פוסט זה נכתב בשיתוף עם Mahima Agarwal, מהנדס למידת מכונה, ודיפק מטם, מנהל הנדסה בכיר, ב-VMware Carbon Black
VMware פחמן שחור הוא פתרון אבטחה ידוע המציע הגנה מפני כל הספקטרום של התקפות סייבר מודרניות. עם טרה-בייט של נתונים שנוצרו על ידי המוצר, צוות ניתוח האבטחה מתמקד בבניית פתרונות למידת מכונה (ML) כדי להציג התקפות קריטיות ולהאיר זרקור איומים המתעוררים מרעש.
זה קריטי לצוות VMware Carbon Black לתכנן ולבנות צינור MLOps מותאם אישית מקצה לקצה, שמתזמר וממכן זרימות עבודה במחזור החיים של ML ומאפשר הדרכה, הערכות ופריסה של מודלים.
ישנן שתי מטרות עיקריות לבניית צינור זה: תמיכה במדענים לפיתוח מודלים בשלבים מאוחרים, וחיזוי מודל עילי במוצר על ידי הגשת מודלים בנפח גבוה ובתעבורת ייצור בזמן אמת. לכן, VMware Carbon Black ו-AWS בחרו לבנות צינור MLOps מותאם אישית באמצעות אמזון SageMaker על קלות השימוש, הרבגוניות והתשתית המנוהלת במלואה. אנו מתזמרים את צינורות ההדרכה והפריסה של ML שלנו באמצעות תהליכי עבודה מנוהלים של אמזון עבור זרימת האוויר של אפאצ'י (Amazon MWAA), המאפשרת לנו להתמקד יותר בתכנון תהליכי עבודה וצינורות ללא צורך לדאוג לגבי קנה מידה אוטומטי או תחזוקת תשתית.
עם צינור זה, מה שהיה פעם מחקר ML מונע מחברת Jupyter הוא כעת תהליך אוטומטי של פריסת מודלים לייצור עם מעט התערבות ידנית של מדעני נתונים. מוקדם יותר, תהליך ההכשרה, ההערכה והפריסה של מודל יכול לקחת יותר מיום; עם היישום הזה, הכל נמצא במרחק טריגר והפחית את הזמן הכולל לכמה דקות.
בפוסט זה, אדריכלי VMware Carbon Black ו-AWS דנים כיצד בנינו וניהלנו זרימות עבודה מותאמות אישית של ML באמצעות גיטלב, Amazon MWAA ו- SageMaker. אנו דנים במה שהשגנו עד כה, שיפורים נוספים בצנרת ולקחים שנלמדו לאורך הדרך.
סקירת פתרונות
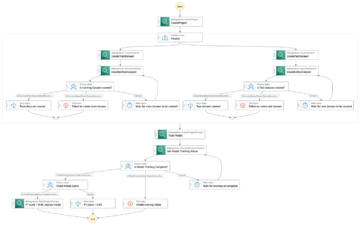
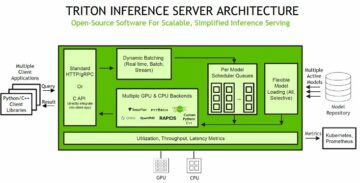
התרשים הבא ממחיש את ארכיטקטורת פלטפורמת ML.

עיצוב פתרונות ברמה גבוהה
פלטפורמת ML זו תוכננה ונועדה להיות נצרך על ידי דגמים שונים על פני מאגרי קוד שונים. הצוות שלנו משתמש ב-GitLab ככלי לניהול קוד מקור כדי לתחזק את כל מאגרי הקוד. כל שינוי בקוד המקור של מאגר המודלים משולבים באופן רציף באמצעות ה Gitlab CI, אשר מפעיל את זרימות העבודה הבאות בצנרת (הדרכה של מודל, הערכה ופריסה).
דיאגרמת הארכיטקטורה הבאה ממחישה את זרימת העבודה מקצה לקצה ואת הרכיבים המעורבים בצינור MLOps שלנו.

