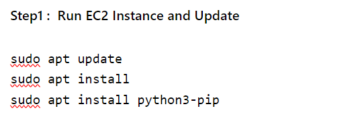
f דגמי ML. זה גם יעמיק בטכניקות ה-ETL piphe המשמשות לניקוי נתונים, עיבוד מקדים והנדסת תכונות. בסוף מאמר זה, תהיה לך הבנה מוצקה של החשיבות של איכות נתונים ב-ML והטכניקות המשמשות כדי להבטיח נתונים באיכות גבוהה. זה יעזור ליישם את הטכניקות הללו בפרויקטים בעולם האמיתי ולשפר את הביצועים של מודלים ML שלהם.
מטרות למידה
- הבנת היסודות של למידת מכונה ויישומיה השונים.
- הכרה בחשיבותה של איכות נתונים בהצלחת מודלים של למידת מכונה.
- היכרות עם צינור ה-ETL ותפקידו בהבטחת איכות הנתונים.
- לימוד טכניקות מרובות לניקוי נתונים, כולל טיפול בנתונים חסרים ושכפולים, חריגים ורעש ומשתנים קטגוריים.
- הבנת החשיבות של עיבוד מוקדם של נתונים והנדסת תכונות בשיפור איכות הנתונים המשמשים במודלים של ML.
- ניסיון מעשי ביישום צינור ETL שלם באמצעות קוד, כולל חילוץ נתונים, טרנספורמציה וטעינה.
- היכרות עם הזרקת נתונים וכיצד היא יכולה להשפיע על הביצועים של מודלים של ML.
- הבנת הרעיון והחשיבות של הנדסת תכונות בלמידת מכונה.
מאמר זה פורסם כחלק מה- בלוגאת מדע הנתונים.
תוכן העניינים
- מבוא
- מהי למידת מכונה?
- מדוע נתונים קריטיים בלמידת מכונה?
- איסוף נתונים באמצעות צינור ETL?
- מהי הזרקת נתונים?
- החשיבות של ניקוי נתונים
- מהו עיבוד מוקדם של נתונים?
- צלילה להנדסת תכונות
- קוד מלא עבור ETL-Pipeline
- סיכום
מהי למידת מכונה?
למידת מכונה היא סוג של בינה מלאכותית המאפשרת למחשבים ללמוד ולהשתפר על סמך ניסיון ללא תכנות מפורש. הוא ממלא תפקיד מכריע בביצוע תחזיות, זיהוי דפוסים בנתונים וקבלת החלטות ללא התערבות אנושית. זה מביא למערכת מדויקת ויעילה יותר.

למידת מכונה היא חלק חיוני מחיינו ומשמשת ביישומים החל מעוזרים וירטואליים ועד למכוניות בנהיגה עצמית, שירותי בריאות, פיננסים, תחבורה ומסחר אלקטרוני.
נתונים, במיוחד למידת מכונה, הם אחד המרכיבים הקריטיים של כל מודל. זה תמיד תלוי באיכות הנתונים שאתה מזין את הדגם שלך. הבה נבחן מדוע נתונים כה חיוניים ללמידת מכונה.
מדוע נתונים קריטיים בלמידת מכונה?
אנחנו מוקפים במידע רב מדי יום. ענקיות טכנולוגיה כמו אמזון, פייסבוק וגוגל אוספות כמויות עצומות של נתונים מדי יום. אבל למה הם אוספים נתונים? אתה צודק אם ראית את אמזון וגוגל תומכות במוצרים שאתה מחפש.
לבסוף, נתונים מטכניקות למידת מכונה ממלאים תפקיד חיוני ביישום מודל זה. בקיצור, נתונים הם הדלק שמניע למידת מכונה, והזמינות של נתונים באיכות גבוהה היא קריטית ליצירת מודלים מדויקים ואמינים. סוגי נתונים רבים משמשים למידת מכונה, כולל נתונים קטגוריים, מספריים, סדרות זמן ונתוני טקסט. הנתונים נאספים באמצעות צינור ETL. מהו צינור ETL?
איסוף נתונים באמצעות צינור ETL
הכנת נתונים ללמידת מכונה מכונה לעתים קרובות כצינור ETL לחילוץ, טרנספורמציה וטעינה.
- הפקה: השלב הראשון בצינור ה-ETL הוא חילוץ נתונים ממקורות שונים. זה יכול לכלול חילוץ נתונים מבסיסי נתונים, ממשקי API או קבצים רגילים כמו CSV או Excel. נתונים יכולים להיות מובנים או לא מובנים.
