この投稿は、VMware Carbon Black の機械学習エンジニアである Mahima Agarwal とシニア エンジニアリング マネージャーである Deepak Mettem の共著です。
VMwareカーボンブラック は、最新のサイバー攻撃の全範囲に対する保護を提供する有名なセキュリティ ソリューションです。 製品によって生成された数テラバイトのデータを使用して、セキュリティ分析チームは機械学習 (ML) ソリューションの構築に注力し、重大な攻撃を表面化し、ノイズから新たな脅威にスポットライトを当てています。
VMware Carbon Black チームにとって、ML ライフサイクルのワークフローを調整および自動化し、モデルのトレーニング、評価、デプロイを可能にするエンド ツー エンドのカスタム MLOps パイプラインを設計および構築することが重要です。
このパイプラインを構築する主な目的は XNUMX つあります。後期段階のモデル開発のためにデータ サイエンティストをサポートすることと、大量かつリアルタイムの本番トラフィックでモデルを提供することにより、製品のモデル予測を表面化することです。 そのため、VMware Carbon Black と AWS は、カスタム MLOps パイプラインを構築することを選択しました。 アマゾンセージメーカー 使いやすさ、汎用性、完全に管理されたインフラストラクチャ。 以下を使用して、ML トレーニングとデプロイ パイプラインをオーケストレーションします。 ApacheAirflowのAmazonマネージドワークフロー (Amazon MWAA) により、自動スケーリングやインフラストラクチャのメンテナンスについて心配することなく、ワークフローとパイプラインをプログラムで作成することに集中できます。
このパイプラインにより、かつては Jupyter ノートブック主導の ML 研究であったものが、データ サイエンティストによる手作業による介入をほとんど必要とせずに、モデルを本番環境にデプロイする自動化されたプロセスになりました。 以前は、モデルのトレーニング、評価、デプロイのプロセスに XNUMX 日以上かかっていました。 この実装により、すべてがトリガーされるだけで、全体の時間が数分に短縮されました.
この投稿では、VMware Carbon Black と AWS のアーキテクトが、カスタム ML ワークフローをどのように構築および管理したかについて説明します。 Gitlab、Amazon MWAA、および SageMaker。 これまでに達成したこと、パイプラインのさらなる強化、およびその過程で学んだ教訓について説明します。
ソリューションの概要
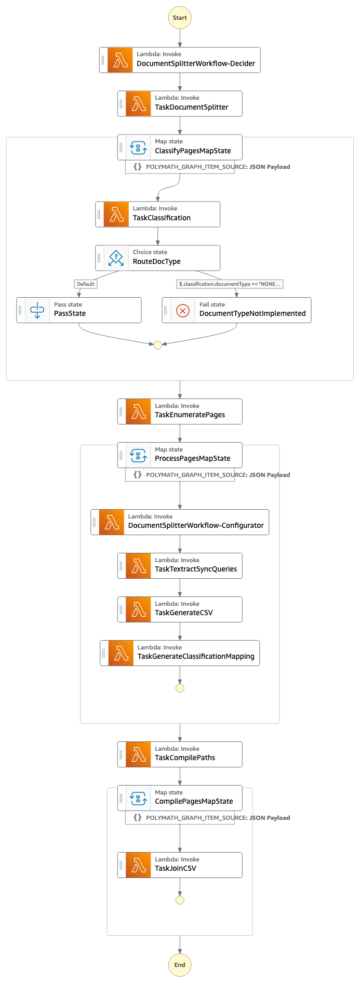
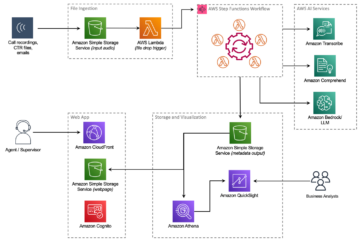
次の図は、ML プラットフォームのアーキテクチャを示しています。

高レベルのソリューション設計
この ML プラットフォームは、さまざまなコード リポジトリのさまざまなモデルで使用できるように想定され、設計されています。 私たちのチームは、GitLab をソース コード管理ツールとして使用して、すべてのコード リポジトリを維持しています。 モデル リポジトリ ソース コードの変更は、 Gitlab CI、パイプラインの後続のワークフロー (モデルのトレーニング、評価、デプロイ) を呼び出します。
次のアーキテクチャ図は、エンドツーエンドのワークフローと、MLOps パイプラインに含まれるコンポーネントを示しています。

エンドツーエンドのワークフロー
ML モデルのトレーニング、評価、デプロイのパイプラインは、Amazon MWAA を使用して調整されます。 有向無彩色グラフ (DAG)。 DAG は、実行方法を示す依存関係と関係で編成されたタスクの集まりです。
大まかに言うと、ソリューション アーキテクチャには次の XNUMX つの主要コンポーネントが含まれます。
- ML パイプライン コード リポジトリ
- ML モデルのトレーニングと評価のパイプライン
- ML モデルのデプロイ パイプライン
これらのさまざまなコンポーネントがどのように管理され、どのように相互作用するかについて説明します。
ML パイプライン コード リポジトリ
