מחקרים בשנים האחרונות הראו שמודלים של למידת מכונה (ML) פגיעים תשומות יריבות, שבו יריב יכול ליצור תשומות כדי לשנות אסטרטגית את הפלט של המודל (ב סיווג תמונה, זיהוי דיבור, או גילוי הונאה). לדוגמה, דמיינו שפרסתם מודל שמזהה את העובדים שלכם על סמך תמונות הפנים שלהם. כפי שהוכח במאמר הלבן אביזר לפשע: התקפות אמיתיות וחמקניות על זיהוי פנים עדכני, עובדים זדוניים עשויים להחיל שינויים עדינים אך מתוכננים בקפידה בתדמית שלהם ולהטעות את המודל כדי לאמת אותם כעובדים אחרים. ברור שלתשומות יריבות כאלה - במיוחד אם יש כמות משמעותית מהן - יכולה להיות השפעה עסקית הרסנית.
באופן אידיאלי, אנו רוצים לזהות בכל פעם שנשלחת קלט יריבות למודל כדי לכמת כיצד קלט יריבות משפיע על המודל והעסק שלך. לשם כך, מחלקה רחבה של שיטות מנתחת תשומות של מודלים בודדים כדי לבדוק התנהגות יריבות. עם זאת, מחקר פעיל ב-ML יריבות הוביל לתשומות יריבות מתוחכמות יותר ויותר, שרבים מהם ידועים כגורמים לאיתור יעיל. הסיבה לחסרון הזה היא שקשה להסיק מסקנות אישיות אם זה יריב או לא. לשם כך, מחלקה עדכנית של שיטות מתמקדת בבדיקות ברמת התפלגות על ידי ניתוח תשומות מרובות בו-זמנית. הרעיון המרכזי מאחורי השיטות החדשות הללו הוא שבחינת תשומות מרובות בו-זמנית מאפשרת ניתוח סטטיסטי חזק יותר שאינו אפשרי עם תשומות בודדות. עם זאת, מול יריב נחוש עם היכרות מעמיקה עם המודל, אפילו שיטות הזיהוי המתקדמות הללו עלולות להיכשל.
עם זאת, אנו יכולים להביס אפילו את היריבים הנחושים הללו על ידי מתן מידע נוסף לשיטות ההגנה. באופן ספציפי, במקום רק לנתח את תשומות המודל, ניתוח הייצוגים הסמויים שנאספו משכבות הביניים ברשת עצבית עמוקה מחזק משמעותית את ההגנה.
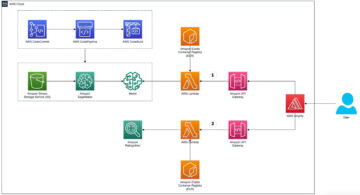
בפוסט זה, אנו מדריכים אותך כיצד לזהות תשומות יריבות באמצעות אמזון SageMaker דגם צג ו באגים של SageMaker באמזון עבור מודל סיווג תמונה המתארח ב אמזון SageMaker.
כדי לשחזר את השלבים והתוצאות השונים המפורטים בפוסט זה, שכפל את המאגר זיהוי-דגימות-יריבות-באמצעות-מרווה לתוך מופע המחברת של Amazon SageMaker והפעל את המחברת.
זיהוי תשומות יריבות
אנו מראים לך כיצד לזהות תשומות יריבות באמצעות הייצוגים שנאספו מרשת עצבית עמוקה. ארבע התמונות הבאות מציגות את תמונת האימון המקורית משמאל (נלקחה ממערך הנתונים של Tiny ImageNet) ושלוש תמונות שהופקו על ידי התקפת Projected Gradient Descent (PGD) [1] עם פרמטרי הפרעה שונים ϵ. המודל המשמש כאן היה ResNet18. הפרמטר ϵ מגדיר את כמות הרעש היריב שנוסף לתמונות. התמונה המקורית (משמאל) חזויה בצורה נכונה כמחלקה 67 (goose). התמונות 2, 3 ו-4 ששונו באופן יריב צפויות באופן שגוי כמחלקה 51 (mantis) על ידי דגם ResNet18. אנו יכולים גם לראות שתמונות שנוצרות עם ϵ קטן אינן ניתנות להבדלה תפיסתית מתמונת הקלט המקורית.

