この記事は、の一部として公開されました データサイエンスブログソン
概要
こんにちは、みんな! サイバーパンクはまだ私たちの生活にそれほど浸透しておらず、ニューロインターフェースは理想からほど遠いですが、LiDARはマニピュレーターの未来への道の最初の段階になる可能性があります。 したがって、休暇中に退屈しないように、私はコンピューターの制御について少し想像することにしました。おそらく、掘削機、宇宙船、ドローン、ストーブまでのあらゆるデバイスです。
主なアイデアは、マウスを動かして、手全体ではなく人差し指だけを動かすことです。これにより、キーボードから手を離さずにメニューを実行し、ボタンを押して、ホットキーと一緒に、本物のキーボード忍者! スワイプまたはスクロールジェスチャを追加するとどうなりますか? 爆弾があると思います! しかし、この瞬間まで、私たちはまだ数年待たなければなりません)
未来のマニピュレータのプロトタイプの組み立てを始めましょう
あなたが必要なもの:
-
LiDAR Intel RealsenseL515を搭載したカメラ。
-
Pythonでプログラムする機能
-
学校の数学を少し覚えておいてください
-
モニター、別名三脚にカメラを取り付けます。
私たちはaliexpressでカメラを三脚に取り付けます、それは非常に便利で、軽量で安価であることがわかりました)


プロトタイプを作成する方法と方法を理解します
このタスクを達成するための多くのアプローチがあります。 検出器または手のセグメンテーションを自分でトレーニングし、右手の結果の画像を切り取ってから、Facebookの調査からこの素晴らしいリポジトリを画像に適用して、優れた結果を得るか、さらに簡単にすることができます。
メディアパイプリポジトリを使用するには、このリンクを読んだ後, これが今日の最良の選択肢のXNUMXつであることを理解できます。
まず、すべてが箱から出してすぐに使用できます。すべての前提条件を考慮すると、インストールと起動には30分かかります。
第二に、強力な開発チームのおかげで、彼らは最先端の手のポーズ推定を行うだけでなく、理解しやすいAPIも提供します。
第XNUMXに、ネットワークはCPUで実行する準備ができているため、エントリのしきい値は最小限に抑えられます。
おそらく、なぜ私がここに来なかったのか、そしてこのコンテストの勝者のリポジトリを使用しなかったのか、あなたは尋ねるでしょう。 実際、私はそれらのソリューションをある程度詳細に研究しました。それらは非常に製品対応であり、何百万ものグリッドのスタックなどはありません。しかし、最大の問題は、深度画像で機能することです。 これらは学者であるため、Matlabを介してすべてのデータを変換することを躊躇しませんでした。さらに、深度が撮影された解像度は私には小さかったようです。 これは結果に大きな影響を与える可能性があります。 したがって、最も簡単な方法は、RGB画像のキーポイントを取得し、XY座標によって深度フレームのZ軸に沿って値を取得することであると思われます。 今のタスクは何かをあまり最適化することではないので、開発の観点からはより速いのでそれを行います。
学校の数学を覚えている
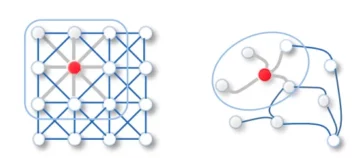
すでに書いたように、マウスカーソルがあるべき点の座標を取得するには、指の指節のXNUMXつの重要な点を通る線を作成し、線と線の交点を見つける必要があります。モニターの平面。

写真は、モニターの平面とそれと交差する線を概略的に示しています。 あなたはここで数学を見ることができます。
XNUMXつのポイントを使用して、空間内の直線のパラメトリック表現を取得します。


私は学校の数学のカリキュラムにあまり焦点を合わせません。
カメラを操作するためのライブラリのインストール
これはおそらくこの仕事の最も難しい部分です。 結局のところ、Ubuntu用のカメラのソフトウェアは非常に粗雑で、リベラルな感覚にはあらゆる種類のバグ、グリッチ、タンバリンとのダンスが散らばっています。
今まで、カメラの奇妙な振る舞いを打ち負かすことができませんでした、時々それは起動時にパラメータをロードしません。
コンピュータを再起動した後、カメラは一度だけ動作します!!! しかし、解決策があります。各起動の前に、カメラのソフトウェアハードリセットを実行し、USBをリセットすると、すべてがうまくいく可能性があります。 ちなみに、Windows 10の場合、すべて問題ありません。 開発者がWindowsベースのロボットを想像するのは奇妙です=)
Ubuntu 20で本当の意味を理解するには、次のようにします。
$ sudo apt-get install libusb-1.0-0-dev次に、cmakeを再実行します & インストールします。 ここ is うまくいった完全なレシピ for 私:$ sudo apt-get install libusb-1.0-0-dev $ git clone https://github.com/IntelRealSense/librealsense.git $ cd librealsense / $ mkdir build && cd build
ある種から収集したので、多かれ少なかれ安定します。 テクニカルサポートとの16か月のコミュニケーションにより、Ubuntu XNUMXをインストールする必要があるか、苦しんでいることが明らかになりました。 私はそれを自分で選びました、あなたは何を知っていますか。
私たちはニューラルネットワークの複雑さを理解し続けています
それでは、指とマウスの操作の別のビデオを見てみましょう。 ポインタは一箇所に立つことはできず、いわば目的のポイントの周りに浮かんでいることに注意してください。 同時に、必要な単語に簡単に向けることができますが、文字を使用すると、より難しくなり、カーソルを慎重に移動する必要があります。
