조직은 데이터 레이크를 구축하기로 결정했습니다. 아마존 단순 스토리지 서비스 (Amazon S3) 수년 동안. 데이터 레이크는 조직에서 다양한 팀, 비즈니스 도메인, 다양한 형식, 심지어는 기록에 걸쳐 생성한 모든 조직 데이터를 저장하는 데 가장 많이 사용되는 선택입니다. 에 따르면 연구, 평균적인 회사에서는 데이터 양이 매년 50%를 초과하는 속도로 증가하고 있으며 일반적으로 분석을 위해 평균 33개의 고유한 데이터 소스를 관리하고 있습니다.
팀은 종종 동일한 ETL(추출, 변환 및 로드) 패턴을 사용하여 관계형 데이터베이스에서 수천 개의 작업을 복제하려고 시도합니다. 작업 상태를 유지하고 이러한 개별 작업을 예약하는 데 많은 노력이 필요합니다. 이 접근 방식은 팀이 거의 변경하지 않고 테이블을 추가하고 최소한의 노력으로 작업 상태를 유지하는 데 도움이 됩니다. 이를 통해 개발 일정을 크게 개선하고 작업을 쉽게 추적할 수 있습니다.
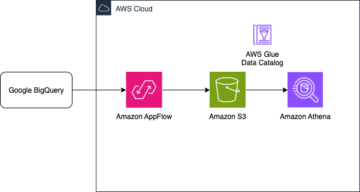
이 게시물에서는 Apache Iceberg 및 AWS 접착제.
솔루션 아키텍처
데이터 레이크는 일반적으로 조직 세 가지 데이터 계층에 별도의 S3 버킷 사용: 원래 형식의 데이터를 포함하는 원시 계층, 소비에 최적화된 중간 처리 데이터를 포함하는 단계 계층, 특정 사용 사례에 대해 집계된 데이터를 포함하는 분석 계층. 원시 계층에서 테이블은 일반적으로 데이터 소스를 기반으로 구성되는 반면, 단계 계층의 테이블은 속한 비즈니스 도메인을 기반으로 구성됩니다.
이 게시물은 AWS 클라우드 포메이션 데이터 레이크 원시 계층의 한 데이터 소스에 대한 Amazon S3 경로를 읽고 다음을 사용하여 스테이지 계층의 Apache Iceberg 테이블로 데이터를 수집하는 AWS Glue 작업을 배포하는 템플릿 데이터 레이크 프레임워크에 대한 AWS Glue 지원. 작업은 원시 계층의 테이블이 다음 방식으로 구조화될 것으로 예상합니다. AWS 데이터베이스 마이그레이션 서비스 (AWS DMS)는 스키마, 테이블, 데이터 파일을 수집합니다.
이 솔루션은 AWS Systems Manager 파라미터 스토어 테이블 구성용. 기본 키, 파티션 및 연관된 비즈니스 도메인과 같은 정보를 포함하여 처리할 테이블과 방법을 지정하여 이 매개변수를 수정해야 합니다. 작업은 이 정보를 사용하여 모든 비즈니스 도메인에 대한 데이터베이스(아직 존재하지 않는 경우)를 자동으로 만들고 Iceberg 테이블을 만들고 데이터 로드를 수행합니다.
마지막으로 아마존 아테나 Iceberg 테이블의 데이터를 쿼리합니다.
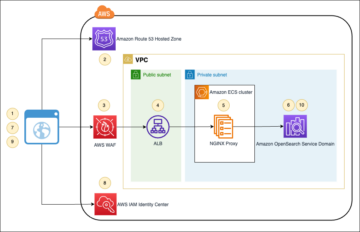
다음 다이어그램은이 아키텍처를 보여줍니다.

이 구현에는 다음과 같은 고려 사항이 있습니다.
- 데이터 원본의 모든 테이블에는 이 솔루션을 사용하여 복제할 기본 키가 있어야 합니다. 기본 키는 단일 열이거나 둘 이상의 열이 있는 복합 키일 수 있습니다.
- 데이터 레이크에 upsert가 필요하지 않거나 기본 키가 없는 테이블이 포함된 경우 매개 변수 구성에서 제외하고 기존 ETL 프로세스를 구현하여 데이터 레이크로 수집할 수 있습니다. 이 게시물의 범위를 벗어납니다.
- 수집해야 하는 추가 데이터 소스가 있는 경우 각 데이터 소스를 처리하기 위해 하나씩 여러 CloudFormation 스택을 배포할 수 있습니다.
- AWS Glue 작업은 AWS DMS가 전체 로드 작업을 완료한 후 실행되는 초기 로드와 AWS DMS에서 캡처한 변경 데이터 캡처(CDC) 파일을 적용하는 일정에 따라 실행되는 증분 로드의 두 단계로 데이터를 처리하도록 설계되었습니다. 증분 처리는 다음을 사용하여 수행됩니다. AWS Glue 작업 북마크.
이 자습서를 완료하는 데는 XNUMX단계가 있습니다.
- AWS DMS에 대한 소스 엔드포인트를 설정합니다.
- AWS CloudFormation을 사용하여 솔루션을 배포합니다.
- AWS DMS 복제 작업을 검토합니다.
- 선택적으로 암호화 및 암호 해독에 대한 권한을 추가하거나 AWS Lake 형성.
- Parameter Store에서 테이블 구성을 검토하십시오.
- 초기 데이터 로드를 수행합니다.
- 증분 데이터 로드를 수행합니다.
- 테이블 수집을 모니터링합니다.
