개요
우리는 사전 훈련된 모델, 전이 학습 등과 같은 AI 및 딥 러닝에 대한 멋진 용어를 보았습니다. 널리 사용되는 기술과 가장 중요하고 효과적인 기술 중 하나인 YOLOv5를 사용한 전이 학습에 대해 알려드리겠습니다.
You Only Look Once 또는 YOLO는 가장 광범위하게 사용되는 딥 러닝 기반 객체 식별 방법 중 하나입니다. 사용자 지정 데이터 세트를 사용하여 이 기사에서는 최신 변형 중 하나인 YOLOv5를 교육하는 방법을 보여줍니다.
학습 목표
- 이 기사는 주로 사용자 지정 데이터 세트 구현에서 YOLOv5 모델을 교육하는 데 중점을 둘 것입니다.
- 사전 훈련된 모델이 무엇인지, 전이 학습이 무엇인지 살펴보겠습니다.
- YOLOv5가 무엇이며 왜 YOLO 버전 5를 사용하는지 이해할 것입니다.
따라서 시간을 낭비하지 않고 프로세스를 시작하겠습니다.
내용의 표
- 사전 훈련된 모델
- 전학 학습
- YOLOv5는 무엇이며 왜 필요한가요?
- 전이 학습에 관련된 단계
- 실시
- 직면할 수 있는 몇 가지 문제
- 결론
사전 훈련된 모델
데이터 과학자들이 "사전 훈련된 모델"이라는 용어를 널리 사용하는 것을 들어보셨을 것입니다. 딥러닝 모델/네트워크가 무엇을 하는지 설명한 후에 용어를 설명하겠습니다. 딥 러닝 모델은 분류, 탐지 등과 같은 단일 목적을 수행하기 위해 함께 쌓인 다양한 레이어를 포함하는 모델입니다. 딥 러닝 네트워크는 입력된 데이터에서 복잡한 구조를 발견하고 가중치를 파일에 저장하여 학습합니다. 나중에 유사한 작업을 수행하는 데 사용됩니다. 사전 훈련된 모델은 이미 훈련된 딥 러닝 모델입니다. 이것이 의미하는 바는 수백만 개의 이미지가 포함된 거대한 데이터 세트에서 이미 훈련을 받았다는 것입니다.
방법은 다음과 같습니다 TensorFlow 웹 사이트는 사전 학습된 모델을 정의합니다. 사전 훈련된 모델은 일반적으로 대규모 이미지 분류 작업에서 대규모 데이터 세트에 대해 이전에 훈련된 저장된 네트워크입니다.
고도로 최적화되고 매우 효율적인 일부 사전 훈련 된 모델 인터넷에서 사용할 수 있습니다. 다른 모델은 다른 작업을 수행하는 데 사용됩니다. 사전 훈련된 모델 중 일부는 VGG-16, VGG-19, YOLOv5, YOLOv3 및 레스넷 50.
사용할 모델은 수행하려는 작업에 따라 다릅니다. 예를 들어 내가 수행하려는 경우 물체 감지 작업에서는 YOLOv5 모델을 사용하겠습니다.
전학 학습
전학 학습 데이터 과학자의 작업을 쉽게 해주는 가장 중요한 기술입니다. 모델 교육은 시간이 많이 걸리고 시간이 많이 걸리는 작업입니다. 모델이 처음부터 훈련되면 일반적으로 좋은 결과를 제공하지 않습니다. 사전 훈련된 모델과 유사한 모델을 훈련하더라도 효과적으로 수행되지 않으며 모델을 훈련하는 데 몇 주가 걸릴 수 있습니다. 대신 사전 훈련된 모델을 사용하고 유사한 작업을 수행하기 위해 사용자 정의 데이터 세트에서 훈련함으로써 이미 학습된 가중치를 사용할 수 있습니다. 이 모델은 아키텍처와 성능 측면에서 매우 효율적이고 세련되었으며 다양한 대회에서 더 나은 성능을 발휘하여 정상에 올랐습니다. 이러한 모델은 매우 많은 양의 데이터에 대해 학습되므로 지식이 더욱 다양해집니다.
따라서 전이 학습은 기본적으로 이전 데이터에서 모델을 훈련하여 얻은 지식을 이전하여 모델이 다르지만 유사한 작업을 수행하기 위해 더 빠르고 더 잘 학습하도록 돕는 것을 의미합니다.
예를 들어, 객체 감지를 위해 YOLOv5를 사용하지만 객체는 객체의 이전 데이터가 아닌 다른 것입니다.
YOLOv5는 무엇이며 왜 필요한가요?
YOLOv5는 사전 훈련된 모델로, 버전 5가 실시간 물체 감지에 사용되며 정확성과 추론 시간 측면에서 매우 효율적인 것으로 입증되었습니다. 다른 버전의 YOLO가 있지만 예상대로 YOLOv5가 다른 버전보다 성능이 좋습니다. YOLOv5는 빠르고 사용하기 쉽습니다. Yolo v4 Darknet보다 커뮤니티가 더 큰 PyTorch 프레임워크를 기반으로 합니다.