הנה דוגמה לאופן שבו אנו מחלצים נתונים מקובץ CSV.
קוד פייתון:
import pandas as pd
#read csv file
df = pd.read_csv("data.csv")
#extract specific data
name = df["name"]
age = df["age"]
address = df["address"]
#print extracted data
print("Name:", name)
print("Age:", age)
print("Address:", address)
- טרנספורמציה: זהו תהליך של הפיכת הנתונים כדי להפוך אותם למתאים לשימוש במודלים של למידת מכונה. זה עשוי לכלול ניקוי הנתונים כדי להסיר שגיאות או חוסר עקביות, סטנדרטיזציה של הנתונים והמרת הנתונים לפורמט שהמודל יכול להשתמש בו. שלב זה כולל גם הנדסת תכונות, שבה הנתונים הגולמיים הופכים לסט של תכונות שישמשו כקלט עבור המודל.
- זהו קוד פשוט להמרת נתונים מ-json ל-DataFrame.
import json
import pandas as pd
#load json file
with open("data.json", "r") as json_file:
data = json.load(json_file)
#convert json data to a DataFrame
df = pd.DataFrame(data)
#write to csv
df.to_csv("data.csv", index=False)
- לִטעוֹן: השלב האחרון הוא להעלות או לטעון את הנתונים שהומרו ליעד. זה יכול להיות מסד נתונים, מאגר נתונים או מערכת קבצים. הנתונים המתקבלים מוכנים לשימוש נוסף, כגון הדרכה או בדיקת מודלים של למידת מכונה.
הנה קוד פשוט שמראה כיצד אנו טוענים נתונים באמצעות הפנדות:
import pandas as pd
df = pd.read_csv('data.csv')
לאחר איסוף הנתונים, אנו משתמשים בדרך כלל בהזרקת הנתונים אם אנו מוצאים ערכים חסרים.
מהי הזרקת נתונים?
הוספת נתונים חדשים לשרת נתונים קיים יכולה להיעשות מסיבות שונות כדי לעדכן את מסד הנתונים בנתונים חדשים ולהוסיף נתונים מגוונים יותר כדי לשפר את הביצועים של מודלים של למידת מכונה. או תיקון שגיאות של מערך הנתונים המקורי נעשה בדרך כלל על ידי אוטומציה עם כמה כלים שימושיים.

ישנם שלושה סוגים.
- הכנסת אצווה: הנתונים מוכנסים בכמות גדולה, זה בדרך כלל בזמן קבוע
- הזרקה בזמן אמת: נתונים מוזרקים מיד כאשר הם נוצרים.
- הזרקת זרם: נתונים מוזרקים בזרם רציף. הוא משמש לעתים קרובות בזמן אמת.
הנה דוגמה לקוד כיצד אנו מחדירים נתונים באמצעות פונקציית ה-append באמצעות ספריית הפנדות.
השלב הבא בצנרת הנתונים הוא ניקוי נתונים.
import pandas as pd # Create an empty DataFrame
df = pd.DataFrame() # Add some data to the DataFrame
df = df.append({'Name': 'John', 'Age': 30, 'Country': 'US'}, ignore_index=True)
df = df.append({'Name': 'Jane', 'Age': 25, 'Country': 'UK'}, ignore_index=True) # Print the DataFrame
print(df)
החשיבות של ניקוי נתונים
ניקוי נתונים הוא הסרה או תיקון של שגיאות בנתונים. זה עשוי לכלול הסרת ערכים חסרים וכפילויות וניהול חריגים. ניקוי נתונים הוא תהליך איטרטיבי, ותובנות חדשות עשויות לחייב אותך לחזור אחורה ולבצע שינויים. ב-Python, ספריית הפנדות משמשת לעתים קרובות לניקוי נתונים.
ישנן סיבות חשובות לניקוי נתונים.
- איכות מידע: איכות הנתונים חיונית לניתוח מדויק ואמין. מידע מדויק ועקבי יותר יכול להוביל לתוצאות בפועל וקבלת החלטות טובה יותר.
- ביצועים של למידת מכונה: נתונים מלוכלכים יכולים להשפיע לרעה על הביצועים של מודלים של למידת מכונה. ניקוי הנתונים שלך משפר את הדיוק והאמינות של הדגם שלך.
