概要
今日のデータ主導の世界では、研究論文から洞察を抽出しようとしている学生であっても、データセットから答えを求めているデータ アナリストであっても、さまざまなファイル形式で保存された情報が氾濫しています。 PDF の研究論文から DOCX およびプレーン テキスト ドキュメント (TXT) のレポート、CSV ファイルの構造化データに至るまで、これらの多様なソースに効率的にアクセスして情報を抽出するニーズはますます高まっています。 そこで、 複数ファイルのチャットボット これは、PDF、DOCX ファイル、TXT ドキュメント、CSV データセットに保存されている情報にアクセスし、複数のファイルを同時に処理できるように設計された多機能ツールです。
マルチファイル チャットボットを実現するコードと機能の複雑さを理解しながら、エキサイティングな旅の準備をしましょう。 Generative AI の力をすぐに利用して、データの可能性を最大限に引き出す準備をしましょう。
学習目標
詳細に入る前に、この記事の主な学習目標の概要を説明しましょう。
- さまざまなファイル形式 (PDF、DOCX、TXT) からのテキスト抽出を実装し、自然言語の理解、応答の生成、効率的な質問応答のための言語モデルを統合します。
- 効率的な情報処理のために、抽出されたテキスト チャンクからベクトル ストアを作成します。
- CSV アップロードを含む複数ファイルのサポートを有効にして、XNUMX つのセッションでさまざまな種類のドキュメントを操作できるようにします。
- チャットボットと簡単に対話できるように、ユーザーフレンドリーな Streamlit インターフェイスを開発します。
この記事は、の一部として公開されました データサイエンスブログ。
目次
マルチファイルチャットボットの必要性は何ですか?
今日のデジタル時代では、さまざまなファイル形式で保存される情報の量が飛躍的に増加しました。 これらの多様なソースに効率的にアクセスし、貴重な洞察を抽出する能力がますます重要になっています。 このニーズにより、情報検索の課題に対処するために設計された特殊なツールであるマルチファイル チャットボットが誕生しました。 高度な生成 AI を活用したファイル チャットボットは、情報検索の未来です。
1.1 ファイルチャットボットとは何ですか?
ファイル チャットボットは、次の機能を備えた革新的なソフトウェア アプリケーションです。 Artificial Intelligence (AI)と 自然言語処理 (NLP) テクノロジー。 PDF、DOCX ドキュメント、プレーン テキスト ファイル (TXT)、CSV ファイルの構造化データなど、さまざまなファイル形式から情報を分析および抽出するように設計されています。 主にテキストでの会話を通じてユーザーと対話する従来のチャットボットとは異なり、ファイル チャットボットは、これらのファイル内に保存されているコンテンツに基づいて質問を理解し、回答することに重点を置いています。
1.2ユースケース
マルチファイル チャットボットの有用性は、さまざまなドメインや業界に広がります。 その重要性を強調するいくつかの主要な使用例を次に示します。
1.2.1 学術研究と教育
– 研究論文の分析: 学生や研究者は、ファイル チャットボットを使用して、PDF 形式で保存されている広範な研究論文から重要な情報や洞察を抽出できます。 概要を提供したり、特定の質問に答えたり、文献レビューのプロセスを支援したりできます。
–教科書のサポート: 教育機関はファイル チャットボットを導入して、教科書の内容に関連する質問に答えて学生を支援し、学習体験を向上させることができます。
1.2.2 データ分析とビジネス インテリジェンス
- データ探索: データ アナリストやビジネス プロフェッショナルは、ファイル チャットボットを利用して、CSV ファイルに保存されているデータセットを操作できます。 データ内の傾向、相関関係、パターンに関するクエリに答えることができるため、データに基づいた意思決定のための貴重なツールになります。
- レポートの抽出: チャットボットは、DOCX 形式のビジネス レポートから情報を抽出できるため、専門家が主要な指標や洞察に迅速にアクセスできるようになります。
1.2.3 法的およびコンプライアンス
- 法的文書のレビュー: 法務分野では、ファイル チャットボットは、契約書や事件準備書などの長い法的文書から重要な詳細を要約して抽出することで弁護士を支援できます。
- 企業コンプライアンス: 企業はチャットボットを使用して複雑な規制文書をナビゲートし、進化する法律や規制に準拠し続けることができます。
1.2.4 コンテンツ管理
- アーカイブと取得: 組織はファイル チャットボットを使用してドキュメントを効率的にアーカイブおよび取得できるため、履歴記録や情報へのアクセスが容易になります。
1.2.5 ヘルスケアおよび医療研究
- 医療記録の分析: ヘルスケア分野では、チャットボットは医療専門家が患者記録から貴重な情報を抽出し、診断や治療の決定を支援するのに役立ちます。
- 研究データの処理: 研究者はチャットボットを活用して医学研究論文を分析し、研究に関連する知見を抽出できます。
1.2.6 カスタマーサポートとよくある質問
- 自動サポート: 企業はファイル チャットボットを自社のカスタマー サポート システムに統合して、クエリを処理し、FAQ、マニュアル、ガイドなどのドキュメントから情報を提供できます。
ファイルチャットボットのワークフロー
マルチファイル チャットボットのワークフローには、ユーザー対話からファイル処理、質問への回答まで、いくつかの重要なステップが含まれます。 ワークフローの包括的な概要は次のとおりです
