日時 OpenAI 2020年XNUMX月にテキスト生成に特化した機械学習(ML)モデルの第XNUMX世代をリリースしましたが、何かが違うことを知っていました。 このモデルは、その前に誰も来なかったような神経を打ちました。 突然、テクノロジーに興味があるかもしれないが、通常はAI / ML空間の最新の進歩についてあまり気にしない友人や同僚が、それについて話しているのを聞きました。 ガーディアンでさえ書いた 記事 それについて。 または、正確には、 記事を書き、ガーディアンはそれを編集して公開しました。 それを否定することはできませんでした– GPT-3 ゲームチェンジャーでした。
モデルがリリースされた後、人々はすぐにそれの潜在的なアプリケーションを考え出し始めました。 数週間以内に、多くの印象的なデモが作成されました。 GPT-3ウェブサイト。 私の目を引いた特定のアプリケーションのXNUMXつは テキスト要約– 特定のテキストを読み取り、その内容を要約するコンピューターの機能。 自然言語処理(NLP)の分野で、読解とテキスト生成の3つの分野を組み合わせているため、コンピューターにとって最も難しい作業のXNUMXつです。 そのため、テキスト要約のGPT-XNUMXデモに非常に感銘を受けました。
あなたは彼らに試してみることができます フェイススペースのウェブサイトを抱き締める。 現時点で私のお気に入りは これは、記事のURLだけを入力としてニュース記事の要約を生成します。
このXNUMX部構成のシリーズでは、ドメインのテキスト要約モデルの品質を評価できるように、組織向けの実用的なガイドを提案します。
チュートリアルの概要
私が協力している多くの組織(慈善団体、企業、NGO)には、財務報告やニュース記事、科学研究論文、特許出願、法的契約など、読んで要約する必要のある膨大な量のテキストがあります。 当然、これらの組織は、NLPテクノロジーを使用してこれらのタスクを自動化することに関心があります。 可能性の芸術を示すために、私はしばしばテキスト要約デモを使用しますが、これはほとんど印象に残りません。
しかし、今は何ですか?
これらの組織にとっての課題は、一度にXNUMXつずつではなく、多数のドキュメントの要約に基づいてテキスト要約モデルを評価したいということです。 彼らは、アプリケーションを開き、ドキュメントを貼り付け、ヒットすることだけが仕事であるインターンを雇いたくないのです。 まとめる ボタンをクリックし、出力を待ち、要約が適切かどうかを評価し、何千ものドキュメントに対してそれを繰り返します。
このチュートリアルは、XNUMX週間前の過去の自分を念頭に置いて作成しました。これは、この旅を始めた当時に持っていたかったチュートリアルです。 その意味で、このチュートリアルの対象読者は、AI / MLに精通しており、以前にTransformerモデルを使用したことがあるが、テキスト要約の旅の始まりであり、さらに深く掘り下げたいと考えている人です。 「初心者」と初心者向けに書かれているので、このチュートリアルが a 実用ガイド–ではありません 実用ガイド。 まるで扱ってください ジョージEPボックス 言っていました:
![]()
このチュートリアルで必要な技術的知識の量に関して:Pythonでのコーディングが含まれますが、ほとんどの場合、コードを使用してAPIを呼び出すだけなので、コーディングに関する深い知識も必要ありません。 MLの特定の概念(意味など)に精通していると役立ちます。 列車 & 展開します モデル、の概念 トレーニング, , テストデータセット、 等々。 また、に手を出した Transformersライブラリ このチュートリアル全体でこのライブラリを広範囲に使用するため、beforeが役立つ場合があります。 また、これらの概念をさらに読むための便利なリンクも含まれています。
