מודלים של שפה הם שיטות סטטיסטיות המנבאות את רצף האסימונים ברצפים, תוך שימוש בטקסט טבעי. מודלים של שפה גדולה (LLMs) הם מודלים של שפה מבוססי רשת עצבית עם מאות מיליונים (ברט) עד מעל טריליון פרמטרים (MiCS), ושגודלו הופך את האימון ב-GPU יחיד לבלתי מעשי. היכולות היצירתיות של LLMs הופכות אותם לפופולריים עבור סינתזת טקסט, סיכום, תרגום מכונה ועוד.
גודלו של LLM ונתוני ההדרכה שלו הם חרב פיפיות: זה מביא איכות דוגמנות, אבל כרוך באתגרי תשתית. הדגם עצמו לרוב גדול מכדי להכנס לזיכרון של התקן GPU יחיד או במכשירים מרובים של מופע מרובה GPU. גורמים אלה דורשים הכשרה של LLM על גבי אשכולות גדולים של מופעי למידת מכונה מואצת (ML). בשנים האחרונות, לקוחות רבים השתמשו ב-AWS Cloud להדרכה של LLM.
בפוסט זה, אנו צוללים לתוך טיפים ושיטות עבודה מומלצות להכשרה מוצלחת של LLM בנושא אימון אמזון SageMaker. SageMaker Training הוא שירות מחשוב ML מנוהל המפחית את הזמן והעלות לאימון ולכוונן דגמים בקנה מידה ללא צורך בניהול תשתית. בתוך פקודת הפעלה אחת, אמזון SageMaker משיקה אשכול מחשוב ארעי פונקציונלי במלואו המריץ את המשימה שתבחר, ועם תכונות ML משופרות כגון metastore, I/O מנוהל והפצה. הפוסט מכסה את כל השלבים של עומס עבודה בהדרכה LLM ומתאר תכונות תשתית ושיטות עבודה מומלצות הקשורות. חלק מהשיטות המומלצות בפוסט זה מתייחסות ספציפית למופעי ml.p4d.24xlarge, אך רובם מתאימים לכל סוג מופע. שיטות עבודה מומלצות אלו מאפשרות לך להכשיר LLMs ב- SageMaker בקנה מידה של עשרות עד מאות מיליוני פרמטרים.
לגבי היקף הפוסט הזה, שים לב לדברים הבאים:
- אנחנו לא מכסים עיצוב מדעי של רשתות עצביות ואופטימיזציות נלוות. Amazon.Science כולל פרסומים מדעיים רבים, כולל ולא רק לימודי תואר שני.
- למרות שפוסט זה מתמקד בלימודי LLM, רוב השיטות המומלצות שלו רלוונטיות לכל סוג של הכשרה במודלים גדולים, כולל ראייה ממוחשבת ומודלים מולטי-מודאליים, כגון Stable Diffusion.
שיטות עבודה מומלצות
אנו דנים בשיטות המומלצות הבאות בפוסט זה:
- לחשב - SageMaker Training הוא ממשק API נהדר להשיק עבודות הכנה של מערך נתונים של CPU ועבודות GPU בקנה מידה אלף.
- אחסון - אנו רואים טעינת נתונים ובדיקת נקודות בשתי דרכים, בהתאם לכישורים והעדפות: עם א אמזון FSx ברק מערכת קבצים, או שירות אחסון פשוט של אמזון (Amazon S3) בלבד.
- מקביליות - הבחירה שלך בספריית אימון מבוזרת היא קריטית לשימוש מתאים ב-GPUs. אנו ממליצים להשתמש בספרייה מותאמת לענן, כגון SageMaker sharded data parallelism, אך גם ספריות בניהול עצמי וקוד פתוח יכולות לעבוד.
- רישות - ודא ש-EFA ו-NVIDIA GPUDirectRDMA מופעלים, לתקשורת בין-מכונות מהירה.
- גמישות - בקנה מידה, כשלי חומרה יכולים לקרות. אנו ממליצים לבצע מחסומים באופן קבוע. כל כמה שעות זה נפוץ.
בחירת אזור
סוג המופע והקיבולת הרצויה הם גורם מכריע לבחירת אזור. עבור האזורים הנתמכים על ידי SageMaker וה- ענן מחשוב אלסטי של אמזון (Amazon EC2) סוגי מופעים הזמינים בכל אזור, ראה תמחור SageMaker של אמזון. בפוסט זה, אנו מניחים שסוג מופע האימון הוא ml.p4d.24xlarge המנוהל על ידי SageMaker.
אנו ממליצים לעבוד עם צוות חשבון AWS שלך או ליצור קשר מכירות AWS כדי לקבוע את האזור המתאים לעומס העבודה שלך ב-LLM.
הכנת נתונים
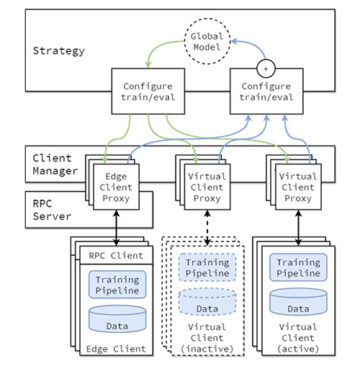
מפתחי LLM מאמנים את המודלים שלהם על מערכי נתונים גדולים של טקסט המתרחש באופן טבעי. דוגמאות פופולריות למקורות נתונים כאלה כוללים סריקה נפוצה ו הערימה. טקסט המתרחש באופן טבעי עשוי להכיל הטיות, אי דיוקים, שגיאות דקדוקיות וגרסאות תחביר. האיכות הסופית של LLM תלויה באופן משמעותי בבחירה ואצור של נתוני ההדרכה. הכנת נתוני אימון LLM הוא תחום פעיל של מחקר וחדשנות בתעשיית LLM. ההכנה של מערך נתונים לעיבוד שפה טבעית (NLP) שופעת הזדמנויות מקבילות ללא שיתוף. במילים אחרות, ישנם שלבים שניתן ליישם על יחידות יצירות - קבצי מקור, פסקאות, משפטים, מילים - מבלי להידרש לסנכרון בין עובדים.
ממשקי ה-API של SageMaker Jobs, כלומר SageMaker Training ו- SageMaker Processing, מצטיינים עבור משימות מסוג זה. הם מאפשרים למפתחים להפעיל קונטיינר שרירותי של Docker על צי של מכונות מרובות. במקרה של SageMaker Training API, צי המחשוב יכול להיות הטרוגנית. נעשה שימוש במספר מסגרות מחשוב מבוזרות ב- SageMaker, כולל לוּחַ מַחווָנִים, ריי, וגם PySpark, שיש להם ייעודי מיכל מנוהל AWS ו SDK ב- SageMaker Processing.
כאשר אתה משיק עבודה עם מספר מכונות, SageMaker Training and Processing מריצים את הקוד שלך פעם אחת לכל מכונה. אינך צריך להשתמש במסגרת מחשוב מבוזרת מסוימת כדי לכתוב יישום מבוזר: אתה יכול לכתוב את הקוד לפי בחירתך, שיפעל פעם אחת בכל מכונה, כדי לממש מקביליות של שיתוף-כלום. אתה יכול גם לכתוב או להתקין את לוגיקת התקשורת הבין-צומתית לפי בחירתך.