זרימת עבודה מקצה לקצה
צינורות ההדרכה, ההערכה והפריסה של מודל ML מתוזמרים באמצעות Amazon MWAA, המכונה בימוי גרף Acyclic (DAG). DAG הוא אוסף של משימות ביחד, מאורגנות עם תלות ומערכות יחסים כדי לומר כיצד עליהן לפעול.
ברמה גבוהה, ארכיטקטורת הפתרון כוללת שלושה מרכיבים עיקריים:
- מאגר קודים של צינורות ML
- צינור הדרכה והערכה של מודל ML
- צינור פריסת מודל ML
הבה נדון כיצד הרכיבים השונים הללו מנוהלים וכיצד הם מקיימים אינטראקציה זה עם זה.
מאגר קודים של צינורות ML
לאחר שה-repo של המודל משלב את ה-MLOps כ-pipeline שלהם במורד הזרם, ומדען נתונים מחייב קוד ב-repo של המודל שלו, רץ של GitLab מבצע אימות ובדיקות קוד סטנדרטיים המוגדרים ב-repo זה ומפעיל את צינור ה-MLOps בהתבסס על שינויי הקוד. אנו משתמשים בצינור מרובת הפרויקטים של Gitlab כדי לאפשר טריגר זה על פני ריפואים שונים.
צינור MLOps GitLab מפעיל סט מסוים של שלבים. הוא מבצע אימות קוד בסיסי באמצעות pylint, אורז את קוד ההדרכה וההסקה של המודל בתוך תמונת Docker, ומפרסם את תמונת המיכל ל- מרשם מיכל אלסטי של אמזון (Amazon ECR). Amazon ECR הוא רישום מיכלים מנוהל במלואו המציע אירוח בעל ביצועים גבוהים, כך שתוכל לפרוס באופן מהימן תמונות אפליקציות וחפצים בכל מקום.
צינור הדרכה והערכה של מודל ML
לאחר פרסום התמונה, היא מפעילה את ההדרכה וההערכה זרימת אוויר של אפאצ'י צינור דרך AWS למבדה פוּנקצִיָה. Lambda הוא שירות מחשוב נטול שרתים מונע אירועים המאפשר לך להריץ קוד כמעט עבור כל סוג של יישום או שירות אחורי מבלי להקצות או לנהל שרתים.
לאחר שהצנרת מופעלת בהצלחה, היא מפעילה את ה-DAG Training and Evaluation, אשר בתורו מתחיל את הדרכת המודל ב- SageMaker. בסוף צינור הדרכה זה, קבוצת המשתמשים שזוהתה מקבלת הודעה עם תוצאות ההדרכה והערכת המודלים באמצעות דואר אלקטרוני דרך שירות התראה פשוט של אמזון (Amazon SNS) ו-Slack. Amazon SNS הוא שירות פאב/משנה מנוהל במלואו עבור הודעות A2A ו-A2P.
לאחר ניתוח מדוקדק של תוצאות ההערכה, מדען הנתונים או מהנדס ML יכולים לפרוס את המודל החדש אם הביצועים של המודל שהוכשר לאחרונה טובים יותר בהשוואה לגרסה הקודמת. הביצועים של המודלים מוערכים על סמך המדדים הספציפיים למודל (כגון ציון F1, MSE או מטריצת בלבול).
צינור פריסת מודל ML
כדי להתחיל את הפריסה, המשתמש מתחיל את עבודת GitLab שמפעילה את ה-Deployment DAG דרך אותה פונקציית Lambda. לאחר שהצינור פועל בהצלחה, הוא יוצר או מעדכן את נקודת הקצה של SageMaker עם הדגם החדש. זה גם שולח הודעה עם פרטי נקודת הקצה בדוא"ל באמצעות Amazon SNS ו-Slack.
במקרה של כשל באחד מהצינורות, המשתמשים מקבלים הודעה באותם ערוצי תקשורת.
