אפאצ'י קרח הוא פורמט טבלה פתוח עבור מערכי נתונים אנליטיים גדולים מאוד, אשר לוכד מידע מטא נתונים על מצב מערכי הנתונים כפי שהם מתפתחים ומשתנים עם הזמן. הוא מוסיף טבלאות למנועי מחשוב כולל Spark, Trino, PrestoDB, Flink וכוורת באמצעות פורמט טבלה בעל ביצועים גבוהים שעובד בדיוק כמו טבלת SQL. Iceberg הפך לפופולרי מאוד בגלל התמיכה שלו בעסקאות ACID באגמי נתונים ותכונות כמו התפתחות סכימה ומחיצות, מסע בזמן והחזרה לאחור.
שילוב Apache Iceberg נתמך על ידי שירותי ניתוח AWS כולל אמזון EMR, אמזונה אתנה, ו דבק AWS. Amazon EMR יכולה לספק אשכולות עם Spark, Hive, Trino ו-Flink שיכולים להפעיל את Iceberg. החל מגרסה 6.5.0 של אמזון EMR, אתה יכול השתמש ב-Iceberg עם אשכול ה-EMR שלך ללא צורך בפעולת אתחול. בתחילת 2022, AWS הכריזה על זמינות כללית של עסקאות Athena ACID, המופעלות על ידי Apache Iceberg. זה שוחרר לאחרונה מנוע שאילתות אתנה גרסה 3 מספק אינטגרציה טובה יותר עם פורמט טבלת Iceberg. AWS Glue 3.0 ואילך תומך במסגרת Apache Iceberg עבור אגמי נתונים.
בפוסט זה, אנו דנים במה הלקוחות רוצים באגמי נתונים מודרניים וכיצד Apache Iceberg עוזר לתת מענה לצרכי הלקוחות. לאחר מכן נעבור על פתרון לבניית אגם נתונים של Iceberg בעל ביצועים גבוהים ומתפתח שירות אחסון פשוט של אמזון (Amazon S3) ועבד נתונים מצטברים על ידי הפעלת הוספה, עדכון ומחיקה של הצהרות SQL. לבסוף, אנו מראים לך כיצד לכוון את הביצועים לתהליך כדי לשפר את ביצועי הקריאה והכתיבה.
איך Apache Iceberg מתייחס למה שהלקוחות רוצים באגמי נתונים מודרניים
יותר ויותר לקוחות בונים אגמי נתונים, עם נתונים מובנים ולא מובנים, כדי לתמוך במשתמשים, אפליקציות וכלי ניתוח רבים. יש צורך מוגבר באגמי נתונים כדי לתמוך במסד נתונים כמו תכונות כגון עסקאות ACID, עדכונים ומחיקות ברמת שיא, נסיעות בזמן והחזרה לאחור. Apache Iceberg נועד לתמוך בתכונות אלה באגמי נתונים חסכוניים בקנה מידה פטה-בייט ב-Amazon S3.
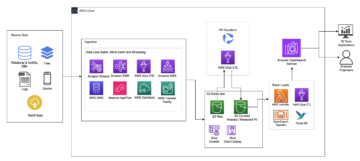
Apache Iceberg נותן מענה לצרכי הלקוח על ידי לכידת מידע עשיר של מטא נתונים על מערך הנתונים בזמן יצירת קובצי הנתונים הבודדים. ישנן שלוש שכבות בארכיטקטורה של טבלת אייסברג: קטלוג אייסברג, שכבת המטא נתונים ושכבת הנתונים, כפי שמתואר באיור הבא (מָקוֹר).

קטלוג Iceberg מאחסן את מצביע המטא נתונים לקובץ המטא נתונים הנוכחי של הטבלה. כאשר שאילתת בחירה קוראת טבלת Iceberg, מנוע השאילתה עובר תחילה לקטלוג Iceberg, ולאחר מכן מאחזר את המיקום של קובץ המטא נתונים הנוכחי. בכל פעם שיש עדכון לטבלת Iceberg, נוצרת תמונת מצב חדשה של הטבלה, ומצביע המטא נתונים מצביע על קובץ המטא נתונים הנוכחי של הטבלה.
להלן דוגמה לקטלוג Iceberg עם יישום AWS Glue. אתה יכול לראות את שם מסד הנתונים, המיקום (נתיב S3) של טבלת Iceberg ומיקום המטא נתונים.

