בנובמבר 2022, אנחנו הודיע שלקוחות AWS יכולים ליצור איתם תמונות מטקסט דיפוזיה יציבה מודלים אמזון SageMaker JumpStart. Stable Diffusion הוא מודל למידה עמוקה המאפשר לך ליצור תמונות ריאליסטיות ואיכותיות ואמנות מדהימה תוך שניות ספורות. למרות שיצירת תמונות מרשימות יכולה למצוא שימוש בתעשיות החל מאמנות ועד NFTs ומעבר לכך, היום אנחנו גם מצפים שבינה מלאכותית תהיה ניתנת להתאמה אישית. היום, אנו מכריזים שאתה יכול להתאים אישית את מודל יצירת התמונה למקרה השימוש שלך על ידי כוונון עדין במערך הנתונים המותאם אישית שלך ב אמזון SageMaker JumpStart. זה יכול להיות שימושי בעת יצירת אמנות, לוגו, עיצובים מותאמים אישית, NFTs וכן הלאה, או דברים מהנים כגון יצירת תמונות AI מותאמות אישית של חיות המחמד שלך או אווטרים שלך.
בפוסט זה, אנו מספקים סקירה כללית כיצד לכוונן את מודל הדיפוזיה היציבה בשתי דרכים: באופן תוכניתי באמצעות ממשקי API של JumpStart זמין ב SageMaker Python SDK, וממשק המשתמש (UI) של JumpStart ב סטודיו SageMaker של אמזון. כמו כן, אנו דנים כיצד לבצע בחירות עיצוביות, כולל איכות מערך הנתונים, גודל מערך ההדרכה, בחירת ערכי היפרפרמטרים והחלה על מערכי נתונים מרובים. לבסוף, אנו דנים בלמעלה מ-80 הדגמים המכוונים לציבור עם שפות וסגנונות קלט שונים שנוספו לאחרונה ב-JumpStart.
דיפוזיה יציבה ולמידת העברה
Stable Diffusion הוא מודל טקסט לתמונה המאפשר לך ליצור תמונות פוטוריאליסטיות רק מבקשת טקסט. מודל דיפוזיה מתאמן על ידי למידה להסיר רעש שנוסף לתמונה אמיתית. תהליך מניעת רעשים זה יוצר תמונה מציאותית. מודלים אלה יכולים גם ליצור תמונות מטקסט בלבד על ידי התניה של תהליך היצירה על הטקסט. לדוגמה, דיפוזיה יציבה היא דיפוזיה סמויה שבה המודל לומד לזהות צורות בתמונת רעש טהורה ומביא בהדרגה את הצורות הללו למיקוד אם הצורות תואמות למילים בטקסט הקלט. ראשית יש להטמיע את הטקסט במרחב סמוי באמצעות מודל שפה. לאחר מכן, סדרה של פעולות הוספת רעש והסרת רעש מתבצעות בחלל הסמוי עם ארכיטקטורת U-Net. לבסוף, הפלט משחרר רעשים מפוענח לתוך חלל הפיקסלים.
בלמידת מכונה (ML), נקראת היכולת להעביר את הידע הנלמד בתחום אחד לתחום אחר העברת למידה. אתה יכול להשתמש בלמידה של העברה כדי לייצר מודלים מדויקים על מערכי הנתונים הקטנים יותר שלך, עם עלויות הדרכה נמוכות בהרבה מאלו הכרוכות באימון המודל המקורי. עם למידת העברה, אתה יכול לכוונן את מודל הדיפוזיה היציב במערך הנתונים שלך עם חמש תמונות בלבד. לדוגמה, בצד שמאל יש תמונות אילוף של כלב בשם דופלר המשמשות לכוונון עדין של הדגם, באמצע ובימין תמונות שנוצרו על ידי המודל המכוונן כאשר מתבקשים לחזות את תמונתו של דופלר על החוף וסקיצה בעיפרון.

בצד שמאל תמונות של כיסא לבן המשמש לכיוונון עדין של הדגם ותמונה של הכיסא באדום שנוצר על ידי הדגם המעודן. בצד ימין יש תמונות של עות'מאנית המשמשת לכוונון עדין של הדגם ותמונה של חתול יושב על עות'מאנית.

