מבוא
עולם ביקורת הנתונים יכול להיות מורכב, עם אתגרים רבים שצריך להתגבר עליהם. אחד האתגרים הגדולים ביותר הוא טיפול בתכונות קטגוריות תוך כדי התמודדות עם מערכי נתונים. במאמר זה נעמיק בעולם של נתוני ביקורת, זיהוי אנומליות והשפעת קידוד תכונות קטגוריות על מודלים.
אחד האתגרים העיקריים הקשורים לאיתור חריגות לביקורת נתונים הוא טיפול בתכונות קטגוריות. קידוד תכונות קטגוריות הוא חובה מכיוון שהמודלים אינם יכולים לפרש קלט טקסט. בדרך כלל, זה נעשה באמצעות קידוד Label או קידוד One Hot. עם זאת, במערך נתונים גדול, קידוד One-hot יכול להוביל לביצועי מודל גרועים עקב קללת הממדיות.
מטרות למידה
-
להבין את הרעיון של ביקורת נתונים ואת האתגר
- להעריך שיטות שונות של זיהוי אנומליות עמוק ללא פיקוח.
- להבין את ההשפעה של קידוד תכונות קטגוריות על מודלים המשמשים לזיהוי חריגות בנתוני ביקורת.
מאמר זה פורסם כחלק מה- בלוגאת מדע הנתונים.
תוכן העניינים
- מה זה אואטה?
- מהי זיהוי חריגות?
- האתגרים העיקריים הניצבים בפניהם בעת ביקורת נתונים
- ביקורת מערכי נתונים לזיהוי אנומליות
- קידוד של תכונות קטגוריות
- קידודים קטגוריים
- מודלים לזיהוי אנומליות ללא פיקוח
- כיצד קידוד תכונות קטגוריות משפיע על המודלים?
8.1 ייצוג t-SNE של מערך הנתונים של ביטוח רכב
8.2 ייצוג t-SNE של מערך הנתונים של ביטוח רכב
8.3 ייצוג t-SNE של מערך התביעות לרכב - סיכום
ב- Auditing Data?
נתוני ביקורת יכולים לכלול יומנים, תביעות ביטוח ונתוני פריצה למערכות מידע; במאמר זה, הדוגמאות המוצגות הן תביעות ביטוח של כלי רכב. ניתן להבחין בין תביעות ביטוח לבין מערכי נתונים לזיהוי חריגות, למשל, KDD, במספר גדול יותר של מאפיינים קטגוריים.
מאפיינים קטגוריים הם דיסקוטים בנתונים שלנו שיכולים להיות מסוג מספר שלם או אופי. תכונות מספריות הן תכונות רציפות בנתונים שלנו שתמיד מוערכות ממש. מערכי נתונים עם מאפיינים מספריים פופולריים בקהילת זיהוי חריגות כמו נתוני הונאה בכרטיס אשראי. רוב מערכי הנתונים הזמינים לציבור מכילים פחות מאפיינים קטגוריים מנתוני תביעות ביטוח. מאפיינים קטגוריים הם יותר במספר מאשר מאפיינים מספריים במערך הנתונים של תביעות ביטוח.
