החזון של Amazon Search הוא לאפשר ללקוחות לחפש ללא מאמץ. תיקון האיות שלנו עוזר לך למצוא את מה שאתה רוצה גם אם אינך יודע את האיות המדויק של המילים המיועדות. בעבר, השתמשנו באלגוריתמים של למידת מכונה קלאסית (ML) עם הנדסת תכונות ידנית לתיקון איות. כדי לבצע את הקפיצה הדורית הבאה בביצועי תיקון האיות, אנו מאמצים מספר גישות של למידה עמוקה, כולל מודלים מרצף לרצף. מודלים של למידה עמוקה (DL) הם עתירי מחשוב הן בהדרכה והן בהסקת מסקנות, ועלויות אלו הפכו את מודלים של DL באופן היסטורי לבלתי מעשיים במסגרת ייצור בקנה מידה של אמזון. בפוסט זה, אנו מציגים את התוצאות של ניסוי אופטימיזציה של מסקנות שבה אנו מתגברים על המכשולים הללו ומשיגים מהירות מסקנת של 534% עבור ה-Hugging Face T5 Transformer הפופולרי.
אתגר
שנאי העברת טקסט לטקסט (T5, בחינת מגבלות לימוד ההעברה עם שנאי טקסט לטקסט אחיד, Reffel et al) היא ארכיטקטורת מודל עיבוד השפה הטבעית (NLP) החדישה ביותר. T5 היא ארכיטקטורה מבטיחה לתיקון איות, שמצאנו שהיא מתפקדת היטב בניסויים שלנו. קל לחקור, לפתח ולהכשיר מודלים של T5, הודות למסגרות למידה עמוקה בקוד פתוח ומחקר אקדמי וארגוני מתמשך.
עם זאת, קשה להשיג מסקנות בדרגת ייצור עם אחזור נמוך עם T5. לדוגמה, הסקה בודדת עם PyTorch T5 נמשכת 45 מילישניות באחד מארבעת ה-NVIDIA V100 Tensor Core GPUs המציידים מופע של Amazon Elastic Compute Cloud (EC2) p3.8xlarge. (כל המספרים המדווחים הם עבור קלט של 9 אסימונים ופלט של 11 אסימונים. ההשהיה של ארכיטקטורות T5 רגישה לאורכי הקלט והפלט כאחד).
מסקנות T5 עם זמן אחזור נמוך וחסכוני בקנה מידה הוא קושי ידוע שדווח על ידי מספר לקוחות AWS מעבר לאמזון חיפוש, מה שמגביר את המוטיבציה שלנו לתרום את הפוסט הזה. כדי לעבור מהישג מדעי לא מקוון לשירות ייצור מול לקוח, אמזון חיפוש עומדת בפני האתגרים הבאים:
- חֶבִיוֹן - כיצד לממש מסקנות T5 בפחות מ-50 אלפיות השנייה של חביון P99
- התפוקה - כיצד לטפל בבקשות מסקנות בו-זמניות בקנה מידה גדול
- יעילות מחיר - כיצד לשמור על עלויות בשליטה
בהמשך הפוסט הזה, אנו מסבירים כיצד מחסנית אופטימיזציית ההסקות של NVIDIA - כלומר NVIDIA TensorRT מהדר והקוד הפתוח NVIDIA Triton Inference Server- פותר את האתגרים האלה. לקרוא הודעה לעיתונות של NVIDIA כדי ללמוד על העדכונים.
NVIDIA TensorRT: הפחתת עלויות והשהייה עם אופטימיזציה של מסקנות
מסגרות למידה עמוקה נוחות לחזרה מהירה על המדע, ומגיעות עם פונקציונליות רבות עבור מודלים מדעיים, טעינת נתונים ואופטימיזציה של הדרכה. עם זאת, רוב הכלים הללו אינם אופטימליים להסקה, מה שדורש רק קבוצה מינימלית של אופרטורים עבור פונקציות הכפל והפעלה של מטריצה. לכן, ניתן לממש רווחים משמעותיים על ידי שימוש ביישום מיוחד, חיזוי בלבד, במקום להפעיל מסקנות במסגרת פיתוח הלמידה העמוקה.
