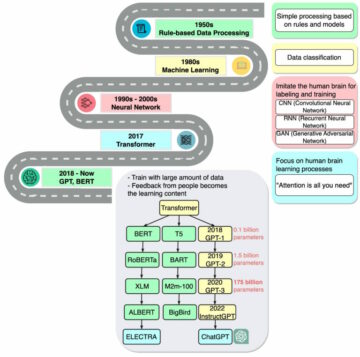
Pythonを使用したNLPの基本概念から高度な概念までをすべて説明する一連の記事を書くことにしました。 したがって、NLPを読んでコーディングすることで学習したい場合、これはあなたにとって完璧な一連の記事になります。
NLPの新規またはゼロの人は誰でも私たちから始めて、この一連の記事に従うことができます。
使用したライブラリ:Keras、Tensorflow、Scikit learn、NLTK、Gloveなど。
すべてのトピックは、Pythonのコードと、sci-kit learn、Keras、TensorFlowなどの一般的なディープラーニングと機械学習のフレームワークを使用して説明されます。
NLPとは何ですか?
自然言語処理は、コンピュータが人と同じように自然に言語を理解できるようにするコンピュータサイエンスの一部です。 これは、ラップトップが感情、スピーチ、質問への回答、テキストの要約などを理解することを意味します。その歴史と進化についてはあまり話しません。 あなたが興味を持っているなら、これを好む リンクをクリックします。
Step1データクリーニング
生のテキストデータは、さまざまなソースがクリーンアップされていない直後に取得されます。 データをクリーンにするために複数の手順を適用します。 クリーンアップされていないテキストデータには、結果を逸脱する役に立たない情報が含まれているため、データをクリーンアップするための最初のステップは常にそれです。 データをよりクリーンにするために、いくつかの標準的な前処理技術を適用する必要があります。 クリーンアップされたデータは、モデルの過剰適合も防ぎます。
この記事では、テキスト処理と探索的データ分析の下で次のトピックを取り上げます。
生のテキストデータをパンダのデータフレームに変換し、さまざまなデータクリーニング手法を実行しています。
import pandas as pd text = ['これは、ABhishek Jaiswal** によって書かれた NLP タスクの記事です ','この記事では、さまざまなデータ クリーニング テクニックについて説明します', 'さらなる詳細にご期待ください &&','Nah彼は USF には行かないと思います。彼はその辺に住んでいます'] df = pd.DataFrame({'text':text})
出力:

小文字
方法 lower()すべて大文字を小文字に変換して返します。
適用 lower() ラムダ関数を使用するメソッド
df ['lower'] = df ['text']。apply(lambda x: "" .join(x.lower()for x in x.split()))

句読点の削除
句読点の削除(*,&,%#@#())は重要なステップです。句読点はデータに追加の情報や価値を追加しないためです。 したがって、句読点を削除すると、データサイズが小さくなります。 したがって、計算効率が向上します。
この手順は、正規表現または置換メソッドを使用して実行できます。

string.punctuation すべての句読点を含む文字列を返します。

句読点の削除 正規表現:

単語の削除を停止します
文中に頻繁に出現し、文に重要な意味を持たない単語。 これらは予測にとって重要ではないため、ストップワードを削除してデータサイズを削減し、過剰適合を防ぎます。 注:ストップワードは小文字であるため、ストップワードをフィルタリングする前に、必ずデータを小文字にしてください。
NLTKライブラリを使用して、データセットからストップワードを除外できます。
# !pip install nltk import nltk nltk.download('stopwords') from nltk.corpus import stopwords allstopwords = stopwords.words('english') df. lower.apply(lambda x: " ".join(i for i in x) allstopwords にない場合は .split()))

スペル修正
カスタマーレビュー、ブログ、またはツイートで抽出されたテキストデータのほとんどは、スペルミスの可能性があります。
スペルミスを修正すると、モデルの精度が向上します。
スペルミスを修正するためのさまざまなライブラリがありますが、最も便利な方法はテキストブロブを使用することです。
方法 correct() テキストブロブオブジェクトで動作し、スペルミスを修正します。
#install textblobライブラリ!pip install textblob from textblob import TextBlob

トークン化
トークン化とは、テキストを意味のある単位単語に分割することを意味します。 文のトークナイザーと単語のトークナイザーがあります。
文のトークナイザーは段落を意味のある文に分割し、単語のトークナイザーは文を単位の意味のある単語に分割します。 SpaCy、NLTK、TextBlobなどの多くのライブラリはトークン化を実行できます。
個々の単位単語を取得するためにスペースで文を分割することは、トークン化として理解できます。
import nltk mystring = "私の好きな動物は猫です" nltk.word_tokenize(mystring)
mystring.split( "")
出力:
['My'、 'favorite'、 'animal'、 'is'、 'cat']
ステミング
ステミングとは、意味に関係なく、いくつかのルールセットを使用して単語をルート単語に変換することです。 つまり、
- 「魚」、「魚」、「釣り」は「魚」に分類されます。
- 「遊ぶ」、「遊ぶ」、「遊ぶ」は「遊ぶ」に由来します。
- ステミングは語彙を減らし、精度を向上させるのに役立ちます。
ステミングを実行する最も簡単な方法は、NLTKまたはTextBlobライブラリを使用することです。
NLTKは、Snowball、PorterStemmerなどのさまざまなステミング技術を提供します。 さまざまな手法がさまざまなルールのセットに従って、単語をルート単語に変換します。
nltk.stem から nltk をインポート import PorterStemmer st = PorterStemmer() df['text'].apply(lambda x:" ".join([st.stem(word) for word in x.split()]))

