概要
このプロジェクトでは、インドのデータに焦点を当てます。 そして私たちの目標は、 予測モデル、ロジスティック回帰など。これにより、候補者の特性を与えると、モデルは採用するかどうかを予測できます。
データセット インドのビジネススクールの配置シーズンを中心に展開しています。 データセットには、職歴、試験の割合など、候補者に関するさまざまな要素が含まれています。最後に、採用状況と報酬の詳細が含まれています。

キャンパスでの採用は、インターンシップや新入社員向けの若い人材を調達、関与、採用するための戦略です。 多くの場合、大学のキャリアサービスセンターと協力し、キャリアフェアに参加して大学生や最近の卒業生と直接会うことが含まれます.
この記事は、の一部として公開されました データサイエンスブログ。
目次
問題の解決に必要な手順
この記事では、そのデータセットをインポートしてクリーンアップし、ロジスティック回帰モデルを構築する準備をします。 ここでの目標は次のとおりです。
まず、データセットを準備します バイナリ分類. さて、私はどういう意味ですか? アパートの価格など、継続的な値を予測しようとすると、XNUMX から数百万ドルの間の任意の数値になる可能性があります。 これを回帰問題と呼びます。
しかし、このプロジェクトでは少し事情が異なります。 連続値を予測する代わりに、それらの間で予測しようとしている離散グループまたはクラスがあります。 これは分類問題と呼ばれます。このプロジェクトでは、選択しようとしているグループが XNUMX つしかないため、XNUMX 項分類になります。
XNUMX 番目の目標は、採用を予測するためのロジスティック回帰モデルを作成することです。 XNUMX つ目の目標は、オッズ比を使用してモデルの予測を説明することです。
機械学習のワークフロー、従う手順、およびいくつかの新しいことに関しては、その過程で学習します。 そのため、インポート フェーズでは、バイナリ ターゲットで動作するようにデータを準備します。 探索段階では、クラスのバランスを見ていきます。 では、基本的に、候補者のどの割合がサードで、どの割合がそうでなかったのでしょうか? フィーチャ エンコーディング フェーズでは、カテゴリ フィーチャのエンコーディングを行います。 分割部分では、ランダム化された列車のテスト分割を行います。
モデル構築フェーズでは、まずベースラインを設定します。精度スコアを使用するため、精度スコアとは何か、およびベースラインが関心のあるメトリックである場合にベースラインを構築する方法について詳しく説明します。次に、ロジスティック回帰を行います。 そして最後になりましたが、評価フェーズがあります。 再び精度スコアに焦点を当てます。 最後に、結果を伝えるために、オッズ比を見ていきます。
最後に、作業に入る前に、プロジェクトで使用するライブラリを紹介しましょう。 まず、データを Google Colabe ノートブックの io ライブラリにインポートします。 次に、ロジスティック回帰モデルを使用するので、それを scikit-learn からインポートします。 その後も、こちらから scikit-学ぶ、パフォーマンス メトリクス、精度スコア、およびトレーニング テスト分割をインポートします。
我々は使用するだろう matplotlib 視覚化のためのシーボーン、および NumPy ちょっとした数学のためだけになります。
必要です パンダ データを操作するには labelencoder を使用してカテゴリ変数をエンコードし、標準のスケーラーを使用してデータを正規化します。 それが必要なライブラリです。
データの準備に取り掛かりましょう。
#import libraries
import io
import warnings import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler warnings.simplefilter(action="ignore", category=FutureWarning)データを準備する
インポート
データの準備を始めるために、重要な作業を始めましょう。 まず、データ ファイルをロードしてから、それらを DataFrame `df` に配置する必要があります。
from google.colab import files
uploaded = files.upload()# Read CSV file
df = pd.read_csv(io.BytesIO(uploaded["Placement_Data_Full_Class.csv"]))
print(df.shape)
df.head()
美しい DataFrame を見ることができます。215 のレコードと、ターゲットである `status` 属性を含む 15 の列があります。 これは、すべての機能の説明です。

詳細
これで、これらの機能がすべて揃いました。 それでは始めましょう 探索的データ分析. まず、このデータフレームの情報を見て、それらのいずれかを保持する必要があるかどうか、または削除する必要があるかどうかを確認しましょう。
# Inspect DataFrame
df.info() <class 'pandas.core.frame.DataFrame'>
RangeIndex: 215 entries, 0 to 214
Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sl_no 215 non-null int64 1 gender 215 non-null object 2 ssc_p 215 non-null float64 3 ssc_b 215 non-null object 4 hsc_p 215 non-null float64 5 hsc_b 215 non-null object 6 hsc_s 215 non-null object 7 degree_p 215 non-null float64 8 degree_t 215 non-null object 9 workex 215 non-null object 10 etest_p 215 non-null float64 11 specialisation 215 non-null object 12 mba_p 215 non-null float64 13 status 215 non-null object 14 salary 148 non-null float64
dtypes: float64(6), int64(1), object(8)
memory usage: 25.3+ KB「df」情報を見ると、探していることがいくつかあります。データフレームには 215 行あります。自分自身に問いかけたい質問は、不足しているデータはありますか? そして、ここを見ると、予想通り、採用されていない候補者のために、給与の列を除いて欠落しているデータはないようです。
ここでのもう XNUMX つの懸念は、モデルが現実の世界に展開された場合に得られない情報をモデルに提供する漏れやすい機能がないかどうかです。 候補者が配置されるかどうかをモデルで予測し、採用が行われる前にモデルでそれらの予測を行う必要があることを思い出してください。 そのため、採用後にこれらの候補者に関する情報を提供したくありません。
したがって、この「給与」機能が、企業が提供する給与に関する情報を提供することは明らかです。 そして、この給与は受け入れられた人のためのものであるため、ここでのこの機能は漏れを構成し、削除する必要があります.
df.drop(columns="salary", inplace=True)次に注目したいのは、これらのさまざまな機能のデータ型です。 したがって、これらのデータ型を見ると、ターゲットを含む XNUMX つのカテゴリ特徴と XNUMX つの数値特徴があり、すべてが正しいです。 これらのアイデアが得られたので、時間をかけてさらに深く掘り下げてみましょう。
ターゲットには XNUMX つのクラスがあることがわかっています。 私たちは候補者を配置しましたが、候補者を配置しませんでした。 問題は、これら XNUMX つのクラスの相対的な比率はどのくらいかということです。 それらはほぼ同じバランスですか? それとも、一方が他方よりもはるかに多いですか? これは、分類問題を行うときに検討する必要があるものです。 したがって、これは EDA における重要なステップです。
# Plot class balance
df["status"].value_counts(normalize=True).plot( kind="bar", xlabel="Class", ylabel="Relative Frequency", title="Class Balance"
);
肯定的なクラス「配置済み」は観測の 65% 以上を占め、否定的なクラス「配置されていません」は約 30% です。 これらが非常に不均衡である場合、たとえば 80 以上またはそれ以上である場合、これらは不均衡なクラスであると言えます。 そして、モデルが正しく機能することを確認するために、いくつかの作業を行う必要があります。 でもこれはバランスがいい。
フィーチャとターゲットの間の関係に気付くために、別の視覚化を行いましょう。 数値の特徴から始めましょう。
まず、分布プロットを使用して特徴の個々の分布を確認し、箱ひげ図を使用して数値特徴とターゲットの関係も確認します。
fig,ax=plt.subplots(5,2,figsize=(15,35))
for index,i in enumerate(df.select_dtypes("number").drop(columns="sl_no")): plt.suptitle("Visualizing Distribution of Numerical Columns Indivualy and by Class",size=20) sns.histplot(data=df, x=i, kde=True, ax=ax[index,0]) sns.boxplot(data=df, x='status', y=i, ax=ax[index,1]);
プロットの最初の列では、すべての分布が正規分布に従っており、候補者の教育成績のほとんどが 60 ~ 80% の間にあることがわかります。