- 증분 배치 데이터 로드를 예약합니다.
사전 조건
이 튜토리얼을 시작하기 전에 이미 Iceberg에 대해 잘 알고 있어야 합니다. 그렇지 않은 경우 다음 지침에 따라 단일 테이블을 복제하여 시작할 수 있습니다. Apache Iceberg 및 AWS Glue를 사용하여 데이터 레이크에서 CDC 기반 UPSERT 구현. 추가로 다음을 설정합니다.
AWS DMS에 대한 소스 엔드포인트 설정
AWS DMS 작업을 생성하기 전에 소스 데이터베이스에 연결할 소스 엔드포인트를 설정해야 합니다.
- AWS DMS 콘솔에서 다음을 선택합니다. 종점 탐색 창에서
- 왼쪽 메뉴에서 엔드 포인트 생성.
- 데이터베이스가 Amazon RDS에서 실행 중인 경우 다음을 선택합니다. RDS DB 인스턴스 선택을 클릭한 다음 목록에서 인스턴스를 선택합니다. 그렇지 않으면 소스 엔진을 선택하고 다음을 통해 연결 정보를 제공하십시오. AWS 비밀 관리자 또는 수동으로.
- 럭셔리 끝점 식별자, 끝점의 이름을 입력합니다. 예를 들어, 소스-postgresql.
- 왼쪽 메뉴에서 엔드 포인트 생성.
AWS CloudFormation을 사용하여 솔루션 배포
제공된 템플릿을 사용하여 CloudFormation 스택을 생성합니다. 다음 단계를 완료하십시오.
- 왼쪽 메뉴에서 스택 시작 :

- 왼쪽 메뉴에서 다음 보기.
- 다음과 같은 스택 이름을 제공하십시오.
transactionaldl-postgresql. - 필수 매개변수를 입력합니다.
- DMSS3엔드포인트IAMRoleARN – Amazon S3에 데이터를 쓰기 위한 AWS DMS의 IAM 역할 ARN.
- 복제 인스턴스Arn – AWS DMS 복제 인스턴스 ARN.
- S3버킷스테이지 – 데이터 레이크의 단계 계층에 사용되는 기존 버킷의 이름입니다.
- S3버킷글루 – AWS Glue 스크립트를 저장하기 위한 기존 S3 버킷의 이름입니다.
- S3Bucket원시 – 데이터 레이크의 원시 계층에 사용되는 기존 버킷의 이름입니다.
- 소스엔드포인트Arn – 이전에 생성한 AWS DMS 엔드포인트 ARN.
- 소스 이름 – 복제할 데이터 소스의 임의 식별자(예:
postgres). 이는 데이터가 저장될 데이터 레이크(원시 계층)의 S3 경로를 정의하는 데 사용됩니다.
- 다음 매개변수를 수정하지 마십시오.
- 소스S3Bucket블로그 – 제공된 AWS Glue 스크립트가 저장된 버킷 이름입니다.
- SourceS3BucketPrefix – 제공된 AWS Glue 스크립트가 저장되는 버킷 접두사 이름입니다.
- 왼쪽 메뉴에서 다음 보기 두번.
- 선택 AWS CloudFormation이 사용자 지정 이름으로 IAM 리소스를 생성 할 수 있음을 인정합니다.
- 왼쪽 메뉴에서 스택 생성.
약 5분 후에 CloudFormation 스택이 배포됩니다.
AWS DMS 복제 작업 검토
AWS CloudFormation 배포는 AWS DMS 대상 엔드포인트를 생성했습니다. 두 가지 특정 엔드포인트 설정으로 인해 Amazon S3에서 필요할 때 데이터가 수집됩니다.
- AWS DMS 콘솔에서 다음을 선택합니다. 종점 탐색 창에서
- 로 시작하는 엔드포인트를 검색하고 선택합니다.
dmsIcebergs3endpoint. - 끝점 설정을 검토합니다.
DataFormat다음과 같이 지정됩니다.parquet.TimestampColumnName열을 추가합니다last_update_timeAmazon S3에서 레코드 생성 날짜.

또한 배포는 다음으로 시작하는 AWS DMS 복제 작업을 생성합니다. dmsicebergtask.
- 왼쪽 메뉴에서 복제 작업 탐색 창에서 작업을 검색합니다.
당신은 그것을 볼 것입니다 작업 유형 다음과 같이 표시됩니다. 전체 로드, 지속적인 복제. AWS DMS는 기존 데이터의 초기 전체 로드를 수행한 다음 소스 데이터베이스에 수행된 변경 사항으로 증분 파일을 생성합니다.
에 매핑 규칙 탭에는 두 가지 유형의 규칙이 있습니다.
- 소스 데이터베이스에서 수집될 소스 스키마 및 테이블의 이름이 포함된 선택 규칙. 기본적으로 prerequisites에서 제공하는 샘플 데이터베이스를 사용하며,
dms_sample, 키워드 %가 있는 모든 테이블. - Amazon S3의 대상 파일에 스키마 이름과 테이블 이름을 열로 포함하는 두 가지 변환 규칙. 이는 AWS Glue 작업에서 데이터 레이크의 파일이 해당하는 테이블을 파악하는 데 사용됩니다.
자신의 데이터 소스에 맞게 이를 사용자 정의하는 방법에 대해 자세히 알아보려면 다음을 참조하십시오. 선택 규칙 및 작업.

작업 준비를 완료하기 위해 몇 가지 구성을 변경해 보겠습니다.
