この投稿は、bpx Energy の Thatcher Thornberry との共同執筆です。
相分類は、坑井位置の地質データから岩層をセグメント化するプロセスです。 掘削中に、深さに依存する地質情報を含むワイヤーラインログが取得されます。 地質学者は、このログ データを分析し、さまざまなタイプのログ データから対象となる可能性のある相の深さの範囲を決定するために配置されます。 これらの領域を正確に分類することは、その後の掘削プロセスにとって非常に重要です。
AI と機械学習 (ML) を使用した相分類は、多くの石油メジャーにとってますます人気のある調査分野となっています。 大手石油会社のデータ サイエンティストやビジネス アナリストの多くは、相似分類などの重要なタスクについて高度な ML 実験を実行するために必要なスキルセットを持っていません。 これに対処するために、この問題に関してクラス最高の ML 分類モデルを簡単に準備してトレーニングする方法を示します。
この投稿では、主にすでに Snowflake を使用しているユーザーを対象として、相分類タスクのトレーニング データと検証データの両方を、Snowflake からインポートする方法について説明します。 スノーフレーク に Amazon SageMaker キャンバス その後、3+ カテゴリ予測モデルを使用してモデルをトレーニングします。
ソリューションの概要
私たちのソリューションは、次の手順で構成されています。
- ローカルマシンからSnowflakeにfacies CSVデータをアップロードします。 この投稿では、次のデータを使用します オープンソースの GitHub リポジトリ.
- 構成 AWS IDおよびアクセス管理 Snowflake の (IAM) ロールを作成し、Snowflake 統合を作成します。
- Snowflake 資格情報のシークレットを作成します (オプションですが、推奨されます)。
- Snowflake を Canvas に直接インポートします。
- 相分類モデルを構築します。
- モデルを分析します。
- マルチクラス モデルを使用してバッチ予測と単一予測を実行します。
- トレーニングされたモデルを共有する Amazon SageMakerスタジオ.
前提条件
この投稿の前提条件は次のとおりです。
顔のCSVデータをSnowflakeにアップロードする
このセクションでは、XNUMX つのオープンソース データセットを取得し、ローカル マシンから Snowflake データベースに直接アップロードします。 そこから、Snowflake と Canvas の間に統合レイヤーを設定します。
- ダウンロード トレーニングデータ.csv & validation_data_nofacies.csv ファイルをローカルマシンにコピーします。 保存した場所をメモしておきます。
- 正しい Snowflake 資格情報を持ち、Snowflake CLI デスクトップ アプリがインストールされていることを確認すると、フェデレーションを行うことができます。詳細については、を参照してください。 SnowSQL にログインする.

- 作業する適切な Snowflake ウェアハウスを選択します。この例では、
COMPUTE_WH:

- チュートリアルの残りの部分で使用するデータベースを選択します。
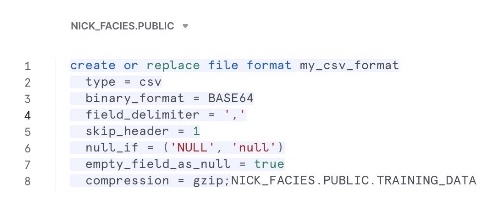
- Snowflake テーブルにアクセスまたはロードするためのステージングされたデータのセットを記述する名前付きファイル形式を作成します。
これは、Snowflake CLI または Web アプリケーション上の Snowflake ワークシートで実行できます。 この投稿では、Web アプリケーションで SnowSQL クエリを実行します。 見る ワークシートの使用を開始する Snowflake Web アプリケーションでワークシートを作成する手順については、「Snowflake Web アプリケーションでワークシートを作成する手順」を参照してください。
- CREATE ステートメントを使用して、Snowflake にテーブルを作成します。
次のステートメントは、現在のスキーマまたは指定されたスキーマに新しいテーブルを作成します (または既存のテーブルを置き換えます)。
データ型とその表示順序が正しく、以前にダウンロードした CSV ファイルの内容と一致していることが重要です。 矛盾している場合は、後でデータをコピーしようとしたときに問題が発生します。