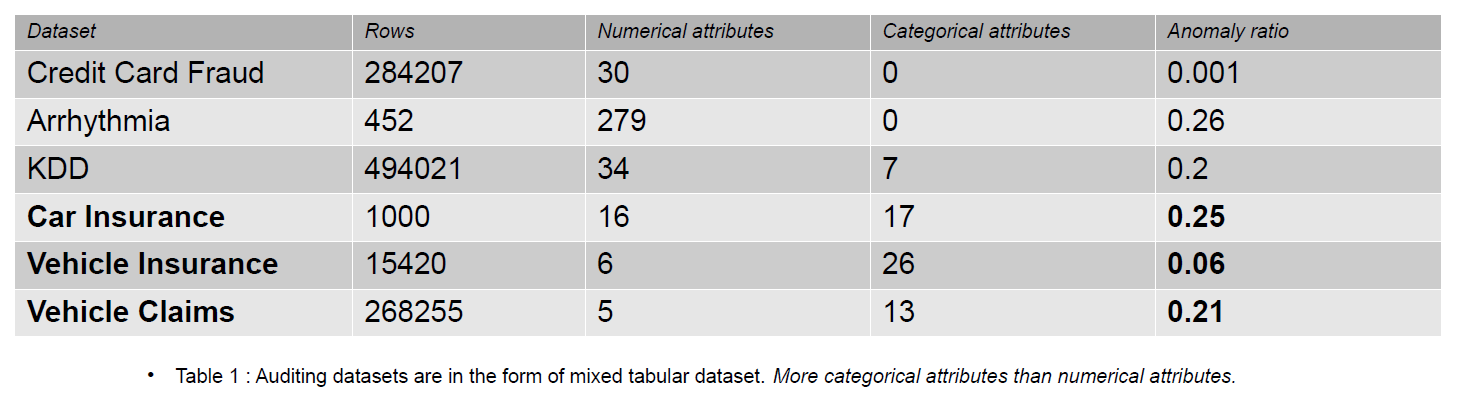
תביעת ביטוח כוללת תכונות כמו דגם, מותג, הכנסה, עלות, הנפקה, צבע וכו'. מספר המאפיינים הקטגוריים גבוה יותר בנתוני ביקורת מאשר במערך הנתונים של כרטיסי אשראי ו-KDD. מערכי נתונים אלה הם אמות מידה בשיטות זיהוי אנומליות ללא פיקוח. כפי שניתן לראות בטבלה שלהלן, למערך הנתונים של תביעות ביטוח יש מאפיינים קטגוריים יותר, שחשובים להבנת ההתנהגות של נתונים הונאה.
מערכי הביקורת המשמשים להערכת ההשפעה של קידודים קטגוריים הם ביטוח רכב, ביטוח רכב ותביעות רכב.
מהי זיהוי חריגות?
אנומליה היא תצפית הממוקמת הרחק מנתונים רגילים במערך נתונים לפי מרחק מסוים (Threshold). מבחינת נתוני ביקורת, אנו מעדיפים את המונח נתונים הונאה. זיהוי חריגות מבחין בין נתונים רגילים לנתונים הונאה באמצעות למידת מכונה או מודל למידה עמוקה. שיטות שונות יכול לשמש לזיהוי חריגות, כמו הערכת צפיפות, שגיאת שחזור ושיטות סיווג.
- הערכת צפיפות – שיטות אלו מעריכות את התפלגות הנתונים הנורמלית ומסווגות נתונים חריגים אם הם לא נדגמו מההתפלגות הנלמדת.
- שגיאת שחזור - שיטות מבוססות שגיאות שחזור מבוססות על העיקרון שניתן לשחזר נתונים רגילים עם הפסדים קטנים יותר מאשר נתונים חריגים. ככל שאובדן השחזור גבוה יותר מגדיל את הסיכוי שהנתונים הם חריגים.
- שיטות סיווג - שיטות סיווג כמו יער אקראיניתן להשתמש ב-, Isolation Forest, One Class – Support Vector Machines ו- Local Outlier Factors לזיהוי אנומליות. סיווג בגילוי חריגות כולל זיהוי של אחד המחלקות כאנומליה. ובכל זאת, המחלקות מחולקות לשתי קבוצות (0 ו-1) בתרחיש הרב-מחלקות, והמחלקה עם פחות נתונים היא המחלקה החריגה.
הפלט של השיטות לעיל הוא ציוני אנומליה או שגיאות שחזור. לאחר מכן עלינו להחליט על סף, לפיו אנו מסווגים את הנתונים החריגים.
האתגרים העיקריים הניצבים בפניהם בעת ביקורת נתונים
- טיפול בתכונות קטגוריות: קידוד תכונות קטגוריות הוא חובה מכיוון שהמודל אינו יכול לפרש קלט טקסט. אז, הערכים מקודדים בקידוד Label או בקידוד One Hot. אבל במערך נתונים גדול, קידוד חם אחד הופך את הנתונים למרחב רב ממדי על ידי הגדלת מספר התכונות. המודל מתפקד גרוע בשל קללת המימד.