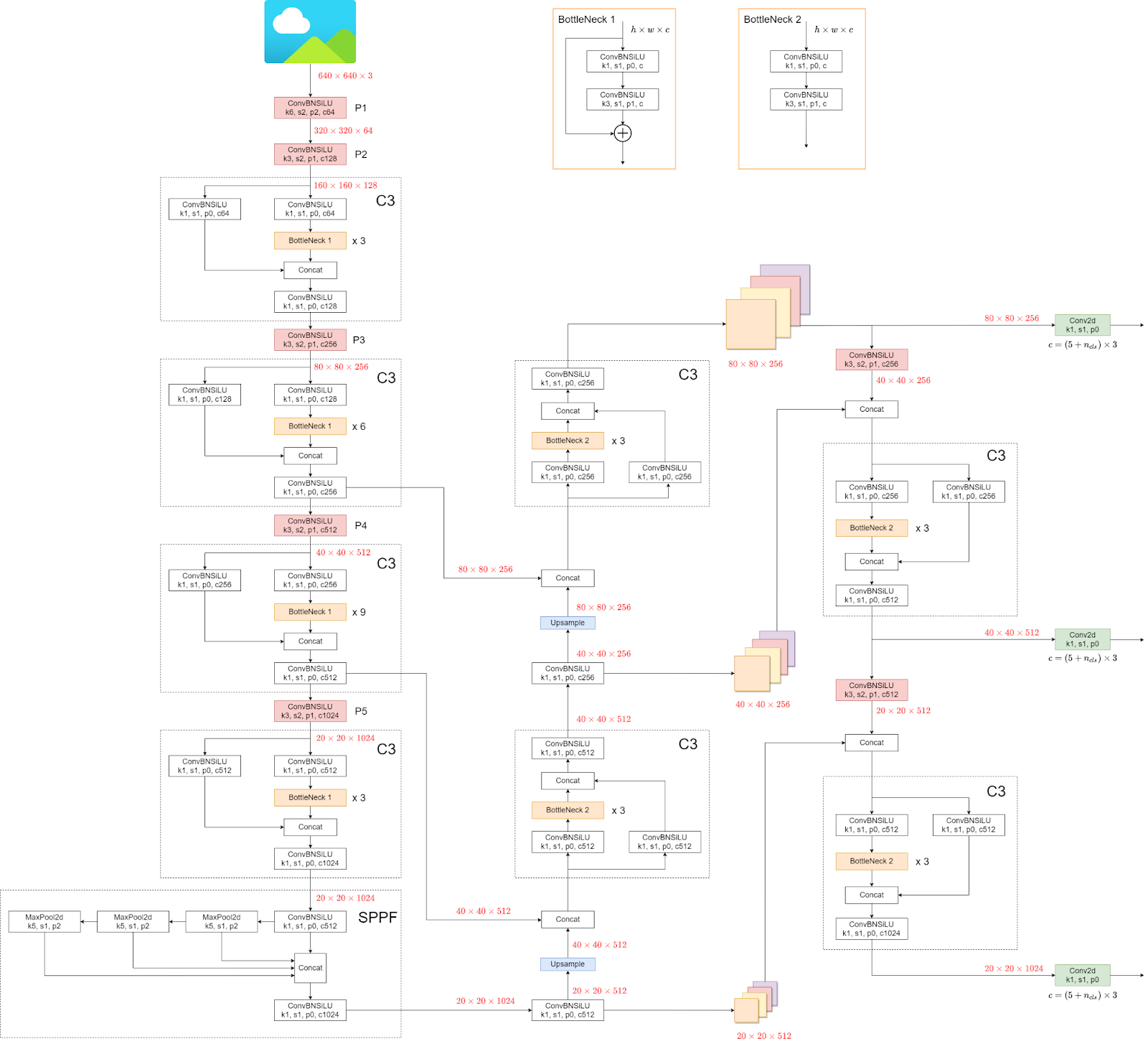
이제 YOLOv5의 아키텍처를 살펴보겠습니다.
구조가 복잡해 보일 수 있지만 아키텍처를 볼 필요 없이 모델과 가중치를 직접 사용하므로 문제가 되지 않습니다.
전이 학습에서 우리는 맞춤형 데이터 세트, 즉 모델이 이전에 본 적이 없는 데이터 또는 모델이 훈련되지 않은 데이터를 사용합니다. 모델이 이미 큰 데이터 세트에서 훈련되었으므로 이미 가중치가 있습니다. 이제 작업하려는 데이터에 대해 여러 시대에 대해 모델을 훈련할 수 있습니다. 모델이 처음으로 데이터를 보았고 작업을 수행하려면 약간의 지식이 필요하므로 교육이 필요합니다.
전이 학습에 관련된 단계
전이 학습은 간단한 프로세스이며 몇 가지 간단한 단계로 수행할 수 있습니다.
- 데이터 준비
- 주석의 올바른 형식
- 원하는 경우 몇 개의 레이어를 변경하십시오.
- 몇 번의 반복을 위해 모델 재교육
- 검증/테스트
데이터 준비
선택한 데이터가 약간 크면 데이터 준비에 시간이 많이 걸릴 수 있습니다. 데이터 준비는 이미지에 주석을 다는 것을 의미하며 이미지의 개체 주위에 상자를 만들어 이미지에 레이블을 지정하는 프로세스입니다. 이렇게 하면 표시된 개체의 좌표가 파일에 저장되어 훈련을 위해 모델에 제공됩니다. 다음과 같은 몇 가지 웹사이트가 있습니다. 상식.ai 과 roboflow.com, 데이터에 레이블을 지정하는 데 도움이 될 수 있습니다.
다음은 makeense.ai에서 YOLOv5 모델의 데이터에 주석을 추가하는 방법입니다.
1. 방문 https://www.makesense.ai/.
2. 화면 오른쪽 하단의 시작하기를 클릭합니다.
