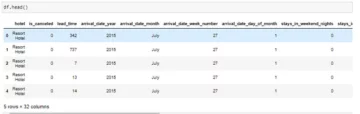
概要
監査データの世界は複雑で、克服すべき多くの課題があります。 最大の課題の XNUMX つは、データセットを処理しながらカテゴリ属性を処理することです。 この記事では、監査データ、異常検出、およびモデルに対するカテゴリ属性のエンコードの影響について詳しく説明します。
監査データの異常検出に関連する主な課題の XNUMX つは、カテゴリ属性の処理です。 モデルはテキスト入力を解釈できないため、カテゴリ属性のエンコードは必須です。 通常、これはラベル エンコーディングまたはワン ホット エンコーディングを使用して行われます。 ただし、大規模なデータセットでは、次元の呪いにより、ワンホット エンコーディングによってモデルのパフォーマンスが低下する可能性があります。
学習目標
-
監査データの概念と課題を理解する
- 深い教師なし異常検出のさまざまな方法を評価する。
- 監査データの異常検出に使用されるモデルに対するカテゴリ属性のエンコードの影響を理解する。
この記事は、の一部として公開されました データサイエンスブログソン.
目次
- アウタとは?
- 異常検出とは何ですか?
- データの監査中に直面する主な課題
- 異常検出のためのデータセットの監査
- カテゴリ属性のエンコード
- カテゴリーエンコーディング
- 教師なし異常検出モデル
- カテゴリ属性のエンコードはモデルにどのように影響しますか?
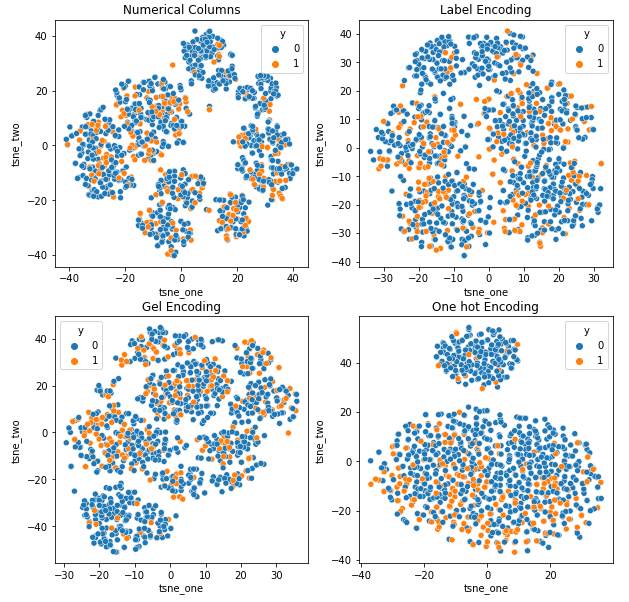
8.1 自動車保険データセットの t-SNE 表現
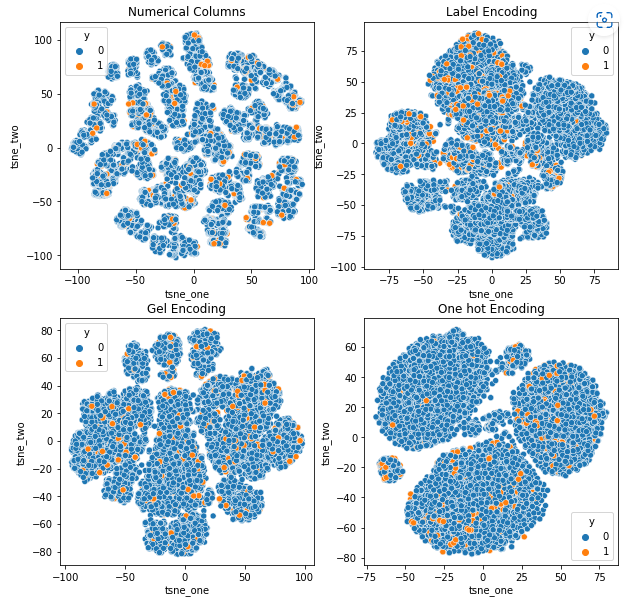
8.2 車両保険データセットの t-SNE 表現
8.3 Vehicle Claims データセットの t-SNE 表現 - まとめ
at は監査データですか?