לשכבת המטא נתונים יש שלושה סוגים של קבצים: קובץ המטא נתונים, רשימת המניפסטים וקובץ המניפסט בהיררכיה. בראש ההיררכיה נמצא קובץ המטא נתונים, המאחסן מידע על הסכימה של הטבלה, מידע על מחיצות ותצלומי מצב. תמונת המצב מצביעה על רשימת המניפסט. רשימת המניפסט מכילה את המידע על כל קובץ מניפסט המרכיב את תמונת המצב, כגון מיקום קובץ המניפסט, המחיצות אליהן הוא שייך והגבול התחתון והעליון לעמודות המחיצות עבור קבצי הנתונים שאחריהם הוא עוקב. קובץ המניפסט עוקב אחר קבצי נתונים וכן פרטים נוספים על כל קובץ, כגון פורמט הקובץ. כל שלושת הקבצים פועלים בהיררכיה כדי לעקוב אחר התמונות, הסכימה, החלוקה, המאפיינים וקבצי הנתונים בטבלת Iceberg.
לשכבת הנתונים יש את קבצי הנתונים הבודדים של טבלת Iceberg. Iceberg תומך במגוון רחב של פורמטים של קבצים כולל פרקט, ORC ו-Avro. מכיוון שטבלת Iceberg עוקבת אחר קבצי הנתונים הבודדים במקום להצביע רק על מיקום המחיצה עם קבצי נתונים, היא מבודדת את פעולות הכתיבה מפעולות קריאה. אתה יכול לכתוב את קבצי הנתונים בכל עת, אך רק לבצע את השינוי במפורש, מה שיוצר גרסה חדשה של קבצי תמונת המצב ושל המטא נתונים.
סקירת פתרונות
בפוסט זה, אנו מדריכים אותך דרך פתרון לבניית אגם נתונים Apache Iceberg בעל ביצועים גבוהים ב-Amazon S3; עיבוד נתונים מצטברים עם הוספה, עדכון ומחיקה של הצהרות SQL; וכוונו את טבלת Iceberg כדי לשפר את ביצועי הקריאה והכתיבה. התרשים הבא ממחיש את ארכיטקטורת הפתרון.

כדי להדגים פתרון זה, אנו משתמשים ב- ביקורות לקוחות של אמזון מערך נתונים בדלי S3 (s3://amazon-reviews-pds/parquet/). במקרה של שימוש אמיתי, זה יהיה נתונים גולמיים המאוחסנים בדלי S3 שלך. אנחנו יכולים לבדוק את גודל הנתונים עם הקוד הבא ב- ממשק שורת הפקודה של AWS (AWS CLI):
ספירת האובייקטים הכוללת היא 430, והגודל הכולל הוא 47.4 GiB.
כדי להגדיר ולבדוק פתרון זה, אנו משלימים את השלבים הבאים ברמה גבוהה:
- הגדר דלי S3 באזור שנאסף כדי לאחסן נתונים שהומרו בפורמט טבלת Iceberg.
- הפעל אשכול EMR עם תצורות מתאימות עבור Apache Iceberg.
- צור מחברת ב-EMR Studio.
- הגדר את הפעלת Spark עבור Apache Iceberg.
- המר נתונים לפורמט טבלת Iceberg והעבר נתונים לאזור שנאסף.
- הפעל הוספה, עדכון ומחיקה של שאילתות ב- Athena כדי לעבד נתונים מצטברים.
- בצע כוונון ביצועים.
תנאים מוקדמים
כדי לעקוב אחר ההדרכה הזו, עליך להיות בעל חשבון AWS עם AWS זהות וניהול גישה תפקיד (IAM) בעל גישה מספקת כדי לספק את המשאבים הנדרשים.
הגדר את דלי S3 לנתוני Iceberg באזור שנאסף באגם הנתונים שלך
בחר את האזור שבו ברצונך ליצור את דלי S3 וספק שם ייחודי:
הפעל אשכול EMR כדי להפעיל עבודות Iceberg באמצעות Spark
אתה יכול ליצור אשכול EMR מתוך קונסולת הניהול של AWS, Amazon EMR CLI, או ערכת פיתוח ענן AWS (AWS CDK). עבור פוסט זה, אנו מדריכים אותך כיצד ליצור אשכול EMR מהמסוף.
- בקונסולת אמזון EMR, בחר צור אשכול.
- לבחור אפשרויות מתקדמות.
- בעד תצורת תוכנה, בחר את המהדורה האחרונה של Amazon EMR. החל מינואר 2023, המהדורה האחרונה היא 6.9.0. Iceberg דורש גרסה 6.5.0 ומעלה.
- בחר JupyterEnterpriseGateway ו לעורר בתור התוכנה להתקנה.
- בעד ערוך את הגדרות התוכנה, בחר הכנס לתצורה והזן
[{"classification":"iceberg-defaults","properties":{"iceberg.enabled":true}}]. - השאר הגדרות אחרות כברירת מחדל ובחר הַבָּא.

- בעד חומרה, השתמש בהגדרת ברירת המחדל.
- לבחור הַבָּא.
- בעד שם אשכול, הכנס שם. אנו משתמשים
iceberg-blog-cluster. - השאר את שאר ההגדרות ללא שינוי ובחר הַבָּא.
- לבחור צור אשכול.
צור מחברת ב-EMR Studio
כעת אנו מדריכים אותך כיצד ליצור מחברת ב-EMR Studio מהמסוף.