- 에 행위 메뉴, 선택 수정.
- . 작업 설정 섹션 아래 전체 로드 완료 후 작업 중지선택한다. 캐시된 변경 사항 적용 후 중지.
이렇게 하면 초기 로드와 증분 파일 생성을 서로 다른 두 단계로 제어할 수 있습니다. 이 XNUMX단계 접근 방식을 사용하여 각 단계마다 한 번씩 AWS Glue 작업을 실행합니다.
- $XNUMX Million 미만 작업 로그선택한다. CloudWatch 로그 켜기.
- 왼쪽 메뉴에서 찜하기.
- 데이터베이스 마이그레이션 작업 상태가 다음과 같이 표시될 때까지 약 1분 정도 기다립니다. 준비.
암호화 및 암호 해독 또는 Lake Formation에 대한 권한 추가
선택적으로 암호화 및 암호 해독 또는 Lake Formation에 대한 권한을 추가할 수 있습니다.
암호화 및 복호화 권한 추가
원시 및 단계 계층에 사용되는 S3 버킷이 다음을 사용하여 암호화된 경우 AWS 키 관리 서비스 (AWS KMS) 고객 관리형 키를 사용하려면 AWS Glue 작업이 데이터에 액세스할 수 있도록 권한을 추가해야 합니다.
Lake Formation 권한 추가
Lake Formation을 사용하여 권한을 관리하는 경우 AWS Glue 작업이 IAM 역할을 통해 도메인의 데이터베이스 및 테이블을 생성하도록 허용해야 합니다. GlueJobRole.
- 데이터베이스를 생성할 수 있는 권한을 부여합니다(자세한 내용은 다음을 참조하십시오. 데이터베이스 생성).
- 에 SUPER 권한 부여
default데이터 베이스. - 데이터 위치 권한 부여.
- 데이터베이스를 수동으로 생성하는 경우 모든 데이터베이스에 대한 권한을 부여하여 테이블을 생성하십시오. 인용하다 Lake Formation 콘솔 및 명명된 리소스 메서드를 사용하여 테이블 권한 부여 or LF-TBAC 방법을 사용하여 Data Catalog 권한 부여 사용 사례에 따라.
초기 데이터 로드를 수행하는 이후 단계를 완료한 후에는 소비자가 테이블을 쿼리할 수 있는 권한도 추가해야 합니다. 작업 역할은 생성된 모든 테이블의 소유자가 되며 Data Lake 관리자는 추가 사용자에게 권한 부여를 수행할 수 있습니다.
Parameter Store에서 테이블 구성 검토
Iceberg 테이블로 데이터 수집을 수행하는 AWS Glue 작업은 Parameter Store에서 제공되는 테이블 사양을 사용합니다. 자동으로 구성된 매개변수 저장소를 검토하려면 다음 단계를 완료하십시오. 필요한 경우 자신의 필요에 따라 수정합니다.
- Parameter Store 콘솔에서 다음을 선택합니다. 내 매개변수 탐색 창에서
CloudFormation 스택은 두 개의 매개변수를 생성했습니다.
iceberg-config작업 구성iceberg-tables테이블 구성을 위해
- 매개변수 선택 빙산 테이블.
JSON 구조에는 AWS Glue가 데이터를 읽고 대상 도메인에서 Iceberg 테이블을 쓰는 데 사용하는 정보가 포함되어 있습니다.
- 테이블당 하나의 개체 – 객체의 이름은 스키마 이름, 마침표 및 테이블 이름을 사용하여 생성됩니다. 예를 들어,
schema.table. - 기본 키 – 이것은 모든 소스 테이블에 대해 지정되어야 합니다. 단일 열 또는 쉼표로 구분된 열 목록(공백 없이)을 제공할 수 있습니다.
- 파티션콜 – 이것은 선택적으로 대상 테이블에 대한 열을 분할합니다. 분할된 테이블을 생성하지 않으려면 빈 문자열을 제공하십시오. 그렇지 않으면 사용할 단일 열 또는 쉼표로 구분된 열 목록을 공백 없이 제공하십시오.
- 자체 데이터 원본을 사용하려면 다음 JSON 코드를 사용하고 제공된 템플릿에서 CAPS의 텍스트를 바꿉니다. 제공된 샘플 데이터 원본을 사용하는 경우 기본 설정을 유지합니다.
{ "SCHEMA_NAME.TABLE_NAME_1": { "primaryKey": "ONLY_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "" }, "SCHEMA_NAME.TABLE_NAME_2": { "primaryKey": "FIRST_PRIMARY_KEY,SECOND_PRIMARY_KEY", "domain": "TARGET_DOMAIN", "partitionCols": "PARTITION_COLUMN_ONE,PARTITION_COLUMN_TWO" }
}- 왼쪽 메뉴에서 변경 사항을 저장.
초기 데이터 로드 수행
필요한 구성이 완료되었으므로 이제 초기 데이터를 수집합니다. 이 단계에는 소스 관계형 데이터베이스의 데이터를 데이터 레이크의 원시 계층으로 수집, 데이터 레이크의 단계 계층에 Iceberg 테이블 생성, Athena를 사용하여 결과 확인의 세 부분이 포함됩니다.
데이터 레이크의 원시 계층으로 데이터 수집
Iceberg를 사용하여 관계형 데이터 원본(제공된 샘플을 사용하는 경우 PostgreSQL)에서 트랜잭션 데이터 레이크로 데이터를 수집하려면 다음 단계를 완료하세요.