טעינת נתונים
ישנן דרכים מרובות לאחסן את נתוני האימון ולהעביר אותם מהאחסון שלו לצמתי המחשוב המואצים. בסעיף זה, אנו דנים באפשרויות ובשיטות העבודה המומלצות לטעינת נתונים.
אפשרויות אחסון וטעינה של SageMaker
גודל מערך LLM טיפוסי הוא במאות מיליוני אסימוני טקסט, המייצגים כמה מאות גיגה-בייט. אשכולות המנוהלים על ידי SageMaker של מופעי ml.p4d.24xlarge מציעים מספר אפשרויות לאחסון וטעינה של מערכי נתונים:
- SSD NVMe בצומת – מופעי ml.P4d.24xlarge מצוידים ב-8TB NVMe, זמין תחת
/opt/ml/input/data/<channel>אם אתה משתמש מצב קובץ SageMaker, וב-/tmp. אם אתה מחפש את הפשטות והביצועים של קריאה מקומית, אתה יכול להעתיק את הנתונים שלך ל-NVMe SSD. ההעתקה יכולה להיעשות על ידי מצב SageMaker File, או על ידי קוד משלך, למשל באמצעות ריבוי עיבודים Boto3 or S5cmd. - FSx עבור Luster - כונני SSD NVMe בצומת מוגבלים בגודלם, ודורשים קליטה מאמזון S3 בכל עבודה או יצירת אשכול חמים. אם אתה מעוניין להגדיל את קנה המידה למערכי נתונים גדולים יותר תוך שמירה על גישה אקראית עם זמן אחזור נמוך, אתה יכול להשתמש ב-FSx עבור Lustre. אמזון FSx היא מערכת קבצים מקבילית בקוד פתוח, פופולרית במחשוב בעל ביצועים גבוהים (HPC). FSx לשימושים ב-Luster אחסון קבצים מבוזר (הפשטה) ומפרידה פיזית מטא נתונים של קבצים מתוכן הקובץ כדי להשיג קריאה/כתיבה בעלת ביצועים גבוהים.
- SageMaker FastFile Mode - FastFile מצב (FFM) היא תכונה של SageMaker בלבד המציגה אובייקטי S3 מרוחקים במופעי מחשוב המנוהלים על ידי SageMaker תחת ממשק תואם POSIX, ומזרימה אותם רק בקריאה, באמצעות FUSE. FFM קורא תוצאות בשיחות S3 שמזרימות קבצים מרוחקים בלוק אחר בלוק. כדרך מומלצת להימנע משגיאות הקשורות לתעבורה של Amazon S3, מפתחי FFM צריכים לשאוף לשמור על המספר הבסיסי של שיחות S3 סביר, למשל על ידי קריאת קבצים ברצף ועם כמות מבוקרת של מקביליות.
- טעינת נתונים בניהול עצמי - כמובן, אתה יכול גם להחליט ליישם את לוגיקית טעינת הנתונים בהתאמה אישית משלך, באמצעות קוד קנייני או קוד פתוח. כמה סיבות להשתמש בטעינת נתונים בניהול עצמי הן כדי להקל על הגירה על ידי שימוש חוזר בקוד שכבר פותח, כדי ליישם לוגיקת טיפול מותאמת אישית בשגיאות, או כדי לקבל שליטה רבה יותר על הביצועים הבסיסיים והפיצול. דוגמאות לספריות שבהן אתה עשוי להשתמש לטעינת נתונים בניהול עצמי כוללות torchdata.datapipes (בעבר תוסף AWS PyTorch S3) ו ערכת נתונים באינטרנט. AWS Python SDK Boto3 ניתן לשלב גם עם ערכת נתונים לפיד שיעורים ליצירת קוד טעינת נתונים מותאם אישית. שיעורי טעינת נתונים מותאמים אישית מאפשרים גם שימוש יצירתי באשכולות הטרוגניים של SageMaker Training, כדי להתאים היטב את איזון המעבד וה-GPU לעומס עבודה נתון.
למידע נוסף על אפשרויות אלו וכיצד לבחור בהן, עיין ב בחר את מקור הנתונים הטוב ביותר עבור עבודת ההדרכה שלך ב-Amazon SageMaker.
שיטות עבודה מומלצות לאינטראקציה בקנה מידה גדול עם Amazon S3
Amazon S3 מסוגל להתמודד עם עומסי עבודה של LLM, הן לקריאת נתונים והן לבדיקת נקודות ביקורת. זה תומך ב שיעור בקשה של 3,500 PUT/COPY/POST/DELETE או 5,500 GET/HEAD בקשות לשנייה לכל קידומת בדלי. עם זאת, שיעור זה אינו זמין בהכרח כברירת מחדל. במקום זאת, ככל שקצב הבקשות לקידומת גדל, אמזון S3 משתנה אוטומטית כדי להתמודד עם הקצב המוגבר. למידע נוסף, עיין ב מדוע אני מקבל שגיאות 503 האטה מאמזון S3 כאשר הבקשות נמצאות בקצב הבקשות הנתמך לכל קידומת.
אם אתה מצפה לאינטראקציה בתדירות גבוהה של Amazon S3, אנו ממליצים על השיטות המומלצות הבאות:
- נסה לקרוא ולכתוב ממספר דליים של S3 ו קידומות. לדוגמה, אתה יכול לחלק נתוני אימון ונקודות ביקורת על פני קידומות שונות.
- בדוק את מדדי Amazon S3 אמזון CloudWatch כדי לעקוב אחר שיעורי הבקשות.
- נסה למזער את כמות ה-PUT/GET בו-זמנית:
- יש פחות תהליכים באמצעות Amazon S3 בו-זמנית. לדוגמה, אם שמונה תהליכים לכל צמתים צריכים לעבור נקודת ביקורת ל-Amazon S3, אתה יכול להפחית את תעבורת ה-PUT בפקטור של 8 על ידי בדיקה היררכית: תחילה בתוך הצומת, ואז מהצומת ל-Amazon S3.
- קרא רשומות אימון מרובות מקובץ בודד או S3 GET, במקום להשתמש ב-S3 GET עבור כל רשומת אימון.
- אם אתה משתמש באמזון S3 דרך SageMaker FFM, SageMaker FFM מבצע שיחות S3 כדי להביא קבצים חלק אחר נתח. כדי להגביל את תעבורת Amazon S3 שנוצרת על ידי FFM, אנו ממליצים לך לקרוא קבצים ברצף ולהגביל את מספר הקבצים שנפתחו במקביל.
אם יש לך תוכנית תמיכה למפתחים, לעסקים או ארגוניים, אתה יכול לפתוח תיק תמיכה טכנית לגבי שגיאות S3 503 Slow Down. אבל תחילה ודא שפעלת לפי השיטות המומלצות, וכן לקבל את מזהי הבקשה לבקשות שנכשלו.
