다양한 소스에서 거의 매초마다 수집된 시계열 데이터는 종종 다음과 같은 영향을 받습니다. 여러 가지 데이터 품질 문제, 그중 누락된 데이터가 있습니다.
순차적 데이터의 맥락에서 누락된 정보는 여러 가지 이유로 인해 발생할 수 있습니다. 즉, 수집 시스템(예: 오작동 센서)에서 발생하는 오류, 전송 과정 중 오류 (예: 잘못된 네트워크 연결) 또는 데이터 수집 중 오류(예: 데이터 로깅 중 인적 오류). 이러한 상황은 수집된 데이터 스트림의 작은 공백에 해당하는 데이터 세트에서 산발적이고 명시적인 누락 값을 생성하는 경우가 많습니다.
또한, 없는 정보 또한 도메인 자체의 특성으로 인해 자연적으로 발생하여 데이터에 더 큰 간격이 발생할 수도 있습니다. 예를 들어 특정 기간 동안 수집을 중단하는 기능으로 인해 명시적이지 않은 누락 데이터가 생성됩니다.
근본 원인에 관계없이 시계열 시퀀스에 데이터가 누락되면 예측 및 예측 모델링에 매우 불리하며 개인(예: 잘못된 위험 평가)과 비즈니스 결과(예: 편향된 비즈니스 결정, 손실) 모두에 심각한 결과를 초래할 수 있습니다. 수익 및 기회).
따라서 모델링 접근 방식을 위한 데이터를 준비할 때 중요한 단계는 알려지지 않은 정보의 패턴을 식별할 수 있는 것입니다. 데이터를 처리하는 최선의 접근 방식 정렬 수정, 데이터 보간, 데이터 대치 또는 경우에 따라 사례별 삭제(예: 특정 분석에 사용된 기능에 대해 누락된 값이 있는 사례 생략)를 통해 효율성을 높이고 일관성을 향상시킵니다.
이러한 이유로 철저한 탐색적 데이터 분석 및 데이터 프로파일링을 수행하는 것은 데이터 특성을 이해하는 것뿐만 아니라 분석을 위한 데이터를 가장 잘 준비하는 방법에 대한 정보에 입각한 결정을 내리는 데 필수적입니다.
이 실습 튜토리얼에서는 ydata 프로파일링 새 릴리스에 최근 도입된 기능을 통해 이러한 문제를 해결하는 데 도움이 될 수 있습니다. 우리는 미국 오염 데이터세트, 가능 카글 (특허 DbCL v1.0)에는 미국 주 전체의 NO2, O3, SO2 및 CO 오염 물질에 관한 자세한 정보가 나와 있습니다.
튜토리얼을 시작하려면 먼저 최신 버전의 ydata 프로파일링을 설치해야 합니다.
pip install ydata-profiling==4.5.1
그런 다음 데이터를 로드하고, 불필요한 기능을 제거하고, 조사하려는 내용에 집중할 수 있습니다. 이 예의 목적을 위해 우리는 Scottsdale의 Maricopa에 있는 Arizona 관측소에서 수행된 대기 오염 물질 측정의 특정 동작에 중점을 둘 것입니다.
import pandas as pd data = pd.read_csv("data/pollution_us_2000_2016.csv")
data = data.drop('Unnamed: 0', axis = 1) # dropping unnecessary index # Select data from Arizona, Maricopa, Scottsdale (Site Num: 3003)
data_scottsdale = data[data['Site Num'] == 3003].reset_index(drop=True)
이제 데이터 세트 프로파일링을 시작할 준비가 되었습니다! 시계열 프로파일링을 사용하려면 매개변수를 전달해야 한다는 점을 기억하세요. tsmode=True ydata 프로파일링이 시간에 따른 특징을 식별할 수 있도록:
# Change 'Data Local' to datetime
data_scottsdale['Date Local'] = pd.to_datetime(data_scottsdale['Date Local']) # Create the Profile Report
profile_scottsdale = ProfileReport(data_scottsdale, tsmode=True, sortby="Date Local")
profile_scottsdale.to_file('profile_scottsdale.html')시계열 개요
출력 보고서는 우리가 이미 알고 있는 것과 유사하지만 향상된 경험과 시계열 데이터에 대한 새로운 요약 통계를 포함합니다.
