DJL
אתה יכול להשתמש בקונטיינרים של SageMaker LMI כדי לארח דגמי AI יצירתיים גדולים עם קוד מסקנות מותאם אישית מבלי לספק קוד מסקנות משלך. זה שימושי ביותר כאשר אין עיבוד מקדים מותאם אישית של נתוני הקלט או עיבוד לאחר של תחזיות המודל. אתה יכול גם לפרוס מודל באמצעות קוד הסקה מותאם אישית. בפוסט זה, אנו מדגימים כיצד לפרוס מודלים של OpenChatKit עם קוד הסקה מותאם אישית.
SageMaker מצפה לחפצי הדגם בפורמט זפת. אנו יוצרים כל מודל OpenChatKit עם הקבצים הבאים: serving.properties ו model.py.
השמיים serving.properties קובץ התצורה מציין ל-DJL Serving באילו ספריות מקבילות ואופטימיזציה של הסקות תרצה להשתמש. להלן רשימה של הגדרות שבהן אנו משתמשים בקובץ תצורה זה:
זה מכיל את הפרמטרים הבאים:
- מנוע - המנוע לשימוש DJL.
- option.entryPoint – הקובץ או המודול של Python של נקודת הכניסה. זה אמור להתיישר עם המנוע שנמצא בשימוש.
- option.s3url - הגדר זאת ל-URI של דלי S3 המכיל את הדגם.
- option.modelid – אם אתה רוצה להוריד את הדגם מhuggingface.co, אתה יכול להגדיר
option.modelidלמזהה הדגם של דגם מאומן מראש המתארח בתוך מאגר מודלים ב-huggingface.co (https://huggingface.co/models). הקונטיינר משתמש במזהה הדגם הזה כדי להוריד את מאגר המודלים המתאים ב-huggingface.co. - option.tensor_parallel_degree - הגדר את זה למספר התקני GPU שעליהם DeepSpeed צריך לחלק את הדגם. פרמטר זה שולט גם במספר העובדים לכל דגם שיופעל כאשר DJL Serving פועל. לדוגמה, אם יש לנו מכונת 8 GPU ואנחנו יוצרים שמונה מחיצות, אז יהיה לנו עובד אחד לכל דגם שישרת את הבקשות. יש צורך לכוונן את מידת ההקבלה ולזהות את הערך האופטימלי עבור ארכיטקטורת מודל ופלטפורמת חומרה נתונה. אנחנו קוראים לזה יכולת מקביליות מותאמת להסקת מסקנות.
עיין תצורות והגדרות לרשימה ממצה של אפשרויות.
דגמי OpenChatKit
למימוש מודל הבסיס של OpenChatKit יש את ארבעת הקבצים הבאים:
- model.py – קובץ זה מיישם את היגיון הטיפול עבור המודל הראשי של OpenChatKit GPT-NeoX. הוא מקבל את בקשת קלט ההסקה, טוען את המודל, טוען את אינדקס ויקיפדיה ומשרת את התגובה. מתייחס
model.py(נוצר חלק מהמחברת) לפרטים נוספים.model.pyמשתמש במחלקות המפתח הבאות:- OpenChatKitService - זה מטפל בהעברת הנתונים בין מודל GPT-NeoX, חיפוש Faiss ואובייקט שיחה.
WikipediaIndexוConversationאובייקטים מאותחלים ושיחות צ'אט קלט נשלחות לאינדקס כדי לחפש תוכן רלוונטי מויקיפדיה. זה גם יוצר מזהה ייחודי לכל הזמנה אם לא מסופק אחד לצורך אחסון ההנחיות ב אמזון דינמו. - ChatModel - מחלקה זו טוענת את הדגם והטוקניר ומייצר את התגובה. הוא מטפל בחלוקת המודל על פני מספר GPUs באמצעות
tensor_parallel_degree, ומגדיר את הdtypesוdevice_map. ההנחיות מועברות למודל כדי ליצור תגובות. קריטריון עצירהStopWordsCriteriaמוגדר עבור הדור לייצר רק את תגובת הבוט בהסקה. - ModationModel - אנו משתמשים בשני מודלים של מתינות ב-
ModerationModelclass: מודל הקלט כדי לציין למודל הצ'אט שהקלט אינו מתאים לעקוף את תוצאת ההסקה, ומודל הפלט כדי לעקוף את תוצאת ההסקה. אנו מסווגים את הנחיית הקלט ואת תגובת הפלט עם התוויות האפשריות הבאות:- אגבי
- צריך זהירות
- צריך התערבות (זה מסומן כמנחה על ידי המודל)
- אולי צריך זהירות
- כנראה צריך זהירות
- OpenChatKitService - זה מטפל בהעברת הנתונים בין מודל GPT-NeoX, חיפוש Faiss ואובייקט שיחה.