- AWS DMS 콘솔에서 다음을 선택합니다. 데이터베이스 마이그레이션 작업 탐색 창에서
- 생성한 복제 작업을 선택하고 행위 메뉴, 선택 다시 시작/재개.
- 복제 작업이 완료될 때까지 5분 정도 기다립니다. 에서 수집된 테이블을 모니터링할 수 있습니다. 통계 복제 작업의 탭.

몇 분 후 메시지와 함께 작업이 완료됩니다. 전체 로드 완료.
- Amazon S3 콘솔에서 원시 계층으로 정의한 버킷을 선택합니다.
AWS DMS에 정의된 S3 접두사(예: postgres) 다음 구조의 폴더 계층이 표시되어야 합니다.
- 개요
- 테이블 이름
LOAD00000001.parquetLOAD0000000N.parquet
- 테이블 이름

S3 버킷이 비어 있으면 검토하십시오. AWS Database Migration Service의 마이그레이션 작업 문제 해결 AWS Glue 작업을 실행하기 전에.
Iceberg 테이블에 데이터 생성 및 수집
작업을 실행하기 전에 CloudFormation 스택의 일부로 제공된 AWS Glue 작업의 스크립트를 탐색하여 동작을 이해해 보겠습니다.
- AWS Glue Studio 콘솔에서 다음을 선택합니다. 작업 탐색 창에서
- 로 시작하는 작업 검색
IcebergJob-CloudFormation 스택 이름의 접미사(예:IcebergJob-transactionaldl-postgresql). - 직업을 선택하십시오.

작업 스크립트는 Parameter Store에서 필요한 구성을 가져옵니다. 함수 getConfigFromSSM() 데이터를 읽고 써야 하는 원본 및 대상 버킷과 같은 작업 관련 구성을 반환합니다. 변수 ssmparam_table_values 데이터 도메인, 테이블 이름, 파티션 열, 수집해야 하는 테이블의 기본 키와 같은 테이블 관련 정보를 포함합니다. 다음 Python 코드를 참조하십시오.
# Main application
args = getResolvedOptions(sys.argv, ['JOB_NAME', 'stackName'])
SSM_PARAMETER_NAME = f"{args['stackName']}-iceberg-config"
SSM_TABLE_PARAMETER_NAME = f"{args['stackName']}-iceberg-tables" # Parameters for job
rawS3BucketName, rawBucketPrefix, stageS3BucketName, warehouse_path = getConfigFromSSM(SSM_PARAMETER_NAME)
ssm_param_table_values = json.loads(ssmClient.get_parameter(Name = SSM_TABLE_PARAMETER_NAME)['Parameter']['Value'])
dropColumnList = ['db','table_name', 'schema_name','Op', 'last_update_time', 'max_op_date']스크립트는 my_catalog로 정의된 Iceberg의 임의 카탈로그 이름을 사용합니다. 이는 Spark 구성을 사용하여 AWS Glue 데이터 카탈로그에서 구현되므로 my_catalog를 가리키는 SQL 작업이 데이터 카탈로그에 적용됩니다. 다음 코드를 참조하십시오.
catalog_name = 'my_catalog'
errored_table_list = [] # Iceberg configuration
spark = SparkSession.builder .config('spark.sql.warehouse.dir', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}', 'org.apache.iceberg.spark.SparkCatalog') .config(f'spark.sql.catalog.{catalog_name}.warehouse', warehouse_path) .config(f'spark.sql.catalog.{catalog_name}.catalog-impl', 'org.apache.iceberg.aws.glue.GlueCatalog') .config(f'spark.sql.catalog.{catalog_name}.io-impl', 'org.apache.iceberg.aws.s3.S3FileIO') .config('spark.sql.extensions', 'org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions') .getOrCreate()
스크립트는 Parameter Store에 정의된 테이블을 반복하고 테이블이 존재하는지, 수신 데이터가 초기 로드인지 upsert인지 감지하기 위한 논리를 수행합니다.
# Iteration over tables stored on Parameter Store
for key in ssm_param_table_values: # Get table data isTableExists = False schemaName, tableName = key.split('.') logger.info(f'Processing table : {tableName}')XNUMXD덴탈의 initialLoadRecordsSparkSQL() 함수는 S3 파일에 작업 열이 없을 때 초기 데이터를 로드합니다. AWS DMS는 연속 복제(CDC)에서 생성된 Parquet 데이터 파일에만 이 열을 추가합니다. 데이터 로드는 SparkSQL과 함께 INSERT INTO 명령을 사용하여 수행됩니다. 다음 코드를 참조하십시오.
sqltemp = Template(""" INSERT INTO $catalog_name.$dbName.$tableName ($insertTableColumnList) SELECT $insertTableColumnList FROM insertTable $partitionStrSQL """)
SQLQUERY = sqltemp.substitute( catalog_name = catalog_name, dbName = dbName, tableName = tableName, insertTableColumnList = insertTableColumnList[ : -1], partitionStrSQL = partitionStrSQL) logger.info(f'****SQL QUERY IS : {SQLQUERY}')
spark.sql(SQLQUERY)
이제 AWS Glue 작업을 실행하여 초기 데이터를 Iceberg 테이블로 수집합니다. CloudFormation 스택은 다음을 추가합니다. --datalake-formats 필요한 Iceberg 라이브러리를 작업에 추가합니다.
- 왼쪽 메뉴에서 작업 실행.
- 왼쪽 메뉴에서 작업 실행 상태를 모니터링합니다. 상태가 될 때까지 기다리십시오. 실행 성공.
