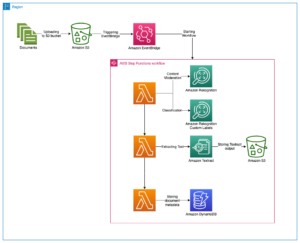
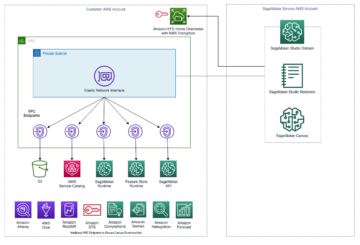
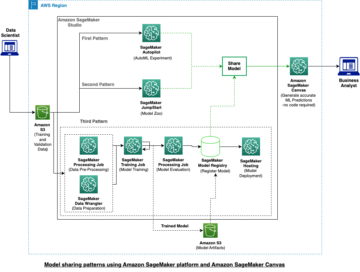
言語モデルは、自然なテキストを使用して、シーケンス内のトークンの連続を予測する統計的手法です。 大規模言語モデル (LLM) は、数億 (ベルト) 兆を超えるパラメータ (MiCS)、そのサイズはシングル GPU トレーニングを非現実的にします。 LLM の生成能力により、LLM はテキスト合成、要約、機械翻訳などで人気があります。
LLM とそのトレーニング データのサイズは両刃の剣です。モデリングの品質は向上しますが、インフラストラクチャの課題が伴います。 多くの場合、モデル自体が大きすぎて、単一の GPU デバイスのメモリまたはマルチ GPU インスタンスの複数のデバイスに収まりません。 これらの要因により、加速された機械学習 (ML) インスタンスの大規模なクラスターで LLM をトレーニングする必要があります。 ここ数年、多くのお客様が AWS クラウドを LLM トレーニングに使用しています。
この投稿では、LLM トレーニングを成功させるためのヒントとベスト プラクティスについて詳しく説明します。 Amazon SageMaker トレーニング. SageMaker Training は、マネージド バッチ ML コンピューティング サービスであり、インフラストラクチャを管理する必要なく、モデルを大規模にトレーニングおよび調整するための時間とコストを削減します。 XNUMX つの起動コマンド内で、 アマゾンセージメーカー 選択したタスクを実行し、メタストア、マネージド I/O、分散などの強化された ML 機能を備えた、完全に機能する一時的なコンピューティング クラスターを起動します。 この投稿では、LLM トレーニング ワークロードのすべてのフェーズをカバーし、関連するインフラストラクチャ機能とベスト プラクティスについて説明します。 この投稿のベスト プラクティスの一部は特に ml.p4d.24xlarge インスタンスに言及していますが、ほとんどはどのインスタンス タイプにも適用できます。 これらのベストプラクティスにより、数十から数億のパラメーターのスケールで SageMaker で LLM をトレーニングできます。
この投稿の範囲に関しては、次の点に注意してください。
- ニューラル ネットワークの科学的設計と関連する最適化については説明しません。 アマゾン・サイエンス 以下を含むがこれらに限定されない多数の科学出版物を特集しています LLM.
- この投稿では LLM に焦点を当てていますが、そのベスト プラクティスのほとんどは、コンピューター ビジョンや Stable Diffusion などのマルチモーダル モデルを含む、あらゆる種類の大規模モデル トレーニングに関連しています。
ベストプラクティス
この投稿では、次のベスト プラクティスについて説明します。
- 計算 – SageMaker Training は、CPU データセットの準備ジョブと千規模の GPU ジョブを起動するための優れた API です。
- Storage – データのロードとチェックポイントは、スキルと好みに応じて XNUMX つの方法で行われます。 Amazon FSx 光沢 ファイルシステム、または Amazon シンプル ストレージ サービス (Amazon S3) のみ。
- 平行度 – 分散トレーニング ライブラリの選択は、GPU を適切に使用するために重要です。 SageMaker シャード データ並列処理など、クラウドに最適化されたライブラリを使用することをお勧めしますが、セルフマネージド ライブラリやオープンソース ライブラリも機能します。
- ネットワーキング – 高速なマシン間通信のために、EFA と NVIDIA GPUDirectRDMA が有効になっていることを確認します。
- 回復力 – 大規模な場合、ハードウェア障害が発生する可能性があります。 定期的にチェックポイントを設定することをお勧めします。 数時間おきが一般的です。
地域選択
インスタンスタイプと必要な容量は、リージョン選択の決定要因です。 SageMaker でサポートされているリージョンと アマゾン エラスティック コンピューティング クラウド 各リージョンで利用可能な (Amazon EC2) インスタンス タイプについては、を参照してください。 Amazon SageMakerの価格. この投稿では、トレーニング インスタンス タイプが SageMaker 管理の ml.p4d.24xlarge であると想定しています。
AWS アカウントチームと協力するか、連絡することをお勧めします AWS セールス LLM ワークロードに適したリージョンを決定します。
データの準備
LLM 開発者は、自然に発生するテキストの大規模なデータセットでモデルをトレーニングします。 このようなデータ ソースの一般的な例としては、 一般的なクロール & パイル. 自然に発生するテキストには、バイアス、不正確さ、文法上の誤り、および構文のバリエーションが含まれる場合があります。 LLM の最終的な品質は、トレーニング データの選択とキュレーションに大きく依存します。 LLM トレーニング データの準備は、LLM 業界における研究と革新の活発な分野です。 自然言語処理 (NLP) データセットの準備には、シェアナッシング並列処理の機会がたくさんあります。 つまり、作業単位 (ソース ファイル、段落、文、単語) に適用できるステップがあり、ワーカー間の同期を必要としません。
