最終更新:2021年XNUMX月。
このブログは、ドキュメントワークフローを自動化するためのRPAツールでのOCRの使用に関する包括的な概要です。 最新の機械学習ベースのOCRテクノロジーがルールやテンプレートの設定を必要としない方法を探ります。

RPAまたはロボットプロセス自動化は、反復的なビジネスタスクを排除することを目的としたソフトウェアツールです。 より多くのCIOが、コストを削減し、従業員がより価値の高いビジネス作業に集中できるように支援するために、CIOに目を向けています。 例としては、ウェブサイトへのコメントへの返信や顧客の注文処理などがあります。 もう少し複雑なタスクには、次のようなドキュメントの処理が含まれます。 手書きフォーム & 請求書 – これらは通常、あるレガシー システムから別のレガシー システムに移動する必要があります。たとえば、電子メール クライアントを、データを抽出する必要がある SAP ERP システムに移動する必要があります。 これは問題のある部分です。
これらのドキュメントからデータをキャプチャするほとんどの OCR ツールはテンプレート ベースです (たとえば、 アビー Flexicapture)、半構造化ドキュメントではうまく拡張できません。 通常は API を提供する、新世代の機械学習ベースのソリューションがあります。
ドキュメントからキーと値のペアをキャプチャできる統合–エンタープライズシステムは通常、レガシーであり、外部APIと統合するために開かれていません。 一方、RPAは、フォルダーからのドキュメントの取り込みやERPまたはCRMへの結果の入力などのこれらのレガシーシステムワークフローを処理するように構築されています。
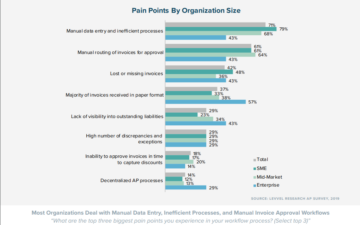
Robotic Process Automation(RPA)とMLはハイパーオートメーションに向かって進化しているため、ソフトウェアボットをMLと組み合わせて使用して、ドキュメント分類、抽出、光学式文字認識などの複雑なタスクを処理できます。 最近の調査では、RPAを使用してタスクの機能の29%のみを自動化することにより、財務部門だけで、人的エラーによって引き起こされる25,000時間以上のやり直しを節約でき、878,000人のフルタイムの組織で年間40ドルのコストがかかると言われています。時間会計スタッフ[1]。 このブログでは、RPAでOCRを使用する方法について学習し、ドキュメント理解ワークフローについて詳しく説明します。 以下は目次です。
定義と概要
一般に RPA は、ソフトウェア/ハードウェア ボットを介して管理タスクを自動化するのに役立つテクノロジーです。 これらのボットはユーザー インターフェイスを利用します。 人間と同じようにデータをキャプチャし、アプリケーションを操作します。 たとえば、RPA は、GUI で実行される一連のタスク (カーソルの移動、API への接続、データのコピー & ペーストなど) を確認し、同じ一連のアクションをコードに変換する RPA ワイヤーフレームで定式化できます。 さらに、これらのタスクは将来的には人間の介入なしで実行できるようになります。 光学式文字認識 (OCR) は、機能的なロボット プロセス オートメーション (RPA) ソリューションの重要な機能です。 このテクノロジーは、画像やテキストなどのさまざまなソースからテキストを読み取り、抽出するために使用されます。 pdfs 手動でキャプチャしなくてもデジタル形式に変換できます。
一方、ドキュメントの理解は、ドキュメントデータの読み取り、解釈、および操作を自動的に説明するために使用される用語です。 このプロセスで最も重要なのは、ソフトウェアボット自体がすべてのタスクを実行することです。 これらのボットは、人工知能と機械学習の力を活用して、ドキュメントをデジタルアシスタントとして理解します。 このように、ドキュメントの理解は、ドキュメント処理、AI、RPAの交差点で発生すると言えます。

