概要
事前トレーニング済みモデル、転移学習など、AI とディープ ラーニングに関するいくつかの凝った用語を見てきました。広く使用されているテクノロジと、最も重要で効果的なテクノロジの 5 つである YOLOvXNUMX を使用した転移学習について説明しましょう。
You Only Look Once、または YOLO は、最も広く使用されている深層学習ベースのオブジェクト識別方法の 5 つです。 この記事では、カスタム データセットを使用して、最新のバリエーションの XNUMX つである YOLOvXNUMX をトレーニングする方法を示します。
学習目標
- この記事では主に、カスタム データセット実装での YOLOv5 モデルのトレーニングに焦点を当てます。
- 事前トレーニング済みモデルとは何か、転移学習とは何かを見ていきます。
- YOLOv5 とは何か、そしてなぜ YOLO のバージョン 5 を使用しているのかを理解します。
それでは、時間を無駄にすることなく、プロセスを開始しましょう
コンテンツの表
- 事前トレーニング済みモデル
- 転移学習
- YOLOv5とは何ですか?
- 転移学習に含まれる手順
- 製品の導入
- 直面する可能性のあるいくつかの課題
- まとめ
事前トレーニング済みモデル
データ サイエンティストが「事前トレーニング済みモデル」という用語を広く使用しているのを聞いたことがあるかもしれません。 深層学習モデル/ネットワークが何をするかを説明した後、用語について説明します。 深層学習モデルは、分類、検出などの単一の目的を果たすために、さまざまなレイヤーが積み重ねられたモデルです。深層学習ネットワークは、供給されたデータの複雑な構造を発見し、重みをファイルに保存することで学習します。後で同様のタスクを実行するために使用されます。 事前トレーニング済みモデルは、すでにトレーニング済みの深層学習モデルです。 つまり、何百万もの画像を含む巨大なデータセットですでにトレーニングされているということです。
ここにどのように TensorFlow Web サイトでは、事前トレーニング済みのモデルを定義しています。 事前トレーニング済みモデルは、大規模なデータセット (通常は大規模な画像分類タスク) で以前にトレーニングされた保存済みネットワークです。
いくつかの高度に最適化された非常に効率的な 事前トレーニング済みモデル インターネットで利用できます。 さまざまなタスクを実行するために、さまざまなモデルが使用されます。 事前トレーニング済みのモデルには、VGG-16、VGG-19、YOLOv5、YOLOv3、および レスネット 50.
どのモデルを使用するかは、実行するタスクによって異なります。 たとえば、実行したい場合 物体検出 タスクでは、YOLOv5 モデルを使用します。