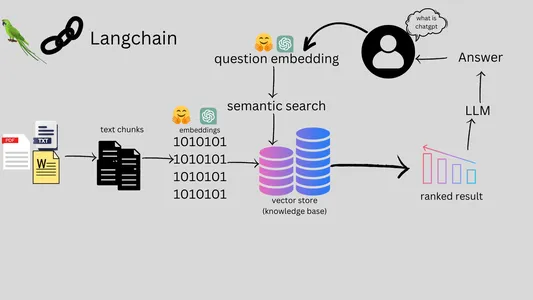
- ユーザーは、Web またはチャット プラットフォームを介してマルチファイル チャットボットと対話します。
- ユーザーはチャットボットの情報検索のためのクエリを送信します。
- ユーザーは特定のファイル (PDF、DOCX、TXT、CSV) をアップロードできます。
- チャットボットは、クリーニングやセグメンテーションなど、アップロードされたファイルのテキストを処理します。
- チャットボットは、処理されたテキストを効率的にインデックス付けして保存します。
- チャットボットはクエリの理解に NLP を使用します。
- チャットボットは関連情報を取得し、回答を生成します。
- チャットボットは自然言語で応答します。
- ユーザーは応答を受け取り、対話を続行できます。
- 会話はさらに質問を続けていきます。
- 会話はユーザーの判断で終了します。
開発環境のセットアップ
Python 環境のセットアップ:
仮想環境は、プロジェクト固有の依存関係を分離し、システム全体のパッケージとの競合を回避するための良い方法です。 Python 環境をセットアップする方法は次のとおりです。
仮想環境を作成します。
- ターミナルまたはコマンド プロンプトを開きます。
- プロジェクト ディレクトリに移動します。
- 仮想環境を作成します (env_name を希望の環境名に置き換えます)。
python -m venv env_name
仮想環境をアクティブ化します。
- 窓の場合
.env_nameScriptsactivate
- macOSおよびLinuxの場合:
source env_name/bin/activateプロジェクトの依存関係をインストールします。
- 仮想環境がアクティブなときに、プロジェクト ディレクトリに移動し、pip を使用して必要なライブラリをインストールします。 これにより、ライブラリはグローバル Python 環境から隔離された仮想環境内に確実にインストールされます。
必要な依存関係
- ラングチェーン: さまざまな NLP タスク用のカスタム ライブラリ。
- PyPDF2: PDF ファイルを操作するためのライブラリ。PDF ドキュメントからのテキスト抽出に使用されます。
- Python-docx: DOCX ファイルを操作するためのライブラリ。DOCX ドキュメントからテキストを抽出するために使用されます。
- Python-dotenv: 機密情報を安全に保つために重要な環境変数を管理するためのライブラリ。
- ストリームライト: 最小限のコードで Web アプリケーションを作成するための Python ライブラリ。 チャットボットのユーザー インターフェイスを構築するために使用されます。
- オープンナイ: OpenAI Python ライブラリ。コードに応じて特定の NLP タスクに使用される場合があります。
- フェイスCPU: Faiss は、コード内のベクトルのインデックス付けに使用される、密なベクトルの効率的な類似性検索とクラスタリングのためのライブラリです。
- アルタイル: Python の宣言型統計視覚化ライブラリ。プロジェクトのデータ視覚化に使用される可能性があります。
- ティックトークン: テキスト文字列内のトークンの数をカウントするための Python ライブラリ。テキスト データの管理に役立ちます。
- ハグフェイスハブ: Hugging Face のモデル ハブからモデルとリソースにアクセスするためのライブラリ。事前トレーニングされたモデルにアクセスするために使用されます。
- 講師埋め込み: 特定の NLP タスクに使用されるカスタム埋め込みライブラリまたはモジュールの可能性があります。
- センテンストランスフォーマー: 文埋め込み用のライブラリ。文レベルの表現を含むさまざまな NLP タスクに役立ちます。
注: 言語関連のタスクには、Hugging Face または OpenAI のいずれかを選択してください。
複数ファイルのチャットボットのコーディング
4.1 依存関係のインポート
import streamlit as st
from docx import Document
from PyPDF2 import PdfReader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, HuggingFaceInstructEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from htmlTemplates import css, bot_template, user_template
from langchain.llms import HuggingFaceHub
import os
from dotenv import load_dotenv
import tempfile
from transformers import pipeline
import pandas as pd
import io以下のファイルを処理しています:
# Extract text from a PDF file def get_pdf_text(pdf_file): text = "" pdf_reader = PdfReader(pdf_file) for page in pdf_reader.pages: text += page.extract_text() return textDocx
# Extract text from a DOCX file def get_word_text(docx_file): document = Document(docx_file) text = "n".join([paragraph.text for paragraph in document.paragraphs]) return textTXT
# Extract text from a TXT file
def read_text_file(txt_file): text = txt_file.getvalue().decode('utf-8') return textCSV