SageMaker מציע הסקת הסקה בזמן אמת שהיא אידיאלית לעומסי עבודה עם השהייה נמוכה ודרישות תפוקה גבוהות. נקודות קצה אלו מנוהלות במלואן, מאוזנות עומסים ומותאמות אוטומטית, וניתן לפרוס אותן על פני מספר אזורי זמינות לזמינות גבוהה. הצינור שלנו יוצר נקודת קצה כזו עבור מודל לאחר שהוא פועל בהצלחה.
בסעיפים הבאים נרחיב על המרכיבים השונים וצולל לפרטים.
GitLab: חבילות מודלים וצינורות טריגר
אנו משתמשים ב-GitLab כמאגר הקוד שלנו ועבור הצינור כדי לארוז את קוד הדגם ולהפעיל DAGs של זרימת אוויר במורד הזרם.
צינור רב פרויקטים
תכונת ה- GitLab מרובת פרויקטים משמשת כאשר צינור האב (במעלה הזרם) הוא מאגר מודל והצינור הצאצא (בהמשך) הוא ה-MLOps repo. כל ריפו שומר על .gitlab-ci.yml, ובלוק הקוד הבא המופעל בצינור במעלה הזרם מפעיל את צינור MLOps במורד הזרם.
הצינור במעלה הזרם שולח את קוד הדגם אל הצינור במורד הזרם שבו מופעלות עבודות האריזה והפרסום של CI. הקוד למיכל קוד הדגם ולפרסם אותו באמזון ECR מתוחזק ומנוהל על ידי צינור MLOps. הוא שולח את המשתנים כמו ACCESS_TOKEN (ניתן ליצור תחת הגדרות, גִישָׁה), JOB_ID (כדי לגשת לממצאים במעלה הזרם), ומשתני $CI_PROJECT_ID (מזהה הפרויקט של מודל repo), כך שהצינור של MLOps יוכל לגשת לקובצי קוד המודל. עם ה חפצי עבודה תכונה מ- Gitlab, ה-repo במורד הזרם ניגש לממצאים המרוחקים באמצעות הפקודה הבאה:
ריפו המודל יכול לצרוך צינורות במורד הזרם עבור דגמים מרובים מאותו ריפו על ידי הארכת השלב שמפעיל אותו באמצעות משתרע מילת מפתח מבית GitLab, המאפשרת לך לעשות שימוש חוזר באותה תצורה על פני שלבים שונים.
לאחר פרסום תמונת הדגם לאמזון ECR, צינור MLOps מפעיל את צינור ההדרכה של אמזון MWAA באמצעות Lambda. לאחר אישור המשתמש, הוא מפעיל את פריסת המודל של Amazon MWAA pipeline גם באמצעות אותה פונקציית Lambda.
ניהול גרסאות סמנטיות והעברת גרסאות במורד הזרם
פיתחנו קוד מותאם אישית לגרסת תמונות ECR ודגמי SageMaker. הצינור של MLOps מנהל את הלוגיקה הסמנטית של גירסאות התמונות והדגמים כחלק מהשלב שבו קוד המודל מתרכז, ומעביר את הגרסאות לשלבים מאוחרים יותר כחפצים.
הסבה מקצועית
מכיוון שהסבה מחדש היא היבט מכריע במחזור החיים של ML, הטמענו יכולות הסבה מחדש כחלק מהצינור שלנו. אנו משתמשים בממשק ה-API של SageMaker list-models כדי לזהות אם מדובר באימון מחדש בהתבסס על מספר גרסת הדרכה וחותמת הזמן של המודל.
אנו מנהלים את לוח הזמנים היומי של צינור ההסבה באמצעות צינורות לוח הזמנים של GitLab.
Terraform: הגדרת תשתית
בנוסף לאשכול MWAA של אמזון, מאגרי ECR, פונקציות Lambda ונושא SNS, פתרון זה משתמש גם AWS זהות וניהול גישה (IAM) תפקידים, משתמשים ומדיניות; שירות אחסון פשוט של אמזון (אמזון S3) דליים, וא אמזון CloudWatch משלח יומן.