ロボットがOCRとMLを使用してドキュメントを理解する方法を学ぶ方法
最初にドキュメントの理解について深く掘り下げる前に、ドキュメントの理解のためのロボットの役割について話しましょう。 これらの完全に目に見えないヘルパーは、私たちの生活をはるかに快適にします。 映画やシリーズとは異なり、これらのロボットは、デスクトップに座ってボタンを押してタスクを実行する物理デバイスや人工知能プログラムではありません。 これらは、私たちと同じようにアプリケーションを読んで使用することでドキュメントを処理するように訓練されたデジタルアシスタントと考えることができます。 機能面では、ロボットはプロセスのパフォーマンスと効率を向上させるのに優れています。 それでも、それらはスタンドアロンソフトウェアであるため、プロセスを評価して認知的決定を下すことはできません。 ただし、機械学習が正常に統合されると、ロボット工学はより動的で適応性のあるものになります。 たとえば、フロントオフィスとミドルオフィス全体でドキュメント処理、データ管理、およびその他の機能に使用されるロボットは、重複エントリの排除やプロセス内の不明なシステム例外の解決など、よりインテリジェントなアクションを実行します。 さらに、ロボットは、人工知能(AI)を使用して、ドキュメントからデータを読み取り、抽出、解釈、および操作するようにトレーニングされています。
企業がインテリジェントOCRをRPAと統合して、ワークフローを改善するにはどうすればよいですか
ドキュメントデータの抽出は、ドキュメントを理解するための重要なコンポーネントです。 このセクションでは、OCRをRPAと統合する方法、またはその逆の方法について説明します。 まず、テンプレート、スタイル、フォーマット、場合によっては言語の点で、さまざまな種類のドキュメントがあることを私たちは皆知っていました。 したがって、これらのドキュメントからデータを抽出するために単純なOCR手法に依存することはできません。 この問題に対処するために、OCR内でルールベースのアプローチとモデルベースのアプローチの両方を使用して、さまざまなドキュメント構造からのデータを処理します。 次に、OCRを実行している企業が、ドキュメントの種類に基づいてRPAを既存のシステムに統合する方法を説明します。
構造化されたドキュメント: このタイプのドキュメントでは、レイアウトとテンプレートは通常固定されており、ほぼ一貫しています。 たとえば、パスポートや運転免許証などの政府発行のIDを使用してKYCを行う組織について考えてみます。 これらのドキュメントはすべて同一であり、ID番号、人の名前、年齢、および同じ位置にある他のいくつかのフィールドと同じフィールドがあります。 ただし、詳細のみが異なります。 テーブルのオーバーフローやファイルされていないデータなど、いくつかの制約がある場合があります。
通常、推奨されるアプローチでは、テンプレートまたはルールベースのエンジンを使用して、構造化ドキュメントの情報を抽出します。 これらには、正規表現または単純な位置マッピングとOCRを含めることができます。 したがって、ソフトウェアロボットを統合して情報抽出を自動化するには、既存のテンプレートを使用するか、構造化データのルールを作成します。 ルールベースのアプローチを使用する場合の欠点がXNUMXつあります。これは、固定パーツに依存しているため、フォーム構造のわずかな変更でもルールが破損する可能性があるためです。
半構造化ドキュメント: これらの文書には同じ情報が含まれていますが、配置されている位置が異なります。 たとえば、次のように考えてみましょう 請求書 8 ~ 12 個の同一フィールドが含まれます。 少しで 請求書、販売者の住所は上部にある場合もあれば、下部にある場合もあります。 通常、これらのルールベースのアプローチでは高い精度は得られません。 そのため、OCR を使用した情報抽出のために機械学習および深層学習モデルを取り入れています。 あるいは、場合によっては、ルールと ML モデルの両方を含むハイブリッド モデルを使用することもできます。 事前トレーニング済みモデルとしてよく知られているのは、文書内の情報抽出用の FastRCNN、Attention OCR、Graph Convolutions などです。 ただし、これらのモデルにもいくつかの欠点があります。 したがって、精度や信頼スコアなどの指標を使用してアルゴリズムのパフォーマンスを測定します。 モデルは具体的なルールに基づいて動作するのではなく、パターンを学習しているため、修正直後に最初は間違いを犯す可能性があります。 ただし、これらの欠点を解決するには、ML モデルが処理するサンプルが増えるほど、精度を確保するために学習するパターンが増えます。
