著者による画像
並列処理では、タスクをサブユニットに分割します。 プログラムによって処理されるジョブの数が増え、全体的な処理時間が短縮されます。
たとえば、大きなCSVファイルを使用していて、単一の列を変更する場合です。 データを配列として関数にフィードし、使用可能な数に基づいて一度に複数の値を並列処理します 労働者。 これらのワーカーは、プロセッサ内のコアの数に基づいています。
注: 小さいデータセットで並列処理を使用しても、処理時間は改善されません。
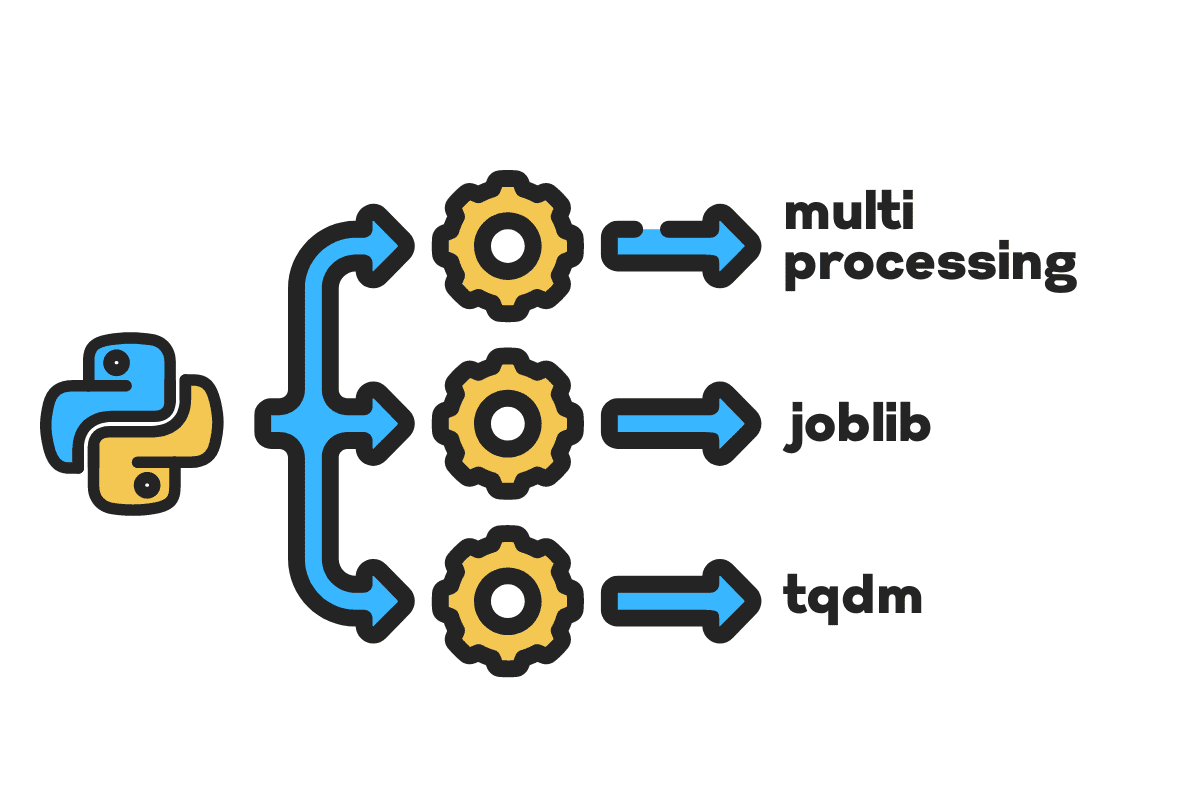
このブログでは、を使用して大きなファイルの処理時間を短縮する方法を学習します マルチプロセッシング, ジョブライブラリ, tqdm Pythonパッケージ。 これは、任意のファイル、データベース、画像、ビデオ、およびオーディオに適用できる簡単なチュートリアルです。
注: 実験にはKaggleノートブックを使用しています。 処理時間はマシンごとに異なります。
私たちは使用します 米国の事故(2016 – 2021) 2.8万レコードと47列で構成されるKaggleのデータセット。
輸入します multiprocessing, joblib, tqdm for 並列処理, pandas for データの取り込み, re, nltk, string for テキスト処理.