- wikipedia_prepare.py – קובץ זה מטפל בהורדה והכנת אינדקס ויקיפדיה. בפוסט זה, אנו משתמשים באינדקס של ויקיפדיה המסופק על מערכי נתונים של Hugging Face. כדי לחפש במסמכי ויקיפדיה טקסט רלוונטי, יש להוריד את האינדקס מ-Huging Face מכיוון שהוא לא ארוז במקום אחר. ה
wikipedia_prepare.pyהקובץ אחראי לטיפול בהורדה בעת הייבוא. רק תהליך בודד ברבוי הפועלים להסקה יכול לשכפל את המאגר. השאר ממתינים עד שהקבצים יהיו נוכחים במערכת הקבצים המקומית. - wikipedia.py – קובץ זה משמש לחיפוש באינדקס ויקיפדיה אחר מסמכים רלוונטיים מבחינה הקשרית. שאילתת הקלט מאוזנת והטמעות נוצרות באמצעות
mean_pooling. אנו מחשבים מדדי מרחק דמיון קוסינוס בין הטבעת השאילתה לאינדקס ויקיפדיה כדי לאחזר משפטי ויקיפדיה רלוונטיים מבחינה הקשרית. מתייחסwikipedia.pyלפרטי יישום.
- conversation.py – קובץ זה משמש לאחסון ואחזור שרשור השיחה ב-DynamoDB לצורך העברה לדגם ולמשתמש.
conversation.pyמותאם ממאגר OpenChatKit בקוד פתוח. קובץ זה אחראי על הגדרת האובייקט המאחסן את סיבובי השיחה בין האדם לדגם. בעזרת זה, המודל מסוגל לשמור סשן לשיחה, ולאפשר למשתמש להתייחס להודעות קודמות. מכיוון שקריאת נקודות הקצה של SageMaker הן חסרות מצב, השיחה הזו צריכה להיות מאוחסנת במיקום חיצוני למופעי נקודת הקצה. בעת ההפעלה, המופע יוצר טבלת DynamoDB אם היא לא קיימת. כל העדכונים לשיחה מאוחסנים אז ב-DynamoDB בהתבסס עלsession_idמפתח, אשר נוצר על ידי נקודת הקצה. כל הזמנה עם מזהה הפעלה תאחזר את מחרוזת השיחה המשויכת ותעדכן אותה כנדרש.
בנו מיכל להסקת LMI עם תלות מותאמות אישית
חיפוש האינדקס משתמש בזו של פייסבוק פייס ספרייה לביצוע חיפוש הדמיון. מכיוון שזה לא כלול בתמונת ה-LMI הבסיסית, יש להתאים את המיכל להתקנת ספרייה זו. הקוד הבא מגדיר Dockerfile שמתקין את Faiss מהמקור לצד ספריות אחרות הדרושות לנקודת הקצה של הבוט. אנו משתמשים ב- sm-docker כלי לבנייה ולדחוף את התמונה מרשם מיכל אלסטי של אמזון (Amazon ECR) מ סטודיו SageMaker של אמזון. מתייחס שימוש ב- Amazon SageMaker Studio Image Build CLI לבניית תמונות מיכל ממחברות הסטודיו שלך לקבלת פרטים נוספים.
ב-DJL מיכל לא מותקן Conda, ולכן יש לשבט את Faiss ולהרכיב מהמקור. כדי להתקין את Faiss, יש להתקין את התלות לשימוש בממשקי ה-API של BLAS ובתמיכה של Python. לאחר התקנת החבילות הללו, Faiss מוגדר להשתמש ב-AVX2 וב-CUDA לפני הידור עם הרחבות Python המותקנות.
pandas, fastparquet, boto3, ו git-lfs מותקנים לאחר מכן מכיוון שאלו נדרשים להורדה וקריאה של קבצי האינדקס.