モデル リポジトリが MLOps リポジトリをダウンストリーム パイプラインとして統合し、データ サイエンティストがモデル リポジトリでコードをコミットした後、GitLab ランナーはそのリポジトリで定義された標準的なコード検証とテストを実行し、コードの変更に基づいて MLOps パイプラインをトリガーします。 Gitlab のマルチプロジェクト パイプラインを使用して、異なるリポジトリ間でこのトリガーを有効にします。
MLOps GitLab パイプラインは、特定の一連のステージを実行します。 pylint を使用して基本的なコード検証を行い、モデルのトレーニングと推論コードを Docker イメージ内にパッケージ化し、コンテナー イメージを Amazon エラスティック コンテナ レジストリ (アマゾン ECR)。 Amazon ECR は、高性能のホスティングを提供する完全マネージド型のコンテナ レジストリであるため、アプリケーション イメージとアーティファクトをどこにでも確実にデプロイできます。
ML モデルのトレーニングと評価のパイプライン
画像が公開されると、トレーニングと評価がトリガーされます ApacheAirflow を通るパイプライン AWSラムダ 関数。 Lambda は、サーバーをプロビジョニングまたは管理することなく、ほぼすべてのタイプのアプリケーションまたはバックエンド サービスのコードを実行できる、サーバーレスのイベント駆動型コンピューティング サービスです。
パイプラインが正常にトリガーされると、トレーニングと評価の DAG が実行され、SageMaker でモデルのトレーニングが開始されます。 このトレーニング パイプラインの最後に、識別されたユーザー グループは、トレーニングとモデル評価の結果を含む通知を電子メールで受け取ります。 Amazon シンプル通知サービス (Amazon SNS) と Slack。 Amazon SNS は、A2A および A2P メッセージング用のフルマネージド pub/sub サービスです。
評価結果を綿密に分析した後、データ サイエンティストまたは ML エンジニアは、新しくトレーニングされたモデルのパフォーマンスが以前のバージョンよりも優れている場合、新しいモデルをデプロイできます。 モデルのパフォーマンスは、モデル固有の指標 (F1 スコア、MSE、混同行列など) に基づいて評価されます。
ML モデルのデプロイ パイプライン
デプロイを開始するには、ユーザーは同じ Lambda 関数を介して Deployment DAG をトリガーする GitLab ジョブを開始します。 パイプラインが正常に実行されると、新しいモデルで SageMaker エンドポイントが作成または更新されます。 これにより、Amazon SNS と Slack を使用して、エンドポイントの詳細を含む通知も E メールで送信されます。
いずれかのパイプラインで障害が発生した場合、ユーザーは同じ通信チャネルを介して通知されます。
SageMaker は、低レイテンシーと高スループットの要件を持つ推論ワークロードに最適なリアルタイム推論を提供します。 これらのエンドポイントは、完全に管理され、負荷分散され、自動スケーリングされ、高可用性のために複数のアベイラビリティー ゾーンにデプロイできます。 私たちのパイプラインは、モデルが正常に実行された後に、そのようなモデルのエンドポイントを作成します。
次のセクションでは、さまざまなコンポーネントを展開し、詳細を掘り下げます。
GitLab: モデルのパッケージ化とパイプラインのトリガー
GitLab をコード リポジトリとして使用し、パイプラインでモデル コードをパッケージ化し、ダウンストリームの Airflow DAG をトリガーします。
マルチプロジェクト パイプライン
マルチプロジェクト GitLab パイプライン機能は、親パイプライン (アップストリーム) がモデル リポジトリであり、子パイプライン (ダウンストリーム) が MLOps リポジトリである場合に使用されます。 各リポジトリは .gitlab-ci.yml を維持し、上流のパイプラインで有効になっている次のコード ブロックは、下流の MLOps パイプラインをトリガーします。
アップストリーム パイプラインはモデル コードをダウンストリーム パイプラインに送信し、そこでパッケージ化と発行の CI ジョブがトリガーされます。 モデル コードをコンテナ化し、Amazon ECR に発行するためのコードは、MLOps パイプラインによって維持および管理されます。 ACCESS_TOKEN などの変数を送信します (以下で作成できます)。 設定, アクセス)、JOB_ID (アップストリーム アーティファクトにアクセスするため)、および $CI_PROJECT_ID (モデル リポジトリのプロジェクト ID) 変数を使用して、MLOps パイプラインがモデル コード ファイルにアクセスできるようにします。 とともに 仕事の成果物 Gitlab の機能を使用すると、ダウンストリーム リポジトリは、次のコマンドを使用してリモート アーティファクトにアクセスします。