לאחר מכן, אנו יוצרים קבוצה של תמונות נורמליות ונגדיות ומשתמשים בהן t-Distributed Stochastic Neighbor Embedding (t-SNE [2]) כדי להשוות חזותית את ההפצות שלהם. t-SNE היא שיטת הפחתת מימד הממפה נתונים בעלי ממדים גבוהים לתוך מרחב דו- או תלת מימדי. כל נקודת נתונים בתמונה הבאה מציגה תמונת קלט. נקודות נתונים כתומות מציגות את התשומות הרגילות שנלקחו ממערך הבדיקה, ונקודות נתונים כחולות מציינות את התמונות הנגדיות המתאימות שנוצרו עם אפסילון של 2. אם ניתן להבחין בין תשומות נורמליות ונגדיות, היינו מצפים לאשכולות נפרדים בהדמיה של t-SNE. מכיוון ששניהם שייכים לאותו אשכול, משמעות הדבר היא שטכניקת זיהוי המתמקדת אך ורק בשינויים בהתפלגות הקלט של המודל אינה יכולה להבחין בין התשומות הללו.

בואו נסתכל מקרוב על ייצוגי השכבות המיוצרים על ידי שכבות שונות במודל ResNet18. ResNet18 מורכב מ-18 שכבות; בתמונה הבאה, אנו מדמיינים את הטבעות t-SNE עבור הייצוגים עבור שש מהשכבות הללו.

כפי שהאיור הקודם מראה, תשומות טבעיות ונגדיות הופכות להבדלות יותר עבור שכבות עמוקות יותר של מודל ResNet18.
בהתבסס על תצפיות אלו, אנו משתמשים בשיטה סטטיסטית המודדת את יכולת ההבחנה באמצעות בדיקת השערות. השיטה מורכבת מא מבחן שני מדגמים באמצעות אי התאמה ממוצעת מקסימלית (MMD). MMD הוא מדד מבוסס ליבה למדידת הדמיון בין שתי הפצות המייצרות את הנתונים. בדיקה של שני מדגמים לוקחת שתי קבוצות המכילות תשומות שנלקחו משתי התפלגויות, וקובעת אם ההתפלגויות הללו זהות. אנו משווים את התפלגות התשומות שנצפו בנתוני האימון ומשווים אותה עם התפלגות התשומות שהתקבלו במהלך ההסקה.
השיטה שלנו משתמשת בתשומות אלה כדי להעריך את ערך ה-p באמצעות MMD. אם ערך ה-p גדול מסף מובהקות ספציפי למשתמש (5% במקרה שלנו), אנו מסיקים ששתי ההתפלגויות שונות. הסף מכוון את ההחלפה בין חיוביות שגויות לשליליות שגויות. סף גבוה יותר, כגון 10%, מקטין את השיעור שלילי כוזב (יש פחות מקרים שבהם שתי ההתפלגויות היו שונות אך הבדיקה לא הצליחה להצביע על כך). עם זאת, זה גם מביא ליותר תוצאות חיוביות שגויות (הבדיקה מצביעה על כך ששתי ההתפלגויות שונות גם כשזה לא המקרה). מצד שני, סף נמוך יותר, כמו 1%, מביא לפחות תוצאות שגויות אבל יותר תוצאות שווא.