אימון מקביליות
ל-LLMs יש בדרך כלל עשרות עד מאות מיליארדי פרמטרים, מה שהופך אותם לגדולים מכדי להתאים לכרטיס NVIDIA GPU יחיד. מתרגלי LLM פיתחו מספר ספריות קוד פתוח המאפשרות את החישוב המבוזר של אימון LLM, כולל FSDP, DeepSpeed ו מגהטרון. אתה יכול להפעיל את הספריות האלה ב- SageMaker Training, אבל אתה יכול גם להשתמש בספריות הדרכה מבוזרות של SageMaker, שעברו אופטימיזציה עבור AWS Cloud ומספקות חווית מפתח פשוטה יותר. למפתחים יש שתי אפשרויות להדרכה מבוזרת של LLM שלהם ב- SageMaker: ספריות מבוזרות או בניהול עצמי.
SageMaker חילקה ספריות
כדי לספק לך ביצועי אימון מבוזר משופרים ושימושיות, SageMaker Training מציע מספר הרחבות קנייניות להגדלת קוד האימון של TensorFlow ו- PyTorch. אימון LLM מבוצע לעתים קרובות בצורה מקבילית תלת מימדית:
- מקבילות נתונים מפצל ומזין את מיני-אצות האימון למספר העתקים זהים של הדגם, כדי להגביר את מהירות העיבוד
- מקביליות צנרת מייחס שכבות שונות של המודל למעבדי GPU שונים או אפילו למופעים שונים, כדי להגדיל את גודל הדגם מעבר ל-GPU בודד ולשרת בודד
- מקביליות טנזור מפצל שכבה בודדת למספר GPUs, בדרך כלל בתוך אותו שרת, כדי לשנות את קנה המידה של שכבות בודדות לגדלים העולים על GPU בודד
בדוגמה הבאה, מודל 6 שכבות מאומן על אשכול של שרתים k*3 עם 8*k*3 GPUs (8 GPUs לשרת). דרגת מקביליות הנתונים היא k, מקביליות צינור 6 ומקביליות טנזור 4. כל GPU באשכול מכיל רבע משכבת מודל, ודגם מלא מחולק על פני שלושה שרתים (24 GPU בסך הכל).

הדברים הבאים רלוונטיים במיוחד עבור לימודי תואר שני:
- SageMaker הפיץ דגם מקביל - ספריה זו משתמשת בחלוקה של גרפים כדי לייצר חלוקה חכמה של מודלים המותאמת למהירות או לזיכרון. במקביל למודלים מבוזרים של SageMaker חושפת את מיטוב ההדרכה העדכנית והטובה ביותר של מודלים גדולים, כולל מקביליות נתונים, מקביליות צינורות, מקביליות טנזור, פיצול מצבי מיטוב, בדיקת הפעלה והורדה. עם ספריית הדגמים המקבילים המבוזרים של SageMaker, תיעדנו אימון מודל של 175 מיליארד פרמטרים על פני 920 GPUs של NVIDIA A100. למידע נוסף, עיין ב אימון של 175+ מיליארד פרמטרים של דגמי NLP עם תוספות מקבילות לדגמים ו-Huging Face ב-Amazon SageMaker.
- SageMaker חילקה נתונים במקביל - ב MiCS: קנה מידה כמעט ליניארי לאימון מודל ענק בענן ציבורי, Zhang et al. הצג אסטרטגיה מקבילה של מודל תקשורת נמוך שמחלקת מודלים על פני קבוצת נתונים מקבילה בלבד, במקום האשכול כולו. עם MiCS, מדעני AWS הצליחו להשיג 176 טרה-פלופים לכל GPU (56.4% מהשיא התיאורטי) לאימון מודל של 210 שכבות של 1.06 טריליון פרמטרים במקרי EC2 P4de. MiCS זמין כעת עבור לקוחות SageMaker Training as SageMaker חילקה נתונים במקביל.
ספריות הדרכה מבוזרות של SageMaker מספקות ביצועים גבוהים וחווית מפתח פשוטה יותר. בפרט, מפתחים אינם צריכים לכתוב ולתחזק משגר תהליכים מקבילים מותאם אישית או להשתמש בכלי השקה ספציפי למסגרת, מכיוון שהמשגר המקביל מובנה ב-SDK להפעלת העבודה.
בניהול עצמי
עם SageMaker Training, יש לך את החופש להשתמש במסגרת ובפרדיגמה המדעית שתבחר. בפרט, אם אתה רוצה לנהל אימונים מבוזרים בעצמך, יש לך שתי אפשרויות לכתוב את הקוד המותאם אישית שלך:
- השתמש במיכל ללמידה עמוקה של AWS (DLC) – AWS מפתחת ומתחזקת DLC, מתן סביבות מבוססות Docker מותאמות ל-AWS עבור מסגרות ML מובילות בקוד פתוח. ל- SageMaker Training יש אינטגרציה ייחודית המאפשרת לך למשוך ולהפעיל DLCs של AWS עם נקודת כניסה חיצונית המוגדרת על ידי משתמש. עבור אימון LLM במיוחד, DLCs AWS עבור TensorFlow, PyTorch, Hugging Face ו-MXNet רלוונטיים במיוחד. שימוש ב-Framework DLC מאפשר לך להשתמש במקביליות-Native-framework, כגון PyTorch Distributed, מבלי שתצטרך לפתח ולנהל תמונות Docker משלך. בנוסף, ה-DLCs שלנו כוללים אינטגרציה של MPI, המאפשר לך להפעיל קוד מקביל בקלות.
- כתוב תמונת Docker מותאמת אישית של SageMaker - אתה יכול להביא תמונה משלך (BYO) (ראה השתמש באלגוריתמי אימון משלך ו מכולות הדרכה מותאמות אישית של אמזון SageMaker), החל מאפס או הרחבת תמונת DLC קיימת. בעת שימוש בתמונה מותאמת אישית עבור אימון LLM ב- SageMaker, חשוב במיוחד לאמת את הדברים הבאים:
- התמונה שלך מכילה EFA עם הגדרות מתאימות (נדון בהרחבה בהמשך הפוסט הזה)
- התמונה שלך מכילה ספריית תקשורת NVIDIA NCCL, מופעלת עם GPUDirectRDMA
לקוחות יכלו להשתמש במספר ספריות הדרכה מבוזרות בניהול עצמי, כולל DeepSpeed.
תקשורת
בהתחשב באופי המבוזר של עבודת אימון LLM, תקשורת בין-מכונות היא קריטית להיתכנות, לביצועים ולעלויות של עומס העבודה. בחלק זה, אנו מציגים מאפיינים מרכזיים לתקשורת בין-מכונות ומסיימים בטיפים להתקנה וכיוונון.
מתאם בד אלסטי
על מנת להאיץ את יישומי ML ולשפר ביצועים על ידי השגת גמישות, מדרגיות וגמישות שמספק הענן, אתה יכול לנצל מתאם בד אלסטי (EFA) עם SageMaker. מניסיוננו, שימוש ב-EFA הוא דרישה כדי לקבל ביצועי אימון LLM מרובי צמתים משביעי רצון.
מכשיר EFA הוא ממשק רשת המחובר למופעי EC2 המנוהלים על ידי SageMaker במהלך הפעלת עבודות ההדרכה. EFA זמין במשפחות ספציפיות של מקרים, כולל P4d. רשתות EFA מסוגלות להשיג כמה מאות Gbps של תפוקה.