XNUMX 番目の列には、右側に「Placed」クラス、左側に「Not Placed」クラスの二重ボックス プロットがあります。 「etest_p」機能と「mba_p」機能については、モデル構築の観点からこれら XNUMX つのディストリビューションに大きな違いはありません。 クラス全体の分布にはかなりの重複があるため、これらの特徴はターゲットの適切な予測子にはなりません。 残りの機能については、ターゲットの潜在的な優れた予測因子として十分に明確です。 カテゴリ機能に移りましょう。 それらを調べるために、カウント プロットを使用します。
fig,ax=plt.subplots(7,2,figsize=(15,35))
for index,i in enumerate(df.select_dtypes("object").drop(columns="status")): plt.suptitle("Visualizing Count of Categorical Columns",size=20) sns.countplot(data=df,x=i,ax=ax[index,0]) sns.countplot(data=df,x=i,ax=ax[index,1],hue="status")
プロットを見ると、女性よりも男性の候補者が多いことがわかります。 また、ほとんどの候補者は実務経験がありませんが、これらの候補者は、実務経験のある候補者よりも多く採用されています。 「hsc」コースとして商業を行った候補者がいます。学部生と同様に、科学のバックグラウンドを持つ候補者は両方のケースで XNUMX 番目に高くなっています。
ロジスティック回帰モデルについて少し注意してください。これらは分類用ですが、線形回帰などの他の線形モデルと同じグループに属します。そのため、両方とも線形モデルであるためです。 多重共線性の問題についても心配する必要があります。 したがって、相関行列を作成する必要があり、それをヒートマップにプロットする必要があります。 ここではすべての特徴を見たいわけではありません。数値的な特徴だけを見たいのです。また、ターゲットを含めたくありません。 ターゲットがいくつかの機能と相関する場合、それは非常に良いことです。
corr = df.select_dtypes("number").corr()
# Plot heatmap of `correlation`
plt.title('Correlation Matrix')
sns.heatmap(corr, vmax=1, square=True, annot=True, cmap='GnBu');
これは、相関がほとんどまたはまったくないことを意味する水色と、相関が高いことを意味する濃い青です。 そのため、私たちはそれらのダークブルーに目を光らせたいと考えています. このプロットの中央を下る斜めの線である濃い青色の線が見えます。 それらは、それ自体と相関する機能です。 そして、いくつかの暗い四角が見えます。 これは、機能間に多数の相関関係があることを意味します。
EDA の最後のステップで、カテゴリ特徴の高低カーディナリティを確認する必要があります。 カーディナリティとは、カテゴリ変数の一意の値の数を指します。 カーディナリティが高いということは、カテゴリ特徴に多数の一意の値があることを意味します。 機能のカーディナリティを高くする一意の値の正確な数はありません。 ただし、カテゴリ特徴の値がほとんどすべての観測で一意である場合は、通常は削除できます。
# Check for high- and low-cardinality categorical features
df.select_dtypes("object").nunique() gender 2
ssc_b 2
hsc_b 2
hsc_s 3
degree_t 3
workex 2
specialisation 2
status 2
dtype: int64一意の値の数が XNUMX つまたは非常に多い列はありません。 しかし、ここで欠落しているカテゴリ型の列が XNUMX つあります。 その理由は、オブジェクトとしてではなく整数としてエンコードされているためです。 「sl_no」列は、私たちが知っている意味では整数ではありません。 これらの候補は、ある順序でランク付けされます。 ユニークなネームタグだけで、名前はカテゴリーのようなものですよね? したがって、これはカテゴリ変数です。 情報がないので、削除する必要があります。
df.drop(columns="sl_no", inplace=True)特徴のエンコーディング
分析を終了しました。次に行う必要があるのは、カテゴリ特徴をエンコードすることです。「LabelEncoder」を使用します。 ラベル エンコーディングは、カテゴリ変数を処理するための一般的なエンコーディング手法です。 この手法を使用すると、アルファベット順に基づいて各ラベルに一意の整数が割り当てられます。
lb = LabelEncoder () cat_data = ['gender', 'ssc_b', 'hsc_b', 'hsc_s', 'degree_t', 'workex', 'specialisation', 'status']
for i in cat_data: df[i] = lb.fit_transform(df[i]) df.head()
スプリット
データをインポートしてクリーニングしました。 少し探索的なデータ分析を行ったので、データを分割する必要があります。 分割には XNUMX つのタイプがあります。垂直分割または機能ターゲットと水平分割またはトレーニング テスト セットです。垂直分割から始めましょう。 特徴行列「X」とターゲット ベクトル「y」を作成します。 目指すは「ステータス」。 私たちの機能は、「df」に残っているすべての列である必要があります。