#並列計算 import マルチプロセッシング as mp から ジョブライブラリ import 並列、遅延 から tqdm.ノートブック import tqdm #データの取り込み import パンダ as pd #テキスト処理 import re から nltk.コーパス import ストップワード import 文字列
すぐに飛び込む前に、設定しましょう n_workers 倍増することによって cpu_count()。 ご覧のとおり、8人の労働者がいます。
n_workers = 2 * mp.cpu_count() print(f"{n_workers} 個のワーカーが利用可能です") >>> 8人の労働者が利用可能です
次のステップでは、を使用して大きなCSVファイルを取り込みます パンダ read_csv 関数。 次に、データフレームの形状、列の名前、および処理時間を印刷します。
注: Jupyter の魔法の機能
%%time表示することができます CPU時間 および 実時間 プロセスの最後に。
%%time file_name="../input/us-accidents/US_Accidents_Dec21_updated.csv" df = pd.read_csv(file_name) print(f"Shape:{df.shape}nnColumn Names:n{df.columns}n")
出力
形状:(2845342, 47) 列名: Index(['ID', 'Severity', 'Start_Time', 'End_Time', 'Start_Lat', 'Start_Lng', 'End_Lat', 'End_Lng', 'Distance(mi) ', '説明', '番号', '通り', '側', '市', '郡', '都道府県', '郵便番号', '国', 'タイムゾーン', 'Airport_Code', 'Weather_Timestamp', 'Temperature(F)', 'Wind_Chill(F)', 'Humidity(%)', 'Pressure(in)', 'Visibility(mi)', 'Wind_Direction', 'Wind_Speed(mph)', 'Precipitation(in) )', 'Weather_Condition', 'Amenity', 'Bump', 'Crossing', 'Give_Way', 'Junction', 'No_Exit', 'Railway', 'Roundabout', 'Station', 'Stop', 'Traffic_Calming' , 'Traffic_Signal', 'Turning_Loop', 'Sunrise_Sunset', 'Civil_Twilight', 'Nautical_Twilight', 'Astronomical_Twilight'], dtype='object') CPU 時間: ユーザー 33.9 秒、システム: 3.93 秒、合計: 37.9 秒:46.9秒
clean_text テキストを処理およびクリーニングするための簡単な関数です。 私たちは英語を取得します ストップワード nltk.copus これを使用して、テキスト行からストップワードを除外します。 その後、文から特殊文字と余分なスペースを削除します。 の処理時間を決定するためのベースライン関数になります シリアル, パラレル, バッチ 処理。
def クリーンテキスト(文章): #ストップワードを削除する stops = stopwords.words("english") text = " ".join([単語 for 単語 in text.split() if 単語 in 停止]) #特殊文字を削除する text = text.translate(str.maketrans(''、''、string.punctuation)) #余分なスペースを削除する text = re.sub('+'、''、text) return 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO
많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
シリアル処理にはパンダを使用できます .apply() 機能しますが、プログレスバーを表示したい場合は、アクティブ化する必要があります tqdm for パンダ 次に、 .progress_apply() 機能。
2.8万件のレコードを処理し、結果を「説明」列の列に保存します。
%%time tqdm.pandas() df['説明'] = df['説明'].progress_apply(clean_text)
出力
に9分5秒かかりました ハイエンド プロセッサからシリアル処理まで2.8万行。
100% 2845342/2845342 [09:05<00:00、5724.25it/s] CPU 時間: ユーザー 8 分 14 秒、sys: 53.6 秒、合計: 9 分 7 秒 経過時間: 9 分 5 秒
ファイルを並列処理するにはさまざまな方法があり、それらすべてについて学習します。 の multiprocessing 大きなファイルを並列処理するために一般的に使用される組み込みの python パッケージです。
マルチプロセッシングを作成します プール 8労働者 そして使用する 地図 プロセスを開始する機能。 プログレスバーを表示するには、 tqdm.
マップ関数はXNUMXつのセクションで構成されています。 XNUMXつ目は関数を必要とし、XNUMXつ目は引数または引数のリストを必要とします。
読んで詳細を見る ドキュメント.
%%time p = mp.Pool(n_workers) df['説明'] = p.map(clean_text,tqdm(df['説明']))
出力
処理時間をほぼ改善しました 3X。 から処理時間が短縮されました 9分5秒 〜へ 3分51秒.