- 検証データベースに対しても同じことを行います。
スキーマはトレーニング データとは少し異なることに注意してください。 もう一度、データ型と列または特徴の順序が正しいことを確認してください。

- CSV データ ファイルをローカル システムから Snowflake ステージング環境にロードします。
- Windows OS のステートメントの構文は次のとおりです。
- Mac OS のステートメントの構文は次のとおりです。
次のスクリーンショットは、SnowSQL CLI 内からのコマンドと出力の例を示しています。

- データをターゲットの Snowflake テーブルにコピーします。
ここでは、前に作成したターゲット テーブルにトレーニング CSV データを読み込みます。 トレーニングと検証の両方の CSV ファイルに対してこれを実行し、それぞれをトレーニング テーブルと検証テーブルにコピーする必要があることに注意してください。

- SELECT クエリを実行して、データがターゲット テーブルにロードされたことを確認します (これはトレーニング データと検証データの両方に対して実行できます)。

Snowflake IAM ロールを構成し、Snowflake 統合を作成する
このセクションの前提条件として、次の方法については Snowflake の公式ドキュメントに従ってください。Amazon S3 にアクセスするための Snowflake ストレージ統合の設定.
Snowflake アカウントの IAM ユーザーを取得する
Snowflake ストレージ統合を正常に構成したら、次のコマンドを実行します。 DESCRIBE INTEGRATION Snowflake アカウント用に自動的に作成された IAM ユーザーの ARN を取得するコマンド:
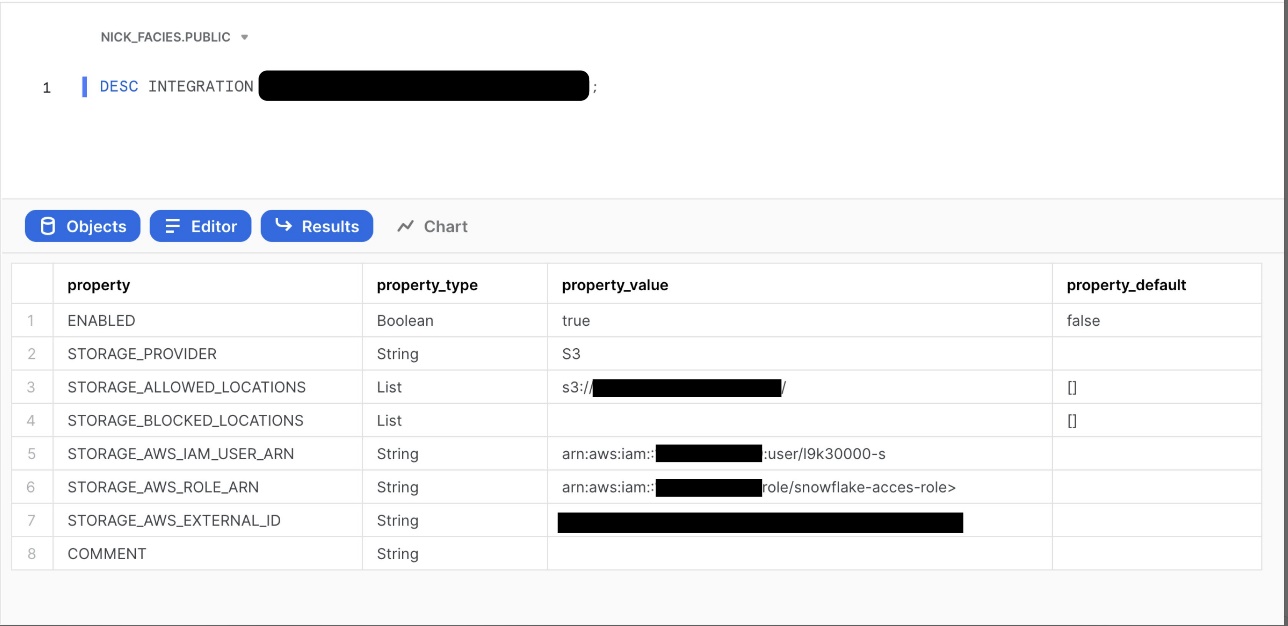
出力から次の値を記録します。
- STORAGE_AWS_IAM_USER_ARN – Snowflake アカウント用に作成された IAM ユーザー
- STORAGE_AWS_EXTERNAL_ID – 信頼関係を確立するために必要な外部 ID
IAM ロールの信頼ポリシーを更新する
次に、信頼ポリシーを更新します。
- IAMコンソールで、 役割 ナビゲーションペインに表示されます。
- 作成した役割を選択します。
- ソフトウェア設定ページで、下図のように 信頼関係 タブを選択 信頼関係を編集する.
- 次のコードに示すように、前の手順で記録した DESC STORAGE INTEGRATION 出力値を使用してポリシー ドキュメントを変更します。
- 選択する 信頼ポリシーの更新.
Snowflake で外部ステージを作成する
自分のアカウントの S3 バケットから Snowflake にデータをロードするために、Snowflake 内の外部ステージを使用します。 このステップでは、作成したストレージ統合を参照する外部 (Amazon S3) ステージを作成します。 詳細については、次を参照してください。 S3 ステージの作成.