#vertical split
target = "status"
X = df.drop(columns = target)
y = df[target]モデルは通常、トレーニング用に正規化されたデータを使用するとパフォーマンスが向上します。正規化とは何ですか? 正規化 いくつかの変数の値を同様の範囲に変換しています。 私たちの目標は、変数を正規化することです。 したがって、それらの値の範囲は 0 から 1 になります。そうしましょう。「StandardScaler」を使用します。
scaler = StandardScaler()
X = scaler.fit_transform(X)次に、水平分割またはトレーニング テスト セットを実行しましょう。 ランダム化されたトレーニングとテストの分割を使用して、データ (X と y) をトレーニング セットとテスト セットに分割する必要があります。 テスト セットは全データの 20% である必要があります。 また、再現性のために random_state を設定することも忘れていません。
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size = 0.2, random_state = 42 ) print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape) X_train shape: (172, 12)
y_train shape: (172,)
X_test shape: (43, 12)
y_test shape: (43,)ロジスティック回帰モデルの構築
ベースライン
それでは、モデルの構築を開始する必要があり、ベースラインを設定するために注文を開始する必要があります。 私たちが扱っている問題のタイプは分類の問題であり、分類モデルを評価するためのさまざまなメトリックがあることに注意してください。 私が注目したいのは、精度スコアです。
さて、正解率は? 機械学習の精度スコアは、行われた予測の総数に対する、モデルによって行われた正しい予測の数を測定する評価指標です。 正しい予測の数を予測の総数で割って計算します。 つまり、精度スコアが 0 から 1 の間になるということです。XNUMX は良くありません。 それはあなたがなりたくない場所であり、XNUMXつは完璧です. ベースラインとは、観察結果に関係なく、XNUMX つの予測を何度も繰り返すモデルであることを覚えておいてください。
私たちの場合、配置されているかどうかにかかわらず、XNUMX つのクラスがあります。 では、予測を XNUMX つだけ行うことができるとしたら、XNUMX つの推測は何でしょうか? マジョリティクラスと言えば。 それは理にかなっていると思いますよね? 予測が XNUMX つしかない場合は、おそらく、データセットで観測値が最も高いものを選択する必要があります。 したがって、ベースラインでは、トレーニング データに多数派クラスが現れるパーセンテージが使用されます。 モデルがこのベースラインを上回っていない場合、機能は観測を分類するための貴重な情報を追加していません。
「value_counts」メソッドを「normalize = True」引数とともに使用して、ベースラインの精度を計算できます。
acc_baseline = y_train.value_counts(normalize=True).max()
print("Baseline Accuracy:", round(acc_baseline, 2)) Baseline Accuracy: 0.68ベースラインの精度は 68%、つまり割合として 0.68 であることがわかります。 ですから、役に立つ価値を付加するためには、その数を超えて XNUMX に近づきたいのです。 それが私たちの目標です。では、モデルの構築を始めましょう。
繰り返す
ここで、ロジスティック回帰を使用してモデルを構築します。 ロジスティック回帰を使用しますが、その前に、ロジスティック回帰とは何か、どのように機能するかについて少し話してから、コーディング作業を行うことができます. そのために、ここに小さなグリッドがあります。
x 軸に沿って、データ セットに候補の p_degrees があるとします。 右から左に移動すると、次数がどんどん高くなり、Y 軸に沿って、配置可能なクラスが XNUMX と XNUMX になります。

では、データ ポイントをプロットすると、どのように見えるでしょうか? 私たちの分析によると、「p_degree」が高い候補者は採用される可能性が高くなります。 ということで、p_degree が小さい候補は XNUMX に下がってしまう、こんな感じになるのではないでしょうか。 そして、「p_degree」が高い候補は XNUMX になります。

ここで、これで線形回帰を行いたいとしましょう。 線をプロットしたいとしましょう。
これを行うと、すべてのポイントにできるだけ近づけるように線がプロットされます。 そのため、おそらく次のような行になります。 これは良いモデルになるでしょうか?