SageMaker ジョブ API、つまり SageMaker Training と SageMaker Processing は、このタイプのタスクに優れています。 これらにより、開発者は複数のマシンのフリートで任意の Docker コンテナーを実行できます。 SageMaker Training API の場合、コンピューティング フリートは 不均質な. SageMaker では、以下を含む多数の分散コンピューティング フレームワークが使用されています。 ダスク, レイ、また パイスパーク、専用の AWS が管理するコンテナ & SDK SageMaker 処理で。
複数のマシンでジョブを起動すると、SageMaker Training and Processing はマシンごとに XNUMX 回コードを実行します。 分散アプリケーションを作成するために、特定の分散コンピューティング フレームワークを使用する必要はありません。マシンごとに XNUMX 回実行される任意のコードを作成して、シェアナッシング並列処理を実現できます。 選択したノード間通信ロジックを作成またはインストールすることもできます。
データの読み込み
トレーニング データを保存し、そのストレージから高速化されたコンピューティング ノードに移動するには、複数の方法があります。 このセクションでは、データ読み込みのオプションとベスト プラクティスについて説明します。
SageMaker のストレージと読み込みオプション
一般的な LLM データセットのサイズは、数百ギガバイトに相当する数億のテキスト トークンです。 SageMaker が管理する ml.p4d.24xlarge インスタンスのクラスターは、データセットのストレージと読み込みに関するいくつかのオプションを提案します。
- オンノード NVMe SSD – ml.P4d.24xlarge インスタンスには 8TB NVMe が搭載されており、以下で利用できます。
/opt/ml/input/data/<channel>あなたが使うなら SageMaker ファイルモード、および/tmp. ローカル読み取りのシンプルさとパフォーマンスを求めている場合は、データを NVMe SSD にコピーできます。 コピーは、SageMaker ファイルモードで行うか、マルチプロセスを使用するなどの独自のコードで行うことができます。 ボト3 or S5cmd. - 光沢のためのFSx – オンノード NVMe SSD はサイズが制限されており、各ジョブまたはウォーム クラスターの作成時に Amazon S3 からの取り込みが必要です。 低レイテンシのランダム アクセスを維持しながら、より大きなデータセットにスケーリングすることを検討している場合は、FSx for Lustre を使用できます。 Amazon FSx はオープンソースの並列ファイル システムで、ハイパフォーマンス コンピューティング (HPC) で人気があります。 FSx for Lustre の使用 分散ファイル ストレージ (ストリッピング) し、ファイル メタデータをファイル コンテンツから物理的に分離して、高性能の読み取り/書き込みを実現します。
- SageMaker FastFile モード – FastFile モード (FFM) は、SageMaker が管理するコンピューティング インスタンス内のリモート S3 オブジェクトを POSIX 準拠のインターフェイスで表示し、FUSE を使用して読み取り時にのみストリーミングする SageMaker 専用の機能です。 FFM 読み取りの結果、リモート ファイルをブロックごとにストリーミングする S3 呼び出しが発生します。 Amazon S3 トラフィックに関連するエラーを回避するためのベスト プラクティスとして、FFM 開発者は、たとえば、ファイルを順番に読み取り、並列処理の量を制御して、S3 呼び出しの基本的な数を適切に保つことを目指す必要があります。
- 自己管理データの読み込み – もちろん、プロプライエタリまたはオープンソース コードを使用して、独自の完全にカスタムのデータ読み込みロジックを実装することもできます。 自己管理型のデータ読み込みを使用する理由としては、開発済みのコードを再利用して移行を容易にしたり、カスタム エラー処理ロジックを実装したり、基になるパフォーマンスやシャーディングをより詳細に制御したりするためなどがあります。 セルフマネージド データの読み込みに使用できるライブラリの例には、次のものがあります。 トーチデータ.データパイプ (以前 AWS PyTorch S3 プラグイン)と ウェブデータセット. AWS Python SDK ボト3 と組み合わせることもできます トーチ データセット クラスを使用して、カスタム データ ロード コードを作成します。 カスタムデータローディングクラスにより、SageMaker Training の異種クラスターをクリエイティブに使用して、CPU と GPU のバランスを特定のワークロードに細かく適応させることもできます。
これらのオプションとその選択方法の詳細については、次を参照してください。 AmazonSageMakerトレーニングジョブに最適なデータソースを選択してください.
Amazon S3 との大規模なやり取りのベスト プラクティス
Amazon S3 は、データの読み取りとチェックポイントの両方で、LLM ワークロードを処理できます。 それはサポートします リクエスト率 バケット内のプレフィックスごとに 3,500 秒あたり 5,500 の PUT/COPY/POST/DELETE または 3 の GET/HEAD リクエスト。 ただし、このレートはデフォルトで利用できるとは限りません。 代わりに、プレフィックスのリクエストレートが増加すると、Amazon SXNUMX は増加したレートを処理するために自動的にスケーリングします。 詳細については、次を参照してください。 リクエストがプレフィックスごとにサポートされているリクエストレートの範囲内にあるのに、Amazon S503 から 3 Slow Down エラーが発生するのはなぜですか?.