100% 2845342/2845342 [02:58<00:00, 135646.12it/s] CPU 時間: ユーザー 5.68 秒、システム: 1.56 秒、合計: 7.23 秒 経過時間: 3 分 51 秒
次に、並列処理を実行するための別のPythonパッケージについて学習します。 このセクションでは、joblibを使用します 並列シミュレーションの設定 および 遅延 複製するには 地図 機能。
- Parallelには、n_jobs=8とbackend=multiprocessingのXNUMXつの引数が必要です。
- 次に、追加します クリーンテキスト 遅延 機能。
- 一度にXNUMXつの値をフィードするループを作成します。
以下のプロセスは非常に一般的であり、必要に応じて関数と配列を変更できます。 私は何千ものオーディオとビデオファイルを問題なく処理するためにそれを使用しました。
推奨: を使用して例外処理を追加する try: および except:
def text_Parallel_clean(配列): 結果 = Parallel(n_jobs=n_workers,backend="multiprocessing")( 遅延 (clean_text) (テキスト) for 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다. in tqdm(配列) ) return 結果
「説明」列をに追加します text_parallel_clean().
%%time df['説明'] = text_parallel_clean(df['説明'])
出力
マルチプロセッシングよりも13秒以上かかった プール。 その時でさえ、 並列シミュレーションの設定 より4分59秒速い シリアル 処理。
100% 2845342/2845342 [04:03<00:00, 10514.98it/s] CPU 時間: ユーザー 44.2 秒、システム: 2.92 秒、合計: 47.1 秒 経過時間: 4 分 4 秒
大きなファイルをバッチに分割して並列処理することで、大きなファイルを処理するためのより良い方法があります。 を実行するバッチ関数を作成することから始めましょう clean_function 値の単一のバッチ。
バッチ処理機能
def proc_バッチ(バッチ): return [ clean_text(テキスト) for 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다. in バッチ ]
ファイルをバッチに分割する
以下の関数は、ワーカーの数に基づいてファイルを複数のバッチに分割します。 この場合、8つのバッチを取得します。
def バッチファイル(配列,n_workers): file_len = len(array) バッチサイズ =round(file_len / n_workers) バッチ = [ array[ix:ix+batch_size] for ix in tqdm(範囲(0, ファイル長, バッチサイズ)) ] return batches batches = batch_file(df['Description'],n_workers) >>> 100% 8/8 [00:00<00:00, 280.01it/s]
並列バッチ処理の実行
最後に、 並列シミュレーションの設定 および 遅延 バッチを処理します。
注: 単一の値の配列を取得するには、以下に示すようにリスト内包表記を実行する必要があります。
%%time batch_output = Parallel(n_jobs=n_workers,backend="multiprocessing")( 遅延(proc_batch) (バッチ) for バッチ in tqdm(バッチ) ) df['説明'] = [j for i in バッチ出力 for j in i]
出力
処理時間を改善しました。 この手法は、複雑なデータの処理と深層学習モデルのトレーニングで有名です。
100% 8/8 [00:00<00:00, 2.19it/s] CPU 時間: ユーザー 3.39 秒、システム: 1.42 秒、合計: 4.81 秒 経過時間: 3 分 56 秒
tqdmは、マルチプロセッシングを次のレベルに引き上げます。 シンプルでパワフルです。 すべてのデータサイエンティストにお勧めします。
チェックアウトします ドキュメント マルチプロセッシングの詳細については、こちらをご覧ください。
process_map 必要です:
- 関数名
- データフレーム列
- max_workers
- チャックサイズはバッチサイズに似ています。 ワーカーの数を使用してバッチ サイズを計算するか、好みに応じて数を追加できます。
%%時間 から tqdm.contrib.concurrent import process_map batch = round(len(df)/n_workers) df["Description"] = process_map( clean_text, df["Description"], max_workers=n_workers, chunksize=batch )
出力
XNUMX行のコードで、最良の結果が得られます。
100% 2845342/2845342 [03:48<00:00, 1426320.93it/s] CPU 時間: ユーザー 7.32 秒、システム: 1.97 秒、合計: 9.29 秒 経過時間: 3 分 51 秒