PDF や DOCX ファイルに加えて、チャットボットは CSV ファイルも使用できます。 Hugging Face Transformers ライブラリを使用して、表形式のデータに基づいて質問に答えます。 CSV ファイルとユーザーの質問の処理方法は次のとおりです。
def handle_csv_file(csv_file, user_question): # Read the CSV file csv_text = csv_file.read().decode("utf-8") # Create a DataFrame from the CSV text df = pd.read_csv(io.StringIO(csv_text)) df = df.astype(str) # Initialize a Hugging Face table-question-answering pipeline qa_pipeline = pipeline("table-question-answering", model="google/tapas-large-finetuned-wtq") # Use the pipeline to answer the question response = qa_pipeline(table=df, query=user_question) # Display the answer st.write(response['answer'])4.3 知識ベースの構築
さまざまなファイルから抽出されたテキストが結合され、管理可能なチャンクに分割されます。 これらのチャンクは、チャットボット用のインテリジェントなナレッジ ベースの作成に使用されます。 コンテンツをより深く理解するために、最先端の自然言語処理 (NLP) 技術を使用しています。
# Combine text from different files def combine_text(text_list): return "n".join(text_list) # Split text into chunks
def get_text_chunks(text): text_splitter = CharacterTextSplitter( separator="n", chunk_size=1000, chunk_overlap=200, length_function=len ) chunks = text_splitter.split_text(text) return chunksベクター ストアの作成
私たちのプロジェクトは、最適なパフォーマンスを実現するために、Hugging Face モデルと LangChain をシームレスに統合します。
def get_vectorstore(text_chunks): #embeddings = OpenAIEmbeddings() embeddings = HuggingFaceInstructEmbeddings(model_name="hkunlp/instructor-xl") vectorstore = FAISS.from_texts(texts=text_chunks, embedding=embeddings) return vectorstore4.4 会話型 AI モデルの構築
チャットボットが有意義な応答を提供できるようにするには、会話型 AI モデルが必要です。 このプロジェクトでは、Hugging Face のモデル ハブのモデルを使用します。 会話型 AI モデルを設定する方法は次のとおりです。
def get_conversation_chain(vectorstore): # llm = ChatOpenAI() llm = HuggingFaceHub( repo_id="google/flan-t5-xxl", model_kwargs={"temperature": 0.5, "max_length": 512}) memory = ConversationBufferMemory( memory_key='chat_history', return_messages=True) conversation_chain = Conversational RetrievalChain.from_llm( llm=llm, retriever=vectorstore.as_retriever(), memory=memory ) return conversation_chain4.5 ユーザーの質問に答える
ユーザーは、アップロードしたドキュメントに関連する質問をすることができます。 チャットボットは、ナレッジ ベースと NLP モデルを使用して、関連する回答をリアルタイムで提供します。 ユーザー i を処理する方法は次のとおりです。