あまり。 何が起こるかというと、候補の p_degree に関係なく、常にある種の値が得られます。 この文脈では、数字は何の意味もないので、それは私たちの助けにはなりません。 この分類問題は、ゼロか XNUMX である必要があります。 したがって、そのようには機能しません。
一方、これは線なので、p_degree が非常に低い候補がある場合はどうなるでしょうか。 さて、突然、私たちの見積もりは負の数になりました。 繰り返しますが、これは意味がありません。 ゼロまたは XNUMX である必要がある負の数はありません。 同様に、p_degree が非常に高い候補者がいる場合、XNUMX を超える何かが陽性である可能性があります。 繰り返しますが、それは意味がありません。 ゼロか XNUMX が必要です。

したがって、ここで見られるのは、分類に線形回帰を使用する際の重大な制限です。 それで、私たちは何をする必要がありますか? 第一に、ゼロを下回ったり XNUMX を上回ったりしないモデルを作成する必要があるため、XNUMX と XNUMX の間でバインドする必要があります。 第二に、その関数から得られるもの、作成した方程式は、それ自体を予測として扱うのではなく、最終的な予測を行うためのステップとして扱うべきです。
さて、今言ったことを解き明かしましょう。線形回帰モデルを実行しているとき、最終的にこの線形方程式になることを思い出してください。これは最も単純な形式です。 そして、これがその直線を与える方程式または関数です。

その線を 0 と 1 の間でバインドする方法があります。そして、作成したばかりのこの関数を別の関数 (シグモイド関数と呼ばれるもの) で囲むことができます。

ですから、先ほど得た線形方程式をシグモイド関数に縮小して指数関数として入れます。

何が起こるかというと、直線ではなく、このような線になります。 一つに詰まっています。 それは入ってきて、くねくねと下ります。 その後、ゼロでスタックします。

そうです、これが線の外観であり、最初の問題を解決したことがわかります。 この関数から得られるものはすべて 0 と 1 の間になります。XNUMX 番目のステップでは、この方程式から得られるものを最終的な予測として扱いません。 代わりに、確率として扱います。

どういう意味ですか? つまり、予測を行うと、0 から 1 の間の浮動小数点値が得られます。そして、それを予測が陽性クラスに属する確率として扱います。
したがって、値は 0.9999 になります。 この候補者が私たちの正の順位クラスに属する確率は 99% です。 だから私はそれが陽性クラスに属しているとほぼ確信しています。 逆に、ポイント 0.001 などで低下している場合、この数値は低いと言えます。 この特定の観測値がポジティブに属する確率、配置されたクラスはほぼゼロです。 それで、それはクラス XNUMX に属していると言うつもりです。
したがって、0.5 に近い数値または XNUMX に近い数値については意味があります。 しかし、その間に他の値を入れてどうすればよいのだろうかと自問するかもしれません。 うまくいく方法は、XNUMX にカットオフラインを設定することです。そのため、その線を下回る値はすべてゼロに設定されます。したがって、私の予測はノーであり、それがその線を上回っている場合は、ポイント XNUMX を上回っている場合です。 、これをポジティブクラスに入れます、私の予測はXNUMXつです。

これで、0.5 と 50 の間の予測を行う関数ができました。これを確率として扱います。 そして、その確率が 50 または 1000% を超えている場合は、正のクラス XNUMX です。 XNUMX% 未満の場合、それはネガティブ クラス、ゼロです。 これがロジスティック回帰の仕組みです。 これで理解できたので、コードを作成して適合させましょう。 ハイパーパラメーター 'max_iter' を XNUMX に設定します。このパラメーターは、ソルバーが収束するための反復の最大回数を示します。
# Build model
model = LogisticRegression(max_iter=1000) # Fit model to training data
model.fit(X_train, y_train) LogisticRegression(max_iter=1000)評価します
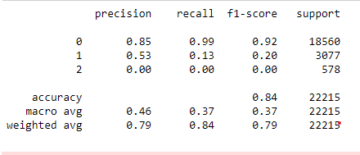
では、モデルがどのように機能するかを見てみましょう。 ロジスティック回帰モデルを評価する時が来ました。 ですから、今回関心のあるパフォーマンス メトリクスは精度スコアであり、正確なスコアが必要であることを思い出してください。 そして、0.68 のベースラインを打ち破りたいと考えています。 モデルの精度は、 accuracy_score 関数を使用して計算できます。 この関数には、真のラベルと予測されたラベルの XNUMX つの引数が必要です。
acc_train = accuracy_score(y_train, model.predict(X_train))
acc_test = model.score(X_test, y_test) print("Training Accuracy:", round(acc_train, 2))