- בחירת סף לסיווג: אם הנתונים אינם מסומנים, קשה להעריך את ביצועי המודל מכיוון שאיננו יודעים את מספר החריגות הקיימות במערך הנתונים. הידע הקודם על מערך הנתונים מקל על קביעת הסף. נניח שיש לנו 5 מתוך 10 דגימות חריגות בנתונים שלנו. אז, אנחנו יכולים לבחור את הסף בציון 50 אחוזון.
- מערכי נתונים ציבוריים: רוב מערכי הביקורת הם חסויים מכיוון שהם שייכים לחברות ארגוניות ומכילים מידע רגיש ואישי. דרך אפשרית אחת לצמצם בעיות סודיות היא אימון באמצעות מערכי נתונים סינתטיים (תביעות רכב).
ביקורת מערכי נתונים לזיהוי אנומליות
תביעות ביטוח לרכב כוללות מידע על מאפייני הרכב, כמו דגם, מותג, מחיר, שנה וסוג הדלק. הוא כולל מידע על הנהג, תאריך לידה, מין ומקצוע. בנוסף, התביעה עשויה לכלול מידע על העלות הכוללת של התיקון. מערכי הנתונים המשמשים במאמר זה הם כולם מתחום יחיד, אך הם משתנים במספר התכונות ובמספר המופעים.
-
מערך הנתונים של Vehicle Claims הוא גדול, מכיל למעלה מ-250,000 שורות, ולתכונות הקטגוריות שלו יש קרדינליות של 1171. בשל גודלו הגדול, מערך הנתונים הזה סובל מקללת הממדיות.
- מערך הנתונים של ביטוח רכב הוא בגודל בינוני, עם 15,420 שורות ו-151 ערכים קטגוריים ייחודיים. זה הופך אותו לפחות נוטה לסבול מקללת הממדיות.
- מערך הנתונים של ביטוח רכב הוא קטן, עם תוויות ו-25% דגימות חריגות, והוא מכיל מספר דומה של מאפיינים מספריים וקטגוריים. עם 169 קטגוריות ייחודיות, הוא אינו סובל מקללת הממדיות.
קידוד של תכונות קטגוריות
קידודים שונים של ערכים קטגוריים
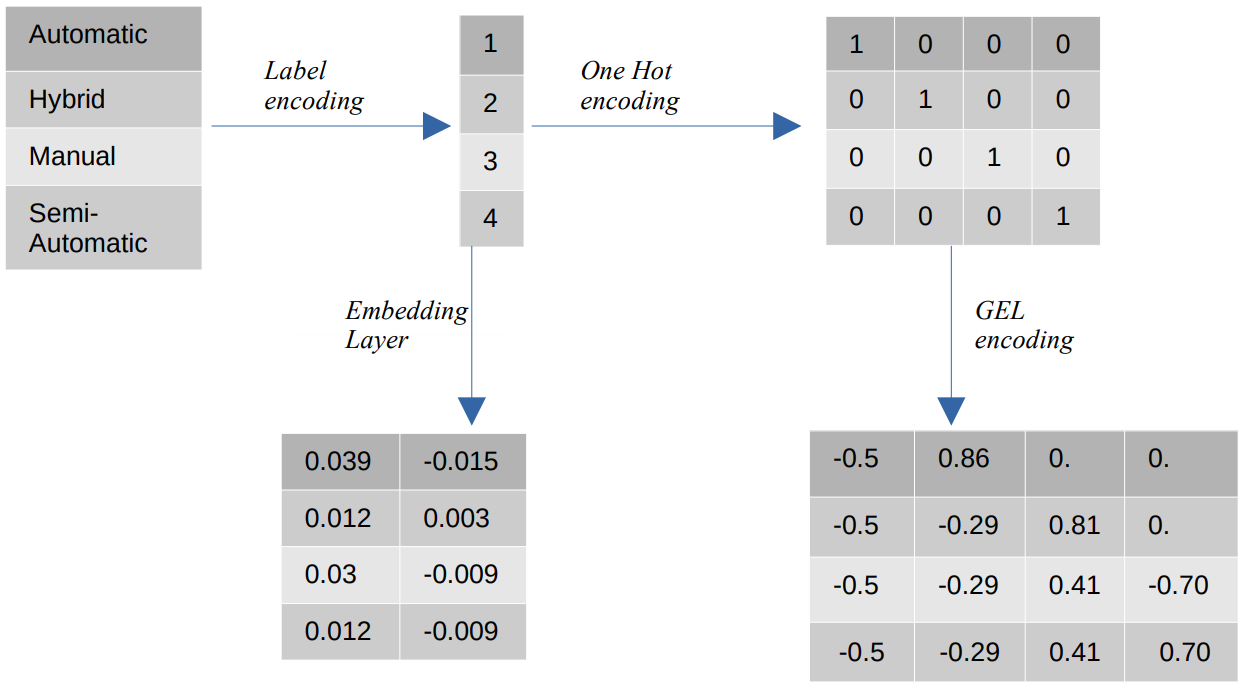
- קידוד תווית – בקידוד תווית, הערכים הקטגוריים מוחלפים בערכים מספריים שלמים בין 1 למספר הקטגוריות. קידוד תווית מייצג את הקטגוריות בצורה המיועדת לערכים סידוריים. ובכל זאת, כאשר התכונות הן נומינליות, הייצוג שגוי מכיוון שהערכים הקטגוריים אינם תואמים לסדר מסוים.