כוונון עדין של דגמים גדולים כמו Stable Diffusion בדרך כלל דורש ממך לספק תסריטי אימון. ישנן שלל בעיות, כולל בעיות של חוסר בזיכרון, בעיות בגודל מטען ועוד. יתר על כן, עליך להריץ בדיקות מקצה לקצה כדי לוודא שהסקריפט, המודל והמופע הרצוי עובדים יחד בצורה יעילה. JumpStart מפשט תהליך זה על ידי אספקת סקריפטים מוכנים לשימוש שנבדקו היטב. תסריט הכוונון העדין של JumpStart עבור דגמי Stable Diffusion מבוסס על תסריט הכוונון העדין מ תא חלומות. אתה יכול לגשת לסקריפטים האלה בלחיצה אחת דרך ממשק המשתמש של Studio או עם מעט מאוד שורות קוד דרך ה ממשקי API של JumpStart.
שים לב שעל ידי שימוש במודל דיפוזיה יציבה, אתה מסכים ל CreativeML Open RAIL++-M License.
השתמש ב-JumpStart באופן פרוגרמטי עם ה-SDK של SageMaker
סעיף זה מתאר כיצד לאמן ולפרוס את המודל עם SageMaker Python SDK. אנו בוחרים מודל מאומן מראש ב-JumpStart, מאמנים מודל זה עם עבודת אימון של SageMaker, ופורסים את המודל המאומן לנקודת קצה של SageMaker. יתר על כן, אנו מריצים הסקה על נקודת הקצה הפרוסה, הכל באמצעות SageMaker Python SDK. הדוגמאות הבאות מכילות קטעי קוד. לקוד המלא עם כל השלבים בהדגמה זו, עיין ב- מבוא ל-JumpStart - טקסט לתמונה מחברת לדוגמא.
אימון וכוונון עדין של דגם ה-Stable Diffusion
כל דגם מזוהה באמצעות ייחודי model_id. הקוד הבא מראה כיצד לכוונן מודל בסיס Stable Diffusion 2.1 המזוהה על ידי model_id model-txt2img-stabilityai-stable-diffusion-v2-1-base על מערך אימון מותאם אישית. לרשימה מלאה של model_id ערכים ואיזה דגמים ניתנים לכוונון עדין, עיין אלגוריתמים מובנים עם טבלת מודל מיומנת מראש. לכל אחד model_id, על מנת להשיק משרת הדרכה של SageMaker דרך ה מעריך מחלקה של SageMaker Python SDK, עליך להביא את ה-URI של התמונה של Docker, ה-URI של סקריפט האימון ו-URI המודל שעבר הכשרה מראש דרך פונקציות השירות הניתנות ב-SageMaker. תסריט האימון URI מכיל את כל הקוד הדרוש לעיבוד נתונים, טעינת המודל שהוכשר מראש, אימון מודלים ושמירת המודל המאומן להסקת מסקנות. ה-URI של המודל שהוכשר מראש מכיל את הגדרת ארכיטקטורת המודל שהוכשר מראש ואת פרמטרי המודל. URI המודל שהוכשר מראש הוא ספציפי לדגם המסוים. כדורי הדגם המאומנים מראש הורדו מראש מ-Huging Face ונשמרו עם חתימת הדגם המתאימה ב- שירות אחסון פשוט של אמזון (Amazon S3) דליים, כך שעבודת ההדרכה פועלת בבידוד רשת. ראה את הקוד הבא:
עם חפצי אימון ספציפיים לדגם, אתה יכול לבנות אובייקט של מעריך מעמד:
מערך נתונים לאימון
להלן ההוראות כיצד יש לעצב את נתוני האימון:
- קֶלֶט - ספרייה המכילה את תמונות המופע,
dataset_info.json, עם התצורה הבאה:- התמונות עשויות להיות בפורמט .png, .jpg או .jpeg
- אל האני
dataset_info.jsonהקובץ חייב להיות בפורמט{'instance_prompt':<<instance_prompt>>}
- תְפוּקָה – מודל מאומן שניתן לפרוס להסקת מסקנות
נתיב S3 אמור להיראות כך s3://bucket_name/input_directory/. שימו לב לנגרר / נדרש.
להלן פורמט לדוגמה של נתוני האימון:
להוראות כיצד לעצב את הנתונים תוך שימוש בשימור קודם, עיין בסעיף שימור מוקדם בפוסט הזה.
אנו מספקים מערך ברירת מחדל של תמונות חתולים. הוא מורכב משמונה תמונות (תמונות מופע המתאימות להנחיית מופע) של חתול בודד ללא תמונות מחלקה. ניתן להוריד אותו מ GitHub. אם אתה משתמש במערך הנתונים המוגדר כברירת מחדל, נסה את ההנחיה "תמונה של חתול riobugger" תוך הסקת מסקנות במחברת ההדגמה.
רישיון: MIT.
היפרפרמטרים
לאחר מכן, להעברת למידה במערך הנתונים המותאם אישית שלך, ייתכן שיהיה עליך לשנות את ערכי ברירת המחדל של ההיפרפרמטרים של האימון. אתה יכול להביא מילון Python של ההיפרפרמטרים האלה עם ערכי ברירת המחדל שלהם על ידי קריאה hyperparameters.retrieve_default, עדכן אותם לפי הצורך ולאחר מכן העביר אותם לכיתה אומד. ראה את הקוד הבא:
ההיפרפרמטרים הבאים נתמכים על ידי אלגוריתם הכוונון העדין:
- עם_שימור_קודם - סמן כדי להוסיף אובדן שימור קודם. שימור מוקדם הוא מסדר המונע התאמת יתר. (בחירות:
[“True”,“False”], ברירת מחדל:“False”.) - num_class_images – תמונות המעמד המינימליות לאובדן שימור קודם. אם
with_prior_preservation = Trueוכבר אין מספיק תמונותclass_data_dir, יידגמו תמונות נוספותclass_prompt. (ערכים: מספר שלם חיובי, ברירת מחדל: 100.) - תקופות – מספר המעברים שאלגוריתם הכוונון העדין לוקח דרך מערך האימון. (ערכים: מספר שלם חיובי, ברירת מחדל: 20.)
- מקסימום_צעדים – המספר הכולל של שלבי האימון שיש לבצע. אם לא
None, גובר על תקופות. (ערכים:“None”או מחרוזת של מספר שלם, ברירת מחדל:“None”.) - גודל אצווה –: מספר דוגמאות האימון שעוברות לפני עדכון משקולות הדגם. זהה לגודל האצווה במהלך יצירת תמונות בכיתה אם
with_prior_preservation = True. (ערכים: מספר שלם חיובי, ברירת מחדל: 1.) - שיעור_למידה – קצב עדכון משקלי הדגם לאחר עבודה על כל אצווה של דוגמאות אימון. (ערכים: צף חיובי, ברירת מחדל: 2e-06.)
- לפני_ירידה_משקל - המשקל של אובדן שימור קודם. (ערכים: צף חיובי, ברירת מחדל: 1.0.)
- center_crop - האם לחתוך את התמונות לפני שינוי הגודל לרזולוציה הרצויה. (בחירות:
[“True”/“False”], ברירת מחדל:“False”.) - lr_scheduler – סוג מתזמן קצב הלמידה. (בחירות:
["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"], ברירת מחדל:"constant".) למידע נוסף, ראה מתזמני תעריף למידה. - Adam_weight_decay – ירידת המשקל ליישום (אם לא אפס) על כל השכבות למעט כל הטיה ו
LayerNormמשקולות פנימהAdamWמייעל. (ערך: צף, ברירת מחדל: 1e-2.) - adam_beta1 – ההיפרפרמטר beta1 (קצב דעיכה מעריכי עבור הערכות הרגע הראשון) עבור
AdamWמייעל. (ערך: צף, ברירת מחדל: 0.9.) - adam_beta2 – ההיפרפרמטר beta2 (קצב דעיכה מעריכי עבור הערכות הרגע הראשון) עבור
AdamWמייעל. (ערך: צף, ברירת מחדל: 0.999.) - אדם_אפסילון -
epsilonהיפרפרמטר עבור הAdamWמייעל. בדרך כלל הוא מוגדר לערך קטן כדי להימנע מחלוקה ב-0. (ערך: צף, ברירת מחדל: 1e-8.) - צעדי_צבירת_הדרגה – מספר שלבי העדכונים שיש לצבור לפני ביצוע מעבר אחורה/עדכון. (ערך: מספר שלם, ברירת מחדל: 1.)
- max_grad_norm – נורמת השיפוע המקסימלית (לחיתוך שיפוע). (ערך: צף, ברירת מחדל: 1.0.)
- זרע - תקן את המצב האקראי כדי להשיג תוצאות שניתן לשחזר באימון. (ערך: מספר שלם, ברירת מחדל: 0.)
פרוס את הדגם המאומן היטב
לאחר סיום הכשרת המודל, תוכל לפרוס את המודל ישירות לנקודת קצה מתמשכת בזמן אמת. אנו מביאים את ה-URI של Docker Image ו-URI של script ופורסים את המודל. ראה את הקוד הבא:
בצד שמאל מוצגות תמונות האימון של חתול בשם riobugger המשמש לכוונון עדין של הדגם (פרמטרי ברירת מחדל למעט max_steps = 400). באמצע ובימין מופיעות התמונות שנוצרו על ידי הדגם המכוונן כשהתבקש לחזות את תמונתו של riobugger על החוף וסקיצה בעיפרון.

