組織は、データレイクを上に構築することを選択しました Amazon シンプル ストレージ サービス (Amazon S3) 長年にわたって。 データ レイクは、組織がさまざまなチームによって生成されたすべての組織データを、ビジネス ドメイン全体で、さまざまな形式から、さらには履歴にわたって保存するための最も一般的な選択肢です。 によると 調査、平均的な企業では、データ量が年間 50% を超える速度で増加しており、通常、分析のために平均 33 の固有のデータ ソースを管理しています。
チームは、同じ抽出、変換、読み込み (ETL) パターンを使用して、リレーショナル データベースから何千ものジョブを複製しようとすることがよくあります。 ジョブの状態を維持し、これらの個々のジョブをスケジュールするには、多くの労力が必要です。 このアプローチは、チームがほとんど変更を加えずにテーブルを追加し、最小限の労力でジョブ ステータスを維持するのに役立ちます。 これにより、開発タイムラインが大幅に改善され、ジョブの追跡が容易になります。
この投稿では、Apache Iceberg と AWSグルー.
ソリューションのアーキテクチャ
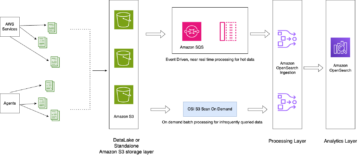
データレイクは 通常は組織化された データの 3 つのレイヤーに個別の SXNUMX バケットを使用します。元の形式のデータを含む生のレイヤー、消費用に最適化された中間処理済みデータを含むステージ レイヤー、および特定のユース ケースの集計データを含む分析レイヤーです。 未加工レイヤーでは、テーブルは通常、データ ソースに基づいて編成されますが、ステージ レイヤーのテーブルは、所属するビジネス ドメインに基づいて編成されます。
この投稿は、 AWS CloudFormation データレイク raw レイヤーの 3 つのデータ ソースの Amazon SXNUMX パスを読み取る AWS Glue ジョブをデプロイし、ステージ レイヤーの Apache Iceberg テーブルにデータを取り込むテンプレート データレイクフレームワークの AWS Glue サポート. ジョブは、未加工レイヤーのテーブルが次のように構造化されていることを期待しています AWSデータベース移行サービス (AWS DMS) は、スキーマ、テーブル、データ ファイルの順に取り込みます。
このソリューションは AWS SystemsManagerパラメータストア テーブル構成用。 主キー、パーティション、関連するビジネス ドメインなどの情報を含め、処理するテーブルとその方法を指定して、このパラメーターを変更する必要があります。 ジョブはこの情報を使用して、すべてのビジネス ドメインのデータベースを自動的に作成し (まだ存在しない場合)、Iceberg テーブルを作成し、データの読み込みを実行します。
最後に、 アマゾンアテナ Iceberg テーブルのデータをクエリします。
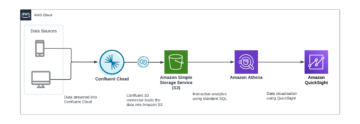
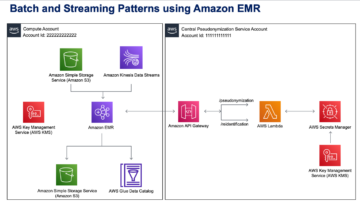
次の図は、このアーキテクチャを示しています。

この実装には、次の考慮事項があります。
- このソリューションを使用してレプリケートするには、データ ソースのすべてのテーブルに主キーが必要です。 主キーは、単一の列または複数の列を持つ複合キーにすることができます。
- アップサートを必要としない、または主キーを持たないテーブルがデータ レイクに含まれている場合は、それらをパラメーター構成から除外し、従来の ETL プロセスを実装してそれらをデータ レイクに取り込むことができます。 それはこの投稿の範囲外です。
- 取り込む必要がある追加のデータ ソースがある場合は、複数の CloudFormation スタックをデプロイして、各データ ソースを XNUMX つずつ処理できます。
- AWS Glue ジョブは、AWS DMS が全ロードタスクを完了した後に実行される初期ロードと、AWS DMS によってキャプチャされた変更データキャプチャ (CDC) ファイルを適用するスケジュールで実行される増分ロードの XNUMX つのフェーズでデータを処理するように設計されています。 インクリメンタル処理は、 AWS Glue ジョブのブックマーク.
