이 기사는 데이터 과학 Blogathon
개요

ConvNets라고도 하는 컨볼루션 신경망은 1980년대 백그라운드에서 일한 컴퓨터 과학 연구원인 Yann LeCun에 의해 처음 소개되었습니다. LeCun은 이미지 인식을 위한 기본 네트워크인 일본 과학자 Kunihiko Fukushima의 작업을 기반으로 구축되었습니다.
LeNet(LeCun 이후)이라고 하는 이전 버전의 CNN은 손으로 쓴 숫자를 볼 수 있습니다. CNN은 우편에서 핀 코드를 찾는 데 도움이 됩니다. 그러나 전문 지식에도 불구하고 ConvNet은 큰 문제에 직면했기 때문에 컴퓨터 비전 및 인공 지능에 근접했습니다. 확장할 수 없다는 것입니다. CNN은 큰 이미지에서 잘 작동하기 위해 많은 데이터와 통합 리소스가 필요합니다.
당시 이 방법은 저해상도 이미지에만 적용할 수 있었습니다. Pytorch는 딥 러닝 작업을 수행할 수 있는 라이브러리입니다. 이것을 사용하여 컨볼루션 신경망을 수행할 수 있습니다. 컨볼루션 신경망에는 여러 계층의 인공 뉴런이 포함되어 있습니다. 생물학적 대응물의 복잡한 시뮬레이션인 합성 뉴런은 다중 입력 및 제품 가치 활성화의 가중 질량을 계산하는 수학 함수입니다.

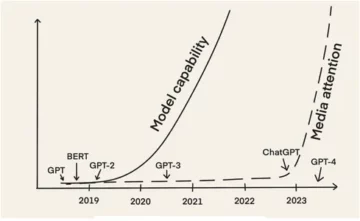
위의 이미지는 2의 숫자와 같은 이미지를 가져와 이미지에 숫자로 표시된 숫자의 결과를 제공하는 CNN 모델을 보여줍니다. 이 기사에서 이것을 얻는 방법에 대해 자세히 설명합니다.
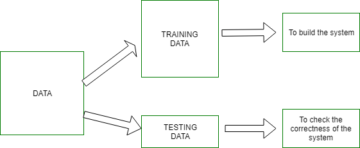
CIFAR-10은 10가지 다른 클래스의 이미지 모음이 있는 데이터세트입니다. 이 데이터 세트는 다양한 기계 학습 모델, 특히 컴퓨터 비전 문제를 테스트하기 위한 연구 목적으로 널리 사용됩니다. 이 기사에서는 Pytorch를 사용하여 신경망 모델을 구축하고 CIFAR-10 데이터 세트에서 테스트하여 얻을 수 있는 예측 정확도를 확인하려고 합니다.
PyTorch 라이브러리 가져오기
numpy를 np로 가져오기 pandas를 pd로 가져오기
토치 가져오기 토치 가져오기 데이터 세트에서 F로 기능 가져오기 토치 가져오기 nn 가져오기 matplotlib.pyplot에서 plt 가져오기 numpy로 np 가져오기 sns로 가져오기 seaborn #tqdm.notebook에서 가져오기 tqdm에서 tqdm 가져오기 tqdm 가져오기
이 단계에서는 필요한 라이브러리를 가져옵니다. 수치 연산에 NumPy를 사용하고 데이터 프레임 연산에 팬더를 사용하는 것을 볼 수 있습니다. 토치 라이브러리는 Pytorch를 가져오는 데 사용됩니다.
Pytorch에는 기계 학습 작업 및 기능의 추상화에 사용되는 nn 구성 요소가 있습니다. 이것은 F로 가져옵니다. CIFAR-10 데이터 세트를 가져올 수 있도록 토치비전 라이브러리가 사용됩니다. 이 라이브러리에는 많은 이미지 데이터 세트가 있으며 연구에 널리 사용됩니다. 모든 이미지에 대해 동일한 크기로 이미지 크기를 조정할 수 있도록 변환을 가져올 수 있습니다. tqdm은 훈련 중 진행 상황을 추적할 수 있도록 사용되며 시각화에 사용됩니다.
필요한 데이터 세트 읽기
trainData = pd.read_csv('cifar-10/trainLabels.csv') trainData.head()
데이터 세트를 읽으면 개구리, 트럭, 사슴, 자동차 등과 같은 다양한 레이블을 볼 수 있습니다.