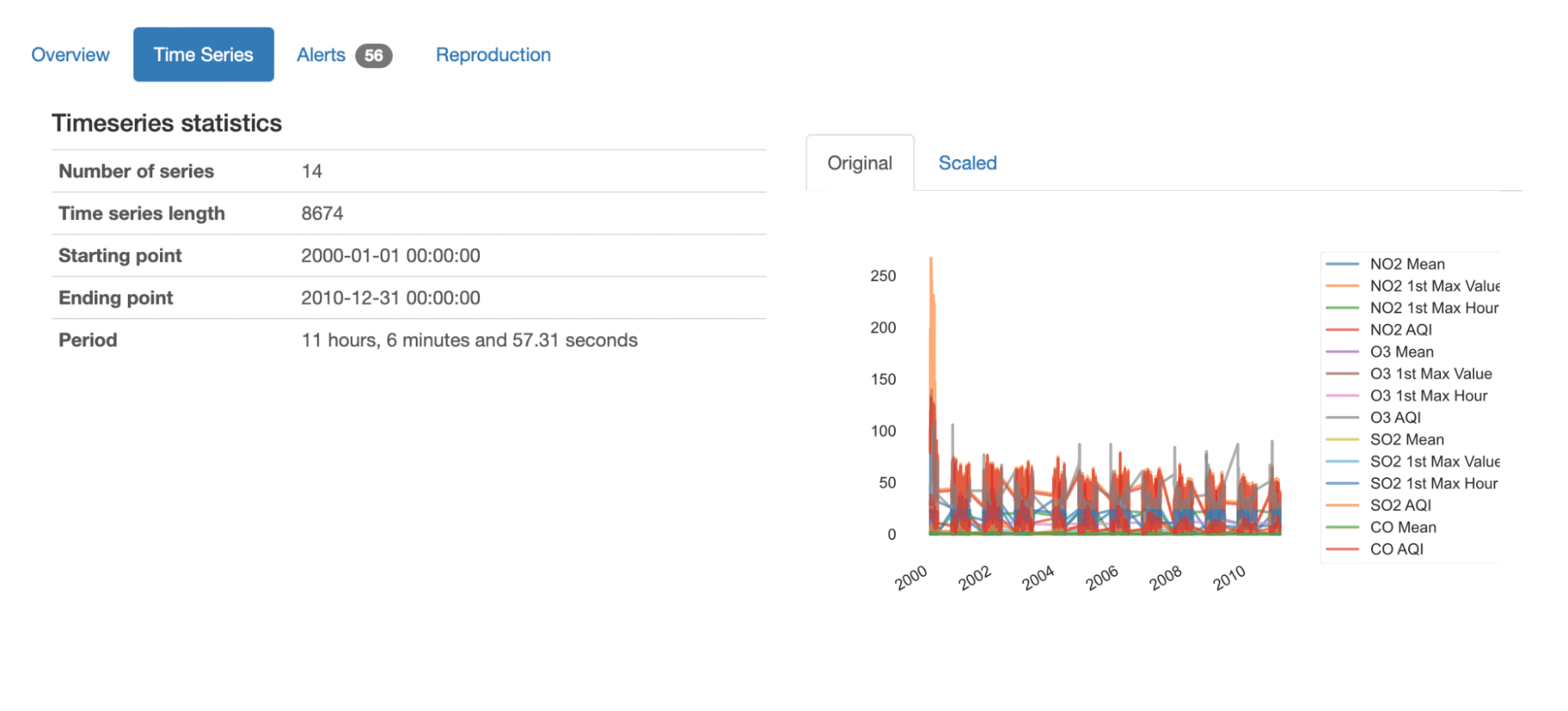
개요에서 제시된 요약 통계를 살펴보면 이 데이터 세트에 대한 전반적인 이해를 즉시 얻을 수 있습니다.
- 여기에는 14개의 서로 다른 시계열이 포함되어 있으며 각각 8674개의 기록된 값이 있습니다.