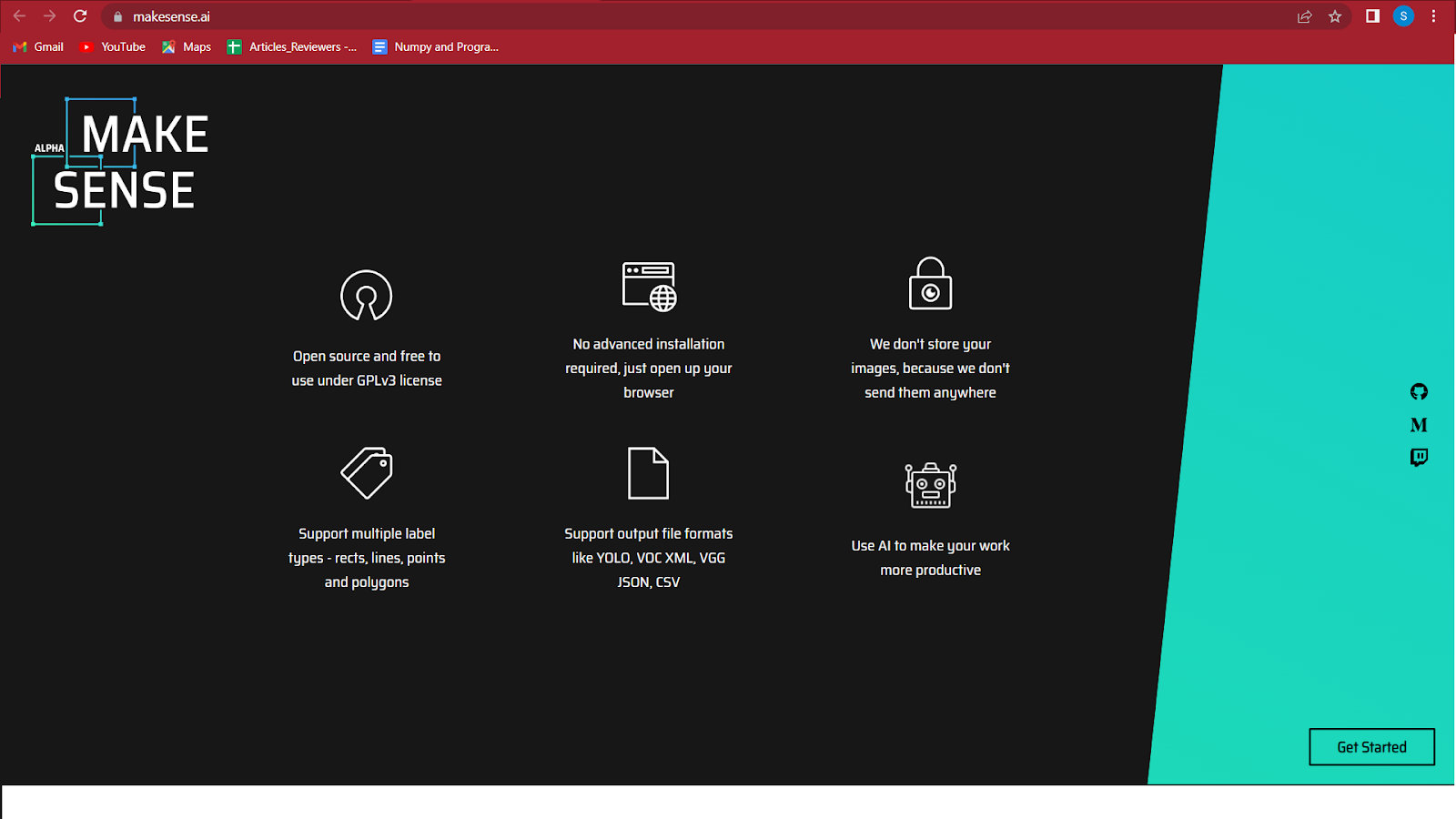
3. 중앙에 강조 표시된 상자를 클릭하여 라벨을 지정하려는 이미지를 선택합니다.