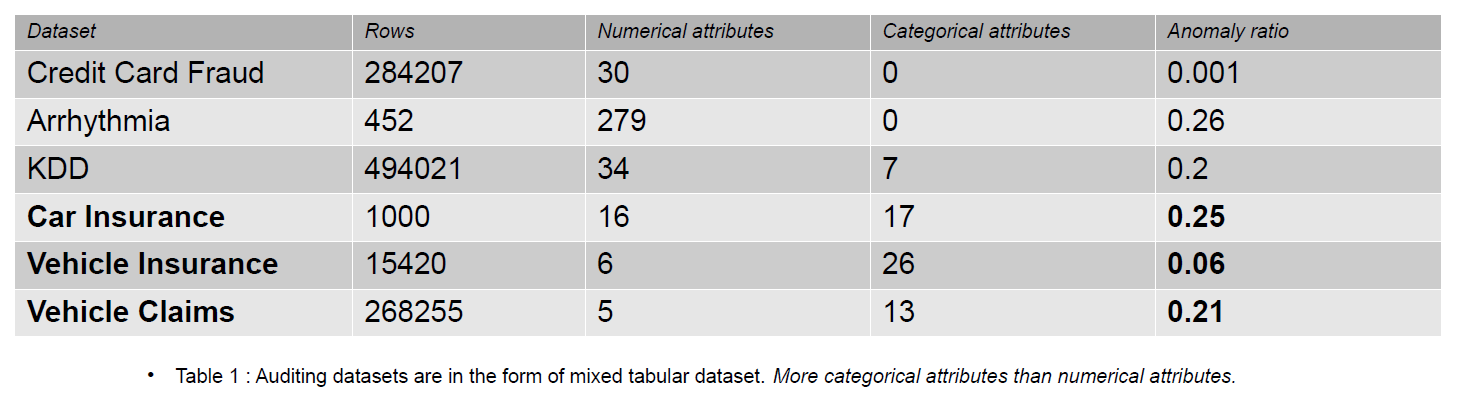
監査データには、ジャーナル、保険請求、および情報システムの侵入データを含めることができます。 この記事では、提供される例は車両の保険金請求です。 保険金請求は、多数のカテゴリ特徴によって、KDD などの異常検出データセットと区別できます。
カテゴリ機能は、整数型または文字型のいずれかであるデータ内の離散です。 数値特徴は、常に実数値であるデータ内の連続属性です。 数値特徴を持つデータセットは、クレジット カード詐欺データなどの異常検出コミュニティで人気があります。 公開されているほとんどのデータセットには、保険金請求データよりも少ないカテゴリ特徴が含まれています。 保険金請求データセットでは、カテゴリ特徴は数値特徴よりも多くなっています。
保険請求には、モデル、ブランド、収入、費用、問題、色などの特徴が含まれます。カテゴリ特徴の数は、クレジット カードおよび KDD データセットよりも監査データの方が多くなります。 これらのデータセットは、教師なし異常検出方法のベンチマークです。 次の表に示すように、保険金請求データセットには、不正なデータの動作を理解するために重要な、よりカテゴリ的な特徴があります。
カテゴリ エンコーディングの影響を評価するために使用される監査データセットは、自動車保険、車両保険、および車両請求です。
異常検出とは何ですか?