לדוגמה, אם יש לנו קטגוריות כמו אוטומטי, היברידי, ידני וחצי אוטומטי בתכונה, קידוד התוויות הופך את הערכים האלה ל-{1: אוטומטי, 2: היברידי, 3: ידני, 4:חצי אוטומטי}. ייצוג זה אינו מספק מידע על הערכים הקטגוריים, אך ייצוג כגון {0: נמוך, 1: בינוני, 2: גבוה} מספק ייצוג ברור מכיוון שלמשתנה התכונה Low מוקצה ערך מספרי נמוך יותר. לכן, קידוד תווית עדיף עבור ערכים סידוריים אך חסר ערך עבור ערכים נומינליים. - קידוד חם אחד – קידוד חם אחד משמש כדי לטפל בבעיה של ערכי קידוד נומינליים, אשר הופך כל ערך קטגורי לתכונה נפרדת במערך הנתונים המורכב מערכים בינאריים. לדוגמה, במקרה של ארבע קטגוריות שונות המקודדות כ-{1, 2, 3, 4}, קידוד One Hot ייצור תכונות חדשות כגון {Automatic: [1,0,0,0], Hybrid: [0,1,0,0 ,0,0,1,0], ידני: [0,0,0,1], חצי אוטומטי: [XNUMX]}.
המימד של מערך הנתונים תלוי ישירות במספר הקטגוריות הקיימות במערך הנתונים. כתוצאה מכך, קידוד One Hot יכול להוביל לקללת הממדיות, שהיא חסרון של שיטת קידוד זו. - קידוד GEL - קידוד GEL הוא טכניקת הטמעה שניתן להשתמש בה בשיטות למידה מפוקחות ובלתי מפוקחות. הוא מבוסס על העיקרון של קידוד One Hot וניתן להשתמש בו כדי להקטין את הממדיות של תכונות קטגוריות שקודדו באמצעות קידוד One Hot.
- הטמעת שכבה - הטבעות מילים מספקות דרך להשתמש בייצוג קומפקטי וצפוף שבו למילים דומות קידודים דומים. הטבעה היא וקטור צפוף של ערכי נקודה צפה שהם פרמטרים הניתנים לאימון. הטמעות מילים יכולות לנוע בין 8 מימדים (עבור מערכי נתונים קטנים) ל-1024 מימדיים (עבור מערכי נתונים גדולים).
הטבעה בממדים גבוהים יותר יכולה ללכוד קשרים מפורטים יותר בין מילים, אבל היא דורשת יותר נתונים כדי ללמוד. שכבת ההטמעה היא טבלת חיפוש הממירה כל מילה הקיימת במטריצה לוקטור בגודל מסוים.