במקום ליישם שיטה זו רק על תשומות המודל הגולמי (תמונות), אנו משתמשים בייצוגים הסמויים המיוצרים על ידי שכבות הביניים של המודל שלנו. כדי להסביר את האופי ההסתברותי שלו, אנו מיישמים את מבחן ההשערה 100 פעמים על 100 תשומות טבעיות שנבחרו באקראי ו-100 תשומות יריבות שנבחרו באקראי. לאחר מכן אנו מדווחים על שיעור הגילוי כאחוז הבדיקות שהביאו לאירוע זיהוי בהתאם לסף המובהקות שלנו של 5%. שיעור הזיהוי הגבוה יותר מהווה אינדיקציה חזקה יותר לכך ששתי ההתפלגויות שונות. הליך זה נותן לנו את שיעורי הזיהוי הבאים:
- שכבה 1: 3%
- שכבה 4: 7%
- שכבה 8: 84%
- שכבה 12: 95%
- שכבה 14: 100%
- שכבה 15: 100%
בשכבות הראשוניות קצב הזיהוי נמוך למדי (פחות מ-10%), אך עולה ל-100% בשכבות העמוקות יותר. באמצעות המבחן הסטטיסטי, השיטה יכולה לזהות בביטחון תשומות יריבות בשכבות עמוקות יותר. לעתים קרובות מספיק פשוט להשתמש בייצוגים שנוצרו על ידי השכבה הלפני אחרונה (השכבה האחרונה לפני שכבת הסיווג במודל). עבור תשומות יריבות מתוחכמות יותר, כדאי להשתמש בייצוגים משכבות אחרות ולצבור את שיעורי הזיהוי.
סקירת פתרונות
בסעיף הקודם, ראינו כיצד לזהות תשומות יריבות באמצעות ייצוגים מהשכבה הלפני אחרונה. לאחר מכן, אנו מראים כיצד להפוך את הבדיקות הללו לאוטומטיות ב- SageMaker באמצעות Model Monitor ו-Debugger. עבור דוגמה זו, אנו מאמנים תחילה מודל ResNet18 לסיווג תמונה על מערך הנתונים הקטן של ImageNet. לאחר מכן, אנו פורסים את המודל ב- SageMaker ויוצרים לוח זמנים מותאם אישית של Model Monitor המריץ את הבדיקה הסטטיסטית. לאחר מכן, אנו מריצים מסקנות עם תשומות נורמליות ונגדיות כדי לראות עד כמה השיטה יעילה.
לכיד טנסורים באמצעות Debugger
במהלך אימון המודל, אנו משתמשים ב-Debugger כדי ללכוד ייצוגים שנוצרו על ידי השכבה הלפני אחרונה, המשמשים מאוחר יותר כדי להפיק מידע על התפלגות התשומות הרגילות. Debugger הוא תכונה של SageMaker המאפשרת לך ללכוד ולנתח מידע כגון פרמטרים של מודל, שיפועים והפעלות במהלך אימון המודל. טנסור הפרמטרים, השיפוע וההפעלה הללו מועלים אל שירות אחסון פשוט של אמזון (Amazon S3) בזמן שהאימון בעיצומו. אתה יכול להגדיר כללים שמנתחים אותם לבעיות כמו התאמת יתר ושיפועים נעלמים. במקרה השימוש שלנו, אנחנו רוצים ללכוד רק את השכבה הלפני אחרונה של הדגם (.*avgpool_output) ותפוקות המודל (תחזיות). אנו מציינים תצורת Debugger hook המגדירה ביטוי רגולרי עבור ייצוגי השכבה שייאסוף. אנו מציינים גם א save_interval שמנחה את Debugger לאסוף את הנתונים הללו במהלך שלב האימות כל 100 מעברים קדימה. ראה את הקוד הבא:
הפעל אימון SageMaker
