この記事では、PDF を Google スプレッドシートに変換するさまざまな方法について説明します。
また、ナノネットがどのようにできるかについても学びます。 PDF を Google スプレッドシートに変換するワークフロー全体を自動化する オンライン。
PDF を Google スプレッドシートに変換する方法を説明する前に、これが重要な理由を見てみましょう。
PDF を Google スプレッドシートに変換する理由
これによれば Googleブログ Googleの公式ブログページからの投稿では、5万を超える企業がGSuiteソリューションを使用しています。 同時に、多くの企業がGoogleSheets統合を使用してタスクを自動化することも開始しています。
典型的なユースケースを考えてみましょう。 買掛金チームは、標準のPDF形式で請求書を受け取ります。 誰かが手動で請求書を調べ、必要な情報をGoogleスプレッドシートのドキュメントに入力してから、財務セクションに転送します。 財務セクションは、サプライヤに支払いを行い、会社の元帳にエントリを作成します。
長く引き出されたプロセスであることは別として、これはエラーが発生しやすく、単純に自動化する方がはるかに理にかなっています。
PDFをGoogleシート形式に変換する必要性が明確になったので、PDFドキュメントがどのように構造化されているか、およびそれらを解析する際の課題を見てみましょう。
変換したい PDF ファイルへ Googleスプレッドシート ? チェックアウト ナノネット 無料です。 PDFからCSVへのコンバーター. または方法を調べる Nanonets を使用して、PDF から Google スプレッドシートへのワークフロー全体を自動化します.
PDFドキュメントの解析に関する課題
ポータブルドキュメント形式は、最初はAdobeによって開発され、後にオープンスタンダードとしてリリースされたファイル形式でした。 基盤となるオペレーティングシステムに依存しないため、広く採用されています。
