תמונה שנוצרה באמצעות דיפוזיה יציבה
עולם הבינה המלאכותית עבר באופן דרמטי לכיוון מודלים גנרטיביים במהלך השנים האחרונות, הן בראייה ממוחשבת והן בעיבוד שפה טבעית. Dalle-2 ו-Midjourney משכו את תשומת לבם של אנשים, מה שהוביל אותם לזהות את העבודה יוצאת הדופן שבוצעה בתחום של AI Generative.
רוב התמונות הנוצרות בינה מלאכותית המיוצרות כיום מסתמכות על דגמי דיפוזיה כבסיסן. מטרת מאמר זה היא להבהיר כמה מהמושגים סביב דיפוזיה יציבה ולהציע הבנה בסיסית של המתודולוגיה המופעלת.
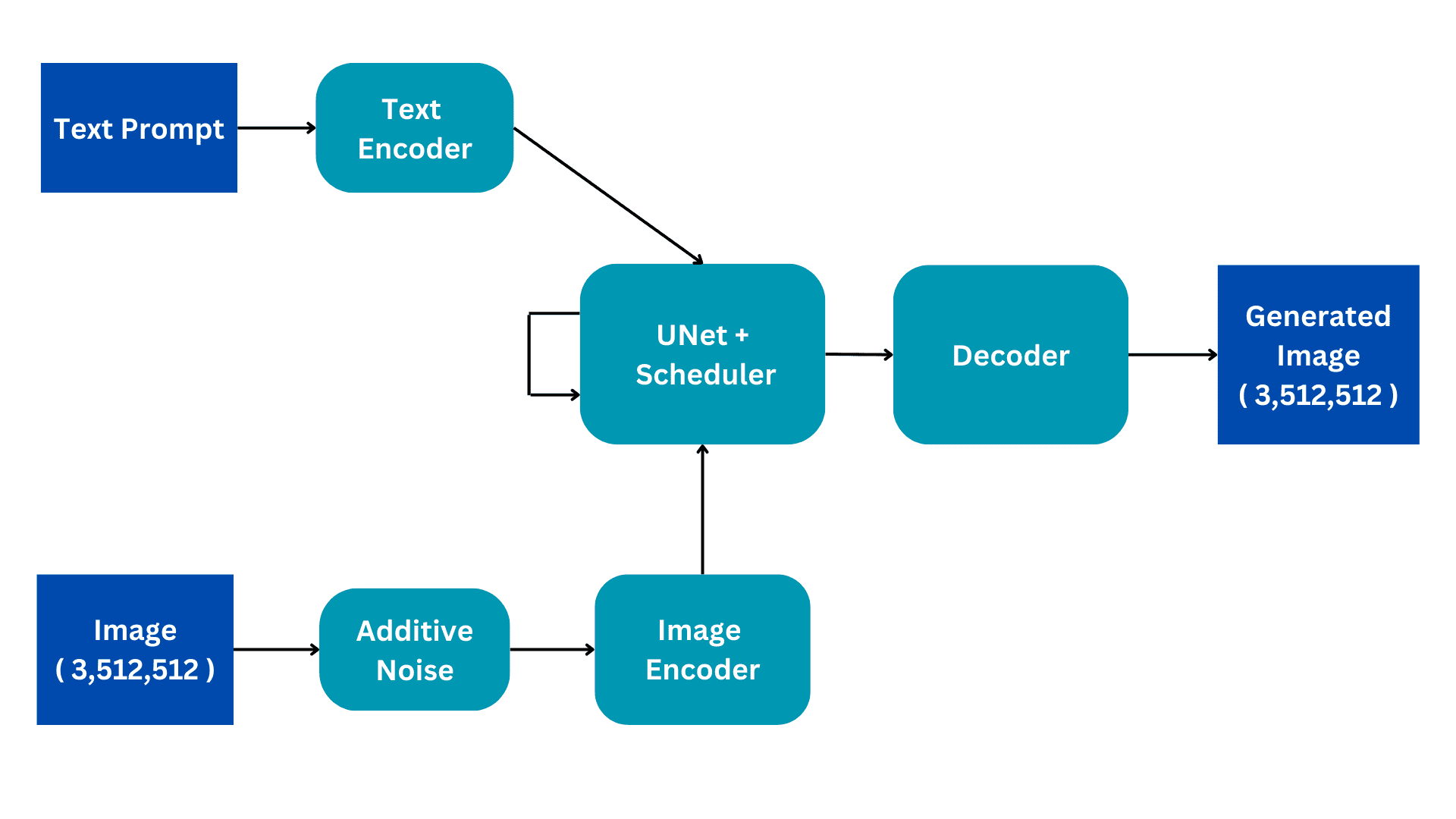
תרשים זרימה זה מציג את הגרסה הפשוטה של ארכיטקטורת דיפוזיה יציבה. נעבור על זה חלק אחר חלק כדי לבנות הבנה טובה יותר של הפעולה הפנימית. נרחיב על תהליך האימון להבנה טובה יותר, כאשר להסקת ההסקה יש רק כמה שינויים עדינים.
תמונה מאת המחבר
תשומות
המודלים של Stable Diffusion מאומנים על מערכי נתונים של Image Captioning כאשר לכל תמונה יש כיתוב או הנחיה המשויכים המתארים את התמונה. לכן ישנן שתי כניסות למודל; הנחיה טקסטואלית בשפה טבעית ותמונה בגודל (3,512,512) בעלת 3 ערוצי צבע ומידות בגודל 512.
רעש נוסף
התמונה מומרת לרעש מלא על ידי הוספת רעש גאוס לתמונה המקורית. זה נעשה בשלבים עוקבים, למשל, כמות קטנה של רעש מתווספת לתמונה במשך 50 צעדים רצופים עד שהתמונה רועשת לחלוטין. תהליך הדיפוזיה ישאף להסיר את הרעש הזה ולשחזר את התמונה המקורית. כיצד זה נעשה יסביר עוד.