לפרטים נוספים על מסקנות, כולל פרמטרים נתמכים, פורמט תגובה וכן הלאה, עיין ב צור תמונות מטקסט עם מודל הדיפוזיה היציב ב- Amazon SageMaker JumpStart.
גש ל-JumpStart דרך ממשק המשתמש של Studio
בחלק זה, אנו מדגימים כיצד לאמן ולפרוס דגמי JumpStart דרך ממשק המשתמש של Studio. הסרטון הבא מראה כיצד למצוא את מודל ה-Stable Diffusion המאומן מראש ב-JumpStart, לאמן אותו ולאחר מכן לפרוס אותו. דף הדגם מכיל מידע רב ערך על הדגם וכיצד להשתמש בו. לאחר הגדרת מופע האימון של SageMaker, בחר רכבת. לאחר הכשרת המודל, תוכל לפרוס את המודל המאומן על ידי בחירה לפרוס. לאחר שנקודת הקצה נמצאת בשלב "בשירות", היא מוכנה להגיב לבקשות להסיק.
כדי להאיץ את זמן ההסקה, JumpStart מספקת מחברת לדוגמה המראה כיצד להפעיל הסקה על נקודת הקצה החדשה שנוצרה. כדי לגשת למחברת בסטודיו, בחר פתח מחברת ב השתמש ב-Endpoint מ-Studio החלק של דף נקודת הקצה של המודל.
JumpStart מספק גם מחברת פשוטה שבה תוכל להשתמש כדי לכוונן את מודל הדיפוזיה היציב ולפרוס את המודל המכוונן המתקבל. אתה יכול להשתמש בו כדי ליצור תמונות מהנות של הכלב שלך. כדי לגשת למחברת, חפש "צור תמונות מהנות של הכלב שלך" בסרגל החיפוש של JumpStart. כדי להפעיל את המחברת, אתה יכול להשתמש בחמש תמונות אימון בלבד ולהעלות לתיקיית הסטודיו המקומית. אם יש לך יותר מחמש תמונות, תוכל להעלות אותן גם כן. Notebook מעלה את תמונות האימון ל-S3, מאמן את המודל במערך הנתונים שלך ופריסה את המודל המתקבל. האימון עשוי להימשך 20 דקות לסיום. ניתן לשנות את מספר הצעדים כדי להאיץ את האימון. Notebook מספק כמה הנחיות לדוגמא לנסות עם המודל שנפרס, אבל אתה יכול לנסות כל הנחיה שתרצה. אתה יכול גם להתאים את המחברת ליצירת אווטרים שלך או של חיות המחמד שלך. לדוגמה, במקום הכלב שלך, אתה יכול להעלות תמונות של החתול שלך בשלב הראשון ולאחר מכן לשנות את ההנחיות מכלבים לחתולים והמודל יפיק תמונות של החתול שלך.
שיקולי כוונון עדין
אימון דגמי דיפוזיה יציבים נוטים להתאים יתר על המידה במהירות. כדי לקבל תמונות באיכות טובה, עלינו למצוא איזון טוב בין ההיפרפרמטרים של האימון הזמינים כגון מספר שלבי האימון וקצב הלמידה. בסעיף זה, אנו מציגים כמה תוצאות ניסויים ומספקים הנחיות כיצד להגדיר פרמטרים אלה.
המלצות
שקול את ההמלצות הבאות:
- התחל עם תמונות אימון באיכות טובה (4-20). אם מתאמנים על פנים אנושיות, ייתכן שתזדקק לתמונות נוספות.
- התאמן עבור 200-400 צעדים בעת אימון על כלבים או חתולים ונושאים אחרים שאינם אנושיים. אם אימון על פנים אנושיות, ייתכן שתצטרך עוד שלבים. אם מתרחשת התאמת יתר, צמצם את מספר הצעדים. אם מתרחשת תת-התאמה (הדגם המכוונן לא יכול ליצור את תמונת נושא המטרה), הגדל את מספר הצעדים.
- אם אימון על פנים לא אנושיות, אתה יכול להגדיר
with_prior_preservation = Falseכי זה לא משפיע באופן משמעותי על הביצועים. על פנים אנושיות, ייתכן שיהיה עליך להגדירwith_prior_preservation=True. - אם הגדרה
with_prior_preservation=True, השתמש בסוג המופע ml.g5.2xlarge. - כאשר מתאמנים על מספר נושאים ברצף, אם הנושאים דומים מאוד (לדוגמה, כל הכלבים), המודל שומר על הנושא האחרון ושוכח את הנושאים הקודמים. אם הנושאים שונים (לדוגמה, קודם כל חתול ואז כלב), המודל שומר על שני הנושאים.
- אנו ממליצים להשתמש בשיעור למידה נמוך ולהגדיל בהדרגה את מספר השלבים עד שהתוצאות משביעות רצון.
מערך נתונים לאימון
איכות הדגם המכוונן מושפעת ישירות מאיכות תמונות האימון. לכן, אתה צריך לאסוף תמונות באיכות גבוהה כדי לקבל תוצאות טובות. תמונות מטושטשות או ברזולוציה נמוכה ישפיעו על איכות הדגם המכוונן. זכור את הפרמטרים הנוספים הבאים:
- מספר תמונות אימון - תוכל לכוונן את הדגם על ארבע תמונות אימון בלבד. עשינו ניסויים באימון מערכי נתונים בגודל קטן כמו 4 תמונות ועד 16 תמונות. בשני המקרים, כוונון עדין הצליח להתאים את הדגם לנושא.
- פורמטים של ערכות נתונים – בדקנו את אלגוריתם הכוונון העדין על תמונות בפורמט .png, .jpg ו-.jpeg. גם פורמטים אחרים עשויים לעבוד.
- רזולוציית תמונה - תמונות אימון עשויות להיות בכל רזולוציה. אלגוריתם הכוונון העדין ישנה את גודל כל תמונות האימון לפני תחילת הכוונון. עם זאת, אם ברצונך לקבל יותר שליטה על החיתוך ושינוי הגודל של תמונות האימון, אנו ממליצים לשנות את גודל התמונות בעצמך לרזולוציית הבסיס של הדגם (בדוגמה זו, 512×512 פיקסלים).
הגדרות ניסוי
בניסוי בפוסט זה, תוך כדי כוונון עדין אנו משתמשים בערכי ברירת המחדל של ההיפרפרמטרים אלא אם צוין. יתר על כן, אנו משתמשים באחד מארבעת מערכי הנתונים:
- כלב1-8 - כלב 1 עם 8 תמונות
- כלב1-16 - כלב 1 עם 16 תמונות
- כלב2-4 - כלב 2 עם ארבע תמונות
- חתול-8 - חתול עם 8 תמונות
כדי להפחית את העומס, אנו מציגים רק תמונה מייצגת אחת של מערך הנתונים בכל חלק יחד עם שם מערך הנתונים. אתה יכול למצוא את מערך ההדרכה המלא במדור ערכות נתונים של ניסוי בפוסט הזה.
יתר על המידה
דגמי דיפוזיה יציבים נוטים להתאים יתר על המידה בעת כוונון עדין של כמה תמונות. לכן, אתה צריך לבחור את הפרמטרים כגון epochs, max_epochs, וקצב הלמידה בזהירות. בחלק זה, השתמשנו במערך הנתונים Dog1-16.