PyTorch로 데이터 분석하기
print("포인트 수:",trainData.shape[0]) print("피처 수:",trainData.shape[1]) print("특성:",trainData.columns.values) print("포인트 수:",trainData.shape[12,8]) trainData의 col에 대한 고유 값"): print(col,":",len(trainData[col].unique())) plt.figure(figsize=(XNUMX))
출력:
포인트 수: 50000 기능 수: 2 기능: ['id' 'label'] 고유 값 수 id: 50000 레이블: 10
이 단계에서는 데이터 세트를 분석하고 기차 데이터에 ID 및 관련 레이블이 있는 약 50000개의 행이 있음을 확인합니다. CIFAR-10이라는 이름처럼 총 10개의 클래스가 있습니다.
PyTorch를 사용하여 유효성 검사 세트 가져오기
토치.utils.data에서 가져오기 random_split val_size = 5000 train_size = len(dataset) - val_size train_ds, val_ds = random_split(dataset, [train_size, val_size]) len(train_ds), len(val_ds)
이 단계는 학습 단계와 동일하지만 데이터를 학습 및 검증 세트로 분할하려고 합니다.
(45000, 5000)
토치.utils.data.dataloader에서 가져오기 DataLoader batch_size=64 train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True) val_dl = DataLoader(val_ds, batch_size, num_workers=4, pin_memory=True)
torch.utils에는 작업자 번호 또는 배치 크기와 같은 다양한 매개변수를 우회하여 필요한 데이터를 로드하는 데 도움이 되는 데이터 로더가 있습니다.
필요한 기능 정의
@torch.no_grad() def 정확도(출력, 레이블): _, preds = torch.max(출력, dim=1) 반환 torch.tensor(torch.sum(preds == 레이블).item() / len(preds )) class ImageClassificationBase(nn.Module): def training_step(self, batch): images, labels = batch out = self(images) # 예측 생성 loss = F.cross_entropy(out, labels) # 손실 계산 accu = 정확도(out ,labels) return loss,accu def validation_step(self, batch): images, labels = batch out = self(images) # 예측 생성 loss = F.cross_entropy(out, labels) # 손실 계산 acc = 정확도(out, labels) # 정확도 계산 return {'Loss': loss.detach(), 'Accuracy': acc} def validation_epoch_end(self, output): batch_losses = [x['Loss'] for x in output] epoch_loss = torch.stack(batch_losses ).mean() # 손실 결합 batch_accs = [x['Accuracy' for x in output] epoch_acc = torch.stack(batch_accs).mean() # 결합 정확도 return {'Loss': epoch_loss.item(), ' 정확도': epoch_acc.item()} def epoch_end(self, epoch, result): pr int("Epoch :",epoch + 1) print(f'열차 정확도:{result["train_accuracy"]*100:.2f}% 유효성 검사 정확도:{result["정확도"]*100:.2f}%' ) print(f'열차 손실:{result["train_loss"]:.4f} 유효성 검사 손실:{result["손실"]:.4f}')
여기에서 볼 수 있듯이 ImageClassification의 클래스 구현을 사용했으며 nn.Module이라는 하나의 매개변수를 사용합니다. 이 클래스 내에서 훈련, 검증 등과 같은 다양한 기능 또는 다양한 단계를 구현할 수 있습니다. 여기의 기능은 간단한 파이썬 구현입니다.
훈련 단계에서는 이미지와 레이블을 일괄적으로 가져옵니다. 손실 함수에 대해 교차 엔트로피를 사용하고 손실을 계산하고 손실을 반환합니다. 이것은 함수에서 볼 수 있는 유효성 검사 단계와 유사합니다. Epoch 끝은 손실과 정확도를 결합하고 마지막으로 정확도와 손실을 인쇄합니다.
