NLP מרובה תוויות מתייחס למשימה של הקצאת תוויות מרובות לקלט טקסט נתון, ולא רק תווית אחת. במשימות NLP מסורתיות, כגון סיווג טקסט או ניתוח סנטימנטים, לכל קלט מוקצית בדרך כלל תווית בודדת על סמך התוכן שלו. עם זאת, בתרחישים רבים בעולם האמיתי, פיסת טקסט יכולה להשתייך למספר קטגוריות או לבטא רגשות מרובים בו-זמנית.
NLP רב-תווית חשוב מכיוון שהוא מאפשר לנו ללכוד מידע ניואנס ומורכב יותר מנתוני טקסט. לדוגמה, בתחום של ניתוח משוב לקוחות, סקירת לקוח עשויה לבטא רגשות חיוביים ושליליים בו-זמנית, או שהיא עשויה לגעת במספר היבטים של מוצר או שירות. על ידי הקצאת תוויות מרובות לתשומות כאלה, נוכל לקבל הבנה מקיפה יותר של המשוב של הלקוח ולנקוט פעולות ממוקדות יותר כדי לטפל בדאגותיו.
מאמר זה מתעמק במקרה ראוי לציון של השימוש של פרובקטוס ב-NLP מרובה תוויות.
הקשר:
לקוח פנה אלינו בבקשה לעזור להם להפוך מסמכי תיוג לאוטומטיים מסוג מסוים. במבט ראשון, המשימה נראתה פשוטה ונפתרת בקלות. עם זאת, כשעבדנו על המקרה, נתקלנו במערך נתונים עם הערות לא עקביות. למרות שהלקוחות שלנו התמודדו עם אתגרים עם מספרי כיתות משתנים ושינויים בצוות הביקורת שלהם לאורך זמן, הם השקיעו מאמצים משמעותיים ביצירת מערך נתונים מגוון עם מגוון הערות. אמנם היו כמה חוסר איזון ואי ודאויות בתוויות, אבל מערך הנתונים הזה סיפק הזדמנות חשובה לניתוח וחקירה נוספת.
בואו נסתכל מקרוב על מערך הנתונים, נחקור את המדדים ואת הגישה שלנו, ונסכם כיצד פרובקטוס פתרה את הבעיה של סיווג טקסט מרובה תוויות.
למערך הנתונים יש 14,354 תצפיות, עם 124 מחלקות (תוויות) ייחודיות. המשימה שלנו היא להקצות שיעור אחד או יותר לכל תצפית.
טבלה 1 מספקת נתונים סטטיסטיים תיאוריים עבור מערך הנתונים.
בממוצע, יש לנו כשתי כיתות לכל תצפית, עם ממוצע של 261 טקסטים שונים המתארים כיתה בודדת.

טבלה 1: סטטיסטיקת מערך נתונים
באיור 1, אנו רואים את התפלגות המחלקות בגרף העליון, ויש לנו מספר מסוים של תוויות HEAD עם תדירות ההתרחשות הגבוהה ביותר במערך הנתונים. שים לב גם שלרוב השיעורים יש תדירות נמוכה של התרחשות.
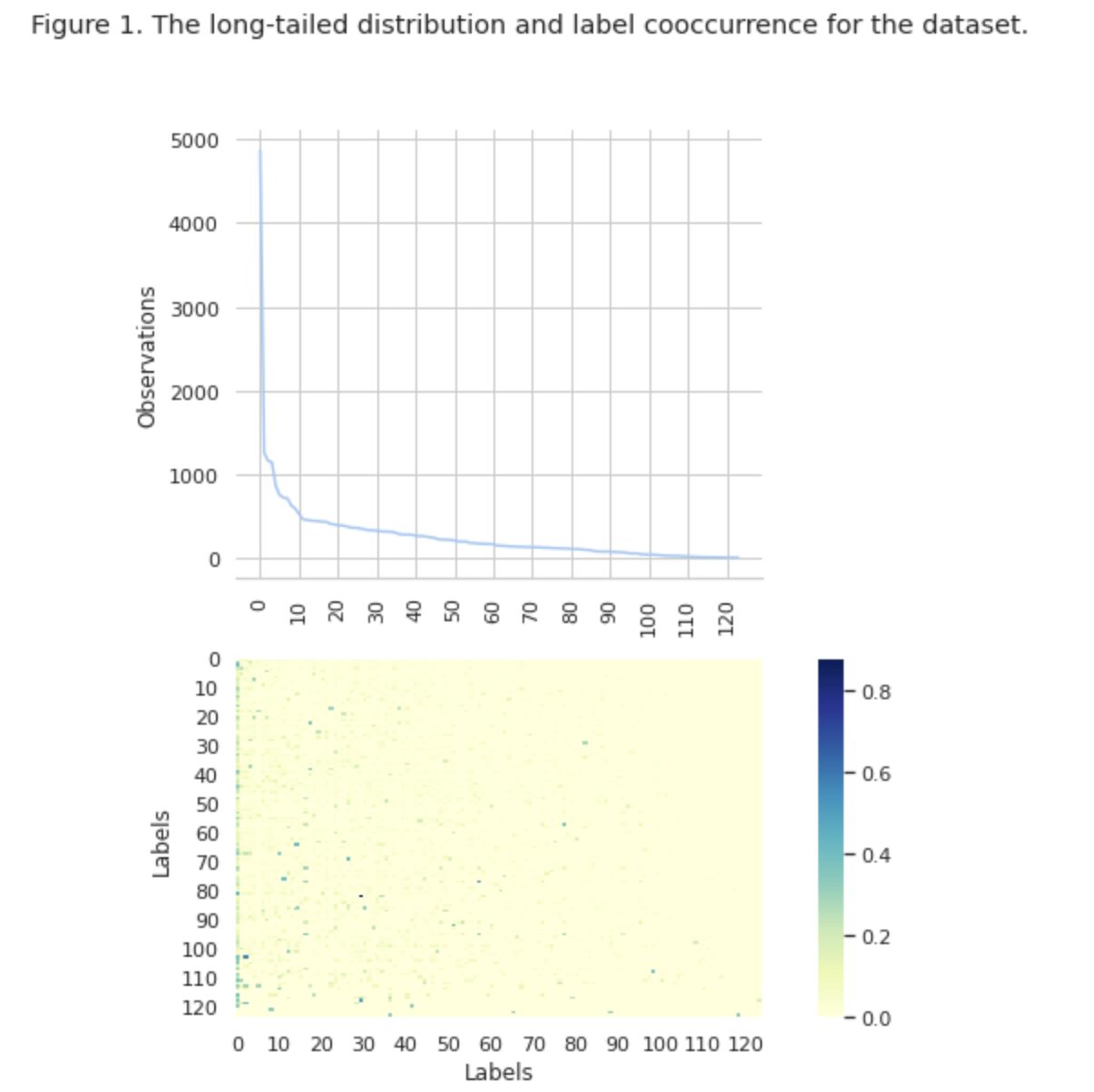
בגרף התחתון אנו רואים שיש חפיפה תכופה בין המחלקות המיוצגות בצורה הטובה ביותר במערך הנתונים, לבין המחלקות בעלות מובהקות נמוכה.