주석을 추가하려는 이미지를 로드하고 개체 감지를 클릭합니다.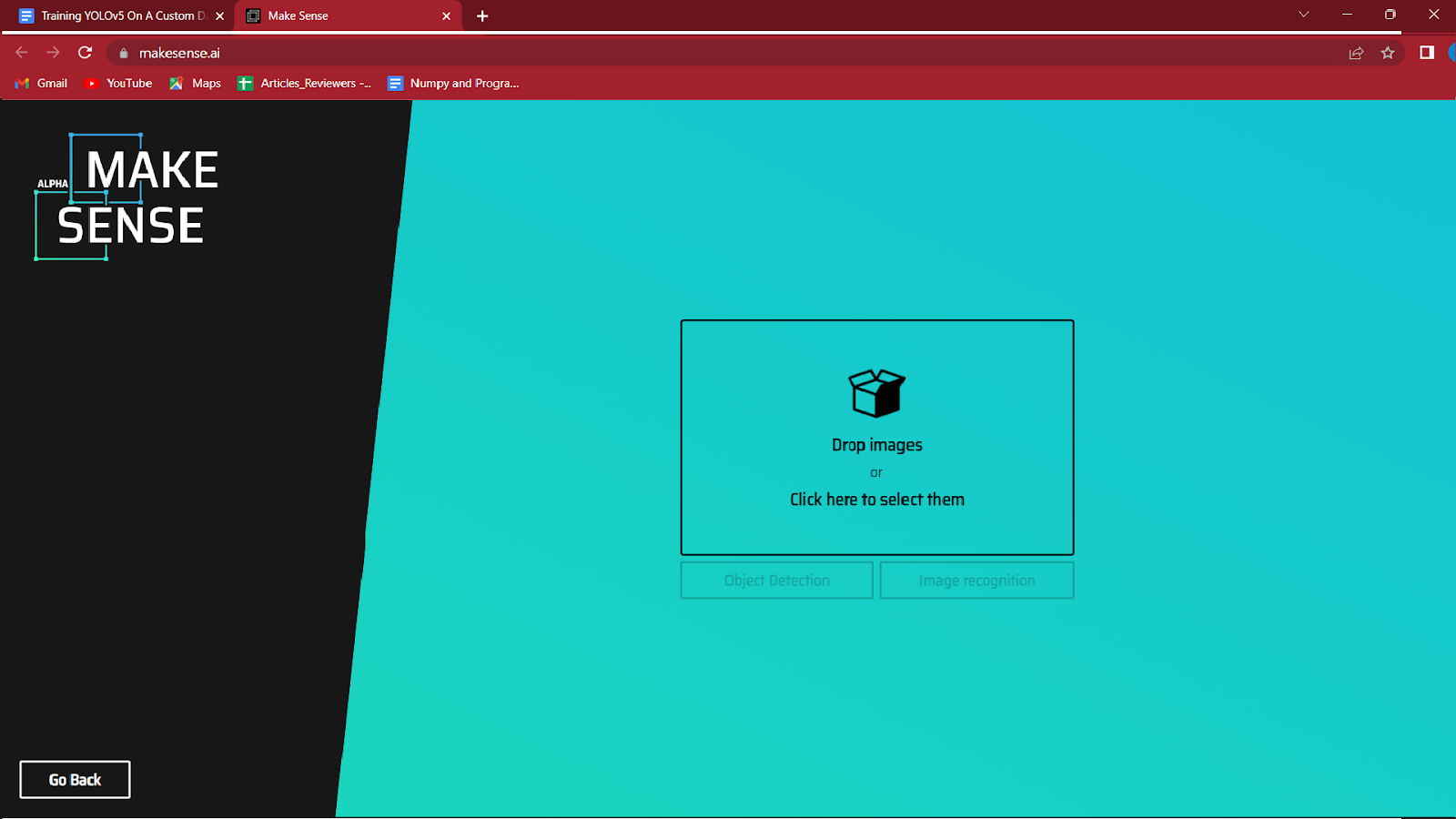
4. 이미지를 로드한 후 데이터 세트의 다양한 클래스에 대한 레이블을 생성하라는 메시지가 표시됩니다.
차량에서 번호판을 감지하고 있으므로 사용할 유일한 레이블은 "License Plate"입니다. 대화 상자 왼쪽에 있는 '+' 버튼을 클릭하여 Enter 키를 누르기만 하면 더 많은 라벨을 만들 수 있습니다.
모든 레이블을 만든 후 프로젝트 시작을 클릭합니다.
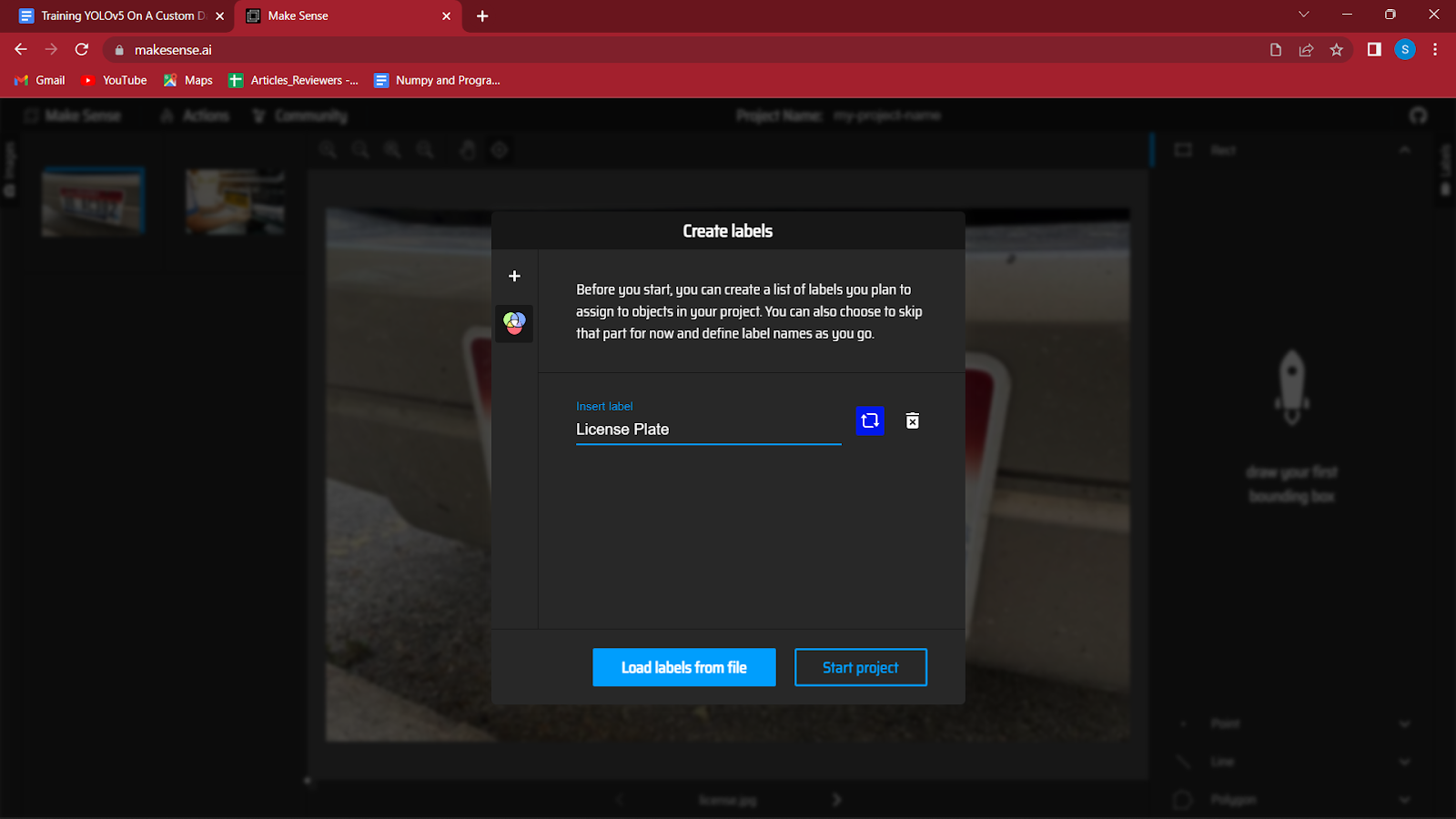
누락된 레이블이 있는 경우 작업을 클릭한 다음 레이블을 편집하여 나중에 편집할 수 있습니다.