כדי לייעל את הגדרת התשתית והתחזוקה עבור השירותים המעורבים לאורך הצינור שלנו, אנו משתמשים Terraform ליישם את התשתית כקוד. בכל פעם שנדרשים עדכוני אינפרא, השינויים בקוד מפעילים צינור GitLab CI שהקמנו, אשר מאמת ופריסה את השינויים בסביבות שונות (לדוגמה, הוספת הרשאה למדיניות IAM בחשבונות dev, stage ו-prod).
Amazon ECR, Amazon S3 ולמבדה: הנחיית צינורות
אנו משתמשים בשירותי המפתח הבאים כדי להקל על הצינור שלנו:
- אמזון ECR – כדי לשמור ולאפשר שליפה נוחה של תמונות המכולה של הדגם, אנו מתייגים אותן עם גרסאות סמנטיות ומעלים אותן למאגרי ECR שהוגדרו לפי
${project_name}/${model_name}דרך Terraform. זה מאפשר שכבה טובה של בידוד בין מודלים שונים, ומאפשר לנו להשתמש באלגוריתמים מותאמים אישית ולעצב בקשות מסקנות ותגובות כדי לכלול מידע מניפסט מודל רצוי (שם דגם, גרסה, נתיב נתוני אימון וכן הלאה). - אמזון S3 - אנו משתמשים בדלי S3 כדי להתמיד בנתוני אימון מודל, חפצי מודל מאומנים לכל דגם, DAGs של זרימת אוויר ומידע נוסף אחר הנדרש על ידי הצינורות.
- למבדה - מכיוון שאשכול זרימת האוויר שלנו פרוס ב-VPC נפרד משיקולי אבטחה, לא ניתן לגשת ישירות ל-DAGs. לכן, אנו משתמשים בפונקציית Lambda, המתוחזקת גם עם Terraform, כדי להפעיל כל DAGs שצוין בשם DAG. עם הגדרה נכונה של IAM, משימת GitLab CI מפעילה את פונקציית Lambda, שעוברת דרך התצורות עד לדגי ההדרכה או הפריסה המבוקשים.
Amazon MWAA: צינורות הדרכה ופריסה
כפי שהוזכר קודם לכן, אנו משתמשים ב-Amazon MWAA כדי לתזמן את צינורות ההדרכה והפריסה. אנו משתמשים באופרטורים של SageMaker הזמינים ב- חבילת ספקים של אמזון עבור Airflow להשתלב עם SageMaker (כדי למנוע תבנית ג'ינג'ה).
אנו משתמשים באופרטורים הבאים בצינור הדרכה זה (מוצג בתרשים זרימת העבודה הבא):

צינור אימון MWAA
אנו משתמשים באופרטורים הבאים בצינור הפריסה (מוצג בתרשים זרימת העבודה הבא):

צינור פריסת מודל
אנו משתמשים ב-Slack וב-Amazon SNS כדי לפרסם את הודעות השגיאה/הצלחה ותוצאות ההערכה בשני הצינורות. Slack מספק מגוון רחב של אפשרויות להתאמה אישית של הודעות, כולל האפשרויות הבאות:
- SnsPublishOperator - אנו משתמשים SnsPublishOperator לשלוח התראות על הצלחה/כישלון למיילים של משתמשים
- Slack API – יצרנו את כתובת URL נכנסת של webhook כדי לקבל את הודעות הצינור לערוץ הרצוי
CloudWatch ו-VMware Wavefront: ניטור ורישום
אנו משתמשים בלוח מחוונים של CloudWatch כדי להגדיר ניטור ורישום נקודות קצה. זה עוזר לדמיין ולעקוב אחר מדדי ביצועים תפעוליים ומודלים שונים ספציפיים לכל פרויקט. בנוסף למדיניות קנה המידה האוטומטי שהוגדרה כדי לעקוב אחר חלק מהן, אנו עוקבים באופן רציף אחר השינויים בשימוש במעבד וזיכרון, בקשות לשנייה, זמן השהיית תגובה ומדדי מודל.
