תמונה מאת המחבר
בעולם שבו נתונים הם השמן החדש, הבנת הניואנסים של קריירה במדעי הנתונים חשובה יותר מאי פעם. בין אם אתה חובב נתונים שמחפש או ותיק בוחן הזדמנויות, שימוש ב-SQL יכול להציע תובנות לגבי שוק העבודה במדעי הנתונים.
אני מקווה שאתה להוט לדעת איזה כותרות עבודה במדעי נתונים הם האטרקטיביים ביותר, או אילו מהם מציעים את המשכורת הכבדה ביותר. או אולי, אתה תוהה איך רמות ניסיון מתקשרות משכורות ממוצעות במדעי הנתונים?
במאמר זה, עוסקנו בכל השאלות הללו (ועוד) כאשר אנו נכנסים עמוק לשוק העבודה במדעי הנתונים. בואו נתחיל!
מערך הנתונים בו נשתמש במאמר זה נועד לשפוך אור על דפוסי שכר בתחום ה-Data Science מ-2021 עד 2023. על ידי הדגשת אלמנטים כגון היסטוריית עבודה, משרות ומיקומים ארגוניים, הוא מציע תובנות חיוניות לגבי פיזור השכר ב- המגזר.
מאמר זה ימצא תשובה לשאלות הבאות:
- איך נראה השכר הממוצע על פני רמות ניסיון שונות?
- מהם כותרות המשרה הנפוצות ביותר במדעי הנתונים?
- כיצד חלוקת השכר משתנה בהתאם לגודל החברה?
- היכן משרות מדעי הנתונים ממוקמות בעיקר מבחינה גיאוגרפית?
- אילו כותרות עבודה מציעות את המשכורות המובילות במדעי הנתונים?
אתה יכול להוריד את הנתונים האלה מה- קגל.
1. איך נראה השכר הממוצע על פני רמות ניסיון שונות?
בשאילתת SQL זו אנו מוצאים את השכר הממוצע עבור רמות ניסיון שונות. סעיף GROUP BY מקבץ את הנתונים לפי רמת ניסיון והפונקציה AVG מחשבת את השכר הממוצע עבור כל קבוצה.
זה עוזר להבין כיצד ניסיון בתחום משפיע על פוטנציאל ההשתכרות, שהוא חיוני עבורך בעת תכנון מסלולי קריירה במדעי הנתונים. בוא נראה את הקוד.
SELECT experience_level, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY experience_level;
עכשיו בואו נראה את הפלט הזה באמצעות Python.
הנה הקוד.
# Import required libraries for plotting
import matplotlib.pyplot as plt
import seaborn as sns
# Set up the style for the graphs
sns.set(style="whitegrid") # Initialize the list for storing graphs
graphs = [] plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x))
plt.title('Average Salary by Experience Level')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
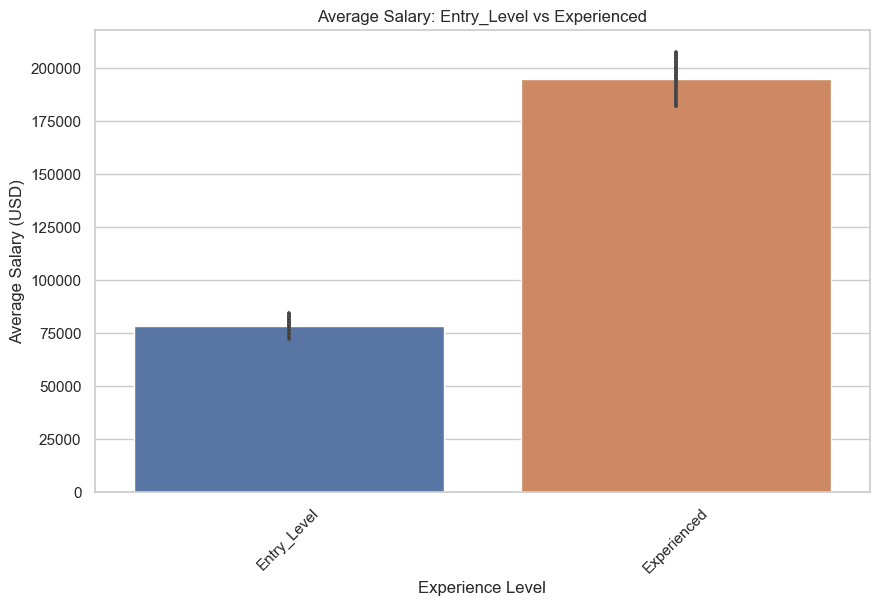
עכשיו בואו נשווה, משכורות ברמת כניסה ומנוסה וברמה בינונית ובכירים.