「記事」は「articl"、"lives「->」live"
レンマ化
Lemmatizationは、語彙マッピングを使用して単語をルート単語に変換します。 Lemmatizationは、品詞とその意味の助けを借りて行われます。 したがって、意味のないルートワードは生成されません。 しかし、レンマ化はステミングよりも遅いです。
- 「良い、 ""優れた、 "または"最良」は「良い"
- Lemmatizationは、すべての同義語を単一のルートワードに変換します。 すなわち「自動車"、"自動車"、" トラック"、" 車両」は「自動車」にレンマ化されます。
- 通常、レマタイゼーションはより良い結果をもたらします。
つまり。 leafs に茎。 に茎の葉 leav while leafs , leaves にlemmatized leaf
Lemmatizationは、NLTK、TextBlobライブラリを使用して実行できます。

データセット全体をレマタイズします。

ステップ2探索的データ分析
これまで、生データを取得した後に実行する必要のあるさまざまなテキスト前処理手法を見てきました。 データをクリーンアップした後、探索的データ分析を実行し、テキストデータを探索して理解できるようになりました。
データ内の単語の頻度
データ内の一意の単語を数えることで、データの最も頻度の高い、最も頻度の低い用語についてのアイデアが得られます。 モデルトレーニングをより一般化するために、最も頻度の低いコメントを削除することがよくあります。
nltk は、大阪で Freq_dist 単語の頻度を計算するクラスであり、入力として単語のバッグを取ります。
all_words = [] df['processed'] の文: all_words.extend(sentence.split())
all_words データセットで使用可能なすべての単語が含まれています。 私たちはしばしばそれを語彙と呼びます。
import nltk nltk.Freq_dist(all_words)

これにより、単語がキーとして表示され、データ内の出現回数が値として表示されます。
ワードクラウド
Wordcloudは、データセットの単語頻度を図で表したものです。WordCloudは理解しやすく、テキストデータに関するより良いアイデアを提供します。
ライブラリ wordcloud 数行のコードでワードクラウドを作成しましょう。
ライブラリのインポート:
from wordcloud import WordCloud from wordcloud import STOPWORDS import matplotlib.pyplot as plt
データのすべての単語を含むテキストを使用して、単語の雲を描くことができます。
Words = [] df['processed'] のメッセージの場合:words.extend([単語が STOPWORDS にない場合は message.split() の単語ごと]) wordcloud = WordCloud(幅 = 1000, 高さ = 500).generate( " ".join(words)) plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.show()

background_color = 'white'このパラメータを使用して、ワードクラウドの背景色を変更できます。collocations = FalseFalseのままにしておくと、コロケーションワードは無視されます。 コロケーションは、一緒に発生する単語によって形成される単語です。 つまり、注意を払う、家事など。- パラメータを使用して高さと幅を調整できます。
Note :ワードクラウドを作成する前に、必ずストップワードを削除してください。
エンドノート
この記事では、テキストデータの前処理に必要なさまざまな手法について説明しました。 データクリーニング後、ワードクラウドを使用して探索的データ分析を実行し、ワード頻度を作成しました。
このシリーズのXNUMX番目の記事では、次のトピックについて学習します。
出典:https://www.analyticsvidhya.com/blog/2022/01/nlp-tutorials-part-i-from-basics-to-advance/
- "
- &
- 私たちについて
- すべて
- 分析
- 周りに
- 記事
- 物品
- 利用できます
- 言葉の袋
- の基礎
- ブログ
- コール
- チャンス
- 変化する
- クリーニング
- クラウド
- コード
- コーディング
- 注釈
- コンピュータサイエンス
- コンピューター
- データ
- データ分析
- 深い学習
- 異なります
- そうではありません
- Drop
- 効率
- 英語
- 等
- 進化
- 名
- 修正する
- 生成する
- 受け
- 助けます
- ことができます
- history
- ホーム
- HTTPS
- アイデア
- 重要
- 改善
- 個人
- 情報
- IT
- 保管
- keras
- キー
- 言語
- ノートパソコン
- LEARN
- 学習
- レンマ化
- 図書館
- 機械学習
- 作成
- ミディアム
- 他には?
- NLP
- 支払う
- 人気
- 予測
- は、大阪で
- Python
- Raw
- 生データ
- リーディング
- 減らします
- replace
- 結果
- 収益
- レビュー
- ルール
- 科学
- シリーズ
- セッションに
- サイズ
- So
- スペース
- start
- 滞在
- ステム
- 会話
- テクニック
- テンソルフロー
- 一緒に
- トークン化
- トピック
- トレーニング
- チュートリアル
- us
- 通常
- 値
- 言葉
- 作品
- X
- ゼロ