異常とは、データセット内の通常のデータから特定の距離 (しきい値) 離れた位置にある観測値です。 データの監査に関しては、不正なデータという用語を好みます。 異常検出では、機械学習またはディープ ラーニング モデルを使用して、正常なデータと不正なデータを区別します。 さまざまな方法 密度推定、再構成エラー、分類方法などの異常検出に使用できます。
- 密度推定 – これらの方法は、正規データ分布を推定し、学習した分布からサンプリングされていない場合は異常データを分類します。
- 再構築エラー – 再構築エラーベースの方法は、正常なデータは異常なデータよりも少ない損失で再構築できるという原則に基づいています。 再構築の損失が大きいほど、データが異常である可能性が高くなります。
- 分類方法 – のような分類方法 ランダムフォレスト、Isolation Forest、One Class – Support Vector Machines、および Local Outlier Factors を異常検出に使用できます。 異常検出における分類には、クラスの 0 つを異常として識別することが含まれます。 それでも、クラスは複数クラスのシナリオで 1 つのグループ (XNUMX と XNUMX) に分割され、データが少ないクラスが異常クラスです。
上記のメソッドの出力は、異常スコアまたは再構築エラーです。 次に、異常なデータを分類するしきい値を決定する必要があります。
データの監査中に直面する主な課題
- カテゴリ属性の処理: モデルはテキスト入力を解釈できないため、カテゴリ属性のエンコードは必須です。 そのため、値は Label エンコーディングまたは One Hot エンコーディングでエンコードされます。 しかし、大規模なデータセットでは、One hot encoding は属性の数を増やすことでデータを高次元空間に変換します。 次の理由により、モデルのパフォーマンスが低下します。 次元の呪い.
- 分類のしきい値の選択: データがラベル付けされていない場合、データセットに存在する異常の数がわからないため、モデルのパフォーマンスを評価することは困難です。 データセットに関する事前知識により、しきい値の決定が容易になります。 データに 5 個の異常なサンプルのうち 10 個があるとします。 したがって、50 パーセンタイル スコアでしきい値を選択できます。
- 公開データセット: ほとんどの監査データセットは企業に属し、機密情報や個人情報が含まれているため、機密です。 機密性の問題を軽減する XNUMX つの可能な方法は、合成データセット (Vehicle Claims) を使用してトレーニングすることです。
異常検出のためのデータセットの監査
車両の保険請求には、モデル、ブランド、価格、年式、燃料の種類など、車両の特性に関する情報が含まれます。 ドライバー、生年月日、性別、職業に関する情報が含まれます。 さらに、クレームには、修理の総費用に関する情報が含まれる場合があります。 この記事で使用するデータセットはすべて XNUMX つのドメインのものですが、属性の数とインスタンスの数は異なります。
-
Vehicle Claims データセットは大規模で、250,000 行以上を含み、そのカテゴリ属性のカーディナリティは 1171 です。サイズが大きいため、このデータセットは次元の呪いに悩まされています。