このチュートリアルを完了するには、次の XNUMX つの手順があります。
- AWS DMS のソース エンドポイントをセットアップします。
- AWS CloudFormation を使用してソリューションをデプロイします。
- AWS DMS レプリケーション タスクを確認します。
- 必要に応じて、暗号化と復号化のアクセス許可を追加するか、 AWSレイクフォーメーション.
- Parameter Store のテーブル構成を確認します。
- 初期データ読み込みを実行します。
- 増分データのロードを実行します。
- テーブルの取り込みを監視します。
- 増分バッチ データの読み込みをスケジュールします。
前提条件
このチュートリアルを開始する前に、Iceberg について十分に理解している必要があります。 そうでない場合は、次の手順に従って単一のテーブルをレプリケートすることから始めることができます。 ApacheIcebergとAWSGlueを使用して、データレイクにCDCベースのUPSERTを実装します. さらに、以下を設定します。
AWS DMS のソース エンドポイントをセットアップする
AWS DMS タスクを作成する前に、ソース データベースに接続するためのソース エンドポイントを設定する必要があります。
- AWS DMSコンソールで、 エンドポイント ナビゲーションペインに表示されます。
- 選択する エンドポイントを作成する.
- データベースが Amazon RDS で実行されている場合は、 RDS DB インスタンスを選択をクリックし、リストからインスタンスを選択します。 それ以外の場合は、ソース エンジンを選択し、次のいずれかの方法で接続情報を提供します。 AWSシークレットマネージャー または手動で。
- エンドポイント識別子、エンドポイントの名前を入力します。 たとえば、source-postgresql.
- 選択する エンドポイントを作成する.
AWSCloudFormationを使用してソリューションをデプロイする
提供されたテンプレートを使用して CloudFormation スタックを作成します。 次の手順を完了します。
- 選択する スタックの起動:

- 選択する Next.
- などのスタック名を指定します。
transactionaldl-postgresql. - 必要なパラメーターを入力します。
- DMSS3エンドポイントIAMRoleARN – AWS DMS が Amazon S3 にデータを書き込むための IAM ロール ARN。
- レプリケーションインスタンスArn – AWS DMS レプリケーションインスタンスの ARN。
- S3バケットステージ – データ レイクのステージ レイヤーに使用される既存のバケットの名前。
- S3バケットグルー – AWS Glue スクリプトを保存するための既存の S3 バケットの名前。
- S3バケット生 – データ レイクの raw レイヤーに使用される既存のバケットの名前。
- ソースエンドポイントArn – 以前に作成した AWS DMS エンドポイント ARN。
- ソース名 – レプリケートするデータ ソースの任意の識別子 (たとえば、
postgres)。 これは、データが保存されるデータレイク (生レイヤー) の S3 パスを定義するために使用されます。
- 次のパラメータは変更しないでください。
- SourceS3Bucketブログ – 提供された AWS Glue スクリプトが保存されているバケット名。
- SourceS3BucketPrefix – 提供された AWS Glue スクリプトが保存されるバケットのプレフィックス名。
- 選択する Next 二度。
- 選択 AWS CloudFormationがカスタム名でIAMリソースを作成する可能性があることを認めます。
- 選択する スタックを作成.
約 5 分後、CloudFormation スタックがデプロイされます。
AWS DMS レプリケーション タスクを確認する
AWS CloudFormation のデプロイにより、AWS DMS ターゲット エンドポイントが作成されました。 3 つの特定のエンドポイント設定により、Amazon SXNUMX で必要に応じてデータが取り込まれます。
- AWS DMSコンソールで、 エンドポイント ナビゲーションペインに表示されます。
- で始まるエンドポイントを検索して選択します
dmsIcebergs3endpoint. - エンドポイントの設定を確認します。
DataFormatとして指定されますparquet.TimestampColumnName列を追加しますlast_update_timeAmazon S3 でのレコードの作成日。

デプロイでは、次で始まる AWS DMS レプリケーション タスクも作成されます。 dmsicebergtask.