NVIDIA TensorRT הוא SDK להסקת למידה עמוקה בעלת ביצועים גבוהים. TensorRT מספקת גם זמן ריצה אופטימלי, באמצעות ליבות אופטימליות ברמה נמוכה הזמינים ב-NVIDIA GPUs, וגם גרף מודל להסקה בלבד, המסדר מחדש את חישובי ההסקה בסדר אופטימלי.
בסעיף הבא, נדבר על הפרטים המתרחשים מאחורי TensorRT וכיצד הוא מאיץ את הביצועים.

- דיוק מופחת ממקסם את התפוקה עם FP16 או INT8 על ידי כימת מודלים תוך שמירה על תקינות.
- Layer and Tensor Fusion מייעל את השימוש בזיכרון ה-GPU וברוחב הפס על-ידי מיזוג צמתים בליבה כדי להימנע מהשהיית השקת הקרנל.
- כוונון אוטומטי של ליבה בוחר את שכבות הנתונים והאלגוריתמים הטובים ביותר בהתבסס על פלטפורמת היעד GPU וצורות ליבת הנתונים.
- זיכרון טנסור דינמי ממזער את טביעת הרגל של הזיכרון על ידי שחרור צריכת זיכרון מיותרת של תוצאות ביניים ושימוש חוזר בזיכרון עבור טנסורים ביעילות.
- ביצוע ריבוי זרמים משתמש בעיצוב שניתן להרחבה לעיבוד זרמי קלט מרובים במקביל לזרמי CUDA ייעודיים.
- זמן פיוז'ן מייעל רשתות עצביות חוזרות לאורך שלבי זמן עם גרעינים שנוצרו באופן דינמי.
T5 משתמש בשכבות שנאי כאבני בניין לארכיטקטורות שלה. המהדורה האחרונה של NVIDIA TensorRT 8.2 מציגה אופטימיזציות חדשות עבור דגמי T5 ו-GPT-2 להסקת מסקנות בזמן אמת. בטבלה הבאה, אנו יכולים לראות את המהירות עם TensorRT בחלק מדגמי T5 ציבוריים הפועלים על מופעי Amazon EC2G4dn, המופעלים על ידי NVIDIA T4 GPUs ומופעי EC2 G5, המופעלים על ידי NVIDIA A10G GPUs.
| מספר סימוכין | מופע | חביון Pytorch של קו הבסיס (ms) | אחזור TensorRT 8.2 (ms) | Speedup לעומת קו הבסיס של HF | ||||||||
| FP32 | FP32 | FP16 | FP32 | FP16 | ||||||||
| קוֹדַאִי | מפענח | מקצה לקצה | קוֹדַאִי | מפענח | מקצה לקצה | קוֹדַאִי | מפענח | מקצה לקצה | מקצה לקצה | מקצה לקצה | ||
| t5-קטן | g4dn.xlarge | 5.98 | 9.74 | 30.71 | 1.28 | 2.25 | 7.54 | 0.93 | 1.59 | 5.91 | 407.40% | 519.34% |
| g5.xlarge | 4.63 | 7.56 | 24.22 | 0.61 | 1.05 | 3.99 | 0.47 | 0.80 | 3.19 | 606.66% | 760.01% | |
| t5-base | g4dn.xlarge | 11.61 | 19.05 | 78.44 | 3.18 | 5.45 | 19.59 | 3.15 | 2.96 | 13.76 | 400.48% | 569.97% |
| g5.xlarge | 8.59 | 14.23 | 59.98 | 1.55 | 2.47 | 11.32 | 1.54 | 1.65 | 8.46 | 530.05% | 709.20% | |
למידע נוסף על אופטימיזציות ושכפול של הביצועים המצורפים, עיין ב אופטימיזציה של T5 ו-GPT-2 להסקת זמן אמת עם NVIDIA TensorRT.