転移学習
転移学習 は、データ サイエンティストの作業を容易にする最も重要な手法です。 モデルのトレーニングは、膨大で時間のかかる作業です。 モデルをゼロからトレーニングした場合、通常、あまり良い結果は得られません。 事前トレーニング済みのモデルと同様のモデルをトレーニングしても、効果的には機能せず、モデルのトレーニングに数週間かかる場合があります。 代わりに、事前トレーニング済みのモデルを使用し、カスタム データセットでトレーニングすることによって既に学習した重みを使用して、同様のタスクを実行できます。 これらのモデルは、アーキテクチャとパフォーマンスの点で非常に効率的で洗練されており、さまざまなコンテストでより優れたパフォーマンスを発揮することでトップに躍り出ました。 これらのモデルは非常に大量のデータでトレーニングされるため、知識がより多様になります。
したがって、転移学習とは基本的に、以前のデータでモデルをトレーニングして得た知識を転移し、モデルがより良く、より速く学習して、異なるが類似したタスクを実行できるようにすることを意味します。
たとえば、オブジェクト検出に YOLOv5 を使用しますが、オブジェクトは以前に使用されたオブジェクトのデータとは別のものです。
YOLOv5とは何ですか?
YOLOv5 は事前トレーニング済みのモデルであり、バージョン 5 がリアルタイムのオブジェクト検出に使用され、精度と推論時間の点で非常に効率的であることが証明されています。 YOLO には他のバージョンもありますが、予想どおり、YOLOv5 は他のバージョンよりも優れたパフォーマンスを発揮します。 YOLOv5 は高速で使いやすいです。 これは、Yolo v4 Darknet よりも大きなコミュニティを持つ PyTorch フレームワークに基づいています。
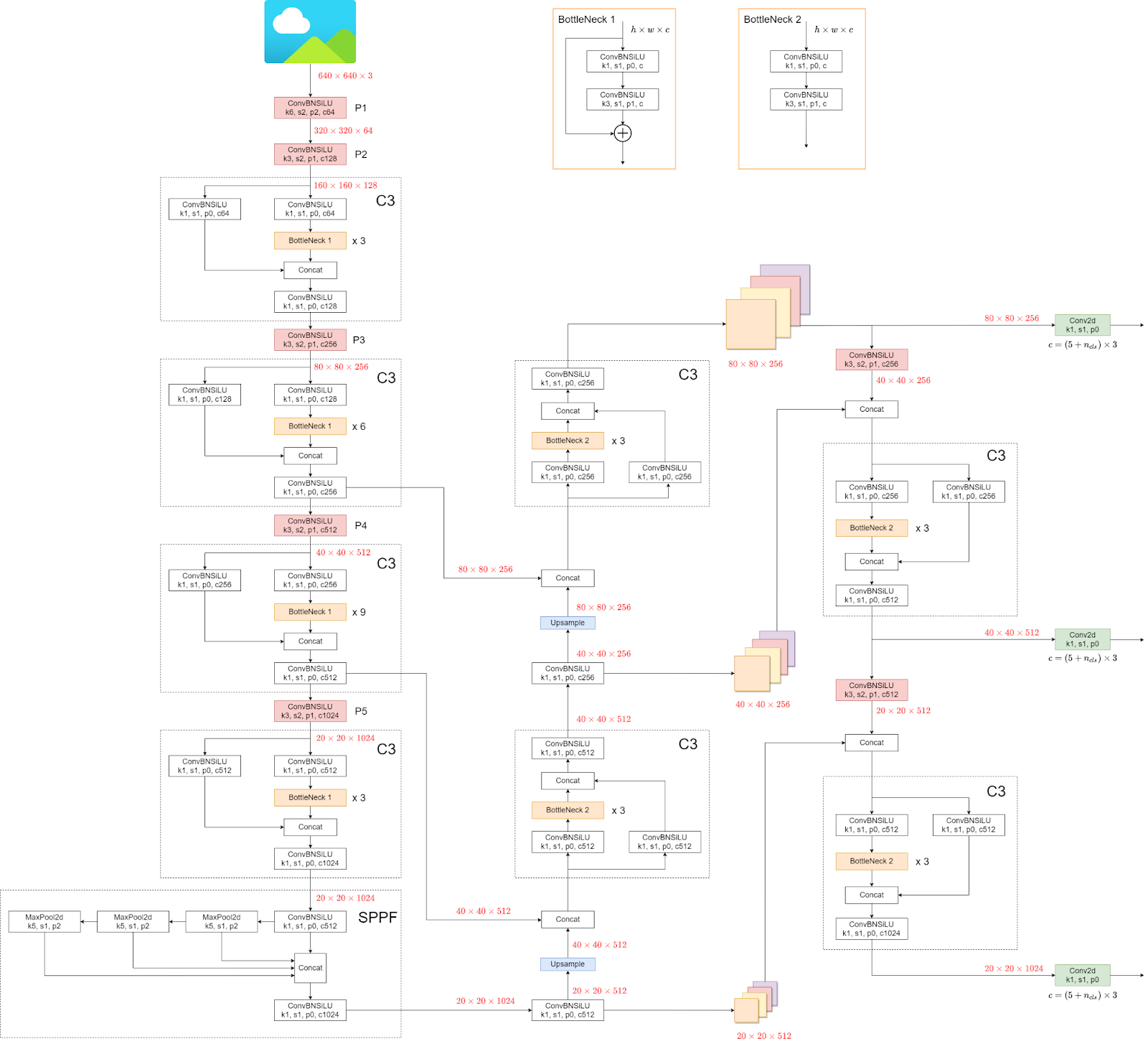
次に、YOLOv5 のアーキテクチャを見ていきます。
構造がわかりにくいかもしれませんが、アーキテクチャを見る必要はなく、モデルと重みを直接使用するので問題ありません。
転移学習では、カスタム データセット、つまりモデルがこれまで見たことのないデータ、またはモデルがトレーニングされていないデータを使用します。 モデルはすでに大規模なデータセットでトレーニングされているため、重みは既にあります。 これで、作業したいデータのいくつかのエポックに対してモデルをトレーニングできます。 モデルは初めてデータを見て、タスクを実行するにはある程度の知識が必要になるため、トレーニングが必要です。
転移学習に含まれる手順
転移学習は簡単なプロセスであり、いくつかの簡単な手順で実行できます。