משויך ל-EFA, AWS הציגה את Datagram אמין להרחבה (SRD), תחבורה מבוססת אתרנט בהשראת ה Datagram Reliable InfiniBand, התפתח עם אילוץ רגוע של הזמנת מנות. למידע נוסף על EFA ו-SRD, עיין ב בחיפוש אחר ביצועים, יש יותר מדרך אחת לבנות רשת, הסרטון איך EFA עובד ומדוע אנחנו לא משתמשים באינפיניבנד בענן, ומאמר המחקר פרוטוקול הובלה מותאם לענן עבור HPC אלסטי וניתן להרחבה משלו ואח'.
אתה יכול להוסיף אינטגרציה של EFA על מופעים תואמים לקונטיינרים קיימים של Docker של SageMaker, או קונטיינרים מותאמים אישית שיכולים לשמש לאימון מודלים של ML באמצעות משרות SageMaker. למידע נוסף, עיין ב אימון ריצה עם EFA. EFA נחשף באמצעות הקוד הפתוח Libfabric חבילת תקשורת. עם זאת, מפתחי LLM לעיתים רחוקות מתכנתים אותו ישירות עם Libfabric, ובדרך כלל מסתמכים במקום זאת על ספריית התקשורת הקולקטיבית של NVIDIA (NCCL).
תוסף AWS-OFI-NCCL
ב-ML מבוזר, EFA משמש לרוב עם ספריית התקשורת הקולקטיבית של NVIDIA (NCCL). NCCL היא ספריית קוד פתוח שפותחה על ידי NVIDIA המיישמת אלגוריתמי תקשורת בין-GPU. תקשורת בין-GPU היא אבן יסוד באימון LLM המזרז מדרגיות וביצועים. זה כל כך קריטי לאימון DL שלעתים קרובות ה-NCCL משולב ישירות כאמצעי תקשורתי בספריות אימון למידה עמוקה, כך שמפתחי LLM משתמשים בו - לפעמים בלי לשים לב - מתוך מסגרת הפיתוח המועדפת עליהם של Python DL. כדי להשתמש ב-NCCL על EFA, מפתחי LLM משתמשים ב-AWS שפותח תוסף AWS OFI NCCL, אשר ממפה קריאות NCCL לממשק Libfabric המשמש את EFA. אנו ממליצים להשתמש בגרסה העדכנית ביותר של AWS OFI NCCL כדי ליהנות מהשיפורים האחרונים.
כדי לוודא שה-NCCL משתמש ב-EFA, עליך להגדיר את משתנה הסביבה NCCL_DEBUG ל INFO, ובדוק ביומנים שה- EFA נטען על ידי ה-NCCL:
למידע נוסף על תצורת NCCL ו-EFA, עיין ב בדוק את תצורת ה-EFA וה-NCCL שלך. אתה יכול להתאים אישית את ה-NCCL עם כמה משתני סביבה. שימו לב כי יעיל ב-NCCL 2.12 ומעלה, AWS תרם לוגיקת בחירת אלגוריתמי תקשורת אוטומטית עבור רשתות EFA (NCCL_ALGO ניתן להשאיר לא מוגדר).
NVIDIA GPUDirect RDMA על EFA
עם סוג המופע P4d, אנחנו הציג GPUDirect RDMA (GDR) על בד EFA. זה מאפשר לכרטיסי ממשק רשת (NIC) לגשת ישירות לזיכרון GPU, מה שהופך את התקשורת המרוחקת של GPU ל-GPU על פני מופעי EC2 מבוססי NVIDIA GPU למהירה יותר, ומפחיתה את תקורה התזמורת במעבדים ויישומי משתמש. GDR משמש מתחת למכסה המנוע על ידי ה-NCCL, כאשר הדבר אפשרי.
שימוש ב-GDR מופיע בתקשורת בין-GPU כאשר רמת היומן מוגדרת ל-INFO, כמו בקוד הבא:
שימוש ב-EFA במיכלי למידה עמוקה של AWS
AWS מתחזקת Deep Learning Containers (DLCs), שרבים מהם מגיעים עם Dockerfiles מנוהלים על ידי AWS ובנויים המכילים EFA, AWS OFI NCCL ו-NCCL. המאגרים הבאים של GitHub מציעים דוגמאות עם PyTorch ו TensorFlow. אתה לא צריך להתקין את הספריות האלה בעצמך.
שימוש ב-EFA במיכל הדרכה SageMaker משלך
אם אתה יוצר מיכל משלך של SageMaker Training וברצונך להשתמש ב-NCCL על EFA לתקשורת בין-צומתים מואצת, עליך להתקין את EFA, NCCL ו-AWS OFI NCCL. למידע נוסף, עיין ב אימון ריצה עם EFA. בנוסף, עליך להגדיר את משתני הסביבה הבאים במיכל שלך או בקוד נקודת הכניסה שלך:
FI_PROVIDER="efa"מציין את ספק ממשק הבדNCCL_PROTO=simpleמורה ל-NCCL להשתמש בפרוטוקול פשוט לתקשורת (כרגע, ספק ה-EFA אינו תומך בפרוטוקולי LL; הפעלתם עלולה להוביל לשחיתות נתונים)FI_EFA_USE_DEVICE_RDMA=1משתמש בפונקציונליות ה-RDMA של המכשיר להעברה חד-צדדית ודו-צדדיתNCCL_LAUNCH_MODE="PARALLEL"NCCL_NET_SHARED_COMMS="0"
תזמורת
ניהול מחזור החיים ועומס העבודה של עשרות עד מאות מופעי מחשוב דורש תוכנת תזמור. בחלק זה, אנו מציעים שיטות עבודה מומלצות לתזמור LLM
תזמור בתוך העבודה
מפתחים חייבים לכתוב גם קוד אימון בצד השרת וגם קוד משגר בצד הלקוח ברוב המסגרות המבוזרות. קוד הדרכה פועל על מכונות אימון, בעוד שקוד משגר בצד הלקוח משגר את עומס העבודה המבוזר ממחשב לקוח. כיום יש מעט סטנדרטיזציה, למשל:
- ב- PyTorch, מפתחים יכולים להפעיל משימות מרובות מכונות באמצעות
torchrun,torchx,torch.distributed.launch(נתיב הוצאה משימוש), אוtorch.multiprocessing.spawn - DeepSpeed מציעה את משגר ה-Deepspeed CLI משלה ותומך גם בהשקת MPI
- MPI היא מסגרת מחשוב מקבילה פופולרית שיש לה יתרון בהיותה אגנוסטית של ML ובעלת קביעות סבירה, ולכן יציבה ומתועדת, והיא נראית יותר ויותר בעומסי עבודה מבוזרים של ML
באשכול הדרכה של SageMaker, מיכל ההדרכה מושק פעם אחת בכל מכונה. כתוצאה מכך, עומדות בפניך שלוש אפשרויות:
- משגר מקומי - אתה יכול להשתמש כנקודת כניסה במפעיל המקורי של מסגרת DL מסוימת, למשל א
torchrunשיחה, אשר בעצמה תוליד תהליכים מקומיים מרובים ותיצור תקשורת בין מופעים. - אינטגרציה של SageMaker MPI - אתה יכול להשתמש באינטגרציה של SageMaker MPI, הזמינה ב-AWS DLC שלנו, או ניתנת להתקנה עצמית באמצעות ערכת כלים של sagemaker-training, כדי להפעיל ישירות את קוד נקודת הכניסה שלך N פעמים לכל מכונה. יש לכך יתרון של הימנעות משימוש בתסריטי משגר מתווכים, ספציפיים למסגרת, בקוד משלך.