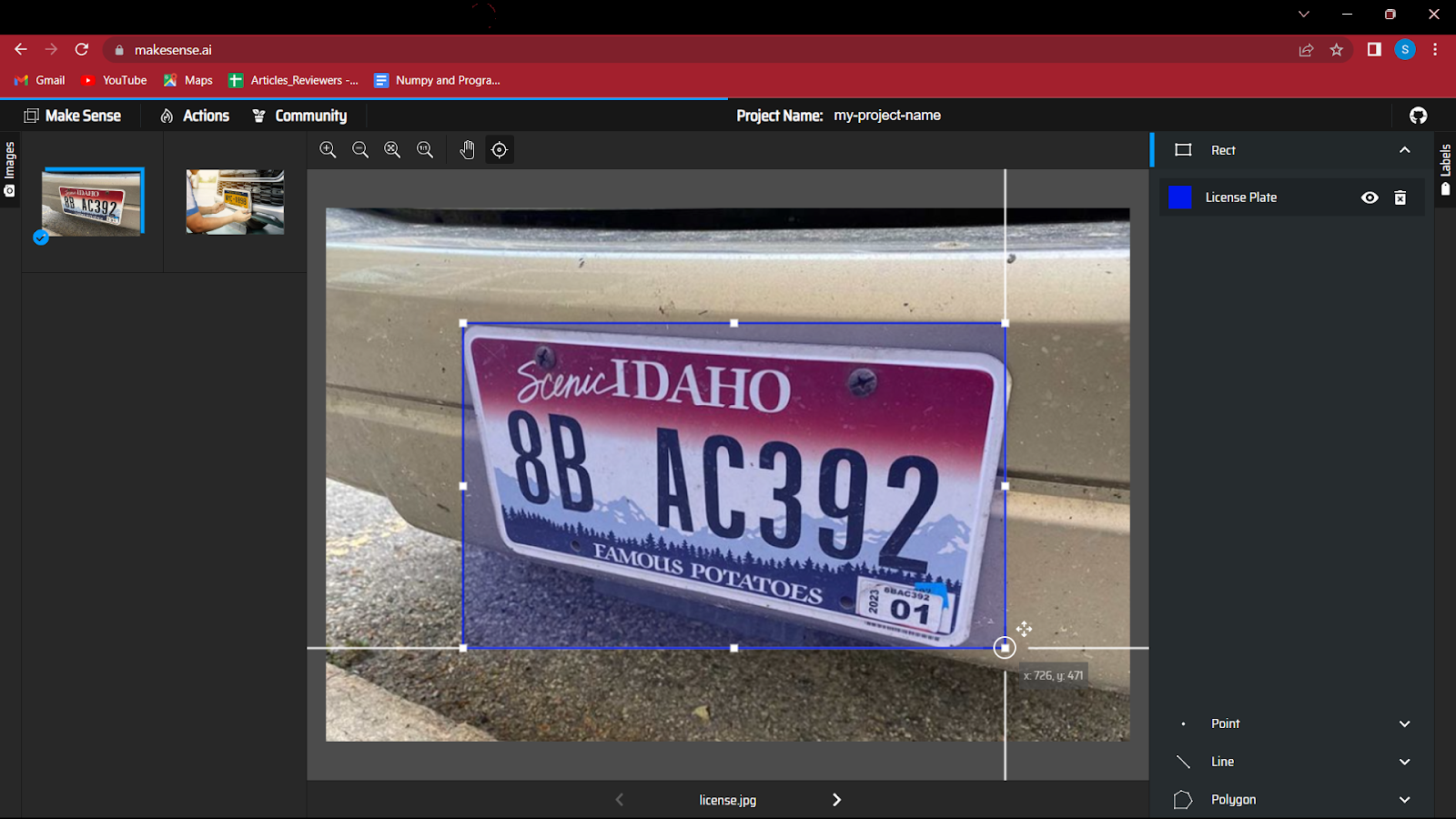
5. 이미지의 개체 주위에 경계 상자 만들기를 시작합니다. 이 연습은 처음에는 약간 재미있을 수 있지만 데이터가 매우 크면 피곤할 수 있습니다.