בואו נתחיל עם רמת כניסה ומנוסה. הנה הקוד.
# Filter the data for Entry_Level and Experienced levels
entry_experienced = df[df['experience_level'].isin(['Entry_Level', 'Experienced'])] # Filter the data for Mid-Level and Senior levels
mid_senior = df[df['experience_level'].isin(['Mid-Level', 'Senior'])] # Plotting the Entry_Level vs Experienced graph
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=entry_experienced, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Average Salary: Entry_Level vs Experienced')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
הנה הגרף.
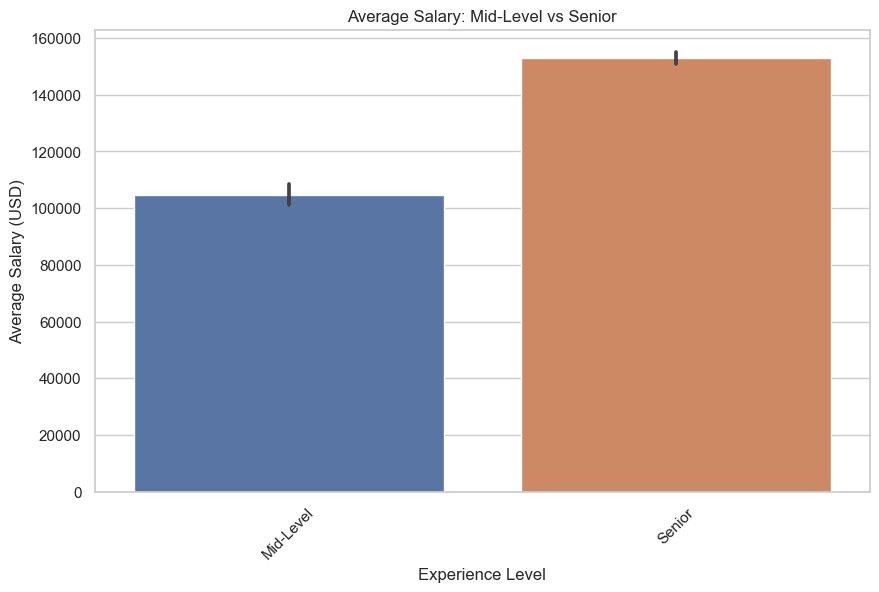
עכשיו בואו נצייר, רמה בינונית ובכירה. הנה הקוד.
# Plotting the Mid-Level vs Senior graph
plt.figure(figsize=(10, 6))
sns.barplot(x='experience_level', y='salary_in_usd', data=mid_senior, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0)
plt.title('Average Salary: Mid-Level vs Senior')