- 데이터 세트는 10년 2000월부터 2010년 XNUMX월까지 XNUMX년간의 데이터를 보고합니다.
- 시간 순서의 평균 기간은 11시간 (거의) 7분입니다. 이는 평균적으로 11시간마다 조치를 취하고 있음을 의미합니다.
또한 원래 값이나 축소된 값으로 데이터의 모든 계열에 대한 개요 플롯을 얻을 수 있습니다. 시퀀스의 전체 변화는 물론 구성 요소(NO2, O3, SO2, CO) 및 특성(평균)을 쉽게 파악할 수 있습니다. , 1차 최대값, 1차 최대 시간, AQI)를 측정하고 있습니다.
누락된 데이터 검사
데이터를 전체적으로 살펴본 후에는 각 시간 순서의 세부 사항에 집중할 수 있습니다.
의 최신 릴리스에서 ydata 프로파일링, 시계열 데이터에 대한 전용 분석, 즉 "시계열" 및 "간격 분석" 지표에 대한 보고를 통해 프로파일링 보고서가 크게 개선되었습니다. 이제 특정 요약 통계와 상세한 시각화를 사용할 수 있는 이러한 새로운 기능을 통해 추세와 누락된 패턴을 더욱 쉽게 식별할 수 있습니다.
즉시 눈에 띄는 것은 연속 측정 사이에 특정 "점프"가 발생하는 것처럼 보이는 모든 시계열에 존재하는 불안정한 패턴입니다. 이는 더 자세히 조사해야 하는 누락된 데이터(누락된 정보의 "간격")가 있음을 나타냅니다. 다음을 살펴보자. S02 Mean 예로서.
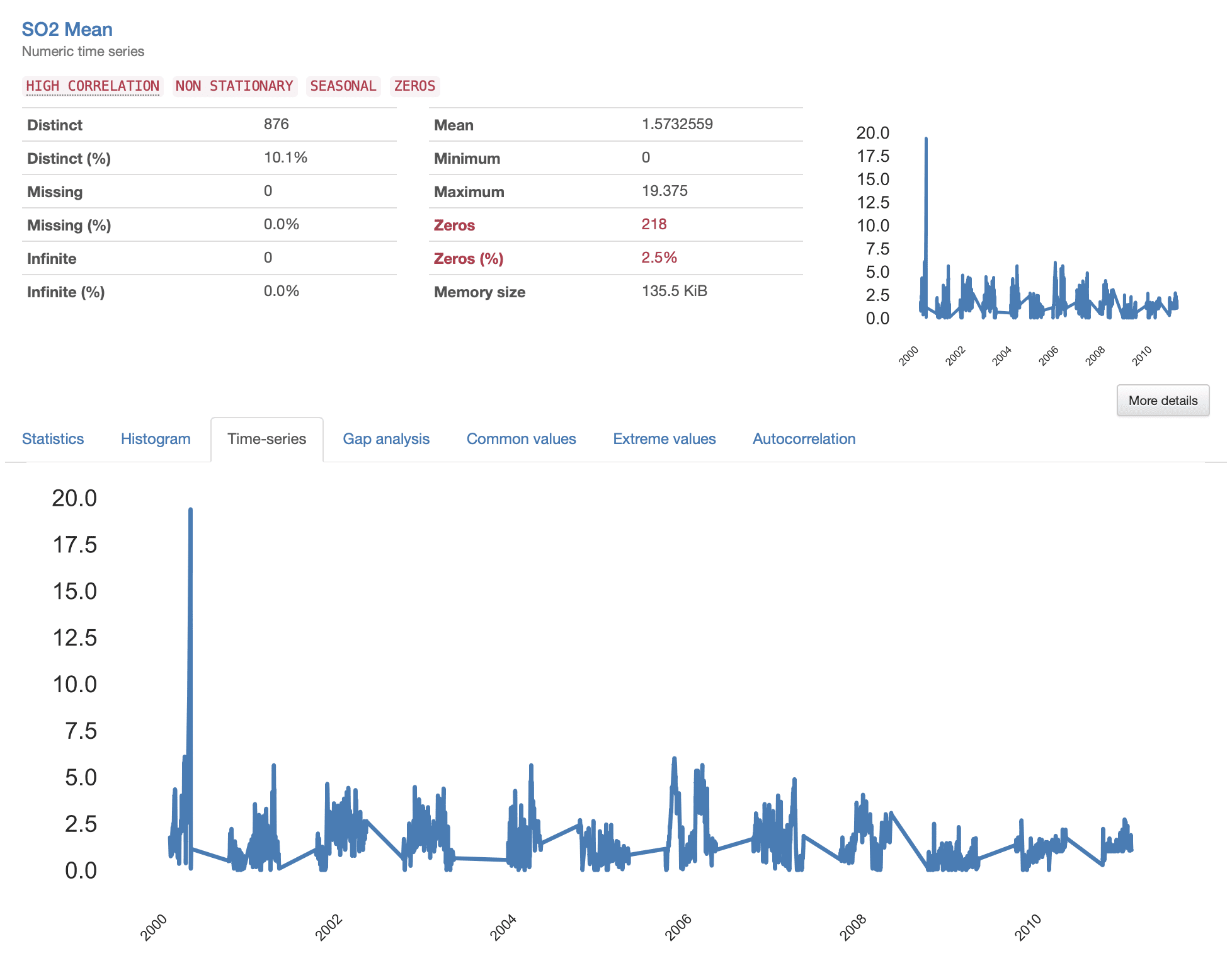
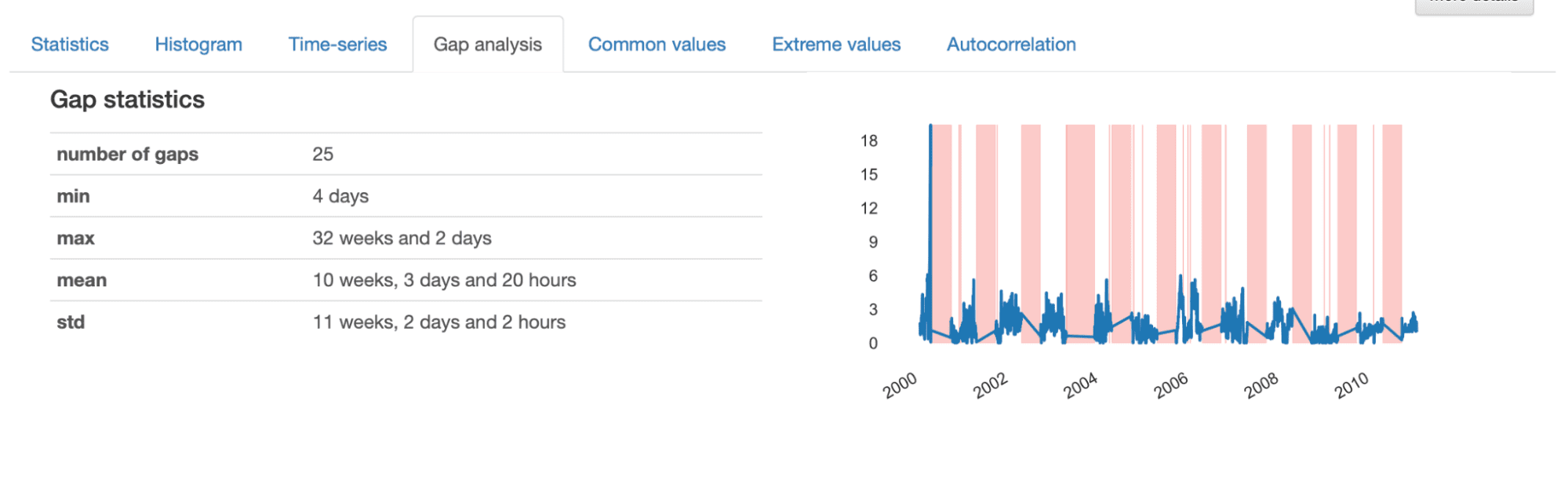
격차 분석에 제공된 세부 사항을 조사할 때 식별된 격차의 특성에 대한 유익한 설명을 얻을 수 있습니다. 전체적으로 시계열에는 25개의 간격이 있으며, 최소 길이는 4일, 최대 32주, 평균 10주입니다.