モデル リポジトリは、それをトリガーするステージを拡張することで、同じリポジトリから複数のモデルのダウンストリーム パイプラインを使用できます。 拡張する GitLab のキーワード。これにより、異なるステージ間で同じ構成を再利用できます。
モデル イメージを Amazon ECR に発行した後、MLOps パイプラインは Lambda を使用して Amazon MWAA トレーニング パイプラインをトリガーします。 ユーザーの承認後、同じ Lambda 関数を使用して、モデルのデプロイ Amazon MWAA パイプラインもトリガーします。
セマンティック バージョニングと下流へのバージョンの受け渡し
ECR イメージと SageMaker モデルをバージョン管理するためのカスタムコードを開発しました。 MLOps パイプラインは、モデル コードがコンテナー化されるステージの一部としてイメージとモデルのセマンティック バージョニング ロジックを管理し、バージョンをアーティファクトとして後のステージに渡します。
再訓練
再トレーニングは ML ライフサイクルの重要な側面であるため、パイプラインの一部として再トレーニング機能を実装しました。 SageMaker list-models API を使用して、モデル再トレーニングのバージョン番号とタイムスタンプに基づいて再トレーニング中かどうかを識別します。
を使用して、再トレーニング パイプラインの毎日のスケジュールを管理します。 GitLab のスケジュール パイプライン.
Terraform: インフラストラクチャのセットアップ
Amazon MWAA クラスター、ECR リポジトリ、Lambda 関数、および SNS トピックに加えて、このソリューションは以下も使用します AWS IDおよびアクセス管理 (IAM) ロール、ユーザー、およびポリシー。 Amazon シンプル ストレージ サービス (Amazon S3) バケット、および アマゾンクラウドウォッチ ログフォワーダー。
パイプライン全体に含まれるサービスのインフラストラクチャのセットアップとメンテナンスを合理化するために、 テラフォーム インフラストラクチャをコードとして実装します。 インフラの更新が必要な場合はいつでも、コードの変更により、セットアップされた GitLab CI パイプラインがトリガーされます。これにより、変更が検証され、さまざまな環境にデプロイされます (たとえば、dev、stage、prod アカウントの IAM ポリシーにアクセス許可を追加します)。
Amazon ECR、Amazon S3、および Lambda: パイプラインの円滑化
パイプラインを促進するために、次の主要なサービスを使用します。
- アマゾンECR – モデル コンテナ イメージを維持し、便利に取得できるようにするために、セマンティック バージョンでタグ付けし、設定ごとに設定された ECR リポジトリにアップロードします。
${project_name}/${model_name}テラフォーム経由。 これにより、異なるモデル間の適切な分離レイヤーが可能になり、カスタム アルゴリズムを使用して、推論要求と応答をフォーマットして、必要なモデル マニフェスト情報 (モデル名、バージョン、トレーニング データ パスなど) を含めることができます。 - アマゾンS3 – S3 バケットを使用して、モデル トレーニング データ、モデルごとのトレーニング済みモデル アーティファクト、Airflow DAG、およびパイプラインに必要なその他の追加情報を保持します。
- ラムダ – Airflow クラスターはセキュリティを考慮して別の VPC にデプロイされているため、DAG に直接アクセスすることはできません。 したがって、DAG 名で指定されたすべての DAG をトリガーするために、同じく Terraform で維持される Lambda 関数を使用します。 適切な IAM セットアップにより、GitLab CI ジョブは Lambda 関数をトリガーし、構成を介して要求されたトレーニングまたはデプロイ DAG に渡されます。
Amazon MWAA: トレーニングとデプロイのパイプライン