plt.xlabel('Experience Level')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
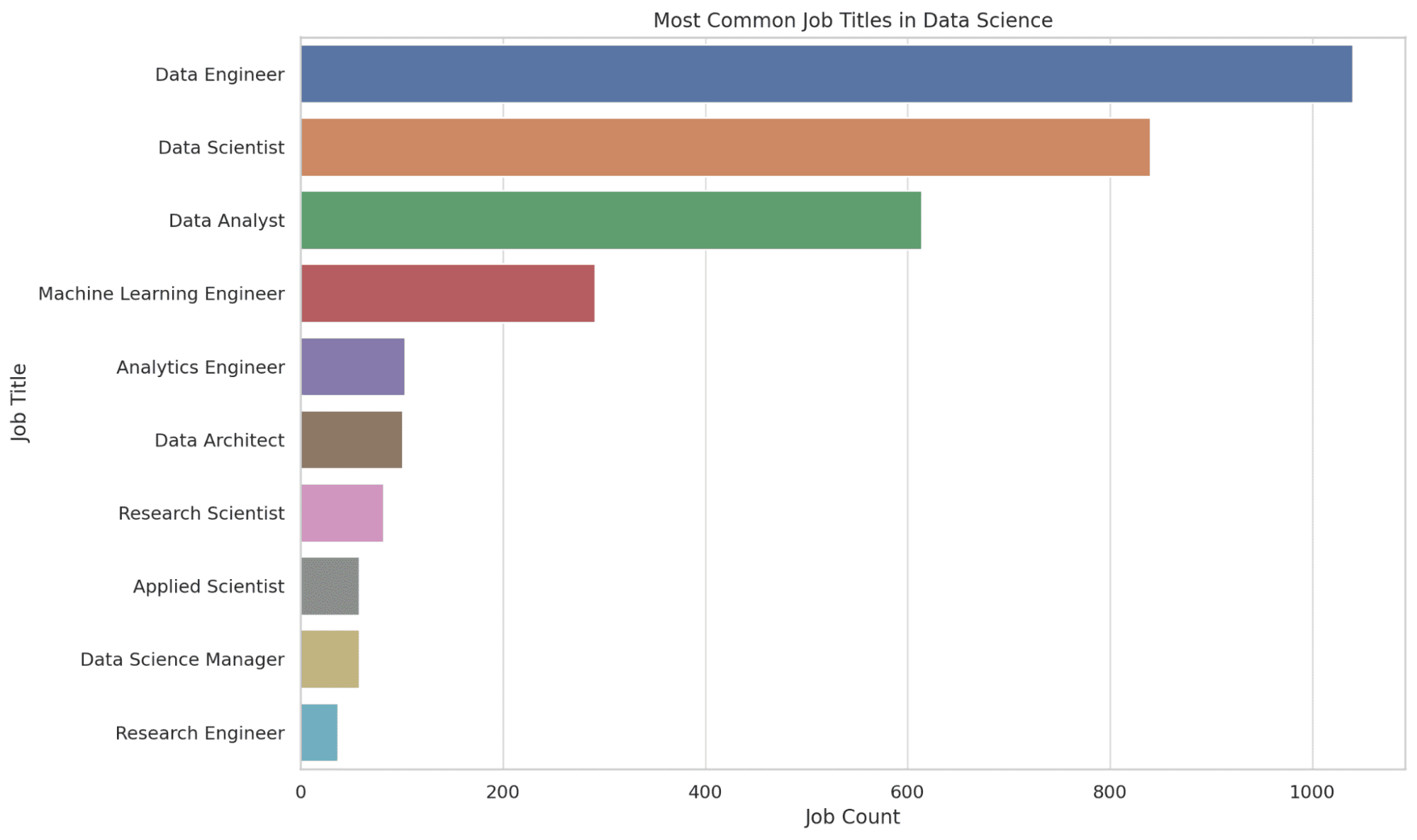
2. מהם כותרות המשרה הנפוצות ביותר במדעי הנתונים?
כאן אנו מחלצים את 10 כותרות העבודה הנפוצות ביותר במדעי הנתונים. הפונקציה COUNT סופרת את מספר המופעים של כל כותרת תפקיד, והתוצאות מסודרות בסדר יורד כדי לקבל את הכותרות הנפוצות ביותר בראש.
מידע זה נותן לך תחושה של הביקוש בשוק העבודה, ומנחה אותך בזיהוי תפקידים פוטנציאליים שאתה יכול לכוון אליהם. בוא נראה את הקוד.
SELECT job_title, COUNT(*) AS job_count
FROM salary_data
GROUP BY job_title
ORDER BY job_count DESC
LIMIT 10;
אוקיי, הגיע הזמן לדמיין את השאילתה הזו באמצעות Python.
הנה הקוד.
plt.figure(figsize=(12, 8))
sns.countplot(y='job_title', data=df, order=df['job_title'].value_counts().index[:10])
plt.title('Most Common Job Titles in Data Science')
plt.xlabel('Job Count')
plt.ylabel('Job Title')
graphs.append(plt.gcf())
plt.show()
בוא נראה את הגרף.