高頻度の Amazon S3 インタラクションが予想される場合は、次のベスト プラクティスをお勧めします。
- 複数の S3 バケットから読み書きを試み、 プレフィックス. たとえば、トレーニング データとチェックポイントを異なるプレフィックスに分割できます。
- Amazon S3 メトリクスを確認する アマゾンクラウドウォッチ リクエスト率を追跡します。
- 同時 PUT/GET の量を最小限に抑えるようにしてください。
- 同時に Amazon S3 を使用するプロセスが少なくなります。 たとえば、ノードごとに 3 つのプロセスが Amazon S8 にチェックポイントする必要がある場合、階層的にチェックポイントを設定することで PUT トラフィックを 3 分の XNUMX に減らすことができます。最初はノード内で、次にノードから Amazon SXNUMX へ。
- すべてのトレーニング レコードに S3 GET を使用する代わりに、3 つのファイルまたは SXNUMX GET から複数のトレーニング レコードを読み取ります。
- SageMaker FFM 経由で Amazon S3 を使用する場合、SageMaker FFM は S3 呼び出しを行い、チャンクごとにファイルをフェッチします。 FFM によって生成される Amazon S3 トラフィックを制限するには、ファイルを順番に読み取り、同時に開くファイルの数を制限することをお勧めします。
あなたが持っている場合 開発者、ビジネス、またはエンタープライズ サポート プラン、S3 503 スローダウン エラーに関するテクニカル サポート ケースを開くことができます。 ただし、最初にベストプラクティスに従っていることを確認してください。 リクエスト ID を取得する 失敗したリクエストについて。
トレーニングの並列性
通常、LLM には数十億から数千億のパラメーターがあり、大きすぎて単一の NVIDIA GPU カードに収まりません。 LLM の実践者は、LLM トレーニングの分散計算を容易にするいくつかのオープンソース ライブラリを開発しました。 FSDP, ディープスピード & メガトロン. これらのライブラリは SageMaker トレーニングで実行できますが、AWS クラウド向けに最適化され、よりシンプルな開発者エクスペリエンスを提供する SageMaker 分散トレーニング ライブラリを使用することもできます。 開発者は、SageMaker での LLM の分散トレーニングについて、分散ライブラリまたは自己管理の XNUMX つの選択肢があります。
SageMaker分散ライブラリ
分散トレーニングのパフォーマンスと使いやすさを向上させるために、SageMaker トレーニングでは、TensorFlow と PyTorch トレーニング コードをスケーリングするための独自の拡張機能をいくつか提案しています。 LLM トレーニングは、多くの場合、3D 並列方式で行われます。
- データの並列処理 トレーニングのミニバッチを分割して、モデルの複数の同一のレプリカにフィードし、処理速度を向上させます
- パイプラインの並列処理 単一の GPU と単一のサーバーを超えてモデルのサイズをスケーリングするために、モデルのさまざまなレイヤーを異なる GPU またはインスタンスに関連付けます。
- テンソル並列処理 通常は同じサーバー内で単一のレイヤーを複数の GPU に分割し、個々のレイヤーを単一の GPU を超えるサイズにスケーリングします。
次の例では、6*k*3 GPU (サーバーあたり 8 GPU) を備えた k*3 サーバーのクラスターで 8 層モデルがトレーニングされます。 データの並列度は k、パイプラインの並列度は 6、テンソルの並列度は 4 です。クラスター内の各 GPU にはモデル レイヤーの 24 分の XNUMX が含まれ、完全なモデルは XNUMX 台のサーバー (合計 XNUMX 個の GPU) に分割されます。

以下は、LLM に特に関連します。
- SageMaker 分散モデルの並列 – このライブラリは、グラフ パーティショニングを使用して、速度またはメモリに最適化されたインテリジェントなモデル パーティショニングを生成します。 SageMaker 分散モデル並列は、データ並列処理、パイプライン並列処理、テンソル並列処理、オプティマイザー状態シャーディング、アクティベーション チェックポイント、オフロードなど、最新かつ最高の大規模モデル トレーニング最適化を公開します。 SageMaker 分散モデル並列ライブラリを使用して、175 の NVIDIA A920 GPU でトレーニングされた 100 億のパラメーター モデルを文書化しました。 詳細については、次を参照してください。 AmazonSageMakerでモデルの並列追加とHuggingFaceを使用して175億以上のパラメーターNLPモデルをトレーニングする.
- SageMaker シャーディングされたデータの並列 - で MiCS: パブリック クラウドで巨大なモデルをトレーニングするためのニアリニア スケーリング、張ら。 クラスター全体ではなく、データ並列グループのみでモデルを分割する低通信モデル並列戦略を導入します。 AWS の科学者は MiCS を使用して、EC176 P56.4de インスタンスで 210 レイヤーの 1.06 兆パラメータ モデルをトレーニングするために、GPU あたり 2 テラフロップス (理論上のピークの 4%) を達成することができました。 SageMaker トレーニングのお客様は、MiCS を次のように利用できるようになりました。 SageMaker シャーディングされたデータの並列.
SageMaker の分散トレーニング ライブラリは、高いパフォーマンスとよりシンプルな開発者エクスペリエンスを提供します。 特に、並列ランチャーはジョブ起動 SDK に組み込まれているため、開発者はカスタムの並列プロセス ランチャーを作成して維持したり、フレームワーク固有の起動ツールを使用したりする必要はありません。
自己管理
SageMaker トレーニングでは、選択したフレームワークと科学的パラダイムを自由に使用できます。 特に、分散トレーニングを自分で管理したい場合は、カスタム コードを記述するための XNUMX つのオプションがあります。
- AWS Deep Learning Container (DLC) を使用する – AWS が開発および保守 DLCの、トップのオープンソース ML フレームワークに AWS に最適化された Docker ベースの環境を提供します。 SageMaker トレーニングには独自の統合があり、外部のユーザー定義のエントリ ポイントを使用して AWS DLC をプルして実行できます。 特に LLM トレーニングでは、TensorFlow、PyTorch、Hugging Face、および MXNet の AWS DLC が特に関連しています。 フレームワーク DLC を使用すると、独自の Docker イメージを開発および管理することなく、PyTorch Distributed などのフレームワーク ネイティブの並列処理を使用できます。 さらに、当社の DLC には MPI 統合これにより、並列コードを簡単に起動できます。
- SageMaker 互換のカスタム Docker イメージを作成する – 自分の (BYO) イメージを持ち込むことができます (を参照)。 独自のトレーニングアルゴリズムを使用する & AmazonSageMakerカスタムトレーニングコンテナ)、最初から開始するか、既存の DLC イメージを拡張します。 SageMaker で LLM トレーニングにカスタム イメージを使用する場合、次のことを確認することが特に重要です。
- 画像には適切な設定の EFA が含まれています (この記事の後半で詳しく説明します)
- イメージには、GPUDirectRDMA で有効化された NVIDIA NCCL 通信ライブラリが含まれています
お客様は、DeepSpeed を含む多数の自己管理型の分散トレーニング ライブラリを使用することができました。
通信部
LLM トレーニング ジョブの分散された性質を考えると、ワークロードの実現可能性、パフォーマンス、およびコストにとって、マシン間通信は重要です。 このセクションでは、マシン間通信の主要な機能を紹介し、インストールとチューニングのヒントを紹介して締めくくります。
エラスティックファブリックアダプター
ML アプリケーションを高速化し、クラウドによって提供される柔軟性、スケーラビリティ、弾力性を実現することでパフォーマンスを向上させるために、以下を利用できます。 エラスティックファブリックアダプター (EFA) SageMaker を使用。 私たちの経験では、満足のいくマルチノード LLM トレーニング パフォーマンスを得るには、EFA を使用する必要があります。
EFA デバイスは、トレーニングジョブの実行中に SageMaker によって管理される EC2 インスタンスに接続されるネットワークインターフェイスです。 EFA は、P4d を含む特定のインスタンス ファミリーで利用できます。 EFA ネットワークは、数百 Gbps のスループットを達成できます。