컨볼루션 신경망 모듈 구현
클래스 Cifar10CnnModel(ImageClassificationBase): def __init__(self): super().__init__() self.network = nn.Sequential( nn.Conv2d(3, 32, kernel_size=3, padding=1), nn.ReLU(), nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(2, 2), # 출력: 64 x 16 x 16 nn.BatchNorm2d(64) , nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1), nn .ReLU(), nn.MaxPool2d(2, 2), # 출력: 128 x 8 x 8 nn.BatchNorm2d(128), nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1), nn.ReLU(), nn.MaxPool2d(2, 2), # 출력: 256 x 4 x 4 nn.BatchNorm2d(256), nn.Flatten(), nn.Linear(256*4*4, 1024), nn.ReLU(), nn.Linear(1024, 512), nn.ReLU(), nn.Linear (512, 10)) def forward(self, xb): self.network(xb)를 반환합니다.
이것은 신경망 구현에서 가장 중요한 부분입니다. 전체적으로 우리는 토치에서 가져온 nn 모듈을 사용합니다. 첫 번째 줄에서 볼 수 있듯이 Conv2d는 합성곱 신경망을 구현하는 데 도움이 되는 모듈입니다. 여기서 첫 번째 매개변수 3은 이미지가 RGB 형식으로 색상이 지정되었음을 나타냅니다. 그것이 회색조 이미지라면 우리는 1로 갔을 것입니다.
32는 초기 출력 채널의 크기이며 다음 conv2d 레이어로 이동할 때 이 32를 입력 채널로, 64를 출력 채널로 사용합니다.
첫 번째 줄의 세 번째 매개변수는 커널 크기라고 하며 사용된 필터를 관리하는 데 도움이 됩니다. 패딩 작업은 마지막 매개변수입니다.
여기서 컨볼루션 연산은 활성화 계층과 Relu에 연결됩니다. 두 개의 Conv2d 레이어 후에 크기가 2 * 2인 최대 풀링 작업이 있습니다. 여기서 나오는 값은 안정성과 내부 공변량 이동을 피하기 위해 일괄 정규화됩니다. 이러한 작업은 네트워크를 더 깊게 하고 크기를 줄이기 위해 더 많은 계층에서 반복됩니다. 마지막으로 값을 10개 값에 매핑하는 선형 레이어를 만들 수 있도록 레이어를 병합합니다. 이 10개 뉴런의 각 뉴런의 확률은 최대 확률을 기반으로 특정 이미지가 속하는 클래스를 결정합니다.
모델 훈련
@torch.no_grad() def 평가(model, data_loader): model.eval() 출력 = [data_loader의 일괄 처리에 대한 model.validation_step(batch)] return model.validation_epoch_end(출력) def fit(model, train_loader, val_loader, epochs =10,learning_rate=0.001): best_valid = 없음 history = [] optimizer = torch.optim.Adam(model.parameters(), learning_rate,weight_decay=0.0005) for epoch in range(epochs): # 훈련 단계 model.train( ) train_losses = [] train_accuracy = [] tqdm(train_loader)의 일괄 처리: loss,accu = model.training_step(batch) train_losses.append(loss) train_accuracy.append(accu) loss.backward() optimizer.step() 옵티마이저 .zero_grad() # 검증 단계 결과 = 평가(모델, val_loader) result['train_loss'] = torch.stack(train_losses).mean().item() result['train_accuracy'] = torch.stack(train_accuracy). mean().item() model.epoch_end(epoch, result) if(best_valid == None 또는 best_valid
히스토리 = fit(모델, train_dl, val_dl)
이것은 필요한 결과를 얻기 위해 모델을 훈련시키는 기본 단계입니다. 여기서 fit 함수는 우리가 만든 모델에 기차와 Val 데이터를 맞출 것입니다. fit 함수는 처음에 모든 epoch의 반복 데이터를 처리하는 history라는 목록을 사용합니다. 각 epoch를 반복할 수 있도록 for 루프를 실행합니다. 각 배치에 대해 tqdm을 사용하여 진행 상황을 표시합니다. 우리는 이전에 구현한 훈련 단계를 호출하고 정확도와 손실을 계산합니다. 역전파로 이동하고 앞서 정의한 최적화 프로그램을 실행합니다. 이 작업을 수행하면 목록을 추적하고 기능을 통해 세부 정보와 진행 상황을 인쇄할 수 있습니다.
반면 평가 함수는 평가 함수를 사용하며 각 단계마다 데이터 로더에서 로드된 배치를 가져와 출력을 계산합니다. 그런 다음 값은 이전에 정의한 유효성 검사 에포크 끝으로 전달되고 해당 값이 반환됩니다.