def handle_userinput(user_question): if st.session_state.conversation is not None: response = st.session_state.conversation({'question': user_question}) st.session_state.chat_history = response['chat_history'] for i, message in enumerate(st.session_state.chat_history): if i % 2 == 0: st.write(user_template.replace( "{{MSG}}", message.content), unsafe_allow_html=True) else: st.write(bot_template.replace( "{{MSG}}", message.content), unsafe_allow_html=True) else: # Handle the case when conversation is not initialized st.write("Please upload and process your documents first.")4.6 Streamlit を使用したチャットボットの導入
最小限の労力で Web アプリケーションを作成するための素晴らしい Python ライブラリである Streamlit を使用してチャットボットをデプロイしました。 ユーザーは文書をアップロードして質問できます。 チャットボットはドキュメントの内容に基づいて応答を生成します。 Streamlit アプリの設定方法は次のとおりです。
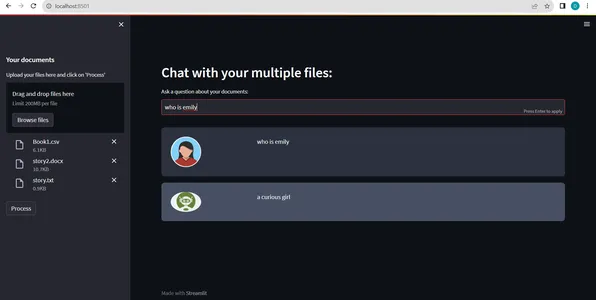
def main(): load_dotenv() st.set_page_config( page_title="File Chatbot", page_icon=":books:", layout="wide" ) st.write(css, unsafe_allow_html=True) if "conversation" not in st.session_state: st.session_state.conversation = None if "chat_history" not in st.session_state: st.session_state.chat_history = None st.header("Chat with your multiple files:") user_question = st.text_input("Ask a question about your documents:") # Initialize variables to hold uploaded files csv_file = None other_files = [] with st.sidebar: st.subheader("Your documents") files = st.file_uploader( "Upload your files here and click on 'Process'", accept_multiple_files=True) for file in files: if file.name.lower().endswith('.csv'): csv_file = file # Store the CSV file else: other_files.append(file) # Store other file types # Initialize empty lists for each file type pdf_texts = [] word_texts = [] txt_texts = [] if st.button("Process"): with st.spinner("Processing"): for file in other_files: if file.name.lower().endswith('.pdf'): pdf_texts.append(get_pdf_text(file)) elif file.name.lower().endswith('.docx'): word_texts.append(get_word_text(file)) elif file.name.lower().endswith('.txt'): txt_texts.append(read_text_file(file)) # Combine text from different file types combined_text = combine_text(pdf_texts + word_texts + txt_texts) # Split the combined text into chunks text_chunks = get_text_chunks(combined_text) # Create vector store and conversation chain if non-CSV documents are uploaded if len(other_files) > 0: vectorstore = get_vectorstore(text_chunks) st.session_state.conversation = get_conversation_chain(vectorstore) else: vectorstore = None # No need for vectorstore with CSV file # Handle user input for CSV file separately if csv_file is not None and user_question: handle_csv_file(csv_file, user_question) # Handle user input for text-based files if user_question: handle_userinput(user_question) if __name__ == '__main__': main()