CloudWatch אפילו משולב עם לוח מחוונים של VMware Tanzu Wavefront כך שהוא יכול לדמיין את המדדים עבור נקודות קצה של מודל כמו גם שירותים אחרים ברמת הפרויקט.
הטבות עסקיות ומה הלאה
צינורות ML חיוניים מאוד לשירותי ותכונות ML. בפוסט זה, דנו במקרה שימוש ב-ML מקצה לקצה באמצעות יכולות מ-AWS. בנינו צנרת מותאמת אישית באמצעות SageMaker ו-Amazon MWAA, שבה נוכל לעשות שימוש חוזר בין פרויקטים ודגמים, ויצרנו את מחזור החיים של ML, מה שהפחית את הזמן מהכשרת מודלים ועד לפריסת הייצור ל-10 דקות בלבד.
עם העברת נטל מחזור החיים של ML ל- SageMaker, היא סיפקה תשתית אופטימלית וניתנת להרחבה להדרכה ופריסה של המודל. הגשת מודלים עם SageMaker עזרה לנו לבצע תחזיות בזמן אמת עם זמן השהייה של אלפיות שנייה ויכולות ניטור. השתמשנו ב- Terraform כדי להקל על ההגדרה ולנהל תשתית.
הצעדים הבאים עבור צינור זה יהיו לשפר את צינור ההכשרה של המודל עם יכולות אימון מחדש בין אם הוא מתוזמן או מבוסס על זיהוי סחיפה של מודל, תמיכה בפריסת צללים או בדיקות A/B לפריסת מודל מהירה ומוסמכת יותר, ומעקב אחר שושלת ML. אנחנו גם מתכננים להעריך צינורות SageMaker של אמזון מכיוון ששילוב GitLab נתמך כעת.
לקחים שהופק
כחלק מבניית הפתרון הזה, למדנו שצריך להכליל מוקדם, אבל לא להכליל יתר על המידה. כשסיימנו לראשונה את תכנון הארכיטקטורה, ניסינו ליצור ולאכוף תבנית קוד עבור קוד המודל כדרך מומלצת. עם זאת, זה היה כל כך מוקדם בתהליך הפיתוח שהתבניות היו כלליות מדי או מפורטות מדי מכדי שניתן יהיה להשתמש בהן מחדש עבור דגמים עתידיים.
לאחר מסירת הדגם הראשון דרך הצינור, התבניות יצאו באופן טבעי בהתבסס על התובנות מהעבודה הקודמת שלנו. צינור לא יכול לעשות הכל מהיום הראשון.
לניסויים ולייצור מודלים יש לרוב דרישות שונות מאוד (או לפעמים אפילו סותרות). חשוב לאזן את הדרישות הללו מההתחלה כצוות ולתעדף בהתאם.
בנוסף, ייתכן שלא תזדקק לכל תכונה של שירות. שימוש בתכונות חיוניות משירות ובעל עיצוב מודולרי הם מפתחות לפיתוח יעיל יותר ולצינור גמיש.
סיכום
בפוסט זה, הראינו כיצד בנינו פתרון MLOps באמצעות SageMaker ו-Amazon MWAA שהפך את תהליך פריסת המודלים לייצור אוטומטית, עם מעט התערבות ידנית של מדעני נתונים. אנו ממליצים לך להעריך שירותי AWS שונים כמו SageMaker, Amazon MWAA, Amazon S3 ו-Amazon ECR כדי לבנות פתרון MLOps שלם.
*Apache, Apache Airflow ו-Airflow הם סימנים מסחריים רשומים או סימנים מסחריים של קרן אפאצ 'י תוכנה בארצות הברית ו / או במדינות אחרות.