- אחסון ואחזור נתונים: קל יותר לאחסן ולאחזר נתונים נקיים ומפחית את הסיכון לשגיאות וחוסר עקביות באחסון ואחזור נתונים.
- ממשל נתונים: ניקוי נתונים הוא חיוני כדי להבטיח שלמות הנתונים ועמידה במדיניות ובתקנות רגולטוריות נתונים.
- אחסון נתונים: ניגוב נתונים עוזר לשמור נתונים לשימוש וניתוח לטווח ארוך.
הנה קוד שמראה כיצד להוריד ערכים חסרים ולהסיר כפילויות באמצעות ספריית הפנדות:
df = df.dropna()
df = df.drop_duplicates() # Fill missing values
df = df.fillna(value=-1)
הנה דוגמה נוספת לאופן שבו אנו מנקים את הנתונים באמצעות טכניקות שונות
import pandas as pd # Create a sample DataFrame
data = {'Name': ['John', 'Jane', 'Mike', 'Sarah', 'NaN'], 'Age': [30, 25, 35, 32, None], 'Country': ['US', 'UK', 'Canada', 'Australia', 'NaN']}
df = pd.DataFrame(data) # Drop missing values
df = df.dropna() # Remove duplicates
df = df.drop_duplicates() # Handle outliers
df = df[df['Age'] < 40] # Print the cleaned DataFrame
print(df)
השלב השלישי של צנרת הנתונים הוא עיבוד מוקדם של נתונים,
זה גם טוב להבין בבירור את הנתונים והתכונות לפני יישום שיטות ניקוי כלשהן ולבדוק את ביצועי הדגם לאחר ניקוי הנתונים.
מהו עיבוד מוקדם של נתונים?
עיבוד נתונים הוא הכנת נתונים לשימוש במודלים של למידת מכונה. זהו שלב חיוני בלמידת מכונה מכיוון שהוא מבטיח שהנתונים יהיו בפורמט שהמודל יכול להשתמש בו ושכל שגיאה או חוסר עקביות ייפתרו.

עיבוד נתונים כולל בדרך כלל שילוב של ניקוי נתונים, טרנספורמציה של נתונים וסטנדרטיזציה של נתונים. השלבים הספציפיים בעיבוד נתונים תלויים בסוג הנתונים ובמודל למידת המכונה שבה אתה משתמש. עם זאת, הנה כמה שלבים כלליים:
- ניקוי נתונים: הסר שגיאות, חוסר עקביות וחריגים ממסד הנתונים.
- שינוי נתונים: המרת נתונים לצורה שיכולה לשמש מודלים של למידת מכונה, כגון שינוי משתנים קטגוריים למשתנים מספריים.
- נתונים נוֹרמָלִיזָצִיָה: קנה קנה מידה של נתונים בטווח מסוים שבין 0 ל-1, מה שעוזר לשפר את הביצועים של מודלים מסוימים של למידת מכונה.
- הוסף נתונים: הוסף שינויים או מניפולציות לנקודות נתונים קיימות כדי ליצור חדשות.
- בחירת תכונות או חילוץ: זהה ובחר את התכונות החיוניות מהנתונים שלך לשימוש כקלט למודל למידת המכונה שלך.
- זיהוי חריגים: זהה והסר נקודות נתונים החורגות באופן משמעותי מכמויות גדולות של נתונים. חריגים יכולים לשנות תוצאות אנליטיות ולהשפיע לרעה על הביצועים של מודלים של למידת מכונה.
- זיהוי כפילויות: זיהוי והסר נקודות נתונים כפולות. נתונים כפולים יכולים להוביל לתוצאות לא מדויקות או לא אמינות ולהגדיל את גודל מערך הנתונים שלך, מה שמקשה על עיבוד וניתוח.
- זיהוי מגמות: מצא דפוסים ומגמות בנתונים שלך שבהם תוכל להשתמש כדי לספק תחזיות עתידיות או להבין טוב יותר את אופי הנתונים שלך.
עיבוד נתונים חיוני בלמידת מכונה מכיוון שהוא מבטיח שהנתונים יהיו בצורה שבה המודל יכול להשתמש ושגיאות או חוסר עקביות יוסרו. זה משפר את ביצועי המודל ואת דיוק החיזוי.
הנה כמה קוד פשוט שמראה כיצד להשתמש במחלקה LabelEncoder כדי לשנות את קנה המידה של משתנים קטגוריים לערכים מספריים ואת המחלקה MinMaxScaler כדי לשנות את קנה המידה של משתנים מספריים.