제시된 시각화에서 우리는 더 얇은 줄무늬로 표시되는 다소 "무작위" 간격과 반복적인 패턴을 따르는 것처럼 보이는 더 큰 간격을 확인합니다. 이는 데이터 세트에 두 가지 서로 다른 데이터 누락 패턴이 있는 것 같다는 것을 나타냅니다.
더 작은 간격은 누락된 데이터를 생성하는 산발적인 이벤트에 해당하며, 대부분 획득 프로세스의 오류로 인해 발생할 가능성이 높으며 데이터 세트에서 쉽게 보간되거나 삭제될 수 있습니다. 결과적으로, 격차가 클수록 더 복잡해지고 더 자세히 분석해야 합니다. 더 철저하게 해결해야 할 기본 패턴이 드러날 수 있기 때문입니다.
이 예에서 더 큰 격차를 조사하면 실제로 계절적 패턴을 반영한다는 사실을 발견할 수 있습니다.
df = data_scottsdale.copy()
for year in df["Date Local"].dt.year.unique(): for month in range(1,13): if ((df["Date Local"].dt.year == year) & (df["Date Local"].dt.month ==month)).sum() == 0: print(f'Year {year} is missing month {month}.')
# Year 2000 is missing month 4.
# Year 2000 is missing month 5.
# Year 2000 is missing month 6.
# Year 2000 is missing month 7.
# Year 2000 is missing month 8.
# (...)
# Year 2007 is missing month 5.
# Year 2007 is missing month 6.
# Year 2007 is missing month 7.
# Year 2007 is missing month 8.
# (...)
# Year 2010 is missing month 5.
# Year 2010 is missing month 6.
# Year 2010 is missing month 7.
# Year 2010 is missing month 8.
의심되는 바와 같이, 시계열은 반복적이고 심지어 계절적으로 나타나는 큰 정보 격차를 나타냅니다. 대부분의 해에 데이터는 5월에서 8월(XNUMX~XNUMX개월) 사이에 수집되지 않았습니다. 이는 예측할 수 없는 이유 또는 알려진 비즈니스 결정(예: 비용 절감과 관련되거나 단순히 날씨 패턴, 온도, 습도 및 대기 조건과 관련된 오염 물질의 계절적 변화)으로 인해 발생할 수 있습니다.
이러한 조사 결과를 바탕으로 이러한 일이 발생한 이유, 향후 이를 방지하기 위한 조치가 필요한지, 현재 보유한 데이터를 처리하는 방법을 조사할 수 있습니다.
이 튜토리얼 전체에서 우리는 시계열에서 누락된 데이터의 패턴을 이해하는 것이 얼마나 중요한지, 그리고 효과적인 프로파일링이 누락된 정보의 격차 뒤에 있는 미스터리를 어떻게 밝힐 수 있는지 살펴보았습니다. 통신, 의료, 에너지, 금융 등 시계열 데이터를 수집하는 모든 부문은 어느 시점에서 데이터 누락에 직면하게 되며, 이들로부터 가능한 모든 지식을 처리하고 추출하는 최선의 방법을 결정해야 합니다.
포괄적인 데이터 프로파일링을 통해 당사는 현재 데이터 특성에 따라 정보에 입각한 효율적인 결정을 내릴 수 있습니다.
- 정보의 격차는 획득, 전송, 수집의 오류로 인해 발생하는 산발적인 사건으로 인해 발생할 수 있습니다. 문제가 다시 발생하지 않도록 문제를 해결하고 간격 길이에 따라 누락된 간격을 보간하거나 대치할 수 있습니다.