では、PDFを解析してその内容を別の形式に変換するのがなぜそれほど難しいのでしょうか。 次の画像は千の言葉を話し、ポイントを家に追いやるでしょう。
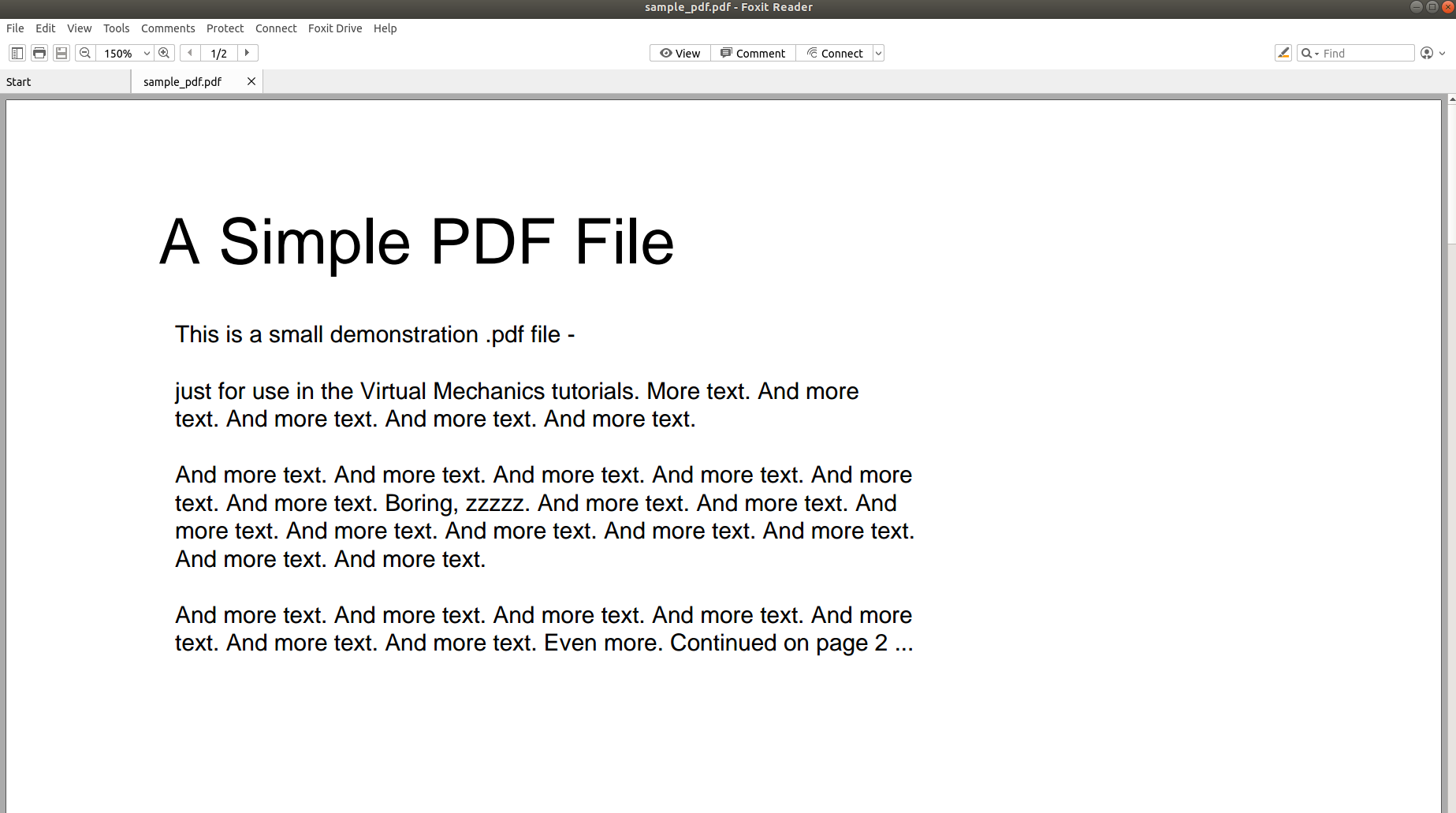
上の画像は、PDFリーダーを使用して開いたPDFドキュメントのスクリーンショットを示しています。 テキストエディタを使用して同じPDFドキュメントを開いてみましょう。
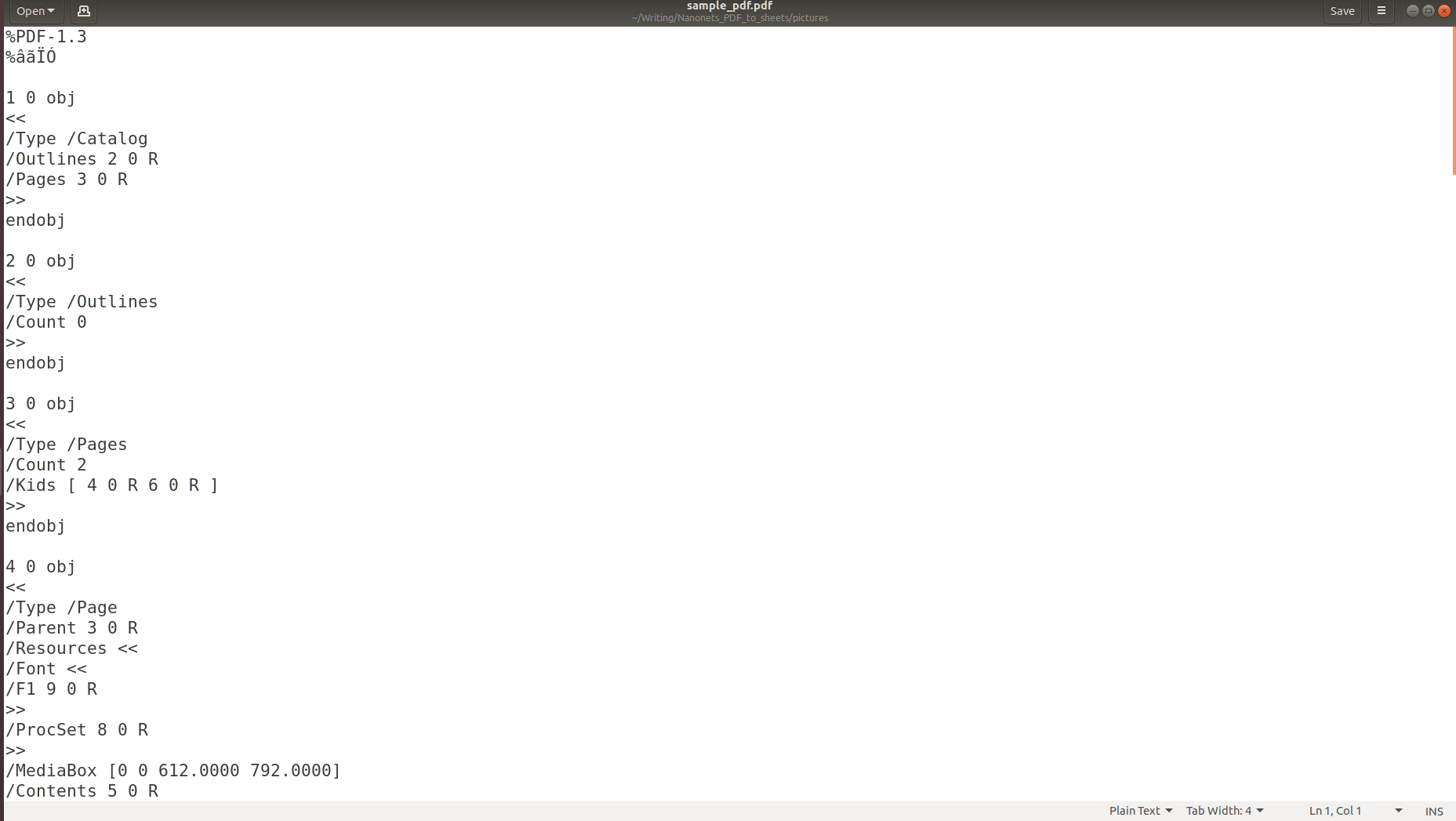
上の写真は、情報をPDFに保存すると、元の構造が完全に失われることを示しています。 これは、PDF形式が、ページ上に一連の文字を印刷/描画する方法の説明だけで構成されているためです。
テキストの抽出が難しいと思われる場合は、使用される表形式が大きく異なるため、テーブルに存在するデータの抽出はさらに困難です。
PDFドキュメントをGoogleスプレッドシートのフォームに変換することは、公園を散歩することではないと確信していることを願っています。 次のセクションでは、PDFドキュメントから情報を認識/解析するために最新のPDFパーサーが採用しているアプローチについて説明します。
PDFドキュメントを解析するための最新のアプローチ
最新のPDFパーサーのほとんどは、以下で説明するフローを利用して、PDFドキュメントから非構造化データを解析します。
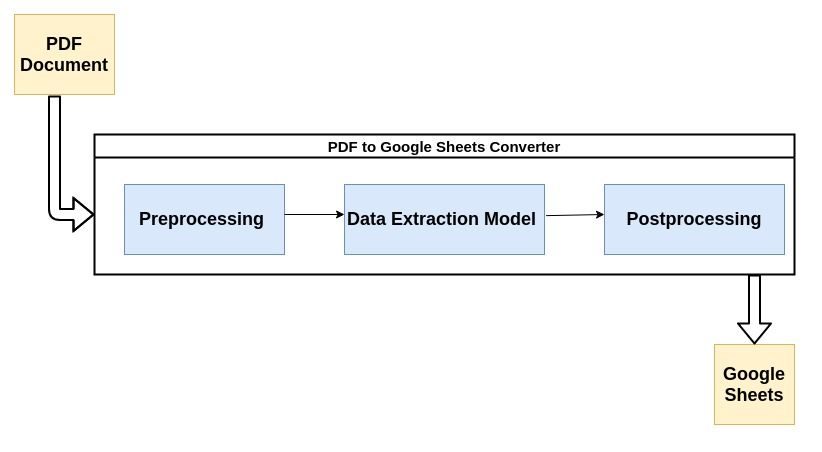
プロセスの各ステップを簡単に見てみましょう。
1.前処理またはデータクリーニング:
PDFの見栄えが良いほど、機械学習モデルの抽出や抽出が容易になります。 データをキャプチャする それから。 たとえば、PDFドキュメントがスキャンされた場合、コンバーターのパフォーマンスに影響を与える可能性のあるスキャンアーティファクトが含まれている可能性があります。
