このブログ投稿は、CepsaのシニアデータサイエンティストであるGuillermoRibeiroによって共同執筆されました。
機械学習(ML)は、学術環境やイノベーション部門から生まれたファッショナブルなトレンドから、あらゆる業界のビジネスに価値を提供するための重要な手段へと急速に進化しました。 実験室での実験から実稼働環境での実際の問題の解決へのこの移行は、 MLOps、またはMLの世界へのDevOpsの適応。
MLOpsは、MLモデルのライフサイクル全体を合理化および自動化するのに役立ち、ソースデータセット、実験の再現性、MLアルゴリズムコード、およびモデルの品質に重点を置いています。
At Cepsaはグローバルなエネルギー企業であり、MLを使用して、産業機器の予知保全から製油所での石油化学プロセスの監視と改善まで、事業全体にわたる複雑な問題に取り組んでいます。
この投稿では、次の主要なAWSサービスを使用してMLOpsのリファレンスアーキテクチャを構築する方法について説明します。
- アマゾンセージメーカー、MLモデルを構築、トレーニング、デプロイするためのサービス
- AWSステップ関数、プロセスの調整と自動化に使用されるサーバーレスローコードビジュアルワークフローサービス
- アマゾンイベントブリッジ、サーバーレスイベントバス
- AWSラムダ、サーバーをプロビジョニングまたは管理せずにコードを実行できるサーバーレスコンピューティングサービス
また、この参照アーキテクチャを適用して、社内の新しいMLプロジェクトをブートストラップする方法についても説明します。
課題
過去4年間で、Cepsa全体の複数の事業部門がMLプロジェクトを開始しましたが、すぐに特定の問題と制限が発生し始めました。
MLの参照アーキテクチャがなかったため、各プロジェクトは異なる実装パスに従い、アドホックモデルのトレーニングと展開を実行しました。 プロジェクトのコードとパラメーターを処理する一般的な方法がなく、MLモデルレジストリまたはバージョン管理システムがないと、データセット、コード、モデル間のトレーサビリティが失われました。
また、デプロイされたモデルを監視していなかったため、モデルのパフォーマンスを追跡する手段がなかったため、本番環境でモデルを操作する方法に改善の余地があることも検出しました。 結果として、情報に基づいた再トレーニングの決定を行うための適切なメトリックが不足していたため、通常、タイムスケジュールに基づいてモデルを再トレーニングしました。
ソリューション
克服しなければならない課題から始めて、データの準備、モデルのトレーニング、推論、モデルの監視を切り離すことを目的とした一般的なソリューションを設計し、一元化されたモデルレジストリを備えました。 このようにして、一元化されたモデルのトレーサビリティを導入しながら、複数のAWSアカウントにわたる環境の管理を簡素化しました。
私たちのデータサイエンティストと開発者は AWS クラウド9 (コードの記述、実行、デバッグ用のクラウドIDE)データラングリングとML実験、およびGitコードリポジトリとしてのGitHub用。
自動トレーニングワークフローは、データサイエンスチームによって構築されたコードを使用して、 SageMakerでモデルをトレーニングする モデルレジストリに出力モデルを登録します。
別のワークフローがモデルの展開を管理します。モデルレジストリから参照を取得し、を使用して推論エンドポイントを作成します。 SageMakerモデルのホスティング機能.