כדי להעריך את ביצועי המודל, אנו מעריכים את המודל המכוונן עבור ארבע משימות:
- האם המודל המכוונן יכול להפיק תמונות של הנושא (כלב דופלר) באותה סביבה שבה הוא אולף?
- תצפית - כן זה יכול. ראוי לציין שביצועי המודל גדלים עם מספר שלבי האימון.
- האם המודל המכוונן יכול להפיק תמונות של הנושא בסביבה שונה ממה שהוא אומן עליה? לדוגמה, האם זה יכול ליצור תמונות של דופלר על חוף הים?
- תצפית - כן זה יכול. ראוי לציין שביצועי המודל עולים עם מספר שלבי האימון עד לנקודה מסוימת. עם זאת, אם הדגם מאומן יותר מדי זמן, ביצועי הדגם יורדים מכיוון שהדגם נוטה להתאים יותר מדי.
- האם המודל המכוונן יכול ליצור תמונות של כיתה שאליה שייך נושא ההדרכה? לדוגמה, האם זה יכול ליצור תמונה של כלב גנרי?
- תצפית - ככל שאנו מגדילים את מספר שלבי האימון, הדגם מתחיל להתאים יתר על המידה. כתוצאה מכך, הוא שוכח את המעמד הגנרי של כלב ויפיק רק תמונות הקשורות לנושא.
- האם המודל המכוונן יכול ליצור תמונות של כיתה או נושא שלא נמצא במערך ההדרכה? לדוגמה, האם זה יכול ליצור תמונה של חתול?
- תצפית - ככל שאנו מגדילים את מספר שלבי האימון, הדגם מתחיל להתאים יתר על המידה. כתוצאה מכך, הוא יפיק רק תמונות הקשורות לנושא, ללא קשר לכיתה שצוינה.
אנו מכווננים את המודל למספר שונה של שלבים (על ידי הגדרה max_steps היפרפרמטרים) ולכל דגם מכוונן עדין, אנו יוצרים תמונות בכל אחת מארבעת ההנחיות הבאות (המוצגות בדוגמאות הבאות משמאל לימין:
- "תמונה של כלב דופלר"
- "תמונה של כלב דופלר על חוף הים"
- "תמונה של כלב"
- "תמונה של חתול"
התמונות הבאות הן מהדגם שאומן ב-50 צעדים.