EFA に関連して、AWS は スケーラブルで信頼性の高いデータグラム (SRD)、に触発されたイーサネットベースのトランスポート InfiniBand 信頼できるデータグラム、緩和されたパケット順序制約で進化しました。 EFA と SRD の詳細については、次を参照してください。 パフォーマンスを求める場合、ネットワークを構築する方法は複数あります、 ビデオ EFA の仕組みとクラウドでインフィニバンドを使用しない理由、および研究論文 エラスティックでスケーラブルな HPC のためのクラウド最適化トランスポート プロトコル Shalevらから。
互換性のあるインスタンスでの EFA 統合を、SageMaker の既存の Docker コンテナ、または SageMaker ジョブを使用して ML モデルのトレーニングに使用できるカスタム コンテナに追加できます。 詳細については、次を参照してください。 EFA でトレーニングを実行する. EFA はオープンソース経由で公開されています リブファブリック 通信パッケージ。 ただし、LLM 開発者が Libfabric で直接プログラムすることはめったになく、通常は代わりに NVIDIA Collective Communications Library (NCCL) に依存しています。
AWS-OFI-NCCL プラグイン
分散型 ML では、EFA は NVIDIA Collective Communications Library (NCCL) と共に最もよく使用されます。 NCCL は、GPU 間通信アルゴリズムを実装する NVIDIA が開発したオープンソース ライブラリです。 GPU 間通信は、スケーラビリティとパフォーマンスを促進する LLM トレーニングの基礎です。 NCCL は DL トレーニングにとって非常に重要であるため、NCCL はディープ ラーニング トレーニング ライブラリの通信バックエンドとして直接統合されることが多いため、LLM 開発者は、好みの Python DL 開発フレームワークから気付かずに使用することがあります。 EFA で NCCL を使用するために、LLM 開発者は AWS が開発した AWS OFI NCCL プラグインこれは、NCCL 呼び出しを EFA が使用する Libfabric インターフェイスにマップします。 最近の改善点を活用するには、AWS OFI NCCL の最新バージョンを使用することをお勧めします。
NCCL が EFA を使用していることを確認するには、環境変数を設定する必要があります。 NCCL_DEBUG 〜へ INFO、EFA が NCCL によってロードされていることをログで確認します。
NCCL および EFA 構成の詳細については、次を参照してください。 EFA と NCCL の構成をテストする. NCCL をさらにカスタマイズするには、いくつかの 環境変数. NCCL 2.12 以降では、AWS が EFA ネットワークの自動通信アルゴリズム選択ロジックに貢献したことに注意してください (NCCL_ALGO 未設定のままにすることができます)。
NVIDIA GPUDirect RDMA over EFA
P4d インスタンス タイプでは、 導入 EFA ファブリック上の GPUDirect RDMA (GDR)。 これにより、ネットワーク インターフェイス カード (NIC) が GPU メモリに直接アクセスできるようになり、NVIDIA GPU ベースの EC2 インスタンス間のリモート GPU 間通信が高速化され、CPU とユーザー アプリケーションのオーケストレーション オーバーヘッドが削減されます。 可能であれば、GDR は NCCL によって内部で使用されます。
次のコードのように、ログ レベルが INFO に設定されている場合、GDR の使用状況が GPU 間通信に表示されます。
AWS 深層学習コンテナでの EFA の使用
AWS は Deep Learning Containers (DLC) を維持しており、その多くには AWS が管理する Dockerfile が付属しており、EFA、AWS OFI NCCL、および NCCL を含んで構築されています。 次の GitHub リポジトリは、 パイトーチ & TensorFlow. これらのライブラリを自分でインストールする必要はありません。
独自の SageMaker Training コンテナで EFA を使用する
独自の SageMaker Training コンテナを作成し、高速化されたノード間通信のために EFA 経由で NCCL を使用する場合は、EFA、NCCL、および AWS OFI NCCL をインストールする必要があります。 詳細については、次を参照してください。 EFA でトレーニングを実行します。 さらに、コンテナまたはエントリ ポイント コードで次の環境変数を設定する必要があります。
FI_PROVIDER="efa"ファブリック インターフェイス プロバイダーを指定しますNCCL_PROTO=simple通信に単純なプロトコルを使用するように NCCL に指示します (現在、EFA プロバイダーは LL プロトコルをサポートしていません。LL プロトコルを有効にすると、データが破損する可能性があります)。FI_EFA_USE_DEVICE_RDMA=1デバイスの RDMA 機能を使用して、片側および両側の転送を行いますNCCL_LAUNCH_MODE="PARALLEL"NCCL_NET_SHARED_COMMS="0"
編成
数十から数百のコンピューティング インスタンスのライフサイクルとワークロードを管理するには、オーケストレーション ソフトウェアが必要です。 このセクションでは、LLM オーケストレーションのベスト プラクティスを紹介します。
ジョブ内オーケストレーション
開発者は、ほとんどの分散フレームワークで、サーバー側のトレーニング コードとクライアント側のランチャー コードの両方を作成する必要があります。 トレーニング コードはトレーニング マシンで実行されますが、クライアント側のランチャー コードは分散ワークロードをクライアント マシンから起動します。 今日、標準化はほとんどありません。たとえば、次のようになります。
- PyTorch では、開発者は次を使用してマルチマシン タスクを起動できます。
torchrun,torchx,torch.distributed.launch(非推奨パス)、またはtorch.multiprocessing.spawn - DeepSpeed は独自の deepspeed CLI ランチャーを提案し、MPI の起動もサポートします
- MPI は人気のある並列コンピューティング フレームワークであり、ML に依存せず、合理的に使用できるという利点があるため、安定して文書化されており、分散 ML ワークロードでますます見られるようになっています。
SageMaker トレーニング クラスターでは、トレーニング コンテナが各マシンで XNUMX 回起動されます。 したがって、次の XNUMX つのオプションがあります。
- ネイティブランチャー – 特定の DL フレームワークのネイティブ ランチャーをエントリ ポイントとして使用できます。
torchrun呼び出し、それ自体が複数のローカル プロセスを生成し、インスタンス間の通信を確立します。 - SageMaker MPI 統合 – AWS DLC で利用できる SageMaker MPI 統合を使用するか、または sagemaker トレーニング ツールキット、エントリ ポイント コードをマシンごとに N 回直接実行します。 これには、独自のコードで中間のフレームワーク固有のランチャー スクリプトを使用しないという利点があります。
- SageMaker分散ライブラリ – SageMaker の分散ライブラリを使用すると、トレーニング コードに集中でき、ランチャー コードをまったく作成する必要がなくなります。 SageMaker 分散ランチャー コードは、SageMaker SDK に組み込まれています。
ジョブ間のオーケストレーション
LLM プロジェクトは多くの場合、パラメーター検索、スケーリング実験、エラーからの回復など、複数のジョブで構成されています。 トレーニング タスクを開始、停止、および並列化するには、ジョブ オーケストレーターを使用することが重要です。 SageMaker Training は、リクエストに応じてすぐに一時的なコンピューティング インスタンスをプロビジョニングするサーバーレス ML ジョブ オーケストレーターです。 使用した分だけ料金が発生し、クラスターはコードが終了するとすぐに廃止されます。 と SageMaker トレーニング ウォーム プール、ジョブ間で同じインフラストラクチャを再利用するために、トレーニング クラスターで有効期限を定義するオプションがあります。 これにより、反復時間とジョブ間の配置のばらつきが減少します。 SageMaker ジョブは、さまざまなプログラミング言語から起動できます。 Python & CLI.