결과 그리기
이 단계에서는 정확도 대 각 에포크를 시각화합니다. Epoch가 증가함에 따라 시스템의 정확도가 계속 증가하고 마찬가지로 손실이 계속 감소하는 것을 관찰할 수 있습니다. 여기에서 빨간색 선은 학습 데이터 진행률을 나타내고 파란색은 유효성 검사를 나타냅니다. 훈련 데이터가 검증 결과를 훨씬 능가하고 손실의 경우에도 유사하기 때문에 결과에 많은 양의 과적합이 있음을 알 수 있습니다. 10 에포크 후에 기차 데이터는 90% 정확도를 우회하는 것처럼 보이지만 약 0.5의 손실이 있습니다. 테스트 데이터는 약 81%이며 손실은 0.2에 가깝습니다.
def plot_accuracy(history): Validation_accurcies = [x['Accuracy'] for x in history] Training_Accurcies = [x['train_accuracy'] for x in history] plt.plot(Training_Accurcies, '-rx') plt.plot(Validation_accurcies , '-bx') plt.xlabel('epoch') plt.ylabel('accuracy') plt.legend(['교육', '검증']) plt.title('정확도 대 에포크 수') ; plot_accuracy(기록)

def plot_losses(history): train_losses = [x.get('train_loss') for x in history] val_losses = [x in history] plt.plot(train_losses, '-bx') plt.plot (val_losses, '-rx') plt.xlabel('epoch') plt.ylabel('loss') plt.legend(['Training', 'Validation']) plt.title('손실 대 epoch 수 '); plot_losses(이력)
test_dataset = ImageFolder(data_dir+'/test', transform=ToTensor()) test_loader = DeviceDataLoader(DataLoader(test_dataset, batch_size), 장치) 결과 = 평가(final_model, test_loader) print(f'테스트 정확도:{result["정확도" ]*100:.2f}%')
테스트 정확도: 81.07%
우리는 81.07%의 정확도로 끝난 것을 볼 수 있습니다.
결론 :
영상:https://unsplash.com/photos/5L0R8ZqPZHk
내 소개 : 저는 딥 러닝 및 자연어 처리 분야에 관심이 있고 현재 인공 지능에서 대학원 과정을 밟고 있는 연구 학생입니다.
이미지 소스
- Image 1: https://becominghuman.ai/cifar-10-image-classification-fd2ace47c5e8
- 이미지 2: https://www.analyticsvidhya.com/blog/2021/05/convolutional-neural-networks-cnn/
언제든지 저와 연락하십시오:
- 링크드인: https://www.linkedin.com/in/siddharth-m-426a9614a/
- 깃허브: https://github.com/Siddharth1698
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- "
- All
- 분석
- 약
- 기사
- 인공 지능
- 빌드
- 전화
- 한
- 현지 시간
- 오는
- 구성 요소
- 컴퓨터 과학
- 컴퓨터 비전
- 컨벌루션 신경망
- 데이터
- 깊은 학습
- 사슴
- 세부 묘사
- 손가락
- 숫자
- 종료
- 등
- 특징
- 필터
- 최종적으로
- 먼저,
- 맞게
- 체재
- 무료
- 기능
- GitHub의
- 좋은
- 그레이 스케일
- 여기에서 지금 확인해 보세요.
- history
- 방법
- HTTPS
- 영상
- 이미지 인식
- 증가
- 인텔리전스
- IT
- 레이블
- 언어
- 넓은
- 배우기
- 도서관
- 라인
- 링크드인
- 명부
- 하중
- 기계 학습
- 주요한
- 지도
- 미디어
- 모델
- 자연어
- 자연 언어 처리
- 가까운
- 네트워크
- 네트워크
- 신경
- 신경망
- 신경망
- 행정부
- 기타
- 예측
- 예측
- 프로덕트
- Python
- 파이 토치
- 감소
- 연구
- 자료
- 결과
- 달리기
- 규모
- 과학
- 세트
- 변화
- 단순, 간단, 편리
- 크기
- So
- 분열
- 안정
- 학생
- 체계
- test
- 시간
- 토치
- 선로
- 트레이닝
- 트럭
- us
- 가치
- 시력
- 심상
- 누구
- 이내
- 작업
- X