- במסוף IAM, ליצור תפקיד שירות EMR Studio.
- בקונסולת אמזון EMR, בחר סטודיו EMR.
- לבחור התחל כאן.
אל האני התחל כאן הדף מופיע בכרטיסייה חדשה.
- לבחור צור סטודיו בכרטיסייה החדשה.
- הכנס שם. אנחנו משתמשים ב-Iceberg-studio.
- בחר את אותה VPC ורשת משנה כמו אלה עבור אשכול EMR, ואת קבוצת האבטחה המוגדרת כברירת מחדל.
- לבחור AWS זהות וניהול גישה (IAM) לאימות, ובחר בתפקיד שירות EMR Studio שיצרת זה עתה.
- בחר נתיב S3 עבור גיבוי סביבות עבודה.
- לבחור צור סטודיו.
- לאחר יצירת הסטודיו, בחר את כתובת האתר של הגישה לסטודיו.
- בלוח המחוונים של EMR Studio, בחר צור סביבת עבודה.
- הזן שם עבור סביבת העבודה שלך. אנו משתמשים
iceberg-workspace. - לְהַרְחִיב תצורה מתקדמת ולבחור צרף סביבת עבודה לאשכול EMR.
- בחר את אשכול ה-EMR שיצרת קודם לכן.
- לבחור צור סביבת עבודה.
- בחר את שם סביבת העבודה כדי לפתוח כרטיסייה חדשה.
בחלונית הניווט, ישנה מחברת בעלת שם זהה ל- Workspace. במקרה שלנו, זה אזור עבודה של קרחון.
- פתח את המחברת.
- כאשר תתבקש לבחור ליבה, בחר לעורר.
הגדר הפעלת Spark עבור Apache Iceberg
השתמש בקוד הבא, ספק שם דלי S3 משלך:
זה מגדיר את תצורות ההפעלה הבאות של Spark:
- spark.sql.catalog.demo – רושם קטלוג Spark בשם הדגמה, המשתמש בתוסף הקטלוג של Iceberg Spark.
- spark.sql.catalog.demo.catalog-impl – קטלוג ההדגמה של Spark משתמש ב-AWS Glue כקטלוג הפיזי לאחסון מסד הנתונים והטבלה של Iceberg.
- spark.sql.catalog.demo.warehouse – קטלוג ההדגמה של Spark מאחסן את כל המטא נתונים וקבצי הנתונים של Iceberg תחת נתיב השורש שהוגדר על ידי מאפיין זה:
s3://iceberg-curated-blog-data. - spark.sql.extensions – מוסיף תמיכה להרחבות של Iceberg Spark SQL, המאפשר לך להפעיל נהלי Iceberg Spark וכמה פקודות SQL של Iceberg בלבד (תוכל להשתמש בזה בשלב מאוחר יותר).
- spark.sql.catalog.demo.io-impl – Iceberg מאפשר למשתמשים לכתוב נתונים לאמזון S3 דרך S3FileIO. ה-AWS Glue Data Catalog כברירת מחדל משתמש ב-FileIO זה, וקטלוגים אחרים יכולים לטעון את FileIO זה באמצעות מאפיין הקטלוג io-impl.
המרת נתונים לפורמט טבלת אייסברג
אתה יכול להשתמש ב- Spark ב- Amazon EMR או ב- Athena כדי לטעון את טבלת Iceberg. בהפעלת Spark מחברת EMR Studio Workspace, הפעל את הפקודות הבאות כדי לטעון את הנתונים:
לאחר הפעלת הקוד, אתה אמור למצוא שתי קידומות שנוצרו בנתיב S3 של מחסן הנתונים שלך (s3://iceberg-curated-blog-data/reviews.db/all_reviews): נתונים ומטא נתונים.
עבד נתונים מצטברים באמצעות הוספה, עדכון ומחיקה של הצהרות SQL באתנה
Athena הוא מנוע שאילתות ללא שרת שבו אתה יכול להשתמש כדי לבצע משימות קריאה, כתיבה, עדכון ואופטימיזציה מול טבלאות Iceberg. כדי להדגים כיצד פורמט אגם הנתונים של Apache Iceberg תומך בהטמעת נתונים מצטברת, אנו מפעילים הוספה, עדכון ומחיקה של הצהרות SQL באגם הנתונים.
נווט אל מסוף Athena ובחר עורך שאילתות. אם זו הפעם הראשונה שאתה משתמש בעורך השאילתות של Athena, עליך לעשות זאת הגדר את מיקום תוצאת השאילתה להיות דלי S3 שיצרת קודם לכן. אתה אמור להיות מסוגל לראות שהטבלה reviews.all_reviews זמינה לשאילתה. הפעל את השאילתה הבאה כדי לוודא שטעינת את טבלת Iceberg בהצלחה:
עבד נתונים מצטברים על ידי הפעלת הוספה, עדכון ומחיקה של הצהרות SQL:
כוונון ביצועים
בחלק זה, אנו עוברים על דרכים שונות לשיפור ביצועי הקריאה והכתיבה של Apache Iceberg.