- SageMaker חילקה ספריות – אם אתה משתמש בספריות המבוזרות של SageMaker, אתה יכול להתמקד בקוד האימון ולא צריך לכתוב קוד משגר בכלל! קוד משגר מבוזר של SageMaker מובנה ב-SageMaker SDK.
תזמור בין תפקידים
פרוייקטים של LLM מורכבים לרוב מעבודות מרובות: חיפוש פרמטרים, ניסויי קנה מידה, התאוששות משגיאות ועוד. על מנת להתחיל, לעצור ולהקביל משימות אימון, חשוב להשתמש במתזמר עבודה. SageMaker Training הוא מתזמר ML ללא שרת המספק מופעי מחשוב חולפים באופן מיידי לפי בקשה. אתה משלם רק על מה שאתה משתמש, ואשכולות מושבתים ברגע שהקוד שלך מסתיים. עם SageMaker אימון בריכות חמות, יש לך אפשרות להגדיר זמן חיים על אשכולות הכשרה, כדי לעשות שימוש חוזר באותה תשתית בין משרות. זה מקטין את זמן האיטרציה ואת השונות במיקום בין-עבודה. ניתן להשיק משרות SageMaker ממגוון שפות תכנות, כולל פיתון ו CLI.
יש Python SDK ספציפית ל-SageMaker שנקראת SageMaker Python SDK ומיושם באמצעות ה בעל חכמים ספריית Python, אך השימוש בה הוא אופציונלי.
הגדלת מכסות למשרות הכשרה עם אשכול הכשרה גדול וארוך
ל- SageMaker יש מכסות ברירת מחדל על משאבים, שנועדו למנוע שימוש ועלויות לא מכוון. כדי להכשיר LLM באמצעות אשכול גדול של מופעים מתקדמים הפועלים לאורך זמן, סביר להניח שתצטרך להגדיל את המכסות בטבלה הבאה.
| שם מכסה | ערך ברירת מחדל |
| זמן הריצה הארוך ביותר עבור עבודת הדרכה | 432,000 שניות |
| מספר המקרים בכל משרות ההדרכה | 4 |
| מספר מקרים מקסימלי לכל עבודת הדרכה | 20 |
| ml.p4d.24xlarge לשימוש בעבודה הדרכה | 0 |
| ml.p4d.24xlarge לאימון שימוש בבריכה חמה | 0 |
לִרְאוֹת מכסות שירות AWS כיצד להציג את ערכי המכסה שלך ולבקש הגדלת מכסה. מכסות לפי דרישה, מופע נקודתי ומכסות בריכות חמות אימון עוקבות ומשונות בנפרד.
אם תחליט להשאיר את SageMaker Profiler מופעל, שים לב שכל עבודת הדרכה משיקה עבודת SageMaker Processing, שכל אחת צורכת מופע אחד של ml.m5.2xlarge. אשר כי מכסות SageMaker Processing שלך גבוהות מספיק כדי להכיל את במקביל לעבודת ההדרכה הצפויה. לדוגמה, אם ברצונך להשיק 50 עבודות הדרכה המותאמות ל-Profiler הפועלות במקביל, תצטרך להעלות את מגבלת השימוש של ml.m5.2xlarge לעיבוד ל-50.
בנוסף, כדי להשיק עבודה ארוכת טווח, תצטרך להגדיר במפורש את מעריך max_run פרמטר למשך המקסימלי הרצוי עבור עבודת ההדרכה בשניות, עד לערך המכסה של זמן הריצה הארוך ביותר עבור עבודת הדרכה.
ניטור וחוסן
כשל בחומרה הוא נדיר ביותר בקנה מידה של מופע בודד והוא הופך תכוף יותר ויותר ככל שמספר המופעים בהם נעשה שימוש בו זמנית גדל. בקנה מידה טיפוסי של LLM - מאות עד אלפי GPUs בשימוש 24/7 במשך שבועות עד חודשים - תקלות חומרה כמעט בטוחות שיתרחשו. לכן, עומס עבודה של LLM חייב ליישם מנגנוני ניטור וחוסן מתאימים. ראשית, חשוב לעקוב מקרוב אחר תשתית LLM, להגביל את ההשפעה של כשלים ולייעל את השימוש במשאבי מחשוב. SageMaker Training מציע מספר תכונות למטרה זו:
- יומנים נשלחים אוטומטית ל-CloudWatch Logs. יומנים כוללים את סקריפט האימון שלך
stdoutוstderr. בהדרכה מבוזרת מבוססת MPI, כל עובדי MPI שולחים את היומנים שלהם לתהליך המנהיג. - מדדי ניצול משאבי המערכת כמו זיכרון, שימוש במעבד ושימוש ב-GPU, נשלחים אוטומטית ל-CloudWatch.
- אתה יכול להגדיר מדדי אימון מותאמים אישית שיישלח ל-CloudWatch. המדדים נלכדים מיומנים המבוססים על ביטויים רגולריים שהגדרת. חבילות ניסוי של צד שלישי כמו שותף AWS ניתן להשתמש בהצעת משקלים והטיות עם SageMaker Training (לדוגמה, ראה מיטוב הפרמטרים של CIFAR-10 עם W&B ו- SageMaker).
- SageMaker Profiler מאפשר לך לבדוק את השימוש בתשתית ולקבל המלצות אופטימיזציה.
- אמזון EventBridge ו AWS למבדה מאפשרים לך ליצור לוגיקה אוטומטית של לקוח המגיבה לאירועים כגון כישלונות בעבודה, הצלחות, העלאות קבצי S3 ועוד.
- SageMaker SSH Helper היא ספריית קוד פתוח המנוהלת על ידי קהילה המאפשרת לך להתחבר למארחי עבודה בהדרכה באמצעות SSH. זה יכול להיות מועיל לבדוק ולפתור תקלות של ריצות קוד בצמתים ספציפיים.
בנוסף לניטור, SageMaker מביאה גם ציוד לחוסן בעבודה:
- בדיקות תקינות אשכול - לפני שהעבודה שלך מתחילה, SageMaker מפעילה בדיקות תקינות של GPU ומאמתת תקשורת NCCL במופעי GPU, ומחליפה כל מופע פגום במידת הצורך על מנת להבטיח שסקריפט האימון שלך יתחיל לרוץ על אשכול בריא של מופעים. בדיקות תקינות מופעלות כעת עבור סוגי מופעים מבוססי P ו-G GPU.
- ניסיונות חוזרים מובנים ועדכון אשכול - אתה יכול להגדיר את SageMaker באופן אוטומטי נסה שוב עבודות הדרכה שנכשלות עם שגיאת שרת פנימית של SageMaker (ISE). כחלק מניסיון חוזר של עבודה, SageMaker תחליף את כל המופעים שנתקלו בשגיאות GPU בלתי ניתנות לשחזור במופעים טריים, תאתחל מחדש את כל המופעים התקינים ותתחיל שוב את העבודה. זה מביא להפעלה מחדש מהירה יותר ולהשלמת עומס העבודה. עדכון אשכול מופעל כעת עבור סוגי מופעים מבוססי P ו-G GPU. אתה יכול להוסיף בעצמך מנגנון ניסיון חוזר אפליקטיבי סביב קוד הלקוח ששולח את העבודה, כדי לטפל בסוגים אחרים של שגיאות השקה, כגון חריגה ממכסת החשבון שלך.