非構造化ドキュメント: 現在の RPA は非構造化データを直接管理できないため、最初にロボットが OCR を使用して構造化データを抽出して作成する必要があります。 構造化ドキュメントや半構造化ドキュメントとは異なり、非構造化データにはキーと値のペアがほとんどありません。 たとえば、いくつかの場合 請求書、キー名のないどこかに販売者の住所が表示されます。 同様に、日付や請求書 ID などの他のフィールドでも同じことが観察されます。 ML モデルがこれらを正確に処理するには、ロボットは書かれたテキストを電子メール、電話番号、住所などの実用的なデータに変換する方法を学習する必要があります。その後、モデルは 7 桁または 10 桁の数字パターンを抽出する必要があることを学習します。電話番号と、XNUMX 桁のコードとさまざまな名詞を含む巨大なテキストがテキストとして表示されます。 これらのモデルをより正確にするために、固有表現認識や単語埋め込みなどの自然言語処理 (NLP) の技術を使用することもできます。
全体として、ドキュメントを理解するには、最初にデータを理解してから、RPAを使用してOCRを実装することが不可欠です。 次に、プロセスを段階的にマッピングするのではなく、ルールと機械学習アルゴリズムを統合することで、前述の強力なOCR機能で発生するプロセスを記録することで、ロボットに「私と同じように行う」ように教えることができます。 ソフトウェアロボットは、画面上のクリックとアクションを追跡し、それらを編集可能なワークフローに変換します。 あなたが完全にローカルプログラムで働いているなら、それはあなたが知る必要があるのと同じくらいです。
RPA開発者が直面するOCRの課題
さまざまなドキュメントのOCRRをRPAと統合する方法を見てきましたが、ロボットが適切に処理する必要がある課題がいくつかあります。 今すぐ話し合いましょう!
- 弱いデータまたは一貫性のないデータ: データは、ドキュメントの理解において重要な役割を果たします。 ほとんどの場合、ドキュメントはカメラを使用してスキャンされ、テキストスキャン中にドキュメントのフォーマットが失われる可能性があります(つまり、太字、斜体、下線が常に認識されるとは限りません)。 OCRが間違った方法でテキストを抽出すると、スペルミスや不規則な段落の区切りが発生し、ロボットの全体的なパフォーマンスが低下する場合があります。 したがって、すべての欠落値を処理し、より高い精度でデータをキャプチャすることは、OCRのより高い精度を達成するために不可欠です。
- ドキュメントのページの向きが正しくありません: ページの向きと歪度も、OCRの誤ったテキスト修正につながる一般的な問題のXNUMXつです。 これは通常、データ収集フェーズ中にドキュメントが誤ってスキャンされた場合に発生します。 これを克服するには、ページへの自動調整、自動フィルタリングなどのいくつかの機能をロボットに宣言して、スキャンしたドキュメントの品質を向上させ、出力で正しいデータを受信できるようにする必要があります。
- 統合の問題: すべてのRPAツールがリモートデスクトップ環境で適切に機能するわけではありません。自動化でクラッシュや重大な問題が発生します。 さらに、RPA開発者は、特定のケースに最適なOCRソリューションを知る必要があります。 また、特定の自動化ツールを使用するには、RPA開発者はMicrosoft、Googleによって作成された限られたOCRテクノロジーのみを選択する必要があります。 したがって、カスタムアルゴリズムとモデルを統合するのは難しい場合があります。
- すべてのテキストはスクランブルされたテキストです。 実際のユースケースでは、一般的なOCRによってキャプチャされたテキストはすべてスクランブルされており、ボットが重要な操作を実行するために使用できる意味のある情報はありません。 RPA開発者は、有用なアプリケーションを構築できるようにするために強力なMLサポートを必要としています。
ドキュメント理解ワークフローのパイプライン
前のセクションでは、ボットがさまざまなタイプのドキュメントに対してOCRを実行するのにどのように役立つかを見てきました。 ただし、OCRは、画像やその他のファイルをテキストに変換する手法にすぎません。 ここで、このセクションでは、ドキュメントの収集から、最終的に意味のある情報を目的の形式で保存するまでのドキュメント理解ワークフローについて説明します。