אנו מעבירים את תצורת Debugger לאומדן SageMaker ומתחילים את ההדרכה:
פרוס מודל סיווג תמונה
לאחר השלמת הכשרת המודל, אנו פורסים את המודל כנקודת קצה ב- SageMaker. אנו מציינים א תסריט מסקנות שמגדיר את model_fn ו transform_fn פונקציות. פונקציות אלה מציינות כיצד המודל נטען וכיצד יש לעבד נתונים נכנסים מראש כדי לבצע את מסקנת המודל. במקרה השימוש שלנו, אנו מאפשרים ל-Debugger ללכוד נתונים רלוונטיים במהלך ההסקה. בתוך ה model_fn פונקציה, אנו מציינים Hook Debugger ו-a save_config שמציין כי עבור כל בקשת מסקנות, קלט המודל (תמונות), פלטי המודל (חיזויים) והשכבה הלפני אחרונה נרשמות (.*avgpool_output). לאחר מכן אנו רושמים את הקרס על הדגם. ראה את הקוד הבא:
כעת אנו פורסים את המודל, שאנו יכולים לעשות מהמחברת בשתי דרכים. אנחנו יכולים להתקשר pytorch_estimator.deploy() או צור מודל PyTorch שמצביע על קבצי חפצי המודל ב-Amazon S3 שנוצרו על ידי עבודת ההדרכה של SageMaker. בפוסט הזה, אנחנו עושים את האחרון. זה מאפשר לנו להעביר משתני סביבה לתוך קונטיינר Docker, אשר נוצר ונפרס על ידי SageMaker. אנחנו צריכים את משתנה הסביבה tensors_output להגיד לתסריט לאן להעלות את הטנזורים שנאספים על ידי SageMaker Debugger במהלך ההסקה. ראה את הקוד הבא:
לאחר מכן, אנו פורסים את המנבא על סוג מופע ml.m5.xlarge:
צור לוח זמנים מותאם אישית של Model Monitor
כאשר נקודת הקצה פועלת, אנו יוצרים לוח זמנים מותאם אישית של Model Monitor. זה עבודת עיבוד SageMaker שפועל במרווח תקופתי (כגון שעתי או יומי) ומנתח את נתוני ההסקה. Model Monitor מספק קונטיינר מוגדר מראש המנתח ומזהה סחיפה של נתונים. במקרה שלנו, אנו רוצים להתאים אותו כדי להביא את נתוני Debugger ולהריץ את מבחן ה-MMD בשתי דגימות על ייצוגי השכבות שאוחזרו.
כדי להתאים אותו, אנו מגדירים תחילה את האובייקט Model Monitor, אשר מציין באיזה סוג מופע יפעלו המשימות הללו ואת המיקום של מיכל ה-Model Monitor המותאם אישית שלנו:
אנחנו רוצים להפעיל את העבודה הזו על בסיס שעתי, אז אנו מפרטים CronExpressionGenerator.hourly() ואת מיקומי הפלט שאליהם מועלות תוצאות הניתוח. בשביל זה אנחנו צריכים להגדיר ProcessingOutput עבור פלט העיבוד של SageMaker:
בואו נסתכל מקרוב על מה פועל מיכל הדגם המותאם אישית שלנו. אנחנו יוצרים א תסריט הערכה, אשר טוען את הנתונים שנלכדו על ידי Debugger. אנחנו גם יוצרים א חפץ משפט, המאפשר לנו לגשת, לבצע שאילתות ולסנן את הנתונים ש-Debugger שמר. עם אובייקט הניסיון, אנו יכולים לעבור על השלבים שנשמרו במהלך שלבי ההסקה וההדרכה trial.steps(mode).