로드된 데이터 확인
작업이 예상대로 데이터를 처리했는지 확인하려면 다음 단계를 완료하십시오.
- Athena 콘솔에서 쿼리 편집기 탐색 창에서
- 확인
AwsDataCatalog데이터 소스로 선택되었습니다. - $XNUMX Million 미만 데이터베이스, 파라미터 스토어에서 정의한 구성에 따라 탐색할 데이터 도메인을 선택합니다. 제공된 샘플 데이터베이스를 사용하는 경우 다음을 사용하십시오.
sports.
$XNUMX Million 미만 테이블과 뷰, AWS Glue 작업으로 생성된 테이블 목록을 볼 수 있습니다.
- 첫 번째 테이블 이름 옆에 있는 옵션 메뉴(점 XNUMX개)를 선택한 다음 데이터 미리보기.
Iceberg 테이블에 로드된 데이터를 볼 수 있습니다. 
증분 데이터 로드 수행
이제 관계형 데이터베이스에서 변경 사항을 캡처하여 트랜잭션 데이터 레이크에 적용하기 시작합니다. 이 단계는 변경 사항 캡처, Iceberg 테이블에 적용 및 결과 확인의 세 부분으로 나뉩니다.
관계형 데이터베이스에서 변경 사항 캡처
지정한 구성으로 인해 전체 로드 단계를 실행한 후 복제 작업이 중지되었습니다. 이제 데이터 레이크의 원시 계층에 변경 사항이 있는 증분 파일을 추가하는 작업을 다시 시작합니다.
- AWS DMS 콘솔에서 이전에 생성하고 실행한 작업을 선택합니다.
- 에 행위 메뉴, 선택 이력서.
- 왼쪽 메뉴에서 작업 시작 변경 사항 캡처를 시작합니다.
- 데이터 레이크에서 새 파일 생성을 트리거하려면 선호하는 데이터베이스 관리 도구를 사용하여 원본 데이터베이스의 테이블에서 삽입, 업데이트 또는 삭제를 수행합니다. 제공된 샘플 데이터베이스를 사용하는 경우 다음 SQL 명령을 실행할 수 있습니다.
UPDATE dms_sample.nfl_stadium_data_upd
SET seatin_capacity=93703
WHERE team = 'Los Angeles Rams' and sport_location_id = '31'; update dms_sample.mlb_data set bats = 'R'
where mlb_id=506560 and bats='L'; update dms_sample.sporting_event set start_date = current_date where id=11 and sold_out=0;
- AWS DMS 작업 세부 정보 페이지에서 다음을 선택합니다. 테이블 통계 탭을 탭하여 캡처된 변경 사항을 확인합니다.

- 데이터 레이크의 원시 계층을 열어 모든 테이블의 접두사(예:
sporting_event접두사.
에 대한 변경 사항이 있는 기록 sporting_event 표는 다음 스크린샷과 같습니다.

공지 사항 Op 업데이트로 식별된 시작 부분의 열(U). 또한 두 번째 날짜/시간 값은 변경 사항이 캡처된 시간과 함께 AWS DMS에서 추가한 제어 열입니다.

AWS Glue를 사용하여 Iceberg 테이블에 변경 사항 적용
이제 AWS Glue 작업을 다시 실행하고 작업 북마크가 활성화되었으므로 새 증분 파일만 자동으로 처리합니다. 어떻게 작동하는지 검토해 보겠습니다.
XNUMXD덴탈의 dedupCDCRecords() 기능은 단일 레코드 ID에 대한 여러 변경 사항이 Amazon S3의 동일한 데이터 파일 내에서 캡처될 수 있기 때문에 데이터 중복 제거를 수행합니다. 중복 제거는 다음을 기반으로 수행됩니다. last_update_time 변경이 캡처된 시간의 타임스탬프를 나타내는 AWS DMS에서 추가한 열입니다. 다음 Python 코드를 참조하십시오.
def dedupCDCRecords(inputDf, keylist): IDWindowDF = Window.partitionBy(*keylist).orderBy(inputDf.last_update_time).rangeBetween(-sys.maxsize, sys.maxsize) inputDFWithTS = inputDf.withColumn('max_op_date', max(inputDf.last_update_time).over(IDWindowDF)) NewInsertsDF = inputDFWithTS.filter('last_update_time=max_op_date').filter("op='I'") UpdateDeleteDf = inputDFWithTS.filter('last_update_time=max_op_date').filter("op IN ('U','D')") finalInputDF = NewInsertsDF.unionAll(UpdateDeleteDf) return finalInputDF99 번째 줄에서 upsertRecordsSparkSQL() 함수는 초기 로드와 유사한 방식으로 upsert를 수행하지만 이번에는 SQL MERGE 명령을 사용합니다.
적용된 변경사항 검토
Athena 콘솔을 열고 원본 데이터베이스에서 변경된 레코드를 선택하는 쿼리를 실행합니다. 제공된 샘플 데이터베이스를 사용하는 경우 다음 SQL 쿼리 중 하나를 사용합니다.
SELECT * FROM "sports"."nfl_stadiu_data_upd"
WHERE team = 'Los Angeles Rams' and sport_location_id = 31
LIMIT 1;

테이블 수집 모니터링
AWS Glue 작업 스크립트는 간단한 파이썬 예외 처리 특정 테이블을 처리하는 동안 오류를 포착합니다. 오류가 있는 테이블에 대해 작업 실행을 다시 시도하는 경우 테이블을 다시 처리하지 않도록 각 테이블이 성공적으로 처리를 마친 후에 작업 북마크가 저장됩니다.
