ニューラル ネットワークは数値を通じて学習するため、各単語は特定の単語を表すベクトルにマッピングされます。 埋め込みレイヤーは、単語の埋め込みを格納し、インデックスを使用してそれらを取得するルックアップ テーブルと考えることができます。
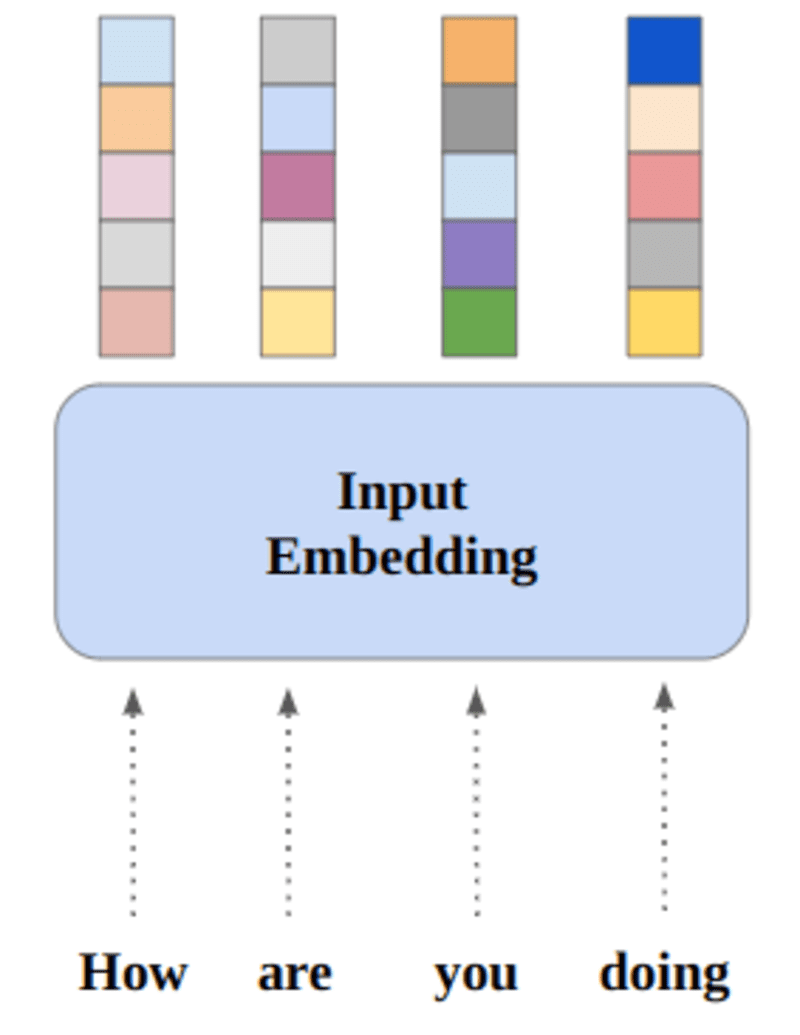
同じ意味を持つ単語は、ユークリッド距離/コサイン類似度の点で近くなります。 たとえば、以下の単語表現では、「Saturday」、「Sunday」、および「Monday」が同じ概念に関連付けられているため、単語が似ていることがわかります。

単語の位置の決定, なぜ単語の位置を決定する必要があるのですか? 変換エンコーダーには再帰型ニューラル ネットワークのような再帰がないため、位置に関する情報を入力埋め込みに追加する必要があります。 これは、位置エンコーディングを使用して行われます。 この論文の著者は、単語の位置をモデル化するために次の関数を使用しました。
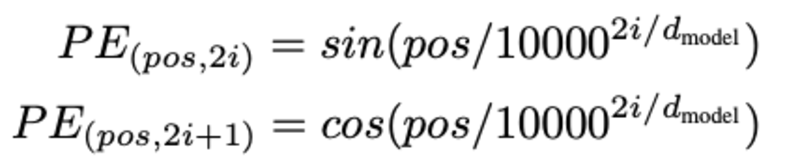
位置エンコーディングについて説明します。
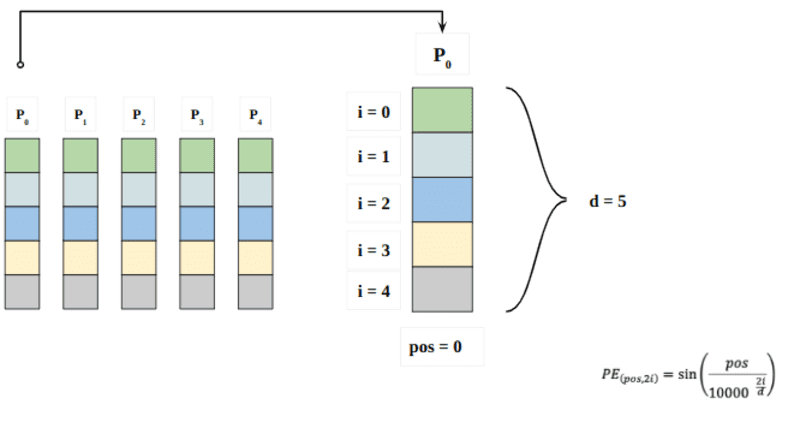
ここで「pos」は、シーケンス内の「単語」の位置を指します。 P0 は、最初の単語の位置埋め込みを指します。 「d」は、単語/トークンの埋め込みのサイズを意味します。 この例では d=5 です。 最後に、「i」は、埋め込みの 5 つの個別の次元 (つまり、0、1,2,3,4、XNUMX、XNUMX、XNUMX) のそれぞれを指します。