ראשית, אנו מביאים את פלטי המודל (trial.tensor("ResNet_output_0")) כמו גם השכבה הלפני אחרונה (trial.tensor_names(regex=".*avgpool_output")). אנו עושים זאת עבור שלבי ההסקה והאימות של האימון (modes.EVAL ו modes.PREDICT). הטנזורים משלב האימות משמשים כאומדן של ההתפלגות הנורמלית, שבה אנו משתמשים לאחר מכן כדי להשוות את התפלגות נתוני ההסקה. יצרנו כיתה לאדיס (זיהוי התפלגות קלט יריבות באמצעות סטטיסטיקה שכבתית). מחלקה זו מספקת את הפונקציונליות הרלוונטית לביצוע מבחן שני הדגימות. הוא לוקח את רשימת הטנזורים משלבי ההסקה והאימות ומריץ את מבחן שני הדגימות. הוא מחזיר שיעור זיהוי, שהוא ערך שבין 0-100%. ככל שהערך גבוה יותר, כך גדל הסיכוי שנתוני המסקנות עוקבים אחר התפלגות אחרת. יתרה מזאת, אנו מחשבים ציון עבור כל מדגם המציין את מידת הסבירות שהדגימה תהיה אדוורסרית ו-100 הדגימות המובילות נרשמות, כדי שמשתמשים יוכלו לבדוק אותן עוד יותר. ראה את הקוד הבא:
בדיקה מול תשומות יריבות
כעת, לאחר שנפרס לוח הזמנים המותאם אישית של מוניטור המודלים שלנו, אנו יכולים להפיק כמה תוצאות מסקנות.
ראשית, אנו פועלים עם נתונים מקבוצת ה-holdout ולאחר מכן עם קלט יריבות:
לאחר מכן נוכל לבדוק את תצוגת צג הדגם סטודיו SageMaker של אמזון או שימוש אמזון CloudWatch יומנים כדי לראות אם נמצאה בעיה.

לאחר מכן, אנו משתמשים בתשומות האדוורסריות מול הדגם המתארח ב- SageMaker. אנו משתמשים במערך הבדיקה של מערך הנתונים Tiny ImageNet ומיישמים את מתקפת ה-PGD, שמציגה הפרעות ברמת הפיקסלים כך שהמודל לא מזהה מחלקות נכונות. בתמונות הבאות, העמודה השמאלית מציגה שתי תמונות בדיקה מקוריות, העמודה האמצעית מציגה את הגרסאות המופרעות שלהן, והעמודה הימנית מציגה את ההבדל בין שתי התמונות.

כעת אנו יכולים לבדוק את מצב ה-Model Monitor ולראות שחלק מתמונות ההסקה נמשכו מהפצה אחרת.

תוצאות ופעולת המשתמש
עבודת ה-Model Monitor המותאמת אישית קובעת ציונים עבור כל בקשת הסקת מסקנות, מה שמציין את מידת הסיכוי שהדגימה תהיה מתנגדת לפי מבחן ה-MMD. ציונים אלה נאספים עבור כל בקשות ההסקה. הציון שלהם עם מספר שלב Debugger המתאים נרשם בקובץ JSON ומועלה לאמזון S3. לאחר השלמת עבודת ניטור המודל, אנו מורידים את קובץ ה-JSON, מאחזרים מספרי צעדים ומשתמשים ב-Debugger כדי לאחזר את כניסות המודל התואמות לשלבים אלו. זה מאפשר לנו לבדוק את התמונות שזוהו כמתנגדות.
בלוק הקוד הבא משרטט את שתי התמונות הראשונות שזוהו כבעל הסבירות הגבוהה ביותר להיות יריבות:
בהפעלת המבחן לדוגמה שלנו, אנו מקבלים את הפלט הבא. תמונת המדוזה נחזה בצורה שגויה כתפוז, ותמונת הגמל כפנדה. ברור שהמודל נכשל בתשומות הללו ואפילו לא חזה מעמד תמונה דומה, כמו דג זהב או סוס. לשם השוואה, אנו מציגים גם את הדגימות הטבעיות המתאימות ממערך הבדיקות בצד ימין. אנו יכולים לראות שההפרעות האקראיות שהציג התוקף נראות מאוד ברקע של שתי התמונות.


עבודת ה-Model Monitor המותאמת אישית מפרסמת את קצב הזיהוי ל-CloudWatch, כך שנוכל לחקור כיצד קצב זה השתנה לאורך זמן. שינוי משמעותי בין שתי נקודות נתונים עשוי להצביע על כך שיריב ניסה לרמות את המודל בפרק זמן מסוים. בנוסף, תוכל גם לשרטט את מספר בקשות ההסקה המעובדות בכל עבודה של Model Monitor ואת קצב הזיהוי הבסיסי, המחושב על מערך האימות. שיעור הבסיס הוא בדרך כלל קרוב ל-0 ומשמש רק כמדד השוואה.