מודלים לזיהוי אנומליות ללא פיקוח
בעולם האמיתי, נתונים אינם מסומנים ברוב המקרים, ונתוני תיוג הם יקרים וגוזלים זמן. לכן, נשתמש במודלים ללא פיקוח להערכות שלנו.
- SOM - מפת הארגון העצמי (SOM) היא שיטת למידה תחרותית שבה משקלם של הנוירונים מתעדכן באופן תחרותי ולא באמצעות למידה של התפשטות לאחור. SOM מורכב ממפה של נוירונים, שלכל אחד מהם וקטור משקל בגודל זהה לזה של וקטור הקלט. וקטור המשקל מאותחל עם משקלים אקראיים לפני תחילת האימון. במהלך האימון, כל קלט מושווה לנוירונים של המפה בהתבסס על מדד מרחק (למשל, מרחק אוקלידי) והוא ממופה ליחידת ההתאמה הטובה ביותר (BMU), שהיא הנוירון עם המרחק המינימלי לוקטור הקלט.
המשקולות של ה-BMU מתעדכנות עם המשקולות של וקטור הקלט, והנוירונים השכנים מתעדכנים על סמך רדיוס השכונה (סיגמה). מכיוון שהנוירונים מתחרים זה בזה כדי להיות היחידה המתאימה ביותר, תהליך זה ידוע כלמידה תחרותית. בסופו של דבר, הנוירונים עבור דגימות נורמליות קרובים יותר מאלה החריגים. ציוני אנומליה מוגדרים על ידי שגיאת הקוונטיזציה, שהיא ההפרש בין מדגם הקלט לבין המשקולות של יחידת ההתאמה הטובה ביותר. שגיאת קוונטיזציה גבוהה יותר מצביעה על הסתברות גבוהה יותר שהמדגם הוא אנומליה. - DAGMM – מודל ה-Deep Autoencoding Gaussian Mixture Model (DAGMM) הוא שיטת הערכת צפיפות שמניחה שהחריגות נמצאות באזור בעל הסתברות נמוכה. הרשת מחולקת לשני חלקים: רשת דחיסה, המשמשת להקרנת נתונים לממדים נמוכים יותר באמצעות מקודד אוטומטי, ורשת אומדן, המשמשת להערכת הפרמטרים של מודל התערובת גאוסית. DAGMM מעריכה k מספר של תערובות גאוסיות, כאשר k יכול להיות כל מספר מ-1 עד N (מספר נקודות הנתונים), וההנחה היא שנקודות נורמליות נמצאות באזור בצפיפות גבוהה, כלומר ההסתברות להידגמה מ- תערובת גאוס גבוהה יותר עבור נקודות רגילות מאשר עבור דגימות חריגות. ציוני אנומליה מוגדרים על ידי האנרגיה המשוערת של המדגם.
- RSRAE – שכבת שחזור השטח החזקה לזיהוי אנומליות ללא פיקוח היא שיטת שגיאות שחזור המקרינה תחילה את הנתונים למימד נמוך יותר באמצעות מקודד אוטומטי. הייצוג הסמוי נתון לאחר מכן להקרנה אורתוגונלית על תת-מרחב ליניארי שעמיד בפני חריגים. לאחר מכן המפענח בונה מחדש את הפלט מתת-המרחב הליניארי. בשיטה זו, שגיאת שחזור גבוהה יותר מצביעה על הסתברות גבוהה יותר שהמדגם הוא אנומליה.
- SOM-DAGMM- מפה ארגונית עצמית (SOM) - Deep Autoencoding Gaussian Mixture Model (DAGMM) הוא גם מודל הערכת צפיפות. כמו DAGMM, הוא גם מעריך את התפלגות ההסתברות של נקודות נתונים נורמליות ומסווג נקודת נתונים כאנומליה אם יש לה סבירות נמוכה להידגם מההתפלגות הנלמדת. ההבדל העיקרי בין SOM-DAGMM ל-DAGMM הוא ש-SOM-DAGMM כולל את הקואורדינטות המנורמלות של SOM עבור מדגם הקלט, המספק את המידע הטופולוגי החסר במקרה של DAGMM לרשת האומדן. המטרה דומה גם ל-DAGMM בכך שציוני האנומליה מוגדרים על ידי האנרגיה המשוערת של המדגם, ואנרגיה נמוכה מצביעה על הסתברות גבוהה יותר של המדגם כאנומליה.