שינינו את התהליך של פיצול מערך הנתונים למערכות רכבת/ערך/בדיקה. במקום להשתמש בשיטה מסורתית, השתמשנו בריבוד איטרטיבי, כדי לספק חלוקה מאוזנת היטב של עדויות ליחסי תווית. בשביל זה, השתמשנו Scikit Multi-learn
from skmultilearn.model_selection import iterative_train_test_split mlb = MultiLabelBinarizer() def balanced_split(df, mlb, test_size=0.5): ind = np.expand_dims(np.arange(len(df)), axis=1) mlb.fit_transform(df["tag"]) labels = mlb.transform(df["tag"]) ind_train, _, ind_test, _ = iterative_train_test_split( ind, labels, test_size ) return df.iloc[ind_train[:, 0]], df.iloc[ind_test[:, 0]] df_train, df_tmp = balanced_split(df, test_size=0.4)
df_val, df_test = balanced_split(df_tmp, test_size=0.5)
השגנו את ההפצה הבאה:
- מערך ההדרכה מכיל 60% מהנתונים ומכסה את כל 124 התוויות
- מערך האימות מכיל 20% מהנתונים ומכסה את כל 124 התוויות
- מערך הנתונים של הבדיקה מכיל 20% מהנתונים ומכסה את כל 124 התוויות
סיווג ריבוי תוויות הוא סוג של אלגוריתם למידת מכונה בפיקוח המאפשר לנו להקצות מספר תוויות לדגימת נתונים בודדת. זה שונה מסיווג בינארי שבו המודל מנבא רק שתי קטגוריות, ומסיווג רב-מעמדי שבו המודל מנבא רק אחת מתוך מחלקות מרובות עבור מדגם.
מדדי הערכה עבור ביצועי סיווג ריבוי תוויות שונים מטבעם מאלה המשמשים בסיווג רב מחלקות (או בינארי) בשל ההבדלים המובנים בבעיית הסיווג. מידע מפורט יותר ניתן למצוא בויקיפדיה.
בחרנו מדדים המתאימים לנו ביותר:
- דיוק מודד את חלקן של התחזיות החיוביות האמיתיות מבין סך התחזיות החיוביות שנעשו על ידי המודל.
- להיזכר מודד את שיעור התחזיות החיוביות האמיתיות בין כל הדגימות החיוביות בפועל.
- ציון F1 הוא האמצעי ההרמוני של דיוק וזיכרונות, שעוזר להחזיר את האיזון בין השניים.
- הפסד המינג הוא שבריר התוויות שנחזו בצורה שגויה
אנחנו גם עוקבים מספר התוויות החזויות בסט { מוגדר כספירה עבור תוויות, עבורן אנו משיגים ציון F1 > 0}.
סיווג רב-תווית הוא סוג של בעיית למידה מפוקחת שבה ניתן לשייך מופע בודד או דוגמה למספר תוויות או סיווגים, בניגוד לסיווג המסורתי של תווית אחת, כאשר כל מופע משויך רק לתווית כיתה אחת.
כדי לפתור בעיות סיווג ריבוי תוויות, ישנן שתי קטגוריות עיקריות של טכניקות:
- שיטות טרנספורמציה של בעיות
- שיטות התאמת אלגוריתמים
שיטות טרנספורמציה של בעיות מאפשרות לנו להפוך משימות סיווג מרובות תוויות למספר משימות סיווג של תווית אחת. לדוגמה, גישת הבסיס של רלוונטיות בינארית (BR) מתייחסת לכל תווית כבעיית סיווג בינארי נפרדת. במקרה זה, בעיית ריבוי התוויות הופכת למספר בעיות של תווית אחת.
שיטות התאמת אלגוריתמים משנות את האלגוריתמים עצמם כדי לטפל בנתונים מרובי תוויות באופן מקורי, מבלי להפוך את המשימה למספר משימות סיווג של תווית אחת. דוגמה לגישה זו היא מודל BERT, שהוא מודל שפה מבוסס שנאי מאומן מראש, שניתן לכוונן עדין למשימות NLP שונות, כולל סיווג טקסט מרובה תוויות. BERT נועד לטפל בנתונים מרובי תוויות ישירות, ללא צורך בטרנספורמציה של בעיה.
בהקשר של שימוש ב-BERT עבור סיווג טקסט מרובה תוויות, הגישה הסטנדרטית היא להשתמש באובדן צולב אנטרופיה בינארית (BCE) כפונקציית ההפסד. אובדן BCE הוא פונקציית אובדן נפוצה עבור בעיות סיווג בינארי וניתן להרחיב אותה בקלות לטיפול בבעיות סיווג רב-תוויות על ידי חישוב ההפסד עבור כל תווית באופן עצמאי, ולאחר מכן סיכום ההפסדים. במקרה זה, פונקציית האובדן BCE מודדת את השגיאה בין הסתברויות חזויות לתוויות אמיתיות, כאשר ההסתברויות החזויות מתקבלות משכבת ההפעלה הסופית של הסיגמואידים במודל BERT.