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler, OneHotEncoder, LabelEncoder # Create a sample DataFrame
data = {'Name': ['John', 'Jane', 'Mike', 'Sarah'], 'Age': [30, 25, 35, 32], 'Country': ['US', 'UK', 'Canada', 'Australia'], 'Gender':['M','F','M','F']}
df = pd.DataFrame(data) # Convert categorical variables to numerical
encoder = LabelEncoder()
df["Gender"] = encoder.fit_transform(df["Gender"]) # One hot encoding
onehot_encoder = OneHotEncoder()
country_encoded = onehot_encoder.fit_transform(df[['Country']])
df = pd.concat([df, pd.DataFrame(country_encoded.toarray())], axis=1)
df = df.drop(['Country'], axis=1) # Scale numerical variables
scaler = MinMaxScaler()
df[['Age']] = scaler.fit_transform(df[['Age']]) # Print the preprocessed DataFrame
print(df)
השלב האחרון של צינור הנתונים הוא הנדסת תכונות,
צלילה להנדסת תכונות
הנדסת תכונות הופך נתונים גולמיים לתכונות שיכולות לשמש כקלט עבור מודלים ללימוד מכונה. זה כרוך בזיהוי והפקת הנתונים הקריטיים ביותר מחומר הגלם והמרתם לפורמט שבו המודל יכול להשתמש. הנדסת תכונות חיונית בלמידת מכונה מכיוון שהיא יכולה להשפיע באופן משמעותי על ביצועי המודל.
טכניקות שונות שניתן להשתמש בהן להנדסת תכונות הן:
- מאפיין הפקה: חילוץ מידע רלוונטי מנתונים גולמיים. לדוגמה, זהה את התכונות החשובות ביותר או שלב תכונות קיימות כדי ליצור תכונות חדשות.
- שינוי תכונה: שנה את סוג התכונה, כגון שינוי משתנה קטגורי למשתנה מספרי או הגדלה של הנתונים כך שיתאימו לטווח מסוים.
- בחירת תכונה: קבע את התכונות החיוניות של הנתונים שלך לשימוש כקלט למודל למידת המכונה שלך.
- הפחתת מימד: צמצם את מספר התכונות במסד הנתונים על ידי הסרת תכונות מיותרות או לא רלוונטיות.
- הוסף נתונים: הוסף שינויים או מניפולציות לנקודות נתונים קיימות כדי ליצור חדשות.
הנדסת תכונות דורשת הבנה טובה של הנתונים שלך, הבעיה שיש לפתור ואלגוריתמים של למידת מכונה לשימוש. תהליך זה הוא איטרטיבי וניסיוני ועשוי לדרוש מספר איטרציות כדי למצוא את מערך התכונות האופטימלי שמשפר את הביצועים של המודל שלנו.
קוד מלא עבור צינור ה-ETL כולו
הנה דוגמה לצינור ETL שלם המשתמש בספריות הפנדות וה-sikit-learn:
import pandas as pd
from sklearn.preprocessing import MinMaxScaler, StandardScaler, OneHotEncoder, LabelEncoder # Extract data from CSV file
df = pd.read_csv('data.csv') # Data cleaning
df = df.dropna()
df = df.drop_duplicates() # Data transformation
encoder = LabelEncoder()
df["Gender"] = encoder.fit_transform(df["Gender"]) onehot_encoder = OneHotEncoder()
country_encoded = onehot_encoder.fit_transform(df[['Country']])
df = pd.concat([df, pd.DataFrame(country_encoded.toarray())], axis=1)
df = df.drop(['Country'], axis=1) scaler = MinMaxScaler()
df[['Age']] = scaler.fit_transform(df[['Age']]) # Load data into a new CSV file
df.to_csv('cleaned_data.csv', index=False)
הנתונים מאוחזרים תחילה מקובץ CSV באמצעות פונקציית pandas read_csv() של דוגמה זו. ניקוי הנתונים מתבצע לאחר מכן על ידי הסרת ערכים חסרים וכפולים. זה נעשה באמצעות LabelEncoder כדי לשנות משתנים קטגוריים למספריים, OneHotEncoder לשינוי קנה מידה של משתנים קטגוריים למספרים, ו-MinMaxScaler לשינוי קנה מידה של משתנים מספריים. לבסוף, הנתונים שנמחקו נקראים לקובץ CSV חדש באמצעות הפונקציה pandas to_csv() .