XNUMXD덴탈의 AWS 명령 줄 인터페이스 (AWS CLI)는 get-job-bookmark 처리된 각 테이블의 책갈피 상태에 대한 통찰력을 제공하는 AWS Glue용 명령입니다.
- AWS Glue Studio 콘솔에서 ETL 작업을 선택합니다.
- 선택 작업 실행 탭을 클릭하고 작업 실행 ID를 복사합니다.
- AWS CLI에 대해 인증된 터미널에서 다음 명령을 실행하여
<GLUE_JOB_RUN_ID>복사한 값으로 1행에 CloudFormation 스택의 이름이 지정되지 않은 경우transactionaldl-postgresql, 스크립트의 2행에 작업 이름을 제공하십시오.
jobrun=<GLUE_JOB_RUN_ID>
jobname=IcebergJob-transactionaldl-postgresql
aws glue get-job-bookmark --job-name jobname --run-id $jobrun이 솔루션에서 테이블 처리로 인해 예외가 발생하면 이 논리에 따라 AWS Glue 작업이 실패하지 않습니다. 대신 작업이 완료된 후 인쇄되는 배열에 테이블이 추가됩니다. 이러한 시나리오에서 작업은 원시 데이터 원본에서 검색된 나머지 테이블을 처리하려고 시도한 후 실패로 표시됩니다. 이렇게 하면 오류가 없는 테이블은 사용자가 충돌하는 테이블에서 문제를 식별하고 해결할 때까지 기다릴 필요가 없습니다. 사용자는 AWS Glue 작업 실행 상태를 사용하여 문제가 있는 작업 실행을 빠르게 감지하고 작업 실행에 대한 CloudWatch 로그를 사용하여 문제를 일으키는 특정 테이블을 식별할 수 있습니다.
- 작업 스크립트는 다음 Python 코드로 이 기능을 구현합니다.
# Performed for every table try: # Table processing logic except Exception as e: logger.info(f'There is an issue with table: {tableName}') logger.info(f'The exception is : {e}') errored_table_list.append(tableName) continue job.commit()
if (len(errored_table_list)): logger.info('Total number of errored tables are ',len(errored_table_list)) logger.info('Tables that failed during processing are ', *errored_table_list, sep=', ') raise Exception(f'***** Some tables failed to process.')다음 스크린샷은 CloudWatch 로그가 처리 오류를 일으키는 테이블을 찾는 방법을 보여줍니다.

에 맞춰 AWS Well-Architected 프레임워크 데이터 분석 렌즈 관행에 따라 데이터 파이프라인에 오류가 나타날 때 이해 관계자를 식별하고 알릴 수 있도록 보다 정교한 제어 메커니즘을 적용할 수 있습니다. 예를 들어 다음을 사용할 수 있습니다. 아마존 DynamoDB 오류가 있는 모든 테이블 및 작업 실행을 저장하거나 다음을 사용하는 제어 테이블 아마존 단순 알림 서비스 (아마존 SNS)에 운영자에게 경고 보내기 특정 기준이 충족되면.
증분 배치 데이터 로드 예약
CloudFormation 스택은 아마존 이벤트 브리지 일정에 따라 실행되도록 AWS Glue 작업을 트리거할 수 있는 규칙(기본적으로 비활성화됨). 고유한 일정을 제공하고 규칙을 활성화하려면 다음 단계를 완료하십시오.
- EventBridge 콘솔에서 다음을 선택합니다. 규칙 탐색 창에서
- CloudFormation 스택의 이름이 접두사로 붙은 규칙을 검색하십시오.
JobTrigger(예 :transactionaldl-postgresql-JobTrigger-randomvalue). - 규칙을 선택합니다.
- $XNUMX Million 미만 이벤트 일정선택한다. 편집.
기본 일정은 매시간 트리거되도록 구성됩니다.
- 작업을 실행할 일정을 제공합니다.
- 또한 다음을 사용할 수 있습니다. EventBridge 크론 표현식 선택하여 세분화된 일정.

- cron 표현식 설정을 마치면 다음을 선택합니다. 다음 보기 세 번, 그리고 마지막으로 선택 업데이트 규칙 변경 사항을 저장합니다.
규칙은 기본적으로 비활성화되어 생성되어 초기 데이터 로드를 먼저 실행할 수 있습니다.
- 선택하여 규칙을 활성화합니다. 사용.
당신은을 사용할 수 있습니다 모니터링 규칙 호출을 보거나 AWS Glue에서 직접 탭 작업 실행 세부.
결론
이 솔루션을 배포한 후 단일 관계형 데이터 원본에서 테이블 수집을 자동화했습니다. 데이터 레이크를 중앙 데이터 플랫폼으로 사용하는 조직은 일반적으로 여러 데이터, 경우에 따라 수십 개의 데이터 소스를 처리해야 합니다. 또한 조직에서 데이터 레이크에 대한 트랜잭션 기능을 구현해야 하는 사용 사례가 점점 더 많아지고 있습니다. 이 솔루션을 사용하여 모든 관계형 데이터 소스에서 이러한 기능의 채택을 가속화하여 새로운 비즈니스 사용 사례를 활성화하고 구현 프로세스를 자동화하여 데이터에서 더 많은 가치를 도출할 수 있습니다.