- ボットを使用してフォルダーからドキュメントを取り込みます。 これは、ボットを介してドキュメントを理解するための最初のステップです。 ここでは、クラウドプラットフォーム(APIを使用)またはローカルマシンのいずれかにあるドキュメントをフェッチします。 場合によっては、ドキュメントがWebページ上にある場合、ボットを介してスクリプトのスクレイピングを自動化して、タイムリーにドキュメントをフェッチできます。
- 伝票タイプ データを取得した後は、ドキュメントの種類とシステムに保存される形式を理解することが重要です。これは、さまざまなソースから次のようなさまざまなファイル形式でデータを受け取ることがあるためです。 PDF、PNG、JPG。 ファイルの種類だけでなく、携帯電話のカメラでドキュメントをスキャンする場合、画像の歪み、回転、明るさ、低解像度などのいくつかの困難な問題も処理する必要がある場合があります。 したがって、ボットがこれらのドキュメントを構造化、半構造化、または非構造化のカテゴリに分類し、汎用形式で保存できるようにする必要があります。 分類タスクは、ドキュメントをテンプレートと比較し、フォント、言語、キーと値のペアの存在、テーブルなどの特徴を分析することによって実現されます。
- OCRを使用したデータの抽出: さて、ボットがドキュメントを一般的な形式に配置して分類したので、OCR技術を使用してドキュメントをデジタル化する時が来ました。 これにより、テキストとその位置が画像からの座標になります。 これは、後続のステップのためにドキュメントとデータを標準化するのに役立ちます。 また、OCRソフトウェアが「t」と「i」、「0」と「O」などの文字を正しく区別できない場合もあります。 OCRテクノロジーがドキュメントの品質や元の形式に基づいてドキュメントのニュアンスを分析できない場合、OCRソフトウェアを使用して回避したいエラーそのものが新たな頭痛の種になる可能性があります。 ここで機械学習が登場します。これについては、次のステップで説明します。
- ボットを使用したインテリジェントOCRのML / DLの活用: データがデジタル化された後、OCRソフトウェアは、処理しているドキュメントの種類と関連性を理解する必要があります。 しかし、従来のOCRソフトウェアは、ドキュメント分類の取り組みを拡大するのに苦労する可能性があります。 したがって、ソフトウェアボットは、機械学習と深層学習の手法を活用してOCRをよりインテリジェントにすることにより、認知能力をトレーニングする必要があります。 MLベースのOCRソリューションは、ドキュメントタイプを識別し、ビジネスで使用されている既知のドキュメントタイプと照合できます。 また、非構造化ドキュメント内のテキストのブロックを解析して理解することもできます。 ソリューションがドキュメント自体について詳しく知ると、意図と意味に基づいて関連情報の抽出を開始できます。
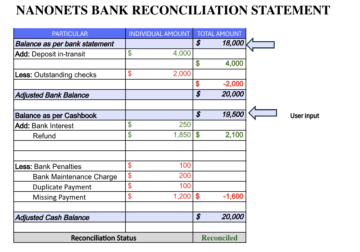
- より良いデータ抽出と分類: データ抽出は、ドキュメント理解の中核です。 このステップのRPAとOCRの統合に関する前のセクションで説明したように、ドキュメントのタイプに基づいてデータ抽出手法を選択します。 RPAを使用すると、ルールベース、MLベース、ハイブリッドモデルのOCR手法を問わず、使用するエクストラクタを簡単に構成できます。 情報抽出後に返される信頼性とパフォーマンスのメトリックに基づいて、ソフトウェアロボットは、さらに分析するためにそれらを目的の形式で保存します。 以下は、UIPathによってRPAツールでエクストラクターを構成して信頼レベルを設定する方法のイメージです。