- 정보의 격차는 계절적이거나 반복되는 패턴을 나타낼 수도 있습니다. 누락된 정보 수집을 시작하기 위해 파이프라인을 재구성하거나 누락된 공백을 다른 분산 시스템의 외부 정보로 대체하도록 선택할 수 있습니다. 검색 프로세스가 실패했는지 여부도 확인할 수 있습니다(데이터 엔지니어링 측면에서 어리석은 쿼리일 수도 있습니다. 우리 모두 그런 시절을 겪었습니다!).
이 튜토리얼이 시계열 데이터에서 누락된 데이터를 적절하게 식별하고 특성화하는 방법에 대해 어느 정도 밝혀졌기를 바랍니다. 여러분의 격차 분석에서 무엇을 찾을 수 있을지 기대됩니다! 질문이나 제안 사항이 있으면 댓글로 한 줄을 남겨주시거나 다음에서 저를 찾아주세요. 데이터 중심 AI 커뮤니티!
파비아나 클레멘테 YData의 공동 창립자이자 CDO로서 데이터 이해, 인과성, 개인 정보 보호를 주요 업무 및 연구 분야로 결합하여 조직에서 데이터를 실행 가능하게 만드는 사명을 갖고 있습니다. 열정적인 데이터 실무자인 그녀는 When Machine Learning Meets Privacy 팟캐스트를 진행하고 있으며 Datacast 및 Privacy Please 팟캐스트의 초청 연사이기도 합니다. 그녀는 또한 ODSC 및 PyData와 같은 컨퍼런스에서 연설합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 차트프라임. ChartPrime으로 트레이딩 게임을 향상시키십시오. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/how-to-identify-missing-data-in-timeseries-datasets?utm_source=rss&utm_medium=rss&utm_campaign=how-to-identify-missing-data-in-time-series-datasets
- :있다
- :이다
- :아니
- :어디
- 1
- 10
- 11
- 12
- 13
- 14
- 1st
- 2000
- 2010
- 25
- 32
- 7
- 8
- a
- 할 수 있는
- 취득
- 가로질러
- 해결 된
- 다시
- AI
- 겨냥
- AIR
- All
- 이미
- 또한
- 중
- an
- 분석
- 분석
- 및
- 어떤
- 접근
- 구혼
- 적절하게
- 있군요
- 발생
- 애리조나
- AS
- 평가
- 관련
- At
- 대기
- 8월
- 가능
- 평균
- 축
- BE
- 행동
- 뒤에
- 존재
- BEST
- 사이에
- 치우친
- 두
- 사업
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- CAN
- 얻을 수 있습니다
- 가지 경우
- 원인
- 발생
- 어떤
- 이전 단계로 돌아가기
- 특성
- 특징
- 왼쪽 메뉴에서
- 면밀히
- CO
- 공동 설립자
- 수집
- 수집
- 결합
- 댓글
- 복잡한
- 구성 요소들
- 포괄적 인
- 조건
- 회의
- 연결
- 연속적인
- 결과
- 이 포함되어 있습니다
- 문맥
- 동
- 비용
- 수
- 만들
- 만들기
- 현재
- 절단
- 데이터
- 데이터 분석
- 데이터 품질
- 데이터 세트
- 날짜
- 날짜 시간
- 일
- XNUMX월
- 2010년 일월
- 결정하다
- 결정
- 결정
- 전용
- 의존
- 설명
- 세부 묘사
- 상세한
- 세부설명
- 다른
- 발견
- 분산
- 분산 시스템
- 도메인
- 한
- 드롭
- 적하
- 두
- ...동안
- e
- 마다
- 용이하게
- 유효한
- 효율적인
- 효율적으로
- 중
- 에너지
- 엔지니어링
- 열광적 인
- 오류
- 오류
- 에테르 (ETH)
- 조차
- 이벤트
- 모든
- 예
- 경험
- 탐색 적 데이터 분석
- 탐험
- 외부
- 추출물
- 매우
- 페이스메이크업
- 촉진
- 사실
- 익숙한
- 결함
- 특색
- 특징
- Fields
- 재원
- Find
- 결과
- 먼저,
- 수정
- 초점
- 따라
- 럭셔리
- 형태
- 에
- 미래
- 갭
- 틈새
- 생성
- 생성
- 얻을
- 주어진
- 파악
- 손님
- 손
- 핸들
- 손 -에
- 일이
- 무슨 일이
- 있다
- 데
- 건강 관리
- 도움
- 그녀의
- 고도로
- 기대
- 호스트
- 시간
- 진료 시간
- 방법
- How To
- HTML
- HTTPS
- 사람의
- i
- 식별
- 확인
- 확인
- if
- 바로
- 중대한
- 개선
- 개선하는
- in
- 색인
- 표시
- 개인
- 정보
- 유익한 정보
- 정보
- 설치
- 예
- 소개
- 조사
- 조사 중
- 발행물
- 문제
- IT
- 그
- 그 자체
- 일월
- 너 겟츠
- 알아
- 지식
- 넓은
- 큰
- 최근
- 최신 릴리스
- 배우기
- 길이
- 특허
- 빛
- 아마도
- 라인
- 링크드인
- 하중
- 지방의
- 로깅
- 보기
- 찾고
- 오프
- 기계
- 기계 학습
- 본관
- 확인
- 유튜브 영상을 만드는 것은
- 최대
- 최고
- XNUMX월..