print("Test Accuracy:", round(acc_test, 2)) Training Accuracy: 0.9
Test Accuracy: 0.88トレーニングの精度が 90% であることを確認できます。 ベースラインを超えています。 私たちのテスト精度は 88% と少し低かった. また、ベースラインを上回り、トレーニングの精度に非常に近かった. これは、私たちのモデルが過適合などではないことを意味するため、朗報です。
ロジスティック回帰モデルの結果
ロジスティック回帰では、これらの最終予測が XNUMX または XNUMX になることを思い出してください。 しかし、その予測の下には、XNUMX または XNUMX の間の浮動小数点数の確率があり、これらの確率の推定値を確認すると役立つ場合があります。 トレーニング予測を見てみましょう。最初の XNUMX つを見てみましょう。 'predict' メソッドは、ラベルのない観測のターゲットを予測します。
model.predict(X_train)[:5] array([0, 1, 1, 1, 1])以上が最終的な予測でしたが、その背後にある確率はどのくらいなのでしょうか? それらを取得するには、少し異なるコードを実行する必要があります。 モデルで「predict」メソッドを使用する代わりに、トレーニング データで「predict_proba」を使用します。
y_train_pred_proba = model.predict_proba(X_train)
print(y_train_pred_proba[:5]) [[0.92003219 0.07996781] [0.03202019 0.96797981] [0.00678421 0.99321579] [0.03889446 0.96110554] [0.00245525 0.99754475]]0.07 つの異なる列を含む一種のネストされたリストを見ることができます。 左側の列は、候補者が配置されない確率、またはネガティブ クラス「配置されない」を表します。 もう 50 つの列は、陽性クラス「配置」または候補者が配置される確率を表します。 0.5 番目の列に焦点を当てます。 最初の確率推定値を正しく見ると、これが XNUMX であることがわかります。 これは XNUMX% 未満なので、私たちのモデルによると、私の予測はゼロです。 そして、次の予測では、それらがすべて XNUMX を超えていることがわかります。これが、モデルが最終的に XNUMX を予測した理由です。
ここで、機能名と重要度を抽出して、それらをシリーズにまとめたいと思います。 また、機能の重要度をオッズ比として表示する必要があるため、重要度の指数関数を使用して、わずかな数学的変換を行うだけで済みます。
# Features names
features = ['gender', 'ssc_p', 'ssc_b', 'hsc_p', 'hsc_b', 'hsc_s', 'degree_p' ,'degree_t', 'workex', 'etest_p', 'specialisation', 'mba_p']
# Get importances
importances = model.coef_[0]
# Put importances into a Series
odds_ratios = pd.Series(np.exp(importances), index= features).sort_values()
# Review odds_ratios.head() mba_p 0.406590
degree_t 0.706021
specialisation 0.850301
hsc_b 0.876864
etest_p 0.877831
dtype: float64オッズ比とその内容について説明する前に、横棒グラフで見てみましょう。 pandas を使用してプロットを作成しましょう。最大の XNUMX つの係数を探すことを思い出してください。 そして、すべてのオッズ比を使用したくはありません。 ですから、しっぽを使いたいのです。
# Horizontal bar chart, five largest coefficients
odds_ratios.tail().plot(kind="barh")
plt.xlabel("Odds Ratio")
plt.ylabel("Feature")
plt.title("High Importance Features");
ここで、5 の位置にある垂直線を想像していただきたいと思います。まず、それを見ることから始めたいと思います。 これらのそれぞれについて個別に、または最初のカップルだけについて話しましょう。 それでは、ここで「ssc_p」から始めましょう。これは、「中等教育の割合 – 10 年生」を指します。 オッズ比が 30 であることがわかります。これはどういう意味ですか? これは、候補者の「ssc_p」が高い場合、その配置のオッズは他の候補者の XNUMX 倍であり、すべてが等しいことを意味します。 別の見方をすれば、候補者が「ssc_p」を持っている場合、その候補者の採用の可能性は XNUMX 倍になります。
