データ統合プロセスは、他のソフトウェアと同様に自動テストの恩恵を受けます。 しかし、自動化されたテストの適切なセットを備えたデータ パイプライン プロジェクトを見つけることはまれです。 プロジェクトに多くのテストがある場合でも、多くの場合、それらは構造化されておらず、目的が伝わらず、実行が困難です。
の特徴 データパイプライン 開発とは、高品質のデータを頻繁にリリースして、ユーザーのフィードバックと承認を得ることです。 すべてのデータ パイプラインの反復の最後に、データが次のフェーズのために高品質であることが期待されます。
自動化されたテストは、データ パイプラインの統合テストに不可欠です。 手動テストは、高度に反復的で適応性のある開発環境では実用的ではありません。
手動データ テストの主な問題
まず、時間がかかりすぎて、パイプラインの頻繁な配信の重大な阻害要因となります。 主に手動テストに依存しているチームは、テストを専用のテスト期間に延期することになり、バグが蓄積する可能性があります。
第 XNUMX に、手動のデータ パイプライン テストでは、回帰テストの再現性が不十分です。
データ パイプライン テストを自動化するには、初期計画と継続的な注意が必要ですが、技術チームが自動化を採用すると、プロジェクトの成功はより確実になります。
データ パイプラインのバリアント
- 抽出、変換、読み込み (ETL)
- 抽出、読み込み、変換 (ELT)
- データレイク、データ ウェアハウス パイプライン
- リアルタイム パイプライン
- 機械学習パイプライン
テスト自動化の考慮事項のためのデータ パイプライン コンポーネント
データ パイプラインは複数のコンポーネントで構成され、それぞれが特定のタスクを担当します。 データ パイプラインの要素は次のとおりです。
- データソース: データの出所
- データの取り込み: データ ソースからデータを収集するプロセス
- データ変換: 収集したデータを、さらなる分析に使用できる形式に変換するプロセス
- データの検証/検証: データが正確で一貫していることを保証するプロセス
- データストレージ: 変換および検証されたデータをデータ ウェアハウスまたはデータ レイクに格納するプロセス
- データ解析: 保存されたデータを分析して、パターン、傾向、洞察を特定するプロセス
データ パイプライン テストを自動化するためのベスト プラクティス
何をいつ自動化するか (または自動化が必要かどうか) は、テスト (または開発) チームにとって重要な決定です。 自動化に適した製品特性の選択は、自動化の成功を大きく左右します。
データ パイプラインのテストを自動化する場合のベスト プラクティスには、次のようなものがあります。
- 明確で具体的なテストの目的を定義します。 テストを開始する前に、テストを通じて達成したいことを定義することが不可欠です。 そうすることで、貴重な洞察を提供する効果的で効率的なテストを作成するのに役立ちます.
- データ パイプラインのすべてのワークフローをテストします。 通常、データ パイプラインは、データの取り込み、処理、変換、およびストレージという複数のコンポーネントで構成されます。 各コンポーネントをテストして、パイプラインを介したデータの流れが適切かつスムーズであることを確認することが重要です。
- 信頼できるテスト データを使用する: データ パイプラインをテストするときは、現実世界のシナリオを模倣した現実的なデータを使用することが重要です。 これは、さまざまなデータ型を処理するときに発生する可能性のある問題を特定するのに役立ちます。
- 効果的なツールで自動化: これは、テスト フレームワークとツールを使用して実現できます。
- 定期的にパイプラインを監視します。 テストが完了した後でも、パイプラインを定期的に監視して、意図したとおりに機能していることを確認することが不可欠です。 これは、重大な問題になる前に問題を特定するのに役立ちます。
- 利害関係者を関与させる: データ アナリスト、データ エンジニア、ビジネス ユーザーなどの関係者をテスト プロセスに参加させます。 これにより、テストがすべての利害関係者にとって関連性があり、価値のあるものであることが保証されます。
- ドキュメントを維持する: テスト、テスト ケース、およびテスト結果を説明するドキュメントを維持することは重要です。 これにより、テストを複製して長期にわたって維持することができます。
気をつけて; 不安定な機能の変更の自動化は避けるべきです。 今日、データ パイプラインの完全なエンド ツー エンド テストと見なすことができる既知のビジネス ツールやメソッド/プロセスのセットはありません。