前述のように、Amazon MWAA を使用して、トレーニングとデプロイのパイプラインを調整します。 で利用可能な SageMaker オペレーターを使用します。 Airflow 用の Amazon プロバイダー パッケージ SageMaker と統合するため (jinja テンプレートを避けるため)。
このトレーニング パイプラインでは、次の演算子を使用します (次のワークフロー図を参照)。

MWAA トレーニング パイプライン
デプロイ パイプラインでは次の演算子を使用します (次のワークフロー図を参照)。

モデル導入パイプライン
Slack と Amazon SNS を使用して、両方のパイプラインでエラー/成功メッセージと評価結果を発行します。 Slack には、メッセージをカスタマイズするための幅広いオプションが用意されています。
- SNSPublishOperator - を使用しております SNSPublishOperator 成功/失敗の通知をユーザーの電子メールに送信する
- スラック API – 私たちは 着信 Webhook URL 目的のチャネルへのパイプライン通知を取得する
CloudWatch と VMware Wavefront: モニタリングとロギング
CloudWatch ダッシュボードを使用して、エンドポイントの監視とログ記録を構成します。 各プロジェクトに固有のさまざまな運用およびモデルのパフォーマンス メトリックを視覚化して追跡するのに役立ちます。 それらの一部を追跡するために設定された Auto Scaling ポリシーに加えて、CPU とメモリの使用率、XNUMX 秒あたりのリクエスト、応答のレイテンシ、およびモデル メトリックの変化を継続的に監視します。
CloudWatch は VMware Tanzu Wavefront ダッシュボードと統合されているため、モデル エンドポイントやその他のサービスのメトリックをプロジェクト レベルで視覚化できます。
ビジネス上のメリットと今後の予定
ML パイプラインは、ML サービスと機能にとって非常に重要です。 この投稿では、AWS の機能を使用したエンドツーエンドの ML ユースケースについて説明しました。 プロジェクトやモデル全体で再利用できる SageMaker と Amazon MWAA を使用してカスタム パイプラインを構築し、ML ライフサイクルを自動化して、モデルのトレーニングから本番環境へのデプロイまでの時間をわずか 10 分に短縮しました。
ML ライフサイクルの負担が SageMaker に移行したことで、モデルのトレーニングとデプロイのための最適化されたスケーラブルなインフラストラクチャが提供されました。 SageMaker を使用したモデル提供は、ミリ秒のレイテンシーとモニタリング機能でリアルタイムの予測を行うのに役立ちました。 セットアップを容易にし、インフラストラクチャを管理するために、Terraform を使用しました。
このパイプラインの次のステップは、再トレーニング機能を使用してモデル トレーニング パイプラインを強化し、それがスケジュールされているかモデル ドリフト検出に基づいているかを問わず、シャドー デプロイまたは A/B テストをサポートして、より迅速で適切なモデル デプロイをサポートし、ML リネージ トラッキングを行うことです。 評価も予定しています AmazonSageMakerパイプライン GitLab 統合がサポートされるようになったためです。
教訓
このソリューションの構築の一環として、早期に一般化する必要があることを学びましたが、過度に一般化しないでください。 最初にアーキテクチャの設計を完了したとき、ベスト プラクティスとして、モデル コードのコード テンプレートを作成して適用しようとしました。 ただし、開発プロセスの初期段階であったため、テンプレートが一般化しすぎていたり、詳細すぎたりして、将来のモデルで再利用できませんでした。
パイプラインを通じて最初のモデルを提供した後、以前の作業からの洞察に基づいてテンプレートが自然に生まれました。 パイプラインは、初日からすべてを行うことはできません。
多くの場合、モデルの実験と製品化には、非常に異なる (場合によっては相反する) 要件があります。 チームとして最初からこれらの要件のバランスを取り、それに応じて優先順位を付けることが重要です。
さらに、サービスのすべての機能が必要なわけではありません。 サービスの重要な機能を使用し、モジュール化された設計を持つことは、より効率的な開発と柔軟なパイプラインの鍵です。
まとめ