上記の式で「i」が変化すると、さまざまな周波数の曲線が多数得られます。 異なる周波数に対する位置埋め込み値を読み取り、P0 と P4 に異なる埋め込み次元で異なる値を与えます。
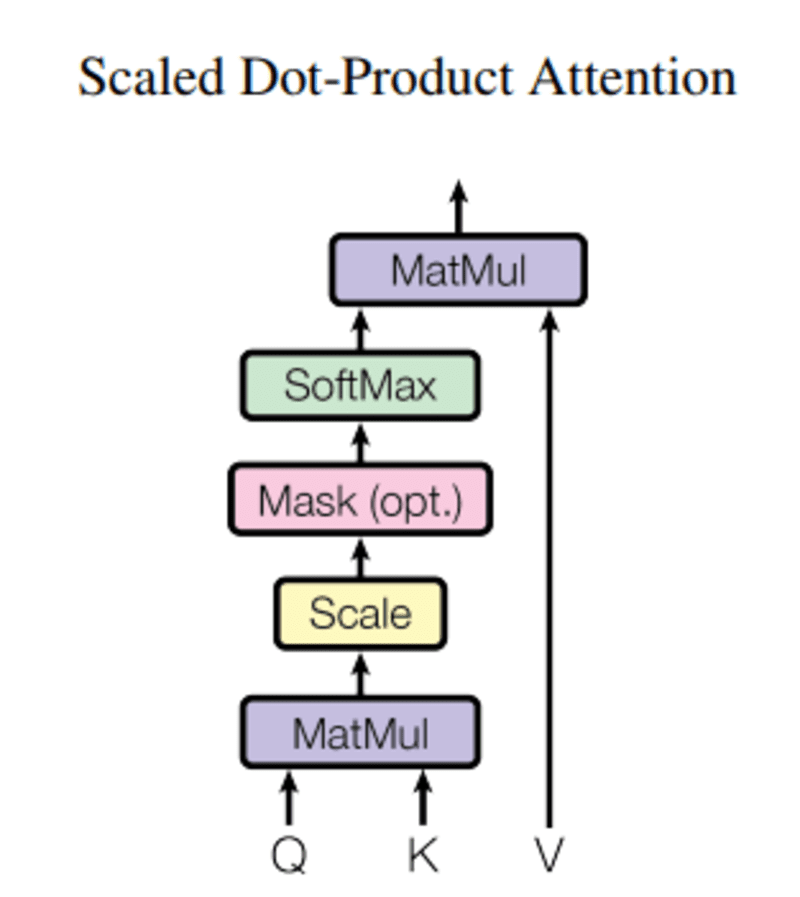
この中の クエリ、Q ベクトル単語を表し、 キーK 文中の他のすべての単語であり、 値 V 単語のベクトルを表します。
注意の目的は、同じ人物/物または概念に関連するクエリ タームと比較して、キー タームの重要性を計算することです。
この場合、V は Q に等しくなります。
注意メカニズムは、文中の単語の重要性を示します。
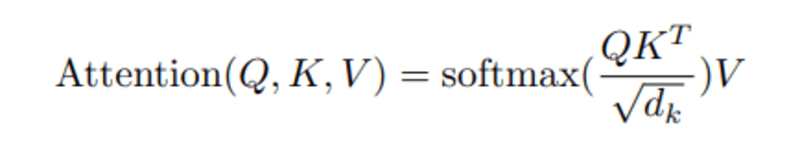
クエリとキーの間の正規化された内積を計算すると、クエリの他の単語の相対的な重要性を表すテンソルが得られます。
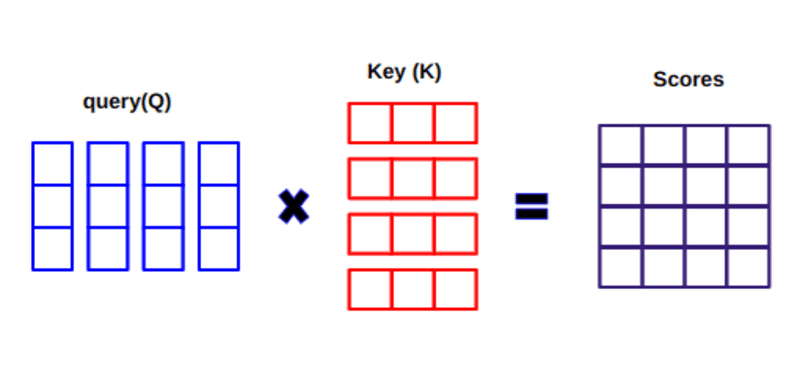
Q と KT の間の内積を計算するとき、ベクトル (クエリとキーの間の単語) がどのように配置されているかを推定し、文内の各単語の重みを返します。
次に、d_k の二乗結果を正規化し、softmax 関数が項を正則化し、0 と 1 の間で再スケーリングします。
最後に、結果 (つまり、重み) に値 (つまり、すべての単語) を掛けて、関連性のない単語の重要性を減らし、最も重要な単語だけに注目します。
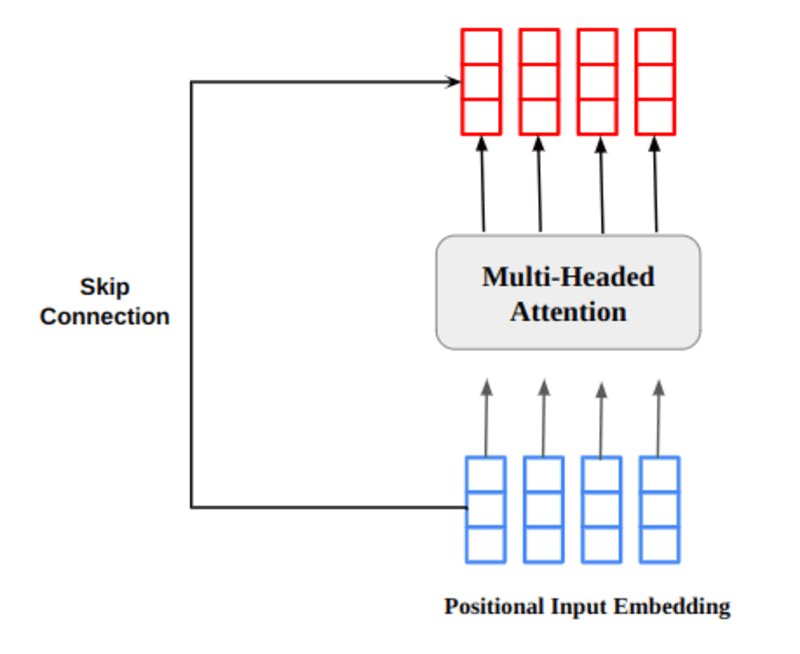
多頭注意出力ベクトルは、元の位置入力埋め込みに追加されます。 これを残留コネクション・スキップコネクションと呼ぶ。 残りの接続の出力は、層の正規化を通過します。 正規化された残差出力は、さらに処理するために点ごとのフィードフォワード ネットワークに渡されます。