- データの準備
- 注釈の適切な形式
- 必要に応じて、いくつかのレイヤーを変更します
- 数回反復してモデルを再トレーニングします
- 検証/テスト
データの準備
選択したデータが少し大きい場合、データの準備に時間がかかることがあります。 データの準備とは、画像に注釈を付けることを意味します。これは、画像内のオブジェクトの周りにボックスを作成して画像にラベルを付けるプロセスです。 これにより、マークされたオブジェクトの座標がファイルに保存され、トレーニングのためにモデルに供給されます。 などのいくつかの Web サイトがあります。 メイクセンス.ai & ロボフロー.com, これは、データにラベルを付けるのに役立ちます。
makesense.ai で YOLOv5 モデルのデータに注釈を付ける方法を次に示します。
1. 訪問 https://www.makesense.ai/.
2. 画面右下の開始をクリックします。
3. 中央で強調表示されているボックスをクリックして、ラベルを付けたい画像を選択します。
注釈を付けたい画像を読み込み、オブジェクト検出をクリックします。
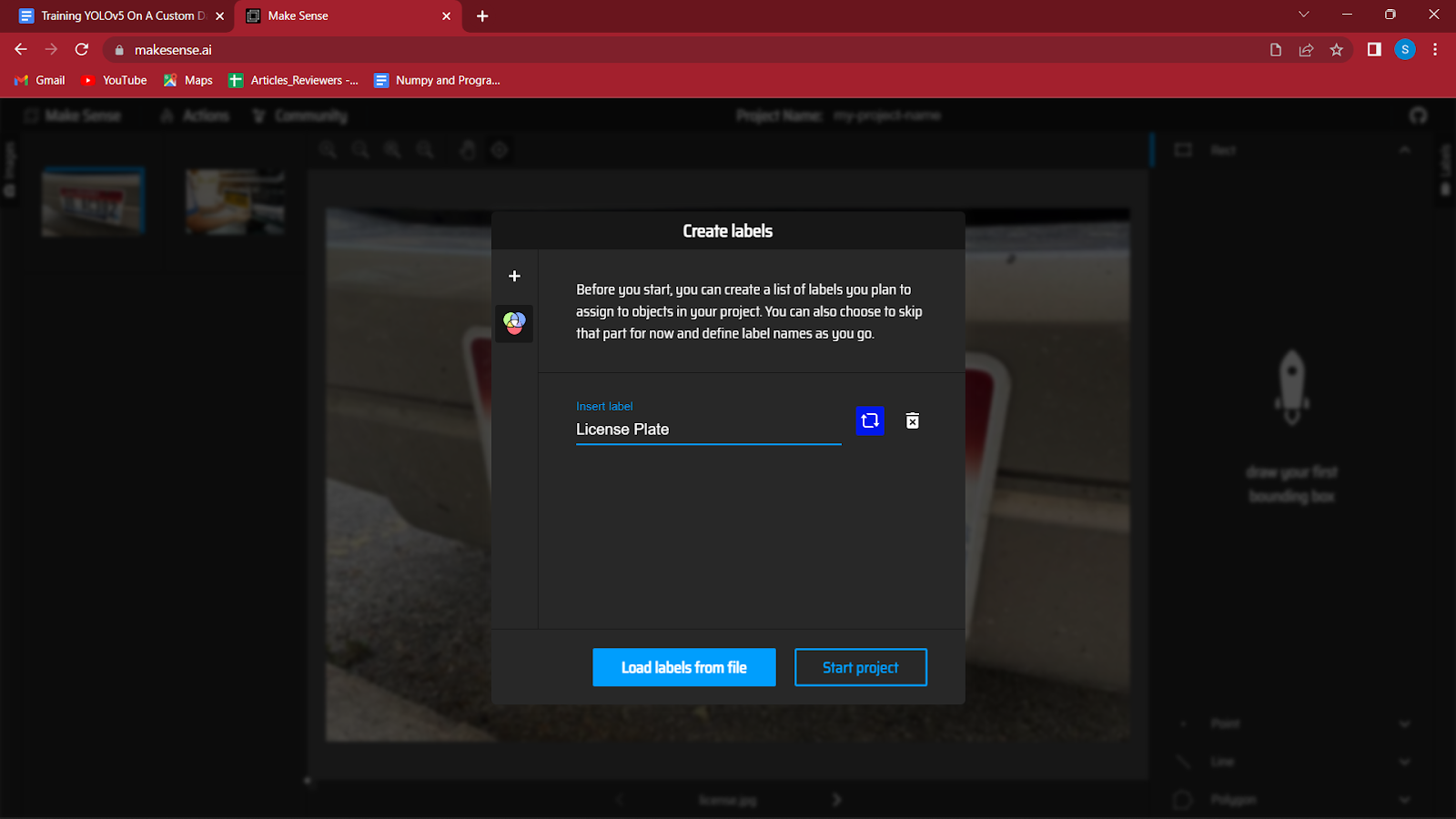
4. 画像を読み込んだ後、データセットのさまざまなクラスのラベルを作成するよう求められます。
車両のナンバー プレートを検出しているので、使用する唯一のラベルは「ライセンス プレート」です。 ダイアログ ボックスの左側にある [+] ボタンをクリックして Enter キーを押すだけで、さらにラベルを作成できます。
すべてのラベルを作成したら、プロジェクトの開始をクリックします。
ラベルを見逃した場合は、後でアクションをクリックして編集し、ラベルを編集できます。
5. 画像内のオブジェクトの周囲にバウンディング ボックスの作成を開始します。 この演習は、最初は少し楽しいかもしれませんが、データが非常に大きい場合、疲れる場合があります。
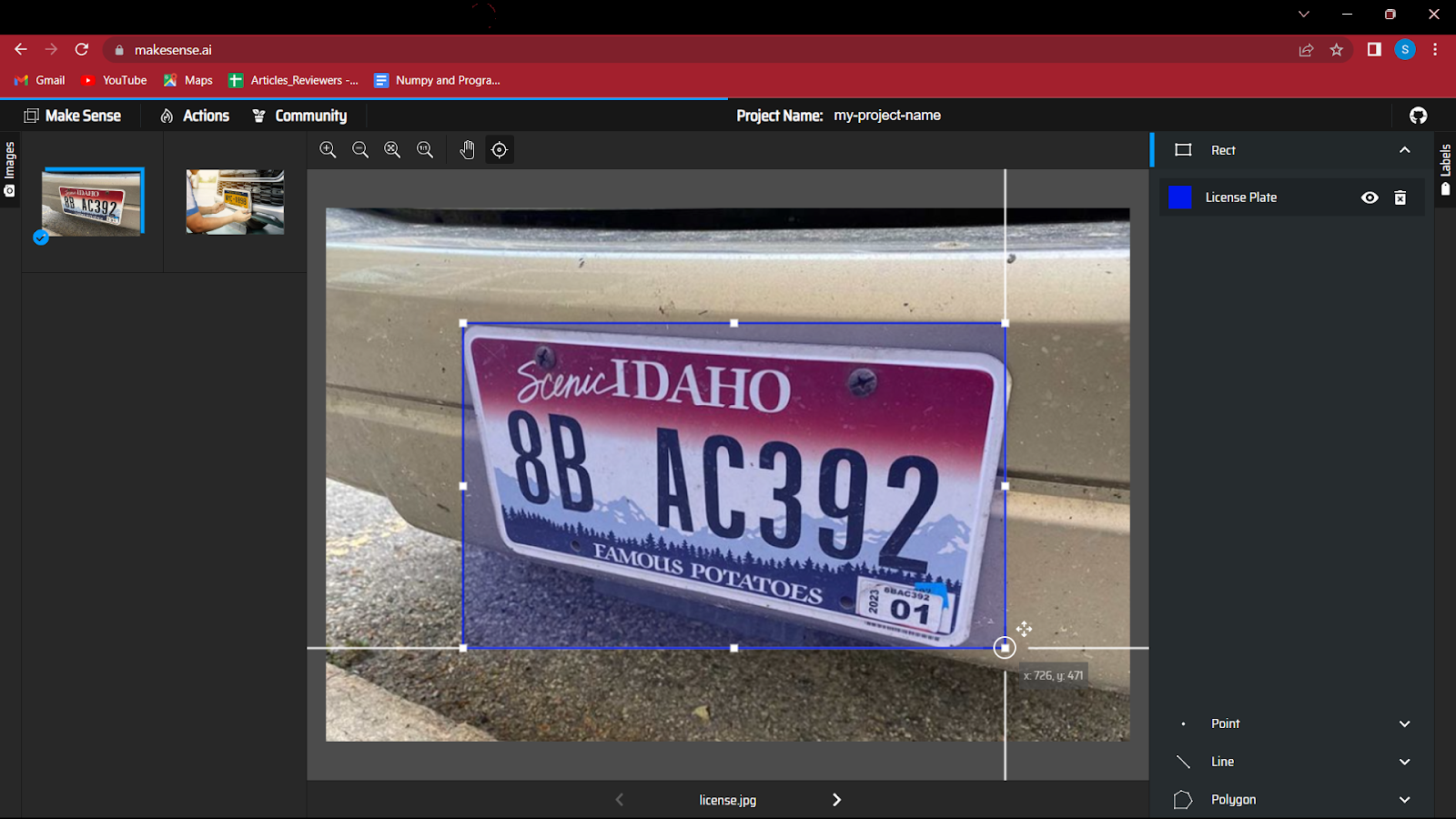
6. すべての画像に注釈を付けた後、境界ボックスの座標とクラスを含むファイルを保存する必要があります。
したがって、アクション ボタンに移動し、注釈のエクスポートをクリックする必要があります。[YOLO 形式のファイルを含む zip パッケージ] オプションをオンにすることを忘れないでください。これにより、YOLO モデルで必要な正しい形式でファイルが保存されます。
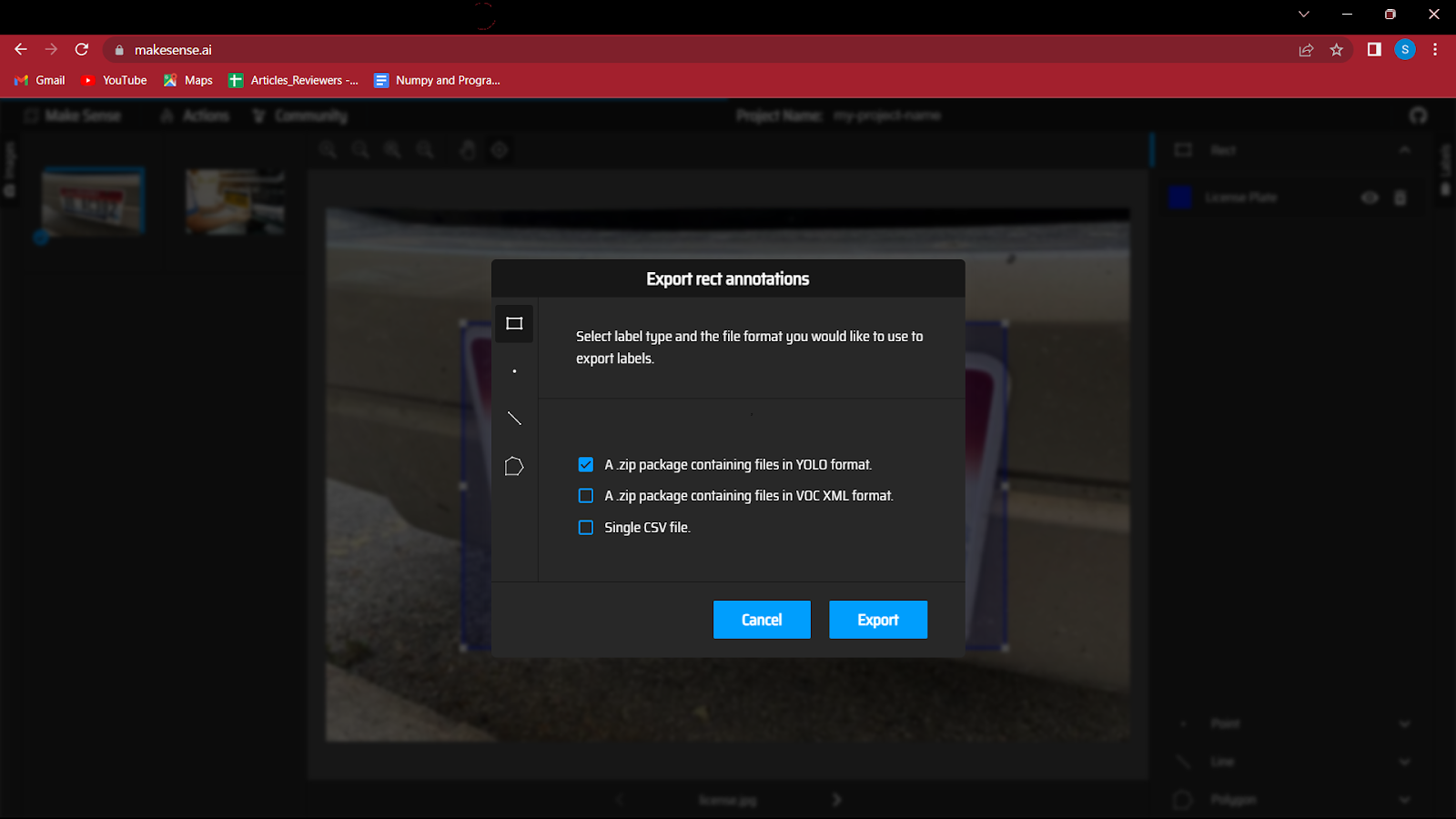
7. これは重要なステップですので、慎重に実行してください。