- CSV ファイルを含む複数のファイルを同時にアップロードし、単一セッションでさまざまな種類のドキュメントを処理できるようにします (ドキュメント処理の図を参照)。
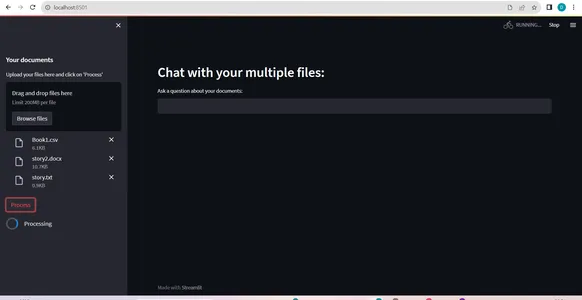
- チャットボットはユーザーのクエリに対する応答を生成します。 この応答は通常、自然言語で行われ、明確で有益な回答を提供することを目的としています。(参照:pic2)
スケーリングと将来の機能拡張
マルチファイル チャットボット プロジェクトに着手する際には、スケーラビリティと将来の機能強化の可能性を考慮することが重要です。未来には、生成 AI および NLP テクノロジの進歩による刺激的な可能性が秘められています。 チャットボットの成長と進化を計画する際に留意すべき重要な側面は次のとおりです。
1 スケーラビリティ
- 並列処理: 多数のユーザーまたはより大規模なファイルを処理するには、並列処理技術を検討できます。 これにより、チャットボットは複数のクエリやドキュメントを同時に効率的に処理できるようになります。
- ロードバランシング: ロード バランシング メカニズムを実装して、ユーザー リクエストを複数のサーバーまたはインスタンスに均等に分散し、ピーク使用時の一貫したパフォーマンスを確保します。
2. 強化されたファイル処理
- より多くのファイル形式のサポート: ドメインで一般的に使用される追加のファイル形式のサポートを追加して、チャットボットの機能を拡張することを検討してください。 たとえば、PowerPoint プレゼンテーションや Excel スプレッドシートのサポートなどです。
- 光学式文字認識(OCR): OCR テクノロジーを組み込んで、スキャンしたドキュメントや画像からテキストを抽出し、チャットボットの範囲を広げます。
3. 機械学習の統合
- 能動的学習: アクティブ ラーニング手法を実装して、チャットボットのパフォーマンスを継続的に向上させます。 ユーザーのフィードバックを収集し、それを使用してモデルを微調整し、応答精度を向上させます。
- カスタムモデルのトレーニング: ドメインに固有のカスタム NLP モデルをトレーニングして、理解を向上させ、コンテキストを認識した応答を実現します。
4. 高度な自然言語処理
- 多言語サポート: チャットボットの言語機能を拡張して複数の言語でユーザーにサービスを提供し、ユーザー ベースを拡大します。
- 感情分析: 感情分析を組み込んでユーザーの感情を測定し、それに応じて応答を調整することで、よりパーソナライズされたエクスペリエンスを実現します。
5. 外部システムとの統合
- APIの統合: チャットボットを外部 API、データベース、またはコンテンツ管理システムに接続して、リアルタイム データを取得し、動的な応答を提供します。
- Webスクレイピング: Web スクレイピング技術を実装して Web サイトから情報を収集し、チャットボットのナレッジ ベースをさらに充実させます。
6.セキュリティとプライバシー
- データ暗号化: ユーザー データと機密情報が暗号化されていることを確認し、安全な認証メカニズムを採用してユーザーのプライバシーを保護します。
- コンプライアンス: データプライバシーの規制と基準を常に最新の状態に保ち、コンプライアンスと信頼性を確保します。
7. ユーザーエクスペリエンスの向上
- 文脈理解: 進行中の会話のコンテキストを記憶して理解するチャットボットの能力を強化し、より自然で一貫した対話を可能にします。
- ユーザーインターフェース: ユーザー インターフェイス (UI) を継続的に改良して、よりユーザー フレンドリーで直感的なものにします。
8.パフォーマンスの最適化
- キャッシング: キャッシュ メカニズムを実装して、頻繁にアクセスされるデータを保存し、応答時間とサーバーの負荷を軽減します。
- 資源管理: システム リソースを監視および管理して、効率的な利用と最適なパフォーマンスを確保します。
9. フィードバックの仕組み
- ユーザーからのフィードバック: ユーザーにチャットボットの対話に関するフィードバックを提供するよう奨励し、改善すべき領域を特定できるようにします。
- 自動フィードバック分析: 自動フィードバック分析を実装して、ユーザーの満足度と注意が必要な領域についての洞察を取得します。
10. 文書化とトレーニング
- ユーザーガイド: ユーザーがチャットボットを最大限に活用できるように、包括的なドキュメントとユーザー ガイドを提供します。
- トレーニングモジュール: ユーザーがチャットボットと効果的に対話する方法を理解するためのトレーニング モジュールまたはチュートリアルを開発します。
まとめ
このブログ投稿では、Streamlit と自然言語処理 (NLP) 技術を使用したマルチファイル チャットボットの開発について検討しました。 このプロジェクトでは、会話型 AI モデルを使用して、さまざまな種類のドキュメントからテキストを抽出し、ユーザーの質問を処理し、関連する回答を提供する方法を紹介します。 このチャットボットを使用すると、ユーザーはドキュメントを簡単に操作し、貴重な洞察を得ることができます。 より多くのドキュメント タイプを統合し、会話型 AI モデルを改善することで、このプロジェクトをさらに強化できます。 このようなアプリケーションを構築すると、ユーザーはデータをより有効に活用できるようになり、さまざまなソースからの情報検索が簡素化されます。 独自のマルチファイル チャットボットの構築を今すぐ始めて、ドキュメントの可能性を解き放ちましょう!