- Vehicle Insurance データセットは中規模で、15,420 行と 151 の一意のカテゴリ値があります。 これにより、次元の呪いに苦しむ可能性が低くなります。
- 自動車保険のデータセットは小さく、ラベルと 25% の異常なサンプルがあり、同様の数の数値およびカテゴリの特徴が含まれています。 169 の独自のカテゴリがあるため、次元の呪いに悩まされることはありません。
カテゴリ属性のエンコード
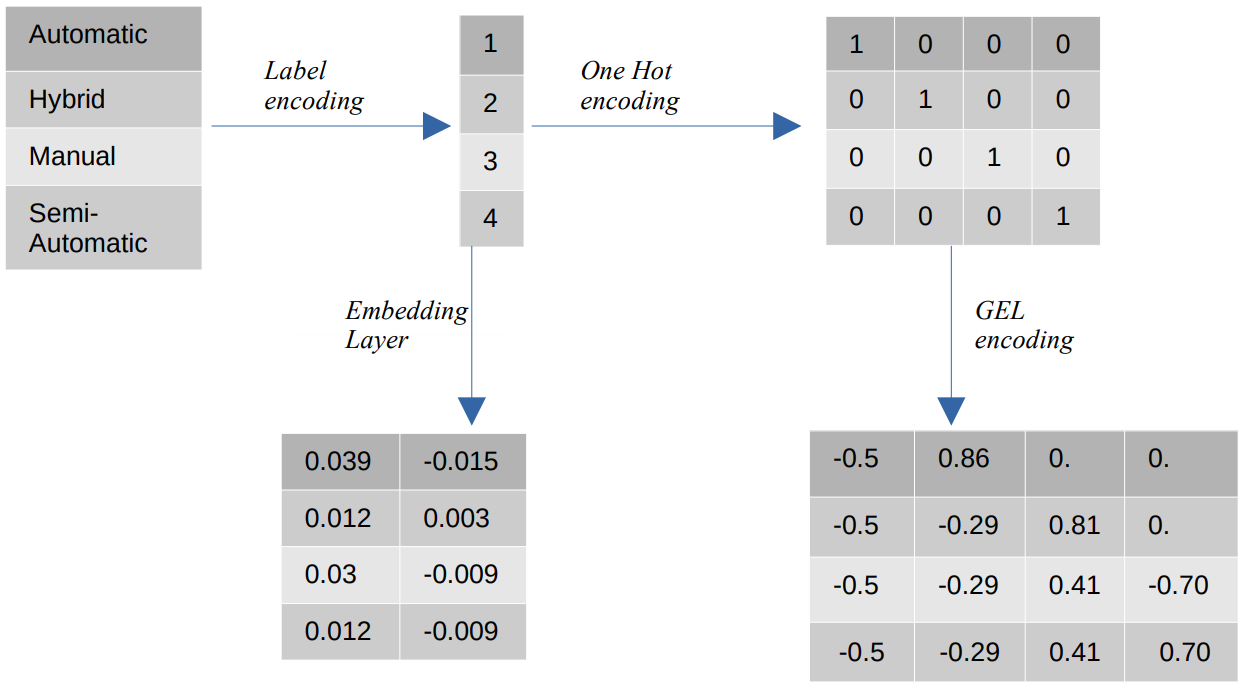
カテゴリ値のさまざまなエンコーディング
- ラベルのエンコード – ラベルのエンコードでは、カテゴリ値は 1 からカテゴリ数までの整数値に置き換えられます。 ラベル エンコーディングは、序数の値に対して意図された方法でカテゴリを表します。 それでも、特徴が名目である場合、カテゴリ値が特定の順序に準拠していないため、表現は正しくありません。
たとえば、フィーチャに自動、ハイブリッド、手動、半自動などのカテゴリがある場合、ラベル エンコーディングはこれらの値を {1: 自動、2: ハイブリッド、3: 手動、4: 半自動} に変換します。 この表現はカテゴリ値に関する情報を提供しませんが、{0: 低、1: 中、2: 高} などの表現は、特徴変数 Low に低い数値が割り当てられるため、明確な表現を提供します。 したがって、ラベルのエンコードは順序値には適していますが、公称値には不利です。 - ワンホットエンコーディング – ワン ホット エンコーディングは、各カテゴリ値をバイナリ値で構成されるデータセット内の個別の特徴に変換する公称エンコーディング値の問題に対処するために使用されます。 たとえば、{1, 2, 3, 4} としてエンコードされた 1,0,0,0 つの異なるカテゴリの場合、One Hot エンコーディングは {自動: [0,1,0,0]、ハイブリッド: [0,0,1,0] などの新しい機能を作成します。 ,0,0,0,1]、手動: [XNUMX]、半自動: [XNUMX]}。
データセットの次元は、データセットに存在するカテゴリの数に直接依存します。 その結果、One Hot エンコーディングは、このエンコーディング方法の欠点である次元の呪いにつながる可能性があります。 - GEL エンコーディング – GEL エンコーディングは、教師ありおよび教師なしの学習方法で使用できる埋め込み技術です。 これは、ワン ホット エンコーディングの原理に基づいており、ワン ホット エンコーディングを使用してエンコードされたカテゴリ特徴の次元を減らすために使用できます。
- 埋め込みレイヤー – 単語の埋め込みは、類似の単語が類似のエンコーディングを持つコンパクトで密な表現を使用する方法を提供します。 埋め込みは、トレーニング可能なパラメーターである浮動小数点値の密なベクトルです。 単語の埋め込みは、8 次元 (小規模なデータセットの場合) から 1024 次元 (大規模なデータセットの場合) までさまざまです。
高次元の埋め込みでは、単語間のより詳細な関係を捉えることができますが、学習にはより多くのデータが必要です。 埋め込みレイヤーは、マトリックスに存在する各単語を特定のサイズのベクトルに変換するルックアップ テーブルです。
教師なし異常検出モデル
現実の世界では、ほとんどの場合、データはラベル付けされておらず、データのラベル付けには費用と時間がかかります。 したがって、評価には教師なしモデルを使用します。