הגדר את מאפייני טבלת Apache Iceberg
Apache Iceberg הוא פורמט טבלה, והוא תומך במאפייני טבלה כדי להגדיר התנהגות טבלה כגון קריאה, כתיבה וקטלוג. ניתן לשפר את ביצועי הקריאה והכתיבה בטבלאות Iceberg על ידי התאמת מאפייני הטבלה.
לדוגמה, אם אתה מבחין שאתה כותב יותר מדי קבצים קטנים עבור טבלת Iceberg, אתה יכול להגדיר את גודל הקובץ לכתוב פחות קבצים אך בגודל גדול יותר, כדי לעזור לשפר את ביצועי השאילתות.
| נכס | בְּרִירַת מֶחדָל | תיאור |
| write.target-file-size-bytes | 536870912 (512 MB) | שולט בגודל הקבצים שנוצרו כדי למקד בערך בתים רבים כל כך |
השתמש בקוד הבא כדי לשנות את פורמט הטבלה:
חלוקה ומיון
כדי לגרום לשאילתה לרוץ מהר, ככל שפחות נתונים יקראו כך ייטב. Iceberg מנצל את המטא נתונים העשירים שהוא לוכד בזמן הכתיבה ומקל על טכניקות כגון תכנון סריקה, חלוקה למחיצות, חיתוך וסטטיסטיקות ברמת העמודה כגון ערכי מינימום/מקסימום כדי לדלג על קבצי נתונים שאין להם רשומות התאמה. אנו מדריכים אותך כיצד פועלים תכנון סריקת שאילתות וחלוקת מחיצות ב-Iceberg וכיצד אנו משתמשים בהם כדי לשפר את ביצועי השאילתות.
תכנון סריקת שאילתות
עבור שאילתה נתונה, השלב הראשון במנוע שאילתות הוא תכנון סריקה, שהוא התהליך למציאת הקבצים בטבלה הדרושים לשאילתה. תכנון בטבלת Iceberg הוא יעיל מאוד, מכיוון שניתן להשתמש במטא-נתונים העשירים של Iceberg כדי לגזום קבצי מטא-נתונים שאינם נחוצים, בנוסף לסינון קבצי נתונים שאינם מכילים נתונים תואמים. בבדיקות שלנו, צפינו באתנה סורקת 50% או פחות נתונים עבור שאילתה נתונה בטבלת Iceberg בהשוואה לנתונים המקוריים לפני המרה לפורמט Iceberg.
ישנם שני סוגי סינון:
- סינון מטא נתונים – Iceberg משתמש בשתי רמות של מטא נתונים כדי לעקוב אחר הקבצים בתמונת מצב: רשימת המניפסט וקובצי המניפסט. תחילה הוא משתמש ברשימת המניפסט, הפועלת כאינדקס של קבצי המניפסט. במהלך התכנון, Iceberg מסנן מניפסטים באמצעות טווח ערכי המחיצות ברשימת המניפסט מבלי לקרוא את כל קבצי המניפסט. לאחר מכן הוא משתמש בקבצי מניפסט נבחרים כדי לקבל קבצי נתונים.
- סינון נתונים – לאחר בחירת רשימת קבצי המניפסט, Iceberg משתמש בנתוני המחיצה ובנתונים הסטטיסטיים ברמת העמודה עבור כל קובץ נתונים המאוחסן בקובצי מניפסט כדי לסנן קבצי נתונים. במהלך התכנון, פרדיקטים של שאילתות מומרים לפרדיקטים על נתוני המחיצה ומוחלים תחילה על סינון קבצי נתונים. לאחר מכן, הנתונים הסטטיסטיים של העמודות כמו ספירת ערכים ברמת העמודה, ספירת אפס, גבולות תחתונים וגבולות עליונים משמשים לסינון קבצי נתונים שאינם יכולים להתאים לפרדיקט השאילתה. על ידי שימוש בגבולות עליונים ותחתונים לסינון קבצי נתונים בזמן התכנון, Iceberg משפר מאוד את ביצועי השאילתות.
חלוקה ומיון
חלוקה למחיצות היא דרך לקבץ רשומות עם אותם ערכי עמודות מפתח יחד בכתב. היתרון של חלוקה למחיצות הוא שאילתות מהירות יותר הניגשות רק לחלק מהנתונים, כפי שהוסבר קודם לכן בתכנון סריקת שאילתות: סינון נתונים. Iceberg הופך את החלוקה לפשוטה על ידי תמיכה בחלוקה נסתרת, באופן שבו Iceberg מייצר ערכי מחיצה על ידי לקיחת ערך עמודה והפיכתו באופן אופציונלי.