- 選択する レプリケーション タスク をクリックして、タスクを検索します。
あなたはそれを見るでしょう タスクタイプ としてマークされています 全負荷、進行中のレプリケーション. AWS DMS は、既存のデータの最初の全ロードを実行し、ソース データベースに対して実行された変更を含む増分ファイルを作成します。
ソフトウェア設定ページで、下図のように マッピング規則 タブには、次の XNUMX 種類のルールがあります。
- ソース データベースから取り込まれるソース スキーマとテーブルの名前を含む選択ルール。 デフォルトでは、前提条件で提供されるサンプル データベースを使用します。
dms_sample、およびキーワード % を持つすべてのテーブル。 - Amazon S3 のターゲット ファイルにスキーマ名とテーブル名を列として含む XNUMX つの変換ルール。 これは AWS Glue ジョブで使用され、データ レイク内のファイルが対応するテーブルを認識します。
独自のデータ ソース用にこれをカスタマイズする方法の詳細については、次を参照してください。 選択ルールとアクション.

タスクの準備を完了するために、いくつかの構成を変更しましょう。
- ソフトウェア設定ページで、下図のように メニュー、選択 修正します.
- タスク設定 セクション 全ロード完了後にタスクを停止、選択する キャッシュされた変更を適用した後に停止する.
このようにして、初期ロードと増分ファイル生成を XNUMX つの異なるステップとして制御できます。 この XNUMX ステップのアプローチを使用して、AWS Glue ジョブをステップごとに XNUMX 回実行します。
- タスクログ、選択する CloudWatch ログをオンにする.
- 選択する Save.
- データベース移行タスクのステータスが次のように表示されるまで、約 1 分間待ちます。 レディ.
暗号化と復号化または Lake Formation のアクセス許可を追加します
必要に応じて、暗号化と復号化または Lake Formation のアクセス許可を追加できます。
暗号化と復号化のアクセス許可を追加する
raw レイヤーとステージ レイヤーに使用される S3 バケットが暗号化されている場合 AWSキー管理サービス (AWS KMS) カスタマー管理キーの場合、AWS Glue ジョブがデータにアクセスできるようにアクセス許可を追加する必要があります。
Lake Formation のアクセス許可を追加する
Lake Formation を使用してアクセス許可を管理している場合は、AWS Glue ジョブが IAM ロールを通じてドメインのデータベースとテーブルを作成できるようにする必要があります。 GlueJobRole.
- データベースを作成する権限を付与します (手順については、 データベースの作成).
- にSUPER権限を付与します
defaultデータベース。 - データの場所のアクセス許可を付与する.
- データベースを手動で作成する場合は、テーブルを作成するための権限をすべてのデータベースに付与します。 参照する Lake Formation コンソールと名前付きリソース メソッドを使用してテーブルのアクセス許可を付与する or LF-TBAC メソッドを使用した Data Catalog 権限の付与 ユースケースに応じて。
最初のデータ ロードを実行する後の手順を完了したら、コンシューマーがテーブルをクエリするためのアクセス許可も必ず追加してください。 ジョブ ロールは、作成されたすべてのテーブルの所有者になり、データ レイク管理者は追加のユーザーに付与を実行できます。
Parameter Store のテーブル構成を確認する
Iceberg テーブルへのデータ取り込みを実行する AWS Glue ジョブは、Parameter Store で提供されるテーブル仕様を使用します。 次の手順を実行して、自動的に構成されたパラメーター ストアを確認します。 必要に応じて、必要に応じて変更してください。
- Parameter Store コンソールで、 私のパラメータ ナビゲーションペインに表示されます。
CloudFormation スタックは XNUMX つのパラメーターを作成しました。
iceberg-configジョブ構成用iceberg-tablesテーブル構成用
- パラメータを選択してください 氷山テーブル.
JSON 構造には、AWS Glue がデータを読み取り、ターゲット ドメインで Iceberg テーブルを書き込むために使用する情報が含まれています。
- テーブルごとに XNUMX つのオブジェクト – オブジェクトの名前は、スキーマ名、ピリオド、およびテーブル名を使用して作成されます。 例えば、
schema.table. - 主キー – これは、ソース表ごとに指定する必要があります。 単一の列またはカンマ区切りの列のリスト (スペースなし) を指定できます。
- パーティション列 – オプションで、ターゲット表の列をパーティション化します。 分割テーブルを作成したくない場合は、空の文字列を指定してください。 それ以外の場合は、使用する単一の列またはカンマ区切りの列のリスト (スペースなし) を指定します。
- 独自のデータ ソースを使用する場合は、次の JSON コードを使用し、提供されたテンプレートの CAPS 内のテキストを置き換えます。 提供されているサンプル データ ソースを使用している場合は、既定の設定をそのまま使用します。
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- 選択する 変更を保存します.