לאחר מכן, נתייחס לאתגר של טיפול בתכונות קטגוריות.
כיצד קידוד תכונות קטגוריות משפיע על המודלים?
כדי להבין את ההשפעה של קידודים שונים על מערכי נתונים, נשתמש ב-t-SNE כדי להמחיש את הייצוגים הנמוכים של הנתונים עבור קידודים שונים. t-SNE מקרין נתונים במימד גבוה לתוך מרחב בעל מימד נמוך יותר, מה שמקל על הדמיה. על ידי השוואת הדמיות t-SNE ותוצאות מספריות של קידודים שונים של אותו מערך נתונים, ההבדל נצפה בייצוגים המתקבלים ובהבנה של השפעת הקידוד על מערך הנתונים.
ייצוג t-SNE של מערך הנתונים של ביטוח רכב
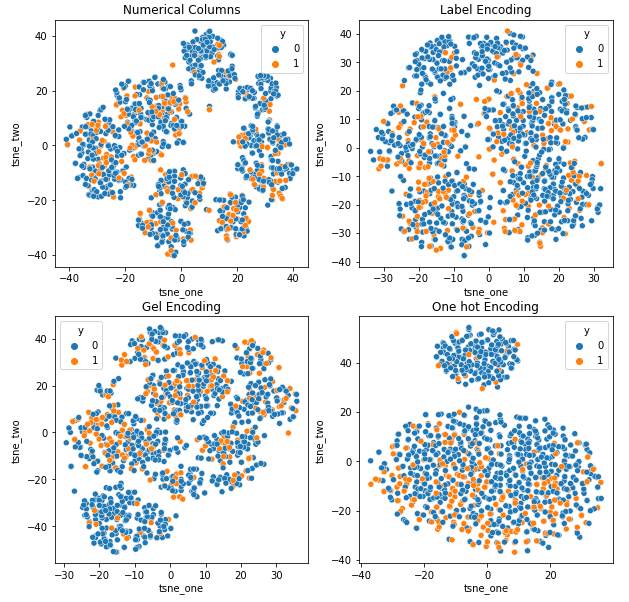
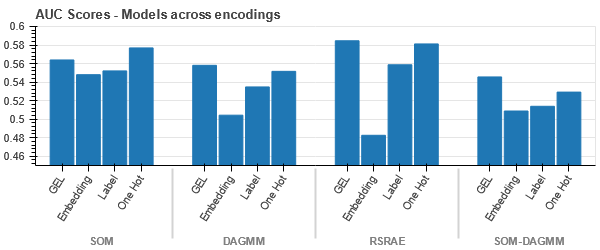
ייצוג t-SNE של מערך הנתונים של ביטוח רכב
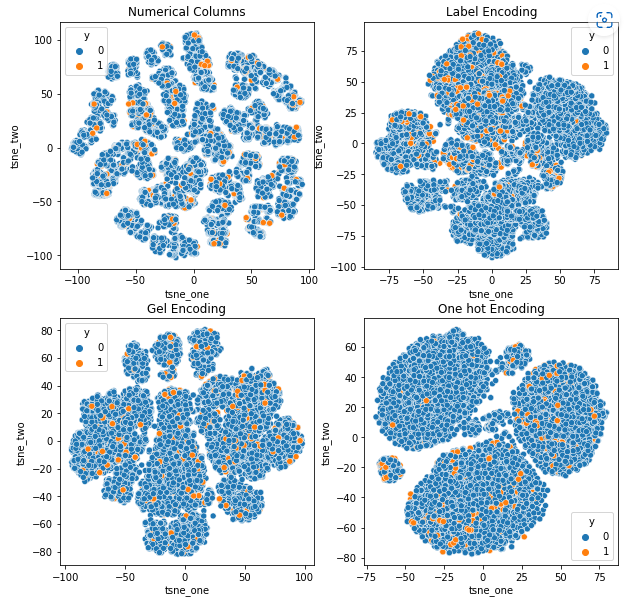
-
הנתונים קרובים יותר זה לזה מכיוון שמספר השורות גבוה יותר מאשר במערך הנתונים של ביטוח רכב. זה הופך להיות קשה להפריד עם מימדיות מוגברת בקידוד One Hot.