マスクは、0 と負の無限大の値で満たされたアテンション スコアと同じサイズのマトリックスです。
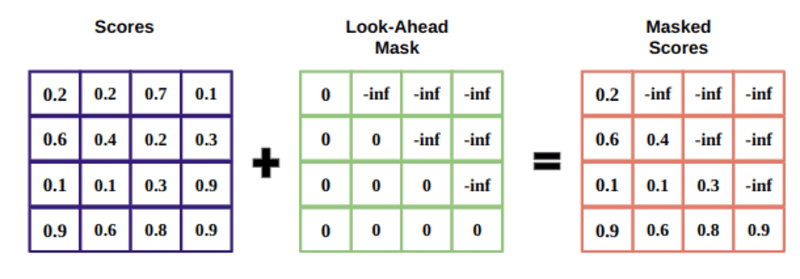
マスクの理由は、マスクされたスコアのソフトマックスを取得すると、負の無限大がゼロになり、将来のトークンのアテンション スコアがゼロになるためです。
これは、これらの単語に焦点を当てないようにモデルに指示します。
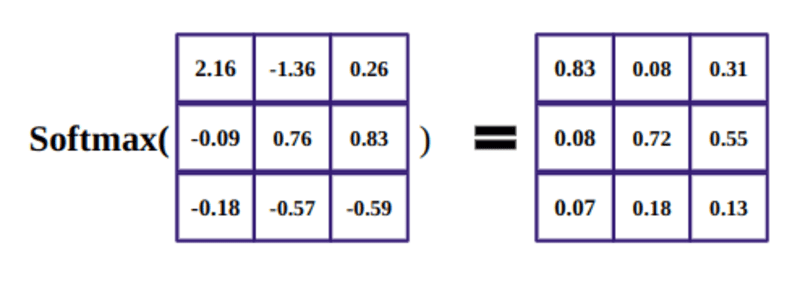
ソフトマックス関数の目的は、実数 (正と負) を取得し、合計が 1 になる正の数に変換することです。
ラビクマール・ナドゥビン PyTorch を使用した NLP タスクの構築と理解に忙しい。
元の。 許可を得て転載。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/01/concepts-know-getting-transformer.html?utm_source=rss&utm_medium=rss&utm_campaign=concepts-you-should-know-before-getting-into-transformer
- 1
- a
- 私たちについて
- 上記の.
- 追加されました
- に対して
- 整列した
- すべて
- &
- 関連する
- 注意
- 著者
- なぜなら
- 以下
- の間に
- 建物
- 束
- 呼ばれます
- 場合
- 閉じる
- 比べ
- 計算
- コンピューティング
- コンセプト
- コンセプト
- 接続
- 決定する
- 決定
- 異なります