と呼ばれる SageMaker 固有の Python SDK があります。 SageMaker Python SDK を介して実装されます。 セージメーカー Python ライブラリですが、その使用はオプションです。
大規模で長時間のトレーニング クラスターを使用したトレーニング ジョブのクォータの増加
SageMaker には、リソースに対するデフォルトのクォータがあり、意図しない使用とコストを防ぐように設計されています。 長時間実行されるハイエンド インスタンスの大規模なクラスターを使用して LLM をトレーニングするには、次の表のクォータを増やす必要がある可能性があります。
| クォータ名 | デフォルト値 |
| トレーニング ジョブの最長実行時間 | 432,000 seconds |
| すべてのトレーニング ジョブのインスタンス数 | 4 |
| トレーニング ジョブあたりのインスタンスの最大数 | 20 |
| ml.p4d.24xlarge トレーニング ジョブの使用 | 0 |
| ml.p4d.24xlarge ウォーム プールの使用方法のトレーニング用 | 0 |
見る AWS サービスのクォータ クォータ値を表示し、クォータの引き上げをリクエストする方法。 オンデマンド、スポット インスタンス、およびトレーニング ウォーム プールのクォータは、個別に追跡および変更されます。
SageMaker Profiler を有効にしておくことにした場合、すべてのトレーニングジョブが SageMaker Processing ジョブを起動し、それぞれが 5.2 つの ml.m50xlarge インスタンスを消費することに注意してください。 SageMaker 処理クォータが、予想されるトレーニング ジョブの同時実行に対応するのに十分な高さであることを確認します。 たとえば、5.2 個の Profiler 対応トレーニング ジョブを同時に実行する場合は、処理ジョブの使用制限の ml.m50xlarge を XNUMX に引き上げる必要があります。
さらに、長時間実行されるジョブを起動するには、明示的に設定する必要があります 推定量 max_run パラメータを、トレーニング ジョブの最長実行時間のクォータ値まで、秒単位でトレーニング ジョブの目的の最大期間に設定します。
監視と回復力
ハードウェア障害は、単一インスタンスの規模では非常にまれであり、同時に使用されるインスタンスの数が増えるにつれてますます頻繁になります。 通常の LLM 規模 (数百から数千の GPU を 24 時間年中無休で数週間から数か月使用) では、ハードウェア障害はほぼ確実に発生します。 したがって、LLM ワークロードは、適切な監視および回復メカニズムを実装する必要があります。 まず、LLM インフラストラクチャを綿密に監視して、障害の影響を制限し、コンピューティング リソースの使用を最適化することが重要です。 SageMaker トレーニングでは、この目的のためにいくつかの機能を提案しています。
- ログは CloudWatch Logs に自動的に送信されます。 ログにはトレーニング スクリプトが含まれます
stdout&stderr. MPI ベースの分散トレーニングでは、すべての MPI ワーカーがログをリーダー プロセスに送信します。 - メモリ、CPU 使用率、GPU 使用率などのシステム リソース使用率のメトリクスは、CloudWatch に自動的に送信されます。
- また、ご購読はいつでも停止することが可能です カスタム トレーニング指標を定義する それが CloudWatch に送信されます。 メトリックは、設定した正規表現に基づいてログから取得されます。 次のようなサードパーティの実験パッケージ AWSパートナー Weights & Biases の提供は、SageMaker Training で使用できます (例については、 W&B と SageMaker による CIFAR-10 ハイパーパラメータの最適化).