適切なフィルターを使用したノイズ除去、XNUMX値化、スキュー補正などは、最も一般的な前処理ステップの一部です。 次のNanonetsの投稿 Nanonets Tesseract ポスト 以前にドキュメントを前処理する方法のいくつかの優れた例が含まれています 光学式文字認識(OCR)はそれらで実行されます。
ここでほとんどの魔法が起こります。 データ抽出は通常、機械学習(ML)モデルによって実行されます。 PDFからのデータ抽出に使用されるほとんどのMLモデルには、光学式文字認識ツール、テキストおよびパターン認識ツールなどの組み合わせが含まれています。
この投稿の目的上、モデルをブラックボックスとして扱うことができます。このブラックボックスは、PDFドキュメントを入力として受け取り、解析された情報を吐き出します。 また、MLをコアとして採用しているため、会社のユースケースに合わせてカスタムデータで再トレーニングできます。
3.後処理:
このステップでは、抽出されたデータがCSV、XML、JSONなどの必要な形式に変換されます。 また、AIによる予測に加えて、ユーザー定義のルールが追加されます。 これには、出力のフォーマットに関するルール、抽出される情報に対する追加の制約などが含まれる可能性があります。
次のセクションでは、PDFパーサーのパフォーマンスを測定するために使用できるいくつかのメトリックについて説明します。
変換したい PDF ファイルへ Googleスプレッドシート ? チェックアウト ナノネット 無料です。 PDFからCSVへのコンバーター. Nanonetsを使用してPDFからGoogleスプレッドシートへのワークフロー全体を自動化する方法をご覧ください。

PDFコンバーターのパフォーマンスを測定するためのメトリック
ほとんどのPDFコンバーターは請求書処理または関連タスクに使用されるため、PDFドキュメントからのテーブル抽出の精度と速度は、PDFコンバーターのパフォーマンスを判断する上で重要な要素です。
2.多言語機能:
ほとんどの大企業は、さまざまな言語で請求書を受け取る必要があります。 PDFパーサーは、すぐに使用できる多言語解析をサポートするか、ユーザーがカスタムデータを使用してモデルをトレーニングできるオプションを提供する必要があります。
3.会計ソフトウェアとの統合:
理想的なPDFコンバーターは、既存のモジュールに簡単に追加できるプラグアンドプレイモジュールである必要があります ドキュメントワークフロー。 QuickBooks、Xero、Waveなどの一般的な会計ソフトウェアとの統合をサポートする必要があります。
4.簡単で直感的:
このツールは、技術者以外のユーザーが操作する可能性があります。 最小限の技術的知識で操作できれば有利です。
PDF を Google スプレッドシートに変換するさまざまな方法
1.Google ドキュメントを使用して PDF を Google スプレッドシートに変換する
Google ドライブには、単純な PDF ドキュメント内の表とテキストを認識する機能が組み込まれています。 次のことを行う必要があります。
-
PDF ファイルを Google ドライブにアップロードする
-
「Googleドキュメントで開く」をクリック
-
必要なデータをコピーして Google スプレッドシートに貼り付けます
これでもうまくいくように思えますが、もう少し実用的な方法を試してみましょう。 この単純な請求書について考えてみましょう。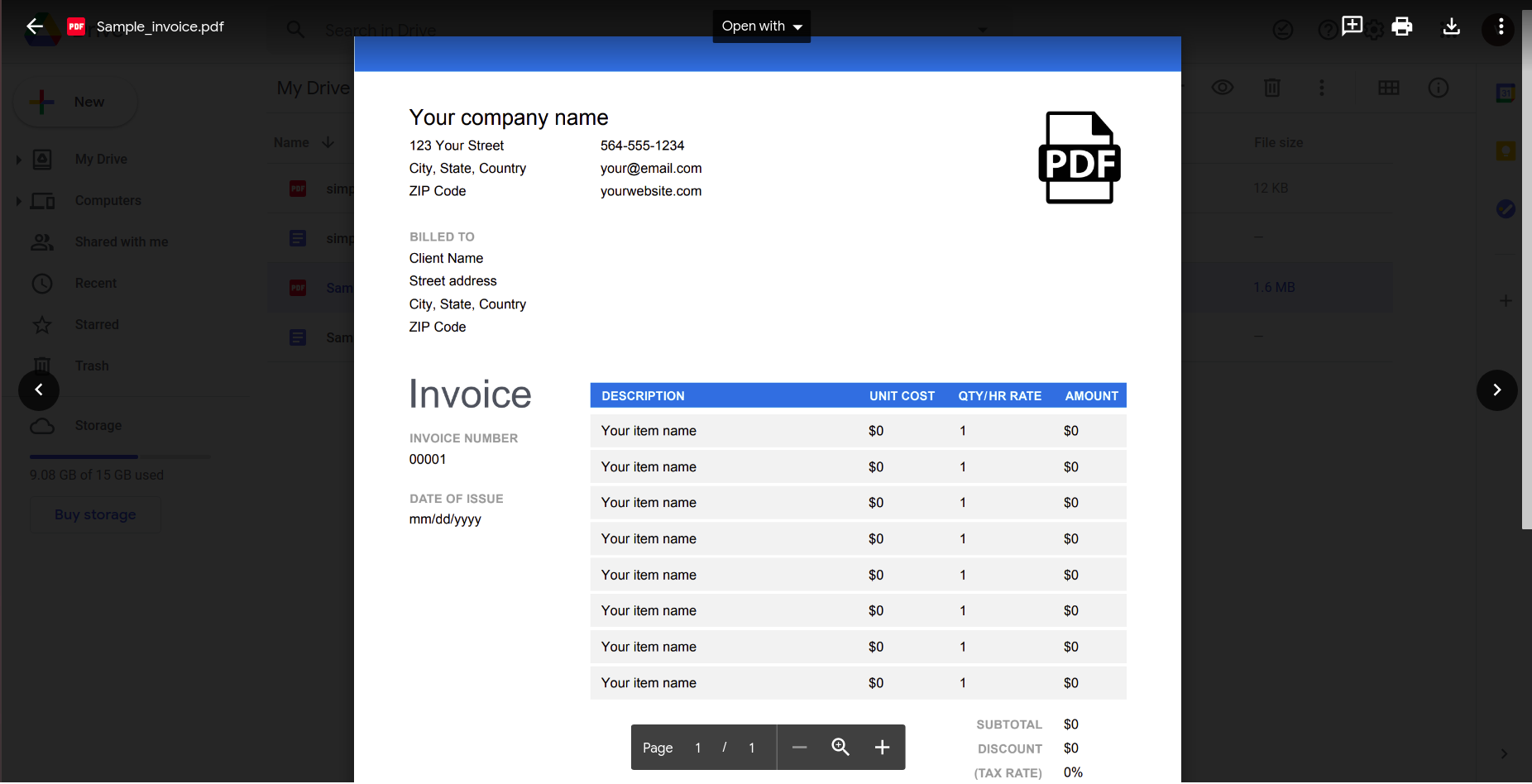
Googleドキュメントアプリケーションを使用してこれを開くと、次の結果が得られます。
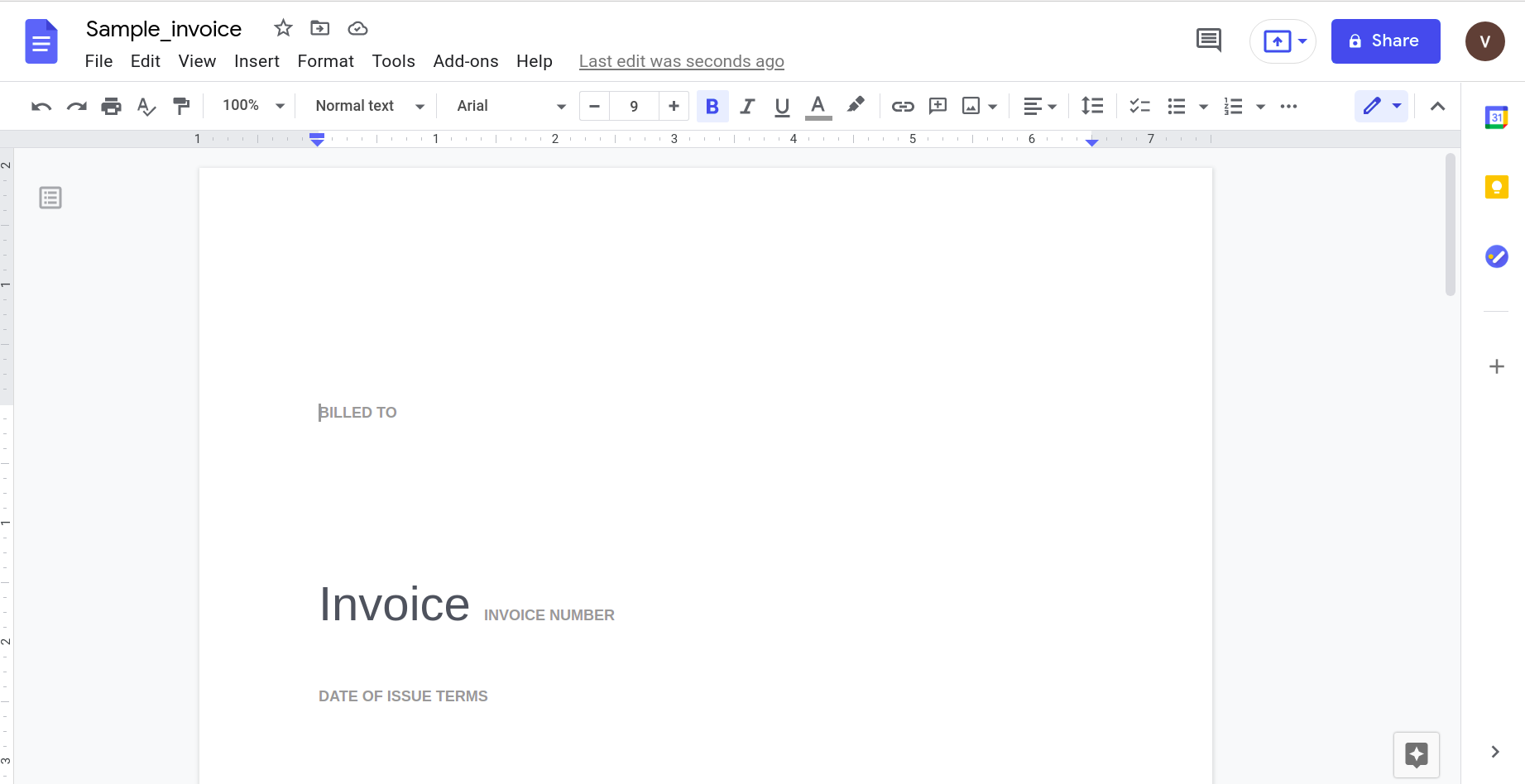
明らかに、ドキュメントの複雑さが増すにつれて、データを認識するためにより洗練されたツールに頼る必要があります。
2.オンラインツールの使用:
PDF テーブル エクストラクタ、Online2PDF などのいくつかのオンライン ツールは、Google ドライブと直接統合され、PDF ドキュメントを Google スプレッドシートに変換するすぐに使える機能を提供します。