הדגם הבא הוכשר ב-100 צעדים.

אימנו את הדגם הבא ב-200 צעדים.

התמונות הבאות הן מדגם מאומן עם 400 צעדים.

לבסוף, התמונות הבאות הן תוצאה של 800 שלבים.

התאמן על מערכי נתונים מרובים
בזמן כוונון עדין, ייתכן שתרצה לכוונן מספר נושאים ולאפשר לדגם המכוונן ליצור תמונות של כל הנושאים. לרוע המזל, JumpStart מוגבל כרגע לאימון בנושא אחד. אתה לא יכול לכוונן את המודל על מספר נושאים בו-זמנית. יתר על כן, כוונון עדין של המודל עבור נושאים שונים מביא לכך שהמודל ישכח את הנושא הראשון אם הנושאים דומים.
אנו רואים את הניסוי הבא בסעיף זה:
- כוונן את המודל עבור נושא א'.
- כוונן את המודל שהתקבל משלב 1 עבור נושא ב'.
- צור תמונות של נושא א' ונבדק ב' באמצעות מודל הפלט משלב 2.
בניסויים הבאים, אנו רואים כי:
- אם A הוא כלב 1 ו-B הוא כלב 2, אז כל התמונות שנוצרו בשלב 3 דומות לכלב 2
- אם A הוא כלב 2 ו-B הוא כלב 1, אז כל התמונות שנוצרו בשלב 3 דומות לכלב 1
- אם A הוא כלב 1 ו-B הוא חתול, אז תמונות שנוצרו עם הנחיות לכלב דומות לכלב 1 ותמונות שנוצרות עם הנחיות חתול דומות לחתול
מתאמן על כלב 1 ולאחר מכן על כלב 2
בשלב 1, אנו מכווננים את המודל ל-200 צעדים על שמונה תמונות של כלב 1. בשלב 2, אנו מכווננים את המודל עוד יותר ל-200 צעדים על ארבע תמונות של כלב 2.

להלן התמונות שנוצרו על ידי הדגם המכוונן בסוף שלב 2 עבור הנחיות שונות.

מתאמן על כלב 2 ולאחר מכן על כלב 1
בשלב 1, אנו מכווננים את המודל ל-200 צעדים על ארבע תמונות של כלב 2. בשלב 2, אנו מכווננים את המודל עוד יותר ל-200 צעדים על שמונה תמונות של כלב 1.

להלן התמונות שנוצרו על ידי הדגם המכוונן בסוף שלב 2 עם הנחיות שונות.

אימון על כלבים וחתולים
בשלב 1, אנו מכווננים את המודל ל-200 צעדים על שמונה תמונות של חתול. לאחר מכן אנו מכווננים את המודל עוד יותר עבור 200 צעדים על שמונה תמונות של כלב 1.

להלן התמונות שנוצרו על ידי המודל המכוונן בסוף שלב 2. תמונות עם הנחיות הקשורות לחתול נראות כמו החתול בשלב 1 של הכוונון העדין, ותמונות עם הנחיות הקשורות לכלב נראות כמו הכלב ב שלב 2 של הכוונון העדין.