מקודד תמונה
מקודד התמונות מתפקד כרכיב של מקודד אוטומטי וריאציוני, ממיר את התמונה ל'מרחב סמוי' ומשנה את גודלה לממדים קטנים יותר, כגון (4, 64, 64), תוך שהוא כולל גם מימד אצווה נוסף. תהליך זה מפחית דרישות חישוביות ומשפר את הביצועים. שלא כמו דגמי הדיפוזיה המקוריים, Stable Diffusion משלבת את שלב הקידוד בממד הסמוי, וכתוצאה מכך חישוב מופחת, כמו גם ירידה בזמן האימון וההסקה.
מקודד טקסט
ההנחיה בשפה הטבעית הופכת להטמעה וקטורית על ידי מקודד הטקסט. תהליך זה משתמש במודל Transformer Language, כגון מודלים מבוססי BERT או GPT CLIP Text. דגמי מקודד טקסט משופרים משפרים משמעותית את איכות התמונות שנוצרו. הפלט המתקבל של מקודד הטקסט מורכב ממערך של וקטורי הטבעה של 768 מימדים עבור כל מילה. על מנת לשלוט באורך ההנחיה, נקבעה מגבלה מקסימלית של 77. כתוצאה מכך, מקודד הטקסט מייצר טנזור עם ממדים של (77, 768).
UNet
זהו החלק היקר ביותר מבחינה חישובית בארכיטקטורה ועיבוד הדיפוזיה העיקרי מתרחש כאן. הוא מקבל קידוד טקסט ותמונה סמויה רועשת כקלט. מודול זה נועד לשחזר את התמונה המקורית מהתמונה הרועשת שהוא מקבל. הוא עושה זאת באמצעות מספר שלבי הסקה שניתן להגדיר כהיפרפרמטר. בדרך כלל מספיקים 50 שלבי הסקה.