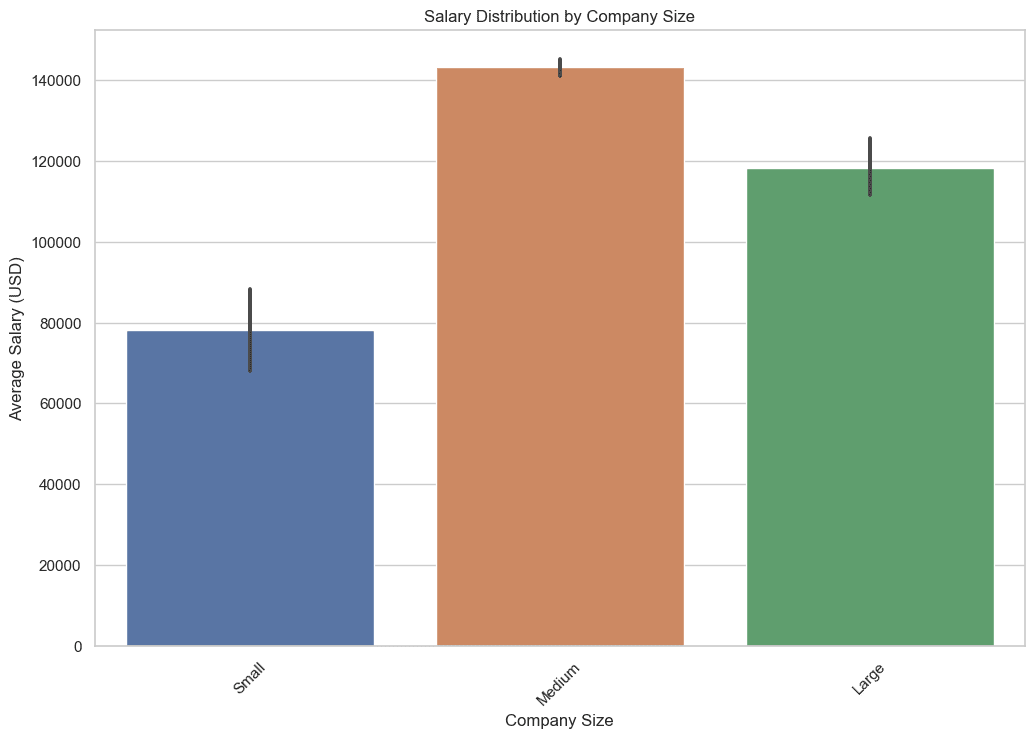
3. כיצד משתנה חלוקת השכר בהתאם לגודל החברה?
בשאילתה זו אנו מחלצים את השכר הממוצע, המינימום והמקסימום עבור כל קבוצת גודל של חברה. שימוש בפונקציות מצטברות כמו AVG, MIN ו-MAX עוזר לספק מבט מקיף על נוף השכר ביחס לגודל החברה.
נתונים אלה חיוניים מכיוון שהם עוזרים לך להבין את הרווחים הפוטנציאליים שאתה יכול לצפות בהתאם לגודל החברה שאתה מחפש להצטרף, בוא נראה את הקוד.
SELECT company_size, AVG(salary_in_usd) AS avg_salary, MIN(salary_in_usd) AS min_salary, MAX(salary_in_usd) AS max_salary
FROM salary_data
GROUP BY company_size;
כעת בואו נדמיין את השאילתה הזו באמצעות Python.
הנה הקוד.
plt.figure(figsize=(12, 8))
sns.barplot(x='company_size', y='salary_in_usd', data=df, estimator=lambda x: sum(x) / len(x) if len(x) != 0 else 0, order=['Small', 'Medium', 'Large'])
plt.title('Salary Distribution by Company Size')
plt.xlabel('Company Size')
plt.ylabel('Average Salary (USD)')
plt.xticks(rotation=45)
graphs.append(plt.gcf())
plt.show()
הנה הפלט.
