데이터 정리는 데이터 과학 프로젝트에서 매우 중요하고 중요한 단계입니다. 머신 모델의 성공 여부는 데이터 전처리 방법에 따라 달라집니다. 데이터 세트의 사전 처리를 과소평가하고 건너뛰면 모델이 제대로 작동하지 않으며 예상대로 작동하지 않는 이유를 이해하기 위해 검색하는 데 많은 시간을 허비하게 됩니다.
최근에는 데이터 과학 활동의 속도를 높이기 위해 치트 시트, 특히 데이터 정리의 기본 사항에 대한 요약을 만들기 시작했습니다. 이번 포스팅과 시트 속임수, 데이터 과학 프로젝트의 전처리 단계를 특징 짓는 다섯 가지 측면을 보여 드리겠습니다.

이 치트 시트에서, 우리는 누락된 데이터 감지 및 처리, 중복 처리 및 중복에 대한 솔루션 찾기, 이상값 감지, 레이블 인코딩 및 범주 기능의 원-핫 인코딩에서 MinMax 정규화 및 표준 정규화와 같은 변환으로 이동합니다. 또한 이 가이드는 Pandas, Scikit-Learn, Seaborn 등 가장 인기 있는 세 가지 Python 라이브러리에서 플롯을 표시하는 방법을 활용합니다.
이러한 Python 트릭을 학습하면 데이터 세트에서 가능한 한 더 많은 정보를 추출하는 데 도움이 되며 결과적으로 기계 학습 모델은 깨끗하고 전처리된 입력에서 학습하여 더 나은 성능을 발휘할 수 있습니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/02/data-cleaning-python-cheat-sheet.html?utm_source=rss&utm_medium=rss&utm_campaign=data-cleaning-with-python-cheat-sheet
더보기 너 겟츠



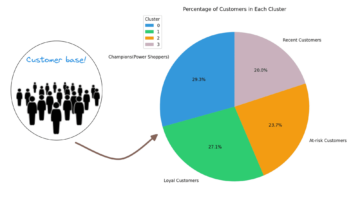

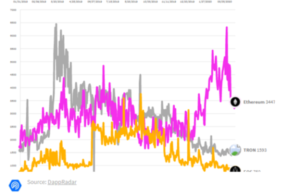



KDnuggets News, 13월 5일: 데이터 과학을 마스터하기 위한 XNUMX가지 슈퍼 치트 시트 • 데이터 과학을 위한 Google NotebookLM 사용: 종합 가이드 – KDnuggets
소스 노드 : 2420693
타임 스탬프 : 12월 13, 2023

DataOps.live를 통해 DataOps 성공을 실현하세요 – Gartner 시장 가이드에 소개! – KD너겟
소스 노드 : 2171188
타임 스탬프 : 14년 2023월 XNUMX일