- אוטומטי מחסום לאמזון S3 - זה עוזר לך מחסום ההתקדמות שלך וטען מחדש מצב עבר על משרות חדשות.
כדי ליהנות מהחלפה ברמת הצומת, הקוד שלך חייב שגיאה. קולקטיבים עשויים להיתקע, במקום לטעות, כאשר צומת נכשל. לכן, כדי לקבל תיקון מהיר, הגדר כראוי פסק זמן על הקולקטיבים שלך והקוד יזרוק שגיאה כאשר הוא מושג.
חלק מהלקוחות מגדירים לקוח ניטור כדי לנטר ולפעול במקרה של ניתוק עבודה או עצירת התכנסות אפליקטיבית, על ידי ניטור יומנים ומדדים של CloudWatch עבור דפוסים חריגים כמו אי כתיבה של יומנים או 0% שימוש ב-GPU כדי לרמז על ניתוק, עצירת התכנסות ואוטומטי עצור/נסה שוב את העבודה.
צלילה עמוקה במחסום
השמיים מחסום SageMaker תכונה מעתיקה את כל מה שאתה כותב עליו /opt/ml/checkpoints חזרה לאמזון S3 כ-URI המצוין ב- checkpoint_s3_uri פרמטר SDK. כאשר עבודה מתחילה או מתחילה מחדש, כל מה שנכתב באותו URI נשלח חזרה לכל המכונות, ב- /opt/ml/checkpoints. זה נוח אם אתה רוצה שלכל הצמתים תהיה גישה לכל המחסומים, אבל בקנה מידה - כשיש לך הרבה מכונות או הרבה מחסומים היסטוריים, זה יכול להוביל לזמני הורדה ארוכים ותעבורה גבוהה מדי באמזון S3. בנוסף, בקביליות טנזור וצנרת, העובדים זקוקים רק לחלק מהמודל המחסום, לא את כולו. אם אתה מתמודד עם מגבלות אלו, אנו ממליצים על האפשרויות הבאות:
- נקודת ביקורת ל-FSx עבור Luster - הודות ל-I/O אקראי בעל ביצועים גבוהים, אתה יכול להגדיר את סכימת הריסוק וייחוס הקבצים לבחירתך
- נקודת ביקורת בניהול עצמי של Amazon S3 – לדוגמאות של פונקציות Python שניתן להשתמש בהן כדי לשמור ולקרוא נקודות ביקורת בצורה לא חוסמת, עיין ב שמירת מחסומים
אנו ממליצים מאוד לבדוק את הדגם שלך כל כמה שעות, למשל 1-3 שעות, בהתאם לתקורה ולעלויות הקשורות.
ניהול חזית ומשתמשים
ניהול משתמשים הוא חוזק השימושיות העיקרי של SageMaker בהשוואה לתשתית HPC משותפת מדור קודם. הרשאות SageMaker Training נשלטות על ידי כמה AWS זהות וניהול גישה (IAM) הפשטות:
- מנהלים - משתמשים ומערכות - מקבלים הרשאה להשיק משאבים
- משרות הדרכה נושאות תפקידים בעצמם, המאפשרים להם לקבל הרשאות משלהם, למשל לגבי גישה לנתונים והזמנת שירות
בנוסף, בשנת 2022 הוספנו מנהל תפקידים של SageMaker כדי להקל על יצירת הרשאות מונחות אישיות.
סיכום
עם SageMaker Training, אתה יכול להפחית עלויות ולהגביר את מהירות האיטרציה בעומס העבודה שלך במודלים גדולים. תיעדנו סיפורי הצלחה במספר פוסטים ומקרי מקרים, כולל:
אם אתה מחפש לשפר את זמן היציאה לשוק של LLM תוך הפחתת העלויות שלך, עיין ב- SageMaker Training API וספר לנו מה אתה בונה!
תודה מיוחדת לעמר רגאב, רשיקה חריה, זמנקו אוראהמן, ארון נגארג'אן, גל אושרי על הביקורות והלימוד המועילות שלהם.
על הכותבים
 אנסטסיה צבלקה הוא ארכיטקט פתרונות מומחה למידת מכונה ו-AI ב-AWS. היא עובדת עם לקוחות ב-EMEA ועוזרת להם לתכנן פתרונות למידת מכונה בקנה מידה באמצעות שירותי AWS. היא עבדה על פרויקטים בתחומים שונים כולל עיבוד שפה טבעית (NLP), MLOps וכלי Low Code No Code.
אנסטסיה צבלקה הוא ארכיטקט פתרונות מומחה למידת מכונה ו-AI ב-AWS. היא עובדת עם לקוחות ב-EMEA ועוזרת להם לתכנן פתרונות למידת מכונה בקנה מידה באמצעות שירותי AWS. היא עבדה על פרויקטים בתחומים שונים כולל עיבוד שפה טבעית (NLP), MLOps וכלי Low Code No Code.
 גילי נחום הוא ארכיטקט פתרונות מומחה בינה מלאכותית/ML בכיר שעובד כחלק מצוות למידת מכונה של אמזון EMEA. גילי נלהב מהאתגרים של הכשרת מודלים של למידה עמוקה, וכיצד למידת מכונה משנה את העולם כפי שאנו מכירים אותו. בזמנו הפנוי גילי נהנה לשחק טניס שולחן.
גילי נחום הוא ארכיטקט פתרונות מומחה בינה מלאכותית/ML בכיר שעובד כחלק מצוות למידת מכונה של אמזון EMEA. גילי נלהב מהאתגרים של הכשרת מודלים של למידה עמוקה, וכיצד למידת מכונה משנה את העולם כפי שאנו מכירים אותו. בזמנו הפנוי גילי נהנה לשחק טניס שולחן.
 אוליבייה קרוצ'אנט הוא ארכיטקט פתרונות מומחה ללימוד מכונות ראשי ב-AWS, שבסיסו בצרפת. אוליבייה עוזרת ללקוחות AWS - החל מסטארט-אפים קטנים ועד ארגונים גדולים - לפתח ולפרוס יישומי למידת מכונה בדרגת ייצור. בזמנו הפנוי הוא נהנה לקרוא מאמרי מחקר ולחקור את השממה עם חברים ובני משפחה.
אוליבייה קרוצ'אנט הוא ארכיטקט פתרונות מומחה ללימוד מכונות ראשי ב-AWS, שבסיסו בצרפת. אוליבייה עוזרת ללקוחות AWS - החל מסטארט-אפים קטנים ועד ארגונים גדולים - לפתח ולפרוס יישומי למידת מכונה בדרגת ייצור. בזמנו הפנוי הוא נהנה לקרוא מאמרי מחקר ולחקור את השממה עם חברים ובני משפחה.
