この XNUMX 部構成のシリーズでは、グラフ ニューラル ネットワーク (GNN) と アマゾン海王星 を使用して映画のおすすめを生成する IMDb とボックス オフィス Mojo 映画/TV/OTT ライセンス可能なデータ パッケージ。1 億を超えるユーザー評価を含む幅広いエンターテイメント メタデータを提供します。 11 万人を超えるキャストとスタッフのクレジット。 9 万の映画、テレビ、エンターテイメント タイトル。 および 60 か国以上からのグローバル興行レポート データ。 多くの AWS メディアおよびエンターテイメントのお客様は、IMDb データのライセンスを AWSデータ交換 コンテンツの発見を改善し、顧客の関与と維持を向上させます。
In 第1部では、GNN のアプリケーションと、クエリ用に IMDb データを変換して準備する方法について説明しました。 この投稿では、Neptune を使用して、パート 3 でカタログ外検索を実行するために使用される埋め込みを生成するプロセスについて説明します。 私たちも行きます アマゾンネプチューンML、Neptune の機械学習 (ML) 機能、および開発プロセスで使用するコードです。 パート 3 では、ナレッジ グラフの埋め込みをカタログ外検索のユース ケースに適用する方法について説明します。
ソリューションの概要
接続された大規模なデータセットには、人間の直感だけに基づくクエリを使用して抽出するのが難しい貴重な情報が含まれていることがよくあります。 ML 手法は、数十億の関係を持つグラフの隠れた相関関係を見つけるのに役立ちます。 これらの相関関係は、製品の推奨、信用度の予測、詐欺の特定、およびその他の多くのユース ケースに役立ちます。
Neptune ML を使用すると、大規模なグラフで有用な ML モデルを数週間ではなく数時間で構築およびトレーニングできます。 これを達成するために、Neptune ML は、 アマゾンセージメーカー と ディープグラフライブラリ(DGL) (これは オープンソースの)。 GNN は、人工知能の新たな分野です (例については、 グラフニューラルネットワークに関する総合調査)。 DGL での GNN の使用に関する実践的なチュートリアルについては、次を参照してください。 ディープ グラフ ライブラリを使用したグラフ ニューラル ネットワークの学習.
この投稿では、パイプラインで Neptune を使用して埋め込みを生成する方法を示します。
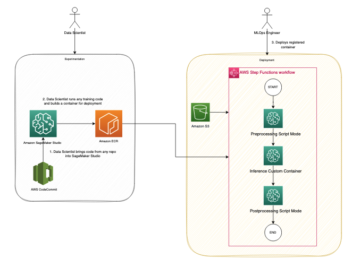
次の図は、ダウンロードから埋め込み生成までの IMDb データの全体的な流れを示しています。
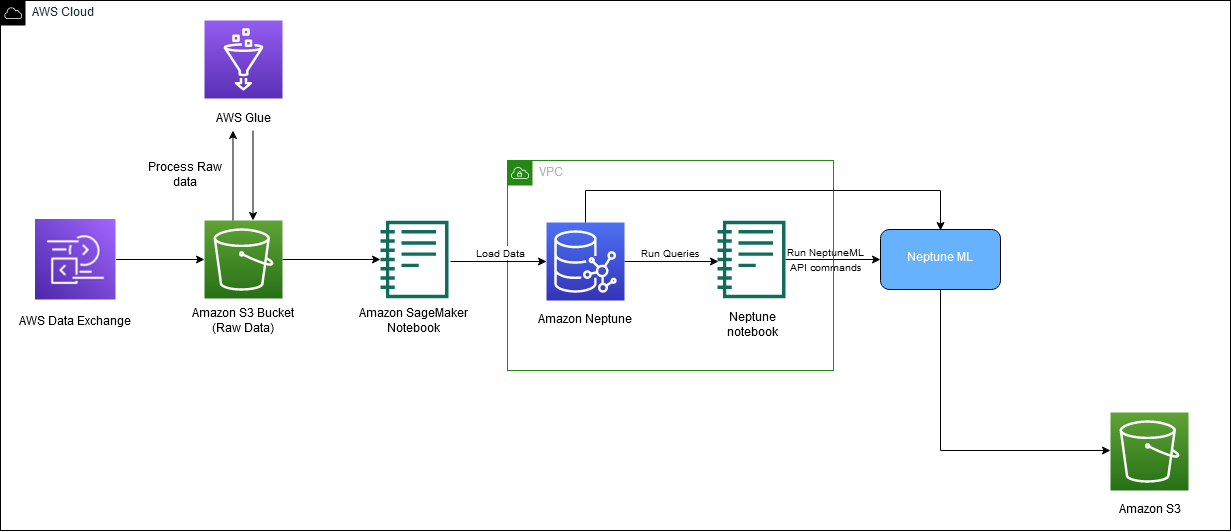
以下の AWS サービスを使用してソリューションを実装します。
この投稿では、次の高レベルの手順について説明します。
- 環境変数を設定する
- エクスポート ジョブを作成します。
- データ処理ジョブを作成します。
- トレーニング ジョブを送信します。
- 埋め込みをダウンロードします。
Neptune ML コマンドのコード
このソリューションの実装の一環として、次のコマンドを使用します。
を使用しております neptune_ml export ステータスを確認するか、Neptune ML エクスポートプロセスを開始します。 neptune_ml training Neptune ML モデルトレーニングジョブを開始してステータスを確認します。
これらおよびその他のコマンドの詳細については、次を参照してください。 ノートブックで Neptune ワークベンチ マジックを使用する.