במקרה השימוש שלנו, אנו מריצים תחילה את השאילתה הבאה בטבלת Iceberg לא מחולקת. לאחר מכן אנו מחלקים את טבלת Iceberg לפי קטגוריית הביקורות, אשר ישמשו בתנאי השאילתה WHERE כדי לסנן רשומות. עם חלוקה למחיצות, השאילתה יכולה לסרוק הרבה פחות נתונים. ראה את הקוד הבא:
הפעל את משפט הבחירה הבא בטבלת all_reviews שאינה מחולקת לעומת הטבלה המחולקת כדי לראות את ההבדל בביצועים:
הטבלה הבאה מציגה את שיפור הביצועים של חלוקת נתונים, עם כ-50% שיפור בביצועים ו-70% פחות נתונים שנסרקו.
| שם מערך הנתונים | ערכת נתונים לא מחולקת | ערכת נתונים מחולקת |
| זמן ריצה (שניות) | 8.20 | 4.25 |
| נתונים סרוקים (MB) | 131.55 | 33.79 |
שימו לב שזמן הריצה הוא זמן הריצה הממוצע עם ריצות מרובות בבדיקה שלנו.
ראינו שיפור ביצועים טוב לאחר החלוקה. עם זאת, ניתן לשפר זאת עוד יותר על ידי שימוש בסטטיסטיקה ברמת העמודה מקובצי מניפסט של Iceberg. כדי להשתמש ביעילות בסטטיסטיקה ברמת העמודה, אתה רוצה למיין את הרשומות שלך על סמך דפוסי השאילתה. מיון כל מערך הנתונים באמצעות העמודות המשמשות לעתים קרובות בשאילתות יסדר מחדש את הנתונים באופן שכל קובץ נתונים יסתיים בטווח ייחודי של ערכים עבור העמודות הספציפיות. אם נעשה שימוש בעמודות אלו במצב השאילתה, זה מאפשר למנועי שאילתות לדלג עוד יותר על קבצי נתונים, ובכך לאפשר שאילתות מהירות אף יותר.
העתקה על כתיבה לעומת קריאה על מיזוג
בעת יישום עדכון ומחיקה בטבלאות Iceberg באגם הנתונים, ישנן שתי גישות המוגדרות על ידי מאפייני טבלת Iceberg:
- העתק על כתיבה - בגישה זו, כאשר יש שינויים בטבלת Iceberg, עדכונים או מחיקות, קבצי הנתונים המשויכים לרשומות המושפעות ישוכפלו ויעודכנו. הרשומות יעודכנו או יימחקו מקובצי הנתונים המשוכפלים. תיווצר תמונת מצב חדשה של טבלת Iceberg ותצביע על הגרסה החדשה יותר של קבצי נתונים. זה הופך את הכתיבה הכללית לאטית יותר. ייתכנו מצבים שבהם יש צורך בכתיבה במקביל עם התנגשויות ולכן יש צורך לנסות שוב, מה שמגדיל את זמן הכתיבה עוד יותר. מצד שני, בעת קריאת הנתונים, אין צורך בתהליך נוסף. השאילתה תאחזר נתונים מהגרסה העדכנית ביותר של קבצי נתונים.
- מיזוג על קריאה – בגישה זו, כאשר יש עדכונים או מחיקות בטבלת Iceberg, קבצי הנתונים הקיימים לא ייכתבו מחדש; במקום זאת יווצרו קבצי מחיקה חדשים כדי לעקוב אחר השינויים. עבור מחיקות, ייווצר קובץ מחיקה חדש עם הרשומות שנמחקו. בעת קריאת טבלת Iceberg, קובץ המחיקה יוחל על הנתונים שאוחזרו כדי לסנן את רשומות המחיקה. עבור עדכונים, ייווצר קובץ מחיקה חדש כדי לסמן את הרשומות המעודכנות כמוחקות. לאחר מכן ייווצר קובץ חדש עבור הרשומות הללו אך עם ערכים מעודכנים. בעת קריאת טבלת Iceberg, הן המחיקה והן הקבצים החדשים יוחלו על הנתונים שאוחזרו כדי לשקף את השינויים האחרונים ולהפיק את התוצאות הנכונות. לכן, עבור כל שאילתות עוקבות, יתרחש שלב נוסף למיזוג קבצי הנתונים עם המחיקה והקבצים החדשים, מה שבדרך כלל יגדיל את זמן השאילתה. מצד שני, הכתיבה עשויה להיות מהירה יותר מכיוון שאין צורך לשכתב את קבצי הנתונים הקיימים.