初期データ読み込みを実行する
必要な構成が完了したので、初期データを取り込みます。 このステップには、ソース リレーショナル データベースからデータ レイクの raw レイヤーへのデータの取り込み、データ レイクのステージ レイヤーでの Iceberg テーブルの作成、Athena を使用した結果の検証という XNUMX つの部分が含まれます。
データレイクの raw レイヤーにデータを取り込む
Iceberg を使用して、リレーショナル データ ソース (提供されているサンプルを使用している場合は PostgreSQL) からトランザクション データ レイクにデータを取り込むには、次の手順を実行します。
- AWS DMSコンソールで、 データベース移行タスク ナビゲーションペインに表示されます。
- 作成したレプリケーション タスクを選択し、 メニュー、選択 再起動/再開.
- 複製タスクが完了するまで約 5 分待ちます。 取り込まれたテーブルを監視できます 統計 レプリケーション タスクのタブ。

数分後、タスクはメッセージで終了します フルロード完了.
- Amazon S3 コンソールで、raw レイヤーとして定義したバケットを選択します。
AWS DMS で定義された S3 プレフィックスの下 (たとえば、 postgres)、次の構造を持つフォルダーの階層が表示されます。
- スキーマ
- テーブル名
LOAD00000001.parquetLOAD0000000N.parquet
- テーブル名

S3 バケットが空の場合は、確認してください AWS Database Migration Service での移行タスクのトラブルシューティング AWS Glue ジョブを実行する前に。
データを作成して Iceberg テーブルに取り込む
ジョブを実行する前に、CloudFormation スタックの一部として提供される AWS Glue ジョブのスクリプトをナビゲートして、その動作を理解しましょう。
- AWS Glue Studioコンソールで、 Jobs > Create New Job ナビゲーションペインに表示されます。
- で始まる仕事を探す
IcebergJob-および CloudFormation スタック名のサフィックス (例:IcebergJob-transactionaldl-postgresql). - ジョブを選択します。

ジョブ スクリプトは必要な構成を Parameter Store から取得します。 関数 getConfigFromSSM() データを読み書きする必要があるソース バケットやターゲット バケットなど、ジョブ関連の構成を返します。 変数 ssmparam_table_values データ ドメイン、テーブル名、パーティション列、取り込む必要のあるテーブルの主キーなど、テーブル関連の情報が含まれています。 次の Python コードを参照してください。
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']このスクリプトは、my_catalog として定義された Iceberg の任意のカタログ名を使用します。 これは、Spark 構成を使用して AWS Glue データ カタログに実装されるため、my_catalog を指す SQL 操作がデータ カタログに適用されます。 次のコードを参照してください。
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
このスクリプトは、Parameter Store で定義されたテーブルを反復処理し、テーブルが存在するかどうか、および受信データが初期ロードかアップサートかを検出するためのロジックを実行します。
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}') initialLoadRecordsSparkSQL() 関数は、S3 ファイルに操作列が存在しない場合に初期データをロードします。 AWS DMS は、連続レプリケーション (CDC) によって生成された Parquet データファイルにのみこの列を追加します。 データの読み込みは、SparkSQL で INSERT INTO コマンドを使用して実行されます。 次のコードを参照してください。
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
次に、AWS Glue ジョブを実行して、初期データを Iceberg テーブルに取り込みます。 CloudFormation スタックは、 --datalake-formats パラメータを使用して、必要な Iceberg ライブラリをジョブに追加します。
- 選択する ジョブを実行する.
- 選択する ジョブ実行 ステータスを監視します。 状態になるまで待ちます 実行成功.
読み込まれたデータを確認する
ジョブが期待どおりにデータを処理したことを確認するには、次の手順を実行します。
- Athenaコンソールで、 クエリエディタ ナビゲーションペインに表示されます。
- 確認します
AwsDataCatalogがデータ ソースとして選択されます。 - データベースで、パラメーター ストアで定義した構成に基づいて、探索するデータ ドメインを選択します。 提供されたサンプル データベースを使用する場合は、
sports.
テーブルとビュー、AWS Glue ジョブによって作成されたテーブルのリストを確認できます。
- 最初のテーブル名の横にあるオプション メニュー (XNUMX つのドット) を選択してから、 プレビューデータ.