ただし、上記のサンプル請求書 PDF を使用してこれらのツールをテストしたところ、ほとんどの場合、テーブルは検出されませんでした。
変換したい PDF ファイルへ Googleスプレッドシート ? チェックアウト ナノネット 無料です。 PDFからCSVへのコンバーター. 以下に示すように、Nanonetを使用してPDFからGoogleスプレッドシートへのワークフロー全体を自動化する方法をご覧ください。
PDF から Google スプレッドシートへの変換プロセスの自動化
次のツールを使用して、PDFを解析し、データをGoogleスプレッドシートフォームに抽出するプロセスを完全に自動化できます。
1. Webhookの使用:
Webhookはカスタム定義のHTTPリクエストです。 これらは通常、イベントでトリガーされます。つまり、イベントが発生すると、アプリケーションは事前定義されたURLに情報を送信します。
これをワークフローの自動化にどのように使用できますか? 請求書処理の典型的な使用例を考えてみましょう。 サプライヤーから多数の請求書を受け取り、クラウド上にあるPDFからGoogleスプレッドシートへのコンバーターにフィードします。 モデルがドキュメントの処理を終了したことをどのようにして知ることができますか?
変換が完了したかどうかを手動で確認する代わりに、PDF内のデータがGoogleスプレッドシートドキュメントに抽出されたときに通知するWebhookを使用するだけで済みます。
2.APIの使用
APIはApplicationProgrammingInterfaceの略です。 適切なAPI呼び出しを使用すると、PDFドキュメントをGoogleスプレッドシートに変換するのは、次のコード行を書くのと同じくらい簡単であることがわかる場合があります。
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