כעת, בואו נסתכל מקרוב על איור 2 להלן.
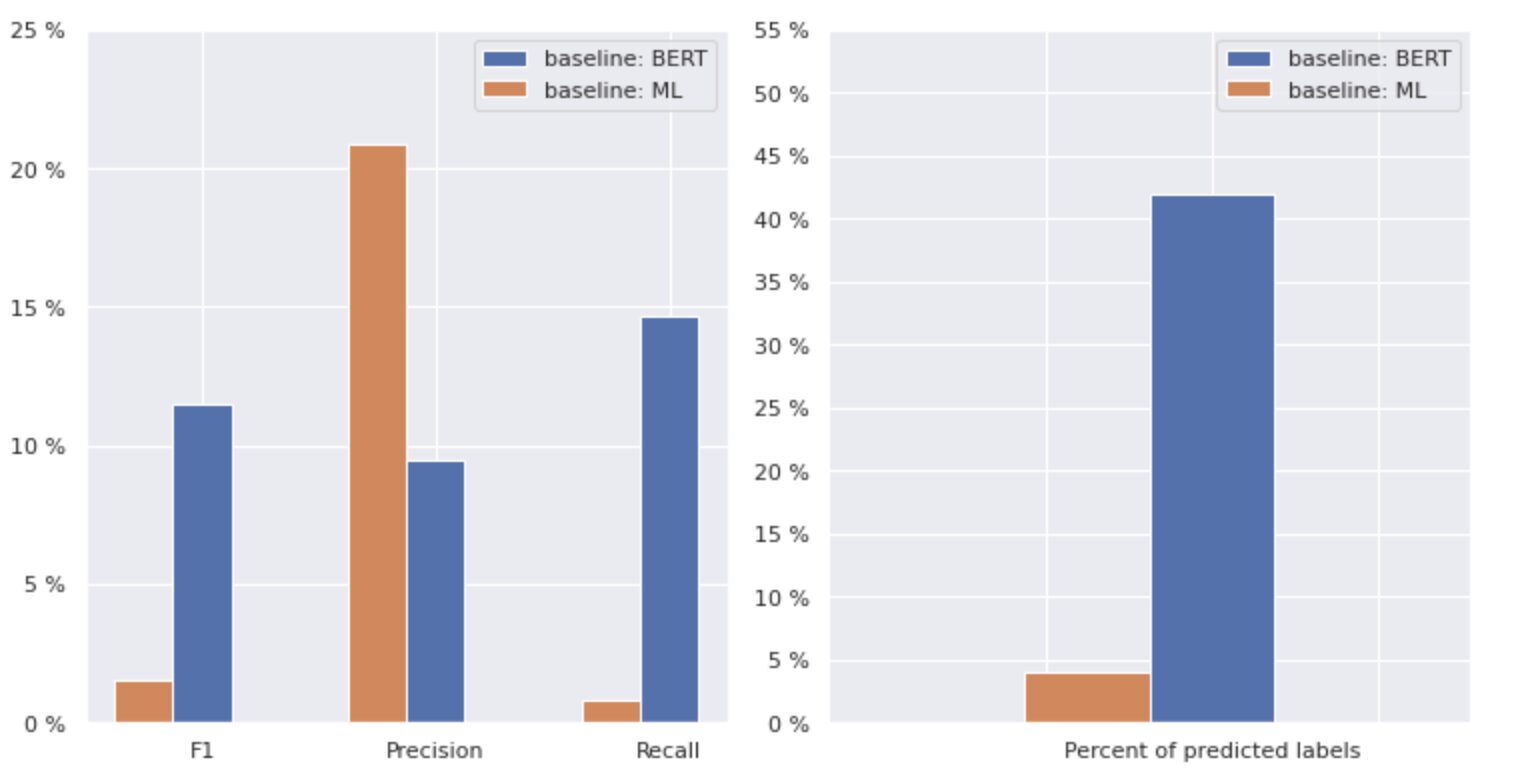
איור 2. מדדים למודלים בסיסיים
הגרף בצד שמאל מציג השוואה של מדדים עבור "בסיס: BERT" ו"בסיס: ML". לפיכך, ניתן לראות כי עבור "בסיס: BERT", ציוני F1 ו-Recall גבוהים בקירוב פי 1.5, בעוד שהדיוק עבור "בסיס: ML" גבוה פי 2 מזה של דגם 1. על ידי ניתוח האחוז הכולל של שיעורים חזויים המוצגים בצד ימין, אנו רואים ש-"baseline: BERT" ניבא שיעורים יותר מפי 10 מזה של "baseline: ML".
מכיוון שהתוצאה המקסימלית עבור "בסיס: BERT" היא פחות מ-50% מכל השיעורים, התוצאות די מייאשות. בואו נבין כיצד לשפר את התוצאות הללו.
מבוסס על המאמר המצטיין "איזון שיטות לסיווג טקסט מרובה תוויות עם התפלגות כיתות ארוכות זנב", למדנו שהפסד מאוזן בחלוקה עשוי להיות הגישה המתאימה ביותר עבורנו.
הפסד מאוזן חלוקה
הפסד מאוזן בהתפלגות היא טכניקה המשמשת בבעיות סיווג טקסט מרובה תוויות כדי לטפל בחוסר איזון בהפצה מחלקה. בבעיות אלה, לחלקים מסוימים יש תדירות התרחשות גבוהה בהרבה בהשוואה לאחרים, וכתוצאה מכך הטיית מודל כלפי מחלקות תכופות יותר אלו.
כדי לטפל בבעיה זו, הפסד מאוזן התפלגות מטרתו לאזן את התרומה של כל מדגם בפונקציית ההפסד. זה מושג על ידי שקלול מחדש של האובדן של כל מדגם בהתבסס על היפוך של תדירות ההתרחשות שלו במערך הנתונים. על ידי כך גדלה תרומתם של כיתות תכופות פחות, ותרומת כיתות תכופות יותר מצטמצמת, ובכך מאזנת את התפלגות המעמדות הכוללת.