Iceberg テーブルに読み込まれたデータを確認できます。 
増分データ読み込みを実行する
ここで、リレーショナル データベースから変更をキャプチャし、それらをトランザクション データ レイクに適用する作業を開始します。 この手順も、変更のキャプチャ、Iceberg テーブルへの適用、および結果の検証という XNUMX つの部分に分かれています。
リレーショナル データベースから変更をキャプチャする
指定した構成により、全ロード フェーズの実行後にレプリケーション タスクが停止しました。 タスクを再開して、データ レイクの raw レイヤーに変更を加えた増分ファイルを追加します。
- AWS DMS コンソールで、前に作成して実行したタスクを選択します。
- ソフトウェア設定ページで、下図のように メニュー、選択 履歴書.
- 選択する タスクを開始 変更のキャプチャを開始します。
- データ レイクで新しいファイルの作成をトリガーするには、任意のデータベース管理ツールを使用して、ソース データベースのテーブルに対して挿入、更新、または削除を実行します。 提供されたサンプル データベースを使用する場合は、次の SQL コマンドを実行できます。
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- AWS DMS タスクの詳細ページで、 テーブル統計 タブをクリックして、キャプチャされた変更を確認します。

- データ レイクの raw レイヤーを開き、すべてのテーブルのプレフィックス内の増分変更を保持する新しいファイルを見つけます。
sporting_event接頭辞。
の変更を含むレコード sporting_event テーブルは次のスクリーンショットのようになります。

TDS1.35%、収率20.8%を維持するために浸漬法は2.1グラム多くのコーヒーが必要になります Op 更新で識別される最初の列 (U)。 また、XNUMX 番目の日付/時刻の値は、変更がキャプチャされた時刻とともに AWS DMS によって追加されたコントロール列です。

AWS Glue を使用して Iceberg テーブルに変更を適用する
AWS Glue ジョブを再度実行すると、ジョブのブックマークが有効になっているため、新しい増分ファイルのみが自動的に処理されます。 それがどのように機能するかを見てみましょう。
dedupCDCRecords() 関数はデータの重複排除を実行します。これは、Amazon S3 の同じデータ ファイル内で単一のレコード ID に対する複数の変更がキャプチャされる可能性があるためです。 重複排除は、 last_update_time 変更がキャプチャされたときのタイムスタンプを示す AWS DMS によって追加された列。 次の Python コードを参照してください。
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDF99行目で、 upsertRecordsSparkSQL() 関数は初期ロードと同様の方法で upsert を実行しますが、今回は SQL MERGE コマンドを使用します。
適用された変更を確認する
Athena コンソールを開き、ソース データベースで変更されたレコードを選択するクエリを実行します。 提供されたサンプル データベースを使用する場合は、次の SQL クエリのいずれかを使用します。
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

テーブルの取り込みを監視する
AWS Glue ジョブ スクリプトは、シンプルなコードでコーディングされています。 Python 例外処理 特定のテーブルの処理中にエラーをキャッチします。 ジョブのブックマークは、各テーブルの処理が正常に終了した後に保存されます。これにより、エラーのあるテーブルに対してジョブの実行が再試行された場合に、テーブルの再処理が回避されます。
AWSコマンドラインインターフェイス (AWS CLI) は、 get-job-bookmark 処理された各テーブルのブックマークのステータスに関する洞察を提供する AWS Glue のコマンド。
- AWS Glue Studio コンソールで、ETL ジョブを選択します。
- 選択する ジョブ実行 タブをクリックして、ジョブ実行 ID をコピーします。
- AWS CLI に対して認証された端末で次のコマンドを実行します。
<GLUE_JOB_RUN_ID>コピーした値で1行目に。 CloudFormation スタックに名前が付けられていない場合transactionaldl-postgresqlで、スクリプトの 2 行目にジョブの名前を指定します。