この投稿では、SageMaker と Amazon MWAA を使用して MLOps ソリューションを構築した方法を紹介しました。このソリューションは、データ サイエンティストによる手作業による介入をほとんど必要とせずに、モデルを本番環境にデプロイするプロセスを自動化します。 完全な MLOps ソリューションを構築するために、SageMaker、Amazon MWAA、Amazon S3、Amazon ECR などのさまざまな AWS サービスを評価することをお勧めします。
※Apache、Apache Airflow、Airflow は、米国の登録商標または商標です。 Apache Software Foundation 米国および/または他の国で。
著者について
 ディーパック・メテム VMware のカーボン ブラック ユニットのシニア エンジニアリング マネージャーです。 彼と彼のチームは、顧客に機械学習ベースのソリューションをリアルタイムで提供するために、可用性が高く、スケーラブルで回復力のあるストリーミング ベースのアプリケーションとサービスの構築に取り組んでいます。 彼と彼のチームは、データ サイエンティストが本番環境で ML モデルを構築、トレーニング、デプロイ、検証するために必要なツールの作成も担当しています。
ディーパック・メテム VMware のカーボン ブラック ユニットのシニア エンジニアリング マネージャーです。 彼と彼のチームは、顧客に機械学習ベースのソリューションをリアルタイムで提供するために、可用性が高く、スケーラブルで回復力のあるストリーミング ベースのアプリケーションとサービスの構築に取り組んでいます。 彼と彼のチームは、データ サイエンティストが本番環境で ML モデルを構築、トレーニング、デプロイ、検証するために必要なツールの作成も担当しています。
 マヒマ・アガルワル VMware のカーボン ブラック ユニットの機械学習エンジニアです。
マヒマ・アガルワル VMware のカーボン ブラック ユニットの機械学習エンジニアです。
彼女は、VMware CB SBU の機械学習プラットフォームのコア コンポーネントとアーキテクチャの設計、構築、開発に取り組んでいます。
 ヴァムシ クリシュナ エナボタラ AWS の上級応用 AI スペシャリスト アーキテクトです。 彼は、さまざまなセクターの顧客と協力して、影響力の大きいデータ、分析、および機械学習のイニシアチブを加速させています。 AI と ML のレコメンデーション システム、NLP、コンピューター ビジョンの分野に情熱を注いでいます。 仕事以外では、Vamshi は RC 愛好家であり、RC 機器 (飛行機、車、ドローン) を組み立て、ガーデニングも楽しんでいます。
ヴァムシ クリシュナ エナボタラ AWS の上級応用 AI スペシャリスト アーキテクトです。 彼は、さまざまなセクターの顧客と協力して、影響力の大きいデータ、分析、および機械学習のイニシアチブを加速させています。 AI と ML のレコメンデーション システム、NLP、コンピューター ビジョンの分野に情熱を注いでいます。 仕事以外では、Vamshi は RC 愛好家であり、RC 機器 (飛行機、車、ドローン) を組み立て、ガーデニングも楽しんでいます。
 サヒル・タパール エンタープライズ ソリューション アーキテクトです。 彼はお客様と協力して、AWS クラウド上で高可用性、スケーラブル、および回復力のあるアプリケーションを構築できるよう支援しています。 彼は現在、コンテナーと機械学習ソリューションに重点を置いています。
サヒル・タパール エンタープライズ ソリューション アーキテクトです。 彼はお客様と協力して、AWS クラウド上で高可用性、スケーラブル、および回復力のあるアプリケーションを構築できるよう支援しています。 彼は現在、コンテナーと機械学習ソリューションに重点を置いています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/how-vmware-built-an-mlops-pipeline-from-scratch-using-gitlab-amazon-mwaa-and-amazon-sagemaker/
- :は
- $UP
- 1
- 10
- 100
- 7
- 8
- a
- 私たちについて
- 加速する
- アクセス
- アクセス
- それに応じて
- アカウント
- 達成
- 越えて
- 非周期的
- 添加
- NEW
- 追加情報
- 後
- に対して
- AI