- SOM – 自己組織化マップ (SOM) は、バックプロパゲーション学習を使用するのではなく、ニューロンの重みが競合的に更新される競合学習方法です。 SOM はニューロンのマップで構成され、それぞれが入力ベクトルと同じサイズの重みベクトルを持ちます。 トレーニングを開始する前に、重みベクトルはランダムな重みで初期化されます。 トレーニング中、各入力は距離メトリック (ユークリッド距離など) に基づいてマップのニューロンと比較され、入力ベクトルまでの距離が最小のニューロンであるベスト マッチング ユニット (BMU) にマッピングされます。
BMU の重みは入力ベクトルの重みで更新され、近隣のニューロンは近傍半径 (シグマ) に基づいて更新されます。 ニューロンは互いに競合して最適なユニットになるため、このプロセスは競合学習として知られています。 最終的に、正常なサンプルのニューロンは、異常なサンプルよりも近くにあります。 異常スコアは、量子化誤差によって定義されます。量子化誤差は、入力サンプルと最適一致ユニットの重みの差です。 量子化誤差が大きいほど、サンプルが異常である可能性が高くなります。 - DAGMM – Deep Autoencoding Gaussian Mixture Model (DAGMM) は、異常が低確率領域にあると仮定する密度推定方法です。 ネットワークは、オートエンコーダーを使用してデータを低次元に射影するために使用される圧縮ネットワークと、ガウス混合モデルのパラメーターを推定するために使用される推定ネットワークの 1 つの部分に分割されます。 DAGMM は k 個のガウス混合を推定します。ここで、k は XNUMX から N (データ ポイントの数) までの任意の数であり、法線ポイントは高密度領域にあると想定されます。ガウス混合は、異常なサンプルよりも正常なポイントの方が高くなります。 異常スコアは、サンプルの推定エネルギーによって定義されます。
- RSRAE – 教師なし異常検出のためのロバスト サーフェス リカバリ レイヤーは、オートエンコーダーを使用して最初にデータをより低い次元に投影する再構成エラー方法です。 次に、潜在表現は、外れ値に対してロバストな線形部分空間への正射影を受けます。 次に、デコーダは線形部分空間から出力を再構築します。 この方法では、再構成誤差が大きいほど、サンプルが異常である確率が高いことを示します。
- ソム-ダグム- 自己組織化マップ (SOM) – Deep Autoencoding Gaussian Mixture Model (DAGMM) も密度推定モデルです。 DAGMM と同様に、正常なデータ ポイントの確率分布も推定し、学習した分布からサンプリングされる確率が低いデータ ポイントを異常として分類します。 SOM-DAGMM と DAGMM の主な違いは、SOM-DAGMM には入力サンプルの SOM の正規化された座標が含まれていることです。これにより、DAGMM の場合に不足しているトポロジ情報が推定ネットワークに提供されます。 この目的は、異常スコアがサンプルの推定エネルギーによって定義されるという点でも DAGMM に似ています。低エネルギーは、サンプルが異常である可能性が高いことを示します。
次に、カテゴリ属性を処理するという課題に取り組みます。
カテゴリ属性のエンコードはモデルにどのように影響しますか?