このチュートリアルは初心者によって作成されているため、NLPの専門家や高度なディープラーニングの実践者がこのチュートリアルの多くを習得することは期待していません。 少なくとも技術的な観点からではありませんが、それでも読むことを楽しむことができるかもしれませんので、まだ離れないでください! しかし、私の単純化に関しては辛抱強くなければなりません。私は、このチュートリアルのすべてを可能な限り単純にするという概念に従って生きようとしましたが、単純ではありません。
このチュートリアルの構造
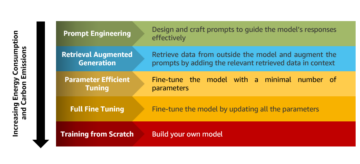
このシリーズは、1つの投稿に分割されたXNUMXつのセクションにまたがっており、テキスト要約プロジェクトのさまざまな段階を経ています。 最初の投稿(セクションXNUMX)では、テキスト要約タスクのメトリックを紹介することから始めます。これは、要約が良いか悪いかを評価できるパフォーマンスの尺度です。 また、要約するデータセットを紹介し、MLなしのモデルを使用してベースラインを作成します。単純なヒューリスティックを使用して、特定のテキストから要約を生成します。 このベースラインを作成することは、今後のAIを使用してどの程度の進歩を遂げるかを定量化できるため、MLプロジェクトで非常に重要なステップです。 「AI技術に投資する価値は本当にあるのか」という質問に答えることができます。
2番目の投稿では、要約を生成するために事前にトレーニングされたモデルを使用します(セクションXNUMX)。 これは、MLの最新のアプローチで可能です。 転移学習。 基本的に既成のモデルを取得してデータセットでテストするため、これはもうXNUMXつの便利な手順です。 これにより、別のベースラインを作成できます。これは、データセットでモデルを実際にトレーニングしたときに何が起こるかを確認するのに役立ちます。 アプローチは呼ばれます ゼロショット要約、モデルのデータセットへの露出がゼロであるため。
その後、事前にトレーニングされたモデルを使用して、独自のデータセットでトレーニングします(セクション3)。 これは、 微調整。 これにより、モデルはデータのパターンと特異性から学習し、ゆっくりとそれに適応することができます。 モデルをトレーニングした後、それを使用して要約を作成します(セクション4)。
要約すると:
- 一部1:
- セクション1:非MLモデルを使用してベースラインを確立する
- 第2部:
- セクション2:ゼロショットモデルを使用して要約を生成する
- セクション3:要約モデルをトレーニングする
- セクション4:トレーニング済みモデルを評価する
このチュートリアルのコード全体は、次の場所にあります。 GitHubレポ.
このチュートリアルの終わりまでに何を達成しますか?
このチュートリアルの終わりまでに、 しません 本番環境で使用できるテキスト要約モデルがあります。 私たちも持っていません 良い 要約モデル(ここに悲鳴の絵文字を挿入)!
代わりに、プロジェクトの次のフェーズである実験フェーズの開始点を用意します。 ここでデータサイエンスの「科学」が登場します。これは、さまざまなモデルとさまざまな設定を試して、利用可能なトレーニングデータを使用して十分な要約モデルをトレーニングできるかどうかを理解するためです。
そして、完全に透明にするために、技術がまだ熟しておらず、プロジェクトが実施されないという結論になる可能性が高いです。 そして、その可能性に備えてビジネスの利害関係者を準備する必要があります。 しかし、それは別の投稿のトピックです。
セクション1:非MLモデルを使用してベースラインを確立する
これは、テキスト要約プロジェクトの設定に関するチュートリアルの最初のセクションです。 このセクションでは、実際にMLを使用せずに、非常に単純なモデルを使用してベースラインを確立します。 これは、MLプロジェクトで非常に重要なステップです。これにより、MLがプロジェクトの期間中にどれだけの価値を追加し、それに投資する価値があるかを理解できるようになります。
チュートリアルのコードは次の場所にあります GitHubレポ.