-
קידוד GEL עדיף על קידוד One Hot בכל המקרים מלבד DAGMM.
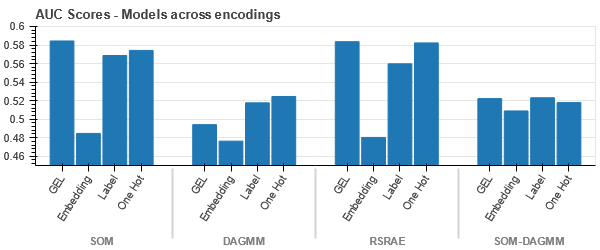
ייצוג t-SNE של מערך התביעות לרכב
-
הנתונים קשורים בחוזקה בכל המקרים, מה שמקשה על הפרדה עם ממדיות מוגברת. זו אחת הסיבות לביצועים ירודים של דגמים עקב הגברת הממדיות.
- SOM עולה על כל המודלים האחרים עבור מערך הנתונים הזה. ובכל זאת, שכבת ההטמעה מתאימה יותר ברוב המקרים, מה שמאפשר לנו אלטרנטיבה לקידוד תכונות קטגוריות לאיתור חריגות.
סיכום
מאמר זה מציג סקירה קצרה של נתוני ביקורת, זיהוי אנומליות וקידודים קטגוריים. חשוב להבין שהטיפול בתכונות קטגוריות בביקורת נתונים הוא מאתגר. על ידי הבנת ההשפעה של קידוד התכונות על מודלים, אנו יכולים לשפר את דיוק זיהוי החריגות במערך הנתונים. הנקודות העיקריות מהמאמר הזה הן:
- ככל שגודל הנתונים גדל, חשוב להשתמש בגישות קידוד חלופיות עבור תכונות קטגוריות, כמו קידוד GEL ושכבות Embedding, מכיוון שקידוד One Hot אינו מתאים.
- מודל אחד לא עובד עבור כל מערכי הנתונים. עבור מערכי נתונים טבלאיים, ידע בתחום הוא חשוב ביותר.
- בחירת שיטת הקידוד תלויה בבחירת הדגם.
הקוד להערכת מודלים זמין ב GitHub.
המדיה המוצגת במאמר זה אינה בבעלות Analytics Vidhya והיא משמשת לפי שיקול דעתו של המחבר.
מוצרים מקושרים
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- אודות
- מֵעַל
- פי
- דיוק
- בנוסף
- כתובת
- תעשיות
- מאפשר
- חלופה
- תמיד
- ניתוח
- אנליטיקה וידיה
- ו
- גילוי חריגות
- גישות
- מאמר
- שהוקצה
- המשויך
- להניח
- תכונות
- ביקורת
- מכני עם סלילה אוטומטית
- זמין
- מבוסס
- כי
- הופך להיות
- לפני
- להיות
- להלן
- מבחני ביצועים
- הטוב ביותר
- מוטב
- בֵּין
- הגדול ביותר
- קשור
- מותג
- לא יכול
- ללכוד
- מכונית
- ביטוח רכב
- כרטיס
- מקרה
- מקרים
- קטגוריות
- לאתגר
- האתגרים
- אתגר
- סיכויים
- אופי
- בחירה
- לטעון
- טענות
- בכיתה
- כיתות
- מיון
- לסווג
- ברור
- קרוב יותר
- קוד
- צֶבַע
- בדרך כלל
- קהילה
- חברות
- לעומת
- השוואה
- להתחרות
- תחרותי
- מורכב
- מושג
- סודיות
- מורכב
- מכיל
- רציף
- משותף
- עלות
- לִיצוֹר
- אשראי
- כרטיס אשראי
- נתונים
- נקודות מידע
- מערכי נתונים
- תַאֲרִיך
- התמודדות
- להקטין
- עמוק
- למידה עמוקה
- תלוי
- מְפוֹרָט
- איתור
- לקבוע
- הבדל
- אחר
- קשה
- מֵמַד
- ממדים