- SageMaker プロファイラー インフラストラクチャの使用状況を調査し、最適化の推奨事項を取得できます。
- アマゾンイベントブリッジ & AWSラムダ ジョブの失敗、成功、S3 ファイルのアップロードなどのイベントに反応する自動化されたクライアント ロジックを作成できます。
- SageMaker SSH ヘルパー はコミュニティが管理するオープンソース ライブラリで、SSH 経由でトレーニング ジョブ ホストに接続できます。 特定のノードで実行されているコードを検査してトラブルシューティングすることが役立つ場合があります。
監視に加えて、SageMaker はジョブの回復力のための機器も提供します。
- クラスターのヘルスチェック – ジョブが開始される前に、SageMaker は GPU ヘルスチェックを実行し、GPU インスタンスで NCCL 通信を検証し、必要に応じて障害のあるインスタンスを置き換えて、トレーニングスクリプトがインスタンスの正常なクラスターで実行を開始できるようにします。 ヘルス チェックは現在、P および G GPU ベースのインスタンス タイプで有効になっています。
- 組み込みの再試行とクラスターの更新 – SageMaker を自動的に設定できます リトライ SageMaker 内部サーバー エラー (ISE) で失敗するトレーニング ジョブ。 ジョブの再試行の一環として、SageMaker は回復不能な GPU エラーが発生したインスタンスを新しいインスタンスに置き換え、すべての正常なインスタンスを再起動して、ジョブを再開します。 これにより、再起動とワークロードの完了が高速化されます。 クラスターの更新は現在、P および G GPU ベースのインスタンス タイプで有効になっています。 自分で追加できます 適用可能な再試行メカニズム ジョブを送信するクライアント コードの周りで、アカウント クォータの超過など、他の種類の起動エラーを処理します。
- 自動化 Amazon S3 へのチェックポイント – これにより、 チェックポイント あなたの進歩と新しい仕事の過去の状態をリロードします。
ノードレベルの置換を利用するには、コードでエラーが発生する必要があります。 ノードに障害が発生した場合、コレクティブはエラーではなくハングすることがあります。 したがって、迅速な修復を行うには、コレクティブにタイムアウトを適切に設定し、到達したときにコードがエラーをスローするようにします。
一部のお客様は、CloudWatch ログとメトリクスを監視して、ログが書き込まれない、GPU 使用率が 0% などの異常なパターンを監視して、ジョブのハングやアプリケーションの収束の停止を監視し、対処するように監視クライアントをセットアップして、ハング、収束の停止、および自動のヒントを示します。ジョブを停止/再試行します。
チェックポイントの詳細
SageMaker チェックポイント 機能はあなたが書いたものすべてをコピーします /opt/ml/checkpoints で指定された URI として Amazon S3 に戻ります checkpoint_s3_uri SDK パラメータ。 ジョブが開始または再開されると、その URI に書き込まれたすべての内容がすべてのマシンに送り返されます。 /opt/ml/checkpoints. これは、すべてのノードがすべてのチェックポイントにアクセスできるようにする場合に便利ですが、規模が大きくなると、多数のマシンまたは多数の履歴チェックポイントがある場合、Amazon S3 でのダウンロード時間が長くなり、トラフィックが過剰になる可能性があります。 さらに、テンソルとパイプラインの並列処理では、ワーカーはチェックポイントが設定されたモデルのすべてではなく、一部のみを必要とします。 これらの制限に直面している場合は、次のオプションをお勧めします。
- Lustre の FSx へのチェックポイント – 高性能ランダム I/O のおかげで、選択したシャーディングとファイル属性スキームを定義できます
- 自己管理型の Amazon S3 チェックポイント – 非ブロッキング方式でチェックポイントを保存および読み取るために使用できる Python 関数の例については、次を参照してください。 チェックポイントの保存
関連するオーバーヘッドとコストに応じて、数時間ごと (たとえば 1 ~ 3 時間) にモデルのチェックポイントを設定することを強くお勧めします。
フロントエンドとユーザー管理
ユーザー管理は、従来の共有 HPC インフラストラクチャと比較して、SageMaker の主要なユーザビリティの強みです。 SageMaker トレーニングのアクセス許可は、複数の権限によって制御されます AWS IDおよびアクセス管理 (IAM) 抽象化:
- プリンシパル (ユーザーとシステム) には、リソースを起動する権限が与えられます
- トレーニング ジョブはそれ自体がロールを持ち、たとえばデータ アクセスやサービス呼び出しに関する独自の権限を持つことができます。
さらに、2022 年に SageMaker ロールマネージャー ペルソナ主導の権限の作成を容易にするため。
まとめ
SageMaker トレーニングを使用すると、コストを削減し、大規模なモデルのトレーニング ワークロードの反復速度を向上させることができます。 以下を含む多数の投稿やケーススタディで成功事例を文書化しています。
コストを削減しながら LLM の市場投入までの時間を短縮したいと考えている場合は、SageMaker Training API をご覧になり、構築したものをお知らせください。
Amr Ragab、Rashika Kheria、Zmnako Awrahman、Arun Nagarajan、Gal Oshri の有益なレビューと教えに特に感謝します。
著者について
 アナスタシア・ツェベレカ AWS の機械学習および AI スペシャリスト ソリューション アーキテクトです。 彼女は EMEA の顧客と協力し、AWS のサービスを使用して大規模な機械学習ソリューションを設計するのを支援しています。 彼女は、自然言語処理 (NLP)、MLOps、Low Code No Code ツールなど、さまざまな分野のプロジェクトに取り組んできました。
アナスタシア・ツェベレカ AWS の機械学習および AI スペシャリスト ソリューション アーキテクトです。 彼女は EMEA の顧客と協力し、AWS のサービスを使用して大規模な機械学習ソリューションを設計するのを支援しています。 彼女は、自然言語処理 (NLP)、MLOps、Low Code No Code ツールなど、さまざまな分野のプロジェクトに取り組んできました。
 ギリナチュム は、EMEAのAmazonMachineLearningチームの一員として働くシニアAI/MLスペシャリストソリューションアーキテクトです。 Giliは、ディープラーニングモデルのトレーニングの課題と、機械学習が世界をどのように変えているかについて情熱を注いでいます。 暇なときは、ギリは卓球を楽しんでいます。
ギリナチュム は、EMEAのAmazonMachineLearningチームの一員として働くシニアAI/MLスペシャリストソリューションアーキテクトです。 Giliは、ディープラーニングモデルのトレーニングの課題と、機械学習が世界をどのように変えているかについて情熱を注いでいます。 暇なときは、ギリは卓球を楽しんでいます。
 オリヴィエ・クルシャン フランスを拠点とする AWS のプリンシパル機械学習スペシャリスト ソリューション アーキテクトです。 Olivier は、AWS のお客様 (小規模なスタートアップから大企業まで) が本番グレードの機械学習アプリケーションを開発およびデプロイするのを支援しています。 余暇には、研究論文を読んだり、友人や家族と一緒に荒野を探索したりしています。
オリヴィエ・クルシャン フランスを拠点とする AWS のプリンシパル機械学習スペシャリスト ソリューション アーキテクトです。 Olivier は、AWS のお客様 (小規模なスタートアップから大企業まで) が本番グレードの機械学習アプリケーションを開発およびデプロイするのを支援しています。 余暇には、研究論文を読んだり、友人や家族と一緒に荒野を探索したりしています。
 ブルーノ・ピストン ミラノを拠点とする AWS の AI/ML スペシャリスト ソリューション アーキテクトです。 彼は、あらゆる規模の顧客と協力して、技術的なニーズを深く理解し、AWS クラウドと Amazon Machine Learning スタックを最大限に活用する AI および機械学習ソリューションを設計できるよう支援しています。 彼の専門分野は、機械学習のエンド ツー エンド、機械学習の産業化、MLOps です。 彼は友達と時間を過ごし、新しい場所を探索したり、新しい目的地に旅行したりすることを楽しんでいます。
ブルーノ・ピストン ミラノを拠点とする AWS の AI/ML スペシャリスト ソリューション アーキテクトです。 彼は、あらゆる規模の顧客と協力して、技術的なニーズを深く理解し、AWS クラウドと Amazon Machine Learning スタックを最大限に活用する AI および機械学習ソリューションを設計できるよう支援しています。 彼の専門分野は、機械学習のエンド ツー エンド、機械学習の産業化、MLOps です。 彼は友達と時間を過ごし、新しい場所を探索したり、新しい目的地に旅行したりすることを楽しんでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/training-large-language-models-on-amazon-sagemaker-best-practices/
- :は
- ][p
- $UP
- 000
- 1
- 100
- 2022
- 7
- 8
- a
- A100
- 能力
- できる
- 私たちについて
- 上記の.