したがって、オッズ比が XNUMX を超えると、候補者が配置されるオッズが増加します。 そのため、縦線が XNUMX になっています。 そして、これらの XNUMX 種類の特徴は、採用の増加に最も関連する特徴です。 それが私たちのオッズ比です。 これで、採用の増加に最も関連する機能を見てきました。 それに関連する機能、採用の減少を見てみましょう。 それでは、最小のものを見てみましょう。 ですから、尻尾を見る代わりに、尻尾を見てみましょう。
odds_ratios.head().plot(kind="barh")
plt.xlabel("Odds Ratio")
plt.xlabel("Odds Ratio")
plt.ylabel("Feature")
plt.title("Low Importance Features");
ここで最初に確認する必要があるのは、x 軸のすべてが 0.45 以下であることです。 さて、それはどういう意味ですか? では、ここで最小オッズ比を見てみましょう。 MBAパーセンテージを参照するのはmba_pです。 約 0.45 で準備ができていることがわかります。 さて、それはどういう意味ですか? 1 と 0.55 の差は 55 です。 わかった? そして、その数字は何を意味するのでしょうか? MBA を取得した候補者は、採用される可能性が 0.55% 低くなります。他のすべての条件が同じ場合です。 わかった? したがって、採用のオッズは55またはXNUMX%減少しました。 そして、それはここにあるすべてに当てはまります。
まとめ
それで、私たちは何を学びましたか? まず、準備されたデータ フェーズで、ロジスティック回帰を使用して分類、特にバイナリ分類を行っていることを学びました。 データの探索に関しては、私たちはたくさんのことをしましたが、ハイライトに関しては、クラスのバランスを見ましたよね? 陽性クラスと陰性クラスの割合。 次に、データを分割します。
ロジスティック回帰は分類モデルであるため、新しいパフォーマンス メトリックである精度スコアについて学びました。 現在、精度スコアは 0 から 1 の間です。XNUMX は悪く、XNUMX は良いです。 反復を行っているときに、ロジスティック回帰について学びました。 これは魔法のような方法です。一次方程式、直線を取り、それを別の関数、シグモイド関数、活性化関数の中に入れて、そこから確率推定値を取得し、その確率推定値を予測に変えることができます。
最後に、オッズ比と、係数を解釈して、特定の機能が候補者を採用したかどうかのオッズを増加させるかどうかを確認する方法について学びました。
プロジェクトのソースコード: https://github.com/SawsanYusuf/Campus-Recruitment.git
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/03/campus-recruitment-a-classification-problem-with-logistic-regression/
- :は
- $UP
- 1
- 10
- 11
- 214
- 7
- 8
- 9
- a
- 私たちについて
- 上記の.
- 一般に認められた
- 精度
- 正確な
- アクティベーション
- 後
- すべて
- しかし
- 常に
- 分析
- 分析論
- 分析Vidhya
- &
- 別の
- 検索&予約
- です
- 引数
- 引数
- 周りに
- 記事
- AS
- 関連する
- At
- 出席する
- 軸
- 背景
- 悪い
- バー
- ベースライン
- 基本的に
- BE
- 美しい
- なぜなら
- 始まる
- 背後に
- さ
- 以下
- より良いです
- の間に
- バインド
- ビット
- ブログソン
- 青
- 結合した
- ボックス
- ビルド
- 建物
- 束
- ビジネス
- ビジネススクール
- by
- 計算する
- 計算された
- コール
- 呼ばれます
- キャンパス
- 缶
- 候補者
- 候補
- キャリア
- 場合
- 例
- カテゴリー
- センター
- チャンス
- 特性
- チャート
- チェック
- 選択する
- class
- クラス
- 分類
- 分類します
- クリア
- 閉じる
- クローザー
- コード
- コーディング
- カレッジ
- コラム
- コラム
- 貿易
- 伝える
- 懸念
- 結論
- 接続
- 含まれています
- コンテキスト
- 連続的な
- 収束する
- 基本
- 企業
- 相関
- 相関関係
- 可能性
- カップル
- ここから
- 作ります
- 作成した
- カット
- 暗いです
- データ
- データ分析
- データポイント
- データサイエンス
- データセット
- 取引
- 減少
- 展開
- 説明
- 細部
- DID
- 違い
- 異なります
- 裁量
- 議論
- ディスプレイ
- 明確な
- ディストリビューション
- ディストリビューション
- そうではありません
- すること
- ドル
- ドント
- ダウン
- Drop
- 落とした
- 各
- 教育
- 教育の
- どちら
- 魅力的
- 十分な
- 初歩的な
- 推定
- 見積もり
- 等
- エーテル(ETH)
- 評価する
- 評価
- さらに
- すべてのもの