テスト自動化の目標を検討する
データ パイプライン テストの自動化は、1) テストの実行、 2) 実際の結果と予測された結果との比較、および 3) テストの前提条件およびその他のテスト制御およびテスト報告機能の設定。
一般に、テストの自動化には、正式なテスト プロセスを使用する既存の手動プロセスの自動化が含まれます。
手動のデータ パイプライン テストでは多くのデータの欠陥が明らかになる可能性がありますが、手間と時間がかかります。 さらに、手動テストは、特定の欠陥を検出するのに効果的でない場合があります。
データ パイプラインの自動化には、手動で実行する必要があるテスト プログラムの開発が含まれます。 テストが自動化されると、すばやく繰り返すことができます。 これは、多くの場合、耐用年数が長いデータ パイプラインにとって最も費用対効果の高い方法です。 パイプラインの存続期間中のマイナーな修正または機能強化でさえ、以前は機能していた機能が壊れる可能性があります。
自動化されたテストをデータ パイプラインの開発に統合すると、独自の一連の課題が生じます。 現在の自動化されたソフトウェア開発テスト ツールは、データベースおよびデータ パイプライン プロジェクトに容易に適応することはできません。
さまざまなデータ パイプライン アーキテクチャがこれらの課題をさらに複雑にしています。これは、データの抽出、変換、ロード、 データクレンジング、データ集約、およびデータ強化。
テスト自動化ツールは高価になる可能性があり、通常は手動テストと共に使用されます。 ただし、特に回帰テストで繰り返し使用する場合は、長期的には費用対効果が高くなる可能性があります。
テスト自動化の頻繁な候補
- BI レポートのテスト
- ビジネス、政府のコンプライアンス
- データ集計処理
- データのクレンジングとアーカイブ
- データ品質テスト
- データ調整 (例: ソースからターゲットへ)
- データ変換
- ディメンション テーブル データの読み込み
- エンドツーエンドのテスト
- ETL、ELT 検証および検証テスト
- ファクト テーブル データの読み込み
- ファイル/データ読み込みの検証
- 増分負荷テスト
- 負荷とスケーラビリティのテスト
- 不足しているファイル、レコード、フィールド
- パフォーマンステスト
- 参照整合性
- 回帰試験
- セキュリティテスト
- ソースデータのテストとプロファイリング
- ステージング、ODS データ検証
- 単体テスト、統合テスト、回帰テスト
これらのテストの自動化は、処理の複雑さと、検証する必要があるソースとターゲットの数のために必要になる場合があります。
ほとんどのプロジェクトでは、データ パイプラインのテスト プロセスは、データ品質を検証して実装するように設計されています。
現在利用可能なさまざまなデータ型がテストの課題を提示
現在、テキスト、数値、日付などの従来の構造化データ型から、音声、画像、ビデオなどの非構造化データ型まで、さまざまなデータ型が利用可能です。 さらに、XML や JSON などのさまざまな種類の半構造化データが、Web 開発やデータ交換で広く使用されています。
モノのインターネット (IoT) の出現により、センサー データ、位置データ、マシン間通信データなど、さまざまなデータ タイプが爆発的に増加しています。 これらのデータ型が抽出および変換されると、適切なツールがないとテストがより複雑になる可能性があります。 これにより、ストリーム処理、エッジ コンピューティング、リアルタイム分析などの新しいデータ管理技術と分析技術が生まれました。
図 1 は、今日広く使用されているデータ型の例を示しています。 膨大な数は、必要な変換が正しく実行されているかどうかをテストする際の課題を表しています。 その結果、データの専門家は、さまざまな種類のデータに精通し、新たなトレンドやテクノロジーのテストに適応できる必要があります。
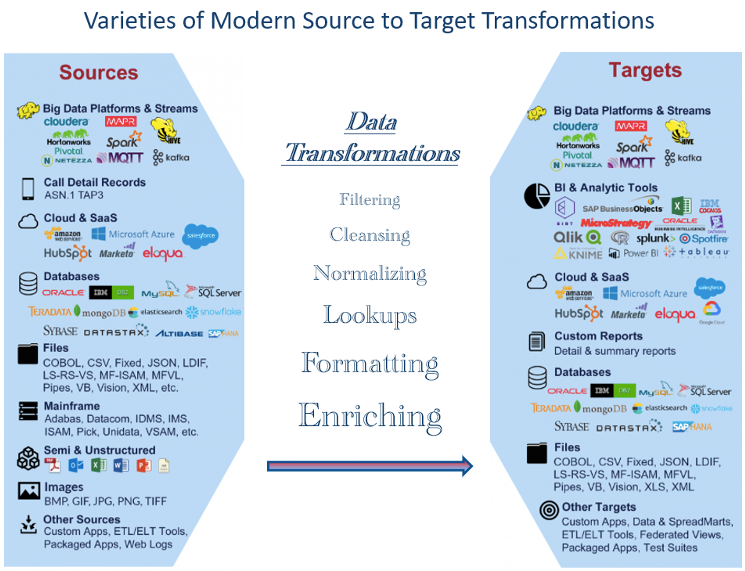
自動テストの可能性についてパイプライン コンポーネントを評価する
アジャイルおよびその他の最新の開発の重要な要素は、自動テストです。 この認識をデータ パイプラインに適用できます。
データ パイプライン テストの重要な側面は、追加された機能とメンテナンスをチェックするために実行されるテストの数が増え続けることです。 図 2 データ パイプラインでテストの自動化を適用できる多くの領域を示します.