חשוב לציין שהקומפילציה משמרת את דיוק המודל, שכן היא פועלת על סביבת ההסקה ועל תזמון החישובים, ומשאירה את מדע המודל ללא שינוי - בניגוד לדחיסת הסרת משקל כגון זיקוק או גיזום. NVIDIA TensorRT מאפשר לשלב קומפילציה עם קוונטיזציה לרווחים נוספים. לכימות יש יתרונות כפולים בחומרת NVIDIA עדכנית: היא מפחיתה את השימוש בזיכרון, ומאפשרת שימוש בליבות NVIDIA Tensor, תאים ספציפיים ל-DL המריצים מטריצה ממוזגת-כפל-הוסף בדיוק מעורב.
במקרה של ניסוי Amazon Search עם דגם Hugging Face T5, החלפת PyTorch ב-TensorRT להסקת מודל מגדילה את המהירות ב-534%.
NVIDIA Triton: הגשת הסקת הסקת השהייה נמוכה ותפוקה גבוהה
פתרונות הגשת דגמים מודרניים יכולים להפוך מודלים מאומנים לא מקוונים למוצרים המופעלים על ידי ML מול לקוחות. כדי לשמור על עלויות סבירות בקנה מידה כזה, חשוב לשמור על הגשת תקורה נמוכה (טיפול ב-HTTP, עיבוד מקדים ואחרי עיבוד, תקשורת CPU-GPU), ולנצל באופן מלא את יכולת העיבוד המקביל של מעבדי GPU.
NVIDIA Triton היא תוכנה המשרתת מסקנות המציעה תמיכה רחבה בזמני ריצה של מודלים (NVIDIA TensorRT, ONNX, PyTorch, XGBoost, בין היתר) וחלקים אחוריים של תשתית, כולל GPUs, CPU ו Inferentia של AWS.
מתרגלי ML אוהבים את טריטון מסיבות רבות. יכולת האצווה הדינמית שלו מאפשרת לצבור בקשות הסקת מסקנות במהלך השהיה המוגדרת על ידי המשתמש ובתוך גודל אצווה מרבי המוגדר על ידי המשתמש, כך שהמסק של ה-GPU הוא אצווה, מה שמפחית את תקורה של תקשורת CPU-GPU. שים לב שאצווה דינמית מתרחשת בצד השרת ובתוך מסגרות זמן קצרות מאוד, כך שללקוח המבקש עדיין יש חווית הפעלה סינכרונית, כמעט בזמן אמת. משתמשי Triton נהנים גם מיכולת ביצוע המודל במקביל שלו. GPUs הם ריבוי משימות חזקים המצטיינים בביצוע עומסי עבודה עתירי מחשוב במקביל. Triton ממקסם את הניצול והתפוקה של ה-GPU על ידי שימוש בזרמי CUDA להפעלת מופעי מודל מרובים במקביל. מופעי מודל אלה יכולים להיות מודלים שונים ממסגרות שונות עבור מקרי שימוש שונים, או עותק ישיר של אותו מודל. זה מתורגם לשיפור תפוקה ישיר כאשר יש לך מספיק זיכרון GPU לא פעיל. כמו כן, מכיוון שטריטון אינו קשור למסגרת פיתוח DL ספציפית, הוא מאפשר למדען לבטא את עצמו במלואו, בכלי לפי בחירתם.
עם Triton ב-AWS, Amazon Search מצפה לשרת טוב יותר Amazon.com לקוחות ועומדים בדרישות השהייה בעלות נמוכה. האינטגרציה ההדוקה בין זמן הריצה של TensorRT לשרת Triton מקלה על חווית הפיתוח. שימוש בתשתית ענן AWS מאפשר להגדיל או להקטין תוך דקות על בסיס דרישות התפוקה, תוך שמירה על רף גבוה או אמינות ואבטחה.
איך AWS מוריד את מחסום הכניסה
בעוד שאמזון חיפוש ערכה את הניסוי הזה על תשתית אמזון EC2, שירותי AWS אחרים קיימים כדי להקל על הפיתוח, ההכשרה והאירוח של פתרונות למידה עמוקה מתקדמים.