データセットに対するさまざまなエンコーディングの影響を理解するために、t-SNE を使用して、さまざまなエンコーディングのデータの低次元表現を視覚化します。 t-SNE は、高次元データを低次元空間に射影し、視覚化を容易にします。 同じデータセットの異なるエンコーディングの t-SNE 視覚化と数値結果を比較することにより、結果の表現とデータセットに対するエンコーディングの影響の理解に違いが見られます。
自動車保険データセットの t-SNE 表現
車両保険データセットの t-SNE 表現
-
行数が自動車保険データセットよりも多いため、データは互いに接近しています。 ワンホット符号化では次元数が増えると分離が難しくなります。
-
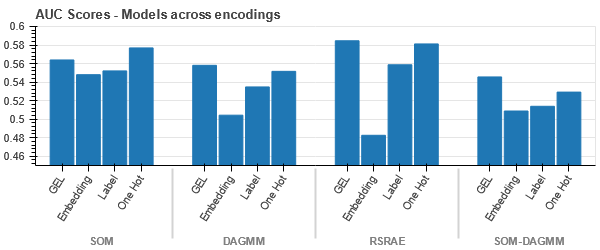
GEL エンコーディングは、DAGMM を除くすべてのケースで One Hot エンコーディングより優れています。
Vehicle Claims データセットの t-SNE 表現
-
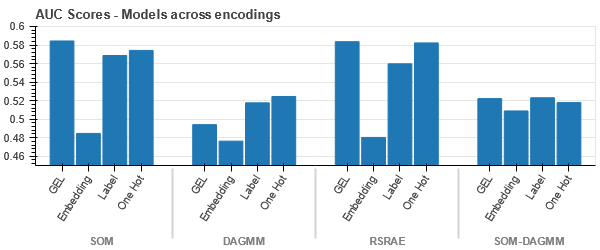
どのような場合でも、データは厳密にバインドされているため、次元が高くなると分離が難しくなります。 これは、次元の増加によりモデルのパフォーマンスが低下する理由の XNUMX つです。
- SOM は、このデータセットの他のすべてのモデルよりも優れています。 それでも、ほとんどの場合、埋め込みレイヤーの方が適しているため、エンコードの代わりに使用できます カテゴリ属性 異常検出用。
まとめ
この記事では、監査データ、異常検出、およびカテゴリ エンコーディングの概要を簡単に説明します。 監査データでカテゴリ属性を処理するのは難しいことを理解することが重要です。 属性のエンコードがモデルに与える影響を理解することで、データセットの異常検出の精度を向上させることができます。 この記事の主なポイントは次のとおりです。
- One Hot エンコーディングは不適切であるため、データのサイズが大きくなるにつれて、GEL エンコーディングや埋め込みレイヤーなど、カテゴリ属性に別のエンコーディング アプローチを使用することが重要になります。
- XNUMX つのモデルがすべてのデータセットで機能するわけではありません。 表形式のデータセットの場合、ドメインの知識は非常に重要です。
- エンコーディング方法の選択は、モデルの選択に依存します。
モデルの評価用のコードは、次のサイトで入手できます。 GitHubの.
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/01/impact-of-categorical-encodings-on-anomaly-detection-methods/
- 000
- 1
- 10
- 420
- a
- 私たちについて
- 上記の.