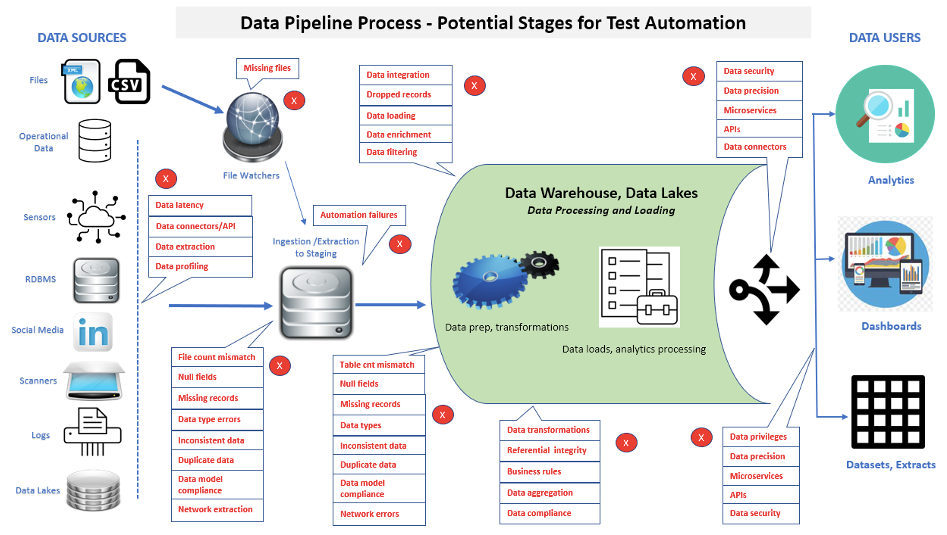
テストの自動化を実装すると、ソース レイヤーからデータ パイプライン処理を経てデータ パイプラインにロードされ、最後にフロントエンド アプリケーションまたはレポートに至るまで、データを追跡できます。 フロントエンド アプリケーションまたはレポートで破損したデータが見つかったとします。 その場合、自動化されたスイートを実行すると、個々の問題がデータ ソース、データ パイプライン プロセス、新しく読み込まれたデータ パイプライン データベース/データ マート、またはビジネス インテリジェンス/分析レポートにあるかどうかをより迅速に判断できます。
複雑なデータ パイプライン アーキテクチャにおけるデータとパフォーマンスの問題を迅速に特定することに重点を置くことで、開発効率を高め、ビルド サイクルを短縮し、リリース基準の目標を達成するための重要なツールが提供されます。
自動化するテストのカテゴリを決定する
秘訣は、何を自動化し、各タスクをどのように処理するかを決定することです。 テストを自動化するときは、次のような一連の質問を考慮する必要があります。
- テストを自動化するコストはいくらですか?
- テスト自動化の責任者は誰ですか (例: 開発、QA、データ エンジニア)?
- どのテスト ツールを使用する必要がありますか (オープン ソース、ベンダーなど)?
- 選択したツールはすべての期待を満たしますか?
- テスト結果はどのように報告されますか?
- 誰がテスト結果を解釈しますか?
- テスト スクリプトはどのように維持されますか?
- 簡単かつ正確にアクセスできるように、スクリプトをどのように編成しますか?