前提条件
この記事を進めるには、次のものが必要です。
- An AWSアカウント
- SageMaker、Amazon S3、および AWS CloudFormation に精通していること
- Neptune クラスターにロードされたグラフデータ (参照 第1部 詳細については)
環境変数を設定する
始める前に、次の変数を設定して環境をセットアップする必要があります。 s3_bucket_uri & processed_folder. s3_bucket_uri はパート 1 で使用したバケットの名前です。 processed_folder は、エクスポート ジョブからの出力の Amazon S3 の場所です。
エクスポート ジョブを作成する
パート 1 では、SageMaker ノートブックとエクスポート サービスを作成して、必要な形式でデータを Neptune DB クラスターから Amazon S3 にエクスポートしました。
データが読み込まれ、エクスポート サービスが作成されたので、エクスポート ジョブを作成して開始する必要があります。 これを行うには、 NeptuneExportApiUri エクスポート ジョブのパラメータを作成します。 次のコードでは、変数を使用します expo & export_params。 セットする expo あなたへ NeptuneExportApiUri 値は、 出力 CloudFormation スタックのタブ。 為に export_params、Neptune クラスターのエンドポイントを使用して、 outputS3path、これは、エクスポート ジョブからの出力の Amazon S3 の場所です。
エクスポート ジョブを送信するには、次のコマンドを使用します。
エクスポート ジョブのステータスを確認するには、次のコマンドを使用します。
ジョブが完了したら、 processed_folder 処理された結果の Amazon S3 の場所を提供する変数:
データ処理ジョブを作成する
エクスポートが完了したので、データ処理ジョブを作成して、Neptune ML トレーニング プロセス用のデータを準備します。 これにはいくつかの方法があります。 このステップでは、 job_name & modelType ただし、他のすべてのパラメーターは同じままにする必要があります。 このコードの主要部分は、 modelType 異種グラフ モデル (heterogeneous) またはナレッジグラフ (kge).
エクスポート ジョブには、 training-data-configuration.json. このファイルを使用して、トレーニングに提供したくないノードまたはエッジを追加または削除します (たとえば、XNUMX つのノード間のリンクを予測する場合は、この構成ファイルでそのリンクを削除できます)。 このブログ投稿では、元の構成ファイルを使用します。 詳細については、次を参照してください。 トレーニング構成ファイルの編集.