バランスを見つけて、自分のケースに最適なテクニックを選択する必要があります。 シリアル処理、パラレル処理、またはバッチ処理が可能です。 より小さく、より複雑でないデータセットで作業している場合、並列処理は逆効果になる可能性があります。
このミニチュートリアルでは、データ関数を並列処理できるようにするさまざまなPythonパッケージと手法について学習しました。
表形式のデータセットのみを使用していて、処理パフォーマンスを向上させたい場合は、試してみることをお勧めします ダスク, データ表, 急流
参照
アビッド・アリ・アワン (@ 1abidaliawan)は、機械学習モデルの構築を愛する認定データサイエンティストの専門家です。 現在、彼はコンテンツの作成と、機械学習とデータサイエンステクノロジーに関する技術ブログの執筆に注力しています。 Abidは、技術管理の修士号と電気通信工学の学士号を取得しています。 彼のビジョンは、精神疾患に苦しんでいる学生のためにグラフニューラルネットワークを使用してAI製品を構築することです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2022/07/parallel-processing-large-file-python.html?utm_source=rss&utm_medium=rss&utm_campaign=parallel-processing-large-file-in-python
- 1
- 10
- 11
- 2016
- 2021
- 39
- 7
- 9
- a
- 私たちについて
- 事故
- 従った
- 後
- AI
- すべて
- および
- 別の
- 申し込む
- 引数
- 引数
- 配列
- オーディオ
- 利用できます
- バック
- バックエンド
- バー
- バー
- ベース
- ベースライン
- 以下
- BEST
- より良いです
- ブログ
- ブログ
- ビルド
- 建物
- 内蔵
- 計算する
- 場合
- 認証
- 文字
- 市町村
- クリーニング
- コード
- コラム
- コラム
- 一般に
- 複雑な
- 同時
- コンテンツ
- 国
- 郡
- CPU
- 作ります
- 作成
- 創造
- 現在
- データ
- データサイエンス
- データサイエンティスト
- データベース
- 深いです
- 深い学習
- 度
- 遅延
- 説明
- 決定する
- ディスプレイ
- 倍増し
- 落とした
- エンジニアリング
- 英語
- エーテル(ETH)
- あらゆる
- 例
- 例外
- 余分な
- 有名な
- 速いです
- File
- filter
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- 焦点
- から
- function
- 機能
- 取得する
- GitHubの
- 行く
- グラフ
- グラフ ニューラル ネットワーク
- ハンドリング
- 保持している
- 認定条件
- How To
- HTML
- HTTPS
- 病気
- 画像
- import
- 改善します
- 改善されました
- in
- 増加
- 開始する
- 問題
- IT
- Jobs > Create New Job
- ジャンプ
- KDナゲット
- 大
- LEARN
- 学んだ
- 学習
- レベル
- LINE
- リスト
- 機械
- 機械学習
- マジック
- 管理
- 地図
- マスター
- メンタル
- 精神疾患
- 百万
- 分
- モデル
- 修正する
- 他には?
- の試合に
- 名
- 名
- 必要
- ニーズ
- ネットワーク
- ニューラル
- ニューラルネットワーク
- 次の
- ノート
- 数
- オブジェクト
- 全体
- パッケージ
- パッケージ
- パンダ
- 並列シミュレーションの設定
- 実行する
- パフォーマンス
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 強力な
- 印刷物
- プロセス
- 処理
- プロセッサ
- プロダクト
- プロ
- 演奏曲目
- 進捗
- Python
- 鉄道
- RE
- リーディング
- 推奨する
- 記録
- 減らします
- 軽減
- 削除します
- 除去
- 必要
- 結果
- ラン
- Save
- 科学
- 科学者
- 二番
- 秒
- セクション
- セクション
- 文
- シリアル
- セッションに
- 形状
- 示す
- 同様の
- 簡単な拡張で
- サイズ
- より小さい
- スペース
- 特別
- split
- start
- 都道府県
- 駅
- 手順
- Force Stop
- 停止する
- 簡単な
- ストリート
- 苦労して
- 生徒
- 取り
- 仕事
- 技術的
- テクニック
- テクノロジー
- テクノロジー
- テレコミュニケーション
- 数千
- 時間
- <font style="vertical-align: inherit;">回数</font>
- タイムゾーン
- 〜へ
- トータル
- トレーニング
- チュートリアル
- us
- つかいます
- ユーザー
- 値
- 価値観
- さまざまな
- ビデオ
- ビジョン
- 方法
- which
- 誰
- 意志
- 以内
- 無し
- Word
- 言葉
- 労働者
- ワーキング
- 作品
- 書き込み
- あなたの
- ゼファーネット