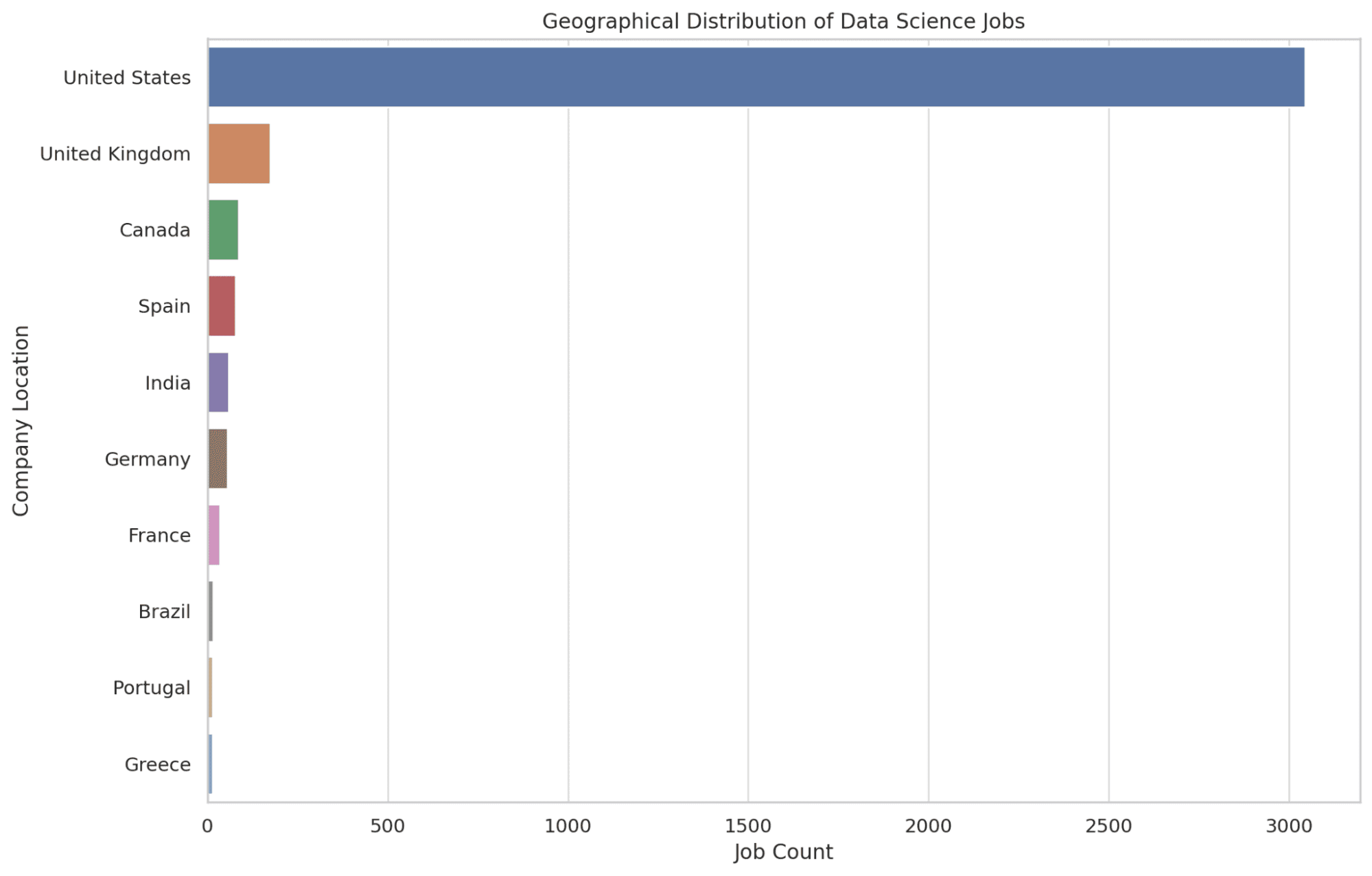
4. איפה משרות מדעי הנתונים ממוקמות בעיקר מבחינה גיאוגרפית?
כאן אנו מציינים את 10 המיקומים המובילים עם המספר הגבוה ביותר של הזדמנויות עבודה בתחום מדעי הנתונים. אנו משתמשים בפונקציה COUNT כדי לקבוע את מספר פרסומי המשרות בכל מיקום, ומסדרים אותם בסדר יורד כדי להאיר את האזורים עם הכי הרבה הזדמנויות.
מידע זה מצייד את הקוראים בידע על האזורים הגיאוגרפיים המהווים מרכז לתפקידי מדעי הנתונים, ומסייע בהחלטות פוטנציאליות להעברה. בוא נראה את הקוד.
SELECT company_location, COUNT(*) AS job_count
FROM salary_data
GROUP BY company_location
ORDER BY job_count DESC
LIMIT 10;
עכשיו בואו ניצור גרפים של הקוד למעלה, עם Python.
plt.figure(figsize=(12, 8))
sns.countplot(y='company_location', data=df, order=df['company_location'].value_counts().index[:10])
plt.title('Geographical Distribution of Data Science Jobs')
plt.xlabel('Job Count')
plt.ylabel('Company Location')
graphs.append(plt.gcf())
plt.show()
בוא נראה את הגרף למטה.