会社がすでにWebhookとの統合をセットアップしている場合は、PDFドキュメントが正常に変換されたときに通知を受け取ります。 次に、以下に示すAPIを使用してGoogleスプレッドシートフォームをダウンロードできます。
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
ナノネットを使用したPDFからGoogleスプレッドシート
Nanonets PDFパーサーは、解析と変換を簡単かつ正確にします。 PDFパーサーは、サンプルの請求書を解析するために使用されました。 このセクションでは、ツールの使いやすさと精度について説明します。 以下の画像は、それがどれほど素晴らしいかについて話すのではなく、その要点を適切に示しています。
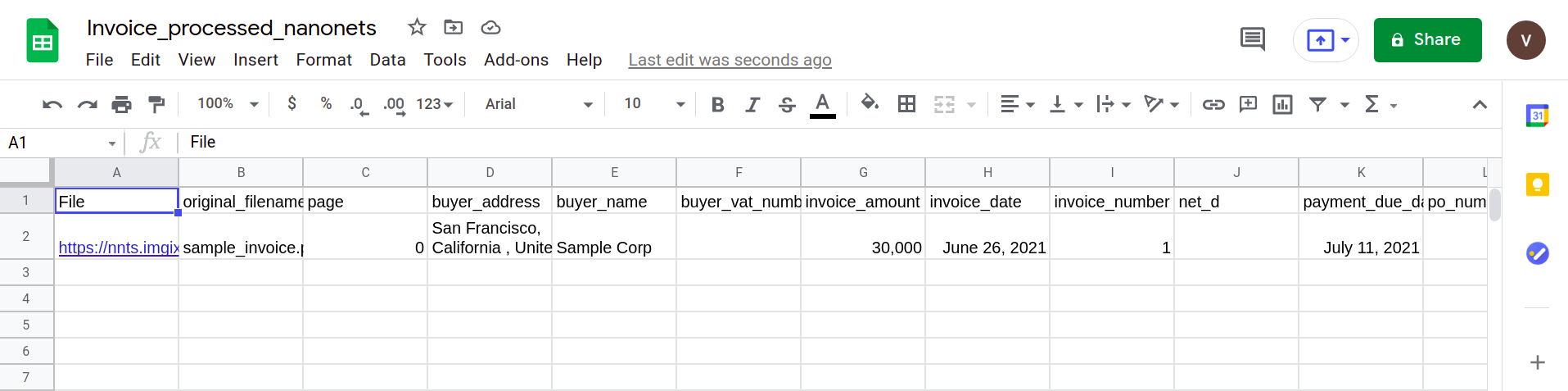
以下に示す画像は、NanonetsPDFパーサーに送信されたサンプル請求書のスクリーンショットです。
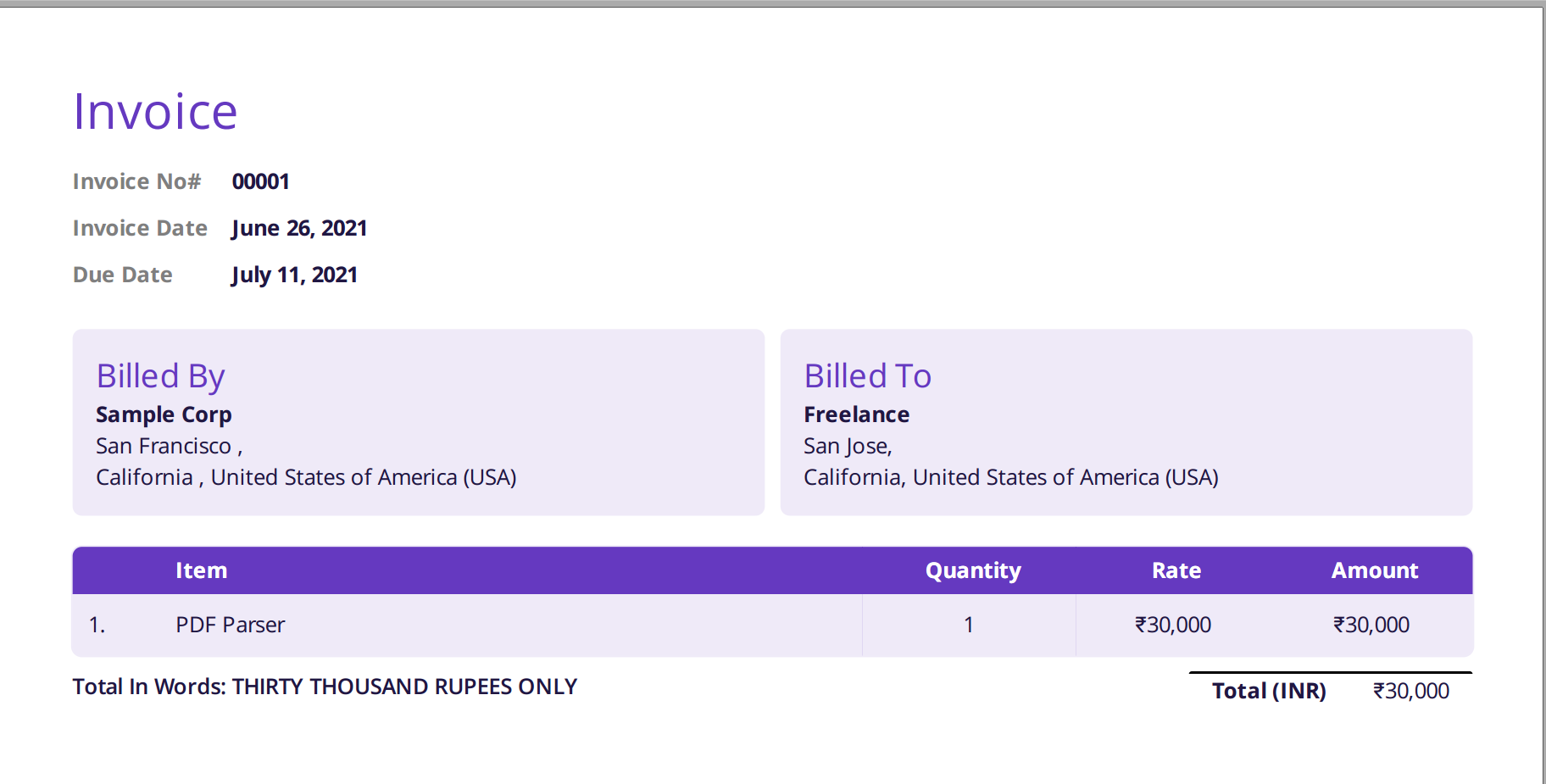
Nanonets Webサイトに移動して、請求書をアップロードするだけです。 変換には数秒しかかかりません。その後、解析されたデータを次のようなさまざまな形式でダウンロードできます。 CSV、XLSXなど(Nanonetsをチェックしてください PDFからCSVへのコンバーター)
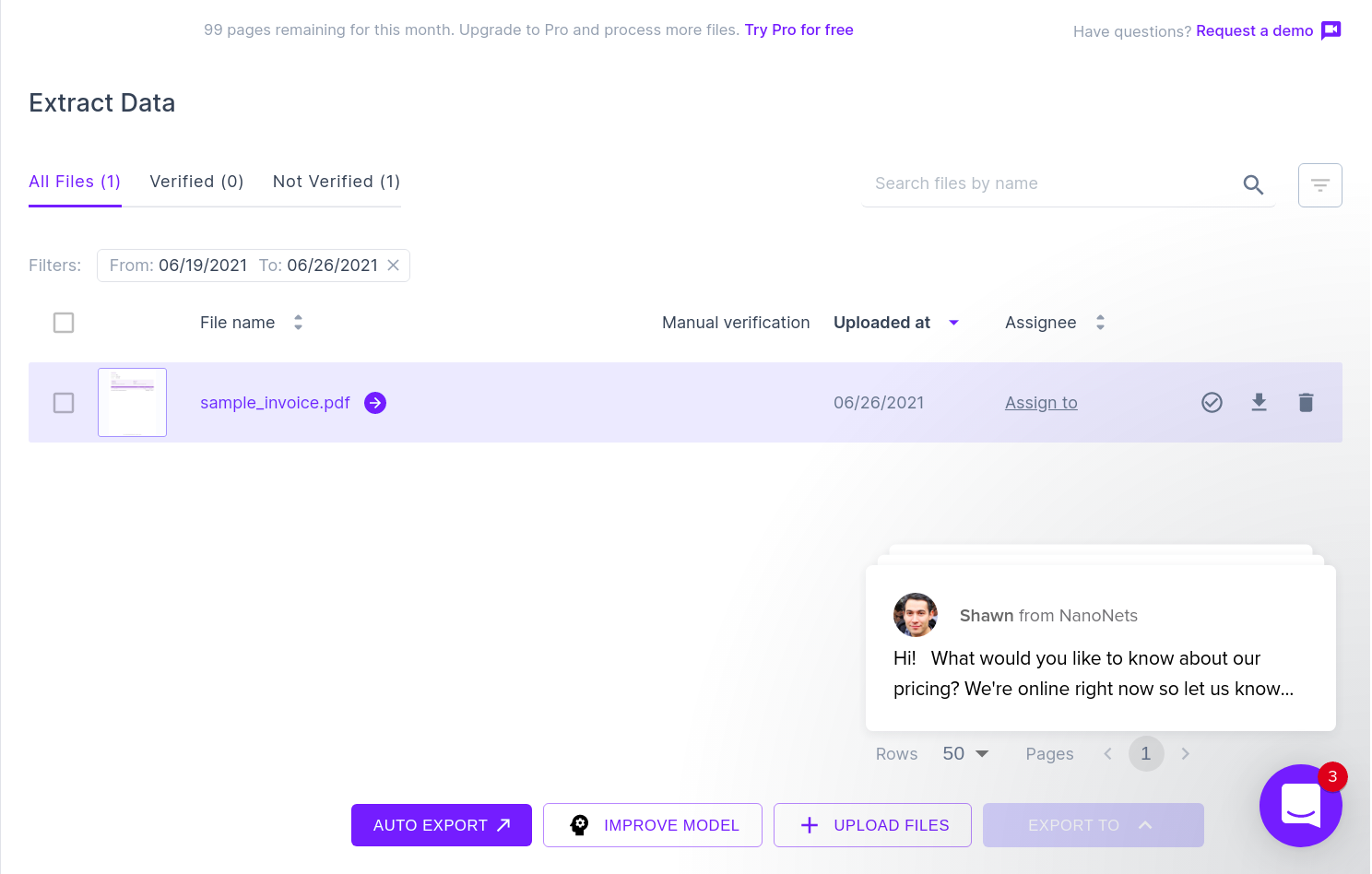
次の画像は、PDFドキュメントから解析されたデータを含むCSVファイルのスクリーンショットを示しています。

最後に、CSVファイルをGoogleスプレッドシートのフォームに変換するには、XLSX / CSVファイルをGoogleドライブにアップロードするだけです。 このステップは、GoogleドライブAPIを利用することで自動化できます。
次のセクションでは、NanonetsPDFパーサーを使用して単純なパイプラインを作成する方法を示します。