図 3 は、実際のプロジェクト経験からの手動テスト ケースと自動テスト ケースの期間 (テストの実行、欠陥の特定、およびレポート) の例を示しています。
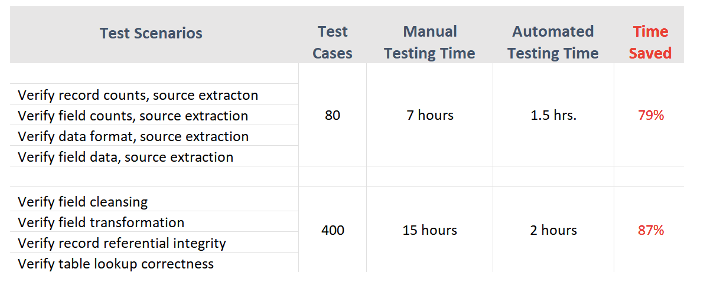
自動化されたデータ パイプライン テストは、データ パイプラインをロードするための最も重要な機能 (ソース データとターゲット データの同期と調整) をカバーすることを目的としています。
自動テストの利点と制限
テスト自動化の課題
- レポートのテスト: 自動化によるビジネス インテリジェンスまたは分析レポートのテスト
- データの複雑さ: 多くの場合、データ パイプラインのテストには複雑なデータ構造と変換が含まれるため、自動化が難しく、専門知識が必要になる場合があります。
- パイプラインの複雑さ: データ パイプラインは複雑になる可能性があり、複数の処理段階が含まれる場合があり、テストとデバッグが困難になる可能性があります。 さらに、パイプラインの一部を変更すると、下流で意図しない結果が生じる可能性があります。
テスト自動化の利点
- テスト ケースをより速く実行します。 自動化により、テスト シナリオの実装が高速化される場合があります。
- 再利用可能なテスト スイートを作成します。 テスト スクリプトが自動化ツールで実行されると、簡単に呼び出して再利用できるようにバックアップできます。
- テスト レポートを容易にします。 多くの自動化ツールの興味深い機能は、レポートとテスト ファイルを生成する機能です。 これらの機能は、データの状態を正確に表し、欠陥を明確に特定し、コンプライアンス監査で使用されます。
- 人員配置とやり直しのコストを削減: 手動テストまたは欠陥修正後の再テストに費やされる時間は、IT 部門内の他のイニシアチブに費やすことができます。
潜在的な制限
- 手動テストを完全に置き換えることはできません: 自動化はさまざまなアプリケーションやテストケースに使用できますが、 手動テストを完全に置き換えることはできません。 自動化がすべてをキャプチャしない複雑なテスト ケースは依然として存在し、ユーザー受け入れテストでは、エンド ユーザーが手動でテストを実行する必要があることがよくあります。 したがって、プロセスで自動テストと手動テストを適切に組み合わせることは非常に重要です。
- ツールのコスト: 市販のテスト ツールは、サイズと機能によっては高価になる場合があります。 表面的には、企業はこれを不要なコストと見なす場合があります。 ただし、再利用するだけですぐに資産になります。
- トレーニングの費用: テスト担当者は、プログラミングだけでなく、自動テストのスケジューリングについてもトレーニングを受ける必要があります。 自動ツールは使い方が複雑で、ユーザーのトレーニングが必要になる場合があります。
- 自動化には、計画、準備、および専用のリソースが必要です。 自動テストの成功は、主に正確なテスト要件と、テスト開始前のテスト ケースの慎重な開発に依存します。 残念ながら、テスト ケースの開発は依然として主に手動のプロセスです。 各組織およびデータ パイプライン アプリケーションは固有のものである可能性があるため、多くの自動テスト ツールではテスト ケースが作成されません。
データ パイプライン テストの自動化を開始する
すべてのデータ パイプライン テストが自動化に適しているわけではありません。 上記の状況を評価して、どのタイプの自動化がテスト プロセスに役立つか、および必要な量を判断します。 テスト要件を評価し、自動テストによって達成できる効率の向上を特定します。 回帰テストにかなりの時間を費やしているデータ パイプライン チームが最も恩恵を受けます。
自動テストのビジネス ケースを作成します。 IT 部門はまず、価値をビジネスに伝えることを主張する必要があります。
オプションを評価します。 IT 部門内の現状と要件を評価した後、どのツールが組織のテスト プロセスと環境に適合するかを判断します。 オプションには、ベンダー、オープン ソース、内部、またはツールの組み合わせが含まれる場合があります。
結論
テストの自動化が急速に手動テストの不可欠な代替手段になるにつれて、ますます多くの企業が自動化をうまく実装するためのツールと戦略を探しています。 これにより、Appium、Selenium、Katalon Studio などに基づくテスト自動化ツールが大幅に成長しました。 ただし、データ パイプラインとデータ エンジニア、BI、および品質保証チームは、これらの自動化ツールを十分に活用するための適切なプログラミング スキルを持っている必要があります。
多くの IT 専門家は、テスターと開発者の間の知識のギャップを継続的に縮小する必要があり、また縮小するだろうと予測しています。 自動化されたデータ パイプライン テスト ツールは、従来の手動の方法と比較して、コードのテストにかかる時間を大幅に短縮できます。
データ パイプラインの開発能力が向上し続けるにつれて、より包括的で最新の自動化されたデータ テストの必要性も高まっています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.dataversity.net/best-practices-in-data-pipeline-test-automation/
- :は
- $UP
- 1
- a
- 能力
- 上記の.