あなたが理解しているように、これは私の手を振っていません、休日に私はニューイングランドDIPAのマグカップをXNUMXつだけ飲みました=)それはすべて、ライダーから得られた値に基づいたキーポイントとZ座標の絶え間ない変動についてです。
詳細を見てみましょう:
メディアパイプからのSOTAでは、確かに変動は少ないですが、変動も存在します。 結局のところ、現在のフレームと列車のネットワークで過去のフレームヒートマップのprokid vaniyaを使用することで、これに苦労しています。安定性は向上しますが、100%ではありません。
また、私には、マークアップの特異性が役割を果たしているように思われます。 フレームの解像度がどこでも異なり、それほど大きくないという事実は言うまでもなく、このような数のフレームで同じマークアップを作成することはほとんど不可能です。 また、光のちらつきは見られません。これは、操作期間やカメラの露出量が異なるため、おそらく一定ではありません。 また、ネットワークはヒートマップから画面上のキーポイントの数に等しいサンドイッチを返します。このテンソルのサイズはBxNx96x96です。ここで、Nはキーポイントの数であり、もちろん、しきい値を設定して元のサイズに変更した後です。フレームサイズ、取得したものを取得します(
ヒートマップのレンダリング例:

コードレビュー
すべてのコードはこのリポジトリにあり、非常に短いです。 メインファイルを見て、残りを自分で見てみましょう。
import cv2
import メディアパイプ as mp
import numpy as np
import pyautogui
import pyrealsense2.pyrealsense2 as rs
から google.protobuf.json_format import メッセージをディクテーションする
から mediapipe.python.solutions.drawing_utils import _ピクセル座標に正規化
から ピンプット import キーボード
から utils.common import get_filtered_values、draw_cam_out、get_right_index
から utils.hard_reset import ハードウェアリセット
から utils.set_options import set_short_range pyautogui.FAILSAFE = False mp_drawing = mp.solutions.drawing_utils mp_hands = mp.solutions.hands#手のポーズ推定hands = mp_hands.Hands(max_num_hands = 2、min_detection_confidence = 0.9) def オンプレス(鍵):
if キー== keyboard.Key.ctrl:pyautogui.leftClick()
if キー== keyboard.Key.alt:pyautogui.rightClick()
def 色の深さの取得(pipeline、align、colorizer):frames = pipe.wait_for_frames(timeout_ms = 15000)#カメラからのフレームを待機しますaligned_frames = align.process(frames)depth_frame = align_frames.get_depth_frame()color_frame = align_frames.get_color_frame()
if 深さ_フレーム or color_frame:
return なし、なし、なしdepth_ima = np.asanyarray(depth_frame.get_data())depth_col_img = np.asanyarray(colorizer.colorize(depth_frame).get_data())color_image = np.asanyarray(color_frame.get_data())depth_col_img = cv2。 cvtColor(cv2.flip(cv2.flip(depth_col_img、1)、0)、cv2.COLOR_BGR2RGB)color_img = cv2.cvtColor(cv2.flip(cv2.flip(color_img、1)、0)、cv2.COLOR_BGR2RGB)depth_img = np.flipud(np.fliplr(depth_img))depth_col_img = cv2.resize(depth_col_img、(1280 * 2、720 * 2))col_img = cv2.resize(col_img、(1280 * 2、720 * 2))depth_img = cv2 .resize(depth_img、(1280 * 2、720 * 2))
return color_image、depth_color_image、depth_image
def 右の座標を取得(color_image、depth_color_image):color_image.flags.writeable =誤った結果= hands.process(color_image)color_image.flags.writeable = True color_image = cv2.cvtColor(color_image、cv2.COLOR_RGB2BGR)handedness_dict = [] idx_to_coordinates = {} xy0、 xy1 =なし、なし
if results.multi_hand_landmarks:
for idx、hand_handedness in enumerate(results.multi_handedness):handedness_dict.append(MessageToDict(hand_handedness))right_hand_index = get_right_index(handedness_dict)
if right_hand_index!= -1:
for i、landmark_list in enumerate(results.multi_hand_landmarks):
if i == right_hand_index:image_rows、image_cols、_ = color_image.shape
for idx、ランドマーク in enumerate(landmark_list.landmark):landmark_px = _normalized_to_pixel_coordinates(landmark.x、landmark.y、image_cols、image_rows)
if ランドマーク_px:idx_to_coordinates [idx] =ランドマーク_px
for i、landmark_px in enumerate(idx_to_coordinates.values()):
if i == 5:xy0 = landmark_px
if i == 7:xy1 = landmark_px
破る
return col_img、depth_col_img、xy0、xy1、idx_to_coordinates
def start():pipeline = rs.pipeline()#初期化librealsense config = rs.config()print( "Start load conf")config.enable_stream(rs.stream.depth、1024、768、rs.format.z16、30) config.enable_stream(rs.stream.color、1280、720、rs.format.bgr8、30)profile = pipe.start(config)depth_sensor = profile.get_device()。 first_depth_sensor()set_short_range(depth_sensor)#短距離で作業するためのロードパラメータcolorizer = rs.colorizer()print( "Confloaded")align_to = rs.stream.color align = rs.align(align_to)#深度マップとカラー画像try:while True:col_img、depth_col_img、depth_img = get_col_depth(pipelin、align、colorize)if color_img is None and color_img is None and color_img is None:continue color_img、depth_col_img、xy00、xy11、idx_to_coordinates = get_right_hand_coords(col_img、 )xy00がNoneでない場合、またはxy11がNoneでない場合:z_val_f、z_val_s、m_xy、c_xy、xy00_f、xy11_f、x、y、z = get_filtered_values(depth_img、xy00、xy11)pyautogui.moveTo(int(x)、int (3500-z))#draw_cam_out(col_img、depth_col_img、xy3500_f、xy00_f、c_xy、m_xy)の場合、モニターに固有の11ハードコード:最終的にブレーク:hands.close()pipeline.stop()hardware_reset()#カメラを再起動して表示されるのを待つlistener = Keyboard.Listener(on_press = on_press)#キーのリスナーを設定するボードボタンがlistener.start()start()#プログラムを開始します
クラスやストリームは使用しませんでした。このような単純なケースでは、メインスレッドのすべてを無限のwhileループで実行するだけで十分だからです。
最初に、メディアパイプ、カメラが初期化され、短距離変数と補助変数のカメラ設定が読み込まれます。 次に、「ライトデプストゥカラー」と呼ばれる魔法があります。この関数は、RGB画像の各ポイント、つまりデプスフレーム上のポイントを照合します。つまり、XY座標、Z値を取得する機会を与えてくれます。 モニターで調整する必要があることは理解されています…私は意図的にこれらのパラメーターを個別に抽出しなかったので、コードを実行することを決定した読者が自分で実行すると同時に、コードで再利用されます)
次に、予測全体から、右手の5と7の番号が付けられたポイントのみを取得します。

あとは、移動平均を使って取得した座標をフィルタリングするだけです。 もちろん、より深刻なフィルタリングアルゴリズムを適用することも可能でしたが、それらの視覚化を見てさまざまなレバーを引くと、デモには5フレームの深さの移動平均で十分であることが明らかになりました。 XYの場合、2〜3フレームで十分でした。 しかし、Zでは事態はさらに悪化します。