על הכותבים
 דיפק מטם הוא מנהל הנדסה בכיר ב-VMware, יחידת פחמן שחור. הוא והצוות שלו עובדים על בניית האפליקציות והשירותים המבוססים על סטרימינג שהם זמינים ביותר, ניתנים להרחבה וגמישים כדי להביא ללקוחות פתרונות מבוססי למידת מכונה בזמן אמת. הוא והצוות שלו אחראים גם ליצירת כלים הדרושים למדעני נתונים כדי לבנות, לאמן, לפרוס ולאמת את מודל ה-ML שלהם בייצור.
דיפק מטם הוא מנהל הנדסה בכיר ב-VMware, יחידת פחמן שחור. הוא והצוות שלו עובדים על בניית האפליקציות והשירותים המבוססים על סטרימינג שהם זמינים ביותר, ניתנים להרחבה וגמישים כדי להביא ללקוחות פתרונות מבוססי למידת מכונה בזמן אמת. הוא והצוות שלו אחראים גם ליצירת כלים הדרושים למדעני נתונים כדי לבנות, לאמן, לפרוס ולאמת את מודל ה-ML שלהם בייצור.
 מהימה אגרוואל הוא מהנדס למידת מכונה ב-VMware, יחידת פחמן שחור.
מהימה אגרוואל הוא מהנדס למידת מכונה ב-VMware, יחידת פחמן שחור.
היא עובדת על תכנון, בנייה ופיתוח של רכיבי הליבה והארכיטקטורה של פלטפורמת למידת המכונה עבור VMware CB SBU.
 ואמשי קרישנה אנבוטאלה הוא Sr. Applied AI Specialist Architect ב-AWS. הוא עובד עם לקוחות ממגזרים שונים כדי להאיץ יוזמות נתונים, ניתוחים ולמידת מכונה בעלי השפעה גבוהה. הוא נלהב ממערכות המלצות, NLP ותחומי ראייה ממוחשבת ב-AI ו-ML. מחוץ לעבודה, ואמשי הוא חובב RC, בונה ציוד RC (מטוסים, מכוניות ומזל"טים), וגם נהנה מגינון.
ואמשי קרישנה אנבוטאלה הוא Sr. Applied AI Specialist Architect ב-AWS. הוא עובד עם לקוחות ממגזרים שונים כדי להאיץ יוזמות נתונים, ניתוחים ולמידת מכונה בעלי השפעה גבוהה. הוא נלהב ממערכות המלצות, NLP ותחומי ראייה ממוחשבת ב-AI ו-ML. מחוץ לעבודה, ואמשי הוא חובב RC, בונה ציוד RC (מטוסים, מכוניות ומזל"טים), וגם נהנה מגינון.
 סאהיל תפאר הוא אדריכל פתרונות ארגוניים. הוא עובד עם לקוחות כדי לעזור להם לבנות יישומים זמינים, מדרגיים ועמידים ביותר בענן AWS. כיום הוא מתמקד בקונטיינרים ובפתרונות למידת מכונה.
סאהיל תפאר הוא אדריכל פתרונות ארגוניים. הוא עובד עם לקוחות כדי לעזור להם לבנות יישומים זמינים, מדרגיים ועמידים ביותר בענן AWS. כיום הוא מתמקד בקונטיינרים ובפתרונות למידת מכונה.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :הוא
- $ למעלה
- 1
- 10
- 100
- 7
- 8
- a
- אודות
- להאיץ
- גישה
- נצפה
- לפיכך
- חשבונות
- הושג
- לרוחב
- מחזורי
- תוספת
- נוסף
- מידע נוסף
- לאחר
- נגד
- AI
- אלגוריתמים
- תעשיות
- מאפשר
- אמזון בעברית
- אמזון SageMaker
- אנליזה
- ניתוח
- ו
- בְּכָל מָקוֹם
- אַפָּשׁ
- API
- בקשה
- יישומים
- יישומית
- יישום AI
- הסכמה
- ארכיטקטורה
- ARE
- אזורים
- AS
- אספקט
- At
- המתקפות
- מחבר
- המכונית
- אוטומטי
- אוטומטית
- זמינות
- זמין
- לְהִמָנַע
- AWS
- קצה אחורי
- איזון
- מבוסס
- בסיסי
- BE
- כי
- התחלה
- הטבות
- הטוב ביותר
- מוטב
- בֵּין
- שחור
- לחסום
- סניף
- להביא
- לִבנוֹת