PDFドキュメントから情報を抽出し、それらをGoogleスプレッドシートドキュメントに変換/追加したいですか? Nanonetsをチェックしてください™ PDFドキュメントからGoogleスプレッドシートへの情報のエクスポートを自動化するために!
シンプルなパイプラインの作成
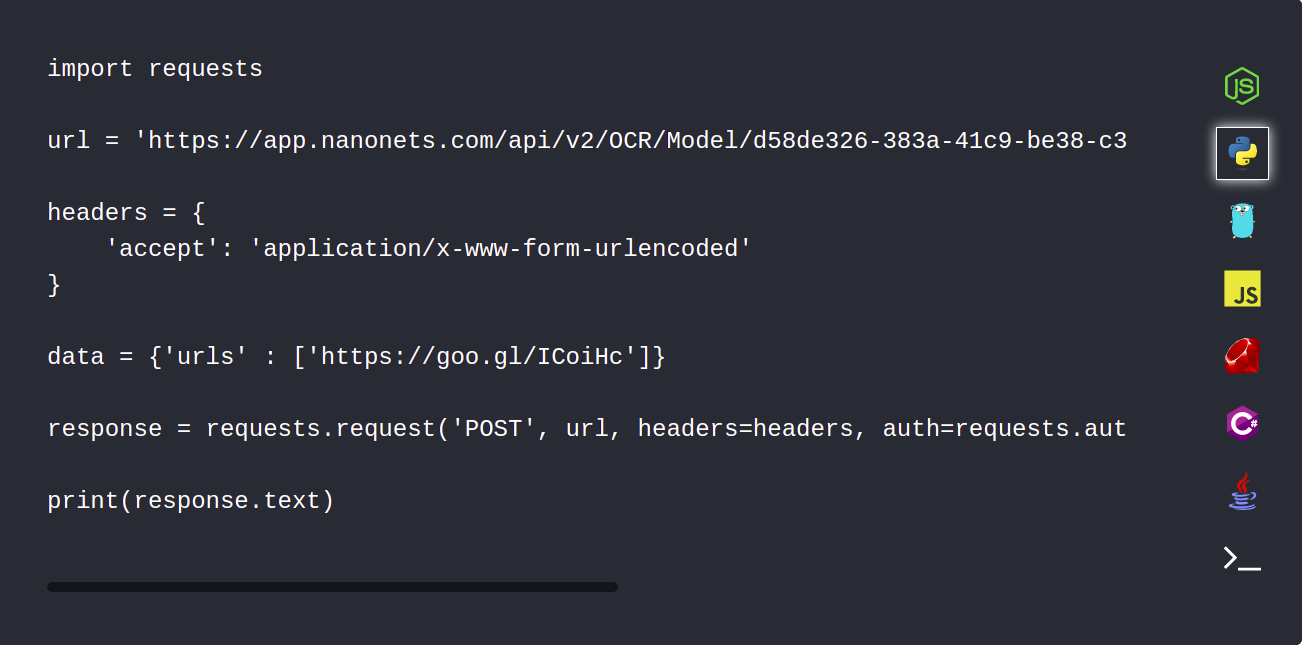
1. NanonetsAPIを使用してPDFドキュメントを自動的にアップロードします
Nanonets APIを使用すると、解析する必要のあるドキュメントを自動的にアップロードできます。 次のコードスニペットは、Pythonを使用してこれを行う方法を示しています。
2. Webhook統合を使用して、解析の完了時に通知を受信します
ドキュメントが解析されると自動的に通知するようにWebhookを構成できます。
3.確認してGoogleスプレッドシートにアップロードします
CSVファイルをダウンロードして確認し、すべてが正常であることを確認し、GoogleドライブAPIを使用してデータをGoogleスプレッドシートにアップロードします。
ナノネットエッジ
Nanonets PDFパーサーのいくつかの機能は、ビジネスに理想的なツールです。
1.外部統合:
nanonetsモデルは、MySql、Quickbooks、Salesforceなどと簡単に統合できます。これは、現在のワークフローが妨げられることなく、nanonetsコンバーターを追加モジュールとしてプラグインするだけで済むことを意味します。
2.高精度と低処理時間:
Nanonets PDFパーサーツールの精度は95%以上で、競合他社と比較するとはるかに高くなっています。
3.クールな後処理機能:
データベースがナノネットモデルと統合されていると仮定します。 モデルは、ドキュメントから抽出されたデータに基づいて、いくつかのフィールド(データベースからのデータを含む)に自動的に入力します。 例えば:
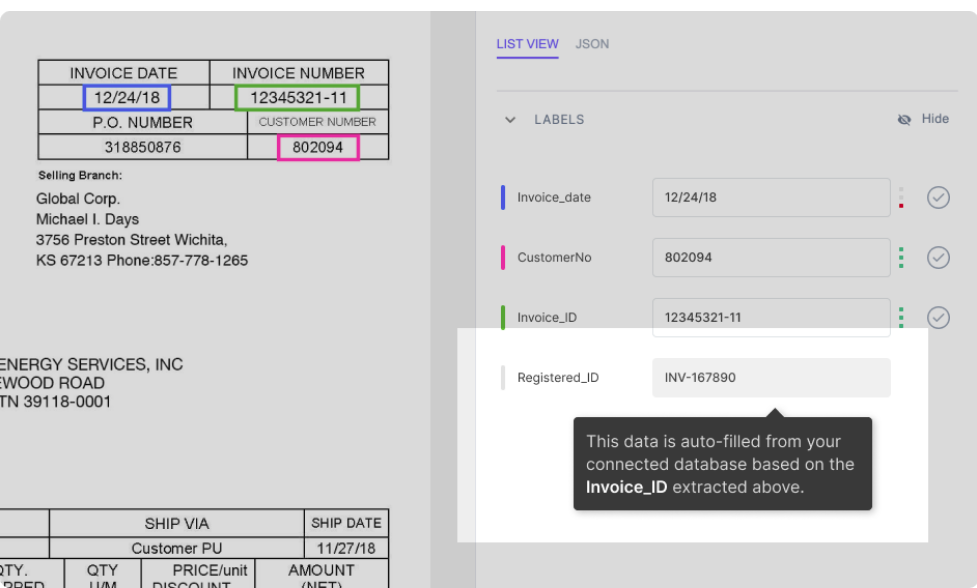
