ETLとは何ですか?
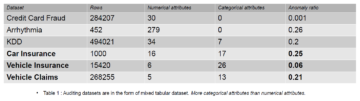
ETL は、複数のソース システムからデータを抽出し、(計算や連結などを通じて) それを変更し、データ ウェアハウス システムに入れるプロセスです。 ETL は、抽出、変換、ロードの略です。
データ ウェアハウスの構築は、多数のソースからデータを取得してデータ ウェアハウス データベースに入力するだけと同じくらい簡単だと思われがちです。 これは事実とは程遠く、複雑な ETL 手順が必要です。 ETL プロセスは技術的に複雑であり、開発者、アナリスト、テスター、上級幹部など、さまざまな関係者が積極的に参加する必要があります。
意思決定ツールとしての価値を維持するには、データ ウェアハウス システムはビジネスの発展と同期して開発する必要があります。 ETL はデータ ウェアハウス システムの定期的な (日次、週次、月次) プロセスであり、俊敏性があり、自動化され、適切に文書化されている必要があります。

ETLはどのように機能しますか?
ここでは、ETL プロセスがどのように機能するかを段階的に学習します。
ステップ1) 抽出
データはソース システムから抽出され、抽出中にステージング領域に配置されます。 変換が必要な場合は、ソース システムのパフォーマンスが損なわれないように、ステージング領域で実行されます。 破損したデータがソースからデータ ウェアハウス データベースに直接転送された場合、ロールバックは困難になります。 抽出されたデータをデータ ウェアハウスに移動する前に、ステージング領域で検証できます。
データ ウェアハウスは、さまざまなハードウェア、データベース管理システム、オペレーティング システム、通信プロトコルを備えたシステムを組み合わせることができます。 データ ウェアハウスでは、システムを異種の DBMS、ハードウェア、オペレーティング システム、および通信プロトコルと組み合わせる必要があります。 ソースには、メインフレームなどのレガシー プログラム、カスタマイズされたアプリケーション、ATM やコール交換機などの POS デバイス、テキスト ファイル、スプレッドシート、ERP、ベンダーやパートナーからのデータなどが含まれる場合があります。
したがって、データを抽出して物理的にロードする前に、論理データ マップが必要です。 ソース データとターゲット データの間の接続は、このデータ マップに示されています。
XNUMX つのデータ抽出方法:
- 部分抽出 – レコードが変更されたときにソース システムから警告が表示される場合、それがデータを取得する最も簡単な方法です。
- 部分抽出(更新通知なし) – すべてのシステムが更新の発生時に通知を配信できるわけではありません。 ただし、変更されたレコードを示し、それらのレコードの抽出を提供することはできます。
- 完全な抽出 – 特定のシステムでは、どのデータが変更されたかをまったく判断できません。 このシナリオでは、システムからデータを取得する唯一の方法は、完全抽出を実行することです。 この方法では、以前の抽出のバックアップが必要です。
行われた変更を確認するために、同じフォーマットを手元に用意してください。
採用された方法に関係なく、抽出はソース システムのパフォーマンスや応答時間に影響を与えてはなりません。 これらはリアルタイムの実稼働データベースです。 速度の低下やロックが発生すると、会社の収益に影響を与える可能性があります。
ステップ2) 変換
ソースサーバーから取得したデータは生データであり、元の状態では使用できません。 その結果、クリーンアップ、マッピング、および変換する必要があります。 実際には、これは、ETL プロセスが価値を追加し、有意義な BI レポートを作成するためにデータを変換する重要なステップです。
これは、抽出されたデータに関数のコレクションを適用するという ETL の重要な概念です。 直接移動 or データを通過するa は、変換を必要としないデータのタイプです。
変換ステップ中に、データに対してカスタマイズされた操作を実行できます。 たとえば、クライアントがデータベースに存在しない売上合計を求めているとします。 または、テーブル内の姓と名が別の列にある場合。 ロードする前に、それらを連結することができます。
データの整合性の問題の例をいくつか次に示します。
- Prashant、Parshant など、同じ個人の異なるスペル。
- Google、Google Inc など、会社名を表す方法はたくさんあります。
- クリーブランドやクリーブランドなど、さまざまな名前が使用されます。
- 同じクライアントの異なるアプリケーションによって複数の口座番号が生成される可能性があります。
- 一部のデータが必要なファイルは空白のままです。
ステップ 3) 読み込み
ETL プロセスの最終段階は、ターゲットのデータ ウェアハウス データベースにデータをロードすることです。 一般的なデータ ウェアハウスでは、大量のデータが比較的短期間にロードされます。 その結果、ロード プロセスはパフォーマンスを最適化する必要があります。
ロード障害が発生した場合、データの整合性を損なうことなく障害が発生した時点から操作を再開できるように、リカバリ手順を導入する必要があります。 データ ウェアハウス管理者は、サーバーのパフォーマンスに基づいて負荷を監視、継続、停止する必要があります。
積載の種類:
- 初期負荷 — すべてを埋める
データ ウェアハウス テーブル - 増分ロード — 継続的に実施
必要に応じて定期的に変更を加える - フルリフレッシュ — コンテンツのクリア
XNUMX つ以上のテーブルの新しいデータを再ロードする
負荷検証
- キー フィールドのデータが欠落していないか、または null になっていないことを確認してください。
- ターゲットテーブルに基づいたビューのモデリングをテストする必要があります。
- 結合された値3 と計算されたメジャーを調べます。
- ディメンション テーブルと履歴テーブルのデータ チェック。
- ロードされたファクトおよびディメンション テーブルに関する BI レポートを調べます。
PythonScript を使用した ETL のセットアップ
その結果、ビジネス インテリジェンスのためのデータ集約を行うには、複数のデータベースからデータ ウェアハウスへの基本的な抽出変換ロード (ETL) を実行する必要があります。 基本的なユースケースには多すぎると思われる、利用可能な ETL パッケージがいくつかあります。