 ברונו פיסטון הוא אדריכל פתרונות AI/ML מומחה ל-AWS שבסיסו במילאנו. הוא עובד עם לקוחות בכל סדר גודל כדי לעזור להם להבין לעומק את הצרכים הטכניים שלהם ולתכנן פתרונות בינה מלאכותית ו-Machine Learning המנצלים את המיטב של AWS Cloud ו-Amazon Machine Learning. תחום המומחיות שלו הם Machine Learning מקצה לקצה, Machine Learning Industrialization ו-MLOps. הוא נהנה לבלות עם חבריו ולחקור מקומות חדשים, כמו גם לנסוע ליעדים חדשים.
ברונו פיסטון הוא אדריכל פתרונות AI/ML מומחה ל-AWS שבסיסו במילאנו. הוא עובד עם לקוחות בכל סדר גודל כדי לעזור להם להבין לעומק את הצרכים הטכניים שלהם ולתכנן פתרונות בינה מלאכותית ו-Machine Learning המנצלים את המיטב של AWS Cloud ו-Amazon Machine Learning. תחום המומחיות שלו הם Machine Learning מקצה לקצה, Machine Learning Industrialization ו-MLOps. הוא נהנה לבלות עם חבריו ולחקור מקומות חדשים, כמו גם לנסוע ליעדים חדשים.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/training-large-language-models-on-amazon-sagemaker-best-practices/
- :הוא
- ][עמ'
- $ למעלה
- 000
- 1
- 100
- 2022
- 7
- 8
- a
- A100
- יכולות
- יכול
- אודות
- מֵעַל
- להאיץ
- מוּאָץ
- גישה
- להתאים
- חֶשְׁבּוֹן
- להשיג
- השגתי
- לרוחב
- לפעול
- הפעלה
- פעיל
- להסתגל
- הוסיף
- תוספת
- בנוסף
- נוסף
- יתרון
- AI
- AI / ML
- AL
- אַלגוֹרִיתְם
- אלגוריתמים
- תעשיות
- מאפשר
- מאפשר
- אמזון בעברית
- אמזון
- אמזון FSx
- למידת מכונת אמזון
- אמזון SageMaker
- כמות
- ו
- API
- ממשקי API
- ישים
- בקשה
- יישומים
- יישומית
- מתאים
- ARE
- AREA
- סביב
- AS
- המשויך
- At
- מְצוֹרָף
- תכונות
- המכונית
- אוטומטי
- באופן אוטומטי
- זמין
- לְהִמָנַע
- הימנעות
- AWS
- בחזרה
- קצה אחורי
- איזון
- מבוסס
- BE
- כי
- הופך להיות
- לפני
- להיות
- תועלת
- הטוב ביותר
- שיטות עבודה מומלצות
- מעבר
- גָדוֹל
- B
- מיליארדים
- לחסום
- להביא
- מביא
- לִבנוֹת
- נבנה
- עסקים
- by
- שיחה
- נקרא
- שיחות
- CAN
- מסוגל
- קיבולת
- כרטיס
- כרטיסים
- לשאת
- מקרה
- מקרים לדוגמא
- מזרז
- האתגרים
- משתנה
- ערוץ
- לבדוק
- בדיקות
- בחירה
- בחירות
- בחרו
- כיתות
- לקוחות
- מקרוב
- ענן
- אשכול
- קוד
- קבוצתי
- משולב
- איך
- Common
- בדרך כלל
- תקשורת
- תקשורת
- לעומת
- תואם
- השלמה
- חישוב
- לחשב
- המחשב
- ראייה ממוחשבת
- מחשוב
- מסכם
- מנוהל
- תְצוּרָה
- לאשר
- לְחַבֵּר
- כתוצאה מכך
- מכולה
- מכולות
- מכיל
- תוכן
- תרם
- לִשְׁלוֹט
- נשלט
- נוֹחַ
- התכנסות
- שְׁחִיתוּת
- עלות
- עלויות
- יכול
- קורס
- לכסות
- מכסה
- CPU
- לִיצוֹר
- יצירה
- יְצִירָתִי
- קריטי
- מכריע
- אוצרות
- כיום
- מנהג
- לקוחות
- אישית
- נתונים
- גישה למידע
- הכנת נתונים
- מערכי נתונים
- להחליט
- מוקדש
- עמוק
- למידה עמוקה
- בְּרִירַת מֶחדָל
- תואר
- תלוי
- תלוי
- לפרוס
- עיצוב
- מעוצב
- יעדים
- לקבוע
- קביעה
- לפתח
- מפותח
- מפתח
- מפתחים
- צעצועי התפתחות
- מפתחת
- מכשיר
- התקנים
- אחר
- שידור
- ישירות
- לדון
- נָדוֹן
- מופץ
- מחשוב מבוזר
- הכשרה מבוזרת
- הפצה
- סַוָר
- מיכל דוקר
- לא
- תחומים
- לא
- מטה
- להורדה
- עשרות
- בְּמַהֲלָך
- כל אחד
- בקלות
- אפקטיבי
- או
- EMEA
- לאפשר
- מופעל
- מאפשר
- מה שמאפשר
- לעודד
- מסתיים
- משופר
- להנות
- מספיק
- לְהַבטִיחַ
- מִפְעָל
- חברות
- כניסה
- סביבה
- סביבות
- ציוד
- מְצוּיָד
- שגיאה
- שגיאות
- להקים
- Ether (ETH)
- אֲפִילוּ
- אירועים
- בסופו של דבר
- כל
- הכל
- התפתח
- דוגמה
- דוגמאות
- Excel
- קיימים
- לצפות
- צפוי
- ניסיון
- לְנַסוֹת
- היכרות
- חשוף
- ביטויים
- מאריך
- סיומות
- חיצוני
- מאוד
- בד
- פָּנִים
- לְהַקֵל
- הקלה
- גורמים
- נכשל
- נכשל
- כשלון
- משפחות
- משפחה
- אופנה
- מהר
- מהר יותר
- פגום
- אפשרי
- מאפיין
- תכונות
- מעטים
- שדה
- שלח
- קבצים
- ראשון
- מתאים
- צי
- גמישות
- להתמקד
- מתמקד
- בעקבות
- הבא
- בעד
- שבריר
- מסגרת
- מסגרות
- צרפת
- חופש
- תכוף
- טרי
- חברים
- החל מ-
- מלא
- לגמרי
- פונקציונלי
- פונקציונלי
- פונקציות
- נוסף
- GAL
- נוצר
- גנרטטיבית
- לקבל
- מקבל
- GitHub
- נתן
- GPU
- GPUs
- גרף
- גדול
- הגדול ביותר
- קְבוּצָה
- גדל
- לטפל
- טיפול
- לִתְלוֹת
- לקרות
- חומרה
- יש
- יש
- בְּרִיאוּת
- בריא
- מועיל
- עזרה
- עוזר
- גָבוֹהַ
- תדר גבוה
- ביצועים גבוהים
- היסטורי
- ברדס
- מארחים
- שעות
- איך
- איך
- אולם
- hpc
- HTML
- http
- HTTPS
- מאות
- מאות מיליונים
- i
- IAM
- זהה
- זהות
- תמונה
- תמונות
- מיד
- פְּגִיעָה
- ליישם
- יושם