これには、 CREATE_STAGE スキーマに対する権限と、ストレージ統合に対する USAGE 権限。 次のステップのコードに示すように、これらの権限をロールに付与できます。
を使用してステージを作成します。 CREATE_STAGE 外部ステージと S3 バケットとプレフィックスのプレースホルダーを含むコマンド。 ステージは、次の名前の名前付きファイル形式オブジェクトも参照します。 my_csv_format:
Snowflake 資格情報のシークレットを作成する
Canvas を使用すると、 AWSシークレットマネージャー Snowflake にアクセスするための Secret または Snowflake アカウント名、ユーザー名、およびパスワード。 Snowflake アカウント名、ユーザー名、およびパスワードのオプションを使用する場合は、データ ソースの追加について説明する次のセクションに進んでください。
Secrets Manager シークレットを手動で作成するには、次の手順を実行します。
- Secrets Managerコンソールで、 新しい秘密を保存する.
- シークレットタイプを選択選択する その他の種類の秘密.
- シークレットの詳細をキーと値のペアとして指定します。
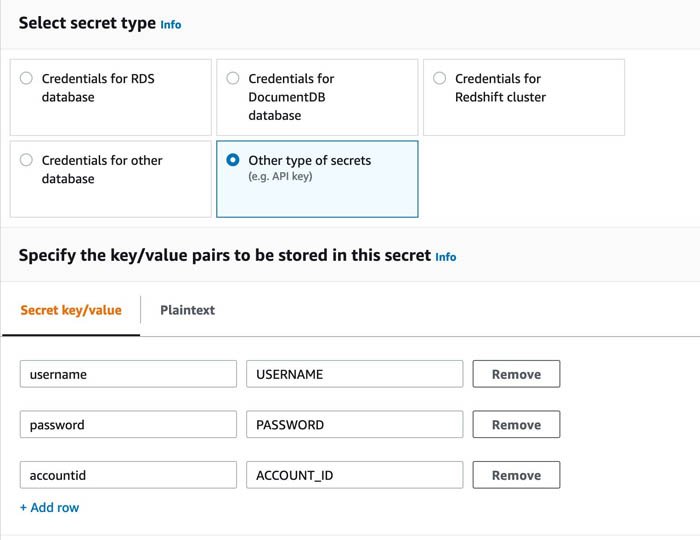
キーの名前は大文字と小文字が区別され、小文字である必要があります。
必要に応じて、プレーンテキスト オプションを使用して、シークレット値を JSON として入力できます。
- 選択する Next.
- 秘密の名前、プレフィックスを追加します
AmazonSageMaker(たとえば、私たちの秘密はAmazonSageMaker-CanvasSnowflakeCreds). - タグ セクションに、キー SageMaker と値 true のタグを追加します。

- 選択する Next.
- 残りのフィールドはオプションです。 選ぶ Next 選択できるようになるまで オンラインショップ 秘密を保存します。
- シークレットを保存すると、Secrets Manager コンソールに戻ります。
- 作成したシークレットを選択し、シークレット ARN を取得します。
- 後で Canvas データ ソースを作成するときに使用できるように、これを好みのテキスト エディターに保存します。
Snowflake を Canvas に直接インポートする
相似データセットを Canvas に直接インポートするには、次の手順を実行します。
- SageMakerコンソールで、 Amazon SageMaker キャンバス ナビゲーションペインに表示されます。
- ユーザープロファイルを選択し、 オープンキャンバス.
- キャンバスのランディング ページで、 データセット ナビゲーションペインに表示されます。
- 選択する インポート.