- 試験
- 除く
- 予想される
- 体験
- 説明する
- 探査
- 探索的データ分析
- 探る
- 探る
- 指数関数
- エキス
- 要因
- 特徴
- 特徴
- 女性
- File
- ファイナル
- 最後に
- 名
- フィット
- floating
- フォーカス
- 焦点
- フォロー中
- フォーム
- FRAME
- 周波数
- から
- function
- 性別
- 一般に
- 取得する
- 受け
- Gitの
- 与える
- 与える
- Go
- 目標
- 目標
- ゴエス
- 行く
- 良い
- でログイン
- グラフ
- 大きい
- グリッド
- グループ
- グループの
- ハンド
- ハンドリング
- 起こる
- 起こります
- 持ってる
- 助けます
- 役立つ
- こちら
- ハイ
- より高い
- 最高
- ハイライト
- 雇用
- 水平な
- 認定条件
- How To
- HTTPS
- i
- 私は
- 考え
- 不均衡
- import
- 重要性
- 重要
- in
- include
- 増える
- 増加した
- 増加
- index
- インド
- 個人
- 個別に
- info
- 情報
- を取得する必要がある者
- 興味がある
- 紹介する
- 概要
- 関係する
- 関与
- 問題
- IT
- 繰り返し
- キープ
- 種類
- 知っている
- ラベル
- ラベル
- 大
- 最大の
- 姓
- LEARN
- 学んだ
- 学習
- ライブラリ
- 図書館
- 光
- ような
- 可能性が高い
- 制限
- LINE
- リスト
- 少し
- 負荷
- 見て
- のように見える
- 見
- 探して
- LOOKS
- たくさん
- ロー
- 機械
- 機械学習
- 製
- 大多数
- make
- 作る
- 作成
- 多くの
- math
- 数学的
- matplotlib
- マトリックス
- MBAを取得
- 手段
- 措置
- メディア
- 大会
- メモリ
- 方法
- メトリック
- メトリック
- 真ん中
- かもしれない
- 百万
- 万ドル
- マインド
- 行方不明
- モデル
- 他には?
- 最も
- 名
- 名
- 必要
- ニーズ
- 負
- 新作
- ニュース
- 次の
- 通常の
- ノート
- 数
- 番号
- numpy
- オブジェクト
- オッズ
- of
- 提供
- 良い
- on
- ONE
- 注文
- その他
- 所有している
- パンダ
- パラメーター
- 部
- 特定の
- 割合
- 完璧
- 実行する
- パフォーマンス
- 公演
- 人
- 視点
- 相
- 場所
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- ポイント
- 人気
- ポジション
- 正の
- 可能
- 潜在的な
- 予測する
- 予測
- 予測
- 予測
- 予測
- Predictor
- 予測
- 準備
- 準備
- 準備中
- かなり
- ブランド
- 確率
- 多分
- 問題
- 問題
- プロジェクト
- 公表
- 置きます
- 質問
- ランダム化
- 範囲
- ランク
- 比
- 読む
- 準備
- リアル
- 現実の世界
- 理由
- 最近
- 記録
- 募集
- 指し
- 関係なく
- 回帰
- 関係
- 残る
- 覚えています
- 報酬
- 表し
- 必要
- REST
- 結果
- レビュー
- 前記
- 給与
- 同じ
- 言う
- 学校
- 科学
- scikit-学ぶ
- 海生まれ
- シーズン
- 二番
- と思われる
- センス
- シリーズ
- 深刻な
- サービス
- セッションに
- セット
- セブン
- いくつかの
- 形状
- すべき
- 示す
- 作品
- 重要
- から
- SIX
- わずかに異なる
- 小さい
- 最小
- So
- 解決
- 一部
- 何か
- ソース
- ソースコード
- 部品調達
- 特に
- split
- 正方形
- 標準
- start
- Status:
- 手順
- ステップ
- ストレート
- 戦略
- 生徒
- そのような
- 突然の
- スーパー
- TAG
- 取る
- 取得
- 才能
- Talk
- ターゲット
- 条件
- test
- それ
- アプリ環境に合わせて
- それら
- 自分自身
- ボーマン
- もの
- 物事
- 考える
- 三番
- 時間
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- トン
- トータル
- に向かって
- トレーニング
- トレーニング
- 変換
- 変換
- 治療する
- true
- 順番
- 究極の
- わかる
- ユニーク
- 大学
- アップロード
- us
- 使用法
- つかいます
- 通常
- 貴重な
- 貴重な情報
- 値
- 価値観
- variables
- さまざまな
- 可視化
- wanted
- 仕方..
- WELL
- この試験は
- 何ですか
- かどうか
- which
- 誰
- 意志
- 仕事
- ワークフロー
- ワーキング
- 作品
- 世界
- でしょう
- 与えるだろう
- X
- 若い
- あなた自身
- ゼファーネット
- ゼロ