- 아마도
- me
- 평균
- 방법
- 측정
- 측정 시간 상관관계
- 조치들
- 만족
- 통계
- 최저한의
- 분
- 누락
- Mission
- 모델링
- 달
- 개월
- 배우기
- 가장
- 즉
- 자연히
- 거의
- 필요
- 요구
- 네트워크
- 신제품
- 새로운 기능
- 주의
- 지금
- 발생
- 발생
- 발생하는
- of
- 자주
- on
- 만
- 기회
- or
- 조직
- 실물
- 기타
- 우리의
- 아웃
- 결과
- 출력
- 전체
- 개요
- 자신의
- 팬더
- 매개 변수
- 특별한
- 패스
- 무늬
- 패턴
- 실행할 수 있는
- 기간
- 관로
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 부디
- 팟 캐스트
- 팟 캐스트
- 포인트 적립
- 오염
- 가능한
- 예언하는
- Prepare
- 준비
- 존재
- 제시
- 제시
- 선물
- 예방
- 개인 정보 보호
- 방법
- 프로필
- 프로파일 링
- 목적
- 품질
- 문의
- 준비
- 이유
- 이유
- 최근에
- 기록
- 반영
- 에 관한
- 관련
- 공개
- 제거
- 반복
- 반복적 인
- 교체
- 신고
- 통계 보고서
- 보고서
- 대표
- 대표되는
- 연구
- 구조 조정
- 공개
- 수익
- 위험
- 위험 평가
- s
- 계절의
- 둘째
- 부문
- 참조
- 보다
- 본
- 센서
- 순서
- 연속
- 진지한
- 몇몇의
- 그녀
- 흘리다
- 영상을
- 측면
- 간단히
- 대지
- 상황
- 작은
- So
- 일부
- 무언가
- 약간
- 지우면 좋을거같음 . SM
- Speaker
- 언어
- 구체적인
- 세부 사항
- 서
- 스타트
- 미국
- 역
- 통계
- 단계
- 중지
- 흐름
- 문
- 연구
- 대체로
- 이러한
- 개요
- 의심
- 시스템은
- 받아
- 촬영
- 통신
- 그
- XNUMXD덴탈의
- 미래
- 그들의
- 그들
- 그때
- 그곳에.
- 따라서
- Bowman의
- 그들
- 이
- 완전히
- 그
- 을 통하여
- 시간
- 시계열
- 에
- 트렌드
- 회전
- 지도 시간
- 두
- 우리
- 밑에 있는
- 이해
- 이해
- 알 수없는
- 이름 없음
- 불필요한
- 예측할 수
- us
- 사용
- 익숙한
- 사용
- v1
- 가치
- 마케팅은:
- 변화
- 버전
- 관측
- 심상
- 기다리다
- 였다
- 방법..
- we
- 날씨
- 날씨 패턴
- 주
- 잘
- 했다
- 뭐
- 언제
- 어느
- why
- 의지
- 과
- 작업
- 겠지
- year
- 년
- 너의
- 제퍼 넷