データ、データ、データ
すべてのMLプロジェクトはデータから始まります! 可能であれば、テキスト要約プロジェクトで達成したいことに関連するデータを常に使用する必要があります。 たとえば、特許出願を要約することが目標である場合は、モデルのトレーニングにも特許出願を使用する必要があります。 MLプロジェクトの大きな注意点は、通常、トレーニングデータにラベルを付ける必要があることです。 テキストの要約のコンテキストでは、要約(ラベル)だけでなく、要約するテキストも提供する必要があることを意味します。 両方を提供することによってのみ、モデルは適切な要約がどのように見えるかを学習できます。
このチュートリアルでは、公開されているデータセットを使用しますが、カスタムデータセットまたはプライベートデータセットを使用する場合、手順とコードはまったく同じです。 また、テキスト要約モデルの目的を念頭に置いており、対応するデータがある場合は、代わりにデータを使用して、これを最大限に活用してください。
私たちが使用するデータは arXivデータセット、arXiv論文の要約とそのタイトルが含まれています。 私たちの目的のために、要約したいテキストとして要約を使用し、参照要約としてタイトルを使用します。 データをダウンロードして前処理するすべての手順は、次の場所で利用できます。 ノート。 必要です AWS IDおよびアクセス管理 (IAM)データのロードを許可する役割 Amazon シンプル ストレージ サービス (Amazon S3)このノートブックを正常に実行するため。 データセットは論文の一部として開発されました データセットとしてのArXivの使用について との下でライセンスされています Creative CommonsCC0ユニバーサルパブリックドメインの献身.
データは、トレーニング、検証、テストデータのXNUMXつのデータセットに分割されます。 独自のデータを使用する場合は、これも当てはまるようにしてください。 次の図は、さまざまなデータセットの使用方法を示しています。
![]()
当然、この時点でよくある質問は次のとおりです。どのくらいのデータが必要ですか。 おそらくすでに推測できるように、答えは次のとおりです。それは状況によって異なります。 それは、ドメインがどれほど専門的であるか(特許出願の要約はニュース記事の要約とはまったく異なります)、モデルが有用であるために必要な正確さ、モデルのトレーニングにかかる費用などによって異なります。 後で実際にモデルをトレーニングするときにこの質問に戻りますが、プロジェクトの実験段階では、さまざまなデータセットサイズを試してみる必要があります。
何が良いモデルになりますか?
多くのMLプロジェクトでは、モデルのパフォーマンスを測定するのはかなり簡単です。 これは、通常、モデルの結果が正しいかどうかについてはほとんどあいまいさがないためです。 データセット内のラベルは、多くの場合、バイナリ(True / False、Yes / No)またはカテゴリです。 いずれにせよ、このシナリオでは、モデルの出力をラベルと比較して、それを正しいまたは正しくないものとしてマークするのは簡単です。
テキストを生成するとき、これはより困難になります。 データセットで提供する要約(ラベル)は、テキストを要約する1つの方法にすぎません。 しかし、与えられたテキストを要約する多くの可能性があります。 したがって、モデルがラベル1:XNUMXと一致しない場合でも、出力は有効で有用な要約である可能性があります。 では、モデルの要約を私たちが提供するものとどのように比較しますか? モデルの品質を測定するためにテキスト要約で最も頻繁に使用されるメトリックは、 ROUGEスコア。 このメトリックの仕組みを理解するには、を参照してください。 NLPの究極のパフォーマンスメトリック。 要約すると、ROUGEスコアは N-グラム (連続したシーケンス n アイテム)モデルの要約(候補の要約)と参照の要約(データセットで提供するラベル)の間。 しかし、もちろん、これは完璧な手段ではありません。 その制限を理解するには、チェックアウトしてください ルージュするかしないか?