ステップ関数を使用してモデルトレーニングとデプロイワークフローの両方を実装しました。これは、プロジェクトごとに特定のワークフローを作成し、さまざまなAWSサービスとコンポーネントを簡単に調整できる柔軟なフレームワークを提供したためです。
データ消費モデル
Cepsaでは、一連のデータレイクを使用してさまざまなビジネスニーズに対応しています。これらのデータレイクはすべて、データエンジニアやデータサイエンティストが必要なデータを簡単に見つけて利用できるようにする共通のデータ消費モデルを共有しています。
コストと責任を簡単に処理するために、データレイク環境はデータプロデューサーおよびコンシューマーアプリケーションから完全に分離され、共通のAWS組織に属するさまざまなAWSアカウントにデプロイされます。
MLモデルのトレーニングに使用されるデータと、トレーニングされたモデルの推論入力として使用されるデータは、さまざまなデータレイクから、 アマゾンAPIゲートウェイ、APIを大規模に作成、公開、維持、監視、保護するためのサービス。 APIバックエンドは アマゾンアテナ (標準SQLを使用してデータを分析するための対話型クエリサービス)にすでに保存されているデータにアクセスする Amazon シンプル ストレージ サービス (Amazon S3)およびカタログ化 AWSグルー データカタログ。
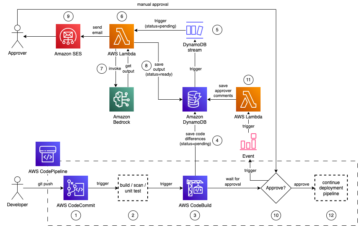
次の図は、CepsaのMLOpsアーキテクチャの概要を示しています。

モデルトレーニング
トレーニングプロセスはモデルごとに独立しており、 ステップ関数の標準ワークフロー、これにより、さまざまなプロジェクト要件に基づいてプロセスをモデル化する柔軟性が得られます。 ほとんどのプロジェクトで再利用する基本テンプレートを定義し、必要に応じて微調整を実行します。 たとえば、一部のプロジェクトオーナーは、新しい本番モデルの展開を承認するために手動ゲートを追加することを決定しましたが、他のプロジェクトオーナーは、独自のエラー検出および再試行メカニズムを実装しました。
また、モデルトレーニングに使用される入力データセットに対して変換を実行します。 この目的のために、トレーニングワークフローに統合されているLambda関数を使用します。 より複雑なデータ変換が必要な一部のシナリオでは、次のコードを実行します。 Amazon エラスティック コンテナ サービス (Amazon ECS)オン AWSファーゲート、コンテナを実行するためのサーバーレスコンピューティングエンジン。
私たちのデータサイエンスチームはカスタムアルゴリズムを頻繁に使用するため、 SageMakerモデルトレーニングでカスタムコンテナを使用する、に頼って Amazon エラスティック コンテナ レジストリ (Amazon ECR)、コンテナイメージの保存、管理、共有、デプロイを簡単にするフルマネージドコンテナレジストリ。
私たちのMLプロジェクトのほとんどは、Scikit-learnライブラリに基づいているため、標準を拡張しました SageMakerScikit-学習コンテナ Gitリポジトリ情報やデプロイオプションなど、プロジェクトに必要な環境変数を含めるため。
このアプローチでは、データサイエンティストは、トレーニングアルゴリズムの開発に集中し、プロジェクトに必要なライブラリを指定するだけで済みます。 彼らがコードの変更をGitリポジトリにプッシュすると、CI / CDシステム(ジェンキンズ AWSでホストされている)は、トレーニングコードとライブラリを使用してコンテナを構築します。 このコンテナはAmazonECRにプッシュされ、最終的にSageMakerトレーニング呼び出しにパラメーターとして渡されます。
トレーニングプロセスが完了すると、結果のモデルがAmazon S3に保存され、参照がモデルレジストリに追加され、収集されたすべての情報とメトリックが実験カタログに保存されます。 これにより、アルゴリズムコードとライブラリが、実験に関連付けられたデータとともにトレーニング済みモデルにリンクされるため、完全な再現性が保証されます。
次の図は、モデルのトレーニングと再トレーニングのプロセスを示しています。

モデルの展開
アーキテクチャは柔軟性があり、トレーニング済みモデルの自動展開と手動展開の両方が可能です。 モデルデプロイヤーワークフローは、トレーニングの終了後にSageMakerトレーニングがEventBridgeで公開するイベントによって自動的に呼び出されますが、必要に応じて手動で呼び出して、モデルレジストリから適切なモデルバージョンを渡すこともできます。 自動呼び出しの詳細については、を参照してください。 AmazonEventBridgeを使用したAmazonSageMakerの自動化.