- בִּניָן
- נבנה
- ניטל
- by
- CAN
- לא יכול
- יכולות
- פַּחמָן
- מכוניות
- מקרה
- CB
- מסוים
- שינויים
- ערוצים
- ילד
- בחר
- ענן
- אשכול
- קוד
- אוסף
- תקשורת
- לעומת
- להשלים
- רכיבים
- לחשב
- המחשב
- ראייה ממוחשבת
- מנצח
- תְצוּרָה
- תצורות
- מתנגש
- בלבול
- שיקולים
- לצרוך
- מאוכל
- מכולה
- מכולות
- ברציפות
- נוֹחַ
- ליבה
- יכול
- מדינות
- CPU
- לִיצוֹר
- נוצר
- יוצר
- יוצרים
- קריטי
- מכריע
- כיום
- מנהג
- לקוחות
- אישית
- התקפות רשת
- DAG
- יומי
- לוח מחוונים
- נתונים
- מדען נתונים
- יְוֹם
- מוגדר
- אספקה
- לפרוס
- פרס
- פריסה
- פריסה
- פריסות
- פורס
- עיצוב
- מעוצב
- תכנון
- מְפוֹרָט
- פרטים
- איתור
- dev
- מפותח
- מתפתח
- צעצועי התפתחות
- אחר
- ישירות
- לדון
- נָדוֹן
- סַוָר
- לא
- מטה
- מזל"ט
- כל אחד
- מוקדם יותר
- מוקדם
- קלות שימוש
- יעיל
- או
- אמייל
- מתעורר
- לאפשר
- מופעל
- מאפשר
- לעודד
- מקצה לקצה
- נקודת קצה
- מהנדס
- הנדסה
- מִפְעָל
- פתרונות ארגוניים
- נלהב
- סביבות
- ציוד
- חיוני
- Ether (ETH)
- להעריך
- העריך
- הערכה
- הערכה
- הערכות
- אֲפִילוּ
- אירוע
- כל
- הכל
- דוגמה
- לְהַרְחִיב
- מאריך
- f1
- לְהַקֵל
- כשלון
- רחוק
- מהר יותר
- מאפיין
- תכונות
- מעטים
- קבצים
- ראשון
- גמיש
- להתמקד
- מרוכז
- מתמקד
- הבא
- בעד
- פוּרמָט
- החל מ-
- מלא
- ספקטרום מלא
- לגמרי
- פונקציה
- פונקציות
- נוסף
- עתיד
- נוצר
- לקבל
- טוב
- קְבוּצָה
- יש
- יש
- לעזור
- עזר
- עוזר
- גָבוֹהַ
- ביצועים גבוהים
- מאוד
- אירוח
- איך
- אולם
- HTML
- http
- HTTPS
- IAM
- ID
- אידאל
- מזוהה
- לזהות
- זהות
- תמונה
- תמונות
- ליישם
- הפעלה
- יושם
- in
- לכלול
- כולל
- כולל
- מידע
- תשתית
- יוזמות
- תובנות
- לשלב
- משולב
- משלב
- השתלבות
- אינטראקציה
- התערבות
- מעורר
- מעורב
- בדידות
- IT
- שֶׁלָה
- עבודה
- מקומות תעסוקה
- jpg
- שמור
- מפתח
- מפתחות
- חֶבִיוֹן
- שכבה
- למד
- למידה
- שיעורים
- הפקת לקחים
- מאפשר לי
- רמה
- מעגל החיים
- כמו
- קְצָת
- לִטעוֹן
- נמוך
- מכונה
- למידת מכונה
- ראשי
- לתחזק
- שומר
- תחזוקה
- לעשות
- לנהל
- הצליח
- ניהול
- מנהל
- מצליח
- ניהול
- מדריך ל
- מַטרִיצָה
- זכרון
- מוּזְכָּר
- הודעות
- הודעות
- מדדים
- יכול
- מילי שניות
- דקות
- ML
- MLOps
- מודל
- מודלים
- מודרני
- צג
- ניטור
- יותר
- יותר יעיל
- מספר
- שם
- כמובן
- הכרחי
- צורך
- חדש
- הבא
- NLP
- רעש
- הודעה
- הודעות
- מספר
- of
- הצעה
- המיוחדות שלנו
- on
- ONE
- מבצעי
- מפעילי
- אופטימיזציה
- אפשרויות
- מתוזמר
- מאורגן
- אחר
- בחוץ
- מקיף
- חבילה
- חבילות
- אריזה
- חלק
- מעברי
- חולף
- לוהט
- נתיב
- ביצועים
- רשות
- צינור
- תכנית
- מטוסים
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- מדיניות
- מדיניות
- הודעה
- תרגול
- התחזיות
- קודם
- תיעדוף
- תהליך
- המוצר
- הפקה
- פּרוֹיֶקט
- פרויקטים
- תָקִין
- .
