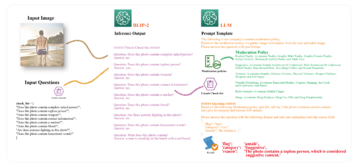
מודלים גדולים של שנאים מבוססי תשומת לב השיגו רווחים מסיביים בעיבוד שפה טבעית (NLP). עם זאת, אימון רשתות ענק אלו מאפס דורש כמות אדירה של נתונים ומחשוב. עבור מערכי נתונים קטנים יותר של NLP, אסטרטגיה פשוטה אך יעילה היא להשתמש בשנאי מאומן מראש, בדרך כלל מאומן בצורה לא מפוקחת על מערכי נתונים גדולים מאוד, ולכוונן אותו במערך הנתונים המעניין. פנים מחבקות מחזיקה בגן חיות מדגם גדול של השנאים שעברו הכשרה מראש והופכת אותם לנגישים בקלות גם למשתמשים מתחילים.
עם זאת, כוונון עדין של מודלים אלה עדיין דורש ידע מומחה, מכיוון שהם די רגישים לפרמטרים ההיפר-פרמטרים שלהם, כגון קצב למידה או גודל אצווה. בפוסט זה, אנו מראים כיצד לבצע אופטימיזציה של ההיפרפרמטרים הללו עם מסגרת הקוד הפתוח Syne Tune עבור אופטימיזציה של היפרפרמטרים מבוזרת (HPO). Syne Tune מאפשר לנו למצוא תצורת היפרפרמטר טובה יותר המשיגה שיפור יחסי בין 1-4% בהשוואה לפרמטרי היפרפרמטרים המוגדרים כברירת מחדל בפופולרי דבק מערכי נתונים של benchmark. גם הבחירה בדגם שהוכשר מראש עצמו יכולה להיחשב כהיפרפרמטר ולכן תיבחר אוטומטית על ידי Syne Tune. בבעיית סיווג טקסט, זה מוביל לעלייה נוספת ברמת הדיוק של כ-5% בהשוואה למודל ברירת המחדל. עם זאת, אנו יכולים להפוך יותר החלטות שמשתמש צריך לקבל; אנו מדגימים זאת גם על ידי חשיפת סוג המופע כהיפרפרמטר שבו אנו משתמשים מאוחר יותר לפריסת המודל. על ידי בחירת סוג המופע המתאים, נוכל למצוא תצורות המחליפות את העלות והשהייה בצורה אופטימלית.
למבוא ל-Syne Tune עיין ב הפעל עבודות כוונון של היפרפרמטרים וארכיטקטורה עצבית עם Syne Tune.
אופטימיזציה של היפרפרמטרים עם Syne Tune
אנו נשתמש דבק חבילת benchmark, המורכבת מתשעה מערכי נתונים עבור משימות הבנת שפה טבעית, כגון זיהוי טקסטואלי או ניתוח סנטימנטים. לשם כך, אנו מתאימים את Hugging Face's run_glue.py תסריט אימון. מערכי נתונים של GLUE מגיעים עם ערכת הכשרה והערכה מוגדרת מראש עם תוויות וכן ערכת בדיקות חזקה ללא תוויות. לכן, אנו מחלקים את מערך ההדרכה למערכי הדרכה ואימות (70%/30% פיצול) ומשתמשים בערכת ההערכה כמערך הנתונים של מבחן ההחזקה שלנו. יתרה מזאת, אנו מוסיפים עוד פונקציית התקשרות חוזרת ל-Trainer API של Hugging Face המדווחת על ביצועי האימות לאחר כל תקופה חזרה ל-Syne Tune. ראה את הקוד הבא:
אנו מתחילים באופטימיזציה של היפרפרמטרים טיפוסיים לאימון: קצב הלמידה, יחס החימום להגדלת קצב הלמידה וגודל האצווה לכוונון עדין של BERT מאומן מראש (bert-base-case) model, שהוא דגם ברירת המחדל בדוגמה של Hugging Face. ראה את הקוד הבא:
כשיטת HPO שלנו, אנו משתמשים ASHA, אשר דוגמת תצורות היפרפרמטרים באופן אחיד באקראי ומפסיקה באופן איטרטיבי את ההערכה של תצורות בעלות ביצועים גרועים. למרות ששיטות מתוחכמות יותר משתמשות במודל הסתברותי של הפונקציה האובייקטיבית, כגון BO או MoBster קיים, אנו משתמשים ב-ASHA עבור פוסט זה מכיוון שהוא מגיע ללא הנחות על מרחב החיפוש.