- 加速する
- 加速された
- アクセス
- 対応する
- 達成する
- 達成する
- 越えて
- 行為
- アクティベーション
- アクティブ
- 適応する
- 追加されました
- 添加
- さらに
- 追加
- 利点
- AI
- AI / ML
- AL
- アルゴリズム
- アルゴリズム
- すべて
- 許可
- ことができます
- Amazon
- Amazon EC2
- アマゾンFSx
- アマゾン機械学習
- アマゾンセージメーカー
- 量
- &
- API
- API
- 適用可能な
- 申し込み
- 適用された
- 適切な
- です
- AREA
- 周りに
- AS
- 関連する
- At
- 添付された
- 属性
- オート
- 自動化
- 自動的に
- 利用できます
- 避ける
- 回避
- AWS
- バック
- バックエンド
- ベース
- BE
- なぜなら
- になる
- さ
- 恩恵
- BEST
- ベストプラクティス
- 越えて
- ビッグ
- 10億
- 億
- ブロック
- 持って来る
- もたらす
- ビルド
- 内蔵
- ビジネス
- by
- コール
- 呼ばれます
- コール
- 缶
- できる
- 容量
- カード
- カード
- キャリー
- 場合
- ケーススタディ
- 触媒する
- 課題
- 変化
- チャネル
- チェック
- 小切手
- 選択
- 選択肢
- 選択する
- クラス
- クライアント
- 密接に
- クラウド
- クラスタ
- コード
- 集団
- 組み合わせた
- 来ます
- コマンドと
- 一般に
- コミュニケーション
- 通信部
- 比べ
- 互換性のあります
- 完成
- 計算
- 計算
- コンピュータ
- Computer Vision
- コンピューティング
- 結論
- 実施
- 確認します
- お問合せ
- その結果
- コンテナ
- コンテナ
- 含まれています
- コンテンツ
- 貢献
- コントロール
- 制御
- 便利
- 収束
- 腐敗
- 費用
- コスト
- 可能性
- ここから
- カバー
- カバー
- CPU
- 作ります
- 創造
- クリエイティブ
- 重大な
- 重大な
- キュレーション
- 現在
- カスタム
- Customers
- カスタマイズ
- データ
- データアクセス
- データの準備
- データセット
- 決めます
- 専用の
- 深いです
- 深い学習
- デフォルト
- 度
- によっては
- 依存
- 展開します
- 設計
- 設計
- 目的地
- 決定する
- 決定
- 開発する
- 発展した
- Developer
- 開発者
- 開発
- 開発
- デバイス
- Devices
- 異なります
- 直接に
- 話し合います
- 議論する
- 配布
- 分散コンピューティング
- 分散トレーニング
- ディストリビューション
- デッカー
- Dockerコンテナ
- そうではありません
- ドメイン
- ドント
- ダウン
- ダウンロード
- 数十
- 間に
- 各
- 簡単に
- 効果的な
- どちら
- EMEA
- enable
- 使用可能
- 可能
- 有効にする
- 奨励する
- 終了
- 強化された
- 楽しみます
- 十分な
- 確保
- Enterprise
- 企業
- エントリ
- 環境
- 環境
- 装置
- 装備
- エラー
- エラー
- 確立する
- エーテル(ETH)
- さらに
- イベント
- やがて
- あらゆる
- すべてのもの
- 進化
- 例
- 例
- Excel
- 既存の
- 期待する
- 予想される
- 体験
- 実験
- 探る
- 露出した
- 表現
- 延伸
- エクステンション
- 外部
- 非常に
- ファブリック
- 顔
- 容易にする
- 容易化する
- 要因
- Failed:
- 失敗
- 不良解析
- 家族
- 家族
- ファッション
- スピーディー
- 速いです
- 欠陥のある
- 実行可能な
- 特徴
- 特徴
- 少数の
- フィールド
- File
- 名
- フィット
- 艦隊
- 柔軟性
- フォーカス
- 焦点を当てて
- 続いて
- フォロー中
- 分数
- フレームワーク
- フレームワーク
- フランス
- 自由
- 頻繁な
- 新鮮な
- 友達
- から
- フル
- 完全に
- 機能的な
- 機能性
- 機能
- さらに
- GAL
- 生成された
- 生々しい
- 取得する
- 受け
- GitHubの
- 与えられた
- GPU
- GPU
- グラフ
- 素晴らしい
- 最大
- グループ
- 育ちます
- ハンドル
- ハンドリング
- ハング
- 起こる
- Hardware
- 持ってる
- 持って
- 健康
- 健康
- 役立つ
- 助け
- ことができます
- ハイ
- 高周波
- ハイパフォーマンス
- 歴史的
- フード
- ホスト
- HOURS
- 認定条件
- How To
- しかしながら
- hpc
- HTML
- HTTP
- HTTPS
- 何百
- 数億
- i
- IAM
- 同一の
- アイデンティティ
- 画像
- 画像
- 直ちに
- 影響
- 実装する
- 実装
- 実装
- 重要
- 改善します
- 改善されました
- 改善
- in
- その他の
- include
- 含めて
- 増える
- 増加した
- 増加
- ますます
- 個人
- 産業を変えます
- info
- 情報
- インフラ
- 革新的手法
- インスピレーションある
- install
- を取得する必要がある者
- 統合された
- 統合
- インテリジェント-
- 相互作用
- インタフェース
- 中間の
- 内部
- 紹介する
- 導入
- IT
- 繰り返し
- ITS
- 自体
- ジョブ
- Jobs > Create New Job
- JPG
- キープ
- キー
- 種類
- 知っている
- 言語
- ESL, ビジネスESL <br> 中国語/フランス語、その他
- 大
- 大規模
- より大きい
- 最新の
- 起動する
- 打ち上げ
- 起動
- 層
- 層
- つながる
- リーダー
- 学習
- Legacy
- レベル
- ライブラリ
- 図書館
- wifecycwe
- ような
- 可能性が高い
- LIMIT
- 制限
- 限定的
- 少し
- ローディング
- ローカル
- 長い
- 長い時間
- 見て
- 探して
- ロー
- 機械
- 機械学習
- 機械翻訳
- マシン
- 維持する
- 維持
- make
- 作る
- 作成
- 管理します
- マネージド
- 管理
- 多くの
- ゲレンデマップ
- メモリ
- メソッド
- メトリック
- 移行
- MILAN
- 何百万
- 最小限に抑えます
- ML
- MLOps
- モード
- モデリング
- モデル
- 修正されました
- モニター
- モニタリング
- 他には?