כדי לבדוק את ההשפעה של שתי הגישות, אתה יכול להפעיל את הקוד הבא כדי להגדיר את מאפייני טבלת Iceberg:
הפעל את העדכון, מחק ובחר במשפטי SQL ב- Athena כדי להציג את ההבדל בזמן הריצה עבור העתקה על כתיבה לעומת מיזוג על קריאה:
הטבלה הבאה מסכמת את זמני הריצה של השאילתה.
| שאלה | העתק-על-כתיבה | מיזוג-על-קריאה | ||||
| עדכון | למחוק | לבחור | עדכון | למחוק | לבחור | |
| זמן ריצה (שניות) | 66.251 | 116.174 | 97.75 | 10.788 | 54.941 | 113.44 |
| נתונים שנסרקו (MB) | 494.06 | 3.07 | 137.16 | 494.06 | 3.07 | 137.16 |
שימו לב שזמן הריצה הוא זמן הריצה הממוצע עם ריצות מרובות בבדיקה שלנו.
כפי שמראות תוצאות הבדיקה שלנו, תמיד יש פשרות בשתי הגישות. איזו גישה להשתמש תלויה במקרים השימוש שלך. לסיכום, השיקולים מסתכמים בהשהייה בקריאה לעומת כתיבה. אתה יכול להפנות לטבלה הבאה ולבצע את הבחירה הנכונה.
| . | העתק-על-כתיבה | מיזוג-על-קריאה |
| Pros | קריאה מהירה יותר | כותב מהר יותר |
| חסרונות | כותב יקר | זמן אחזור גבוה יותר בקריאה |
| מתי להשתמש | טוב לקריאה תכופה, עדכונים ומחיקות נדירות או עדכוני אצווה גדולים | טוב לטבלאות עם עדכונים ומחיקות תכופים |
דחיסת נתונים
אם גודל קובץ הנתונים שלך קטן, אתה עלול לקבל אלפי או מיליוני קבצים בטבלת Iceberg. זה מגדיל באופן דרמטי את פעולת ה-I/O ומאט את השאילתות. יתר על כן, Iceberg עוקב אחר כל קובץ נתונים במערך נתונים. יותר קבצי נתונים מובילים ליותר מטא נתונים. זה בתורו מגדיל את התקורה ואת פעולת ה-I/O בקריאת קבצי מטא נתונים. על מנת לשפר את ביצועי השאילתה, מומלץ לדחוס קבצי נתונים קטנים לקבצי נתונים גדולים יותר.
בעת עדכון ומחיקה של רשומות בטבלת Iceberg, אם נעשה שימוש בגישת קריאה-על-מיזוג, ייתכן שתגמור עם מחיקות קטנות רבות או קבצי נתונים חדשים. הפעלת הדחיסה תשלב את כל הקבצים הללו ותיצור גרסה חדשה יותר של קובץ הנתונים. זה מבטל את הצורך ליישב אותם במהלך הקריאה. מומלץ לבצע עבודות דחיסה רגילות כדי להשפיע על הקריאה כמה שפחות, תוך שמירה על מהירות כתיבה מהירה יותר.
הפעל את פקודת דחיסת הנתונים הבאה, ולאחר מכן הפעל את שאילתת הבחירה מאתנה:
הטבלה הבאה משווה את זמן הריצה לפני דחיסת נתונים לעומת לאחר דחיסה. אתה יכול לראות כ-40% שיפור בביצועים.
| שאלה | לפני דחיסת נתונים | לאחר דחיסת נתונים |
| זמן ריצה (שניות) | 97.75 | 32.676 שניות |
| נתונים שנסרקו (MB) | 137.16 מ' דולר | 189.19 מ' דולר |
שימו לב ששאילתות הבחירה רצו ב- all_reviews טבלה לאחר פעולות עדכון ומחיקה, לפני ואחרי דחיסת הנתונים. זמן הריצה הוא זמן הריצה הממוצע עם ריצות מרובות בבדיקה שלנו.
לנקות את
לאחר שתבצע את ההליכה לפתרון לביצוע מקרי השימוש, השלם את השלבים הבאים כדי לנקות את המשאבים שלך ולהימנע מעלויות נוספות:
- שחרר את טבלאות AWS Glue ומסד הנתונים מאתנה או הפעל את הקוד הבא במחברת שלך:
- במסוף EMR Studio, בחר סביבות עבודה בחלונית הניווט.
- בחר את סביבת העבודה שיצרת ובחר מחק.
- במסוף ה-EMR, נווט אל אולפני עמוד.
- בחר את הסטודיו שיצרת ובחר מחק.
- במסוף ה-EMR, בחר אשכולות בחלונית הניווט.
- בחר את האשכול ובחר לבטל, לסיים.
- מחק את דלי S3 וכל משאבים אחרים שיצרת כחלק מהדרישות המוקדמות לפוסט זה.
סיכום
בפוסט זה, הצגנו את מסגרת Apache Iceberg וכיצד היא עוזרת לפתור כמה מהאתגרים שיש לנו באגם נתונים מודרני. אחר כך הצענו לך פתרון לעיבוד נתונים מצטברים באגם נתונים באמצעות Apache Iceberg. לבסוף, עשינו צלילה עמוקה לכוונון ביצועים כדי לשפר את ביצועי הקריאה והכתיבה עבור מקרי השימוש שלנו.