צור את הדגם
כעת, כשיש לנו את תמונת ה-Docker באמזון ECR, אנו יכולים להמשיך ביצירת אובייקט המודל של SageMaker עבור דגמי OpenChatKit. אנחנו פורסים GPT-NeoXT-Chat-Base-20B שימוש במודלים של מתן קלט ופלט GPT-JT-Moderation-6B. מתייחס ליצור_מודל לקבלת פרטים נוספים.
הגדר את נקודת הקצה
לאחר מכן, אנו מגדירים את תצורות נקודות הקצה עבור דגמי OpenChatKit. אנו פורסים את המודלים באמצעות סוג המופע ml.g5.12xlarge. מתייחס create_endpoint_config לקבלת פרטים נוספים.
פרוס את נקודת הקצה
לבסוף, אנו יוצרים נקודת קצה באמצעות המודל ותצורת נקודת הקצה שהגדרנו בשלבים הקודמים:
הפעל מסקנות מדגמי OpenChatKit
עכשיו הגיע הזמן לשלוח בקשות הסקת מסקנות לדגם ולקבל את התגובות. אנו מעבירים את בקשת טקסט הקלט ואת פרמטרי המודל כגון temperature, top_k, ו max_new_tokens. האיכות של תגובות הצ'אטבוט מבוססת על הפרמטרים שצוינו, לכן מומלץ למדוד את ביצועי המודל מול פרמטרים אלה כדי למצוא את ההגדרה האופטימלית עבור מקרה השימוש שלך. הנחית הקלט נשלחת תחילה למודל ניהול הקלט, והפלט נשלח אל ChatModel ליצור את התגובות. במהלך שלב זה, המודל משתמש באינדקס ויקיפדיה כדי לאחזר קטעים רלוונטיים מבחינה הקשרית למודל בתור הנחיה לקבל תגובות ספציפיות לתחום מהמודל. לבסוף, תגובת המודל נשלחת למודל מתן הפלט כדי לבדוק סיווג, ולאחר מכן התגובות מוחזרות. ראה את הקוד הבא:
עיין לדוגמאות של אינטראקציות צ'אט להלן.

לנקות את
עקוב אחר ההוראות בסעיף הניקוי של כדי למחוק את המשאבים שסופקו כחלק מפוסט זה כדי למנוע חיובים מיותרים. מתייחס תמחור SageMaker של אמזון לפרטים על עלות מקרי ההסקה.
סיכום
בפוסט זה, דנו בחשיבותם של LLMs בקוד פתוח וכיצד לפרוס מודל OpenChatKit ב- SageMaker לבניית יישומי צ'אטבוט מהדור הבא. דנו ברכיבים שונים של מודלים של OpenChatKit, מודלים לניהול וכיצד להשתמש במקור ידע חיצוני כמו ויקיפדיה עבור זרימות עבודה של אחזור דור מוגבר (RAG). תוכל למצוא הוראות שלב אחר שלב ב- מחברת GitHub. ספר לנו על יישומי הצ'טבוט המדהימים שאתה בונה. לחיים!
על הכותבים
 דוואל פאטל הוא אדריכל ראשי למידת מכונה ב-AWS. הוא עבד עם ארגונים החל מארגונים גדולים ועד סטארט-אפים בינוניים על בעיות הקשורות למחשוב מבוזר ובינה מלאכותית. הוא מתמקד בלמידה עמוקה כולל תחומי NLP ו-Computer Vision. הוא עוזר ללקוחות להשיג מסקנות מודל עם ביצועים גבוהים על SageMaker.
דוואל פאטל הוא אדריכל ראשי למידת מכונה ב-AWS. הוא עבד עם ארגונים החל מארגונים גדולים ועד סטארט-אפים בינוניים על בעיות הקשורות למחשוב מבוזר ובינה מלאכותית. הוא מתמקד בלמידה עמוקה כולל תחומי NLP ו-Computer Vision. הוא עוזר ללקוחות להשיג מסקנות מודל עם ביצועים גבוהים על SageMaker.
 ויקראם אלנגו הוא אדריכל פתרונות מומחה AIML Sr. AIML ב-AWS, שבסיסו בווירג'יניה, ארה"ב. כיום הוא מתמקד בבינה מלאכותית, LLMs, הנדסה מיידית, אופטימיזציה של מודלים גדולים והרחבת ML בין ארגונים. Vikram עוזרת ללקוחות תעשיית הפיננסים והביטוח עם תכנון ומנהיגות מחשבתית לבנות ולפרוס יישומי למידת מכונה בקנה מידה. בזמנו הפנוי, הוא נהנה לטייל, לטייל, לבשל ולקמפינג עם משפחתו.