- יישום
- חשוב
- לשפר
- משופר
- שיפורים
- in
- באחר
- לכלול
- כולל
- להגדיל
- גדל
- עליות
- יותר ויותר
- בנפרד
- תעשייה
- מידע
- מידע
- תשתית
- חדשנות
- השראה
- להתקין
- למשל
- במקום
- משולב
- השתלבות
- אינטליגנטי
- אינטראקציה
- מִמְשָׁק
- מתווך
- פנימי
- מבוא
- הציג
- IT
- איטרציה
- שֶׁלָה
- עצמו
- עבודה
- מקומות תעסוקה
- jpg
- שמור
- מפתח
- סוג
- לדעת
- שפה
- שפות
- גָדוֹל
- בקנה מידה גדול
- גדול יותר
- האחרון
- לשגר
- הושק
- השקות
- שכבה
- שכבות
- עוֹפֶרֶת
- מנהיג
- למידה
- מוֹרֶשֶׁת
- רמה
- ספריות
- סִפְרִיָה
- מעגל החיים
- כמו
- סביר
- להגביל
- מגבלות
- מוגבל
- קְצָת
- טוען
- מקומי
- ארוך
- הרבה זמן
- נראה
- הסתכלות
- נמוך
- מכונה
- למידת מכונה
- מכונת תרגום
- מכונה
- לתחזק
- שומר
- לעשות
- עושה
- עשייה
- לנהל
- הצליח
- ניהול
- רב
- מפות
- מקסימום
- זכרון
- מידע נוסף
- שיטות
- מדדים
- הֲגִירָה
- מילאן
- מיליונים
- לצמצם
- ML
- MLOps
- מצב
- מודל
- דוגמנות
- מודלים
- שונים
- צג
- ניטור
- יותר
- רוב
- המהלך
- מספר
- כלומר
- יליד
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- כמובן
- טבע
- בהכרח
- הכרחי
- צורך
- צרכי
- רשת
- מבוסס רשת
- רשתות
- עצביים
- רשת עצבית
- חדש
- NLP
- צומת
- צמתים
- מספר
- רב
- Nvidia
- אובייקטים
- of
- הַצָעָה
- הצעה
- זית
- on
- On-Demand
- ONE
- לפתוח
- קוד פתוח
- קוד קוד פתוח
- נפתח
- הזדמנויות
- אופטימיזציה
- מטב
- אופטימיזציה
- אפשרות
- אפשרויות
- תזמור
- להזמין
- אחר
- שֶׁלוֹ
- חבילה
- חבילות
- מאמר
- ניירות
- פרדיגמה
- מקביל
- פרמטר
- פרמטרים
- חלק
- מסוים
- במיוחד
- לוהט
- עבר
- נתיב
- דפוסי
- תשלום
- שִׂיא
- ביצועים
- הופעות
- רשות
- הרשאות
- פיזית
- צינור
- מקומות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- משחק
- נקודה
- בריכה
- ברכות
- פופולרי
- הודעה
- הודעות
- תרגול
- פרקטיקות
- ניבוי
- העדפות
- מועדף
- להציג
- מתנות
- למנוע
- קוֹדֶם
- מנהל
- תהליך
- תהליכים
- תהליך
- לייצר
- תָכְנִית
- תכנות
- שפות תכנות
- התקדמות
- פרויקטים
- כמו שצריך
- להציע
- מציע
- קניינית
- פרוטוקול
- פרוטוקולים
- לספק
- ובלבד
- ספק
- מתן
- ציבורי
- פרסומים
- מטרה
- גם
- פיתון
- פיטורך
- איכות
- להעלות
- אקראי
- נדיר
- ציון
- תעריפים
- הגיע
- חומר עיוני
- קריאה
- להבין
- סביר
- סיבות
- לקבל
- לאחרונה
- להמליץ
- המלצות
- שיא
- רשום
- התאוששות
- להפחית
- מפחית
- הפחתה
- בדבר
- באזור
- אזורים
- רגיל
- באופן קבוע
- קָשׁוּר
- רלוונטי
- אָמִין
- לסמוך
- מרחוק
- להחליף
- המייצג
- לבקש
- בקשות
- לדרוש
- דרישה
- דורש
- מחקר
- מחקר וחדשנות
- משאב
- משאבים
- תוצאות
- חוות דעת של לקוחותינו
- תפקיד
- תפקידים
- הפעלה
- ריצה
- בעל חכמים
- אותו
- שמור
- בקרת מערכות ותקשורת
- להרחבה
- סולם
- מאזניים
- דרוג
- תכנית
- מדענים
- היקף
- סקריפטים
- Sdk
- חיפוש
- שְׁנִיָה
- שניות
- סעיף
- מחפשים
- נבחר
- מבחר
- לחצני מצוקה לפנסיונרים
- לְחוּד
- ללא שרת
- שרתים
- שרות
- שירותים
- סט
- הגדרות
- כמה
- מגולף
- sharding
- משותף
- צריך
- באופן משמעותי
- פָּשׁוּט
- פשטות
- בו זמנית
- בו זמנית
- יחיד
- מידה
- גדל
- מיומנויות
- להאט
- קטן
- So
- תוכנה
- פתרונות
- כמה
- בקרוב
- מָקוֹר
- מקורות
- תַפטִיר
- מומחה
- ספציפי
- במיוחד
- מפורט
- מְהִירוּת
- הוצאה
- פיצולים
- מסחרי
- יציב
- לערום
- התחלה
- החל
- התחלות
- חברות סטארט
- מדינה
- סטטיסטי
- צעדים
- עצור
- סְתִימָה
- אחסון
- חנות
- סיפורים
- אִסטרָטֶגִיָה
- זרם
- זרמים
- כוח
- הפשטה
- בְּתוֹקֶף
- מחקרים
- הצלחה
- סיפורי הצלחה
- מוצלח
- כזה
- תמיכה
- נתמך
- תומך
- סִנכְּרוּן
- תחביר
- מערכת
- שולחן
- לקחת
- המשימות
- משימות
- נבחרת
- טכני
- תמיכה טכנית
- טֶנִיס
- tensorflow
- זֶה
- השמיים
- העולם
- שֶׁלָהֶם
- אותם
- עצמם
- תיאורטי
- לכן
- אלה
- צד שלישי
- אלפים
- שְׁלוֹשָׁה
- דרך
- תפוקה
- זמן
- פִּי
- טיפים
- ל
- היום
- מטבעות
- גַם
- כלי
- כלים
- חלק עליון
- סה"כ
- לעקוב
- תְנוּעָה
- רכבת
- מְאוּמָן
- הדרכה
- תרגום
- להעביר
- טרִילִיוֹן
- סוגים
- טיפוסי
- תחת
- בְּסִיסִי
- להבין
- ייחודי
- יחידות
- עדכון
- URI
- us
- שמישות
- נוֹהָג
- להשתמש
- משתמש
- בְּדֶרֶך כְּלַל
- ערך
- ערכים
- משתנים
- מגוון
- שונים
- לאמת
- גרסה
- באמצעות
- וִידֵאוֹ
- לצפיה
- חזון
- חם
- דֶרֶך..
- דרכים
- שבועות
- טוֹב
- מה
- אשר
- בזמן
- מי
- יצטרך
- עם
- בתוך
- לְלֹא
- מילים
- תיק עבודות
- עבד
- עובדים
- עובד
- עובד
- עוֹלָם
- לכתוב
- כתוב
- שנים
- עצמך
- YouTube
- זפירנט