6. 検証と洞察力の強化:OCRおよび機械学習モデルは、情報抽出に関してXNUMX%正確ではないため、ロボットの助けを借りて人間の介入の層を追加することで問題を解決できます。 この検証が機能する方法は、ロボットが低精度と例外を処理するときはいつでも、従業員がデータの検証または例外の処理の要求を受信し、クリックの問題で不確実性を解決できるアクションセンターにすぐに通知を出すことです。 さらに、人工知能の可能性を解き放ち、時間の経過とともにデータを文書化して予測を行い、詐欺、重複、その他のエラーを示す可能性のある潜在的な異常を特定できます。
ロボットとドキュメント理解を統合する利点
- プロセスの自動化: ドキュメントを理解するためにボットを統合する主な理由は、最初から最後までプロセス全体を自動化することです。 私たちがする必要があるのは、ボットが学び、座って、リラックスするためのワークフローを作成することです。 検証プロセス中に、エラーや不正が特定された場合にボットから通知される問題に対処する必要がある場合があります。
- 機械学習のボット: 自動化プロセス中に、ボットを機械学習に対して回復力のあるものにすることができます。 つまり、ロボットは機械学習モデルのパフォーマンスを学習し、それによってモデルを強化して、ドキュメントのテキストおよび情報抽出の精度とパフォーマンスを向上させることができます。
- 幅広いドキュメント処理の処理: テーブルや情報抽出などの一般的なタスクでは、さまざまなタイプのドキュメントに対してさまざまなディープラーニングパイプラインを作成する必要があります。 これにより、複数のアプリケーションを構築し、さまざまなモデルをさまざまなサーバーにデプロイすることになり、多大な労力と時間が必要になります。 ボットがさまざまなドキュメントの全体像にある場合、ボットがそれらを分類し、さまざまなタスクに適切なモデルを使用できるパイプラインはXNUMXつしかありません。 また、APIを介してさまざまなサービスを統合し、データのフェッチに関して他の組織と通信することもできます。
- 導入が簡単: パイプラインが作成された後のドキュメントの理解のために、展開プロセスはわずかXNUMX分です。 トレーニング後にボットによってAPIをエクスポートすることも、ローカルシステムで使用できるカスタムRPAソリューションを構築することもできます。 このタイプの展開は、企業を最適化し、最小限のリスクで支出を削減することもできます。
ナノネットに入る
NanoNets は、ユーザーがデータをキャプチャできるようにする機械学習プラットフォームです。 請求書、領収書、その他の書類をテンプレートの設定なしで作成できます。 当社では最先端のディープラーニングとコンピュータービジョンアルゴリズムをバックグラウンドで実行しており、OCR、テーブル抽出、キーと値のペアの抽出など、あらゆる種類の文書理解タスクを処理できます。 これらは通常、API としてエクスポートされるか、さまざまなユースケースに基づいてオンプレミスにデプロイできます。 以下にいくつかの例を示します。
- 請求書モデル: 主要なフィールドを特定します。 請求書 購入者の名前、請求書ID、日付、金額など
- 領収書モデル:売り手の名前、番号、日付、金額など、領収書から重要なフィールドを特定します。
- 運転免許証(米国):ライセンス番号、DOB、有効期限、発行日などの主要なフィールドを特定します。
- 履歴書:経験、教育、スキルセット、候補者情報などを抽出します。
これらのワークフローを高速かつ堅牢にするために、テンプレートを使用せずにドキュメントをシームレスに自動化する RPA ツールである UiPath を使用しています。 次のセクションでは、ドキュメントを理解するために UiPath Connect と Nanonets を使用する方法を説明します。 RPA 市場の 3 大プレーヤーは、UiPath、Automation Anywhere、 ブループリズム。 このブログはUipathに焦点を当てています。
UiPathを使用したNanoNet
前のセクションで、ドキュメント理解パイプラインを作成する方法を学びました。 さまざまな時点でさまざまなタスクにさまざまなアプローチとアルゴリズムがあるため、OCR、RPA、機械学習の基本的な知識が必要です。 また、テンプレートを理解するニューラルネットワークの構築、トレーニング、およびそれらの展開に多大な労力を費やす必要があります。 したがって、ドキュメントのアップロード、分類、OCRの構築、MLモデルの統合に至るまで、すべてを快適に自動化するために、NanonetsはUi Pathに取り組んでおり、ドキュメントを理解するためのシームレスなパイプラインを作成しています。 以下は、これがどのように機能するかの画像です。