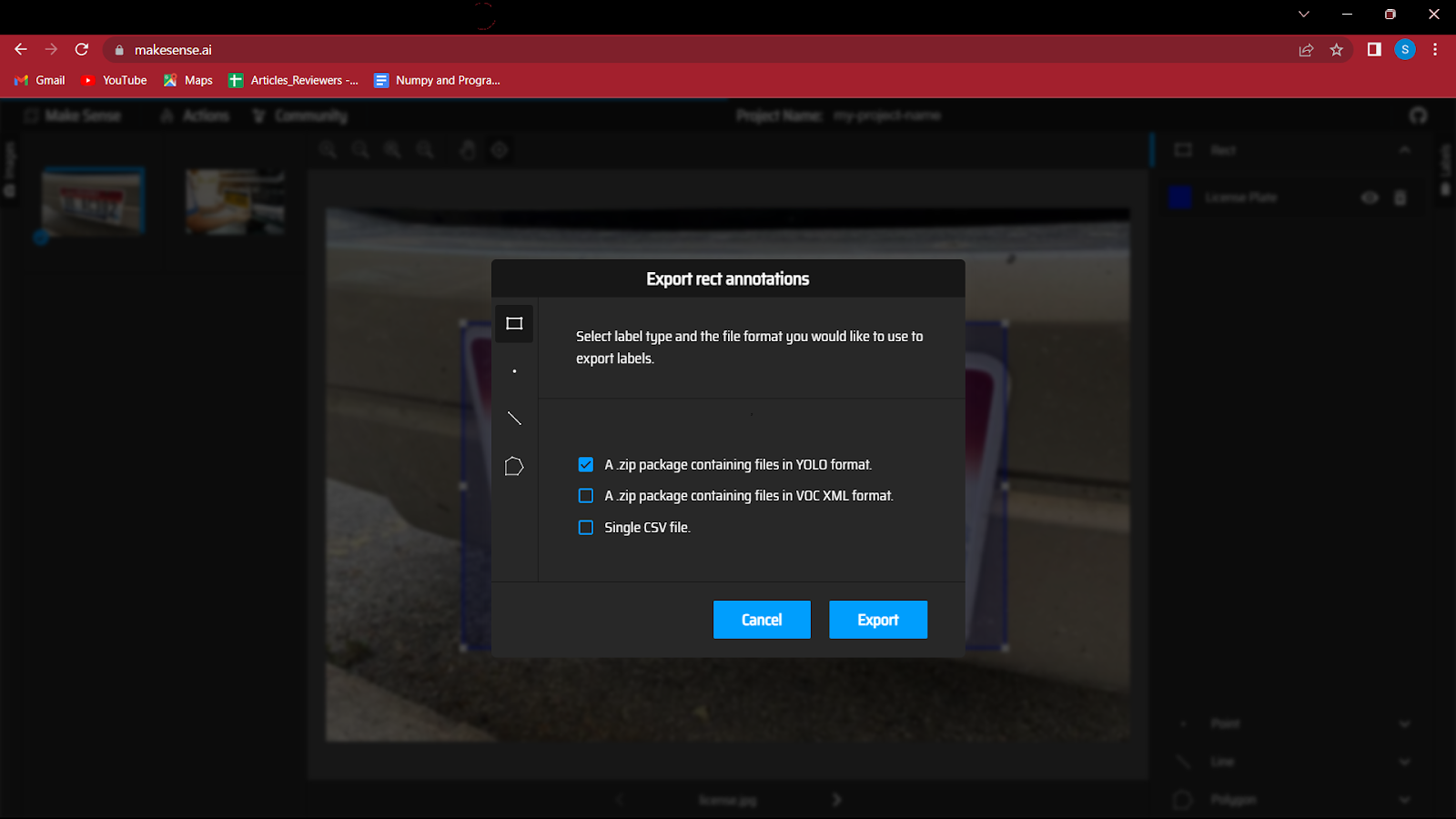
6. 모든 이미지에 주석을 추가한 후 클래스와 함께 경계 상자의 좌표를 포함할 파일을 저장해야 합니다.
따라서 작업 버튼으로 이동하여 주석 내보내기를 클릭해야 합니다. 'YOLO 형식의 파일을 포함하는 zip 패키지' 옵션을 선택하는 것을 잊지 마십시오. 이렇게 하면 YOLO 모델에서 요구하는 올바른 형식으로 파일이 저장됩니다.
7. 이것은 중요한 단계이므로 주의 깊게 따르십시오.
모든 파일과 이미지가 있으면 원하는 이름으로 폴더를 만드십시오. 폴더를 클릭하고 폴더 안에 이름 이미지와 레이블이 있는 폴더를 두 개 더 만듭니다. 명령에 훈련 경로를 입력하면 모델이 자동으로 레이블을 검색하므로 폴더 이름을 위와 동일하게 지정하는 것을 잊지 마십시오.
폴더에 대한 아이디어를 제공하기 위해 'CarsData'라는 폴더를 만들고 그 폴더에 'images'와 'labels'라는 두 개의 폴더를 만들었습니다.