- 受け入れ
- アクセス
- 累積する
- 正確な
- 正確にデジタル化
- 達成する
- 達成
- 追加されました
- 添加
- さらに
- 採用
- 出現
- 後
- 凝集
- 使い勝手のいい
- 目指して
- すべて
- 許可
- 一人で
- 代替案
- しかし
- 分析
- アナリスト
- 分析的
- 分析的
- 分析論
- 分析する
- &
- 申し込み
- 適用された
- 申し込む
- 適切な
- です
- エリア
- AS
- 側面
- 評価中
- 資産
- 保証
- 確実な
- At
- オーディオ
- 監査
- 自動化する
- 自動化
- 自動化する
- オートメーション
- 利用できます
- 避ける
- 認知度
- 支持された
- ベース
- 基礎
- BE
- なぜなら
- になる
- 開始
- 恩恵
- BEST
- ベストプラクティス
- の間に
- ブレーク
- 広い
- バグ
- ビルド
- ビジネス
- ビジネス・インテリジェンス
- ビジネス
- 缶
- 候補
- 機能
- キャプチャー
- 注意深い
- 場合
- 例
- カテゴリ
- 原因となる
- 一定
- 課題
- 挑戦
- 変更
- 変化
- 特性
- 特性
- チェック
- 選ばれた
- クリア
- はっきりと
- コード
- コーディング
- 収集
- 組み合わせ
- 伝える
- コミュニケーション
- 比べ
- コンプリート
- 完全に
- 複雑な
- 複雑さ
- コンプライアンス
- 複雑な
- コンポーネント
- コンポーネント
- 包括的な
- コンピューティング
- 結果
- かなりの
- 見なさ
- 続ける
- 連続的な
- 連続的に
- コントロール
- 従来の
- 費用
- コスト効率の良い
- コスト
- カバー
- 作ります
- 信頼できる
- 基準
- 重大な
- 重大な
- 電流プローブ
- 現在の状態
- サイクル
- データ
- 日付の充実
- データ交換
- データ管理
- データ品質
- データウェアハウス
- データベース
- データベースを追加しました
- データバーシティ
- 試合日
- 決定
- 専用の
- 配達
- 部門
- 依存
- によっては
- 記載された
- 設計
- 決定する
- 決定する
- 決定
- デベロッパー
- 開発者
- 開発
- 開発
- 進展
- 異なります
- 勤勉
- ディスプレイ
- ドキュメント
- ドキュメント
- すること
- e
- 各
- 前
- 簡単に
- エッジ(Edge)
- エッジコンピューティング
- 効果的な
- 効率
- 効率
- 効率的な
- 素子
- 要素は
- 新興の
- 強調
- 端から端まで
- エンジニア
- 確保
- 環境
- 特に
- 本質的な
- 評価する
- さらに
- あらゆる
- すべてのもの
- 例
- 交換
- 実行
- 既存の
- 期待
- 予想される
- 高価な
- 体験
- 専門知識
- 専門家
- 抽出
- 速いです
- 特徴
- 特徴
- フィードバック
- フィギュア
- 最後に
- 発見
- 名
- 欠陥
- フロー
- フォーマル
- 形式でアーカイブしたプロジェクトを保存します.