באיור הבא, אנו משווים את השיפור היחסי בשגיאת הבדיקה לעומת תצורת ההיפרפרמטרים המוגדרים כברירת מחדל של Hugging Faces.
![]()
למען הפשטות, אנו מגבילים את ההשוואה ל-MRPC, COLA ו-STSB, אך אנו רואים גם שיפורים דומים גם עבור מערכי נתונים אחרים של GLUE. עבור כל מערך נתונים, אנו מפעילים את ASHA על ml.g4dn.xlarge יחיד אמזון SageMaker מופע עם תקציב זמן ריצה של 1,800 שניות, המתאים לכ-13, 7 ו-9 הערכות פונקציות מלאות במערך הנתונים הללו, בהתאמה. כדי לתת את הדעת על האקראיות הפנימית של תהליך האימון, למשל הנגרמת על ידי דגימת המיני-אצווה, אנו מפעילים גם את ASHA וגם את תצורת ברירת המחדל עבור חמש חזרות עם סיד עצמאי עבור מחולל המספרים האקראיים ומדווחים על סטיית התקן הממוצעת והתקן של שיפור יחסי על פני החזרות. אנו יכולים לראות שבכל מערכי הנתונים, אנו יכולים למעשה לשפר את הביצועים החזויים ב-1-3% ביחס לביצועים של תצורת ברירת המחדל שנבחרה בקפידה.
אוטומציה של בחירת הדגם שהוכשר מראש
אנו יכולים להשתמש ב-HPO כדי לא רק למצוא היפרפרמטרים, אלא גם לבחור אוטומטית את הדגם המאומן מראש הנכון. למה אנחנו רוצים לעשות את זה? מכיוון שאף מודל אחד לא מתעלה על כל מערכי הנתונים, עלינו לבחור את המודל המתאים עבור מערך נתונים ספציפי. כדי להדגים זאת, אנו מעריכים מגוון דגמי שנאים פופולריים מבית Hugging Face. עבור כל מערך נתונים, אנו מדרגים כל מודל לפי ביצועי הבדיקה שלו. הדירוג על פני מערכי נתונים (ראה את האיור הבא) משתנה ולא מודל אחד שמקבל את הציון הגבוה ביותר בכל מערך נתונים. כהתייחסות אנו מציגים גם את ביצועי הבדיקה המוחלטים של כל מודל ומערך נתונים באיור הבא.
כדי לבחור אוטומטית את הדגם הנכון, נוכל להטיל את בחירת המודל כפרמטרים קטגוריים ולהוסיף את זה למרחב החיפוש ההיפרפרמטר שלנו:
למרות שמרחב החיפוש כעת גדול יותר, זה לא אומר בהכרח שקשה יותר לבצע אופטימיזציה. האיור הבא מציג את שגיאת הבדיקה של התצורה הנצפית הטובה ביותר (בהתבסס על שגיאת האימות) במערך הנתונים של MRPC של ASHA לאורך זמן כאשר אנו מחפשים במרחב המקורי (קו כחול) (עם מודל מאומן מראש מבוסס BERT ) או במרחב החיפוש המוגדל החדש (קו כתום). בהינתן אותו תקציב, ASHA מסוגלת למצוא תצורת היפרפרמטרים בעלת ביצועים טובים בהרבה במרחב החיפוש המורחב מאשר במרחב הקטן יותר.
![]()
הפוך את בחירת סוג המופע לאוטומטי
בפועל, אולי לא אכפת לנו רק מאופטימיזציה של ביצועים חזויים. אולי אכפת לנו גם ממטרות אחרות, כגון זמן אימון, עלות (דולר), זמן אחזור או מדדי הגינות. אנחנו צריכים גם לעשות בחירות אחרות מעבר לפרמטרים ההיפר של המודל, למשל בחירת סוג המופע.
למרות שסוג המופע אינו משפיע על ביצועים חזויים, הוא משפיע מאוד על העלות (הדולר), זמן הריצה של האימון והשהייה. האחרון הופך חשוב במיוחד כאשר המודל נפרס. אנו יכולים לנסח את HPO כבעיית אופטימיזציה רב-אובייקטיבית, שבה אנו שואפים לייעל מספר יעדים בו-זמנית. עם זאת, אין פתרון אחד שמייעל את כל המדדים בו-זמנית. במקום זאת, אנו שואפים למצוא קבוצה של תצורות המחליפות באופן אופטימלי יעד אחד לעומת השני. זה נקרא ה סט פארטו.