すべてのファイルと画像が揃ったら、任意の名前のフォルダーを作成します。 フォルダーをクリックし、フォルダー内に画像とラベルという名前のフォルダーをさらに XNUMX つ作成します。 コマンドでトレーニング パスを入力した後、モデルは自動的にラベルを検索するため、フォルダーに上記と同じ名前を付けることを忘れないでください。
フォルダのイメージをつかむために、「CarsData」という名前のフォルダを作成し、そのフォルダに「images」と「labels」という XNUMX つのフォルダを作成しました。
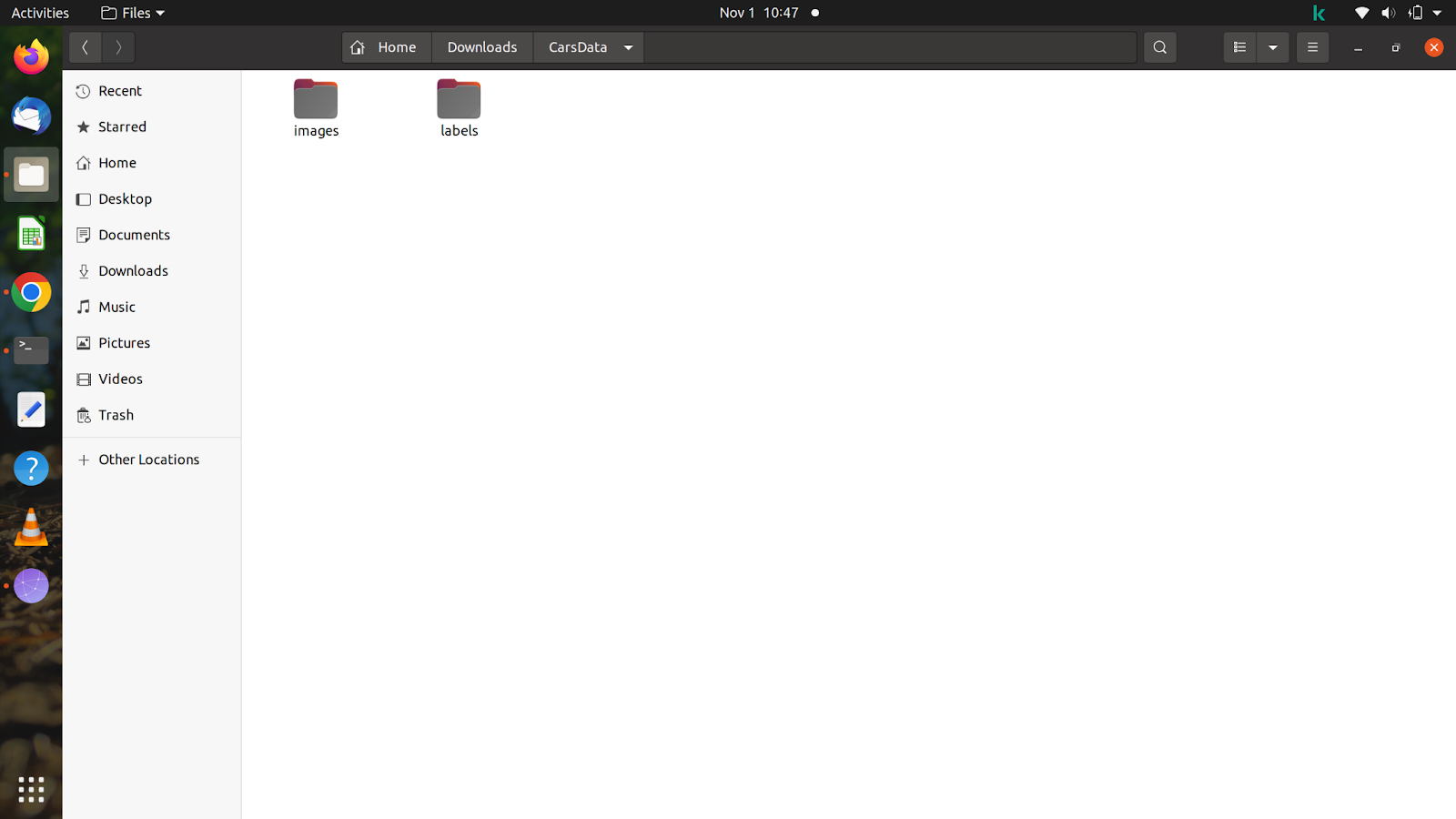
XNUMX つのフォルダー内に、「train」と「val」という名前のフォルダーをさらに XNUMX つ作成する必要があります。 画像フォルダーでは、自由に画像を分割できますが、ラベルは分割した画像と一致する必要があるため、ラベルを分割する際には注意が必要です。
8. 次に、フォルダーの zip ファイルを作成し、ドライブにアップロードして、colab で使用できるようにします。
製品の導入
ここから実装部分に移ります。これは非常に単純ですが、注意が必要です。 どのファイルを正確に変更する必要があるかがわからない場合、カスタム データセットでモデルをトレーニングすることはできません。
カスタム データセットで YOLOv5 モデルをトレーニングするために従うべきコードは次のとおりです。
より高速な計算を提供する GPU も提供するため、このチュートリアルでは google colab を使用することをお勧めします。
1. !git クローン https://github.com/ultralytics/yolov5
これにより、ultralytics によって作成された GitHub リポジトリである YOLOv5 リポジトリのコピーが作成されます。
2.cdヨロフ5
これは、現在の作業ディレクトリを YOLOv5 ディレクトリに変更するために使用されるコマンドライン シェル コマンドです。
3. !pip install -rrequirements.txt
このコマンドは、モデルのトレーニングに使用されるすべてのパッケージとライブラリをインストールします。
4. !unzip '/content/drive/MyDrive/CarsData.zip'
Google Colab で画像とラベルを含むフォルダーを解凍する
これが最も重要なステップです…
これでほぼすべての手順を実行したので、モデルをトレーニングするコードをもう XNUMX 行記述する必要がありますが、その前に、さらにいくつかの手順を実行し、カスタム データセットのパスを指定するためにいくつかのディレクトリを変更する必要があります。そのデータでモデルをトレーニングします。
これがあなたがする必要があることです。