- 大きさ
- DOT
- 各
- 推定
- 例
- 説明する
- 埋め
- 最後に
- 名
- フォーカス
- フォロー中
- function
- 機能
- さらに
- 未来
- 取得する
- 受け
- GitHubの
- 与える
- 与え
- ゴエス
- グラブ
- 認定条件
- HTTPS
- 重要性
- 重要
- in
- 索引
- 個人
- 情報
- KDナゲット
- キー
- キー
- 知っている
- 層
- LEARN
- 残す
- 検索
- mask
- マトリックス
- 意味
- 手段
- メカニズム
- 最も
- 必要
- 負
- ネットワーク
- ネットワーク
- ニューラル
- ニューラルネットワーク
- NLP
- 番号
- オリジナル
- その他
- 紙素材
- 特定の
- 渡された
- 許可
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 位置
- ポジション
- 正の
- 処理
- プロダクト
- 目的
- 置きます
- パイトーチ
- リーディング
- リアル
- 理由
- 再発
- 減らします
- 指し
- 関連する
- 表す
- 表現
- 表し
- 結果
- 結果として
- return
- 同じ
- 文
- シーケンス
- すべき
- 同様の
- サイズ
- So
- 一部
- 二乗
- 店舗
- テーブル
- 取る
- タスク
- 伝える
- 条件
- 考え
- 介して
- 〜へ
- トークン
- トランスフォーマー
- 順番
- 理解する
- us
- 値
- 価値観
- 重量
- which
- 意志
- Word
- 言葉
- ゼファーネット
- ゼロ