モデルデプロイヤワークフローは、モデルレジストリからモデル情報を取得し、 AWS CloudFormation、コードサービスとしての管理されたインフラストラクチャ。プロジェクトの要件に応じて、モデルをリアルタイムの推論エンドポイントにデプロイするか、保存された入力データセットを使用してバッチ推論を実行します。
モデルが任意の環境に正常にデプロイされると、モデルレジストリは、モデルが現在実行されている環境を示す新しいタグで更新されます。 エンドポイントが削除されるたびに、そのタグもモデルレジストリから削除されます。
次の図は、モデルの展開と推論のワークフローを示しています。

実験とモデルレジストリ
すべての実験とモデルバージョンをXNUMXつの場所に保存し、一元化されたコードリポジトリを使用することで、モデルのトレーニングとデプロイを切り離し、プロジェクトと環境ごとに異なるAWSアカウントを使用できます。
すべての実験エントリには、トレーニングおよび推論コードのコミットIDが格納されているため、実験プロセス全体を完全に追跡でき、さまざまな実験を簡単に比較できます。 これにより、アルゴリズムとモデルの科学的調査フェーズで重複作業を実行できなくなり、モデルがトレーニングされたアカウントや環境に関係なく、モデルをどこにでも展開できるようになります。 これは、AWSCloud9実験環境でトレーニングされたモデルにも当てはまります。
全体として、完全に自動化されたモデルトレーニングとデプロイのパイプラインがあり、何かが適切に機能していない場合や、実験目的でチームが別の環境にモデルをデプロイする必要がある場合に、高速の手動モデルデプロイメントを実行する柔軟性があります。
詳細なユースケース:YETDragonプロジェクト
YET Dragonプロジェクトは、上海にあるCepsaの石油化学プラントの生産パフォーマンスを向上させることを目的としています。 この目標を達成するために、私たちは生産プロセスを徹底的に研究し、効率の悪いステップを探しました。 私たちの目標は、成分濃度をしきい値より正確に低く保つことにより、プロセスの歩留まり効率を高めることでした。
このプロセスをシミュレートするために、XNUMXつの一般化された加法モデルまたはGAM、応答が予測変数の滑らかな関数に依存する線形モデルを構築し、XNUMXつの酸化プロセス、XNUMXつの濃縮プロセス、および前述の収率の結果を予測しました。 また、XNUMXつのGAMモデルの結果を処理し、プラントに適用できる最適な最適化を見つけるためのオプティマイザーを構築しました。
モデルは履歴データでトレーニングされていますが、トレーニングデータセットに登録されていない状況でもプラントが動作する場合があります。 シミュレーションモデルはこれらのシナリオではうまく機能しないと予想されるため、Isolation Forestsアルゴリズムを使用してXNUMXつの異常検出モデルを構築しました。これにより、データポイントが残りのデータからどれだけ離れているかを判断して異常を検出します。 これらのモデルは、このような状況を検出して、これが発生するたびに自動最適化プロセスを無効にするのに役立ちます。
工業化学プロセスは非常に多様であり、MLモデルはプラントの運用と十分に整合している必要があるため、頻繁な再トレーニングと、各状況で展開されるモデルのトレーサビリティが必要です。 YET Dragonは、モデルレジストリ、実験の完全な再現性、および完全に管理された自動トレーニングプロセスを特徴とする最初のML最適化プロジェクトでした。
現在、モデルを本番環境に導入する完全なパイプライン(データ変換、モデルトレーニング、実験追跡、モデルレジストリ、モデル展開)は、MLモデルごとに独立しています。 これにより、モデルを繰り返し改善し(たとえば、新しい変数を追加したり、新しいアルゴリズムをテストしたり)、トレーニング段階と展開段階をさまざまなトリガーに接続できます。
結果と将来の改善
現在、YET Dragonプロジェクトで使用されている30つのMLモデルを自動的にトレーニング、デプロイ、追跡することができ、各本番モデルにXNUMXを超えるバージョンをすでにデプロイしています。 このMLOpsアーキテクチャは、会社全体の他のプロジェクトで数百のMLモデルに拡張されています。