次のコードを使用してデータ処理ジョブを作成します。
エクスポート ジョブのステータスを確認するには、次のコマンドを使用します。
トレーニング ジョブを送信する
処理ジョブが完了したら、埋め込みを作成するトレーニング ジョブを開始できます。 ml.m5.24xlarge のインスタンス タイプをお勧めしますが、コンピューティングのニーズに合わせてこれを変更できます。 次のコードを参照してください。
training_results 変数を出力して、トレーニング ジョブの ID を取得します。 次のコマンドを使用して、ジョブのステータスを確認します。
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
埋め込みをダウンロード
トレーニング ジョブが完了したら、最後のステップは未加工の埋め込みをダウンロードすることです。 次の手順は、KGE を使用して作成された埋め込みをダウンロードする方法を示しています (RGCN にも同じプロセスを使用できます)。
次のコードでは、 neptune_ml.get_mapping() & get_embeddings() マッピング ファイルをダウンロードします (mapping.info) と生の埋め込みファイル (entity.npy)。 次に、適切な埋め込みを対応する ID にマップする必要があります。
RGCN をダウンロードするには、modelType パラメーターを heterogeneous、次に modelName パラメーターを に設定してモデルをトレーニングします。 rgcn こちら 詳細については。 それが終わったら、 get_mapping & get_embeddings 新しいダウンロード機能 マッピング情報 & エンティティ.npy ファイル。 エンティティ ファイルとマッピング ファイルを取得したら、CSV ファイルを作成するプロセスは同じです。
最後に、埋め込みを目的の Amazon S3 の場所にアップロードします。
この S3 の場所を覚えておいてください。パート 3 で使用する必要があります。
クリーンアップ
ソリューションの使用が終了したら、リソースをクリーンアップして、継続的な料金が発生しないようにしてください。
まとめ
この投稿では、Neptune ML を使用して IMDb データから GNN 埋め込みをトレーニングする方法について説明しました。
ナレッジ グラフ埋め込みの関連アプリケーションには、カタログ外検索、コンテンツ レコメンデーション、ターゲット広告、ミッシング リンクの予測、一般的な検索、コホート分析などの概念があります。 カタログ外検索は、自分が所有していないコンテンツを検索し、ユーザーが検索したものにできるだけ近いカタログ内のコンテンツを見つけたり、推奨したりするプロセスです。 パート 3 では、カタログ外検索について詳しく説明します。
著者について
 マシューローズ 私は Amazon ML Solutions Lab で働いているデータサイエンティストです。 彼は、自然言語処理やコンピューター ビジョンなどの概念を含む機械学習パイプラインの構築を専門としています。
マシューローズ 私は Amazon ML Solutions Lab で働いているデータサイエンティストです。 彼は、自然言語処理やコンピューター ビジョンなどの概念を含む機械学習パイプラインの構築を専門としています。
 ディヴィヤ・バルガヴィ Amazon ML Solutions Lab のデータサイエンティストであり、メディアとエンターテイメントの垂直リーダーであり、機械学習を使用して AWS のお客様の価値の高いビジネス上の問題を解決しています。 彼女は、画像/ビデオの理解、ナレッジ グラフ推奨システム、予測広告のユース ケースに取り組んでいます。
ディヴィヤ・バルガヴィ Amazon ML Solutions Lab のデータサイエンティストであり、メディアとエンターテイメントの垂直リーダーであり、機械学習を使用して AWS のお客様の価値の高いビジネス上の問題を解決しています。 彼女は、画像/ビデオの理解、ナレッジ グラフ推奨システム、予測広告のユース ケースに取り組んでいます。
 ガウラヴ・レレ はAmazonML Solution Labのデータサイエンティストであり、さまざまな業種のAWSのお客様と協力して、機械学習とAWSクラウドサービスの使用を加速し、ビジネス上の課題を解決しています。
ガウラヴ・レレ はAmazonML Solution Labのデータサイエンティストであり、さまざまな業種のAWSのお客様と協力して、機械学習とAWSクラウドサービスの使用を加速し、ビジネス上の課題を解決しています。
 カランシンドワニ Amazon ML Solutions Lab のデータサイエンティストであり、深層学習モデルの構築とデプロイを行っています。 彼はコンピュータビジョンの分野を専門としています。 余暇には、ハイキングを楽しんでいます。
カランシンドワニ Amazon ML Solutions Lab のデータサイエンティストであり、深層学習モデルの構築とデプロイを行っています。 彼はコンピュータビジョンの分野を専門としています。 余暇には、ハイキングを楽しんでいます。
 アデシナ宗司 AWS の応用科学者であり、グラフ タスクで機械学習を行うためのグラフ ニューラル ネットワーク ベースのモデルを開発し、詐欺や悪用、ナレッジ グラフ、レコメンダー システム、ライフ サイエンスへの応用を行っています。 余暇には、読書と料理を楽しんでいます。
アデシナ宗司 AWS の応用科学者であり、グラフ タスクで機械学習を行うためのグラフ ニューラル ネットワーク ベースのモデルを開発し、詐欺や悪用、ナレッジ グラフ、レコメンダー システム、ライフ サイエンスへの応用を行っています。 余暇には、読書と料理を楽しんでいます。