- 従った
- 精度
- さらに
- 住所
- すべて
- ことができます
- 代替案
- 常に
- 分析論
- 分析Vidhya
- &
- 異常検出
- アプローチ
- 記事
- 割り当てられた
- 関連する
- 想定される
- 属性
- 監査
- オートマチック
- 利用できます
- ベース
- なぜなら
- になる
- さ
- 以下
- ベンチマーク
- BEST
- より良いです
- の間に
- 最大の
- 結合した
- ブランド
- キャプチャー
- 自動車
- 自動車保険
- カード
- 場合
- 例
- カテゴリ
- 挑戦する
- 課題
- 挑戦
- チャンス
- 文字
- 選択
- クレーム
- クレーム
- class
- クラス
- 分類
- 分類します
- クリア
- クローザー
- コード
- カラー
- 一般に
- コミュニティ
- 企業
- 比べ
- 比較
- 競争する
- 競争力のある
- 複雑な
- コンセプト
- 秘密
- からなる
- 含まれています
- 連続的な
- 企業
- 費用
- 作ります
- クレジット
- クレジットカード
- データ
- データポイント
- データセット
- 日付
- 取引
- 減少
- 深いです
- 深い学習
- 依存
- 詳細な
- 検出
- 決定する
- 違い
- 異なります
- 難しい
- 次元
- 大きさ
- 直接に
- 裁量
- 距離
- 明確な
- ディストリビューション
- 分割された
- ドメイン
- ドライバー
- 間に
- 各
- 容易
- どちら
- エネルギー
- エラー
- エラー
- 推定
- 推定
- 見積もり
- 等
- 評価する
- 評価
- 評価
- 例
- 例
- 除く
- 高価な
- 非常に
- 直面して
- 要因
- 特徴
- 特徴
- 名
- 森林
- 詐欺
- 不正な
- から
- ガソリンタンク
- 性別
- グループの
- ハンドリング
- ハイ
- より高い
- HOT
- しかしながら
- HTTPS
- ハイブリッド
- 識別
- 影響
- 重要
- 改善します
- in
- include
- 含ま
- 所得
- 増加した
- 増加
- の増加
- を示し
- 情報
- 情報機器
- 保険
- 分離
- 問題
- 問題
- IT
- キー
- 知っている
- 知識
- 既知の
- ラベル
- ラベリング
- ラベル
- 大
- より大きい
- 層
- 層
- つながる
- LEARN
- 学んだ
- 学習
- ローカル
- 位置して
- 検索
- 損失
- 損失
- ロー
- 機械
- 機械学習
- マシン
- メイン
- 作る
- 作成
- 義務的な
- マニュアル
- 多くの
- 地図
- マッチング
- マトリックス
- 意味
- メディア
- ミディアム
- 方法
- メソッド
- メトリック
- 最小
- 行方不明
- 軽減する
- 混合
- モデル
- 他には?
- 最も
- ネットワーク
- ニューロン
- 新作
- 新しい特徴
- 通常の
- 数
- 客観
- ONE
- 注文
- その他
- 優れた性能
- 克服する
- 概要
- 所有している
- パラメータ
- 部
- 部品
- パフォーマンス
- 実行する
- 個人的な
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- ポイント
- 貧しいです
- 人気
- 可能
- 好む
- 現在
- プレゼント
- ブランド
- 原則
- 事前の
- 確率
- 問題
- プロセス
- 職業
- プロジェクト
- プロジェクトデータ
- 投影
- プロジェクト(実績作品)
- プロパティ
- 提供します
- 提供
- は、大阪で
- 公表
- ランダム
- 範囲
- リアル
- 現実の世界
- 理由は
- 回復
- 地域
- の関係
- 修理
- 置き換え
- 表現
- 表し
- 必要
- 結果
- 結果として
- 結果
- 堅牢な
- 同じ
- 科学
- 敏感な
- 別
- 示す
- シグマ
- 同様の
- から
- サイズ
- 小さい
- より小さい
- So
- スペース
- 特定の
- 開始
- まだ
- そのような
- 苦しみ
- 適当
- サポート
- 表面
- 合成
- システム
- テーブル
- まとめ
- 条件
- 世界
- したがって、
- しきい値
- しっかり
- 時間がかかる
- 〜へ
- トータル
- トレーニング
- トレーニング
- わかる
- 理解する
- ユニーク
- 単位
- 教師なし学習
- 更新しました
- us
- つかいます
- 値
- 価値観
- 自動車
- 車
- 重量
- この試験は
- 何ですか
- which
- while
- 意志
- Word
- 言葉
- 仕事
- 世界
- でしょう
- 年
- ゼファーネット