上記の 4 つの手順を実行すると、Google Colab に yolov5 フォルダーが作成されます。 yolov5 フォルダーに移動し、「data」フォルダーをクリックします。 「coco128.yaml」という名前のフォルダーが表示されます。
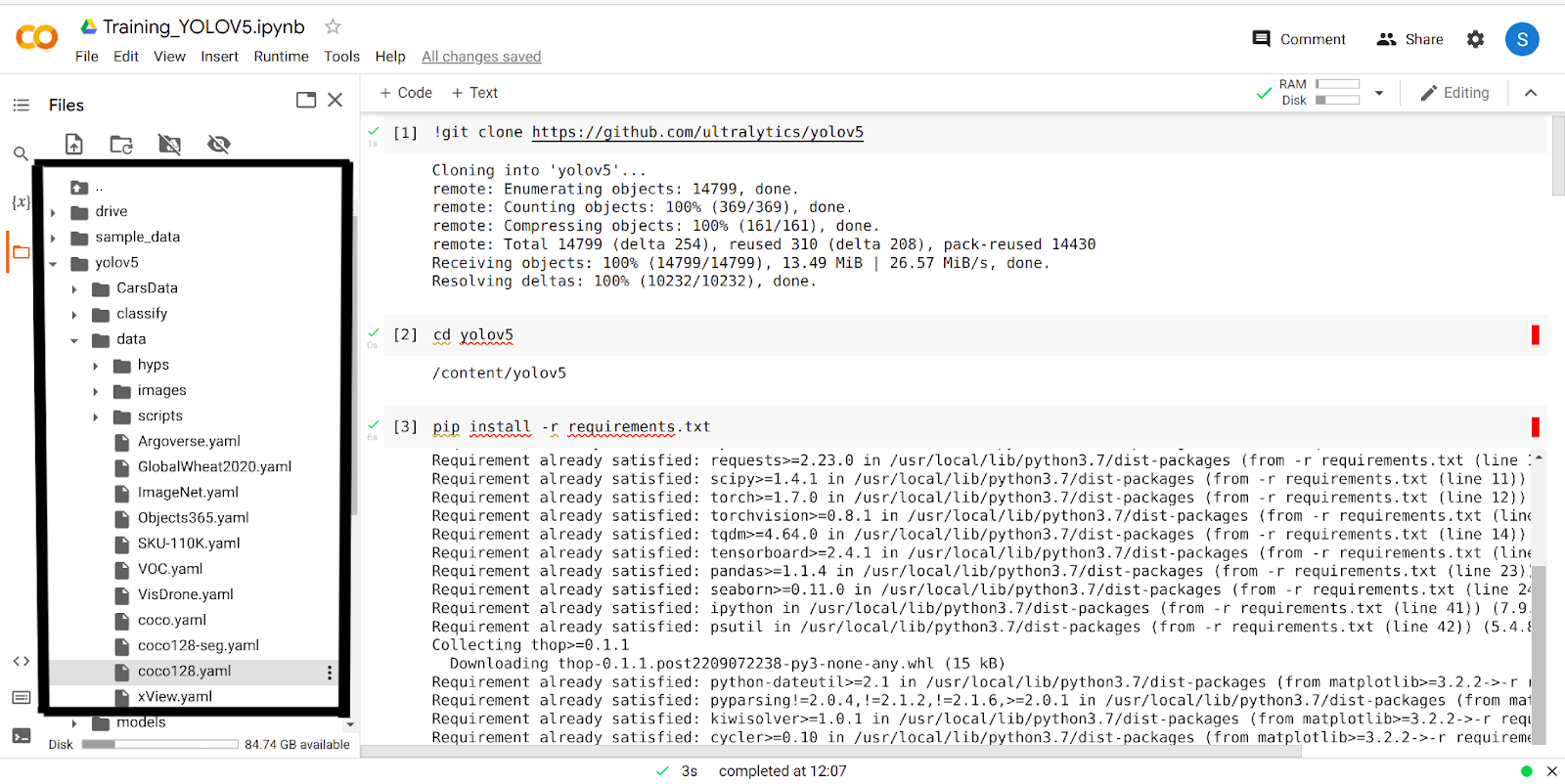
このフォルダをダウンロードしてください。
フォルダーがダウンロードされたら、フォルダーにいくつかの変更を加えて、ダウンロード元と同じフォルダーにアップロードする必要があります。
ダウンロードしたファイルの内容を見てみましょう。次のようになります。
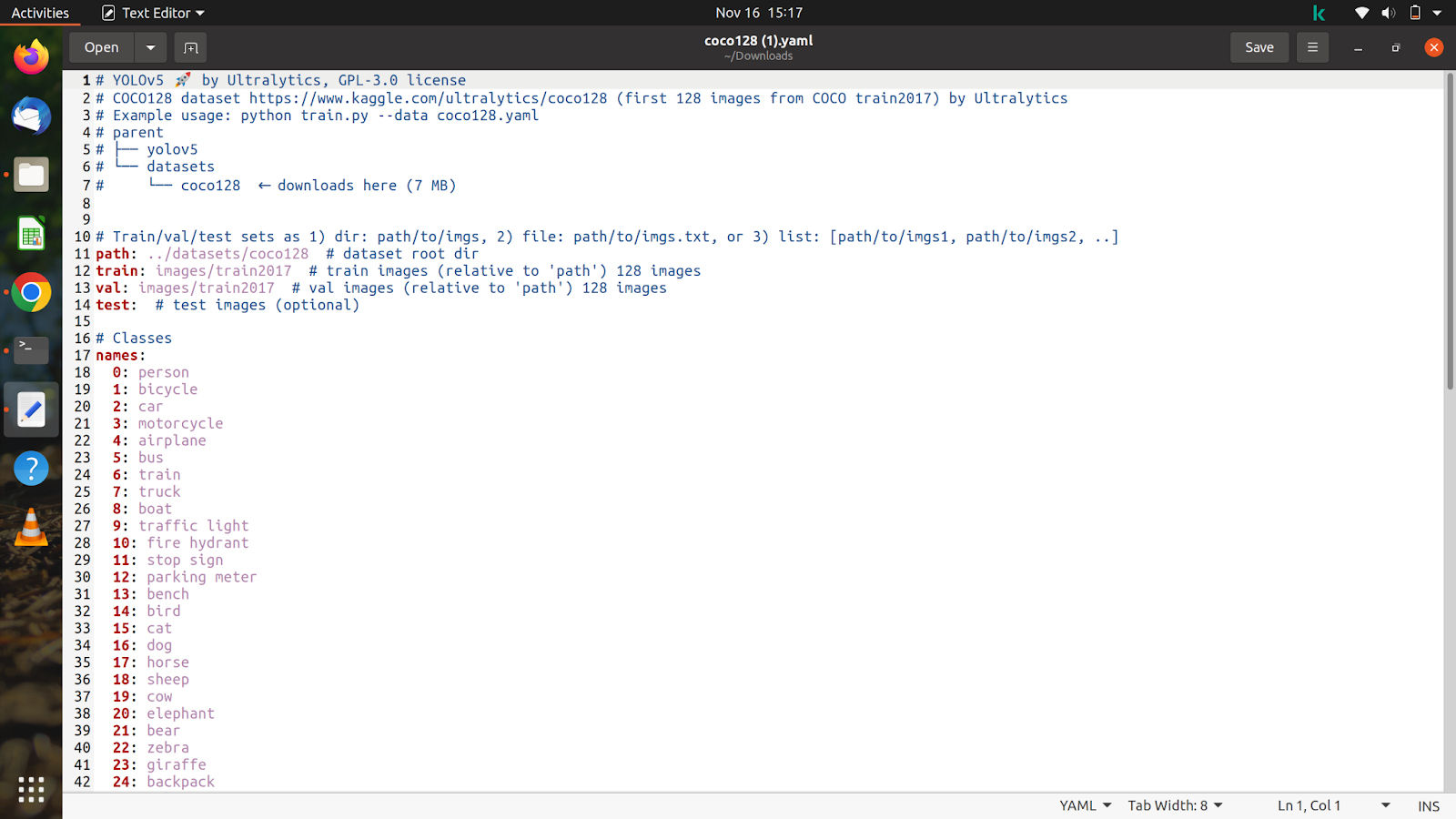
データセットと注釈に従って、このファイルをカスタマイズします。
colab で既にデータセットを解凍しているので、トレーニングと検証イメージのパスをコピーします。 データセット フォルダーにある、「/content/yolov5/CarsData/images/train」のような電車の画像のパスをコピーした後、先ほどダウンロードした coco128.yaml ファイルに貼り付けます。
テスト画像と検証画像についても同じことを行います。
これが終わったら、「nc: 1」のようにクラスの数について言及します。 この場合、クラスの数は 1 つだけです。次に、下の画像に示すように名前を指定します。 他のすべてのクラスと不要なコメント部分を削除すると、ファイルは次のようになります。
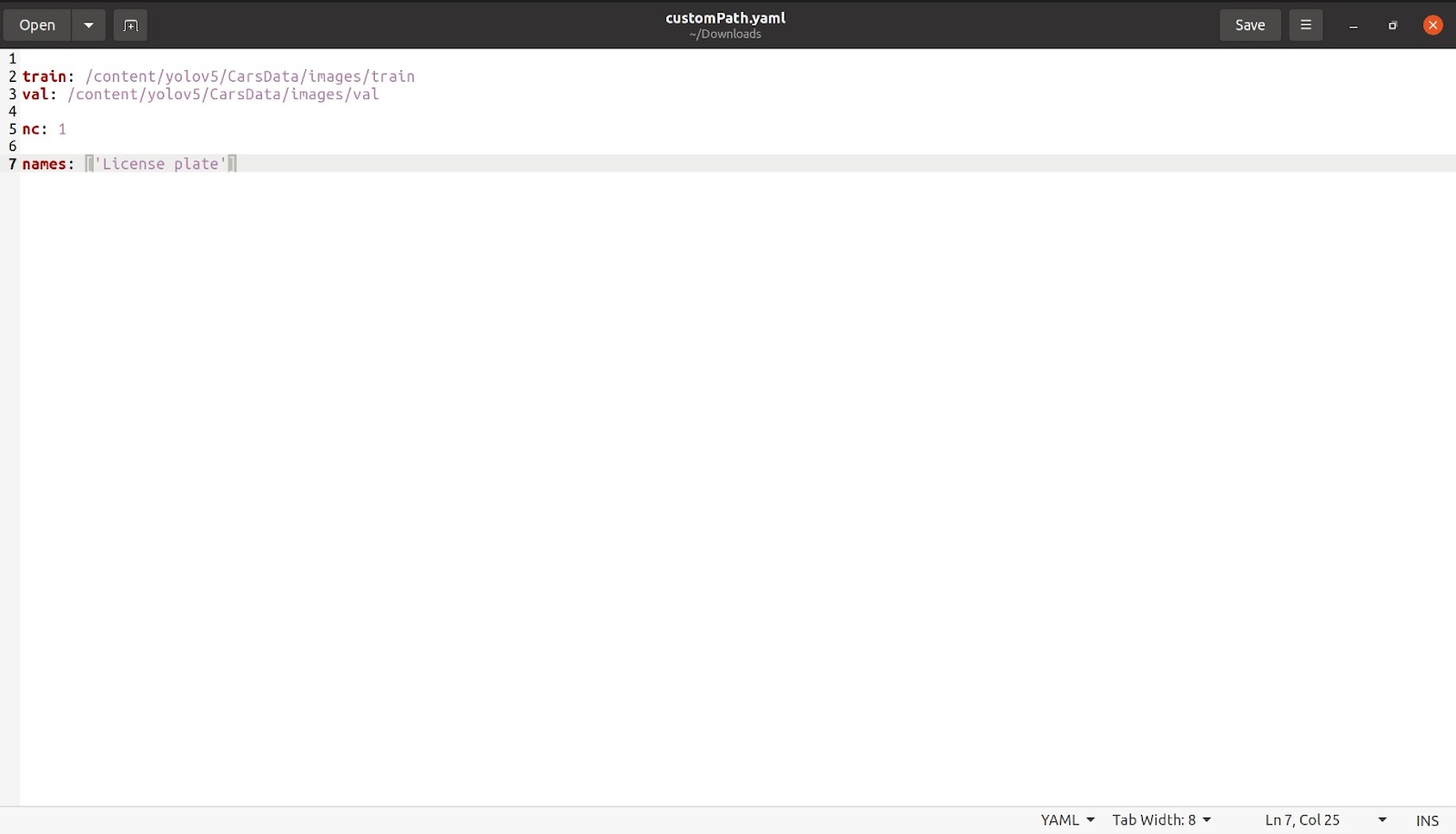
このファイルを任意の名前で保存します。 ファイルを customPath.yaml という名前で保存し、このファイルを coco128.yaml と同じ場所にある colab にアップロードします。
これで編集部分が完了し、モデルをトレーニングする準備が整いました。
次のコマンドを実行して、カスタム データセットでのいくつかの操作についてモデルをトレーニングします。
アップロードしたファイルの名前 ('customPath.yaml) を変更することを忘れないでください。 モデルをトレーニングするエポック数を変更することもできます。 この場合、モデルを 3 エポックだけトレーニングします。
5. !python train.py –img 640 –batch 16 –epochs 10 –data /content/yolov5/customPath.yaml –weights yolov5s.pt
フォルダーをアップロードするパスに注意してください。 パスが変更されると、コマンドはまったく機能しなくなります。