では、ROUGEスコアをどのように計算するのでしょうか。 このメトリックを計算するためのPythonパッケージはかなりたくさんあります。 一貫性を確保するために、プロジェクト全体で同じ方法を使用する必要があります。 このチュートリアルの後半で、独自のスクリプトを作成する代わりに、Transformersライブラリのトレーニングスクリプトを使用するため、 ソースコード スクリプトを作成し、ROUGEスコアを計算するコードをコピーします。
この方法を使用してスコアを計算することにより、プロジェクト全体で常にリンゴとリンゴを比較することができます。
この関数は、いくつかのROUGEスコアを計算します。 rouge1, rouge2, rougeL, rougeLsum。 の「合計」 rougeLsum このメトリックは要約全体にわたって計算されるという事実を指しますが、 rougeL 個々の文の平均として計算されます。 では、プロジェクトに使用する必要があるROUGEスコアはどれですか? 繰り返しになりますが、実験段階ではさまざまなアプローチを試す必要があります。 それが価値があるもののために、 オリジナルROUGEペーパー 「ROUGE-2とROUGE-Lは単一のドキュメント要約タスクでうまく機能した」と述べていますが、「ROUGE-1とROUGE-Lは短い要約の評価に優れています」と述べています。
ベースラインを作成する
次に、単純な非MLモデルを使用してベースラインを作成します。 どういう意味ですか? テキスト要約の分野では、多くの研究が非常に単純なアプローチを使用しています。 n テキストの文とそれを候補の要約として宣言します。 次に、候補の要約を参照の要約と比較し、ROUGEスコアを計算します。 これは、数行のコードで実装できるシンプルで強力なアプローチです(この部分のコード全体は次のとおりです。 ノート):
この評価にはテストデータセットを使用します。 モデルをトレーニングした後、最終評価にも同じテストデータセットを使用するため、これは理にかなっています。 また、別の番号を試してみます n:候補の要約として最初の文のみから始め、次に最初のXNUMXつの文、最後に最初のXNUMXつの文から始めます。
次のスクリーンショットは、最初のモデルの結果を示しています。
![]()
ROUGEスコアが最も高く、候補の要約として最初の文のみが含まれます。 これは、複数の文を使用すると、要約が冗長になりすぎて、スコアが低くなることを意味します。 つまり、XNUMX文の要約のスコアをベースラインとして使用するということです。
このような単純なアプローチの場合、これらの数値は実際には非常に優れていることに注意することが重要です。 rouge1 スコア。 これらの数値をコンテキストに入れるために、参照することができます ペガサスモデル、さまざまなデータセットの最先端モデルのスコアを示します。
結論と次のこと
シリーズのパート1では、要約プロジェクト全体で使用するデータセットと、要約を評価するためのメトリックを紹介しました。 次に、単純な非MLモデルを使用して次のベースラインを作成しました。
![]()
次の投稿、ゼロショットモデルを使用します。具体的には、公開ニュース記事のテキスト要約用に特別にトレーニングされたモデルです。 ただし、このモデルはデータセットでまったくトレーニングされません(そのため、「ゼロショット」という名前が付けられています)。
このゼロショットモデルが私たちの非常に単純なベースラインと比較してどのように機能するかを推測するのは宿題としてあなたに任せます。 一方では、それははるかに洗練されたモデルになります(実際にはニューラルネットワークです)。 一方、ニュース記事の要約にのみ使用されるため、arXivデータセットに固有のパターンに苦労する可能性があります。
著者について
![]() ヘイコ・ホッツ AIと機械学習のシニアソリューションアーキテクトであり、AWS内の自然言語処理(NLP)コミュニティをリードしています。 この役職に就く前は、AmazonのEUカスタマーサービスのデータサイエンス責任者を務めていました。 Heikoは、お客様がAWSでAI / MLの旅を成功させるのを支援し、保険、金融サービス、メディアとエンターテインメント、ヘルスケア、公益事業、製造業など、多くの業界の組織と協力してきました。 余暇には、平子は可能な限り旅をします。