図に示すように、Registered_IDフィールドは、PDFから抽出されたInvoice_IDに基づいて(データベースルックアップによって)自動的に入力されます。
4.シンプルで直感的なインターフェース
この機能は過小評価されていますが、UIとUXが適切であることがわかりました。 サインアップ、ドキュメントのアップロード、データの解析の全プロセスは5分未満で完了しました。 これは、私のラップトップが起動するのにかかる時間とほぼ同じです。
5.巨大な顧客基盤
ワークフローを自動化するためにNanonetを使用することについてまだ予約がある場合は、そのサービスを使用している会社のいくつかを見てください。
- デロイト
- シャーウィンウィリアムズ
- ドアダッシュ
- P&G
PDFドキュメントから情報を抽出し、それらをGoogleスプレッドシートドキュメントに変換/追加したいですか? Nanonetsをチェックしてください™ PDFドキュメントからGoogleスプレッドシートへの情報のエクスポートを自動化するために!
まとめ
この投稿では、PDFからGoogleスプレッドシートへのコンバーターを使用してワークフローを自動化する方法について説明しました。 最初に、PDFドキュメントをGoogleスプレッドシートに変換する必要性について学び、その後、このプロセスで直面する課題について学びました。 次に、PDFドキュメントを解析するために最新のパーサーが採用しているアプローチに飛び込み、いくつかの一般的なアプローチも実装しました。 また、WebhookやAPIなどの外部統合を使用して変換を完全に自動化する方法も学びました。 最後に、Nanonetsツールを使用してサンプルの請求書を解析し、データをGoogleスプレッドシートのフォームに抽出し、その優れた後処理機能のいくつかを調査しました。
Nanonetsモデルを試してみましたか? もしそうなら、ツールの使用経験に関して以下にコメントを残してください。 そうでない場合は、先に進んで試してみてください。 それはあなたの一日を作るかもしれません!