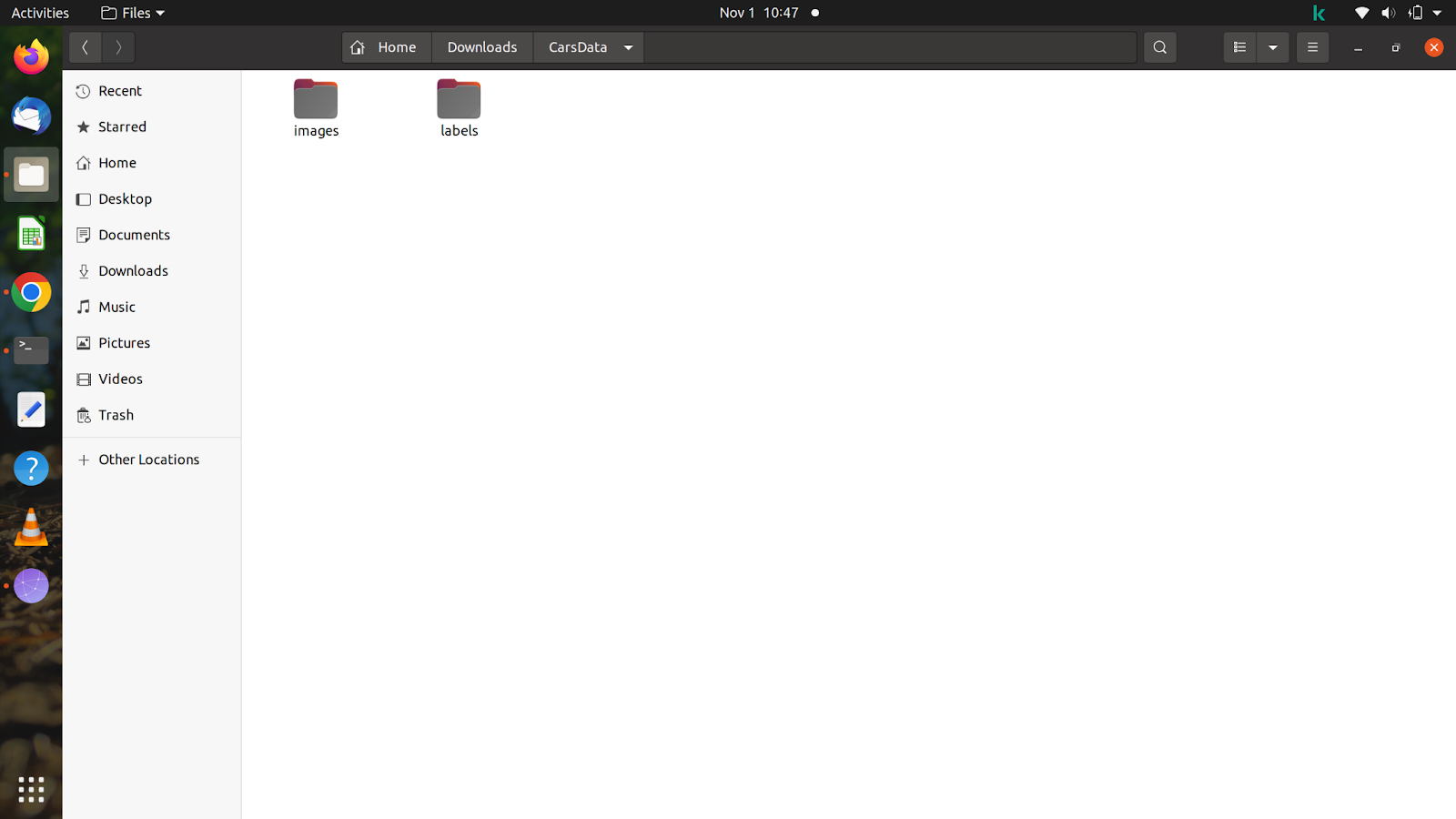
두 폴더 안에 'train'과 'val'이라는 폴더를 두 개 더 만들어야 합니다. 이미지 폴더에서 원하는 대로 이미지를 분할할 수 있지만 레이블은 분할한 이미지와 일치해야 하므로 레이블을 분할할 때 주의해야 합니다.
8. 이제 폴더의 zip 파일을 만들고 colab에서 사용할 수 있도록 드라이브에 업로드합니다.
실시
이제 매우 간단하지만 까다로운 구현 부분에 도달할 것입니다. 정확히 어떤 파일을 변경할지 모르는 경우 사용자 지정 데이터 세트에서 모델을 교육할 수 없습니다.
따라서 사용자 지정 데이터 세트에서 YOLOv5 모델을 교육하기 위해 따라야 하는 코드는 다음과 같습니다.
더 빠른 계산을 제공하는 GPU도 제공하므로 이 튜토리얼에서는 Google Colab을 사용하는 것이 좋습니다.
1. !git 클론 https://github.com/ultralytics/yolov5
이렇게 하면 ultralytics에서 만든 GitHub 저장소인 YOLOv5 저장소의 복사본이 만들어집니다.
2. CD 욜로프5
이것은 현재 작업 디렉터리를 YOLOv5 디렉터리로 변경하는 데 사용되는 명령줄 셸 명령입니다.
3. !pip 설치 -r requirements.txt
이 명령은 모델 교육에 사용되는 모든 패키지와 라이브러리를 설치합니다.
4. !unzip '/content/drive/MyDrive/CarsData.zip'
Google Colab에서 이미지와 라벨이 포함된 폴더의 압축을 풉니다.
가장 중요한 단계가 있습니다…
이제 거의 모든 단계를 수행했으며 모델을 교육할 코드를 한 줄 더 작성해야 하지만 그 전에 사용자 지정 데이터 세트의 경로를 제공하기 위해 몇 가지 단계를 더 수행하고 일부 디렉터리를 변경해야 합니다. 해당 데이터에 대해 모델을 훈련합니다.