ヘイコ・ホッツ AIと機械学習のシニアソリューションアーキテクトであり、AWS内の自然言語処理(NLP)コミュニティをリードしています。 この役職に就く前は、AmazonのEUカスタマーサービスのデータサイエンス責任者を務めていました。 Heikoは、お客様がAWSでAI / MLの旅を成功させるのを支援し、保険、金融サービス、メディアとエンターテインメント、ヘルスケア、公益事業、製造業など、多くの業界の組織と協力してきました。 余暇には、平子は可能な限り旅をします。
- '
- "
- &
- 100
- 2020
- 私たちについて
- 抽象
- アクセス
- 正確な
- 達成
- 高度な
- 進歩
- AI
- すべて
- 既に
- Amazon
- 曖昧さ
- 金額
- 別の
- API
- 申し込み
- アプローチ
- 周りに
- 宝品
- 記事
- 物品
- 聴衆
- 利用できます
- 平均
- AWS
- ベースライン
- 基本的に
- 開始
- さ
- ビジネス
- コール
- これ
- キャッチ
- 挑戦する
- コード
- コーディング
- コマンドと
- コミュニティ
- 企業
- 比べ
- 完全に
- 計算
- コンセプト
- 含まれています
- コンテンツ
- 契約
- 作成
- カスタム
- 顧客サービス
- Customers
- データ
- データサイエンス
- より深い
- 発展した
- 異なります
- ドキュメント
- そうではありません
- ドメイン
- エンターテインメント
- 特に
- 確立する
- EU
- すべてのもの
- 例
- 期待する
- 専門家
- 目
- 顔
- フィールズ
- 最後に
- ファイナンシャル
- 金融業務
- 名
- フォロー中
- フォワード
- 発見
- function
- さらに
- ゲーム
- 生成する
- 世代
- 目標
- 行く
- 良い
- 素晴らしい
- 保護者
- ガイド
- 持って
- ヘルスケア
- 役立つ
- ことができます
- こちら
- 雇う
- 認定条件
- HTTPS
- 巨大な
- アイデンティティ
- 実装する
- 実装
- 重要
- include
- 含めて
- 個人
- 産業
- 保険
- 導入
- 投資
- IT
- ジョブ
- 7月
- キー
- 知識
- ラベル
- 言語
- 最新の
- リード
- LEARN
- 学習
- コメントを残す
- リーガルポリシー
- 図書館
- ライセンス供与
- リンク
- 少し
- 機械
- 機械学習
- 作る
- 作成
- 製造業
- マーク
- 一致
- だけど
- メディア
- マインド
- ML
- モデル
- 他には?
- 最も
- ナチュラル
- ネットワーク
- ニュース
- ノート
- 番号
- 開いた
- 注文
- 組織
- その他
- 紙素材
- 特許
- のワークプ
- パフォーマンス
- 視点
- 相
- ポイント
- の可能性
- 可能性
- 可能
- 投稿
- 潜在的な
- 強力な
- プライベート
- 生産
- プロジェクト
- プロジェクト(実績作品)
- 提案する
- 提供します
- 提供
- 公共
- 目的
- 品質
- 質問
- 範囲
- RE
- リーディング
- レポート
- 必要とする
- の提出が必要です
- 研究
- 結果
- ラン
- 前記
- 科学
- センス
- シリーズ
- サービス
- サービス
- セッションに
- 設定
- ショート
- 簡単な拡張で
- So
- ソリューション
- 誰か
- 何か
- 洗練された
- スペース
- スペース
- 専門の
- 専門にする
- 特に
- split
- start
- 開始
- 開始
- 最先端の
- 米国
- ストレージ利用料
- ストレス
- 研究
- 成功した
- 首尾よく
- Talk
- ターゲット
- タスク
- 技術的
- テクノロジー
- test
- 数千
- 介して
- 全体
- 時間
- 役職
- トレーニング
- トランスペアレント
- 治療する
- 究極の
- わかる
- ユニバーサル
- us
- つかいます
- 通常
- 値
- wait
- この試験は
- かどうか
- 誰
- Wikipedia
- 以内
- 無し
- 仕事
- 働いていました
- 価値
- 書き込み
- X
- ゼロ