このコマンドを実行すると、モデルのトレーニングが開始され、画面に次のようなものが表示されます。
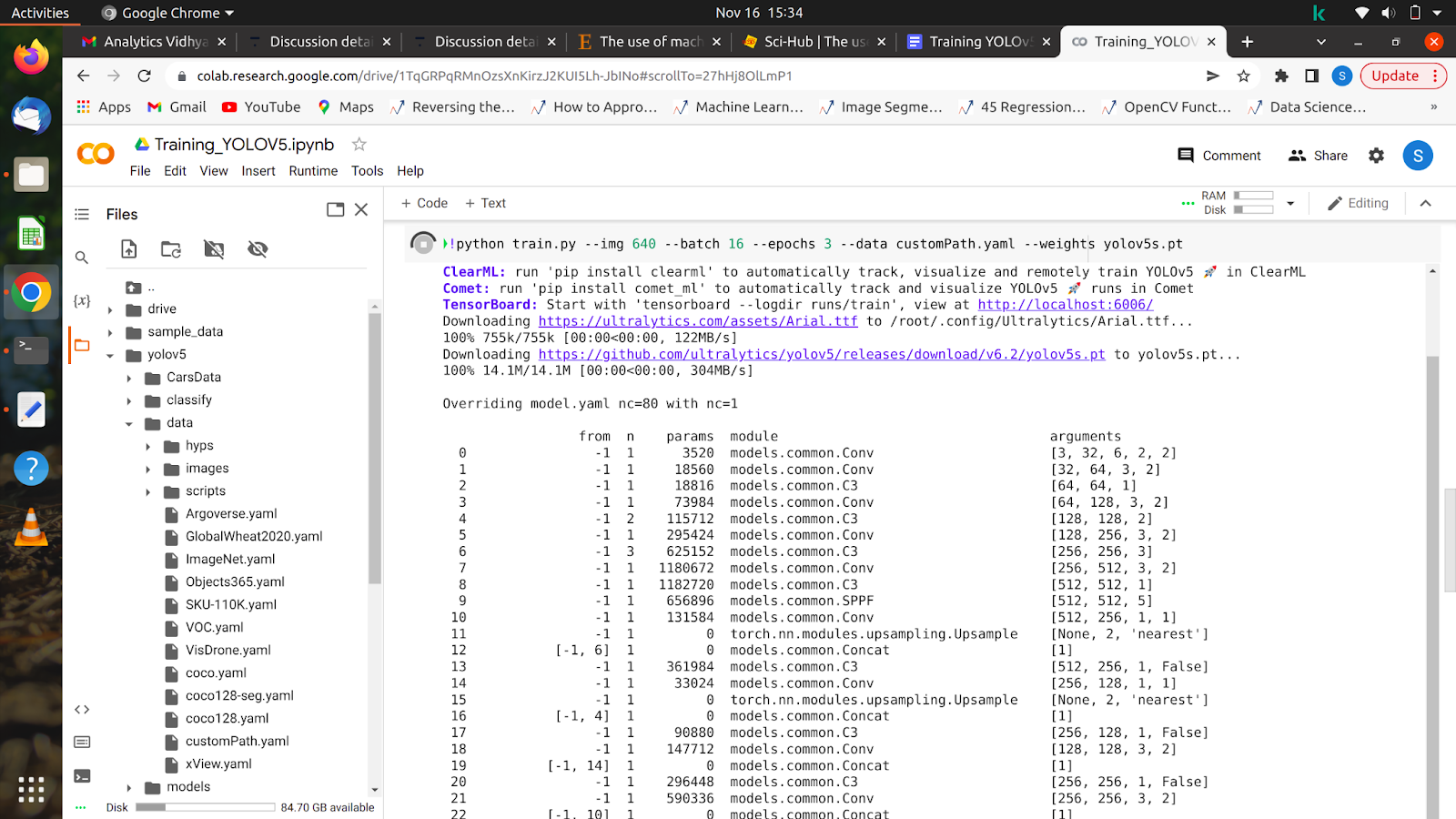
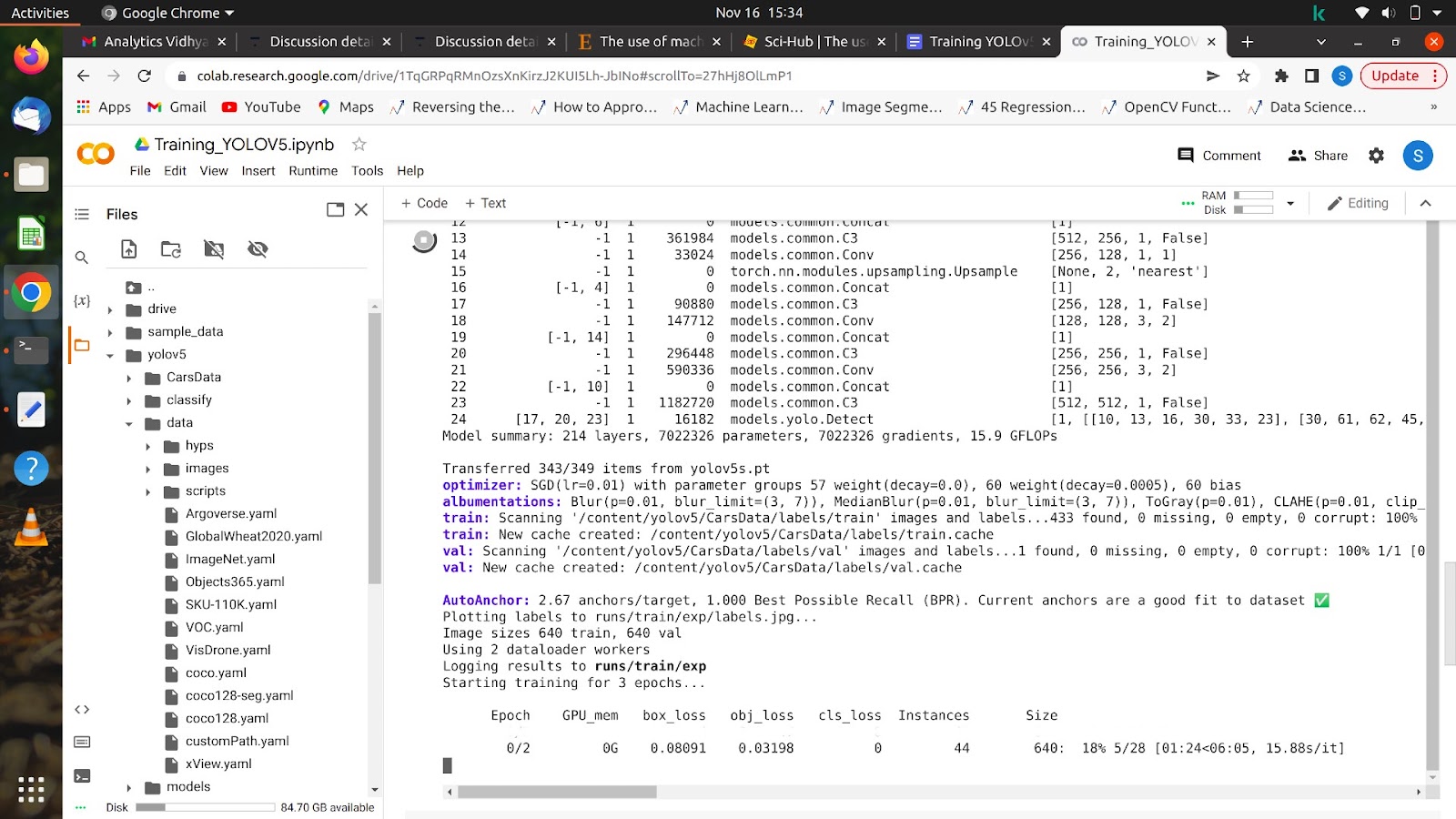
すべてのエポックが完了したら、モデルを任意のイメージでテストできます。
保存したいものと気に入らないもの、ナンバー プレートが検出される検出などについて、detect.py ファイルでさらにカスタマイズを行うことができます。
6. !python detect.py –weight /content/yolov5/runs/train/exp/weights/best.pt –source path_of_the_image
このコマンドを使用して、一部の画像でモデルの予測をテストできます。
直面する可能性のあるいくつかの課題
上で説明した手順は正しいものですが、正確に従わないと直面する可能性のある問題がいくつかあります。
- 間違ったパス: これは頭痛の種または問題になる可能性があります。 画像のトレーニングのどこかに間違ったパスを入力した場合、それを特定するのは容易ではなく、モデルをトレーニングすることはできません。
- ラベルの間違った形式: これは、YOLOv5 のトレーニング中に人々が直面する広範な問題です。 モデルは、すべての画像が目的の形式を内部に含む独自のテキスト ファイルを持つ形式のみを受け入れます。 多くの場合、XLS 形式のファイルまたは単一の CSV ファイルがネットワークに送られ、エラーが発生します。 すべての画像に注釈を付けるのではなく、どこかからデータをダウンロードする場合、ラベルが保存される別のファイル形式が存在する可能性があります。 XLS形式をYOLO形式に変換する記事はこちら。 (記事完成後のリンク)。
- ファイルの名前が正しくない: ファイルの名前が正しくないと、再びエラーが発生します。 フォルダーに名前を付ける際の手順に注意して、このエラーを回避してください。
まとめ
この記事では、転移学習とは何か、事前トレーニング済みのモデルについて学びました。 YOLOv5 モデルを使用するタイミングと理由、およびカスタム データセットでモデルをトレーニングする方法を学びました。 データセットの準備からパスの変更、そして最終的には技術の実装におけるネットワークへのフィードまで、すべてのステップを実行し、そのステップを完全に理解しました。 また、YOLOv5 のトレーニング中に直面する一般的な問題とその解決策についても調べました。 この記事が、カスタム データセットでの最初の YOLOv5 のトレーニングに役立ち、気に入っていただければ幸いです。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/02/how-to-train-a-custom-dataset-with-yolov5/