כדי לנתח עוד הגדרה זו, אנו מוסיפים את הבחירה בסוג המופע כהיפרפרמטר קטגורי נוסף למרחב החיפוש שלנו:
אנו משתמשים MO-ASHA, אשר מתאים את ASHA לתרחיש הרב-אובייקטיבי על ידי שימוש במיון שאינו נשלט. בכל איטרציה, MO-ASHA גם בוחר עבור כל תצורה גם את סוג המופע שאנו רוצים להעריך אותו. כדי להפעיל HPO על קבוצה הטרוגנית של מופעים, Syne Tune מספקת את ה-SageMaker backend. עם הקצה העורפי הזה, כל ניסוי מוערך כעבודת הכשרה עצמאית של SageMaker במופע משלו. מספר העובדים מגדיר כמה משרות SageMaker אנו מפעילים במקביל בזמן נתון. האופטימיזר עצמו, MO-ASHA במקרה שלנו, פועל על המכונה המקומית, מחברת Sagemaker או על עבודת אימון נפרדת של SageMaker. ראה את הקוד הבא:
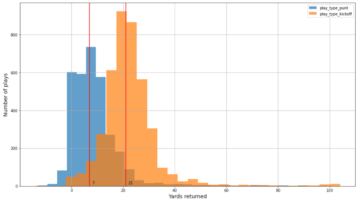
האיורים הבאים מציגים את שגיאת ההשהיה לעומת שגיאת הבדיקה בצד שמאל ואת ההשהיה לעומת העלות בצד ימין עבור תצורות אקראיות שנדגמו על ידי MO-ASHA (אנו מגבילים את הציר לניראות) במערך הנתונים של MRPC לאחר הפעלתו במשך 10,800 שניות על ארבעה עובדים. צבע מציין את סוג המופע. הקו השחור המקווקו מייצג את קבוצת פארטו, כלומר קבוצת הנקודות השולטת בכל הנקודות האחרות לפחות ביעד אחד.
אנו יכולים לראות פשרה בין זמן חביון לשגיאת בדיקה, כלומר התצורה הטובה ביותר עם שגיאת הבדיקה הנמוכה ביותר אינה משיגה את השהייה הנמוכה ביותר. בהתבסס על ההעדפה שלך, אתה יכול לבחור תצורת היפרפרמטר שמקריבה את ביצועי הבדיקה אך מגיעה עם זמן השהייה קטן יותר. אנו רואים גם את ההחלפה בין חביון לעלות. על ידי שימוש במופע קטן יותר של ml.g4dn.xlarge, למשל, אנו מגדילים רק מעט את זמן ההשהיה, אך משלמים רבע מהעלות של מופע ml.g4dn.8xlarge.
סיכום
בפוסט זה, דנו באופטימיזציה של היפרפרמטרים לכוונון עדין של דגמי שנאים מאומנים מראש מבית Hugging Face על בסיס Syne Tune. ראינו שעל ידי אופטימיזציה של הפרמטרים כמו קצב למידה, גודל אצווה ויחס החימום, נוכל לשפר את תצורת ברירת המחדל שנבחרה בקפידה. אנו יכולים גם להרחיב זאת על ידי בחירה אוטומטית של המודל המאומן מראש באמצעות אופטימיזציה של היפרפרמטרים.
בעזרת ה-SageMaker האחורי של Syne Tune, נוכל להתייחס לסוג המופע כאל היפרפרמטר. למרות שסוג המופע אינו משפיע על הביצועים, יש לו השפעה משמעותית על ההשהיה והעלות. לכן, על ידי יציקת HPO כבעיית אופטימיזציה רב-אובייקטיבית, אנו מסוגלים למצוא קבוצה של תצורות המחליפות באופן אופטימלי יעד אחד לעומת השני. אם אתה רוצה לנסות את זה בעצמך, בדוק את שלנו מחברת דוגמה.
על הכותבים
![]() אהרון קליין הוא מדען יישומי ב-AWS.
אהרון קליין הוא מדען יישומי ב-AWS.
![]() מתיאס סיגר הוא מדען יישומי ראשי ב-AWS.
מתיאס סיגר הוא מדען יישומי ראשי ב-AWS.
![]() דיוויד סלינס הוא Sr Applied Scientist ב-AWS.
דיוויד סלינס הוא Sr Applied Scientist ב-AWS.
![]() אמילי וובר הצטרף ל-AWS מיד לאחר השקת SageMaker, ומאז הוא מנסה לספר על כך לעולם! מלבד בניית חוויות ML חדשות ללקוחות, אמילי נהנית לעשות מדיטציה וללמוד בודהיזם טיבטי.