- ソフトウェアの制限をクリック スノーフレーク 下の画像ですぐに 「接続を追加」.

- 以前に作成した Snowflake シークレットの ARN、ストレージ統合名 (
SAGEMAKER_CANVAS_INTEGRATION)、および選択した一意の接続名。 - 選択する 接続を追加.

すべてのエントリが有効な場合は、接続に関連付けられているすべてのデータベースがナビゲーション ペインに表示されます (次の例を参照してください)。 NICK_FACIES).

- 選択する
TRAINING_DATAテーブルを選択し、 データセットのプレビュー.
データに満足したら、データ ビジュアライザーでカスタム SQL を編集できます。
- 選択する SQLで編集.
- Canvas にインポートする前に、次の SQL コマンドを実行します。 (これは、データベースが次のように呼ばれることを前提としています。
NICK_FACIES。 この値をデータベース名に置き換えます。)
次のスクリーンショットのようなものが表示されます。 インポートプレビュー のセクションから無料でダウンロードできます。
- プレビューに満足したら、選択してください インポート日.
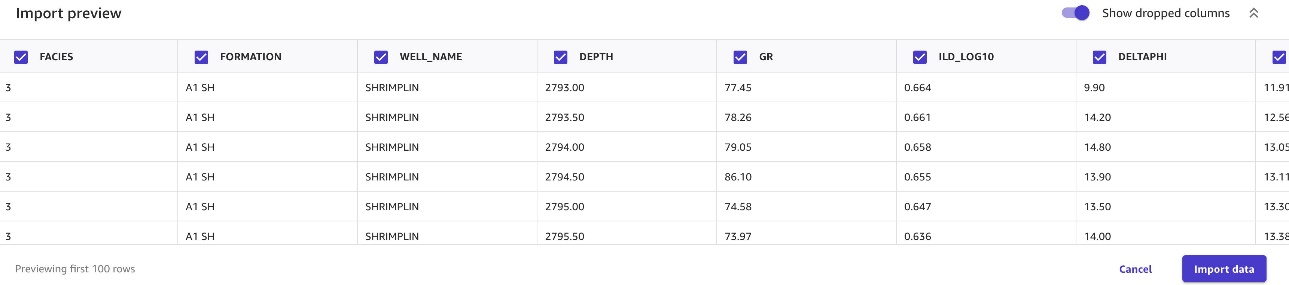
- 適切なデータ名を選択し、一意で長さが 32 文字未満であることを確認してください。
- 次のコマンドを使用して、前と同じ方法で検証データセットをインポートします。
相分類モデルを構築する
顔相分類モデルを構築するには、次の手順を実行します。
- 選択する Models ナビゲーションペインで、を選択します ニューモデル.
- モデルに適切な名前を付けます。
- ソフトウェア設定ページで、下図のように 選択 タブで、最近インポートされたトレーニング データセットを選択し、次に データセットを選択.
- ソフトウェア設定ページで、下図のように 完成に向けてあなたの背中を押してくれる、執筆のための持続可能で本物のモーメンタムを作り出す。 タブをドロップして、
WELL_NAMEコラム。
このようにするのは、ウェル名自体は ML モデルにとって有用な情報ではないためです。 これらは、ウェル自体を区別するのに役立つと考えられる任意の名前にすぎません。 特定の井戸に付ける名前は、ML モデルとは無関係です。
- ターゲット列として FACIES を選択します。
- コメントを残す モデルタイプ as 3 つ以上のカテゴリの予測.
- データを検証します。
- 選択する 標準ビルド.
モデルを構築する直前のページは、次のスクリーンショットのように見えるはずです。