ויקראם אלנגו הוא אדריכל פתרונות מומחה AIML Sr. AIML ב-AWS, שבסיסו בווירג'יניה, ארה"ב. כיום הוא מתמקד בבינה מלאכותית, LLMs, הנדסה מיידית, אופטימיזציה של מודלים גדולים והרחבת ML בין ארגונים. Vikram עוזרת ללקוחות תעשיית הפיננסים והביטוח עם תכנון ומנהיגות מחשבתית לבנות ולפרוס יישומי למידת מכונה בקנה מידה. בזמנו הפנוי, הוא נהנה לטייל, לטייל, לבשל ולקמפינג עם משפחתו.
 אנדרו סמית הוא מהנדס תמיכה בענן בצוות SageMaker, Vision & Other ב-AWS, שבסיסו בסידני, אוסטרליה. הוא תומך בלקוחות המשתמשים בשירותי AI/ML רבים ב-AWS עם מומחיות בעבודה עם Amazon SageMaker. מחוץ לעבודה, הוא נהנה לבלות עם חברים ובני משפחה וכן ללמוד על טכנולוגיות שונות.
אנדרו סמית הוא מהנדס תמיכה בענן בצוות SageMaker, Vision & Other ב-AWS, שבסיסו בסידני, אוסטרליה. הוא תומך בלקוחות המשתמשים בשירותי AI/ML רבים ב-AWS עם מומחיות בעבודה עם Amazon SageMaker. מחוץ לעבודה, הוא נהנה לבלות עם חברים ובני משפחה וכן ללמוד על טכנולוגיות שונות.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- EVM Finance. ממשק מאוחד למימון מבוזר. גישה כאן.
- Quantum Media Group. IR/PR מוגבר. גישה כאן.
- PlatoAiStream. Web3 Data Intelligence. הידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/build-custom-chatbot-applications-using-openchatkit-models-on-amazon-sagemaker/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 1
- 10
- 100
- 11
- 14
- 15%
- 17
- 195
- 20
- 2023
- 30
- 40
- 8
- a
- יכולת
- יכול
- אודות
- להאיץ
- גישה
- דיוק
- במדויק
- להשיג
- לרוחב
- מותאם
- נוסף
- בנוסף
- כתובת
- מתקדם
- לאחר
- לאחר מכן
- נגד
- AI
- מקרי שימוש
- AI / ML
- AIML
- ליישר
- תעשיות
- מאפשר
- מאפשר
- לאורך
- בַּצַד
- גם
- למרות
- מדהים
- אמזון בעברית
- אמזון SageMaker
- סטודיו SageMaker של אמזון
- אמזון שירותי אינטרנט
- an
- לנתח
- ו
- לענות
- תשובות
- כל
- API
- ממשקי API
- בקשה
- יישומים
- החל
- APT
- ארכיטקטורה
- ארכיון
- ARE
- מאמרים
- מלאכותי
- בינה מלאכותית
- AS
- המשויך
- At
- מוגבר
- אוסטרליה
- באופן אוטומטי
- זמין
- לְהִמָנַע
- AWS
- בסיס
- מבוסס
- Baseline
- BE
- כי
- להיות
- הופך להיות
- לפני
- להיות
- להלן
- בנצ 'מרק
- בֵּין
- הטיות
- BIN
- אבני
- גוּף
- בוט
- שניהם
- לִבנוֹת
- בנה צ'אט בוט
- בִּניָן
- נבנה
- ניטל
- עסקים
- יישומים עסקיים
- by
- שיחה
- קמפינג
- CAN
- קיבולת
- פַּחמָן
- מקרה
- מקרים
- CD
- חיובים
- chatbot
- chatbots
- לבדוק
- בכיתה
- כיתות
- מיון
- לסווג
- סגור
- ענן
- CO
- קוד
- שיתוף פעולה
- קהילה
- חברות
- הענות
- רכיבים
- מַקִיף
- לחשב
- המחשב