それでは、これらのそれぞれを確認して、NanonetをUiPathと統合する方法を学びましょう。
ステップ1:UiPathにサインアップし、UiPathStudioをダウンロードする
ワークフローを作成するには、まずUiPathでアカウントを作成する必要があります。 既存のユーザーの場合は、アカウントに直接ログインして、UiPathダッシュボードをリダイレクトできます。 次に、無料のUiPath Studio(Community Edition)をダウンロードしてインストールする必要があります。
ステップ2:Nanonetsコンポーネントをダウンロードする
次に、 請求書処理パイプライン、以下のリンクからNanonetsコネクタをダウンロードする必要があります。
以下は、UiPathマーケットプレイスとNanonetsコンポーネントのスクリーンショットです。 また、これをダウンロードするには、WindowsオペレーティングシステムからUiPathにログインしていることを確認してください。

ダウンロードしたファイルには、以下のファイルが含まれている必要があります。
UiPath OCR Predict ├── Main.xaml
└── project.json
手順3:Main.xamlファイルのNanonetsコンポーネントを開く
Nanonets UiPathが機能しているかどうかを確認するには、Ui Path Studioを使用して、ダウンロードしたNanonetsコンポーネントからMain.xmlファイルを開くことができます。 次に、ドキュメント処理用に作成済みのパイプラインを確認できます。

ステップ4:Nanonets APPからモデルID、APIキー、APIエンドポイントを収集します
次に、Nanonets APPからトレーニング済みのOCRモデルを使用して、モデルID、APIキー、およびエンドポイントを収集できます。 以下は、それらをすばやく見つけるための詳細です。
モデルID: Nanonetsアカウントにログインし、「マイモデル」に移動します。 新しいモデルをトレーニングするか、既存のモデルのアプリケーションIDをコピーできます。

APIエンドポイント: 既存のモデルを選択し、[統合]をクリックしてAPIエンドポイントを見つけることができます。 以下は、エンドポイントがどのように見えるかの例です。
https://app.nanonets.com/api/v2/OCR/Model/XXXXXXX-4840-4c27-8940-d3add200779e/LabelUrls/

3. APIキー:[APIキー]タブに移動すると、既存のAPIキーをコピーするか、新しいAPIキーを作成できます。

ステップ5:HTTPリクエストを追加して、メソッドと変数をUIパスに取得します
モデルをナノネットからUIパスに統合するには、最初にHTTPリクエストをクリックして、左側のナビゲーションの[入力]セクションにあるEndPointを追加します。 以下はスクリーンショットです。

後で、すべての変数を追加して、UiPathスタジオからNanonetsAPIへの接続を確立します。 このセクションは、下部のペインの「[変数]タブ」にあります。 以下はスクリーンショットです。ここで、APIキー、エンドポイント、モデルのモデルIDを更新/コピーする必要があります。

ステップ6:予測用のファイルの場所を追加する
最後に、下のスクリーンショットに示すように、[属性]タブでファイルの場所を追加し、上部のナビゲーションの再生ボタンを押して出力を予測できます。

出来上がり! 以下のスクリーンショットでリクエストしたドキュメントの出力は次のとおりです。 さらに処理するには、ファイルの場所を追加して実行ボタンを押すだけです。

ステップ7–出力をCSV / ERPにプッシュする
最後に、出力を目的の形式にカスタマイズするために、Main.XMLファイルのパイプラインに新しいブロックを追加できます。 オフラインファイルまたはAPI呼び出しを介して、これを既存のERPシステムにプッシュすることもできます。