טכניקה זו הוכחה כיעילה בשיפור הביצועים של מודלים בבעיות הפצת מעמדות ארוכות זנב. על ידי הפחתת ההשפעה של מחלקות תכופות והגדלת ההשפעה של מחלקות נדירות, המודל מסוגל ללכוד טוב יותר דפוסים בנתונים ולייצר תחזיות מאוזנות יותר.

יישום מחלקה מחודשת
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np class ResampleLoss(nn.Module): def __init__( self, use_sigmoid=True, partial=False, loss_weight=1.0, reduction="mean", reweight_func=None, weight_norm=None, focal=dict(focal=True, alpha=0.5, gamma=2), map_param=dict(alpha=10.0, beta=0.2, gamma=0.1), CB_loss=dict(CB_beta=0.9, CB_mode="average_w"), logit_reg=dict(neg_scale=5.0, init_bias=0.1), class_freq=None, train_num=None, ): super(ResampleLoss, self).__init__() assert (use_sigmoid is True) or (partial is False) self.use_sigmoid = use_sigmoid self.partial = partial self.loss_weight = loss_weight self.reduction = reduction if self.use_sigmoid: if self.partial: self.cls_criterion = partial_cross_entropy else: self.cls_criterion = binary_cross_entropy else: self.cls_criterion = cross_entropy # reweighting function self.reweight_func = reweight_func # normalization (optional) self.weight_norm = weight_norm # focal loss params self.focal = focal["focal"] self.gamma = focal["gamma"] self.alpha = focal["alpha"] # mapping function params self.map_alpha = map_param["alpha"] self.map_beta = map_param["beta"] self.map_gamma = map_param["gamma"] # CB loss params (optional) self.CB_beta = CB_loss["CB_beta"] self.CB_mode = CB_loss["CB_mode"] self.class_freq = ( torch.from_numpy(np.asarray(class_freq)).float().cuda() ) self.num_classes = self.class_freq.shape[0] self.train_num = train_num # only used to be divided by class_freq # regularization params self.logit_reg = logit_reg self.neg_scale = ( logit_reg["neg_scale"] if "neg_scale" in logit_reg else 1.0 ) init_bias = ( logit_reg["init_bias"] if "init_bias" in logit_reg else 0.0 ) self.init_bias = ( -torch.log(self.train_num / self.class_freq - 1) * init_bias ) self.freq_inv = ( torch.ones(self.class_freq.shape).cuda() / self.class_freq ) self.propotion_inv = self.train_num / self.class_freq def forward( self, cls_score, label, weight=None, avg_factor=None, reduction_override=None, **kwargs ): assert reduction_override in (None, "none", "mean", "sum") reduction = ( reduction_override if reduction_override else self.reduction ) weight = self.reweight_functions(label) cls_score, weight = self.logit_reg_functions( label.float(), cls_score, weight ) if self.focal: logpt = self.cls_criterion( cls_score.clone(), label, weight=None, reduction="none", avg_factor=avg_factor, ) # pt is sigmoid(logit) for pos or sigmoid(-logit) for neg pt = torch.exp(-logpt) wtloss = self.cls_criterion( cls_score, label.float(), weight=weight, reduction="none" ) alpha_t = torch.where(label == 1, self.alpha, 1 - self.alpha) loss = alpha_t * ((1 - pt) ** self.gamma) * wtloss loss = reduce_loss(loss, reduction) else: loss = self.cls_criterion( cls_score, label.float(), weight, reduction=reduction ) loss = self.loss_weight * loss return loss def reweight_functions(self, label): if self.reweight_func is None: return None elif self.reweight_func in ["inv", "sqrt_inv"]: weight = self.RW_weight(label.float()) elif self.reweight_func in "rebalance": weight = self.rebalance_weight(label.float()) elif self.reweight_func in "CB": weight = self.CB_weight(label.float()) else: return None if self.weight_norm is not None: if "by_instance" in self.weight_norm: max_by_instance, _ = torch.max(weight, dim=-1, keepdim=True) weight = weight / max_by_instance elif "by_batch" in self.weight_norm: weight = weight / torch.max(weight) return weight def logit_reg_functions(self, labels, logits, weight=None): if not self.logit_reg: return logits, weight if "init_bias" in self.logit_reg: logits += self.init_bias if "neg_scale" in self.logit_reg: logits = logits * (1 - labels) * self.neg_scale + logits * labels if weight is not None: weight = ( weight / self.neg_scale * (1 - labels) + weight * labels ) return logits, weight def rebalance_weight(self, gt_labels): repeat_rate = torch.sum( gt_labels.float() * self.freq_inv, dim=1, keepdim=True ) pos_weight = ( self.freq_inv.clone().detach().unsqueeze(0) / repeat_rate ) # pos and neg are equally treated weight = ( torch.sigmoid(self.map_beta * (pos_weight - self.map_gamma)) + self.map_alpha ) return weight def CB_weight(self, gt_labels): if "by_class" in self.CB_mode: weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) elif "average_n" in self.CB_mode: avg_n = torch.sum( gt_labels * self.class_freq, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, avg_n)).cuda() ) elif "average_w" in self.CB_mode: weight_ = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, self.class_freq)).cuda() ) weight = torch.sum( gt_labels * weight_, dim=1, keepdim=True ) / torch.sum(gt_labels, dim=1, keepdim=True) elif "min_n" in self.CB_mode: min_n, _ = torch.min( gt_labels * self.class_freq + (1 - gt_labels) * 100000, dim=1, keepdim=True, ) weight = ( torch.tensor((1 - self.CB_beta)).cuda() / (1 - torch.pow(self.CB_beta, min_n)).cuda() ) else: raise NameError return weight def RW_weight(self, gt_labels, by_class=True): if "sqrt" in self.reweight_func: weight = torch.sqrt(self.propotion_inv) else: weight = self.propotion_inv if not by_class: sum_ = torch.sum(weight * gt_labels, dim=1, keepdim=True) weight = sum_ / torch.sum(gt_labels, dim=1, keepdim=True) return weight def reduce_loss(loss, reduction): """Reduce loss as specified. Args: loss (Tensor): Elementwise loss tensor. reduction (str): Options are "none", "mean" and "sum". Return: Tensor: Reduced loss tensor. """ reduction_enum = F._Reduction.get_enum(reduction) # none: 0, elementwise_mean:1, sum: 2 if reduction_enum == 0: return loss elif reduction_enum == 1: return loss.mean() elif reduction_enum == 2: return loss.sum() def weight_reduce_loss(loss, weight=None, reduction="mean", avg_factor=None): """Apply element-wise weight and reduce loss. Args: loss (Tensor): Element-wise loss. weight (Tensor): Element-wise weights. reduction (str): Same as built-in losses of PyTorch. avg_factor (float): Avarage factor when computing the mean of losses. Returns: Tensor: Processed loss values. """ # if weight is specified, apply element-wise weight if weight is not None: loss = loss * weight # if avg_factor is not specified, just reduce the loss if avg_factor is None: loss = reduce_loss(loss, reduction) else: # if reduction is mean, then average the loss by avg_factor if reduction == "mean": loss = loss.sum() / avg_factor # if reduction is 'none', then do nothing, otherwise raise an error elif reduction != "none": raise ValueError( 'avg_factor can not be used with reduction="sum"' ) return loss def binary_cross_entropy( pred, label, weight=None, reduction="mean", avg_factor=None
): # weighted element-wise losses if weight is not None: weight = weight.float() loss = F.binary_cross_entropy_with_logits( pred, label.float(), weight, reduction="none" ) loss = weight_reduce_loss( loss, reduction=reduction, avg_factor=avg_factor ) return loss
DBLoss
loss_func = ResampleLoss( reweight_func="rebalance", loss_weight=1.0, focal=dict(focal=True, alpha=0.5, gamma=2), logit_reg=dict(init_bias=0.05, neg_scale=2.0), map_param=dict(alpha=0.1, beta=10.0, gamma=0.405), class_freq=class_freq, train_num=train_num,
) """
class_freq - list of frequencies for each class,
train_num - size of train dataset """
על ידי חקירה מדוקדקת של מערך הנתונים, הגענו למסקנה שהפרמטר
= 0.405.
כוונון סף
שלב נוסף בשיפור המודל שלנו היה תהליך כוונון הסף, הן בשלב ההכשרה, והן בשלבי האימות והבדיקה. חישבנו את התלות של מדדים כגון ציון f1, דיוק וזיכרונות ברמת הסף, ובחרנו את הסף על סמך הציון המטרי הגבוה ביותר. להלן ניתן לראות את יישום הפונקציה של תהליך זה.
אופטימיזציה של ציון F1 על ידי כוונון הסף:
def optimise_f1_score(true_labels: np.ndarray, pred_labels: np.ndarray): best_med_th = 0.5 true_bools = [tl == 1 for tl in true_labels] micro_thresholds = (np.array(range(-45, 15)) / 100) + best_med_th f1_results, pre_results, recall_results = [], [], [] for th in micro_thresholds: pred_bools = [pl > th for pl in pred_labels] test_f1 = f1_score(true_bools, pred_bools, average="micro", zero_division=0) test_precision = precision_score( true_bools, pred_bools, average="micro", zero_division=0 ) test_recall = recall_score( true_bools, pred_bools, average="micro", zero_division=0 ) f1_results.append(test_f1) prec_results.append(test_precision) recall_results.append(test_recall) best_f1_idx = np.argmax(f1_results) return micro_thresholds[best_f1_idx]הערכה והשוואה עם קו הבסיס
גישות אלו אפשרו לנו לאמן מודל חדש ולהשיג את התוצאה הבאה, אשר מושווה לקו הבסיס: BERT באיור 3 להלן.

איור 3. מדדי השוואה לפי קו בסיס וגישה חדשה יותר.
על ידי השוואת המדדים הרלוונטיים לסיווג, אנו רואים עלייה משמעותית במדדי הביצועים כמעט פי 5-6:
ציון F1 עלה מ-12% → 55%, בעוד שהדיוק עלה מ-9% → 59% וה-Recall עלה מ-15% → 51%.
עם השינויים המוצגים בגרף הימני באיור 3, אנו יכולים כעת לחזות 80% מהשיעורים.
פרוסות של כיתות
חילקנו את התוויות שלנו לארבע קבוצות: HEAD, MEDIUM, TAIL ואפס. כל קבוצה מכילה תוויות עם כמות דומה של תצפיות נתונים תומכות.
כפי שניתן לראות באיור 4, ההתפלגויות של הקבוצות הן ברורות. לקופסת הוורדים (HEAD) יש התפלגות מוטה לרעה, לקופסת האמצע (MEDIUM) יש התפלגות מוטה חיובית, ולקופסה הירוקה (TAIL) נראה שיש התפלגות נורמלית.
לכל הקבוצות יש גם חריגים, שהם נקודות מחוץ לשפם בעלילת הקופסה. לקבוצת HEAD יש השפעה גדולה על שיעור MAJOR.
בנוסף, זיהינו קבוצה נפרדת בשם "ZERO" המכילה תוויות שהמודל לא הצליח ללמוד ואינו יכול לזהות בגלל המספר המזערי של התרחשויות במערך הנתונים (פחות מ-3% מכל התצפיות).