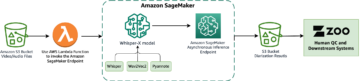
לדוגמה, AWS ו-NVIDIA שיתפו פעולה כדי לשחרר יישום מנוהל של Triton Inference Server ב אמזון SageMaker ; למידע נוסף ראו פרוס AI מהיר וניתן להרחבה עם NVIDIA Triton Inference Server ב-Amazon SageMaker. AWS גם שיתפה פעולה עם Hugging Face כדי לפתח אינטגרציה מנוהלת ומוטבת בין Amazon SageMaker ו-Huging Face Transformers, מסגרת הקוד הפתוח שממנה נגזר מודל Amazon Search T5; קרא עוד ב https://aws.amazon.com/machine-learning/hugging-face/.
אנו מעודדים לקוחות עם יישומי למידה עמוקה של מעבד ו-GPU רגישים לאחזור לשקול את NVIDIA TensorRT ו-Triton ב-AWS. ספר לנו מה אתה בונה!
נלהב מלמידה עמוקה ובניית פתרונות מבוססי למידה עמוקה עבור Amazon Search? בדוק שלנו דף קריירה.
על הכותבים
 RJ הוא מהנדס בצוות Search M5 שמוביל את המאמצים לבניית מערכות למידה עמוקה בקנה מידה גדול לאימון והסקת הסקה. מחוץ לעבודה הוא חוקר מאכלים שונים של אוכל ועוסק בספורט מחבט.
RJ הוא מהנדס בצוות Search M5 שמוביל את המאמצים לבניית מערכות למידה עמוקה בקנה מידה גדול לאימון והסקת הסקה. מחוץ לעבודה הוא חוקר מאכלים שונים של אוכל ועוסק בספורט מחבט.
 המנט פוגליה הוא מדען יישומי ב-Search M5. הוא עובד על יישום המחקר העדכני ביותר של עיבוד שפה טבעית ולמידה עמוקה כדי לשפר את חווית הלקוח בקניות באמזון ברחבי העולם. תחומי המחקר שלו כוללים עיבוד שפה טבעית ומערכות למידת מכונה בקנה מידה גדול. מחוץ לעבודה, הוא נהנה לטייל, לבשל ולקרוא.
המנט פוגליה הוא מדען יישומי ב-Search M5. הוא עובד על יישום המחקר העדכני ביותר של עיבוד שפה טבעית ולמידה עמוקה כדי לשפר את חווית הלקוח בקניות באמזון ברחבי העולם. תחומי המחקר שלו כוללים עיבוד שפה טבעית ומערכות למידת מכונה בקנה מידה גדול. מחוץ לעבודה, הוא נהנה לטייל, לבשל ולקרוא.
 אנדי סאן הוא מהנדס תוכנה ומוביל טכני לתיקון איות חיפוש. תחומי העניין שלו במחקר כוללים אופטימיזציה של השהיית מסקנות למידה עמוקה ובניית פלטפורמות ניסויים מהירות. מחוץ לעבודה, הוא נהנה מעשיית סרטים ואקרובטיקה.
אנדי סאן הוא מהנדס תוכנה ומוביל טכני לתיקון איות חיפוש. תחומי העניין שלו במחקר כוללים אופטימיזציה של השהיית מסקנות למידה עמוקה ובניית פלטפורמות ניסויים מהירות. מחוץ לעבודה, הוא נהנה מעשיית סרטים ואקרובטיקה.
 לה קאי הוא מהנדס תוכנה ב-Amazon Search. הוא עובד על שיפור הביצועים של תיקון איות חיפוש כדי לעזור ללקוחות עם חווית הקנייה שלהם. הוא מתמקד בהסקה מקוונת בעלת ביצועים גבוהים ובאופטימיזציה של הדרכה מבוזרת למודל למידה עמוקה. מחוץ לעבודה, הוא נהנה מסקי, טיולים ורכיבה על אופניים.
לה קאי הוא מהנדס תוכנה ב-Amazon Search. הוא עובד על שיפור הביצועים של תיקון איות חיפוש כדי לעזור ללקוחות עם חווית הקנייה שלהם. הוא מתמקד בהסקה מקוונת בעלת ביצועים גבוהים ובאופטימיזציה של הדרכה מבוזרת למודל למידה עמוקה. מחוץ לעבודה, הוא נהנה מסקי, טיולים ורכיבה על אופניים.