この記事では、MySQL、SQL-server、Firebird からデータを抽出する方法を説明します。 Python 3.6 を使用してデータを変換し、SQL サーバー (データ ウェアハウス) に読み込みます。
まず最初に、プロジェクト用のディレクトリを作成する必要があります。
python_etl |__main.py |__db_credentials.py |__variables.py |__sql_queries.py |__etl.py
Python を使用して ETL を設定するには、プロジェクト ディレクトリに次のファイルを生成する必要があります。.
- db_credentials.py: すべてのデータベースに接続するために必要な情報がすべて含まれている必要があります。 データベースのパスワード、ポート番号など。
- sql_queries.py: 文字列形式でデータを抽出およびロードするために一般的に使用されるデータベース クエリがすべて利用可能である必要があります。
- etl.py: データベースに接続し、必要な手順をすべて実行して必要なクエリを実行します。
- main.py: 操作の流れを管理し、指定された順序で重要な操作を実行する責任を負います。
sql_queries.py のこのセクションでは、ソース データベースから抽出してターゲット データベース (データ ウェアハウス) にインポートするためにすべての SQL クエリを保存する場所です。
データベースの資格情報と変数のセットアップ
variables.py で、ベースの名前を記録する変数を作成します。
データウェアハウス名 = 'あなたのデータウェアハウス名'
以下に示すように、db_credentials.py でソースおよびターゲットのデータベース接続文字列と資格情報をすべて構成します。 構成をリストとして保存すると、後で必要なときにいつでも多くのデータベースで構成を反復できるようになります。
from 変数 import datawarehouse_name datawarehouse_name = 'your_datawarehouse_name' # sql-server (ターゲット データベース、データウェアハウス) datawarehouse_db_config = { 'Trusted_Connection': 'yes', 'driver': '{SQL Server}', 'server': 'datawarehouse_sql_server', 'データベース': '{}'.format(datawarehouse_name), 'user': 'your_db_username', 'password': 'your_db_password', 'autocommit': True, } # sql-server (ソース データベース) sqlserver_db_config = [ { 'Trusted_Connection ': 'はい'、'ドライバー': '{SQL Server}'、'サーバー': 'your_sql_server'、'database': 'db1'、'user': 'your_db_username'、'password': 'your_db_password'、' autocommit': True, } ] # mysql (ソース データベース) mysql_db_config = [ { 'user': 'your_user_1', 'password': 'your_password_1', 'host': 'db_connection_string_1', 'database': 'db_1', } , { 'user': 'your_user_2', 'password': 'your_password_2', 'host': 'db_connection_string_2', 'database': 'db_2', }, ] # firebird (source db) fdb_db_config = [ { 'dsn' : "/your/path/to/source.db", 'user': "your_username", 'password': "your_password", } ]
SQLクエリ
sql_queries.py のこのセクションでは、ソース データベースから抽出してターゲット データベース (データ ウェアハウス) にインポートするためにすべての SQL クエリを保存する場所です。
複数のデータ プラットフォームを使用しているため、データベースごとにさまざまな構文を実装する必要があります。 これは、データベースの種類に基づいてクエリを分離することで実現できます。
# クエリの例は、DB プラットフォームごとに異なります firebird_extract = (''' SELECT fbd_column_1, fbd_column_2, fbd_column_3 FROM fbd_table; ''') firebird_insert = (''' INSERT INTO table (column_1, column_2, column_3) VALUES (?, ?, ?) '') firebird_extract_2 = ('''' SELECT fbd_column_1, fbd_column_2, fbd_column_3 FROM fbd_table_2; '') firebird_insert_2 = ('''' INSERT INTO table_2 (column_1, column_2, column_3) VALUES (?, ?, ? ) ''') sqlserver_extract = (''' SELECT sqlserver_column_1、sqlserver_column_2、sqlserver_column_3 FROM sqlserver_table ''') sqlserver_insert = (''' INSERT INTO table (column_1、column_2、column_3) VALUES (?, ?, ?) ''' ) mysql_extract = (''' SELECT mysql_column_1, mysql_column_2, mysql_column_3 FROM mysql_table ''') mysql_insert = (''' INSERT INTO table (column_1, column_2, column_3) VALUES (?, ?, ?) ''') # クエリのエクスポートclass SqlQuery: def __init__(self, extract_query,load_query): self.extract_query = extract_query self.load_query =load_query # SqlQuery のインスタンスを作成します class fbd_query = SqlQuery(firebird_extract, firebird_insert) fbd_query_2 = SqlQuery(firebird_extract_2, firebird_insert_2) sqlserver_query = SqlQuery(sqlserver_extract , sqlserver_insert) mysql_query = SqlQuery(mysql_extract, mysql_insert) # 反復用のリストとして保存 fbd_queries = [fbdquery, fbd_query_2] sqlserver_queries = [sqlserver_query] mysql_queries = [mysql_query]
抽出、変換、ロード
上記のデータ ソースに対して Python を使用して ETL を設定するには、次のモジュールが必要です。
# Python モジュール import mysql.connector import pyodbc import fdb # 変数からの変数 import datawarehouse_name
これには、etl() と etl_process() という XNUMX つの手法を使用できます。
etl_process() は、データベース ソース接続を確立し、データベース プラットフォームに基づいて etl() メソッドを呼び出すためのプロシージャです。
XNUMX 番目のメソッドである etl() メソッドでは、最初に抽出クエリを実行し、次に SQL データを変数データに格納し、それをターゲットのデータベース (データ ウェアハウス) に挿入します。 データ変換は、タプル型のデータ変数を変更することによって実現できます。
def etl(query, source_cnx, target_cnx): # ソース データベースからデータを抽出します。 source_cursor = source_cnx.cursor() source_cursor.execute(query.extract_query) data = source_cursor.fetchall() source_cursor.close() # ウェアハウス データベースにデータをロードします。データ: target_cursor = target_cnx.cursor() target_cursor.execute("USE {}".format(datawarehouse_name)) target_cursor.executemany(query.load_query, data) print('データをウェアハウス データベースにロードしました') target_cursor.close() else : print('データは空です') def etl_process(queries, target_cnx, source_db_config, db_platform): # ソース DB 接続を確立します if db_platform == 'mysql': source_cnx = mysql.connector.connect(**source_db_config) elif db_platform == 'sqlserver':source_cnx = pyodbc.connect(**source_db_config) elif db_platform == 'firebird':source_cnx = fdb.connect(**source_db_config) else: return 'エラー! 認識されないデータベース プラットフォーム' # クエリ内のクエリの SQL クエリをループします: etl(query, source_cnx, target_cnx) # ソース データベース接続を閉じますsource_cnx.close()
すべてをまとめる
次のステップでは、main.py 内のすべての資格情報をループし、すべてのデータベースに対して etl を実行します。
そのためには、必要な変数とメソッドをすべてインポートする必要があります。
# db_credentials からの変数 import datawarehouse_db_config, sqlserver_db_config, mysql_db_config, fbd_db_config from sql_queries import fbd_queries, sqlserver_queries, mysql_queries from 変数 import * # etl からのメソッド import etl_process
このファイル内のコードは、データベースに接続し、Python を使用して必要な ETL 操作を実行するために資格情報を反復処理する役割を果たします。
def main(): print('starting etl') # ターゲットデータベース (sql-server) への接続を確立します target_cnx = pyodbc.connect(**datawarehouse_db_config) # 認証情報をループします # mysql for config in mysql_db_config: try: print("loading db: " + config['database']) etl_process(mysql_queries, target_cnx, config, 'mysql') 例外としてエラーが発生しました: print("etl for {} has error".format(config['database'])) print ('エラー メッセージ: {}'.format(error)) 続行 # sql-server for config in sqlserver_db_config: try: print("loading db: " + config['database']) etl_process(sqlserver_queries, target_cnx, config, ' sqlserver') 例外としてエラーとして例外が発生します: print("etl for {} has error".format(config['database'])) print('error message: {}'.format(error)) continue # firebird for config in fbd_db_config: try: print("loading db: " + config['database']) etl_process(fbd_queries, target_cnx, config, 'firebird') 例外としてエラーが発生しました: print("etl for {} has error".format(config ['データベース'])) print('エラーメッセージ: {}'.format(error)) 続行 target_cnx.close() if __name__ == "__main__": main()
ターミナルで「python main.py」と入力すると、純粋な Python スクリプトを使用して ETL が作成されました。
ETLツール
市場にはいくつかのデータ ウェアハウジング ツールがあります。 最も有名な例をいくつか示します。
1.マークロジック:
MarkLogic は、さまざまなビジネス機能を使用してデータ統合をより簡単かつ迅速に行うデータ ウェアハウジング システムです。 ドキュメント、関係、メタデータなど、さまざまな種類のデータをクエリできます。
https://www.marklogic.com/product/getting-started/
2. オラクル:
Oracle は業界で最も人気のあるデータベースです。 オンプレミスとクラウド サービスの両方に向けて、多種多様なデータ ウェアハウス ソリューションを提供します。 運用効率を向上させることで、クライアント エクスペリエンスの向上に役立ちます。
https://www.oracle.com/index.html
3. Amazon RedShift:
Redshift は、Amazon のデータ ウェアハウジング ソリューションです。 これは、標準 SQL と既存のビジネス インテリジェンス ツールを使用してさまざまな種類のデータを分析するための、シンプルでコスト効率の高いソリューションです。 また、ペタバイト規模の構造化データに対する複雑なクエリの実行も可能になります。
https://aws.amazon.com/redshift/?nc2=h_m1
まとめ
この記事では、ETL とは何かを深く理解するとともに、Python で ETL を設定する方法についてのステップバイステップのチュートリアルを提供しました。 また、現在ほとんどの組織が ETL データ パイプラインを構築するために使用している最も優れたツールのリストも提供されました。
一方、今日のほとんどの組織は、非常に動的な構造を持つ大量のデータを保有しています。 このようなデータ用に ETL パイプラインを最初から作成するのは困難な手順です。組織はこのパイプラインを作成し、大量のデータとスキーマの変更に確実に対応できるようにするために大量のリソースを使用する必要があるからです。
著者について
Prashant Sharma
現在、私はヴェールール工科大学で技術学士号 (B.Tech) の取得を目指しています。 私はプログラミングと、ソフトウェア開発、機械学習、深層学習、データ サイエンスなどの実際のアプリケーションに非常に熱心です。
記事を気に入っていただければ幸いです。 私とつながりたい場合は、次の場所に接続できます。
または他の疑問については、あなたはすることができます メールを送る 私にも
関連記事
- '
- "
- アクティブ
- すべて
- Amazon
- 分析論
- AREA
- 記事
- 自動化
- バックアップ
- 後押し
- ビルド
- 建物
- ビジネス
- ビジネス・インテリジェンス
- コール
- 小切手
- クリーブランド
- クラウド
- クラウドサービス
- コード
- コミュニケーション
- 会社
- 接続
- 続ける
- 作成
- Credentials
- データ
- データ統合
- データサイエンス
- データウェアハウス
- データウェアハウス
- データベース
- データベースを追加しました
- 深い学習
- 開発する
- 開発者
- 開発
- Devices
- 次元
- ドキュメント
- ドライバー
- 効率
- 等
- 実行
- 幹部
- エクスペリエンス
- 抽出
- 抽出物
- 不良解析
- 名
- フロー
- 形式でアーカイブしたプロジェクトを保存します.
- 新鮮な
- フル
- でログイン
- ガイド
- Hardware
- こちら
- ハイ
- history
- 認定条件
- How To
- HTTPS
- 識別する
- 影響
- インポート
- 含めて
- 情報
- 統合
- インテリジェンス
- 問題
- IT
- キー
- 大
- LEARN
- 学習
- LINE
- リスト
- 負荷
- 機械学習
- 管理
- 地図
- 市場
- メディア
- 一番人気
- 名
- 通知
- 番号
- オファー
- オペレーティング
- OS
- 業務執行統括
- オラクル
- 注文
- 組織
- その他
- パートナー
- パスワード
- パフォーマンス
- プラットフォーム
- プラットフォーム
- 人気
- 生産された
- 生産
- プログラミング
- プログラム
- プロジェクト
- 引き
- Python
- Raw
- への
- 現実
- 記録
- 回復
- の関係
- レポート
- リソース
- 応答
- 収入
- 科学
- サービス
- セッションに
- ショート
- 簡単な拡張で
- So
- ソフトウェア
- ソフトウェア開発
- ソリューション
- SQL
- ステージ
- 都道府県
- 店舗
- 店舗
- システム
- ターゲット
- テク
- テクニック
- テクノロジー
- ソース
- 時間
- 変換
- チュートリアル
- アップデイト
- 値
- ベンダー
- ボリューム
- 倉庫
- 倉庫保管
- weekly
- 仕事
- 作品