ブートストラップ時間の短縮とMLパイプラインの自動化により、プロジェクトの平均期間が25%短縮された、このアーキテクチャに基づく新しいYETプロジェクトの立ち上げを継続する予定です。 また、YET Dragonプロジェクトの直接の結果である歩留まりと集中力の向上のおかげで、年間約300,000万ユーロの節約が見込まれています。
このMLOpsアーキテクチャの短期的な進化は、モデルの監視と自動テストに向けられています。 新しいモデルをデプロイする前に、以前にデプロイしたモデルに対してモデルの効率を自動的にテストする予定です。 また、モデルの監視と推論データのドリフト監視の実装にも取り組んでいます。 Amazon SageMakerモデルモニター、モデルの再トレーニングを自動化するため。
まとめ
企業は、MLプロジェクトを自動化された効率的な方法で本番環境に移行するという課題に直面しています。 MLモデルのライフサイクル全体を自動化することで、プロジェクトの時間を短縮し、モデルの品質を向上させ、本番環境へのデプロイをより迅速かつ頻繁に行うことができます。
Cepsaは、全社のさまざまなビジネスで採用されている標準化されたMLOpsアーキテクチャを開発することで、MLプロジェクトのブートストラップを高速化し、MLモデルの品質を向上させ、データサイエンスチームがより迅速に革新できる信頼性の高い自動フレームワークを提供しました。 。
SageMakerのMLOpsの詳細については、次のWebサイトをご覧ください。 MLOps用のAmazonSageMaker で他の顧客のユースケースをチェックしてください AWS機械学習ブログ.
著者について
 ギレルモ・リベイロ・ヒメネス は、博士号を取得したCepsaのSrデータサイエンティストです。 原子核物理学で。 彼は、主に電話会社とエネルギー業界でデータサイエンスプロジェクトに6年の経験があります。 彼は現在、機械学習プロジェクトのスケーリングと製品化に重点を置いて、Cepsaのデジタルトランスフォーメーション部門のデータサイエンティストチームを率いています。
ギレルモ・リベイロ・ヒメネス は、博士号を取得したCepsaのSrデータサイエンティストです。 原子核物理学で。 彼は、主に電話会社とエネルギー業界でデータサイエンスプロジェクトに6年の経験があります。 彼は現在、機械学習プロジェクトのスケーリングと製品化に重点を置いて、Cepsaのデジタルトランスフォーメーション部門のデータサイエンティストチームを率いています。
 ギレルモメネンデスコラル AWS EnergyandUtilitiesのソリューションアーキテクトです。 彼はSWアプリケーションの設計と構築に15年以上の経験があり、現在、分析と機械学習に重点を置いて、エネルギー業界のAWSのお客様にアーキテクチャガイダンスを提供しています。
ギレルモメネンデスコラル AWS EnergyandUtilitiesのソリューションアーキテクトです。 彼はSWアプリケーションの設計と構築に15年以上の経験があり、現在、分析と機械学習に重点を置いて、エネルギー業界のAWSのお客様にアーキテクチャガイダンスを提供しています。
- "
- 000
- 100
- 15年
- a
- 能力
- 私たちについて
- アクセス
- 達成する
- 越えて
- Ad
- 追加されました
- 利点
- に対して
- アルゴリズム
- アルゴリズム
- すべて
- ことができます
- 既に
- Amazon
- 間に
- 分析論
- 分析します
- どこにでも
- API
- API
- 適用された
- アプローチ
- 承認する
- 建築の
- 建築
- 周りに
- 関連する
- 自動化する
- 自動化
- オートマチック
- 自動的に
- 自動化する
- オートメーション
- 利用できます
- AWS
- なぜなら
- になる
- さ
- 以下
- BEST
- ブログ
- ビルド
- 建物
- 構築します
- ビジネス
- ビジネス
- 場合
- 例
- 集中型の
- 一定
- 挑戦する
- 課題
- 化学物質
- クラウド
- コード
- コミット
- コマンドと
- 会社