אנו מקווים שהפוסט הזה מספק מידע שימושי כדי להחליט אם ברצונך לאמץ את Apache Iceberg בפתרון אגם הנתונים שלך.
על הכותבים
 פלורה וו הוא אדריכל תושב אב במעבדת הנתונים של AWS. היא עוזרת ללקוחות ארגוניים ליצור אסטרטגיות לניתוח נתונים ולבנות פתרונות כדי להאיץ את התוצאות העסקיות שלהם. בזמנה הפנוי היא נהנית לשחק טניס, לרקוד סלסה ולטייל.
פלורה וו הוא אדריכל תושב אב במעבדת הנתונים של AWS. היא עוזרת ללקוחות ארגוניים ליצור אסטרטגיות לניתוח נתונים ולבנות פתרונות כדי להאיץ את התוצאות העסקיות שלהם. בזמנה הפנוי היא נהנית לשחק טניס, לרקוד סלסה ולטייל.
 דניאל לי הוא Sr. Solutions Architect בשירותי האינטרנט של אמזון. הוא מתמקד בסיוע ללקוחות לפתח, לאמץ ולהטמיע שירותי ענן ואסטרטגיה. כשהוא לא עובד, הוא אוהב לבלות בחוץ עם משפחתו.
דניאל לי הוא Sr. Solutions Architect בשירותי האינטרנט של אמזון. הוא מתמקד בסיוע ללקוחות לפתח, לאמץ ולהטמיע שירותי ענן ואסטרטגיה. כשהוא לא עובד, הוא אוהב לבלות בחוץ עם משפחתו.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/use-apache-iceberg-in-a-data-lake-to-support-incremental-data-processing/
- 10
- 100
- 11
- 2022
- 2023
- 7
- 9
- a
- יכול
- אודות
- מֵעַל
- להאיץ
- גישה
- ניהול גישה
- פעולה
- מעשים
- תוספת
- נוסף
- כתובת
- כתובות
- מוסיף
- לְאַמֵץ
- יתרון
- לאחר
- נגד
- תעשיות
- מאפשר
- תמיד
- אמזון בעברית
- אמזון EMR
- אמזון שירותי אינטרנט
- אנליטי
- ניתוח
- ו
- הודיע
- אַפָּשׁ
- יישומים
- יישומית
- גישה
- גישות
- מתאים
- ארכיטקטורה
- המשויך
- אימות
- זמינות
- זמין
- מְמוּצָע
- לְהִמָנַע
- AWS
- דבק AWS
- מבוסס
- כי
- להיות
- לפני
- תועלת
- מוטב
- בֵּין
- גדול
- אוזן נעל
- לִבנוֹת
- בִּניָן
- עסקים
- לוכדת
- לכידה
- מקרה
- מקרים
- קטלוג
- קטלוגים
- קטגוריה
- האתגרים
- שינוי
- שינויים
- לבדוק
- בחירה
- לבחור
- מיון
- ענן
- שירותי ענן
- אשכול
- קוד
- טור
- עמודות
- לשלב
- איך
- לבצע
- לעומת
- להשלים
- לחשב
- במקביל
- מצב
- תצורות
- שיקולים
- קונסול
- המרה
- הומר
- עלות תועלת
- עלויות
- יכול
- לִיצוֹר
- נוצר
- יוצר
- אוצר
- נוֹכְחִי
- לקוח
- לקוחות
- רוקד
- לוח מחוונים
- נתונים
- ניתוח נתונים
- אגם דאטה
- עיבוד נתונים
- מחסן נתונים
- מסד נתונים
- מערכי נתונים
- עמוק
- צלילה לעומק
- בְּרִירַת מֶחדָל
- מוגדר
- הַדגָמָה
- להפגין
- תלוי
- מעוצב
- פרטים
- לפתח
- צעצועי התפתחות
- הבדל
- אחר
- לדון
- לא
- מטה
- באופן דרמטי
- ירידה
- בְּמַהֲלָך
- כל אחד
- מוקדם יותר
- מוקדם
- עורך
- יעילות
- יעיל
- או
- מבטל
- מופעל
- מה שמאפשר
- מסתיים
- מנוע
- מנועים
- זן
- מִפְעָל
- לקוחות ארגוניים
- Ether (ETH)
- אֲפִילוּ
- אבולוציה
- להתפתח
- מתפתח
- דוגמה
- קיימים
- קיים
- מוסבר
- סיומות
- נוסף
- מקל
- משפחה
- מהר
- מהר יותר
- תכונות
- תרשים
- שלח
- קבצים
- לסנן
- סינון
- מסננים
- בסופו של דבר
- ראשון
- firsttime
- מתמקד
- לעקוב
- הבא
- פוּרמָט