主要な取り組み
- 複数ファイルのチャットボットの概要: マルチファイル チャットボットは、生成 AI および NLP テクノロジーを活用した最先端のソリューションです。 PDF、DOCX、TXT、CSV などのさまざまなファイル形式からの情報への効率的なアクセスと抽出が可能になります。
- 多様な使用例: このチャットボットは、学術研究、データ分析、法律およびコンプライアンス、コンテンツ管理、ヘルスケア、カスタマー サポートなど、さまざまな分野で幅広い用途に使用できます。
- ワークフローの概要: チャットボットのワークフローには、ユーザー対話、ファイル処理、テキスト前処理、情報取得、ユーザー クエリ分析、回答生成、応答生成、および継続的な対話が含まれます。
- 開発環境のセットアップ: 仮想環境を使用して Python 環境をセットアップすることは、プロジェクト固有の依存関係を分離し、スムーズな開発を確保するために不可欠です。
- チャットボットのコーディング: 開発プロセスには、依存関係のインポート、さまざまなファイル形式からのテキストの抽出、ナレッジ ベースの構築、会話型 AI モデルのセットアップ、ユーザーのクエリへの回答、Streamlit を使用したチャットボットの展開が含まれます。
- スケーラビリティと将来の機能拡張: チャットボットのスケーリングと将来の機能強化に関する考慮事項には、並列処理、より多くのファイル形式のサポート、機械学習の統合、高度な NLP、外部システムとの統合、セキュリティとプライバシー、ユーザー エクスペリエンスの向上、パフォーマンスの最適化、フィードバック メカニズムが含まれます。
よくある質問
A. チャットボットの応答の精度は、トレーニング データの品質やユーザーのクエリの複雑さなどの要因によって異なる場合があります。 チャットボットのモデルを継続的に改善し、微調整することで、時間の経過とともに精度を向上させることができます。
A. このブログでは、特定の NLP タスクに Hugging Face のモデル ハブと OpenAI の事前トレーニング済みモデルを使用することについて言及しています。 プロジェクトの要件に応じて、既存の事前トレーニング済みモデルを探索したり、カスタム モデルをトレーニングしたりできます。
A. 多くのマルチファイル チャットボットは、会話中にコンテキストを維持するように設計されています。 彼らは進行中のやり取りのコンテキストを記憶して理解することができるため、以前のディスカッションに関連したフォローアップの質問や質問に対して、より自然で一貫した応答が可能になります。
A. マルチファイル チャットボットは多用途ですが、特定のファイル形式を処理できるかどうかは、テキストの抽出と処理のためのライブラリとツールの利用可能性に依存する場合があります。 このブログでは、PDF、TXT、DOCS、CSV ファイルを扱います。 他のファイル形式を追加したり、ユーザーのニーズに基づいてサポートの拡大を検討したりすることもできます。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/09/how-to-develop-a-multi-file-chatbot/
- :持っている
- :は
- :not
- :どこ
- $UP
- 1
- 10
- 14
- 16
- 9
- a
- 能力
- 私たちについて
- アカデミック
- 学術研究
- アクセス
- アクセス
- アクセス
- それに応じて
- 精度
- 越えて
- アクティブ
- 加えます
- 追加
- 添加
- NEW
- 住所
- 高度な
- 進歩
- 年齢
- AI
- 援助
- 目指して
- 許可
- ことができます
- また
- an
- 分析
- アナリスト
- アナリスト
- 分析論
- 分析Vidhya
- 分析します
- および
- 回答
- 回答
- どれか
- API
- アプリ
- 申し込み
- Archive
- です
- エリア
- 記事
- AS
- 頼む
- 尋ね
- 側面
- アシスト
- 援助
- At
- 注意
- 認証
- 自動化
- 賃貸条件の詳細・契約費用のお見積り等について
- 利用できます
- 通り
- 避ける
- バランシング
- ベース
- ベース
- BE
- になる
- 以下
- より良いです
- ブログ
- ブログソン
- 本
- 持って来る
- ビルド
- 建物
- ビジネス