 אנתוני קו עובד כעת כמהנדס תוכנה ב-Search M5 Palo Alto, CA. הוא עובד על בניית כלים ומוצרים לפריסת מודלים ואופטימיזציה של מסקנות. מחוץ לעבודה, הוא נהנה לבשל ולשחק בספורט מחבטים.
אנתוני קו עובד כעת כמהנדס תוכנה ב-Search M5 Palo Alto, CA. הוא עובד על בניית כלים ומוצרים לפריסת מודלים ואופטימיזציה של מסקנות. מחוץ לעבודה, הוא נהנה לבשל ולשחק בספורט מחבטים.
 אוליבייה קרוצ'אנט הוא אדריכל פתרונות מומחה למידת מכונה ב-AWS, שבסיסה בצרפת. אוליבייה עוזרת ללקוחות AWS - החל מסטארט-אפים קטנים ועד לארגונים גדולים - לפתח ולפרוס יישומי למידת מכונה בדרגת ייצור. בזמנו הפנוי הוא נהנה לקרוא מאמרי מחקר ולחקור את השממה עם חברים ובני משפחה.
אוליבייה קרוצ'אנט הוא אדריכל פתרונות מומחה למידת מכונה ב-AWS, שבסיסה בצרפת. אוליבייה עוזרת ללקוחות AWS - החל מסטארט-אפים קטנים ועד לארגונים גדולים - לפתח ולפרוס יישומי למידת מכונה בדרגת ייצור. בזמנו הפנוי הוא נהנה לקרוא מאמרי מחקר ולחקור את השממה עם חברים ובני משפחה.
 אניש מוהאן הוא ארכיטקט למידת מכונה ב-NVIDIA והמנהיג הטכני עבור התקשרויות ML ו-DL עם לקוחותיה באזור סיאטל רבתי.
אניש מוהאן הוא ארכיטקט למידת מכונה ב-NVIDIA והמנהיג הטכני עבור התקשרויות ML ו-DL עם לקוחותיה באזור סיאטל רבתי.
 ג'יהונג ליו הוא ארכיטקט פתרונות בצוות ספק שירותי הענן ב-NVIDIA. הוא מסייע ללקוחות באימוץ פתרונות למידת מכונה ו-AI הממנפים את המחשוב המואץ של NVIDIA כדי להתמודד עם אתגרי ההכשרה וההסקות שלהם. בשעות הפנאי שלו הוא נהנה מאוריגמי, פרויקטים של עשה זאת בעצמך ולשחק כדורסל.
ג'יהונג ליו הוא ארכיטקט פתרונות בצוות ספק שירותי הענן ב-NVIDIA. הוא מסייע ללקוחות באימוץ פתרונות למידת מכונה ו-AI הממנפים את המחשוב המואץ של NVIDIA כדי להתמודד עם אתגרי ההכשרה וההסקות שלהם. בשעות הפנאי שלו הוא נהנה מאוריגמי, פרויקטים של עשה זאת בעצמך ולשחק כדורסל.
 אליוט טריאנה הוא מנהל קשרי מפתחים ב-NVIDIA. הוא מחבר בין מובילי מוצר, מפתחים ומדענים של אמזון ו-AWS עם טכנולוגים ומובילי מוצר של NVIDIA כדי להאיץ את עומסי העבודה של אמזון ML/DL, מוצרי EC2 ושירותי AI של AWS. בנוסף, אליוט הוא רוכב הרים נלהב, גולש סקי ושחקן פוקר.
אליוט טריאנה הוא מנהל קשרי מפתחים ב-NVIDIA. הוא מחבר בין מובילי מוצר, מפתחים ומדענים של אמזון ו-AWS עם טכנולוגים ומובילי מוצר של NVIDIA כדי להאיץ את עומסי העבודה של אמזון ML/DL, מוצרי EC2 ושירותי AI של AWS. בנוסף, אליוט הוא רוכב הרים נלהב, גולש סקי ושחקן פוקר.