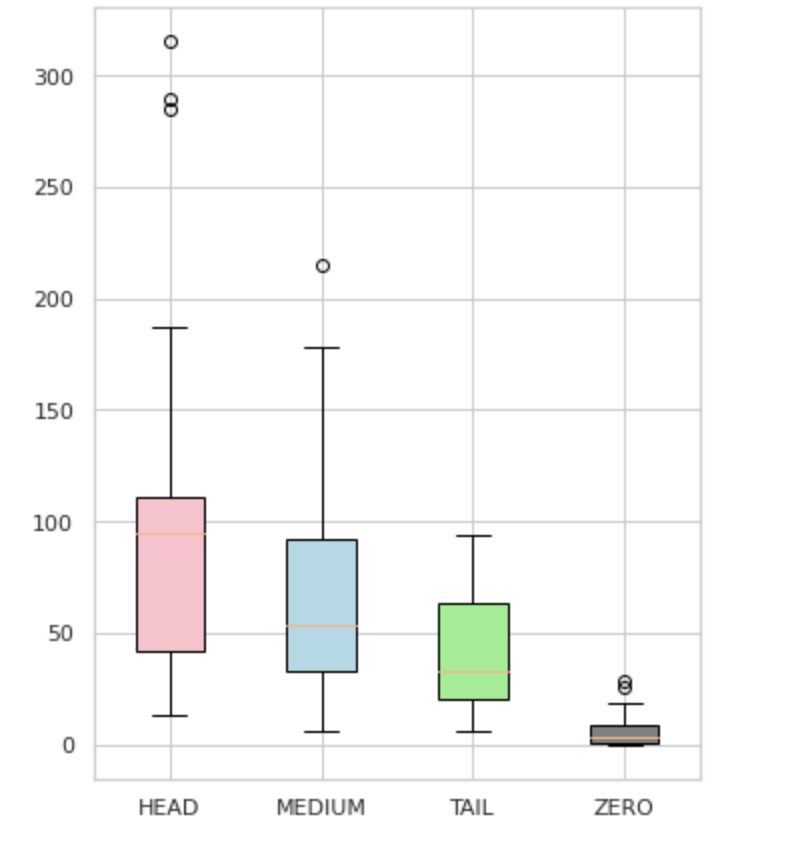
איור 4. ספירת תווית לעומת קבוצות
טבלה 2 מספקת מידע על מדדים לכל קבוצת תוויות עבור תת-קבוצת הנתונים של הבדיקה.
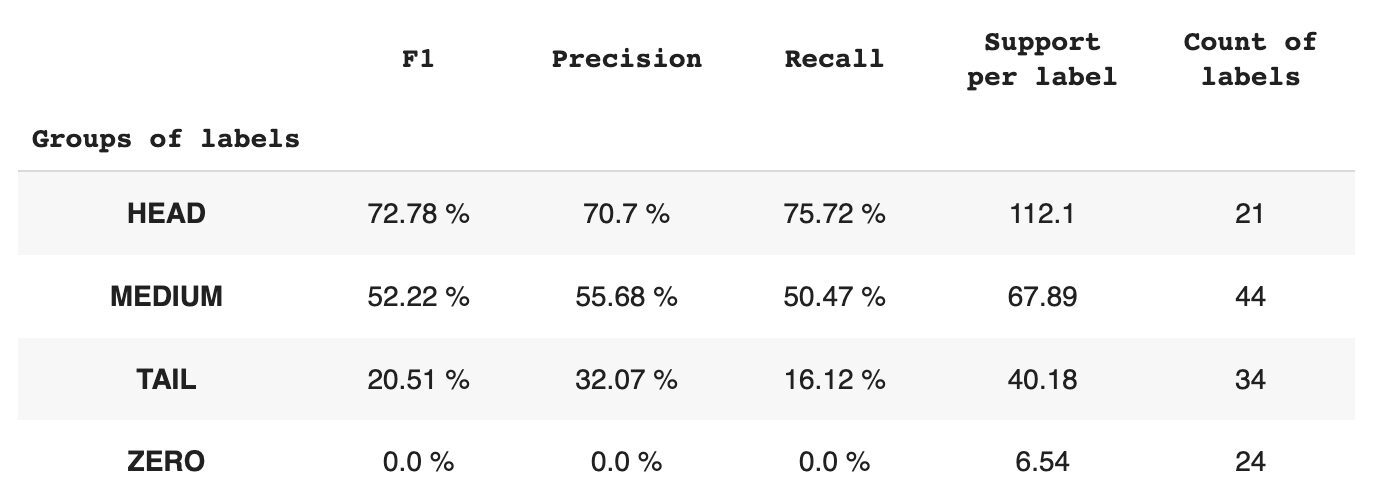
טבלה 2. מדדים לקבוצה.
- קבוצת HEAD מכילה 21 תוויות עם ממוצע של 112 תצפיות תמיכה לכל תווית. קבוצה זו מושפעת מחריגים, ובשל הייצוג הגבוה שלה במערך הנתונים, המדדים שלה גבוהים: F1 - 73%, דיוק - 71%, ריקול - 75%.
- קבוצת MEDIUM מורכבת מ-44 תוויות עם תמיכה ממוצעת של 67 תצפיות, הנמוך בערך פי שניים מקבוצת HEAD. המדדים לקבוצה זו צפויים לרדת ב-50%: F1 – 52%, דיוק – 56%, ריקול – 51%.
- לקבוצת TAIL יש את המספר הגדול ביותר של מחלקות, אך כולן מיוצגות בצורה גרועה במערך הנתונים, עם ממוצע של 40 תצפיות תמיכה לכל תווית. כתוצאה מכך, המדדים יורדים משמעותית: F1 – 21%, דיוק – 32%, ריקול – 16%.
- קבוצת ZERO כוללת מחלקות שהמודל אינו יכול לזהות כלל, פוטנציאלית בשל התרחשותן הנמוכה במערך הנתונים. לכל אחת מ-24 התוויות בקבוצה זו יש בממוצע 7 תצפיות תמיכה.
איור 5 מדגים את המידע המוצג בטבלה 2, ומספק ייצוג חזותי של המדדים לכל קבוצת תוויות.