ヘルプが必要な場合は、support @ nanonets.comまでお問い合わせください。
WEBINAR

来週の火曜日にRPAを使用したOCRに関するウェビナーにご参加ください。 ここに登録してください。
参考文献
【1] ガートナーは、ロボットプロセスの自動化により財務部門が年間25,000時間の回避可能な作業を節約できると述べています
【5] https://www.uipath.com/product/document-understanding
【6] 請求書OCRのUiPathワークフローでのNanoNetの使用
参考文献
あなたは私たちの最新の投稿に興味があるかもしれません:
アップデート:
文書理解における OCR、RPA の使用と影響に関する読み物を追加しました。
出典:https://nanonets.com/blog/ocr-with-rpa-and-document-understanding-uipath/
- '
- &
- 000
- 2021
- 7
- 会計
- Action
- 利点
- AI
- アルゴリズム
- アルゴリズム
- すべて
- 分析
- API
- API
- アプリ
- 申し込み
- 宝品
- 人工知能
- 人工知能(AI)
- 人工知能と機械学習
- オートメーション
- どこでも自動化
- BEST
- 最大の
- ブログ
- ロボット
- ボット
- ビルド
- 建物
- ビジネス
- カメラ
- 例
- 原因となる
- 生じました
- 文字認識
- 分類
- クラウド
- クラウドプラットフォーム
- コード
- 認知
- 収集
- 注釈
- コマンドと
- コミュニティ
- 企業
- コンポーネント
- Computer Vision
- 信頼
- 中身
- 補正
- コスト
- ダッシュボード
- データ
- データ管理
- 取引
- 深い学習
- Developer
- 開発者
- Devices
- デジタル
- ドキュメント
- ダッジ
- 運転
- 教育
- 効率
- 社員
- エンドポイント
- Enterprise
- 等
- データを抽出する
- 抽出
- 特徴
- 特徴
- フィールズ
- 最後に
- ファイナンス
- 名
- フォーカス
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- 詐欺
- 無料版
- 未来
- ガートナー
- GIF
- 良い
- でログイン
- ガイド
- ハンドリング
- 頭痛
- こちら
- ハイ
- 認定条件
- How To
- HTTPS
- 巨大な
- 人間
- ハイブリッド
- 識別する
- 画像
- 影響
- 増える
- info
- 情報
- 情報抽出
- インテリジェンス
- 意図
- 問題
- IT
- キー
- 知識
- KYC
- 言語
- 最新の
- つながる
- 主要な
- LEARN
- 学んだ
- 学習
- レベル
- 活用します
- ライセンス
- 限定的
- LINK
- ローカル
- 場所
- 機械学習
- 管理
- 市場
- 市場
- 一致
- だけど
- マーチャント
- メトリック
- Microsoft
- ML
- 動画
- 自然言語
- 自然言語処理
- ナビゲーション
- ネットワーク
- ニューラル
- ニューラルネットワーク
- NLP
- 通知
- 番号
- OCR
- 開いた
- オペレーティング
- オペレーティングシステム
- 業務執行統括
- 光学式文字認識
- 注文
- その他
- その他
- パスポート
- パフォーマンス
- 画像
- プラットフォーム
- 人気
- 投稿
- 電力
- 精度
- 予測
- プロセスオートメーション
- プログラム
- プロジェクト
- 品質
- 提起
- 範囲
- RE
- リーディング
- 減らします
- 結果
- レビュー
- ロボット
- ロボットプロセス自動化
- ロボット工学
- ロボット
- rpa
- ルール
- ラン
- ランニング
- 樹液
- 節約
- 規模
- スキャニング
- こすること
- 画面
- シームレス
- 販売
- シリーズ
- サービス
- セッションに
- 簡単な拡張で
- So
- ソフトウェア
- ソフトウェアボット
- ソリューション
- 解決する
- 過ごす
- start
- 都道府県
- 勉強
- サポート
- システム
- テーブル抽出
- テクノロジー
- テクノロジー
- 未来
- 時間
- top
- トレーニング
- ui
- UiPath
- アップデイト
- us
- USA
- ユースケース
- users
- 値
- 対
- ビジョン
- ウェブ
- ウェブサイト
- 誰
- ウィンドウズ
- 以内
- 仕事
- ワークフロー
- 作品
- XML
- 年
- ユーチューブ