- アルゴリズム
- すべて
- ことができます
- Amazon
- アマゾンセージメーカー
- 分析
- 分析論
- &
- どこにでも
- アパッチ
- API
- 申し込み
- 適用された
- 応用AI
- 承認
- 建築
- です
- エリア
- AS
- 側面
- At
- 攻撃
- オーサリング
- オート
- 自動化
- 自動化する
- 賃貸条件の詳細・契約費用のお見積り等について
- 利用できます
- 避ける
- AWS
- バックエンド
- ベース
- 基本
- BE
- なぜなら
- 開始
- 利点
- BEST
- より良いです
- の間に
- ブラック
- ブロック
- ブランチ
- 持って来る
- ビルド
- 建物
- 内蔵
- 負担
- by
- 缶
- 機能
- カーボン
- 自動車
- 場合
- CB
- 一定
- 変更
- チャンネル
- 子
- 選んだ
- クラウド
- クラスタ
- コード
- コレクション
- コミュニケーション
- 比べ
- コンプリート
- コンポーネント
- 計算
- コンピュータ
- Computer Vision
- 行動する
- 構成
- 相反する
- 混乱
- 検討事項
- 消費する
- 消費
- コンテナ
- コンテナ
- 連続的に
- 便利
- 基本
- 可能性
- 国
- CPU
- 作ります
- 作成した
- 作成します。
- 作成
- 重大な
- 重大な
- 現在
- カスタム
- Customers
- カスタマイズ
- サイバー攻撃
- DAG
- daily
- ダッシュボード
- データ
- データサイエンティスト
- 中
- 定義済みの
- 配信する
- 展開します
- 展開
- 展開する
- 展開
- 配備
- 配備する
- 設計
- 設計
- 設計
- 詳細な
- 細部
- 検出
- デベロッパー
- 発展した
- 開発
- 開発
- 異なります
- 直接に
- 話し合います
- 議論する
- デッカー
- ドント
- ダウン
- ドローン
- 各
- 前
- 早い
- 使いやすさ
- 効率的な
- どちら
- 新興の
- enable
- 使用可能
- 可能
- 奨励する
- 端から端まで
- エンドポイント
- エンジニア
- エンジニアリング
- Enterprise
- エンタープライズ・ソリューション
- 熱狂者
- 環境
- 装置
- 本質的な
- エーテル(ETH)
- 評価する
- 評価
- 評価します
- 評価
- 評価
- さらに
- イベント
- あらゆる
- すべてのもの
- 例
- 詳細
- 延伸
- f1
- 容易にする
- 不良解析
- 遠く
- 速いです
- 特徴
- 特徴
- 少数の
- 名
- フレキシブル
- フォーカス
- 焦点を当て
- 焦点を当てて
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- から
- フル
- フルスペクトル
- 完全に
- function
- 機能
- さらに
- 未来
- 生成された
- 取得する
- 良い
- グループ
- 持ってる
- 持って
- 助けます
- 助けました
- ことができます
- ハイ
- ハイパフォーマンス
- 非常に
- ホスティング
- 認定条件
- しかしながら
- HTML
- HTTP
- HTTPS
- IAM
- ID
- 理想
- 特定され
- 識別する
- アイデンティティ
- 画像
- 画像
- 実装する
- 実装
- 実装
- in
- include
- 含ま
- 含めて
- 情報
- インフラ
- イニシアチブ
- 洞察
- 統合する
- 統合された
- 統合する
- 統合
- 対話
- 介入
- 呼び出す
- 関係する
- 分離
- IT
- ITS
- ジョブ
- Jobs > Create New Job
- JPG
- キープ
- キー
- キー
- レイテンシ
- 層
- 学んだ
- 学習
- レッスン
- 教訓
- ことができます
- レベル
- wifecycwe
- ような
- 少し
- 負荷
- ロー
- 機械
- 機械学習
- メイン
- 維持する
- 維持
- メンテナンス
- make
- 管理します
- マネージド
- 管理
- マネージャー
- 管理する
- 管理する
- マニュアル
- マトリックス
- メモリ
- 言及した
- メッセージ
- メッセージング
- メトリック
- かもしれない
- ミリ秒
- 分
- ML
- MLOps
- モデル
- モダン
- モニター
- モニタリング
- 他には?