- 発見
- フレームワーク
- 頻繁な
- から
- 完全に
- 機能性
- 機能
- さらに
- 利得
- 利益
- ギャップ
- 政府・公共機関
- 成長性
- ハンドル
- ハンドリング
- ハード
- 持ってる
- 持って
- 助けます
- ハイ
- 高品質
- 非常に
- 認定条件
- How To
- しかしながら
- HTTPS
- 識別
- 識別する
- 画像
- 実装する
- 実装
- 実装
- 重要
- in
- include
- 含めて
- 増える
- 増加
- 個人
- 初期
- イニシアチブ
- 統合
- インテリジェンス
- 興味深い
- 内部
- インターネット
- モノのインターネット
- 巻き込む
- 関与
- IOT
- 問題
- IT
- 繰り返し
- JSON
- キー
- 知識
- 既知の
- 湖
- 主として
- 層
- 学習
- ツェッペリン
- 生活
- 一生
- ような
- 制限
- 負荷
- ローディング
- 負荷
- 位置して
- 場所
- 長い
- 探して
- メンテナンス
- make
- 管理
- マニュアル
- 手動で
- 多くの
- 最大幅
- 大会
- ご相談
- 方法
- メソッド
- マイナー
- モダン
- モニター
- 他には?
- 最も
- の試合に
- 必要
- 必要
- 必要とされる
- ニーズ
- 新作
- 次の
- 数
- 番号
- 目的
- of
- on
- ONE
- 開いた
- オープンソース
- オプション
- 組織
- Origin
- その他
- その他
- さもないと
- 部
- パターン
- 実行する
- パフォーマンス
- 期間
- 相
- パイプライン
- 計画
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 可能
- プラクティス
- 正確な
- 予測
- プレゼント
- 主に
- 問題
- プロセス
- ラボレーション
- 処理
- 作り出す
- プロダクト
- 専門家
- プログラミング
- プログラム
- プロジェクト
- プロジェクト(実績作品)
- 推進
- 適切な
- 提供します
- は、大阪で
- 目的
- 質問と回答
- 品質
- 質問
- すぐに
- 範囲
- 測距
- 急速な
- 急速に
- 珍しい
- 現実の世界
- への
- 現実的な
- 和解
- 記録
- 減らします
- 回帰
- レギュラー
- 定期的に
- リリース
- 関連した
- 頼る
- 繰り返される
- 繰り返し
- replace
- 複製された
- レポート
- 報告
- 各種レポート作成
- レポート
- 表す
- 表し
- 必要とする
- の提出が必要です
- 要件
- 必要
- リソース
- 責任
- 結果
- 結果
- 再利用可能な
- 明らかにする
- ラン
- スケーラビリティ
- シナリオ
- スケジューリング
- スクリプト
- 選択
- サービス
- セッションに
- いくつかの
- すべき
- 作品
- 重要
- 著しく
- 状況
- サイズ
- スキル
- So
- ソフトウェア
- ソフトウェア開発
- ソース
- ソース
- 特別
- 専門の
- 特定の
- スピード
- 費やした
- スタッフの配置
- ステージ
- ステークホルダー
- start
- 開始
- 都道府県
- Status:
- まだ
- ストレージ利用料
- 保存され
- 作戦
- 流れ
- 構造化された
- 研究
- 成功
- 首尾よく
- そのような
- 適当
- スイート
- 表面
- 同期
- テーブル
- 取り
- ターゲット
- ターゲット
- 仕事
- チーム
- チーム
- 技術的
- テクニック
- テクノロジー
- test
- テスト
- テスト
- それ
- アプリ環境に合わせて
- したがって、
- ボーマン
- 物事
- 介して
- 時間
- 時間がかかる
- 〜へ
- 今日
- あまりに
- ツール
- 豊富なツール群
- 伝統的な
- 訓練された
- トレーニング
- 最適化の適用
- 変換
- 変換
- 変換
- 変換
- トレンド
- ユニーク
- つかいます
- ユーザー
- users
- 通常
- 検証済み
- 貴重な
- 値
- 多様
- さまざまな
- 広大な
- ベンダー
- ベンダー
- Verification
- 検証
- 確認する
- ビデオ
- 詳しく見る
- 極めて重要な
- vs
- 倉庫
- ウェブ
- ウェブ開発
- この試験は
- かどうか
- which
- 誰
- ワイド
- 広く
- 意志
- 以内
- 無し
- ワークフロー
- ワーキング
- でしょう
- XML
- あなたの
- ゼファーネット