 ヴィディヤ・サーガル・ラヴィパティ Amazon ML Solutions Lab のマネージャーであり、大規模な分散システムでの豊富な経験と機械学習への情熱を活用して、さまざまな業種の AWS のお客様が AI とクラウドの採用を加速できるよう支援しています。
ヴィディヤ・サーガル・ラヴィパティ Amazon ML Solutions Lab のマネージャーであり、大規模な分散システムでの豊富な経験と機械学習への情熱を活用して、さまざまな業種の AWS のお客様が AI とクラウドの採用を加速できるよう支援しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/
- 1
- 10
- 100
- 11
- 116
- 7
- 9
- a
- 私たちについて
- 虐待
- 加速する
- 越えて
- NEW
- 追加情報
- 養子縁組
- 広告運用
- 後
- AI
- すべて
- 一人で
- Amazon
- Amazon MLソリューションラボ
- 分析
- &
- 適用された
- 申し込む
- 適切な
- AREA
- 人工の
- 人工知能
- AWS
- ベース
- の間に
- 10億
- 億
- ブログ
- ボックス
- 興行収入
- ビルド
- 建物
- 構築します
- ビジネス
- コール
- 場合
- 例
- カタログ
- 課題
- 変化する
- 課金
- チェック
- 閉じる
- クラウド
- クラウドの採用
- クラウドサービス
- クラスタ
- コード
- コホート
- コンプリート
- 包括的な
- コンピュータ
- Computer Vision
- コンピューティング
- コンセプト
- プロフェッショナルな方法で
- 交流
- コンテンツ
- 対応する
- 国
- 作ります
- 作成した
- クレジット
- Applied Deposits
- 顧客
- 顧客エンゲージメント
- Customers
- データ
- データ処理
- データサイエンティスト
- データセット
- 深いです
- 深い学習
- より深い
- 配備する
- 細部
- 開発
- 開発
- dgl
- 異なります
- 発見
- 話し合います
- 議論する
- 配布
- 分散システム
- ドント
- ダウンロード
- どちら
- 新興の
- エンドポイント
- 婚約
- エンターテインメント
- エンティティ
- 環境
- エーテル(ETH)
- 例
- 体験
- export
- エキス
- 特徴
- 少数の
- フィールド
- File
- もう完成させ、ワークスペースに掲示しましたか?
- 発見
- フロー
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- 詐欺
- から
- フル
- 機能
- 生成する
- 世代
- 取得する
- グローバル
- Go
- グラフ
- グラフ
- 実践的な
- ハード
- 助けます
- 役立つ
- 隠されました
- ハイレベル
- HOURS
- 認定条件
- How To
- HTML
- HTTPS
- 人間
- 同一の
- 識別
- 実装する
- 実装
- 改善します
- in
- 含ま
- 含めて
- 増える
- index
- 産業を変えます
- info
- 情報
- を取得する必要がある者
- インテリジェンス
- 巻き込む
- IT
- ジョブ
- JSON
- キー
- 知識
- ラボ
- 言語
- 大
- 大規模
- 姓
- つながる
- 学習
- レバレッジ
- 図書館
- ライセンス
- 生活
- 生命科学
- LINK
- リンク
- 場所
- 機械
- 機械学習
- メイン
- 作る
- マネージャー
- 多くの
- 地図
- マッピング
- メディア
- ミディアム
- メンバー
- 百万
- 行方不明
- ML
- モデル
- 他には?
- 映画
- 名
- ナチュラル
- 自然言語処理
- 必要
- ニーズ
- ネプチューン
- ネットワークベース
- ネットワーク
- ニューラルネットワーク
- 新作
- ノード
- ノート
- Office
- 継続
- オリジナル
- その他
- 全体
- 自分の
- パッケージ
- パラメーター
- パラメータ
- 部
- 情熱
- パイプライン
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 可能
- ポスト
- 電力
- パワード
- 予測する
- 予測
- 準備
- 印刷物
- 問題
- プロセス
- 処理
- 製品
- プロフィール
- 提供します
- は、大阪で
- 範囲
- 評価
- Raw
- リーディング
- 推奨する
- おすすめ
- 提言
- 推薦する
- 関連する
- の関係
- 残る
- 覚えています
- 削除します
- 各種レポート作成
- の提出が必要です
- リソース
- 結果
- 保持
- セージメーカー
- 同じ
- 科学
- 科学者
- を検索
- 検索
- シリーズ
- サービス
- サービス
- セッションに
- 設定
- すべき
- 表示する
- 溶液
- ソリューション
- 解決する
- 解決する
- 専門にする
- スタック
- start
- Status:
- 手順
- ステップ
- 店舗
- 提出する
- そのような
- スーツ
- Survey
- システム
- 対象となります
- タスク
- テクニック
- テクノロジー
- エリア
- アプリ環境に合わせて
- 介して
- 時間
- タイトル
- 〜へ
- トレーニング
- トレーニング
- 最適化の適用
- true
- チュートリアル
- tv
- 理解する
- つかいます
- 使用事例
- ユーザー
- 貴重な
- 値
- 広大な
- バージョン
- 垂直
- ビジョン
- 方法
- ウィークス
- この試験は
- which
- ワイド
- 広い範囲
- 意志
- ワーキング
- 作品
- あなたの
- ゼファーネット