- מסגרת
- תכוף
- החל מ-
- נוסף
- יתר על כן
- כללי
- נוצר
- לקבל
- נתן
- Goes
- טוב
- מאוד
- קְבוּצָה
- יד
- לקרות
- לעזור
- עזרה
- עוזר
- מוּסתָר
- היררכיה
- ברמה גבוהה
- ביצועים גבוהים
- ביצועים גבוהים
- כוורת
- לקוות
- איך
- איך
- אולם
- HTML
- HTTPS
- IAM
- זהות
- ניהול זהות וגישה
- פְּגִיעָה
- מושפעים
- ליישם
- הפעלה
- יישום
- לשפר
- משופר
- השבחה
- משפר
- in
- כולל
- להגדיל
- גדל
- עליות
- מדד
- בנפרד
- מידע
- להתקין
- במקום
- השתלבות
- הציג
- מבודד
- IT
- יָנוּאָר
- מקומות תעסוקה
- מפתח
- מעבדה
- אגם
- גָדוֹל
- גדול יותר
- חֶבִיוֹן
- האחרון
- המהדורה האחרונה
- שכבה
- שכבות
- עוֹפֶרֶת
- רמות
- להגביל
- קו
- רשימה
- קְצָת
- לִטעוֹן
- מיקום
- לעשות
- עושה
- ניהול
- רב
- סימן
- שוק
- להתאים
- תואם
- למזג
- מידע נוסף
- יכול
- מיליונים
- מודרני
- יותר
- המהלך
- מספר
- שם
- שם
- נווט
- ניווט
- צורך
- נחוץ
- צרכי
- חדש
- מחברה
- אובייקט
- לפתוח
- מבצע
- תפעול
- אופטימיזציה
- מטב
- להזמין
- מְקוֹרִי
- אחר
- בחוץ
- מקיף
- שֶׁלוֹ
- זגוגית
- חלק
- נתיב
- דפוסי
- לבצע
- ביצועים
- גופני
- תכנון
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- משחק
- חיבור
- נקודות
- פופולרי
- אפשרי
- הודעה
- מופעל
- תנאים מוקדמים
- נהלים
- תהליך
- תהליך
- לייצר
- נכסים
- רכוש
- לספק
- מספק
- מתן
- אַספָּקָה
- רכס
- חי
- נתונים גולמיים
- חומר עיוני
- קריאה
- ממשי
- לאחרונה
- מוּמלָץ
- רשום
- לשקף
- באזור
- רושמים
- רגיל
- לשחרר
- שוחרר
- נותר
- נדרש
- דורש
- משאבים
- תוצאה
- תוצאות
- חוות דעת של לקוחותינו
- עשיר
- תפקיד
- שורש
- הפעלה
- ריצה
- אותו
- סריקה
- שניות
- סעיף
- אבטחה
- נבחר
- בחירה
- ללא שרת
- שרות
- שירותים
- מושב
- סט
- סטים
- הצבה
- הגדרות
- צריך
- לְהַצִיג
- הופעות
- פָּשׁוּט
- מצבים
- מידה
- מאט
- קטן
- תמונת בזק
- So
- תוכנה
- פִּתָרוֹן
- פתרונות
- כמה
- לעורר
- ספציפי
- מְהִירוּת
- הוצאה
- SQL
- החל
- מדינה
- הצהרה
- הצהרות
- סטטיסטיקות
- שלב
- צעדים
- עוד
- אחסון
- חנות
- מאוחסן
- חנויות
- אסטרטגיות
- אִסטרָטֶגִיָה
- מובנה
- נתונים מובנים ולא מובנים
- סטודיו
- המשנה
- לאחר מכן
- בהצלחה
- כזה
- מספיק
- סיכום
- תמיכה
- נתמך
- מסייע
- תומך
- שולחן
- לוקח
- נטילת
- יעד
- משימות
- טכניקות
- טֶנִיס
- מבחן
- בדיקות
- בדיקות
- אל האני
- המידע
- המדינה
- שֶׁלָהֶם
- בכך
- אלפים
- שְׁלוֹשָׁה
- דרך
- זמן
- זמן הנסיעה
- ל
- יַחַד
- גַם
- כלים
- חלק עליון
- סה"כ
- לעקוב
- עסקות
- הפיכה
- נסיעות
- נסיעה
- תור
- סוגים
- תחת
- ייחודי
- עדכון
- מְעוּדכָּן
- עדכונים
- עדכון
- כתובת האתר
- להשתמש
- במקרה להשתמש
- משתמשים
- בְּדֶרֶך כְּלַל
- מדד
- ערך
- ערכים
- לאמת
- גרסה
- הלך
- בהדרכה
- מחסן
- שעונים
- דרכים
- אינטרנט
- שירותי אינטרנט
- מה
- אם
- אשר
- בזמן
- רָחָב
- טווח רחב
- יצטרך
- לְלֹא
- תיק עבודות
- עובד
- עובד
- היה
- לכתוב
- כתיבה
- זפירנט