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 缶
- 機能
- 場合
- 例
- 一定
- チェーン
- チェーン
- 課題
- 文字
- 文字認識
- チャットボット
- チャットボット
- 選択する
- クリーニング
- クリア
- クリック
- クラスタリング
- コード
- コヒーレント
- 組み合わせる
- 組み合わせた
- comes
- 一般に
- 複雑な
- 複雑さ
- コンプライアンス
- 準拠した
- 包括的な
- 競合
- お問合せ
- 検討
- 検討事項
- 整合性のある
- コンテンツ
- コンテンツ管理
- コンテキスト
- 継続的に
- 続ける
- 続ける
- 連続的な
- 契約
- 会話
- 会話
- 会話型AI
- 会話
- 相関関係
- カウント
- 作ります
- 作成
- 重大な
- 重大な
- CSS
- カスタム
- 顧客
- カスタマーサービス
- 最先端
- データ
- データ分析
- データアナリスト
- データプライバシー
- データ処理
- データの可視化
- データ駆動型の
- データベースを追加しました
- データセット
- 意思決定
- 決定
- 密集
- 依存関係
- によっては
- 展開します
- 展開
- 展開する
- 設計
- 細部
- 開発する
- 開発
- 診断
- 異なります
- デジタル
- デジタル時代
- 裁量
- 議論
- ディスプレイ
- 分配します
- ダイビング
- 異なる
- ドキュメント
- ドキュメント
- ドキュメント
- ありません
- ドメイン
- ドメイン
- 間に
- ダイナミック
- 各
- 容易
- 簡単に
- 教育の
- 効果的に
- 効率的な
- 効率良く
- 努力
- 楽
- どちら
- ほかに
- 乗り出す
- 埋め込み
- 感情
- 力を与える
- 空の
- enable
- 可能
- 有効にする
- 奨励する
- では使用できません
- 終了
- 高めます
- 強化された
- 強化
- 強化
- 濃縮
- 確保
- 確実に
- 確保する
- 環境
- 環境
- 本質的な
- エーテル(ETH)
- 均等に
- ますます増加する
- 進化
- 進化
- 例
- Excel
- エキサイティング
- 既存の
- 拡大
- 予想される
- 体験
- 探査
- 探る
- 調査済み
- 指数関数的に
- 伸ばす
- 拡張する
- 広範囲
- 外部
- エキス
- 抽出
- 顔
- 要因
- 素晴らしい
- フィードバック
- フィールド
- File
- 調査結果
- 名
- 焦点を当てて
- 形式でアーカイブしたプロジェクトを保存します.
- フォーマット
- 頻繁に
- から
- フル
- 機能性
- さらに
- 未来
- 利得
- 集める
- ゲージ
- 生成する
- 生成
- 世代
- 生々しい
- 生成AI
- 取得する
- 与えられた
- グローバル
- 良い
- 成長した
- 成長性
- ガイド
- ハンドル
- ハンドリング
- ヘルスケア
- ヘルスケア部門
- 助けます
- 助け
- こちら
- 特徴
- 歴史的
- 保持している
- 認定条件
- How To
- HTTPS
- ハブ
- i
- 識別する
- if
- 画像
- 実装する
- import
- 重要
- インポート
- 改善します
- 改善されました
- 改善
- 改善
- 改善
- in
- include
- 含ま
- 含めて
- 組み込む
- ますます
- インデックス
- 産業
- info
- 情報
- 有益な
- 革新的な
- 洞察
- install
- インストール
- 機関
- 統合する
- 統合する
- 統合
- 統合
- インテリジェント-
- 対話
- 相互作用
- 相互作用
- 相互作用する
- インタフェース
- に
- 複雑さ
- 直観的な
- 関与
- 関与
- 分離された
- IT
- ITS
- 旅
- キープ
- 保管
- キー
- 知識
- 言語
- ESL, ビジネスESL <br> 中国語/フランス語、その他
- より大きい
- 法制
- 法令
- 弁護士
- 学習
- リーガルポリシー
- 活用します
- ライブラリ
- 図書館
- 生活
- 制限
- 限定的
- linuxの
- リスト
- レポート
- 負荷
- 探して
- 機械
- 機械学習
- MacOSの
- 維持する
- make
- 作成
- 管理します
- 扱いやすいです
- 管理
- 管理する
- 多くの
- 五月..