צילום המסך הבא מציג את המדדים שנוצרו על ידי ריצות הבדיקה שלנו, שהריצו שלוש עבודות ניטור מודלים במשך 3 שעות. כל עבודה מעבדת כ-200-300 בקשות להסיק בכל פעם. שיעור הזיהוי הוא 100% בין 5:00 ל-6:00, ויורד לאחר מכן.

יתר על כן, אנו יכולים גם לבדוק את התפלגות הייצוגים שנוצרו על ידי שכבות הביניים של המודל. עם Debugger, אנו יכולים לגשת לנתונים משלב האימות של עבודת ההדרכה ולטנסורים משלב ההסקה, ולהשתמש ב-t-SNE כדי לדמיין את התפלגותם עבור שיעורים חזויים מסוימים. ראה את הקוד הבא:
במקרה המבחן שלנו, אנו מקבלים את ההדמיה הבאה של t-SNE עבור מחלקת התמונה השנייה. אנו יכולים להבחין שהדגימות האדוורסריות מקובצות בצורה שונה מהדגימות הטבעיות.

<br> סיכום
בפוסט זה, הראינו כיצד להשתמש במבחן שני מדגמים תוך שימוש באי התאמה ממוצעת מקסימלית כדי לזהות תשומות יריבות. הדגמנו כיצד ניתן לפרוס מנגנוני זיהוי כאלה באמצעות Debugger ו-Model Monitor. זרימת עבודה זו מאפשרת לך לנטר את הדגמים שלך המתארחים ב- SageMaker בקנה מידה ולזהות קלט יריבות באופן אוטומטי. כדי ללמוד עוד על זה, בדוק את שלנו GitHub ריפו.
הפניות
[1] אלכסנדר מדרי, אלכסנדר מקלוב, לודוויג שמידט, דימיטריס ציפראס ואדריאן ולאדו. לקראת מודלים של למידה עמוקה עמידים בפני התקפות יריבות. ב ועידה בינלאומית לייצוגי למידה 2018.
[2] לורנס ואן דר מאטן וג'פרי הינטון. הדמיית נתונים באמצעות t-SNE. Journal of Machine Learning Research, 9:2579–2605, 2008. URL http://www.jmlr.org/papers/v9/vandermaaten08a.html.
על הכותבים
 נטלי ראושמאייר היא מדענית שימושית בכירה ב-AWS, שם היא עוזרת ללקוחות לפתח יישומי למידה עמוקה.
נטלי ראושמאייר היא מדענית שימושית בכירה ב-AWS, שם היא עוזרת ללקוחות לפתח יישומי למידה עמוקה.
 יגיטקן קאיה הוא דוקטורנט שנה חמישית באוניברסיטת מרילנד ומתמחה במדען יישומי ב-AWS, שעובד על אבטחת למידת מכונה ויישומים של למידת מכונה לאבטחה.
יגיטקן קאיה הוא דוקטורנט שנה חמישית באוניברסיטת מרילנד ומתמחה במדען יישומי ב-AWS, שעובד על אבטחת למידת מכונה ויישומים של למידת מכונה לאבטחה.
 בילאל צפר הוא מדען יישומי ב-AWS, עובד על הוגנות, הסבר ואבטחה בלמידת מכונה.
בילאל צפר הוא מדען יישומי ב-AWS, עובד על הוגנות, הסבר ואבטחה בלמידת מכונה.
 סרגול אידור הוא מדען יישומי בכיר ב-AWS שעובד על פרטיות ואבטחה בלמידת מכונה
סרגול אידור הוא מדען יישומי בכיר ב-AWS שעובד על פרטיות ואבטחה בלמידת מכונה
- Coinsmart. בורסת הביטקוין והקריפטו הטובה באירופה.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה חופשית.