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrunこのソリューションでは、テーブル処理で例外が発生した場合、AWS Glue ジョブはこのロジックに従って失敗しません。 代わりに、ジョブの完了後に印刷される配列にテーブルが追加されます。 このようなシナリオでは、生データ ソースで検出された残りのテーブルを処理しようとした後、ジョブは失敗としてマークされます。 このように、エラーのないテーブルは、ユーザーが競合するテーブルの問題を特定して解決するまで待つ必要がありません。 ユーザーは、AWS Glue ジョブ実行ステータスを使用して問題が発生したジョブ実行をすばやく検出し、ジョブ実行の CloudWatch ログを使用して問題の原因となっている特定のテーブルを特定できます。
- ジョブ スクリプトは、次の Python コードを使用してこの機能を実装します。
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')次のスクリーンショットは、CloudWatch ログが処理エラーの原因となるテーブルをどのように探すかを示しています。

に合わせて AWS Well-Architected フレームワーク データ分析レンズ データ パイプラインでエラーが発生した場合に関係者を特定して通知する、より高度な制御メカニズムを適応させることができます。 たとえば、 Amazon DynamoDB エラーのあるすべてのテーブルとジョブ実行を格納する制御テーブル、または使用 Amazon シンプル通知サービス (アマゾンSNS)へ オペレーターにアラートを送信する 一定の基準を満たしたとき。
増分バッチ データの読み込みをスケジュールする
CloudFormation スタックは、 アマゾンイベントブリッジ AWS Glue ジョブをトリガーしてスケジュールに従って実行できるルール (デフォルトでは無効)。 独自のスケジュールを指定してルールを有効にするには、次の手順を実行します。
- EventBridge コンソールで、 キャンペーンのルール ナビゲーションペインに表示されます。
- CloudFormation スタックの名前で始まり、その後に続くルールを検索します。
JobTrigger(例えば、transactionaldl-postgresql-JobTrigger-randomvalue). - ルールを選択します。
- イベントスケジュール、選択する 編集.
デフォルトのスケジュールは、XNUMX 時間ごとにトリガーするように構成されています。
- ジョブを実行するスケジュールを指定します。
- さらに、 EventBridge cron 式 選択することにより きめの細かいスケジュール.

- cron 式の設定が完了したら、次を選択します。 Next XNUMX回、最後に選択 ルールの更新 変更を保存する。
ルールは、最初のデータ ロードを最初に実行できるように、デフォルトで無効に作成されます。
- を選択してルールを有効にします。 有効にします.
あなたが使用することができます 監視 タブでルールの呼び出しを表示するか、AWS Glue で直接 ジョブ実行 詳細。
まとめ
このソリューションをデプロイすると、単一のリレーショナル データ ソースでのテーブルの取り込みが自動化されました。 中央のデータ プラットフォームとしてデータ レイクを使用している組織は、通常、複数、場合によっては数十ものデータ ソースを処理する必要があります。 また、組織がデータ レイクにトランザクション機能を実装する必要があるユース ケースがますます増えています。 このソリューションを使用して、すべてのリレーショナル データ ソースでこのような機能の採用を加速し、新しいビジネス ユース ケースを可能にし、実装プロセスを自動化してデータからより多くの価値を引き出すことができます。
著者について
 ルイス・ヘラルド・バエサ アマゾン ウェブ サービス (AWS) データ ラボのビッグ データ アーキテクトです。 彼は、ヘルスケア、金融、および教育セクターの組織がエンタープライズ アーキテクチャ プログラム、クラウド コンピューティング、およびデータ分析機能を採用するのを支援してきた 12 年の経験があります。 Luis は現在、ラテンアメリカ全体の組織が戦略的なデータ イニシアチブを加速するのを支援しています。
ルイス・ヘラルド・バエサ アマゾン ウェブ サービス (AWS) データ ラボのビッグ データ アーキテクトです。 彼は、ヘルスケア、金融、および教育セクターの組織がエンタープライズ アーキテクチャ プログラム、クラウド コンピューティング、およびデータ分析機能を採用するのを支援してきた 12 年の経験があります。 Luis は現在、ラテンアメリカ全体の組織が戦略的なデータ イニシアチブを加速するのを支援しています。