- 意味のある
- メカニズム
- メディア
- 医療の
- 医学研究
- メモリ
- 言及
- メッセージ
- メトリック
- かもしれない
- マインド
- 最小限の
- モデル
- モジュール
- モジュール
- モニター
- 他には?
- 最も
- の試合に
- 名
- ナチュラル
- 自然言語
- 自然言語処理
- 自然言語理解
- ナビゲート
- 必要
- 必要
- ニーズ
- NLP
- いいえ
- なし
- 数
- 目的
- OCR
- of
- on
- ONE
- 継続
- OpenAI
- 最適な
- 最適化
- or
- 組織
- OS
- その他
- 私たちの
- アウトライン
- が
- 概要
- 自分の
- 所有している
- パッケージ
- ページ
- ページ
- パンダ
- 紙素材
- 論文
- 並列シミュレーションの設定
- 部
- 患者
- パターン
- ピーク
- パフォーマンス
- カスタマイズ
- パイプライン
- シンプルスタイル
- 計画
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- お願いします
- 急落
- の可能性
- ポスト
- 潜在的な
- :
- 電力
- パワード
- 練習
- 優先
- プレゼンテーション
- 前
- 主に
- プライバシー
- プロセス
- 処理されました
- ラボレーション
- 処理
- 専門家
- プロジェクト
- プロジェクト(実績作品)
- 守る
- 提供します
- 公表
- Python
- 品質
- クエリ
- 質問
- 質問
- すぐに
- 範囲
- 読む
- 準備
- への
- リアルタイムデータ
- 認識
- 記録
- 記録
- 縮小
- 参照する
- リファイン
- 規制
- レギュレータ
- 関連する
- 関連した
- 残る
- 覚えています
- replace
- レポート
- リクエスト
- 必要とする
- の提出が必要です
- 要件
- 研究
- 研究者
- リソース
- 応答
- 応答
- 応答時間
- 回答
- return
- レビュー
- 上昇
- 満足
- スケーラビリティ
- スケーリング
- 科学
- スコープ
- こすること
- シームレス
- を検索
- セクター
- 安全に
- セキュリティ
- を求める
- セグメンテーション
- 敏感な
- 文
- 感情
- 別々
- 役立つ
- サーバー
- セッション
- セッションに
- 設定
- いくつかの
- 示す
- 意義
- 同時に
- スムーズ
- ソフトウェア
- 溶液
- 一部
- ソース
- 専門の
- 特定の
- split
- st
- 規格
- start
- 最先端の
- 統計的
- 滞在
- ステップ
- 店舗
- 保存され
- 店舗
- 文字列
- 構造化された
- 学生
- 生徒
- 研究
- そのような
- サポート
- サポートシステム
- システム
- テーラード
- タスク
- テクニック
- テクノロジー
- テクノロジー
- ターミナル
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- 教科書
- それ
- 未来
- アプリ環境に合わせて
- その後
- そこ。
- それによって
- ボーマン
- 彼ら
- この
- 介して
- 時間
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- 今日の
- トークン
- ツール
- 豊富なツール群
- 伝統的な
- トレーニング
- トレーニング
- トランスフォーマー
- 治療
- トレンド
- 信頼性
- チュートリアル
- type
- 一般的に
- ui
- わかる
- 理解する
- 異なり、
- アンロック
- 更新しました
- アップロード
- 使用法
- つかいます
- 中古
- 便利
- ユーザー
- 操作方法
- ユーザーインターフェース
- ユーザーのプライバシー
- 「DeckleBenchは非常に使いやすく最適なソリューションを簡単に見つけることができるため、稼働率が向上しコストも削減した。当社の旧システムは良かったが改善は期待していなかった。
- users
- 使用されます
- ユーティリティ
- 活用する
- 貴重な
- 貴重な情報
- variables
- さまざまな
- 変わります
- 多才な
- 、
- バーチャル
- 可視化
- 極めて重要な
- ボリューム
- ました
- we
- ウェブ
- Webアプリケーション
- ウェブスクレイピング
- webp
- ウェブサイト
- この試験は
- 何ですか
- いつ
- かどうか
- which
- while
- ワイド
- 広い範囲
- 意志
- 以内
- 仕事
- ワークフロー
- ワーキング
- 世界
- 貴社
- あなたの
- ゼファーネット