あなたが選んだ後 標準ビルド、モデルは分析段階に入ります。 予想されるビルド時間が提供されます。 これで、このウィンドウを閉じ、Canvas からログアウトし (料金の発生を避けるため)、後で Canvas に戻ることができます。
相分類モデルを分析する
モデルを分析するには、次の手順を実行します。
- フェデレーションをキャンバスに戻します。
- 以前に作成したモデルを見つけて、選択します 詳しく見る、を選択します 解析.
- ソフトウェア設定ページで、下図のように 概要 タブでは、個々の特徴がモデルの出力に与えている影響を確認できます。
- 右側のペインでは、特定の特徴 (X 軸) が各相クラスの予測 (Y 軸) に与えている影響を視覚化できます。
これらのビジュアライゼーションは、選択した機能に応じて変化します。 9 つのクラスと 10 の機能すべてを循環してこのページを探索することをお勧めします。
- ソフトウェア設定ページで、下図のように 得点 タブでは、予測された相と実際の相の分類を確認できます。
- 選択する 高度な指標 F1 スコア、平均精度、適合率、再現率、AUC を表示します。
- 繰り返しになりますが、さまざまなクラスをすべて見ることをお勧めします。
- 選択する ダウンロード イメージをローカル マシンにダウンロードします。
次の画像では、F1 スコアなどのさまざまな高度なメトリクスを確認できます。 統計分析では、F1 スコアは分類モデルの適合率と再現率のバランスを表し、次の方程式を使用して計算されます。 2*((Precision * Recall)/ (Precision + Recall)).

マルチクラス相分類モデルを使用してバッチ予測と単一予測を実行する
予測を実行するには、次の手順を実行します。
- 選択する 単一の予測 必要に応じて特徴値を変更し、ページの右側に返される相分類を取得します。
その後、予測チャートの画像をクリップボードにコピーしたり、予測を CSV ファイルにダウンロードしたりできます。

- 選択する バッチ予測 それから、 データセットを選択 をクリックして、以前にインポートした検証データセットを選択します。
- 選択する 予測を生成する.
にリダイレクトされます 予測する ページ、 Status: 読むつもりです 予測の生成 数秒間。
予測が返された後、予測の横にあるオプション メニュー (縦に XNUMX つあるドット) を選択して、予測をプレビュー、ダウンロード、または削除できます。

以下は予測プレビューの例です。

Studio でトレーニング済みモデルを共有する
モデルの最新バージョンを別の Studio ユーザーと共有できるようになりました。 これにより、データ サイエンティストはモデルを詳細にレビューし、テストし、精度を向上させる可能性のある変更を加え、更新されたモデルを共有することができます。
ML ペルソナのワークフロー間の重要な違いを考慮すると、Studio 内でより技術的なユーザーと作業を共有できる機能は Canvas の重要な機能です。 ここでは、異なる技術的能力を持つ部門を超えたチーム間のコラボレーションに重点が置かれていることに注目してください。
- 選択する シェアする モデルを共有します。

- 共有するモデルのバージョンを選択します。
- モデルを共有する Studio ユーザーを入力します。
- オプションのメモを追加します。
- 選択する シェアする.