 サイキラン・レディ・エヌグ アマゾン ウェブ サービス (AWS) データ ラボのデータ アーキテクトです。 彼は、データの読み込み、変換、および視覚化プロセスの実装に 10 年の経験があります。 SaiKiran は現在、北米の組織がデータ レイクやデータ メッシュなどの最新のデータ アーキテクチャを採用するのを支援しています。 彼は、小売、航空、および金融部門での経験があります。
サイキラン・レディ・エヌグ アマゾン ウェブ サービス (AWS) データ ラボのデータ アーキテクトです。 彼は、データの読み込み、変換、および視覚化プロセスの実装に 10 年の経験があります。 SaiKiran は現在、北米の組織がデータ レイクやデータ メッシュなどの最新のデータ アーキテクチャを採用するのを支援しています。 彼は、小売、航空、および金融部門での経験があります。
 ナレンドラ・メルラ アマゾン ウェブ サービス (AWS) データ ラボのデータ アーキテクトです。 彼は、リアルタイムとバッチ指向の両方のデータ パイプラインの設計と製品化、およびクラウドとオンプレミスの両方の環境でのデータ レイクの構築において 12 年の経験があります。 Narendra は現在、北米の組織が堅牢なデータ アーキテクチャを構築および設計するのを支援しており、通信および金融部門での経験があります。
ナレンドラ・メルラ アマゾン ウェブ サービス (AWS) データ ラボのデータ アーキテクトです。 彼は、リアルタイムとバッチ指向の両方のデータ パイプラインの設計と製品化、およびクラウドとオンプレミスの両方の環境でのデータ レイクの構築において 12 年の経験があります。 Narendra は現在、北米の組織が堅牢なデータ アーキテクチャを構築および設計するのを支援しており、通信および金融部門での経験があります。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- 私たちについて
- 加速する
- アクセス
- 従った
- 認める
- 越えて
- 適応する
- 追加されました
- NEW
- さらに
- 追加
- 管理人
- 管理
- 採用
- 養子縁組
- 後
- 航空会社
- すべて
- 既に
- Amazon
- アマゾンアテナ
- アマゾンRDS
- Amazon Webサービス
- Amazon Webサービス(AWS)
- アメリカ
- 分析
- 分析論
- &
- アンヘレス
- アパッチ
- 現れる
- 申し込み
- 適用された
- 適用
- アプローチ
- 約
- 建築
- 配列
- 関連する
- 認証された
- 自動化する
- 自動化
- 自動的に
- 自動化する
- 平均
- 避ける
- AWS
- AWS CloudFormation
- AWSグルー
- ベース
- コウモリ
- なぜなら
- になる
- 開始
- ビッグ
- ビッグデータ
- ビルド
- ビルダー
- 建物
- ビジネス
- 取得することができます
- 機能
- キャップ
- キャプチャー
- キャプチャ
- 場合
- 例
- カタログ
- レスリング
- 原因となる
- 原因
- 原因
- CDC
- 中央の
- 一定
- 変化する
- 変更
- 選択
- 選択する
- 選択する
- 選ばれた
- クラウド
- クラウドコンピューティング
- コード
- コラム
- コラム
- 会社
- コンプリート
- コンピューティング
- 構成
- 確認します
- 相反する
- お問合せ
- 接続
- 検討事項
- 領事
- 消費者
- 消費
- 含まれています
- 続ける
- 連続的な
- コントロール
- 可能性
- 作ります
- 作成した
- 作成します。
- 作成
- 創造
- 基準
- 現在
- カスタム
- 顧客
- カスタマイズ
- データ
- データ分析
- データレイク
- データベース
- データベースを追加しました
- 日付
- デフォルト
- 定義済みの
- 展開します
- 展開
- 展開する
- 展開
- 配備する
- 設計
- 設計
- 設計
- 細部
- 検出された
- 開発
- 異なります
- 直接に
- 無効
- 分割された
- そうではありません
- ドメイン
- ドメイン
- ドント
- 間に
- 各
- 前
- 簡単に
- 教育
- 努力
- どちら
- enable
- 使用可能
- では使用できません
- 暗号化
- エンドポイント
- エンジン
- 入力します
- Enterprise
- 環境
- エラー
- エーテル(ETH)
- さらに
- あらゆる
- 例
- 超え
- 除く
- 例外
- 既存の
- 存在
- 予想される
- 期待する
- 体験
- 探る
- エクステンション
- エキス
- Failed:
- おなじみの
- ファッション
- 特徴
- 少数の
- File
- 最後に
- ファイナンス
- ファイナンシャル
- もう完成させ、ワークスペースに掲示しましたか?