저자에 관하여
 루이스 헤라르도 바에사 Amazon Web Services(AWS) Data Lab의 빅 데이터 아키텍트입니다. 그는 12년 동안 의료, 금융 및 교육 부문의 조직이 엔터프라이즈 아키텍처 프로그램, 클라우드 컴퓨팅 및 데이터 분석 기능을 채택하도록 돕는 경험을 가지고 있습니다. Luis는 현재 라틴 아메리카 전역의 조직이 전략적 데이터 이니셔티브를 가속화하도록 돕고 있습니다.
루이스 헤라르도 바에사 Amazon Web Services(AWS) Data Lab의 빅 데이터 아키텍트입니다. 그는 12년 동안 의료, 금융 및 교육 부문의 조직이 엔터프라이즈 아키텍처 프로그램, 클라우드 컴퓨팅 및 데이터 분석 기능을 채택하도록 돕는 경험을 가지고 있습니다. Luis는 현재 라틴 아메리카 전역의 조직이 전략적 데이터 이니셔티브를 가속화하도록 돕고 있습니다.
 사이키란 레디 애누구 Amazon Web Services(AWS) Data Lab의 데이터 아키텍트입니다. 그는 데이터 로딩, 변환 및 시각화 프로세스를 구현한 10년의 경험을 가지고 있습니다. SaiKiran은 현재 북미 지역의 조직이 데이터 레이크 및 데이터 메시와 같은 최신 데이터 아키텍처를 채택하도록 돕고 있습니다. 그는 소매, 항공 및 금융 부문에서 경험을 쌓았습니다.
사이키란 레디 애누구 Amazon Web Services(AWS) Data Lab의 데이터 아키텍트입니다. 그는 데이터 로딩, 변환 및 시각화 프로세스를 구현한 10년의 경험을 가지고 있습니다. SaiKiran은 현재 북미 지역의 조직이 데이터 레이크 및 데이터 메시와 같은 최신 데이터 아키텍처를 채택하도록 돕고 있습니다. 그는 소매, 항공 및 금융 부문에서 경험을 쌓았습니다.
 나렌드라 멀라 Amazon Web Services(AWS) Data Lab의 데이터 아키텍트입니다. 그는 실시간 및 배치 지향 데이터 파이프라인을 모두 설계 및 생산하고 클라우드 및 온프레미스 환경에서 데이터 레이크를 구축하는 데 12년의 경험을 가지고 있습니다. Narendra는 현재 북미 지역의 조직이 강력한 데이터 아키텍처를 구축 및 설계하도록 돕고 있으며 통신 및 금융 부문에서 경험이 있습니다.
나렌드라 멀라 Amazon Web Services(AWS) Data Lab의 데이터 아키텍트입니다. 그는 실시간 및 배치 지향 데이터 파이프라인을 모두 설계 및 생산하고 클라우드 및 온프레미스 환경에서 데이터 레이크를 구축하는 데 12년의 경험을 가지고 있습니다. Narendra는 현재 북미 지역의 조직이 강력한 데이터 아키텍처를 구축 및 설계하도록 돕고 있으며 통신 및 금융 부문에서 경험이 있습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/automate-replication-of-relational-sources-into-a-transactional-data-lake-with-apache-iceberg-and-aws-glue/
- 1
- 10
- 100
- 102
- 107
- 7
- a
- 소개
- 가속
- ACCESS
- 에 따르면
- 인정
- 가로질러
- 각색하다
- 추가
- 추가
- 또한
- 추가
- 관리자
- 관리
- 채택
- 양자
- 후
- 항공 회사
- All
- 이미
- 아마존
- 아마존 아테나
- 아마존 RDS
- Amazon Web Services
- Amazon Web Services (AWS)
- 미국
- 분석
- 분석
- 과
- 앤젤레스
- 아파치
- 표시
- 어플리케이션
- 적용된
- 적용
- 접근
- 대략
- 아키텍처
- 배열
- 관련
- 인증 된
- 자동화
- 자동화
- 자동적으로
- 자동화
- 평균
- 피하기
- AWS
- AWS 클라우드 포메이션
- AWS 접착제
- 기반으로
- 박쥐
- 때문에
- 가
- 전에
- 처음
- 큰
- 빅 데이터
- 빌드
- 건축업자
- 건물
- 사업
- 얻을 수 있습니다
- 기능
- 모자
- 포착
- 캡처
- 케이스
- 가지 경우
- 목록
- 잡아라
- 원인
- 원인
- 일으키는
- CDC
- 중심적인
- 어떤
- 이전 단계로 돌아가기
- 변경
- 선택
- 왼쪽 메뉴에서
- 선택
- 선택
- 클라우드
- 클라우드 컴퓨팅
- 암호
- 단
- 열
- 회사
- 완전한
- 컴퓨팅
- 구성
- 구성
- 확인하기
- 서로 싸우는
- 연결하기
- 연결
- 고려 사항
- 콘솔에서
- 소비자
- 소비
- 이 포함되어 있습니다
- 계속
- 끊임없는
- 제어
- 수
- 만들
- 만든
- 생성
- 만들기
- 창조
- 기준
- 현재
- 관습
- 고객
- 사용자 정의
- 데이터
- 데이터 분석
- 데이터 레이크
- 데이터 플랫폼
- 데이터베이스
- 데이터베이스
- 날짜
- 태만
- 한정된
- 배포
- 배포
- 배치
- 전개
- 배치하다
- 디자인
- 설계
- 설계