שימו לב שדוגמה זו היא גרסה פשוטה מאוד של צינור ה-ETL. בתרחיש אמיתי, הצינור עשוי להיות מורכב יותר ולכלול יותר עיבוד ומיקור חוץ, תמחיר וכו' יכול לכלול שיטות כגון. בנוסף, מעקב אחר נתונים הוא גם חיוני. כלומר, הוא עוקב אחר מקור הנתונים, השינויים שלהם והיכן הוא נמצא לא רק עוזר לך להבין את איכות הנתונים שלך אלא גם עוזר לך לנפות באגים ולבדוק את הצינור שלך. כמו כן, חיוני להבין בבירור את הנתונים והתכונות לפני יישום שיטות שלאחר עיבוד ובדיקת ביצועי המודל לאחר עיבוד מקדים. מֵידָע.
סיכום
איכות הנתונים היא קריטית להצלחת מודלים של למידת מכונה. על ידי טיפול בכל שלב בתהליך, מ איסוף הנתונים לניקוי, עיבוד ואימות, אתה יכול להבטיח שהנתונים שלך יהיו באיכות הגבוהה ביותר. זה יאפשר למודל שלך ליצור תחזיות מדויקות יותר, מה שיוביל לתוצאות טובות יותר ולפרוייקטים מוצלחים של לימוד מכונה.
כעת תדע את החשיבות של איכות נתונים בלמידת מכונה. הנה כמה מהדברים העיקריים מהמאמר שלי:
המנות העיקריות
- הבנת ההשפעה של איכות נתונים ירודה על מודלים של למידת מכונה והתוצאות הנובעות מכך.
- הכרה בחשיבותה של איכות נתונים בהצלחת מודלים של למידת מכונה.
- היכרות עם צינור ה-ETL ותפקידו בהבטחת איכות הנתונים.
- רכישת מיומנויות לניקוי נתונים, עיבוד מקדים וטכניקות הנדסיות לשיפור איכות הנתונים המשמשים במודלים של ML.
- הבנת הרעיון והחשיבות של הנדסת תכונות בלמידת מכונה.
- לימוד טכניקות לבחירה, יצירה והמרת תכונות לשיפור הביצועים של מודלים של ML.
תודה שקראת! רוצה לשתף משהו שלא הוזכר למעלה? מחשבות? אתם מוזמנים להגיב למטה.
המדיה המוצגת במאמר זה אינה בבעלות Analytics Vidhya והיא משמשת לפי שיקול דעתו של המחבר.
מוצרים מקושרים
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://www.analyticsvidhya.com/blog/2023/01/the-role-of-data-quality-in-machine-learning/
- 1
- a
- מֵעַל
- דיוק
- מדויק
- תוספת
- כתובת
- באופן שלילי
- להשפיע על
- לאחר
- אלגוריתמים
- תמיד
- אמזון בעברית
- כמויות
- אנליזה
- אנליטית
- ניתוח
- אנליטיקה וידיה
- לנתח
- ו
- אחר
- ממשקי API
- יישומים
- מריחה
- מאמר
- מלאכותי
- בינה מלאכותית
- עוזרים
- אוסטרליה
- אוטומציה
- זמינות
- בחזרה
- מבוסס
- יסודות
- כי
- לפני
- להלן
- מוטב
- בֵּין
- קנדה
- אשר
- מכוניות
- שינוי
- שינויים
- משתנה
- בדיקה
- בכיתה
- ניקוי
- בבירור
- קוד
- לגבות
- איסוף
- שילוב
- לשלב
- הערה
- להשלים
- מורכב
- הענות
- רכיבים
- מחשבים
- מושג
- עִקבִי
- רציף
- להמיר
- הומר
- מדינה
- לִיצוֹר
- יוצרים
- קריטי
- מכריע
- יומי
- נתונים
- נקודות מידע
- עיבוד נתונים
- איכות נתונים
- מערך נתונים
- אחסון נתונים
- מסד נתונים
- מאגרי מידע
- יְוֹם
- קבלת החלטות
- החלטות
- תלוי
- יעד
- לקבוע
- קשה
- שיקול דעת
- שונה
- ירידה
- כפילויות
- מסחר אלקטרוני
- קל יותר
- יעיל