5. אילו כותרות עבודה מציעות את המשכורות המובילות במדעי הנתונים?
כאן, אנו מזהים את 10 כותרות המשרה בעלי השכר הגבוה ביותר במגזר מדעי הנתונים. על ידי שימוש ב-AVG, אנו מחשבים את השכר הממוצע עבור כל תפקיד, ממיינים אותם בסדר יורד על סמך השכר הממוצע כדי להדגיש את התפקידים הרווחיים ביותר.
אתה יכול לשאוף למסע הקריירה שלך, על ידי התבוננות בנתונים אלה. בואו נמשיך להבין כיצד קוראים יכולים ליצור הדמיה של Python עבור נתונים אלה.
SELECT job_title, AVG(salary_in_usd) AS avg_salary
FROM salary_data
GROUP BY job_title
ORDER BY avg_salary DESC
LIMIT 10;
הנה הפלט.
(כאן אנחנו לא יכולים להשתמש בתמונות, כי הוספנו 4 תמונות למעלה, ואחת נשארה לתמונה ממוזערת, האם יש לנו הזדמנות להשתמש בטבלה כמו למטה כדי להדגים את הפלט?)
| דַרגָה | כותרת העבודה | שכר ממוצע (דולר ארה"ב) |
| 1 | מוביל טכנולוגי במדעי הנתונים | 375,000.00 |
| 2 | ארכיטקט נתונים בענן | 250,000.00 |
| 3 | מוביל נתונים | 212,500.00 |
| 4 | הובלה לניתוח נתונים | 211,254.50 |
| 5 | מדען נתונים ראשי | 198,171.13 |
| 6 | מנהל מדעי הנתונים | 195,140.73 |
| 7 | מהנדס נתונים ראשי | 192,500.00 |
| 8 | מהנדס תוכנה למידת מכונה | 192,420.00 |
| 9 | מנהל מדעי הנתונים | 191,278.78 |
| 10 | מדען יישומי | 190,264.48 |
הפעם, בואו ננסה ליצור גרף בעצמכם.
טיפים: אתה יכול להשתמש בהנחיה הבאה ב-ChatGPT כדי ליצור קוד פיתוני של גרף זה:
<SQL Query here> Create a Python graph to visualize the top 10 highest-paying job titles in Data Science, similar to the insights gathered from the given SQL query above.בעודנו מסיימים את המסע שלנו בשטחים המגוונים של עולם הקריירה במדעי הנתונים, אנו מקווים ש-SQL יתגלה כמדריך אמין, שיעזור לך לחשוף פנינים של תובנות כדי לתמוך בהחלטות הקריירה שלך.
אני מקווה שאתה מרגיש מצויד יותר כעת, לא רק במיפוי מסלול הקריירה שלך, אלא גם בשימוש ב-SQL בעיצוב נתונים גולמיים לנרטיבים רבי עוצמה. אז הנה לצעוד לעתיד מלא בהזדמנויות, עם נתונים כמצפן שלך ו-SQL ככוח המנחה שלך!
תודה על הקריאה!