まとめ
この投稿では、Amazon SageMaker Canvas で数回クリックするだけで、Snowflake からデータを準備してインポートし、データセットを結合し、推定精度を分析し、影響のある列を検証し、最高のパフォーマンスのモデルをトレーニングし、新しい個人を生成する方法を説明しました。またはバッチ予測。 皆様からのフィードバックをお待ちしており、ML を使用してさらに多くのビジネス上の問題を解決できるようお手伝いいたします。 独自のモデルを構築するには、次を参照してください。 AmazonSageMakerCanvasの使用を開始する.
著者について
 ニック・マッカーシー は、AWS プロフェッショナル サービス チームの機械学習エンジニアです。 彼は、ヘルスケア、金融、スポーツ、通信、エネルギーなどのさまざまな業界の AWS クライアントと協力して、AI/ML の使用を通じてビジネス成果を加速させてきました。 bpx データサイエンスチームと協力して、Nick は最近、Amazon SageMaker での bpx の機械学習プラットフォームの構築を完了しました。
ニック・マッカーシー は、AWS プロフェッショナル サービス チームの機械学習エンジニアです。 彼は、ヘルスケア、金融、スポーツ、通信、エネルギーなどのさまざまな業界の AWS クライアントと協力して、AI/ML の使用を通じてビジネス成果を加速させてきました。 bpx データサイエンスチームと協力して、Nick は最近、Amazon SageMaker での bpx の機械学習プラットフォームの構築を完了しました。
 サッチャー・ソーンベリー bpx Energy の機械学習エンジニアです。 彼は、Amazon SageMaker で同社の中核となるデータ サイエンス プラットフォームを開発および保守することで、bpx のデータ サイエンティストをサポートしています。 自由時間には、個人的なコーディング プロジェクトをハッキングしたり、妻と屋外で時間を過ごすのが大好きです。
サッチャー・ソーンベリー bpx Energy の機械学習エンジニアです。 彼は、Amazon SageMaker で同社の中核となるデータ サイエンス プラットフォームを開発および保守することで、bpx のデータ サイエンティストをサポートしています。 自由時間には、個人的なコーディング プロジェクトをハッキングしたり、妻と屋外で時間を過ごすのが大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/prepare-training-and-validation-dataset-for-facies-classification-using-snowflake-integration-and-train-using-amazon-sagemaker-canvas/
- :持っている
- :は
- :どこ
- $UP
- 10
- 100
- 11
- 12
- 14
- 17
- 50
- 7
- 8
- 9
- a
- 能力
- 能力
- 加速する
- アクセス
- それに応じて
- 精度
- 正確にデジタル化
- 越えて
- Action
- 実際の
- 加えます
- 追加
- 住所
- 高度な
- 再び
- AI
- AI / ML
- 目的としました
- 整列する
- すべて
- 許す
- ことができます
- 既に
- また
- Amazon
- アマゾンセージメーカー
- Amazon SageMaker キャンバス
- Amazon Webサービス
- an
- 分析
- アナリスト
- 分析します
- &
- 別の
- どれか
- アプリ
- 現れる
- 申し込み
- 適切な
- です
- AREA
- AS
- 関連する
- At
- 自動的に
- 平均
- 避ける
- AWS
- AWSプロフェッショナルサービス
- 軸
- バック
- BE
- なぜなら
- になる
- き
- 以下
- BEST
- の間に
- 両言語で
- ビルド
- 建物
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 呼ばれます
- 缶
- キャンバス
- 場合
- カテゴリー
- 変化する
- 変更
- 文字
- 課金
- チャート
- 選択する
- 選択する
- class
- クラス
- 分類
- クライアント
- 閉じる
- コード
- コーディング
- 環境、テクノロジーを推奨
- コラム
- コラム
- 企業
- 会社の
- コンプリート
- 条件
- 接続
- 領事
- 複写
- 基本
- 正しい
- カバー
- 作ります
- 作成した
- 作成します。
- Credentials
- 重大な
- クロスファンクショナルチーム
- 電流プローブ
- カスタム
- データ
- データサイエンス
- データベース
- データベースを追加しました
- データセット
- によっては
- 展開
- 深さ
- 説明する
- デスクトップ
- 詳細
- 細部
- 決定する
- 開発
- 異なります
- 異なる
- 直接に
- 見分けます
- do
- ドキュメント
- ドキュメント
- ドント
- ダウンロード