- Coinsmart. בורסת הביטקוין והקריפטו הטובה באירופה.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה חופשית.
- CryptoHawk. רדאר אלטקוין. ניסיון חינם.
- מקור: https://aws.amazon.com/blogs/machine-learning/how-amazon-search-achieves-low-latency-high-throughput-t5-inference-with-nvidia-triton-on-aws/
- "
- 100
- 11
- 9
- אודות
- להאיץ
- מוּאָץ
- תוספת
- כתובת
- יתרון
- AI
- שירותי AI
- אלגוריתמים
- תעשיות
- אמזון בעברית
- בין
- בקשה
- יישומים
- מריחה
- ארכיטקטורה
- זמין
- AWS
- כדורסל
- הטבות
- הטוב ביותר
- בִּניָן
- קיבולת
- מקרים
- האתגרים
- ענן
- תשתית ענן
- תקשורת
- לחשב
- מחשוב
- צְרִיכָה
- לתרום
- נוֹחַ
- ליבה
- עלויות
- חווית לקוח
- לקוחות
- נתונים
- מוקדש
- עיכוב
- מספק
- לפרוס
- פריסה
- עיצוב
- לפתח
- מפתח
- מפתחים
- צעצועי התפתחות
- אחר
- ישיר
- מופץ
- DIY
- לְהַכפִּיל
- מטה
- דינמי
- מַאֲמָצִים
- לעודד
- מהנדס
- הנדסה
- מִפְעָל
- סביבה
- דוגמה
- Excel
- הוצאת להורג
- מצפה
- ניסיון
- לְנַסוֹת
- פָּנִים
- פנים
- משפחה
- מהר
- מאפיין
- הבא
- מזון
- עָקֵב
- מצא
- מסגרת
- צרפת
- GPU
- טיפול
- חומרה
- לעזור
- עוזר
- גָבוֹהַ
- איך
- איך
- HTTPS
- הפעלה
- חשוב
- לשפר
- לכלול
- כולל
- מידע
- תשתית
- השתלבות
- אינטרסים
- IT
- ידוע
- שפה
- גָדוֹל
- האחרון
- לשגר
- עוֹפֶרֶת
- מוביל
- לִלמוֹד
- למידה
- תנופה
- אהבה
- מכונה
- למידת מכונה
- לתחזק
- הצליח
- מנהל
- מדריך ל
- מַטרִיצָה
- זכרון
- מעורב
- ML
- מודל
- מודלים
- יותר
- רוב
- MS
- טבעי
- רשתות
- צמתים
- מספר
- מספרים
- רב
- באינטרנט
- לפתוח
- קוד פתוח
- אופטימיזציה
- להזמין
- אחר
- ביצועים
- פלטפורמה
- פלטפורמות
- שחקן
- פופולרי
- חזק
- להציג
- ללחוץ
- תהליך
- המוצר
- הפקה
- מוצרים
- פרויקטים
- מבטיח
- ציבורי
- קריאה
- זמן אמת
- הבין
- סביר
- סיבות
- הפחתה
- לשחרר
- דרישות
- מחקר
- REST
- תוצאות
- הפעלה
- ריצה
- להרחבה
- סולם
- מדע
- מַדְעָן
- מדענים
- Sdk
- חיפוש
- אבטחה
- שרות
- שירותים
- הגשה
- סט
- הצבה
- צורות
- קניות
- קצר
- משמעותי
- מידה
- קטן
- So
- תוכנה
- מהנדס תוכנה
- פִּתָרוֹן
- פתרונות
- מיוחד
- מְהִירוּת
- ספורט
- חברות סטארט
- מדינה-of-the-art
- תמיכה
- מערכות
- לדבר
- יעד
- נבחרת
- טכני
- טכנולוגים
- קָשׁוּר
- זמן
- מטבעות
- כלי
- כלים
- הדרכה
- לשנות
- עדכונים
- us
- להשתמש
- משתמשים
- חזון
- מה
- בתוך
- מילים
- תיק עבודות
- עובד
- עובד
- עולמי