- מאפשר
- תומך
- הנדסה
- לְהַבטִיחַ
- מבטיח
- הבטחתי
- שלם
- שגיאה
- שגיאות
- במיוחד
- חיוני
- וכו '
- Ether (ETH)
- כל
- כל יום
- דוגמה
- Excel
- קיימים
- ניסיון
- תמצית
- הוֹצָאָה
- פייסבוק
- מאפיין
- תכונות
- שלח
- קבצים
- למלא
- סופי
- בסופו של דבר
- לממן
- ראשון
- מתאים
- קבוע
- טופס
- פוּרמָט
- חופשי
- החל מ-
- לתדלק
- פונקציה
- נוסף
- עתיד
- מין
- כללי
- בדרך כלל
- נוצר
- Go
- טוב
- לטפל
- טיפול
- שימושי
- בריאות
- לעזור
- עוזר
- כאן
- באיכות גבוהה
- הגבוה ביותר
- חַם
- איך
- איך
- אולם
- HTTPS
- בן אנוש
- לזהות
- זיהוי
- מיד
- פְּגִיעָה
- ליישם
- יישום
- לייבא
- חשיבות
- חשוב
- לשפר
- משפר
- שיפור
- in
- לֹא מְדוּיָק
- לכלול
- כולל
- כולל
- להגדיל
- מידע
- קלט
- תובנות
- השתלבות
- שלמות
- מוֹדִיעִין
- התערבות
- לערב
- IT
- איטרציות
- ג'ון
- ג'סון
- מפתח
- לדעת
- גָדוֹל
- עוֹפֶרֶת
- מוביל
- לִלמוֹד
- למידה
- ספריות
- סִפְרִיָה
- חי
- לִטעוֹן
- טוען
- לטווח ארוך
- הסתכלות
- מגרש
- מכונה
- למידת מכונה
- טכניקות למידת מכונות
- לעשות
- עשייה
- ניהול
- רב
- חוֹמֶר
- max-width
- מדיה
- מוּזְכָּר
- שיטות
- חסר
- ML
- מודל
- מודלים
- יותר
- רוב
- מספר
- שם
- טבע
- באופן שלילי
- חדש
- תכונות חדשות
- הבא
- רעש
- מספר
- מספרים
- ONE
- אופטימלי
- מָקוֹר
- מְקוֹרִי
- מיקור חוץ
- בבעלות
- דובי פנדה
- חלק
- דפוסי
- ביצועים
- צינור
- מישור
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- לְשַׂחֵק
- נקודות
- מדיניות
- עני
- נבואה
- התחזיות
- העריכה
- קופונים להדפסה
- בעיה
- תהליך
- תהליך
- מוצרים
- תכנות
- פרויקטים
- לאור
- פיתון
- איכות
- רכס
- טִוּוּחַ
- חי
- נתונים גולמיים
- חומר עיוני
- מוכן
- ממשי
- עולם אמיתי
- זמן אמת
- סיבות
- להפחית
- מפחית
- מכונה
- תקנון
- רגולטורים
- רלוונטי
- אמינות
- אָמִין
- הסרה
- להסיר
- הוסר
- הסרת
- לדרוש
- דורש
- נפתרה
- וכתוצאה מכך
- תוצאות
- סקירה
- הסיכון
- תפקיד
- שמור
- סולם
- מדע
- סקיקיט-לימוד
- בחירה
- מבחר
- נהיגה עצמית
- סדרה
- סט
- כמה
- שיתוף
- קצר
- הראה
- הופעות
- באופן משמעותי
- פָּשׁוּט
- פשוט
- מידה
- מיומנויות
- So
- מוצק
- כמה
- משהו
- מקורות
- ספציפי
- התמחות
- תקינה
- שלב
- צעדים
- אחסון
- חנות
- זרם
- מובנה
- הצלחה
- מוצלח
- כזה
- מַתְאִים
- מוּקָף
- מערכת
- תמונת חיה
- Takeaways
- נטילת
- טק
- ענקיות טק
- טכניקות
- מבחן
- בדיקות
- השמיים
- היסודות
- שֶׁלָהֶם
- שְׁלִישִׁי
- שְׁלוֹשָׁה
- דרך
- זמן
- סדרת זמן
- ל
- כלים
- עקיבות
- הדרכה
- טרנספורמציה
- טרנספורמציה
- הפיכה
- הובלה
- מגמות
- סוגים
- Uk
- להבין
- הבנה
- עדכון
- us
- להשתמש
- בְּדֶרֶך כְּלַל
- אימות
- ערכים
- שונים
- Vast
- גרסה
- וירטואלי
- מה
- מה
- אשר
- יצטרך
- קִנוּחַ
- בתוך
- לְלֹא
- זפירנט
- מתקרב