- ראייה ממוחשבת
- מחשוב
- דאגות
- תְצוּרָה
- תצורות
- מוגדר
- מכולה
- מכולות
- מכיל
- תוכן
- הקשר
- לתרום
- לִשְׁלוֹט
- בקרות
- שיחה
- שיחות
- בישול
- תוֹאֵם
- עלות
- לִיצוֹר
- נוצר
- יוצר
- יוצרים
- הקריטריונים
- נוֹכְחִי
- כיום
- מנהג
- לקוחות
- אישית
- אישית
- נתונים
- מהנדס נתונים
- מערכי נתונים
- עמוק
- למידה עמוקה
- מוגדר
- מגדיר
- הגדרה
- תואר
- דרישות
- דמוקרטיזציה
- להפגין
- הפגנה
- תלוי
- לפרוס
- פריסה
- עיצוב
- מעוצב
- פרטים
- מפתחים
- התפתחויות
- התקנים
- אחר
- קשה
- קשיים
- לדון
- נָדוֹן
- מרחק
- מופץ
- מחשוב מבוזר
- do
- סַוָר
- מסמך
- תיעוד
- מסמכים
- עושה
- לא
- מַבחֵשׁ
- תחום
- תחומים
- לא
- להורדה
- הורדות
- בְּמַהֲלָך
- באופן דינמי
- כל אחד
- אחר
- במקום אחר
- הטבעה
- מוּעֳסָק
- מאפשר
- מה שמאפשר
- פְּגִישָׁה
- מעודד את
- נקודת קצה
- לאכוף
- מנוע
- מהנדס
- הנדסה
- חברות
- שלם
- כניסה
- חיוני
- Ether (ETH)
- אֶתִי
- אי פעם
- דוגמה
- להתקיים
- מצפה
- מומחיות
- סיומות
- חיצוני
- מאוד
- פָּנִים
- עובד
- משפחה
- אופנה
- שלח
- קבצים
- לסנן
- סינון
- בסופו של דבר
- כספי
- חדשות פיננסיות
- מוצרים פיננסיים
- ראשון
- מסומן
- מרוכז
- מתמקד
- התמקדות
- לעקוב
- הבא
- כדלקמן
- בעד
- פוּרמָט
- לטפח
- ארבע
- חברים
- החל מ-
- לגמרי
- פונקציונלי
- מטרה כללית
- ליצור
- נוצר
- מייצר
- דור
- גנרטטיבית
- AI Generative
- לקבל
- Git
- נתן
- טוב
- GPU
- GPUs
- מטפל
- טיפול
- חומרה
- יש
- he
- עוזר
- גָבוֹהַ
- ביצועים גבוהים
- טיולים
- שֶׁלוֹ
- המארח
- אירח
- אירוח
- איך
- איך
- HTML
- http
- HTTPS
- חיבוק פנים
- בן אנוש
- ID
- לזהות
- if
- מדגים
- תמונה
- תמונות
- הפעלה
- מיישמים
- לייבא
- חשיבות
- חשוב
- השבחה
- in
- כלול
- כולל
- בע"מ
- גדל
- מדד
- להצביע
- מצביע על
- תעשיות
- תעשייה
- מידע
- ייזום
- חדשנות
- קלט
- תשומות
- בתוך
- תובנות
- להתקין
- מותקן
- למשל
- הוראות
- ביטוח
- תעשיית הביטוח
- לשלב
- מוֹדִיעִין
- יחסי גומלין
- פנימי
- התערבות
- אל תוך
- השקעה
- המלצות השקעה
- מעורב
- IT
- שֶׁלָה
- עצמו
- Java
- jpg
- ג'סון
- מחברת צדק
- מפתח
- לדעת
- ידע
- תוויות
- שפה
- גָדוֹל
- מפעלים גדולים
- חֶבִיוֹן
- מנהיגות
- למידה
- הכי פחות
- משפטי
- תנופה
- ספריות
- סִפְרִיָה
- רישיון
- כמו
- להגביל
- רשימה
- לאמה
- המון
- מקומי
- מיקום
- הגיון
- מגרש
- נמוך
- מכונה
- למידת מכונה
- עשוי
- ראשי
- לעשות
- עשייה
- רב
- צעדה
- שוק
- סנטימנט שוק
- טרנדים בשוק
- מסכה
- תואם
- לִפְגוֹשׁ
- הודעות
- שיטות
- מדדים
- מִילִיוֹן
- ML
- מודל
- מודלים
- בינוני
- מתינות
- מודול
- צג
- יותר
- מספר
- שם