- 最も
- の試合に
- すなわち
- ネイティブ
- ナチュラル
- 自然言語
- 自然言語処理
- 自然に
- 自然
- 必ずしも
- 必要
- 必要
- ニーズ
- ネットワーク
- ネットワークベース
- ネットワーク
- ニューラル
- ニューラルネットワーク
- 新作
- NLP
- ノード
- 数
- 多数の
- Nvidia
- オブジェクト
- of
- 提供
- 提供すること
- オリーブ
- on
- オンデマンド
- ONE
- 開いた
- オープンソース
- オープンソースコード
- 開かれた
- 機会
- 最適化
- 最適化
- 最適化
- オプション
- オプション
- 編成
- 注文
- その他
- 自分の
- パッケージ
- パッケージ
- 紙素材
- 論文
- パラダイム
- 並列シミュレーションの設定
- パラメーター
- パラメータ
- 部
- 特定の
- 特に
- 情熱的な
- 過去
- path
- パターン
- 支払う
- ピーク
- パフォーマンス
- 公演
- 許可
- パーミッション
- 物理的に
- パイプライン
- 場所
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 再生
- ポイント
- プール
- プール
- 人気
- ポスト
- 投稿
- 練習
- プラクティス
- 予測
- プ
- 優先
- 現在
- プレゼント
- 防ぐ
- 前に
- 校長
- プロセス
- ラボレーション
- 処理
- 作り出す
- 演奏曲目
- プログラミング
- プログラミング言語
- 進捗
- プロジェクト(実績作品)
- 正しく
- 提案する
- 提案する
- 所有権
- プロトコル
- 提供します
- 提供
- プロバイダー
- 提供
- 公共
- 出版物
- 目的
- 置きます
- Python
- パイトーチ
- 品質
- 上げる
- ランダム
- 珍しい
- レート
- 価格表
- 達した
- 読む
- リーディング
- 実現する
- 合理的な
- 理由は
- 受け取ります
- 最近
- 推奨する
- 提言
- 記録
- 記録
- 回復
- 減らします
- 軽減
- 縮小
- に対する
- 地域
- 地域
- レギュラー
- 定期的に
- 関連する
- 関連した
- 信頼性のある
- 頼る
- リモート
- replace
- 表します
- 要求
- リクエスト
- 必要とする
- 要件
- 必要
- 研究
- 研究とイノベーション
- リソースを追加する。
- リソース
- 結果
- レビュー
- 職種
- 役割
- ラン
- ランニング
- セージメーカー
- 同じ
- Save
- スケーラビリティ
- ド電源のデ
- 規模
- 秤
- スケーリング
- スキーム
- 科学者たち
- スコープ
- スクリプト
- SDDK
- を検索
- 二番
- 秒
- セクション
- を求める
- 選択
- 選択
- シニア
- 別々
- サーバレス
- サーバー
- サービス
- サービス
- セッションに
- 設定
- いくつかの
- シャード
- シャーディング
- shared
- すべき
- 著しく
- 簡単な拡張で
- 単純
- 同時
- 同時に
- サイズ
- サイズ
- スキル
- 遅く
- 小さい
- So
- ソフトウェア
- ソリューション
- 一部
- すぐに
- ソース
- ソース
- スポーン
- 専門家
- 特定の
- 特に
- 指定の
- スピード
- 支出
- 分割
- Spot
- 安定した
- スタック
- start
- 起動
- 開始
- スタートアップ
- 都道府県
- 統計的
- ステップ
- Force Stop
- 停止
- ストレージ利用料
- 店舗
- ストーリー
- 戦略
- 流れ
- ストリーム
- 力
- ストリッピング
- 強く
- 研究
- 成功
- 導入事例
- 成功した
- そのような
- サポート
- サポート
- サポート
- 同期
- 構文
- テーブル
- 取る
- 仕事
- タスク
- チーム
- 技術的
- テクニカル·サポート
- テニス
- テンソルフロー
- それ
- 世界
- アプリ環境に合わせて
- それら
- 自分自身
- 理論的な
- したがって、
- ボーマン
- サードパーティ
- 数千
- 三
- 介して
- スループット
- 時間
- <font style="vertical-align: inherit;">回数</font>
- ヒント
- 〜へ
- 今日
- トークン
- あまりに
- ツール
- 豊富なツール群
- top
- トータル
- 追跡する
- トラフィック
- トレーニング
- 訓練された
- トレーニング
- インタビュー
- 輸送
- 1兆
- 典型的な
- 下
- 根本的な
- わかる
- ユニーク
- ユニット
- アップデイト
- URI
- us
- 使いやすさ
- 使用法
- つかいます
- ユーザー
- 通常
- 値
- 価値観
- variables
- 多様
- さまざまな
- 確認する
- バージョン
- 、
- ビデオ
- 詳しく見る
- ビジョン
- 暖かいです
- 仕方..
- 方法
- ウィークス
- WELL
- この試験は
- which
- while
- 誰
- 意志
- 以内
- 無し
- 言葉
- 仕事
- 働いていました
- 労働者
- ワーキング
- 作品
- 世界
- 書きます
- 書かれた
- 年
- あなたの
- あなた自身
- ユーチューブ
- ゼファーネット