- もっと効率的
- の試合に
- 名
- 自然に
- 必要
- 必要
- 新作
- 次の
- NLP
- ノイズ
- 通知
- 通知
- 数
- of
- 提供すること
- オファー
- on
- ONE
- オペレーショナル
- 演算子
- 最適化
- オプション
- 調整された
- 整理
- その他
- 外側
- 全体
- パッケージ
- パッケージ
- 包装
- 部
- パス
- 通過
- 情熱的な
- path
- パフォーマンス
- 許可
- パイプライン
- 計画
- プレーン
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポリシー
- 方針
- ポスト
- 練習
- 予測
- 前
- 優先順位をつける
- プロセス
- プロダクト
- 生産
- プロジェクト
- プロジェクト(実績作品)
- 適切な
- 保護
- 提供
- プロバイダー
- は、大阪で
- パブリッシュ
- 公表
- パブリッシュ
- 出版
- 目的
- 修飾
- 範囲
- への
- おすすめ
- 電話代などの費用を削減
- 言及
- 登録された
- レジストリ
- の関係
- リモート
- 名高い
- 倉庫
- 要求されました
- リクエスト
- の提出が必要です
- 要件
- 研究
- 弾力性のあります
- 応答
- 責任
- 結果
- 再訓練
- 再利用可能な
- 役割
- ラン
- ランナー
- セージメーカー
- 同じ
- ド電源のデ
- スケーリング
- スケジュール
- 予定の
- 科学者
- 科学者たち
- 二番
- セクション
- セクター
- セキュリティ
- シニア
- 別
- サーバレス
- サーバー
- サービス
- サービス
- サービング
- セッションに
- 影
- シフト
- すべき
- 示す
- 簡単な拡張で
- スラック
- So
- これまでのところ
- ソフトウェア
- 溶液
- ソリューション
- 一部
- ソース
- ソースコード
- 専門家
- 特定の
- 指定の
- スペクトラム
- スポットライト
- ステージ
- ステージ
- 標準
- start
- 開始
- 米国
- ステップ
- ストレージ利用料
- 戦略
- ストリーミング
- 流線
- それに続きます
- 首尾よく
- そのような
- サポート
- サポート
- 表面
- システム
- TAG
- 取る
- タスク
- チーム
- テンプレート
- テラフォーム
- テスト
- それ
- アプリ環境に合わせて
- それら
- したがって、
- ボーマン
- 脅威
- 三
- 介して
- 全体
- スループット
- 時間
- タイムスタンプ
- 〜へ
- 一緒に
- あまりに
- ツール
- 豊富なツール群
- top
- トピック
- 追跡する
- 追跡
- 商標
- トラフィック
- トレーニング
- 訓練された
- トレーニング
- トリガー
- トリガ
- 順番
- 下
- 単位
- ユナイテッド
- 米国
- 更新版
- us
- 使用法
- つかいます
- 使用事例
- ユーザー
- users
- 検証
- variables
- さまざまな
- バージョン
- 事実上
- ビジョン
- 視覚化する
- ヴイエムウェア
- ボリューム
- 仕方..
- WELL
- この試験は
- かどうか
- which
- ワイド
- 広い範囲
- 以内
- 無し
- 仕事
- ワークフロー
- ワークフロー
- 作品
- でしょう
- ゼファーネット
- 〒
- ゾーン