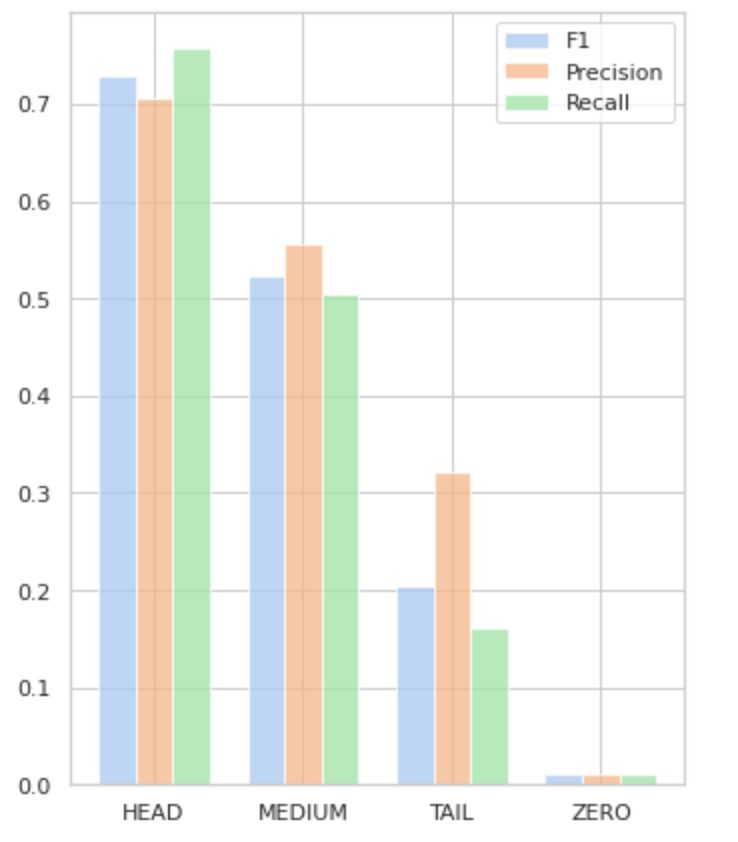
איור 5. מדדים לעומת קבוצות תוויות. כל ערכי האפס = 0.
במאמר מקיף זה, הוכחנו שמשימה פשוטה לכאורה של סיווג טקסט מרובה תוויות יכולה להיות מאתגרת כאשר מיישמים שיטות מסורתיות. הצענו שימוש בפונקציות הפסד של איזון התפלגות כדי להתמודד עם סוגיית חוסר האיזון המעמדי.
השווינו את הביצועים של הגישה המוצעת שלנו לשיטה הקלאסית, והערכנו אותה באמצעות מדדים עסקיים מהעולם האמיתי. התוצאות מוכיחות ששימוש בפונקציות אובדן כדי לטפל בחוסר איזון בכיתה והתרחשויות משותפים של תוויות מציעים פתרון בר-קיימא לסיווג טקסט מרובה תוויות.
מקרה השימוש המוצע מדגיש את החשיבות של התחשבות בגישות וטכניקות שונות בעת התמודדות עם סיווג טקסט מרובה תוויות, ואת היתרונות הפוטנציאליים של פונקציות הפסד-איזון התפלגות בטיפול בחוסר איזון מעמדי.
אם אתה מתמודד עם בעיה דומה ומבקש לייעל את פעולות עיבוד המסמכים בתוך הארגון שלך, אנא צור איתי קשר או עם צוות Provectus. נשמח לסייע לכם במציאת שיטות יעילות יותר לאוטומציה של התהליכים שלכם.
אולקסי בייביץ' הוא מהנדס למידת מכונה בפרובקטוס. עם רקע בפיזיקה, הוא בעל כישורים אנליטיים ומתמטיים מצוינים, וצבר ניסיון רב ערך באמצעות מחקר מדעי ומצגות כנס בינלאומיות, כולל SPIE Photonics West. Oleksii מתמחה ביצירת פתרונות AI/ML מקצה לקצה בקנה מידה גדול עבור תעשיות בריאות ופינטק. הוא מעורב בכל שלב במחזור החיים של פיתוח ML, מזיהוי בעיות עסקיות ועד לפריסה והרצה של מודלים של ML ייצור.
רינת אחמטוב הוא ה-ML Solution Architect ב-Provectus. עם רקע מעשי מוצק ב-Machine Learning (במיוחד ב-Computer Vision), רינת היא חנונית, חובבת נתונים, מהנדסת תוכנה ומכורת עבודה שהתשוקה השנייה בגודלה היא תכנות. בפרובקטוס רינת אחראית על שלבי הגילוי וההוכחה של הרעיון, ומובילה את ביצוע פרויקטים מורכבים של בינה מלאכותית.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://www.kdnuggets.com/2023/03/multilabel-nlp-analysis-class-imbalance-loss-function-approaches.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-label-nlp-an-analysis-of-class-imbalance-and-loss-function-approaches
- :הוא
- 1
- 10
- 100
- 15%
- 67
- 7
- 9
- a
- יכול
- אודות
- להשיג
- הושג
- פעולות
- הפעלה
- הסתגלות
- כתובת
- פְּנִיָה
- AI
- AI / ML
- מטרות
- אַלגוֹרִיתְם
- אלגוריתמים
- תעשיות
- מאפשר
- אלפא
- בין
- כמות
- אנליזה
- אנליטית
- ניתוח
- ו
- נראה
- יישומית
- החל
- גישה
- גישות
- בערך
- ARE
- מאמר
- AS
- היבטים
- שהוקצה
- לעזור
- המשויך
- At
- אוטומציה
- מְמוּצָע
- רקע
- איזון
- מבוסס
- Baseline
- BE
- כי
- להלן
- הטבות
- הטוב ביותר
- בטא
- מוטב
- בֵּין
- הטיה
- הגדול ביותר
- תַחתִית
- אריזה מקורית
- מובנה
- עסקים
- by
- מחושב
- CAN
- לא יכול
- ללכוד
- מקרה
- קטגוריות
- CB
- מסוים
- האתגרים
- אתגר
- שינויים
- תשלום
- בכיתה
- כיתות
- קלאסי
- מיון
- לקוחות
- מקרוב
- קרוב יותר
- בדרך כלל
- לעומת
- השוואה
- השוואה
- מורכב
- מַקִיף
- המחשב
- ראייה ממוחשבת
- מחשוב
- מושג
- דאגות
- הגיע למסקנה
- כנס
- בהתחשב
- צור קשר
- מכיל
- תוכן
- הקשר
- תרומה
- מכסה
- יוצרים
- לקוח
- מחזור
- נתונים
- התמודדות
- להקטין
- מוגדר
- להפגין
- מופגן
- פריסה
- מעוצב
- מְפוֹרָט
- צעצועי התפתחות
- ההבדלים
- אחר
- ישירות
- תגלית
- מובהק
- הפצה
- הפצות
- שונה
- מחולק
- מסמך
- מסמכים
- עושה
- תחום
- ירידה
- כל אחד
- בקלות