- 1
- 10
- a
- できる
- 上記の.
- 受け入れる
- 従った
- 精度
- 行動
- 後
- 先んじて
- AI
- すべて
- 既に
- 金額
- &
- 建築
- 周りに
- 記事
- 注意
- 自動的に
- 利用できます
- 避ける
- バック
- ベース
- 基本的に
- 以下
- より良いです
- ビット
- ボトム
- ボックス
- ボックス
- (Comma Separated Values) ボタンをクリックして、各々のジョブ実行の詳細(開始/停止時間、変数値など)のCSVファイルをダウンロードします。
- 注意深い
- 慎重に
- 場合
- CD
- センター
- 課題
- 変化する
- 変更
- 変化
- チェック
- 選ばれた
- class
- クラス
- 分類
- コード
- 来ます
- コメントアウト
- コマンドと
- コミュニティ
- 記入済みの
- 完成
- 複雑な
- 計算
- 紛らわしい
- 含まれています
- コンテンツ
- 変換
- 複写
- 作ります
- 作成した
- 作成
- 電流プローブ
- カスタム
- カスタム化
- カスタマイズ
- ダークネット
- データ
- データの準備
- データサイエンティスト
- 深いです
- 深い学習
- 定義する
- 依存
- 検出された
- 検出
- 対話
- 異なります
- 直接に
- ディレクトリ
- 発見する
- 異なる
- すること
- ドント
- ダウンロード
- ドライブ
- 各
- 簡単
- 教育します
- 効果的な
- 効果的に
- 効率的な
- 入力します
- 入力されました
- エポック
- エラー
- 等
- さらに
- あらゆる
- 正確に
- 例
- 運動
- 説明する
- 説明
- 説明
- export
- 並外れて
- 顔
- 直面して
- スピーディー
- 速いです
- FRBは
- 摂食
- 少数の
- File
- 最後に
- 名
- 初回
- フォーカス
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- フレームワーク
- から
- 楽しいです
- 取得する
- GitHubの
- 与える
- Go
- 行く
- 良い
- でログイン
- GPU
- 聞いた
- 助けます
- 助けました
- こちら
- 強調表示された
- 非常に
- ヒッティング
- 希望
- 認定条件
- How To
- HTTPS
- 巨大な
- アイデア
- 識別
- 識別する
- 画像
- 画像
- 実装
- 重要
- in
- 当初