- ישירות
- שיקול דעת
- מרחק
- מובהק
- הפצה
- מחולק
- תחום
- נהג
- בְּמַהֲלָך
- כל אחד
- קל יותר
- או
- אנרגיה
- שגיאה
- שגיאות
- לְהַעֲרִיך
- מוערך
- הערכות
- וכו '
- להעריך
- הערכה
- הערכות
- דוגמה
- דוגמאות
- אלא
- יקר
- מאוד
- מתמודד
- גורמים
- מאפיין
- תכונות
- ראשון
- יער
- הונאה
- רמאי
- החל מ-
- לתדלק
- מין
- קבוצה
- טיפול
- גָבוֹהַ
- גבוה יותר
- חַם
- אולם
- HTTPS
- היברידי
- זיהוי
- פְּגִיעָה
- חשוב
- לשפר
- in
- לכלול
- כולל
- הַכנָסָה
- גדל
- עליות
- גדל
- מצביע על
- מידע
- מערכות מידע
- קלט
- ביטוח
- בדידות
- סוגיה
- בעיות
- IT
- מפתח
- לדעת
- ידע
- ידוע
- תווית
- תיוג
- תוויות
- גָדוֹל
- גדול יותר
- שכבה
- שכבות
- עוֹפֶרֶת
- לִלמוֹד
- למד
- למידה
- מקומי
- ממוקם
- בדיקה
- את
- אבדות
- נמוך
- מכונה
- למידת מכונה
- מכונה
- ראשי
- עושה
- עשייה
- מנדטורי
- מדריך ל
- רב
- מַפָּה
- תואם
- מַטרִיצָה
- משמעות
- מדיה
- בינוני
- שיטה
- שיטות
- מטרי
- מינימום
- חסר
- להקל
- תַעֲרוֹבֶת
- מודל
- מודלים
- יותר
- רוב
- רשת
- נוירונים
- חדש
- תכונות חדשות
- נוֹרמָלִי
- מספר
- מטרה
- ONE
- להזמין
- אחר
- ביצועים טובים יותר
- להתגבר על
- סקירה
- בבעלות
- פרמטרים
- חלק
- חלקים
- ביצועים
- מבצע
- אישי
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודה
- נקודות
- עני
- פופולרי
- אפשרי
- לְהַעֲדִיף
- להציג
- מתנות
- מחיר
- עקרון
- קודם
- הסתברות
- בעיה
- תהליך
- מקצוע
- פּרוֹיֶקט
- נתוני הפרויקט
- הקרנה
- פרויקטים
- נכסים
- לספק
- ובלבד
- מספק
- לאור
- אקראי
- רכס
- ממשי
- עולם אמיתי
- סיבות
- התאוששות
- באזור
- מערכות יחסים
- תיקון
- החליף
- נציגות
- מייצג
- דורש
- תוצאה
- וכתוצאה מכך
- תוצאות
- חָסוֹן
- אותו
- מדע
- רגיש
- נפרד
- הראה
- סיגמא
- דומה
- since
- יחיד
- מידה
- קטן
- קטן יותר
- So
- מֶרחָב
- ספציפי
- התחלות
- עוד
- כזה
- סובל
- מַתְאִים
- תמיכה
- משטח
- סינטטי
- מערכות
- שולחן
- Takeaways
- מונחים
- השמיים
- העולם
- לכן
- סף
- בחוזקה
- דורש זמן רב
- ל
- סה"כ
- רכבת
- הדרכה
- להבין
- הבנה
- ייחודי
- יחידה
- למידה ללא פיקוח
- מְעוּדכָּן
- us
- להשתמש
- ערך
- ערכים
- רכב
- כלי רכב
- מִשׁקָל
- מה
- מה
- אשר
- בזמן
- יצטרך
- Word
- מילים
- תיק עבודות
- עוֹלָם
- היה
- שנה
- זפירנט