- אפקטיבי
- יעיל
- מַאֲמָצִים
- לאפשר
- מקצה לקצה
- מהנדס
- נלהב
- באותה מידה
- שגיאה
- במיוחד
- Ether (ETH)
- העריך
- כל
- עדות
- דוגמה
- מצוין
- הוצאת להורג
- צפוי
- ניסיון
- חקירה
- לחקור
- אקספרס
- f1
- מתמודד
- מול
- מָשׁוֹב
- תרשים
- סופי
- מציאת
- fintech
- ראשון
- לָצוּף
- הבא
- בעד
- מצא
- שבריר
- תדר
- תכוף
- החל מ-
- פונקציה
- פונקציונלי
- פונקציות
- נוסף
- לְהַשִׂיג
- נתן
- מבט
- גרף
- ירוק
- קְבוּצָה
- קבוצה
- לטפל
- שמח
- יש
- ראש
- בריאות
- לעזור
- עוזר
- גָבוֹהַ
- גבוה יותר
- הגבוה ביותר
- פסים
- איך
- איך
- אולם
- HTML
- http
- HTTPS
- מזוהה
- זיהוי
- חוסר איזון
- פְּגִיעָה
- מושפעים
- הפעלה
- לייבא
- חשיבות
- חשוב
- לשפר
- שיפור
- in
- כולל
- כולל
- לא נכון
- להגדיל
- גדל
- גדל
- באופן עצמאי
- תעשיות
- מידע
- הטמון
- קלט
- למשל
- במקום
- ברמה בינלאומית
- מוּשׁקָע
- מעורב
- סוגיה
- IT
- שֶׁלָה
- jpg
- רק אחד
- KDnuggets
- תווית
- תיוג
- תוויות
- שפה
- בקנה מידה גדול
- הגדול ביותר
- שכבה
- מוביל
- לִלמוֹד
- למד
- למידה
- רמה
- החיים
- לינקדין
- רשימה
- נראה
- את
- אבדות
- נמוך
- מכונה
- למידת מכונה
- עשוי
- ראשי
- גדול
- הרוב
- רב
- מיפוי
- מתמטיקה
- מקסימום
- אמצעים
- בינוני
- שיטה
- שיטות
- מטרי
- מדדים
- מינימלי
- ML
- MLB
- מודל
- מודלים
- לשנות
- מודול
- יותר
- יותר יעיל
- רוב
- מספר
- שם
- צורך
- שלילי
- באופן שלילי
- חדש
- NLP
- נוֹרמָלִי
- ראוי לציון
- מספר
- מספרים
- קהות
- להשיג
- מושג
- of
- הַצָעָה
- on
- ONE
- הזדמנות
- מִתנַגֵד
- אפשרויות
- ארגון
- אחרים
- אַחֶרֶת
- בחוץ
- בולט
- מקיף
- פרמטר
- תשוקה
- דפוסי
- אחוזים
- ביצועים
- פיסיקה
- לְחַבֵּר
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- אנא
- נקודות
- PoS
- חיובי
- פוטנציאל
- פוטנציאל
- מעשי
- דיוק
- לחזות
- חזה
- התחזיות
- תחזית
- מצגות
- מוצג
- בעיה
- בעיות
- תהליך
- תהליכים
- תהליך
- לייצר
- המוצר
- הפקה
- תכנות
- פרויקטים
- הוכחה
- הוכחה של רעיון או תאוריה
- מוּצָע
- לספק
- ובלבד
- מספק
- מתן
- פיטורך
- להעלות
- רכס
- במקום
- עולם אמיתי
- לאזן
- לסכם
- להכיר
- להפחית
- מופחת
- הפחתה
- מתייחס
- יחסים
- הרלוונטיות
- רלוונטי
- נציגות
- מיוצג
- לבקש
- מחקר
- תוצאה
- וכתוצאה מכך
- תוצאות
- לַחֲזוֹר
- החזרות
- סקירה
- רוז
- ריצה
- s
- אותו
- תרחישים
- מחקר מדעי
- שְׁנִיָה
- מחפשים
- נבחר
- עצמי
- רגש
- נפרד
- שרות
- סט
- סטים
- צוּרָה
- הראה
- הופעות
- משמעות
- משמעותי
- באופן משמעותי
- דומה
- פָּשׁוּט
- בו זמנית
- יחיד
- מידה
- מיומנויות
- So
- תוכנה
- מהנדס תוכנה
- מוצק
- פִּתָרוֹן
- פתרונות
- לפתור
- כמה
- מתמחה
- מפורט
- התמחות
- שלבים
- תֶקֶן
- סטטיסטיקה
- שלב
- פשוט
- כזה
- מַתְאִים
- למידה מפוקחת
- תמיכה
- מסייע
- שולחן
- תָג
- לקחת
- ממוקד
- המשימות
- משימות
- נבחרת
- טכניקות
- מבחן
- בדיקות
- סיווג טקסט
- זֶה
- השמיים
- המידע
- שֶׁלָהֶם
- אותם
- עצמם
- אלה
- סף
- דרך
- זמן
- פִּי
- ל
- חלק עליון
- לפיד
- סה"כ
- לגעת
- לקראת
- לעקוב
- מסורתי
- רכבת
- הדרכה
- לשנות
- טרנספורמציה
- טרנספורמציה
- הפיכה
- מטפלת
- נָכוֹן
- בדרך כלל
- אי וודאויות
- הבנה
- ייחודי
- us
- להשתמש
- במקרה להשתמש
- ניצול
- אימות
- בעל ערך
- ערכים
- שונים
- בַּר חַיִים
- חזון
- vs
- מִשׁקָל
- מערב
- אשר
- בזמן
- ויקיפדיה
- יצטרך
- עם
- בתוך
- לְלֹא
- עבד
- זפירנט
- אפס