- install
- を取得する必要がある者
- 相互作用
- インターネット
- 関係する
- IT
- 知っている
- 知識
- ラベル
- ラベル
- 大
- 大規模
- より大きい
- 層
- つながる
- LEARN
- 学んだ
- 学習
- ライブラリ
- ライセンス
- LINE
- LINK
- ローディング
- 見て
- 見
- LOOKS
- 製
- make
- 作成
- マークされた
- 一致
- 問題
- 最大幅
- 手段
- メソッド
- かもしれない
- 何百万
- マインド
- モデル
- 他には?
- 最も
- 名
- 名前付き
- 命名
- 必要
- 必要とされる
- ネットワーク
- ネットワーク
- 数
- オブジェクト
- オブジェクト検出
- ONE
- 最適化
- オプション
- 注文
- その他
- 自分の
- パッケージ
- パッケージ
- 部
- path
- 支払う
- のワークプ
- 実行する
- パフォーマンス
- 実行
- 実行する
- 場所
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 予測する
- 予測
- 準備中
- 前
- 前に
- 問題
- 問題
- プロセス
- プロジェクト
- 実績のある
- は、大阪で
- 目的
- パイトーチ
- 準備
- への
- 最近
- 推奨する
- 洗練された
- 削除します
- 倉庫
- 必要とする
- の提出が必要です
- 要件
- 結果として
- 結果
- ラン
- 同じ
- Save
- 節約
- 科学者
- 科学者たち
- 画面
- 役立つ
- シェル(Shell)
- すべき
- 表示する
- 示す
- 重要
- 同様の
- 簡単な拡張で
- 単に
- から
- So
- 溶液
- 一部
- 何か
- どこか
- split
- 積み上げ
- スタンド
- start
- 開始
- 手順
- ステップ
- 構造
- そのような
- 取る
- 仕事
- タスク
- テクノロジー
- 条件
- test
- アプリ環境に合わせて
- 徹底的に
- 介して
- 時間
- 時間がかかる
- 〜へ
- 一緒に
- top
- トレーニング
- 訓練された
- トレーニング
- 転送
- 転送
- チュートリアル
- 一般的に
- わかる
- 理解された
- つかいます
- 通常
- さまざまな
- 自動車
- バージョン
- ウェブサイト
- ウェブサイト
- ウィークス
- この試験は
- which
- while
- 広く
- 広範囲
- 意志
- 無し
- 仕事
- ワーキング
- でしょう
- 書きます
- 間違った
- ヤムル
- ヨロ
- あなたの
- ゼファーネット
- 〒