deque_l = 5 x0_d = collections.deque(deque_l * [0。]、deque_l)y0_d = collections.deque(deque_l * [0。]、deque_l)x1_d = collections.deque(deque_l * [0。]、deque_l)y1_d = collections.deque(deque_l * [0。]、deque_l)z_val_f_d = collections.deque(deque_l * [0。]、deque_l)z_val_s_d = collections.deque(deque_l * [0。]、deque_l)m_xy_d = collections.deque(deque_l * [0。]、deque_l)c_xy_d = collections.deque(deque_l * [0。]、deque_l)x_d = collections.deque(deque_l * [0。]、deque_l)y_d = collections.deque(deque_l * [0.] 、deque_l)z_d = collections.deque(deque_l * [0。]、deque_l) def get_filtered_values(depth_image、xy0、xy1): 全体的な x0_d、y0_d、x1_d、y1_d、m_xy_d、c_xy_d、z_val_f_d、z_val_s_d、x_d、y_d、z_d x0_d.append(float(xy0 [1]))x0_f = round(mean(x0_d))y0_d 0]))y0_f = round(mean(y0_d))x0_d.append(float(xy1 [1]))x1_f = round(mean(x1_d))y1_d.append(float(xy1 [1]))y0_f = round( mean(y1_d))z_val_f = get_area_mean_z_val(depth_image、x1_f、y0_f)z_val_f_d.append(float(z_val_f))z_val_f = mean(z_val_f_d)z_val_s = get_area_mean_z_val(depth_image、x = mean(z_val_s_d)points = [(y0_f、x1_f)、(y1_f、x0_f)] x_coords、y_coords = zip(* points)A = np.vstack([x_coords、np.ones(len(x_coords))])。 T m、c = lstsq(A、y_coords)[0] m_xy_d.append(float(m))m_xy = mean(m_xy_d)c_xy_d.append(float(c))c_xy = mean(c_xy_d)a1、a1、a0、 a0 = Equation_plane()x、y、z = line_plane_intersection(y1_f、x2_f、z_v_s、y3_f、x0_f、z_v_f、a0、a1、a1、a0)x_d.append(float(x))x = round(mean(x_d) )y_d.append(float(y))y = round(mean(y_d))z_d.append(float(z))z = round(mean(z_d)) return z_v_f、z_v_s、m_xy、c_xy、(y00_f、x0_f)、(y11_f、x1_f)、x、y、z
5フレームの長さの両端キューを作成し、行のすべてを平均します=)さらに、y = mx + c、Ax + By + Cz + d = 0を計算します。直線の方程式は、RGBの光線です。画像とモニター平面の方程式から、y = 0が得られます。
まとめ
さて、それだけです。私たちは最も単純なマニピュレータを切り落としました。これは、劇的に単純な実行でも、実際の生活では困難ではありますが、すでに使用できます。
この記事に示されているメディアは、Analytics Vidhyaが所有しておらず、作成者の裁量で使用されています。
関連記事
出典:https://www.analyticsvidhya.com/blog/2021/08/hand-pose-estimation-based-on-lidar-in-30-minutes/
- "
- &
- 7
- 9
- アルゴリズム
- すべて
- 分析論
- API
- 周りに
- 宝品
- 記事
- BEST
- 最大の
- ボックス
- バグ
- ビルド
- クローザー
- コード
- コマンドと
- コミュニケーション
- コンペ
- 続ける
- カップル
- 電流プローブ
- CZ
- データ
- 詳細
- 開発者
- 開発
- DID
- 距離
- ドローン
- イングランド
- 等
- 実行
- フィギュア
- 最後に
- 終わり
- 名
- フォーカス
- 形式でアーカイブしたプロジェクトを保存します.
- function
- 未来
- Gitの
- でログイン
- こちら
- 休日
- 認定条件
- HTTPS
- アイデア
- IDX
- 画像
- index
- インテル
- IT
- ジョブ
- キー
- 大
- 起動する
- 図書館
- 対処
- 光
- LINE
- 負荷
- 地図
- 数学
- メディア
- ネットワーク
- ニューラル
- 機会
- オプション
- 注文
- 画像
- パイプ
- 視点
- 予測
- プロフィール
- 演奏曲目
- 引き
- Python
- リーダー
- リーディング
- レシピ
- 研究
- REST
- 結果
- 収益
- ロボット
- ラン
- 学校
- 科学
- 画面
- センス
- セッションに
- ショート
- 簡単な拡張で
- サイズ
- 小さい
- So
- ソフトウェア
- ソリューション
- スペース
- 安定性
- ステージ
- start
- スタートアップ
- 都道府県
- 数独
- サポート
- 技術的
- テクニカル·サポート
- 未来
- 時間
- Ubuntu
- us
- USB
- 値
- ビデオ
- 詳しく見る
- 可視化
- wait
- 誰
- ウィンドウズ
- 仕事
- 作品
- X
- 年