- 세부설명
- 탐지 된
- 개발
- 다른
- 직접
- 사용
- 분할 된
- 하지 않습니다
- 도메인
- 도메인
- 말라
- ...동안
- 마다
- 이전
- 용이하게
- 교육
- 노력
- 중
- 가능
- 사용 가능
- 암호화
- 암호화
- 종점
- 엔진
- 엔터 버튼
- Enterprise
- 환경
- 오류
- 에테르 (ETH)
- 조차
- 모든
- 예
- 초과
- 외
- 예외
- 현존하는
- 존재
- 기대하는
- ~을 기대하는
- 경험
- 탐험
- 확장
- 추출물
- 실패한
- 익숙한
- 패션
- 특색
- 를
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 파일
- 최종적으로
- 재원
- 금융
- Find
- 마무리
- 먼저,
- 다음에
- 수행원
- 소비자 용
- 형태
- 형성
- 뼈대
- 에
- 가득 찬
- 기능
- 생성
- 세대
- 얻을
- 부여
- 보조금
- 성장하는
- 핸들
- 건강 관리
- 도움이
- 도움이
- 계층
- history
- 보유
- 방법
- How To
- HTML
- HTTPS
- 거대한
- IAM
- 확인
- 식별자
- 식별하다
- 확인
- 구현
- 이행
- 구현
- 구현
- 구현하다
- 개량
- in
- 포함
- 포함
- 포함
- 들어오는
- 표시
- 개인
- 정보
- 처음에는
- 이니셔티브
- 삽입물
- 통찰력
- 예
- 를 받아야 하는 미국 여행자
- 명령
- 중간의
- 발행물
- 문제
- IT
- 되풀이
- 일
- 작업
- JSON
- 유지
- 키
- 키
- 알아
- 실험실
- 소금물
- 라틴어
- 라틴 아메리카
- 층
- 레이어
- 리드
- 배우다
- 도서관
- 제한
- 라인
- 명부
- 하중
- 로드
- 잔뜩
- 위치
- 보기
- 봐라.
- 그들
- 로스엔젤레스
- 롯
- 본관
- 유지
- 확인
- 관리
- 구축
- 매니저
- 관리
- 수동으로
- .
- 매핑
- 두드러진
- 메뉴
- 병합
- 메시지
- 수도
- 이주
- 최저한의
- 분
- 분
- 현대
- 수정
- 모니터
- 모니터링
- 배우기
- 가장
- 가장 인기 많은
- 여러
- name
- 이름
- 이름
- 이동
- 카테고리
- 필요
- 필요
- 요구
- 신제품
- 다음 것
- North
- 북아메리카
- 공고
- 번호
- 대상
- 사물
- ONE
- 지속적으로
- OP
- 조작
- 최적화
- 옵션
- 조직
- 조직
- 최
- 실물
- 그렇지 않으면
- 외부
- 자신의
- 소유자
- 빵
- 매개 변수
- 매개 변수
- 부품
- 부품
- 통로
- 무늬
- 수행
- 실행할 수 있는
- 수행하다
- 기간
- 권한
- 상
- 플랫폼
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 인기 문서
- 게시하다
- Postgresql
- 사례
- 선호하는
- 전제 조건
- 제시
- 일차
- 문제
- 방법
- 프로세스
- 처리
- 생산
- 프로그램
- 제공
- 제공
- 제공
- Python
- 빨리
- 모집
- 율
- 살갗이 벗어 진
- 원시 데이터
- 읽기
- 실시간
- 기록
- 기록
- 교체
- 복제 된
- 복제
- 필요
- 필수
- 의지
- 자료
- REST
- 결과
- 소매
- return
- 반품
- 리뷰
- 강력한
- 직위별
- 통치
- 규칙
- 달리기
- 달리는
- 같은
- 찜하기
- 대본
- 예정
- 범위
- 스크립트
- 검색
- 둘째
- 부문
- 보고
- 선택된
- 선택
- 선택
- 별도의
- 서비스
- 세트
- 설정
- 설정
- 영상을
- 표시
- 쇼
- 비슷한
- 단순, 간단, 편리
- 이후
- 단일
- So
- 해결책
- 해결
- 일부
- 정교한
- 출처
- 지우면 좋을거같음 . SM
- 공간
- 불꽃
- 구체적인
- 명세서
- 지정
- 스포츠
- SQL
- 스택
- 스택
- 단계
- 이해 관계자
- 스타트
- 시작
- 시작 중
- 시작
- 미국
- 통계
- Status
- 단계
- 단계
- 정지
- 저장
- 저장
- 저장
- 상점
- 전략의
- 구조
- 구조화
- 스튜디오
- 성공적으로
- 이러한
- 감독자
- SUPPORT
- 시스템은
- 테이블
- 목표
- 태스크
- 작업
- 팀
- 팀
- 통신
- 이 템플릿
- 단말기
- XNUMXD덴탈의
- 소스
- 그들의
- 수천
- 세
- 을 통하여
- 시간
- 타임 라인
- 시대
- 따라서 오른쪽 하단에
- 에
- 수단
- 상단
- 금액
- 추적
- 전통적인
- 거래상의
- 변환
- 변환
- 트리거
- 지도 시간
- 유형
- 아래에
- 이해
- 유일한
- 업데이트
- 업데이트
- 사용
- 유스 케이스
- 사용자
- 사용자
- 보통
- 가치
- 확인하는
- 관측
- 심상
- 음량
- 기다리다
- 창고
- 웹
- 웹 서비스
- 어느
- 의지
- 이내
- 없이
- 일
- 쓰다
- 쓴
- 얌
- year
- 년
- 너의
- 제퍼 넷