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- הכרחי
- צורך
- נחוץ
- צרכי
- שלילי
- חדשות
- הדור הבא
- NLP
- לא
- מחברה
- מספר
- רב
- אובייקט
- אובייקטים
- מכשולים
- להשיג
- of
- הַצָעָה
- on
- ONE
- רק
- קוד פתוח
- אופטימלי
- אופטימיזציה
- אפשרות
- אפשרויות
- or
- ארגון
- ארגונים
- OS
- אחר
- הַחוּצָה
- תפוקה
- בחוץ
- יותר
- לעקוף
- שֶׁלוֹ
- חבילה
- ארוז
- חבילות
- דובי פנדה
- ניירות
- מקביל
- פרמטר
- פרמטרים
- חלק
- לעבור
- עבר
- חולף
- נתיב
- תבנית
- ביצועים
- ביצוע
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודה
- פופולרי
- אפשרי
- הודעה
- פוטנציאל
- מופעל
- חזק
- לחזות
- התחזיות
- העריכה
- להציג
- מוצג
- קודם
- מנהל
- בעיות
- תהליך
- תהליך
- לייצר
- מוצרים
- תכנות
- נכסים
- לספק
- ובלבד
- מספק
- מתן
- מטרה
- דחוף
- פיתון
- פיטורך
- איכות
- שאלה
- שאלות
- רכס
- טִוּוּחַ
- קריאה
- סיבות
- מקבל
- מתכונים
- המלצות
- מוּמלָץ
- הפחתה
- קָשׁוּר
- שוחרר
- רלוונטי
- שְׂרִידִים
- ראוי לציון
- דוחות לדוגמא
- מאגר
- לבקש
- בקשות
- נדרש
- מחקר
- חוקרים
- משאבים
- תגובה
- תגובות
- אחראי
- REST
- מוגבל
- תוצאה
- תוצאות
- לִשְׁמוֹר
- לַחֲזוֹר
- הפעלה
- ריצה
- פועל
- בְּטִיחוּת
- בעל חכמים
- סולם
- דרוג
- חיפוש
- חיפוש
- סעיף
- סעיפים
- לִרְאוֹת
- לשלוח
- נשלח
- משפט
- רגש
- לשרת
- משמש
- שירותים
- הגשה
- מושב
- סט
- הצבה
- הגדרות
- צריך
- לְהַצִיג
- פָּשׁוּט
- since
- יחיד
- במידה ניכרת
- מידה
- תמונת בזק
- So
- פִּתָרוֹן
- פתרונות
- כמה
- מתוחכם
- מָקוֹר
- מקורות
- מומחה
- מיוחד
- ספציפי
- מפורט
- מְהִירוּת
- הוצאה
- החל
- סטארט - אפ
- חברות סטארט
- שלב
- צעדים
- סְתִימָה
- אחסון
- מאוחסן
- חנויות
- מחרוזת
- סטודיו
- בהצלחה
- כזה
- סובל
- לסכם
- שסופק
- אספקה
- תמיכה
- תומך
- סידני
- מערכת
- שולחן
- המשימות
- משימות
- נבחרת
- טכניקות
- טכנולוגיות
- טכנולוגיה
- זֶה
- השמיים
- המקור
- שֶׁלָהֶם
- אותם
- אז
- שם.
- בכך
- לכן
- אלה
- זֶה
- מחשבה
- מנהיגות מחשבתית
- תפוקה
- זמן
- ל
- יַחַד
- token
- כלים
- מְאוּמָן
- הדרכה
- שקיפות
- נסיעה
- מגמות
- נָכוֹן
- פונה
- שתיים
- סוג
- תחת
- להבין
- ייחודי
- אוניברסלי
- עד
- עדכון
- מְעוּדכָּן
- עדכונים
- נטען
- URI
- us
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמש
- משתמשים
- שימושים
- באמצעות
- תועלת
- ערך
- שונים
- VICUNA
- וירג'יניה
- חזון
- לחכות
- רוצה
- we
- אינטרנט
- שירותי אינטרנט
- טוֹב
- מה
- מתי
- אשר
- רָחָב
- טווח רחב
- ויקיפדיה
- יצטרך
- עם
- לְלֹא
- תיק עבודות
- עבד
- עובד
- עובדים
- זרימת עבודה
- זרימות עבודה
- עובד
- עובד
- היה
- X
- אתה
- זפירנט