שימור קודם
שימור מוקדם הוא טכניקה המשתמשת בתמונות נוספות מאותה מחלקה שאנו מנסים להתאמן עליה. לדוגמה, אם נתוני האילוף מורכבים מתמונות של כלב מסוים, עם שימור מוקדם, אנו משלבים תמונות כיתתיות של כלבים גנריים. הוא מנסה להימנע מהתאמה יתר על ידי הצגת תמונות של כלבים שונים בזמן אילוף עבור כלב מסוים. תג המציין את הכלב הספציפי הקיים בהנחיית המופע חסר בהנחיית הכיתה. לדוגמה, בקשת המופע עשויה להיות "תמונה של חתול riobugger" וההנחיה בכיתה יכולה להיות "תמונה של חתול". אתה יכול לאפשר שימור מוקדם על ידי הגדרת ההיפרפרמטר with_prior_preservation = True. אם הגדרה with_prior_preservation = True, עליך לכלול class_prompt in dataset_info.json ועשויים לכלול את כל תמונות הכיתה הזמינות עבורך. להלן פורמט מערך ההדרכה בעת ההגדרה with_prior_preservation = True:
- קֶלֶט - ספרייה המכילה את תמונות המופע,
dataset_info.jsonוספרייה (אופציונלית).class_data_dir. שימו לב לדברים הבאים:- התמונות עשויות להיות בפורמט .png, .jpg, .jpeg.
- אל האני
dataset_info.jsonהקובץ חייב להיות בפורמט{'instance_prompt':<<instance_prompt>>,'class_prompt':<<class_prompt>>}. - אל האני
class_data_dirספרייה חייבת לכלול תמונות מחלקה. אםclass_data_dirאינו קיים או שאין מספיק תמונות כברclass_data_dir, יידגמו תמונות נוספותclass_prompt.
עבור מערכי נתונים כגון חתולים וכלבים, שימור מוקדם אינו משפיע באופן משמעותי על הביצועים של המודל המכוונן, ולכן ניתן להימנע ממנו. עם זאת, כאשר מתאמנים על פנים, זה הכרחי. למידע נוסף, עיין ב אימון דיפוזיה יציבה עם Dreambooth באמצעות מפזרים.
סוגי מופעים
כוונון עדין של דגמי Stable Diffusion דורשים חישוב מואץ המסופק על ידי מופעים הנתמכים ב-GPU. אנו מתנסים בכוונון העדין שלנו עם מופעי ml.g4dn.2xlarge (16 GB זיכרון CUDA, 1 GPU) ו-ml.g5.2xlarge (24 GB זיכרון CUDA, 1 GPU). דרישת הזיכרון גבוהה יותר בעת יצירת תמונות מחלקות. לכן, אם הגדרה with_prior_preservation=True, השתמש בסוג המופע ml.g5.2xlarge, מכיוון שהאימונים נתקלים בבעיית ה-CUDA מחוץ לזיכרון במופע ml.g4dn.2xlarge. סקריפט הכוונון העדין של JumpStart משתמש כעת ב-GPU יחיד ולכן, כוונון עדין במופעים מרובי-GPU לא יניב שיפור בביצועים. למידע נוסף על סוגי מופעים שונים, עיין ב סוגי מופעים של אמזון EC2.
מגבלות והטיה
למרות של-Stable Diffusion יש ביצועים מרשימים ביצירת תמונות, הוא סובל מכמה מגבלות והטיות. אלה כוללים בין היתר:
- ייתכן שהמודל לא יפיק פרצופים או גפיים מדויקים מכיוון שנתוני האימון אינם כוללים מספיק תמונות עם תכונות אלו
- הדגם הוכשר על מערך נתונים של LAION-5B, בעל תוכן למבוגרים בלבד וייתכן שלא יתאים לשימוש במוצר ללא שיקולים נוספים
- ייתכן שהמודל לא יעבוד טוב עם שפות שאינן אנגלית מכיוון שהמודל הוכשר על טקסט בשפה האנגלית
- המודל לא יכול ליצור טקסט טוב בתוך תמונות
למידע נוסף על מגבלות והטיות, ראה כרטיס דגם Stable Diffusion v2-1-base. מגבלות אלו עבור הדגם המאומן מראש יכולות לעבור גם לדגמים המכוונים.
לנקות את
לאחר שתסיים להפעיל את המחברת, הקפד למחוק את כל המשאבים שנוצרו בתהליך כדי להבטיח שהחיוב יופסק. קוד לניקוי נקודת הקצה מסופק בקובץ המשויך מבוא ל-JumpStart - טקסט לתמונה מחברת לדוגמא.
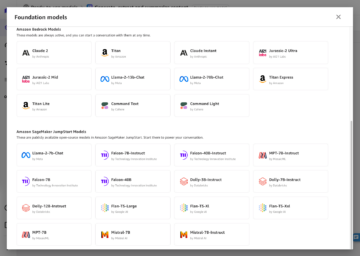
דגמים מכוונים זמינים לציבור ב-JumpStart
למרות שדגמי Stable Diffusion שוחררו על ידי StabilityAI יש להם ביצועים מרשימים, יש להם מגבלות מבחינת השפה או התחום שבו הוא הוכשר. לדוגמה, מודלים של דיפוזיה יציבה הוכשרו על טקסט באנגלית, אך ייתכן שיהיה עליך ליצור תמונות מטקסט שאינו אנגלי. לחלופין, מודלים של דיפוזיה יציבה אומנו ליצור תמונות פוטוריאליסטיות, אך ייתכן שיהיה עליך ליצור תמונות מונפשות או אמנותיות.
JumpStart מספקת למעלה מ-80 דגמים זמינים לציבור עם שפות ונושאים שונים. דגמים אלה הם לרוב גרסאות מכווננות מדגמי Stable Diffusion ששוחררו על ידי StabilityAI. אם מקרה השימוש שלך תואם לאחד מהדגמים המכוונים היטב, אינך צריך לאסוף את מערך הנתונים שלך ולכוון אותו עדין. אתה יכול פשוט לפרוס אחד מהדגמים האלה דרך ממשק המשתמש של Studio או באמצעות ממשקי API קלים לשימוש של JumpStart. כדי לפרוס מודל דיפוזיה יציבה מאומן מראש ב-JumpStart, עיין ב צור תמונות מטקסט עם מודל הדיפוזיה היציב ב- Amazon SageMaker JumpStart.
להלן כמה מהדוגמאות לתמונות שנוצרו על ידי הדגמים השונים הזמינים ב-JumpStart.