- 仕上げ
- 名
- 続いて
- フォロー中
- 消費者向け
- フォーム
- 形成
- フレームワーク
- から
- フル
- function
- 生成された
- 世代
- 取得する
- 助成金
- 助成
- 成長
- ハンドル
- ヘルスケア
- 助け
- ことができます
- 階層
- history
- 開催
- 認定条件
- How To
- HTML
- HTTPS
- 巨大な
- IAM
- 特定され
- 識別子
- 識別する
- 識別する
- 実装する
- 実装
- 実装
- 実装
- 実装する
- 改善
- in
- include
- 含ま
- 含めて
- 入ってくる
- を示し
- 個人
- 情報
- 初期
- イニシアチブ
- インサート
- 洞察力
- を取得する必要がある者
- 説明書
- 中級
- 問題
- 問題
- IT
- 繰り返し
- ジョブ
- Jobs > Create New Job
- JSON
- キープ
- キー
- キー
- 知っている
- ラボ
- 湖
- ラテン
- ラテンアメリカ
- 層
- 層
- つながる
- LEARN
- ライブラリ
- LIMIT
- LINE
- リスト
- 負荷
- ローディング
- 負荷
- 場所
- 見て
- LOOKS
- インクルード
- ロサンゼルス
- たくさん
- メイン
- 維持
- make
- マネージド
- 管理
- マネージャー
- 管理する
- 手動で
- 多くの
- マッピング
- マークされた
- メニュー
- マージ
- メッセージ
- かもしれない
- 移行
- 最小
- 分
- 分
- モダン
- 修正する
- モニター
- モニタリング
- 他には?
- 最も
- 一番人気
- の試合に
- 名
- 名前付き
- 名
- ナビゲート
- ナビゲーション
- 必要
- 必要とされる
- ニーズ
- 新作
- 次の
- ノース
- 北米
- 通知
- 数
- オブジェクト
- オブジェクト
- ONE
- 継続
- OP
- 操作
- 最適化
- オプション
- 組織の
- 組織
- 整理
- オリジナル
- さもないと
- 外側
- 自分の
- 所有者
- ペイン
- パラメーター
- パラメータ
- 部
- 部品
- path
- パターン
- 実行する
- 実行
- 実行する
- 期間
- パーミッション
- 相
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 人気
- ポスト
- Postgresql
- プラクティス
- 優先
- 前提条件
- 現在
- 主要な
- 問題
- プロセス
- ラボレーション
- 処理
- 生産された
- プログラム
- 提供します
- 提供
- は、大阪で
- Python
- すぐに
- 上げる
- レート
- Raw
- 生データ
- 読む
- への
- 記録
- 記録
- replace
- 複製された
- レプリケーション
- 必要とする
- の提出が必要です
- リソースを追加する。
- リソース
- REST
- 結果
- 小売
- return
- 収益
- レビュー
- 堅牢な
- 職種
- ルール
- ルール
- ラン
- ランニング
- 同じ
- Save
- シナリオ
- スケジュール
- スコープ
- スクリプト
- を検索
- 二番
- セクター
- 見ること
- 選択
- 選択
- 選択
- 別
- サービス
- セッションに
- 設定
- 設定
- すべき
- 表示する
- 作品
- 同様の
- 簡単な拡張で
- から
- So
- 溶液
- 解決する
- 一部
- 洗練された
- ソース
- ソース
- スペース
- スパーク
- 特定の
- 仕様
- 指定の
- スポーツ
- SQL
- スタック
- スタック
- ステージ
- ステークホルダー
- start
- 開始
- 起動
- 開始
- 米国
- 統計
- Status:
- 手順
- ステップ
- 停止
- ストレージ利用料
- 店舗
- 保存され
- 店舗
- 戦略的
- 構造
- 構造化された
- 研究
- 首尾よく
- そのような
- スーパー
- サポート
- システム
- テーブル
- ターゲット
- 仕事
- タスク
- チーム
- チーム
- 電気通信
- template
- ターミナル
- ソース
- アプリ環境に合わせて
- 数千
- 三
- 介して
- 時間
- タイムライン
- <font style="vertical-align: inherit;">回数</font>
- タイムスタンプ
- 〜へ
- ツール
- top
- トータル
- 追跡
- 伝統的な
- トランザクションの
- 最適化の適用
- 変換
- トリガー
- チュートリアル
- 下
- わかる
- ユニーク
- アップデイト
- 更新版
- つかいます
- 使用事例
- ユーザー
- users
- 通常
- 値
- 検証する
- 詳しく見る
- 可視化
- ボリューム
- wait
- 倉庫
- ウェブ
- Webサービス
- which
- 意志
- 以内
- 無し
- 作品
- 書きます
- 書かれた
- ヤムル
- 年
- 年
- あなたの
- ゼファーネット