אמילי וובר הצטרף ל-AWS מיד לאחר השקת SageMaker, ומאז הוא מנסה לספר על כך לעולם! מלבד בניית חוויות ML חדשות ללקוחות, אמילי נהנית לעשות מדיטציה וללמוד בודהיזם טיבטי.
![]() סדריק ארכמבו הוא מדען יישומי ראשי ב-AWS ועמית במעבדה האירופית ללמידה ומערכות חכמות.
סדריק ארכמבו הוא מדען יישומי ראשי ב-AWS ועמית במעבדה האירופית ללמידה ומערכות חכמות.
- Coinsmart. בורסת הביטקוין והקריפטו הטובה באירופה.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה חופשית.
- CryptoHawk. רדאר אלטקוין. ניסיון חינם.
- מקור: https://aws.amazon.com/blogs/machine-learning/hyperparameter-optimization-for-fine-tuning-pre-trained-transformer-models-from-hugging-face/
- "
- 10
- 100
- 7
- 9
- a
- אודות
- מוּחלָט
- נגיש
- חֶשְׁבּוֹן
- להשיג
- לרוחב
- נוסף
- להשפיע על
- תעשיות
- מאפשר
- למרות
- אמזון בעברית
- כמות
- אנליזה
- לנתח
- אחר
- API
- יישומית
- בערך
- ארכיטקטורה
- מוגבר
- אוטומטי
- באופן אוטומטי
- מְמוּצָע
- AWS
- צִיר
- כי
- בנצ 'מרק
- הטוב ביותר
- מוטב
- בֵּין
- מעבר
- שחור
- סיכה
- לְהַגבִּיר
- תקציב
- בִּניָן
- אשר
- מקרה
- גרם
- בחירה
- בחירות
- נבחר
- בכיתה
- מיון
- קוד
- איך
- לעומת
- לחשב
- תְצוּרָה
- לִשְׁלוֹט
- לקוחות
- נתונים
- החלטות
- להפגין
- לפרוס
- פרס
- מופץ
- לא
- דוֹלָר
- כל אחד
- בקלות
- אפקטיבי
- אֵירוֹפִּי
- להעריך
- הערכה
- דוגמה
- חוויות
- מומחה
- להאריך
- פָּנִים
- אופנה
- תרשים
- הבא
- מסגרת
- החל מ-
- מלא
- פונקציה
- נוסף
- יתר על כן
- גנרטור
- לעזור
- כאן
- איך
- איך
- אולם
- HTTPS
- פְּגִיעָה
- חשוב
- לשפר
- השבחה
- להגדיל
- עצמאי
- להשפיע
- למשל
- אינטליגנטי
- אינטרס
- IT
- עצמו
- עבודה
- מקומות תעסוקה
- הצטרף
- ידע
- מעבדה
- תוויות
- שפה
- גָדוֹל
- גדול יותר
- הושק
- מוביל
- למידה
- להגביל
- קו
- מקומי
- מכונה
- לעשות
- עושה
- מסיבי
- משמעות
- שיטות
- מדדים
- יכול
- ML
- מודל
- מודלים
- יותר
- מספר
- טבעי
- בהכרח
- צרכי
- רשתות
- מחברה
- מספר
- יעדים
- מושג
- אופטימיזציה
- מטב
- מיטוב
- מְקוֹרִי
- אחר
- שֶׁלוֹ
- במיוחד
- תשלום
- ביצועים
- ביצוע
- אנא
- נקודות
- פופולרי
- תרגול
- מנהל
- בעיה
- תהליך
- תהליך
- מספק
- רכס
- דירוג
- לדווח
- כתב
- דוחות לדוגמא
- מייצג
- דורש
- תוצאות
- הפעלה
- ריצה
- אותו
- מַדְעָן
- חיפוש
- שניות
- זרע
- נבחר
- רגש
- סט
- הצבה
- לְהַצִיג
- משמעותי
- דומה
- פָּשׁוּט
- יחיד
- מידה
- פִּתָרוֹן
- מתוחכם
- מֶרחָב
- ספציפי
- לפצל
- תֶקֶן
- התחלה
- מדינה
- עוד
- אִסטרָטֶגִיָה
- מערכות
- משימות
- מבחן
- אל האני
- העולם
- לכן
- זמן
- סחר
- הדרכה
- טיפול
- עָצוּם
- מִשׁפָּט
- הבנה
- us
- להשתמש
- משתמשים
- בְּדֶרֶך כְּלַל
- לנצל
- אימות
- ראות
- ויקיפדיה
- לְלֹא
- עובדים
- עוֹלָם