שים לב שדגמים אלה אינם מכוונים עדין באמצעות סקריפטים של JumpStart או סקריפטים של DreamBooth. אתה יכול להוריד את הרשימה המלאה של דגמים מכוונים זמינים לציבור עם הנחיות לדוגמה כאן.
לתמונות נוספות שנוצרו לדוגמה מדגמים אלה, אנא עיין בסעיף מודלים מכוונים בקוד פתוח בנספח.
סיכום
בפוסט זה, הראינו כיצד לכוונן את מודל ה-Stable Diffusion עבור טקסט לתמונה ולאחר מכן לפרוס אותו באמצעות JumpStart. יתר על כן, דנו בכמה מהשיקולים שעליך לעשות בעת כוונון עדין של המודל וכיצד זה יכול להשפיע על הביצועים של המודל המכוונן. דנו גם בלמעלה מ-80 הדגמים המכוונים המוכנים לשימוש הזמינים ב-JumpStart. הצגנו קטעי קוד בפוסט זה - לקוד המלא עם כל השלבים בהדגמה זו, ראה את מבוא ל-JumpStart - טקסט לתמונה מחברת לדוגמה. נסה את הפתרון בעצמך ושלח לנו את הערותיך.
למידע נוסף על הדגם ועל הכוונון העדין של DreamBooth, עיין במשאבים הבאים:
למידע נוסף על JumpStart, עיין בפוסטים הבאים בבלוג:
על הכותבים
 ד"ר Vivek Madan הוא מדען יישומי בצוות אמזון SageMaker JumpStart. הוא קיבל את הדוקטורט שלו מאוניברסיטת אילינוי באורבנה-שמפיין והיה חוקר פוסט דוקטורט בג'ורג'יה טק. הוא חוקר פעיל בלמידת מכונה ועיצוב אלגוריתמים ופרסם מאמרים בכנסים של EMNLP, ICLR, COLT, FOCS ו-SODA.
ד"ר Vivek Madan הוא מדען יישומי בצוות אמזון SageMaker JumpStart. הוא קיבל את הדוקטורט שלו מאוניברסיטת אילינוי באורבנה-שמפיין והיה חוקר פוסט דוקטורט בג'ורג'יה טק. הוא חוקר פעיל בלמידת מכונה ועיצוב אלגוריתמים ופרסם מאמרים בכנסים של EMNLP, ICLR, COLT, FOCS ו-SODA.
 הייקו הוץ הוא ארכיטקט פתרונות בכיר עבור AI ולמידת מכונה עם התמקדות מיוחדת בעיבוד שפה טבעית (NLP), מודלים של שפות גדולות (LLMs) ובינה מלאכותית גנרטיבית. לפני תפקיד זה, הוא היה ראש מדעי הנתונים של שירות הלקוחות של אמזון באיחוד האירופי. Heiko עוזרת ללקוחותינו להצליח במסע ה-AI/ML שלהם ב-AWS ועבדה עם ארגונים בתעשיות רבות, כולל ביטוח, שירותים פיננסיים, מדיה ובידור, שירותי בריאות, שירותים וייצור. בזמנו הפנוי, הייקו מטייל כמה שיותר.
הייקו הוץ הוא ארכיטקט פתרונות בכיר עבור AI ולמידת מכונה עם התמקדות מיוחדת בעיבוד שפה טבעית (NLP), מודלים של שפות גדולות (LLMs) ובינה מלאכותית גנרטיבית. לפני תפקיד זה, הוא היה ראש מדעי הנתונים של שירות הלקוחות של אמזון באיחוד האירופי. Heiko עוזרת ללקוחותינו להצליח במסע ה-AI/ML שלהם ב-AWS ועבדה עם ארגונים בתעשיות רבות, כולל ביטוח, שירותים פיננסיים, מדיה ובידור, שירותי בריאות, שירותים וייצור. בזמנו הפנוי, הייקו מטייל כמה שיותר.
נספח: מערכי נתונים של ניסוי
חלק זה מכיל את מערכי הנתונים ששימשו בניסויים בפוסט זה.
כלב1-8

כלב1-16

כלב2-4

כלב3-8

נספח: מודלים מכוונים בקוד פתוח
להלן כמה מהדוגמאות לתמונות שנוצרו על ידי הדגמים השונים הזמינים ב-JumpStart. כל תמונה מסומנת ב-a model_id מתחיל בקידומת huggingface-txt2img- ואחריו ההנחיה המשמשת ליצירת התמונה בשורה הבאה.

























- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/fine-tune-text-to-image-stable-diffusion-models-with-amazon-sagemaker-jumpstart/
- 1
- 100
- 11
- 2022
- 9
- a
- יכולת
- יכול
- אודות
- להאיץ
- מוּאָץ
- גישה
- לצבור
- מדויק
- להשיג
- פעיל
- להסתגל
- הוסיף
- תוספת
- נוסף
- מְבוּגָר
- לאחר
- AI
- AI & Machine Learning
- AI / ML
- אַלגוֹרִיתְם
- אלגוריתמים
- תעשיות
- מאפשר
- לבד
- כְּבָר
- למרות
- אמזון בעברית
- אמזון SageMaker
- אמזון SageMaker JumpStart
- ו
- להכריז
- אחר
- ממשקי API
- יישומית
- החל
- מתאים
- ארכיטקטורה
- אמנות
- אמנותי
- המשויך
- באופן אוטומטי
- זמין
- אווטרים
- לְהִמָנַע
- נמנע
- AWS
- איזון
- בָּר
- בסיס
- חוף
- כי
- לפני
- להיות
- בֵּין
- מעבר
- הטיה
- חיוב
- בלוג
- בלוג הודעות
- מביא
- בונה
- נקרא
- קוראים
- בזהירות
- לשאת
- מקרה
- מקרים
- חָתוּל
- חתולים
- מסוים
- כִּסֵא
- שינוי
- לבדוק
- בחירה
- בחירות
- לבחור
- בחירה
- בכיתה
- מבולגן
- קוד
- לגבות
- הערות
- חישוב
- כנסים
- תְצוּרָה
- לשקול
- שיקולים
- קבוע
- לבנות
- מכולה
- מכיל
- תוכן
- לִשְׁלוֹט
- תוֹאֵם
- עלויות
- לִיצוֹר
- נוצר
- יוצרים
- יבול
- כיום
- מנהג
- לקוח
- שירות לקוחות
- לקוחות
- נתונים
- עיבוד נתונים
- מדע נתונים
- מערכי נתונים
- עמוק
- למידה עמוקה
- בְּרִירַת מֶחדָל
- הַדגָמָה
- להפגין
- לפרוס
- פרס
- עיצוב
- עיצובים
- פרטים
- אחר
- שידור
- ישירות
- לדון
- נָדוֹן
- חטיבה
- סַוָר
- מיכל דוקר
- לא
- כֶּלֶב
- כלבים
- עושה
- תחום
- לא
- להורדה
- בְּמַהֲלָך
- כל אחד
- קל לשימוש
- יעיל
- מוטבע
- לאפשר
- מאפשר
- מקצה לקצה
- נקודת קצה
- אנגלית
- מספיק
- לְהַבטִיחַ
- בידור
- כניסה
- תקופות
- הערכות
- וכו '
- Ether (ETH)
- EU
- להעריך
- דוגמה
- דוגמאות
- אלא
- לבצע
- לצפות
- לְנַסוֹת
- מעריכי
- פָּנִים
- פנים
- מעטים
- שלח
- קבצים
- בסופו של דבר
- כספי
- שירותים פיננסיים
- גימור
- ראשון
- מתאים
- לסדר
- לָצוּף
- להתמקד
- בעקבות
- הבא
- פוּרמָט
- החל מ-
- מלא
- כֵּיף
- פונקציות
- נוסף
- יתר על כן
- לְהַשִׂיג
- ליצור
- נוצר
- מייצר
- יצירת
- דור
- גנרטטיבית
- AI Generative
- לקבל
- GitHub
- טוב
- GPU
- בהדרגה
- טיפול
- קורה
- ראש
- בריאות
- עוזר
- באיכות גבוהה
- גבוה יותר
- המארח
- איך
- איך
- אולם
- HTML
- HTTPS
- בן אנוש
- כיל
- מזוהה
- אילינוי
- תמונה
- דור תמונה
- תמונות
- פְּגִיעָה
- מושפעים
- לייבא
- מרשים
- in
- לכלול
- כולל
- כולל
- בע"מ
- להגדיל
- עליות
- גדל
- תעשיות
- מידע
- קלט
- למשל
- במקום
- הוראות
- ביטוח
- מִמְשָׁק
- מעורב
- בדידות
- סוגיה
- בעיות
- IT
- עבודה
- מסע
- ג'סון
- שמור
- ידע
- שפה
- שפות
- גָדוֹל
- אחרון
- לשגר
- שכבות
- לִלמוֹד
- למד
- למידה
- מגבלות
- מוגבל
- קו
- קווים
- רשימה
- קְצָת
- טוען
- מקומי
- ארוך
- נראה
- נראה כמו
- את
- נמוך
- מכונה
- למידת מכונה
- לעשות
- דרך
- באופן ידני
- ייצור
- רב
- להתאים
- מקסימום
- מדיה
- זכרון
- אמצע
- יכול
- אכפת לי
- מינימום
- חסר
- ML
- מודל
- מודלים
- רֶגַע
- יותר
- מספר
- שם
- שם
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- הכרחי
- צורך
- נחוץ
- רשת
- הבא
- NFTs
- NLP
- רעש
- מחברה
- נוֹבֶמבֶּר
- מספר
- אובייקט
- להתבונן
- ONE
- לפתוח
- תפעול
- להזמין
- ארגונים
- מְקוֹרִי
- אחר
- סקירה
- שֶׁלוֹ
- ניירות
- פרמטרים
- מסוים
- מעברי
- חולף
- נתיב
- לבצע
- ביצועים
- ביצוע
- אישית
- חיות מחמד
- פוטוריאליסטי
- פיקסל
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- אנא
- נקודה
- חיובי
- אפשרי
- הודעה
- הודעות
- לחזות
- להציג
- קודם
- קודם
- תהליך
- תהליך
- לייצר
- המוצר
- בהדרגה
- לספק
- ובלבד
- מספק
- מתן
- בפומבי
- לאור
- פיתון
- איכות
- מהירות
- אקראי
- טִוּוּחַ
- ציון
- מוכן
- ממשי
- זמן אמת
- מציאותי
- לאחרונה
- להכיר
- להמליץ
- המלצות
- Red
- להפחית
- ללא קשר
- קָשׁוּר
- שוחרר
- הסרה
- להסיר
- נציג
- בקשות
- לדרוש
- נדרש
- דרישה
- דורש
- חוקר
- החלטה
- משאבים
- להגיב
- תגובה
- תוצאה
- וכתוצאה מכך
- תוצאות
- תפקיד
- הפעלה
- ריצה
- בעל חכמים
- אמר
- אותו
- חסכת
- מדע
- מַדְעָן
- סקריפטים
- Sdk
- חיפוש
- שניות
- סעיף
- לחצני מצוקה לפנסיונרים
- סדרה
- שרות
- שירותים
- סט
- הצבה
- כמה
- צורות
- צריך
- לְהַצִיג
- הראה
- הופעות
- באופן משמעותי
- דומה
- פָּשׁוּט
- בפשטות
- יחיד
- ישיבה
- מידה
- קטן
- קטן יותר
- So
- פִּתָרוֹן
- פתרונות
- כמה
- מֶרחָב
- מיוחד
- ספציפי
- מפורט
- מְהִירוּת
- יציב
- התמחות
- החל
- התחלות
- מדינה
- שלב
- צעדים
- נעצר
- אחסון
- סטודיו
- נושא
- מוצלח
- כזה
- סובל
- מספיק
- תמיכה
- נתמך
- תומך
- תָג
- לקחת
- לוקח
- יעד
- משימות
- נבחרת
- טק
- מונחים
- בדיקות
- אל האני
- שֶׁלָהֶם
- לכן
- דרך
- זמן
- ל
- היום
- יַחַד
- גַם
- סה"כ
- רכבת
- מְאוּמָן
- הדרכה
- רכבות
- להעביר
- נוסע
- סוגים
- ui
- ייחודי
- אוניברסיטה
- עדכון
- מְעוּדכָּן
- עדכונים
- URI
- us
- להשתמש
- במקרה להשתמש
- משתמש
- ממשק משתמש
- בְּדֶרֶך כְּלַל
- כלי עזר
- תועלת
- מנצל
- בעל ערך
- מידע בעל ערך
- ערך
- ערכים
- שונים
- וִידֵאוֹ
- דרכים
- מִשׁקָל
- אם
- אשר
- בזמן
- לבן
- יצטרך
- בתוך
- לְלֹא
- מילים
- תיק עבודות
- לעבוד יחד
- עבד
- עובד
- ראוי
- תְשׁוּאָה
- עצמך
- זפירנט
- אפס