נייט רוזידי הוא מדען נתונים ואסטרטגיית מוצר. הוא גם פרופסור עזר המלמד אנליטיקה, והוא המייסד של StrataScratch, פלטפורמה המסייעת למדעני נתונים להתכונן לראיונות שלהם עם שאלות ראיונות אמיתיות מחברות מובילות. התחבר אליו הלאה טוויטר: StrataScratch or לינקדין.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.kdnuggets.com/using-sql-to-understand-data-science-career-trends?utm_source=rss&utm_medium=rss&utm_campaign=using-sql-to-understand-data-science-career-trends
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 000
- 1
- 10
- 11
- 12
- 14
- 16
- 17
- 2021
- 2023
- 264
- 420
- 500
- 8
- 9
- a
- מֵעַל
- לרוחב
- הוסיף
- נלווה
- לְקַבֵּץ
- תעשיות
- גם
- an
- ניתוח
- ו
- לענות
- ARE
- אזורים
- מאמר
- AS
- לִשְׁאוֹף
- At
- מושך
- מְמוּצָע
- AVG
- מבוסס
- BE
- כי
- להלן
- אבל
- by
- לחשב
- מחשב
- CAN
- קריירה
- סיכוי
- ChatGPT
- קוד
- COM
- Common
- חברות
- חברה
- לְהַשְׁווֹת
- מצפן
- מַקִיף
- לְחַבֵּר
- משותף
- מכוסה
- לִיצוֹר
- מכריע
- נתונים
- מדע נתונים
- מדען נתונים
- החלטות
- עמוק
- דרישה
- להפגין
- תלוי
- מעוצב
- לקבוע
- אחר
- פיזור
- הפצה
- שונה
- do
- עושה
- להורדה
- לצייר
- כל אחד
- לָהוּט
- רווחים
- שכר
- אלמנטים
- אחר
- נלהב
- ברמת כניסה
- מְצוּיָד
- חיוני
- Ether (ETH)
- אי פעם
- לצפות
- ניסיון
- מנוסה
- היכרות
- תמצית
- להרגיש
- שדה
- ממולא
- לסנן
- מציאת
- הבא
- בעד
- מייסד
- החל מ-
- מ 2021
- פונקציה
- פונקציות
- עתיד
- אסף
- ליצור
- גיאוגרפי
- לקבל
- נתן
- נותן
- Go
- קבל
- גרף
- גרפים
- קְבוּצָה
- קבוצה
- מדריך
- יש
- he
- עזרה
- עוזר
- כאן
- הגבוה ביותר
- להבליט
- לו
- היסטוריה
- מחזיק
- לקוות
- איך
- HTTPS
- רכזות
- זיהוי
- if
- לייבא
- חשוב
- in
- מידע
- תובנות
- ראיון אישי
- שאלות בראיון
- ראיונות
- אל תוך
- IT
- עבודה
- משרות פנויות
- כותרות עבודה
- מקומות תעסוקה
- להצטרף
- מסע
- רק
- KDnuggets
- לדעת
- ידע
- נוף
- גָדוֹל
- למידה
- עזבו
- רמה
- רמות
- ספריות
- אוֹר
- כמו
- להגביל
- לינקדין
- רשימה
- ממוקם
- מיקום
- מקומות
- נראה
- נראה כמו
- הסתכלות
- משתלם
- מיפוי
- שוק
- matplotlib
- מקסימום
- מקסימום
- בינוני
- דקות
- מינימום
- יותר
- רוב
- הנרטיב
- חדש
- עַכשָׁיו
- מספר
- of
- הַצָעָה
- המיוחדות שלנו
- שמן
- on
- ONE
- יחידות
- הזדמנויות
- or
- להזמין
- שלנו
- תפוקה
- נתיב
- דפוסי
- תלושי שכר
- אוּלַי
- תמונות
- תכנון
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- עמדות
- פוטנציאל
- חזק
- להכין
- בראש ובראשונה
- להמשיך
- המוצר
- פרופסור
- מוכיח
- לספק
- פיתון
- שאלות
- חי
- נתונים גולמיים
- RE
- הקוראים
- ממשי
- יחס
- נדרש
- תוצאות
- תפקידים
- s
- משכורות
- משכורת
- מדע
- מַדְעָן
- מדענים
- ים ים
- מגזר
- לִרְאוֹת
- לחצני מצוקה לפנסיונרים
- תחושה
- סט
- מעצבים
- לִשְׁפּוֹך
- דומה
- מידה
- קטן
- So
- תוכנה
- זַרקוֹר
- SQL
- התחלה
- צועד
- אִסטרָטֶגִיָה
- סגנון
- כזה
- תמיכה
- שולחן
- יעד
- הוראה
- טק
- מֵאֲשֶׁר
- זֶה
- השמיים
- הגרף
- שֶׁלָהֶם
- אותם
- זֶה
- אלה
- דרך
- תמונה ממוזערת
- עניבה
- זמן
- כותרת
- כותרות
- ל
- חלק עליון
- 10 למעלה
- מגמות
- אמין
- לנסות
- להבין
- הבנה
- ש״ח
- להשתמש
- באמצעות
- לְהִשְׁתַנוֹת
- ותיק
- לצפיה
- ראיה
- לחזות
- vs
- שכר
- we
- מה
- אם
- אשר
- בזמן
- יצטרך
- עם
- תוהה
- תיק עבודות
- עוֹלָם
- לעטוף
- X
- אתה
- עצמך
- זפירנט