- ובלבד
- ספק
- מספק
- לפרסם
- לאור
- מפרסם
- הוצאה לאור
- למטרות
- מוסמך
- רכס
- זמן אמת
- המלצה
- מופחת
- מכונה
- רשום
- רישום
- מערכות יחסים
- מרחוק
- ידוע
- מאגר
- בקשתי
- בקשות
- נדרש
- דרישות
- מחקר
- מִתאוֹשֵׁשׁ מַהֵר
- תגובה
- אחראי
- תוצאות
- הסבה מקצועית
- לשימוש חוזר
- תפקידים
- הפעלה
- רץ
- בעל חכמים
- אותו
- להרחבה
- דרוג
- לוח זמנים
- מתוכנן
- מַדְעָן
- מדענים
- שְׁנִיָה
- סעיפים
- מגזרים
- אבטחה
- לחצני מצוקה לפנסיונרים
- נפרד
- ללא שרת
- שרתים
- שרות
- שירותים
- הגשה
- סט
- התקנה
- Shadow
- הסטה
- צריך
- הראה
- פָּשׁוּט
- רָפוּי
- So
- עד כה
- תוכנה
- פִּתָרוֹן
- פתרונות
- כמה
- מָקוֹר
- קוד מקור
- מומחה
- ספציפי
- מפורט
- ספֵּקטרוּם
- זַרקוֹר
- התמחות
- שלבים
- תֶקֶן
- התחלה
- התחלות
- הברית
- צעדים
- אחסון
- אִסטרָטֶגִיָה
- נהירה
- לייעל
- לאחר מכן
- בהצלחה
- כזה
- תמיכה
- נתמך
- משטח
- מערכות
- תָג
- לקחת
- משימות
- נבחרת
- תבניות
- Terraform
- בדיקות
- זֶה
- אל האני
- שֶׁלָהֶם
- אותם
- לכן
- אלה
- איומים
- שְׁלוֹשָׁה
- דרך
- בכל
- תפוקה
- זמן
- חותם
- ל
- יַחַד
- גַם
- כלי
- כלים
- חלק עליון
- נושא
- לעקוב
- מעקב
- סימני מסחר
- תְנוּעָה
- רכבת
- מְאוּמָן
- הדרכה
- להפעיל
- מופעל
- תור
- תחת
- יחידה
- מאוחד
- ארצות הברית
- עדכונים
- us
- נוֹהָג
- להשתמש
- במקרה להשתמש
- משתמש
- משתמשים
- לְאַמֵת
- אימות
- משתנים
- שונים
- גרסה
- כמעט
- חזון
- לחזות
- VMware
- כֶּרֶך
- דֶרֶך..
- טוֹב
- מה
- אם
- אשר
- רָחָב
- טווח רחב
- עם
- בתוך
- לְלֹא
- תיק עבודות
- זרימת עבודה
- זרימות עבודה
- עובד
- היה
- זפירנט
- רוכסן
- אזורי