- Drop
- 間に
- 各
- 前
- 簡単に
- エディタ
- 効果
- どちら
- 奨励する
- エネルギー
- エンジニア
- 確保
- 確保する
- 入力します
- 入ります
- 環境
- 確立する
- 推定
- エーテル(ETH)
- さらに
- 例
- 興奮した
- 既存の
- 予想される
- 実験
- 説明する
- 探る
- 外部
- f1
- 特徴
- 特徴
- フィードバック
- 少数の
- より少ない
- フィールズ
- File
- ファイナンス
- もう完成させ、ワークスペースに掲示しましたか?
- フォーカス
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- 形成
- 発見
- 無料版
- から
- 生成する
- 取得する
- GitHubの
- 与える
- 与えられた
- 助成金
- ハック
- ハッピー
- 持ってる
- 持って
- he
- ヘルスケア
- 聞く
- 助けます
- こちら
- 彼の
- 認定条件
- How To
- HTML
- HTTP
- HTTPS
- IAM
- ID
- アイデンティティ
- if
- 画像
- 直ちに
- 影響
- 衝撃的
- import
- 重要
- インポート
- 改善します
- in
- include
- 含めて
- ますます
- 個人
- 産業
- 情報
- インストール
- 説明書
- 統合
- 予定
- 関心
- に
- 調査
- 問題
- IT
- join
- JPG
- JSON
- ただ
- キー
- 着陸
- ランディングページ
- 大
- 後で
- 最新の
- 層
- 学習
- 少し
- 負荷
- ローディング
- ローカル
- 場所
- ログ
- 長い
- 見て
- で
- MAC
- 機械
- 機械学習
- メジャー
- make
- マネージャー
- 手動で
- 多くの
- 五月..
- メニュー
- 単に
- 方法
- メトリック
- ML
- モデル
- 修正する
- 他には?
- しなければなりません
- 名
- 名前付き
- 名
- ナビゲーション
- 必要
- 必要とされる
- 新作
- 次の
- 注意
- 今
- 数
- オブジェクト
- 得
- of
- 公式
- 油
- on
- オープンソース
- オプション
- オプション
- or
- 注文
- 受注
- OS
- 私たちの
- でる
- 成果
- 屋外で
- 出力
- 自分の
- P&E
- ページ
- 足
- ペイン
- 特定の
- パスワード
- 実行
- 個人的な
- 平文
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- お願いします
- 方針
- 人気
- ポスト
- 潜在的な
- 精度
- 予測
- 予測
- 予測
- 好む
- 優先
- 準備
- プレビュー
- 前
- 前に
- 主に
- 校長
- 特権
- 特権
- 問題
- 問題
- プロセス
- ラボレーション
- プロ
- プロフィール
- プロジェクト(実績作品)
- 提供
- 公共
- 読む
- 最近
- 記録された
- リファレンス
- 地域
- replace
- 必要
- REST
- return
- レビュー
- 右
- 職種
- 役割
- ラン
- ランニング
- セージメーカー
- 同じ
- 科学
- 科学者たち
- スコア
- 秒
- 秘密
- セクション
- サービス
- セッションに
- シェアする
- すべき
- 表示する
- 示されました
- 示す
- 作品
- 同様の
- スキルセット
- スノーフレーク データベース
- 溶液
- 解決する
- ソース
- 指定の
- 過ごす
- スポーツ
- SQL
- ステージ
- ステージング
- 開始
- ステートメント
- 統計的
- 手順
- ステップ
- ストレージ利用料
- 店舗
- 強い
- 研究
- 続いて
- 首尾よく
- そのような
- 適当
- サポート
- 構文
- テーブル
- TAG
- 取る
- ターゲット
- 仕事
- タスク
- チーム
- チーム
- 技術的
- 電気通信
- test
- より
- それ
- アプリ環境に合わせて
- それら
- 自分自身
- その後
- そこ。
- ボーマン
- 彼ら
- この
- それらの
- 三
- 介して
- 時間
- 〜へ
- トレーニング
- 訓練された
- トレーニング
- true
- 信頼
- 試します
- 2
- type
- ユニーク
- アップデイト
- 更新しました
- URL
- 使用法
- つかいます
- ユーザー
- ユーザ名
- 値
- 価値観
- さまざまな
- 確認する
- バージョン
- 垂直
- 詳しく見る
- 鑑賞
- 視覚化する
- vs
- ウォークスルー
- 倉庫
- ました
- we
- ウェブ
- ウェブアプリケーション
- Webサービス
- WELL
- ウェルズ
- この試験は
- 何ですか
- いつ
- which
- 誰
- 妻
- 意志
- ウィンドウズ
- 以内
- 仕事
- 働いていました
- ワークフロー
- ワーキング
- X
- 貴社
- あなたの
- ゼファーネット