- CryptoHawk. רדאר אלטקוין. ניסיון חינם.
- מקור: https://aws.amazon.com/blogs/machine-learning/detect-adversarial-inputs-using-amazon-sagemaker-model-monitor-and-amazon-sagemaker-debugger/
- "
- 10
- 100
- 67
- 9
- אודות
- גישה
- פי
- חֶשְׁבּוֹן
- פעיל
- נוסף
- מתקדם
- תעשיות
- אמזון בעברית
- כמות
- אנליזה
- יישומים
- מריחה
- בערך
- AWS
- רקע
- Baseline
- בסיס
- להיות
- להיות
- לחסום
- עסקים
- שיחה
- ללכוד
- מקרים
- שינוי
- בדיקות
- בכיתה
- כיתות
- מיון
- קרוב יותר
- קוד
- לגבות
- טור
- לחשב
- כנס
- תְצוּרָה
- מכולה
- לתרום
- נוצר
- פשע
- מנהג
- לקוחות
- נתונים
- עמוק יותר
- גופי בטחון
- מופגן
- לפרוס
- פרס
- זוהה
- איתור
- לפתח
- אחר
- קשה
- לְהַצִיג
- הפצה
- סַוָר
- לא
- אפקטיבי
- עובדים
- לאפשר
- נקודת קצה
- סביבה
- לְהַעֲרִיך
- אירוע
- דוגמה
- לצפות
- פָּנִים
- פנים
- מאפיין
- תרשים
- ראשון
- מתמקד
- הבא
- קדימה
- מצא
- מסגרת
- מלא
- פונקציה
- נוסף
- יצירת
- הולך
- יותר
- עוזר
- כאן
- גבוה יותר
- איך
- איך
- HTTPS
- רעיון
- תמונה
- פְּגִיעָה
- מדד
- בנפרד
- מידע
- קלט
- לחקור
- סוגיה
- בעיות
- IT
- עבודה
- מקומות תעסוקה
- כתב עת
- מפתח
- ידע
- ידוע
- תוויות
- גָדוֹל
- לִלמוֹד
- למידה
- הוביל
- רמה
- סביר
- רשימה
- ברשימה
- מיקום
- מקומות
- מכונה
- למידת מכונה
- מפות
- מרילנד
- מדדים
- MIT
- ML
- מודל
- מודלים
- צג
- ניטור
- יותר
- רוב
- מספר
- טבעי
- טבע
- רשת
- רעש
- נוֹרמָלִי
- מחברה
- מספר
- מספרים
- אחר
- אחוזים
- שלב
- נקודה
- אפשרי
- חזק
- לחזות
- נבואה
- התחזיות
- להציג
- פְּרָטִיוּת
- פרטיות ואבטחה
- תהליכים
- לייצר
- מיוצר
- מספק
- מתן
- תעריפים
- חי
- להכיר
- הירשם
- רגיל
- רלוונטי
- לדווח
- מאגר
- לבקש
- בקשות
- מחקר
- תוצאות
- החזרות
- כללי
- הפעלה
- ריצה
- סולם
- מַדְעָן
- אבטחה
- נבחר
- סט
- משמעותי
- דומה
- פָּשׁוּט
- שישה
- קטן
- So
- כמה
- מתוחכם
- מֶרחָב
- במיוחד
- התחלה
- מדינה-of-the-art
- סטטיסטי
- סטטיסטיקה
- סטטיסטיקות
- מצב
- אחסון
- סטודנט
- מבחן
- בדיקות
- בדיקות
- דרך
- זמן
- חלק עליון
- לקראת
- הדרכה
- מִשׁפָּט
- אוניברסיטה
- us
- להשתמש
- משתמשים
- בְּדֶרֶך כְּלַל
- ערך
- נראה
- ראיה
- פגיע
- מה
- אם
- בזמן
- סקירה טכנית
- ויקיפדיה
- עובד
- היה
- שנה
- שנים