שקול תרחיש פשוט שבו תמונת קלט עוברת טרנספורמציה לרעש על ידי החדרה הדרגתית של כמויות קטנות של רעש ב-50 שלבים רצופים. תוספת מצטברת זו של רעש הופכת בסופו של דבר את התמונה המקורית לרעש מוחלט. המטרה של UNet היא להפוך את התהליך הזה על ידי חיזוי הרעש שנוסף בשלב הזמן הקודם. במהלך תהליך דה-noising, ה-UNet מתחיל בחיזוי הרעש שנוסף בשלב הזמן ה-50 עבור שלב הזמן הראשוני. לאחר מכן הוא מוריד את הרעש החזוי מתמונת הקלט וחוזר על התהליך. בכל שלב זמן עוקב, ה-UNet חוזה את הרעש שנוסף בשלב הזמן הקודם, ומשחזר בהדרגה את תמונת הקלט המקורית מרעש מלא. לאורך תהליך זה, ה-UNet מסתמך באופן פנימי על וקטור ההטמעה הטקסטואלית כגורם התניה.
ה-UNet מוציא טנסור בגודל (4, 64, 64) המועבר לחלק המפענח של ה- Variational AutoEncoder.
מפענח
המפענח הופך את המרת הייצוג הסמוי שנעשה על ידי המקודד. זה לוקח ייצוג סמוי וממיר אותו בחזרה למרחב תמונה. לכן, הוא מוציא תמונה (3,512,512), בגודל זהה למרחב הקלט המקורי. במהלך האימון, אנו שואפים למזער את האובדן בין התמונה המקורית לתמונה שנוצרה. בהתחשב בכך, בהינתן הנחיה טקסטואלית, אנו יכולים ליצור תמונה הקשורה להנחיה מתמונה רועשת לחלוטין.
במהלך ההסקה, אין לנו תמונת קלט. אנו עובדים רק במצב טקסט לתמונה. אנו מסירים את חלק הרעש התוסף ובמקום זאת משתמשים בטנזור שנוצר באקראי בגודל הנדרש. שאר הארכיטקטורה נשארת זהה.
ה-UNet עבר הכשרה ליצירת תמונה מרעש מוחלט, תוך מינוף הטמעת הודעות טקסט. הקלט הספציפי הזה משמש בשלב ההסקה, ומאפשר לנו ליצור בהצלחה תמונות סינתטיות מהרעש. תפיסה כללית זו משמשת כאינטואיציה הבסיסית מאחורי כל מודלים של ראייה ממוחשבת.
מוחמד ארחם הוא מהנדס למידה עמוקה העובד בראייה ממוחשבת ועיבוד שפה טבעית. הוא עבד על פריסה ואופטימיזציה של מספר יישומי AI גנרטיביים שהגיעו למצעד המוביל העולמי ב-Vyro.AI. הוא מעוניין בבנייה ואופטימיזציה של מודלים של למידת מכונה למערכות חכמות ומאמין בשיפור מתמיד.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. רכב / רכבים חשמליים, פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- BlockOffsets. מודרניזציה של בעלות על קיזוז סביבתי. גישה כאן.