- コンプリート
- 完全に
- 複雑な
- コンポーネント
- コンポーネント
- 計算
- 濃度
- お問合せ
- 消費する
- consumer
- 消費
- コンテナ
- コンテナ
- コスト
- 可能性
- カバー
- 作ります
- 作成します。
- 創造
- 現在
- カスタム
- 顧客
- Customers
- データ
- データサイエンス
- データサイエンティスト
- 決定しました
- 決定
- によっては
- 依存
- 展開します
- 展開
- 展開
- 配備
- 設計
- 設計
- 詳細な
- 検出された
- 検出
- 決定する
- 開発者
- 開発
- 異なります
- デジタル
- 直接
- 話し合います
- Dragon
- 各
- 簡単に
- 効率
- 効率的な
- 新興の
- 可能
- エンドポイント
- エネルギー
- エンジン
- エンジニア
- 環境
- 装置
- 推定
- イベント
- 進化
- 正確に
- 例
- 期待する
- 体験
- 実験
- 探査
- 向い
- スピーディー
- 速いです
- 特徴
- 特集
- 最後に
- 名
- 柔軟性
- フレキシブル
- フォーカス
- フォロー中
- フレームワーク
- から
- フル
- 機能
- 未来
- ゲイツ
- Gitの
- GitHubの
- グローバル
- 目標
- ハンドル
- 持って
- 助けます
- ことができます
- 非常に
- 歴史的
- 保持している
- 主催
- ホスティング
- 認定条件
- HTTPS
- 何百
- 画像
- 実装
- 実装
- 改善します
- 改善
- 改善
- その他の
- include
- 増える
- 独立しました
- 単独で
- インダストリアル
- 産業を変えます
- 情報
- 情報に基づく
- インフラ
- 革新的手法
- 統合された
- 相互作用的
- 導入
- 分離
- 問題
- IT
- キープ
- 保管
- キー
- 発射
- 主要な
- 学習
- 図書館
- ライン
- 場所
- 探して
- 機械
- 機械学習
- 製
- 維持する
- メンテナンス
- make
- 作る
- 管理します
- マネージド
- 管理する
- 方法
- マニュアル
- 手動で
- 手段
- メトリック
- ML
- モデル
- モニター
- モニタリング
- 他には?
- 最も
- の試合に
- ニーズ
- 操作する
- 操作
- 最適化
- オプション
- 注文
- 組織
- その他
- 自分の
- 所有者
- 通過
- パフォーマンス
- 実行
- 相
- 物理学
- ポイント
- 予測する
- 問題
- プロセス
- ラボレーション
- プロデューサー
- 生産
- プロジェクト
- プロジェクト(実績作品)
- 提供
- は、大阪で
- 提供
- パブリッシュ
- 目的
- 目的
- プッシュ
- 品質
- への
- 減らします
- 登録
- 登録された
- 信頼性のある
- 倉庫
- の提出が必要です
- 要件
- 応答
- 責任
- REST
- 結果として
- 結果
- ラン
- ランニング
- 規模
- スケーリング
- 科学
- 科学者
- 科学者たち
- 安全に
- シリーズ
- サーバレス
- サービス
- サービス
- セッションに
- 上海
- シェアする
- 短期
- 簡単な拡張で
- 状況
- SIX
- So
- 溶液
- ソリューション
- 一部
- 何か
- 特定の
- スピード
- ステージ
- 標準
- 開始
- ストレージ利用料
- 店舗
- 流線
- 首尾よく
- ターゲット
- チーム
- チーム
- 電話会社
- test
- テスト
- ソース
- したがって、
- 徹底的に
- しきい値
- 介して
- 時間
- <font style="vertical-align: inherit;">回数</font>
- に向かって
- トレーサビリティ
- 追跡する
- 追跡
- トレーニング
- 変換
- 変換
- 遷移
- 下
- us
- つかいます
- 通常
- 公益事業
- 値
- バージョン
- 明確な
- while
- 無し
- 仕事
- ワークフロー
- ワーキング
- 世界
- 書き込み
- 年
- 年
- 産出