- מקור: https://www.kdnuggets.com/2023/06/stable-diffusion-basic-intuition-behind-generative-ai.html?utm_source=rss&utm_medium=rss&utm_campaign=stable-diffusion-basic-intuition-behind-generative-ai
- :יש ל
- :הוא
- :איפה
- 50
- 77
- a
- מושלם
- הוסיף
- מוסיף
- תוספת
- נוסף
- תוסף
- AI
- המטרה
- מטרות
- תעשיות
- גם
- כמות
- כמויות
- an
- ו
- יישומים
- ארכיטקטורה
- ARE
- מערך
- מאמר
- AS
- המשויך
- At
- תשומת לב
- בחזרה
- בסיסי
- BE
- מאחור
- להיות
- מאמין
- מוטב
- בֵּין
- שניהם
- לִבנוֹת
- בִּניָן
- by
- CAN
- נתפס
- שינויים
- ערוצים
- תרשימים
- צֶבַע
- להשלים
- לחלוטין
- רְכִיב
- חישוב
- המחשב
- ראייה ממוחשבת
- מושג
- מושגים
- רצופים
- מורכב
- לִשְׁלוֹט
- המרה
- הומר
- המרת
- כיום
- מערכי נתונים
- עמוק
- למידה עמוקה
- פריסה
- שידור
- מֵמַד
- ממדים
- עושה
- עשה
- באופן דרמטי
- בְּמַהֲלָך
- כל אחד
- משוכלל
- הטבעה
- מוּעֳסָק
- מעסיקה
- מה שמאפשר
- מהנדס
- להגביר את
- משופר
- משפר
- בסופו של דבר
- דוגמה
- יוצא דופן
- יקר
- מוסבר
- גורם
- מעטים
- שדה
- בעד
- קרן
- החל מ-
- פונקציות
- יסודי
- נוסף
- כללי
- ליצור
- נוצר
- גנרטטיבית
- AI Generative
- נתן
- גלוֹבָּלִי
- Go
- בהדרגה
- יש
- יש
- he
- כאן
- איך
- HTTPS
- תמונה
- תמונות
- השבחה
- in
- כולל
- משלבת
- בתחילה
- קלט
- תשומות
- במקום
- אינטליגנטי
- מעוניין
- פנימי
- כלפי פנים
- אל תוך
- החדרה
- אינטואיציה
- IT
- jpg
- KDnuggets
- שפה
- מוביל
- למידה
- אורך
- מינוף
- להגביל
- לינקדין
- את
- מכונה
- למידת מכונה
- ראשי
- מקסימום
- מֵתוֹדוֹלוֹגִיָה
- מסע אמצע
- לצמצם
- מצב
- מודל
- דוגמנות
- מודלים
- מודול
- רוב
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- לא
- רעש
- בדרך כלל
- מטרה
- of
- הַצָעָה
- on
- רק
- מיטוב
- or
- להזמין
- מְקוֹרִי
- תפוקה
- יותר
- חלק
- עבר
- עבר
- אֲנָשִׁים
- ביצועים
- לְחַבֵּר
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- חזה
- ניבוי
- תחזית
- קודם
- תהליך
- תהליך
- מיוצר
- ייצור
- איכות
- נוצר באופן אקראי
- הגיע
- מקבל
- להכיר
- מופחת
- מפחית
- קָשׁוּר
- לסמוך
- שְׂרִידִים
- להסיר
- נציגות
- נדרש
- דרישות
- REST
- שחזור
- תוצאה
- וכתוצאה מכך
- להפוך
- s
- אותו
- תרחיש
- משמש
- סט
- כמה
- זז
- הופעות
- באופן משמעותי
- פָּשׁוּט
- פשוט
- מידה
- קטן
- קטן יותר
- כמה
- מֶרחָב
- ספציפי
- יציב
- התמחות
- שלב
- צעדים
- לאחר מכן
- בהצלחה
- כזה
- מספיק
- הסובב
- סינטטי
- מערכות
- לוקח
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- אז
- שם.
- לכן
- זֶה
- דרך
- בכל
- זמן
- ל
- חלק עליון
- לקראת
- מְאוּמָן
- הדרכה
- טרנספורמציה
- טרנספורמציה
- שנאי
- התמרות
- שתיים
- עוברת
- עבר
- הבנה
- בניגוד
- עד
- us
- להשתמש
- מְשׁוּמָשׁ
- באמצעות
- גרסה
- חזון
- we
- טוֹב
- אשר
- בזמן
- יצטרך
- עם
- Word
- תיק עבודות
- עבד
- עובד
- עובד
- עוֹלָם
- שנים
- זפירנט