여기 당신이해야 할 일이 있습니다.
위의 4단계를 수행하면 Google Colab에 yolov5 폴더가 생깁니다. yolov5 폴더로 이동하여 'data' 폴더를 클릭합니다. 이제 'coco128.yaml'이라는 폴더가 표시됩니다.
계속해서 이 폴더를 다운로드하십시오.
폴더를 다운로드한 후 몇 가지 사항을 변경하고 다운로드한 동일한 폴더에 다시 업로드해야 합니다.
이제 다운로드한 파일의 내용을 살펴보겠습니다. 그러면 다음과 같이 보일 것입니다.
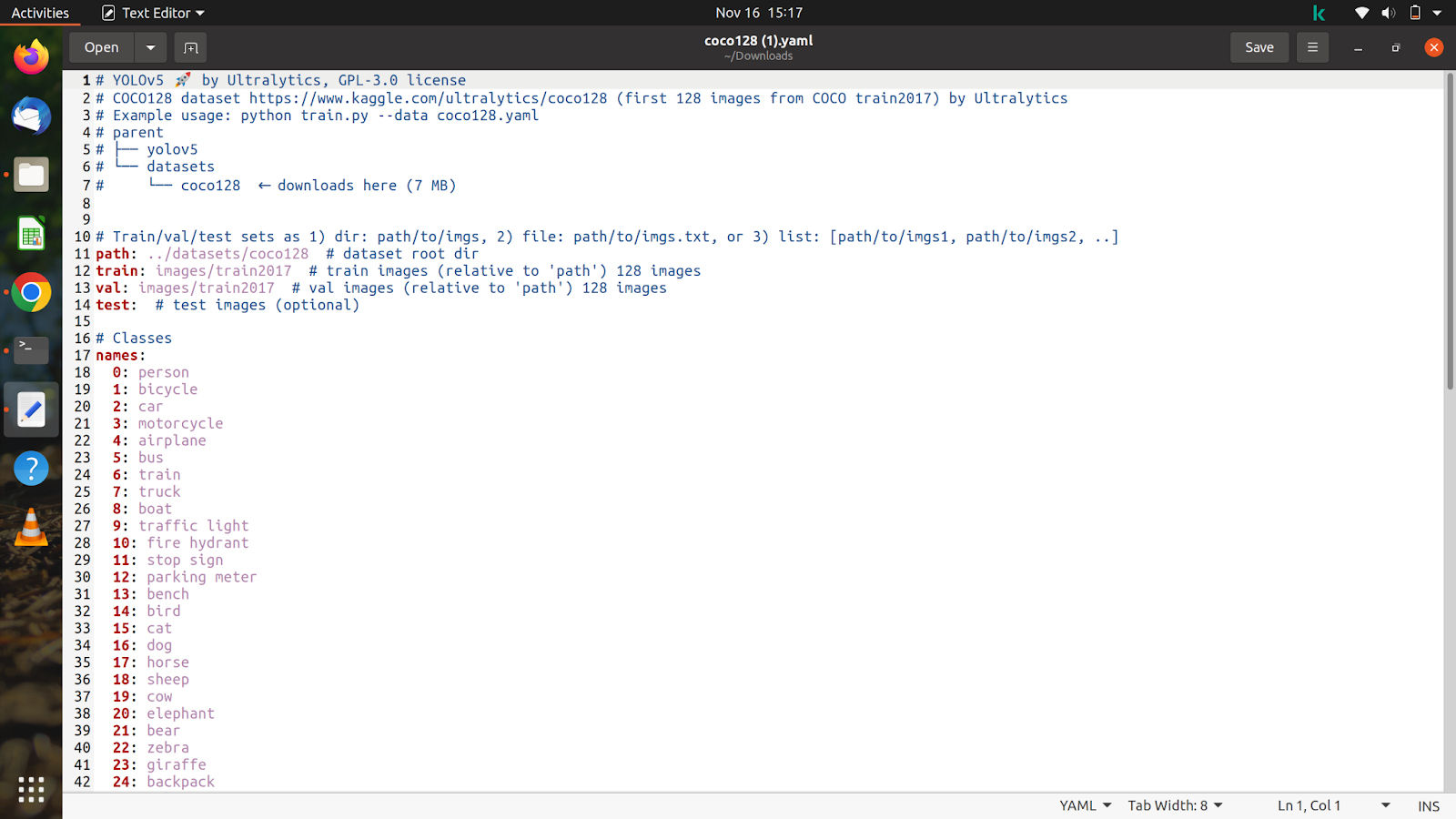
데이터 세트 및 주석에 따라 이 파일을 사용자 정의할 것입니다.
이미 colab에서 데이터 세트의 압축을 풀었으므로 학습 및 검증 이미지의 경로를 복사할 것입니다. dataset 폴더에 있을 '/content/yolov5/CarsData/images/train'과 같은 기차 이미지의 경로를 복사한 후 방금 다운로드한 coco128.yaml 파일에 붙여넣습니다.
테스트 및 검증 이미지에 대해 동일한 작업을 수행합니다.
이제 이 작업을 마친 후 'nc: 1'과 같은 클래스 수를 언급하겠습니다. 이 경우 클래스의 수는 1개뿐입니다. 그러면 아래 이미지와 같이 이름을 언급하겠습니다. 다른 모든 클래스와 필요하지 않은 주석 부분을 제거하면 파일이 다음과 같아야 합니다.
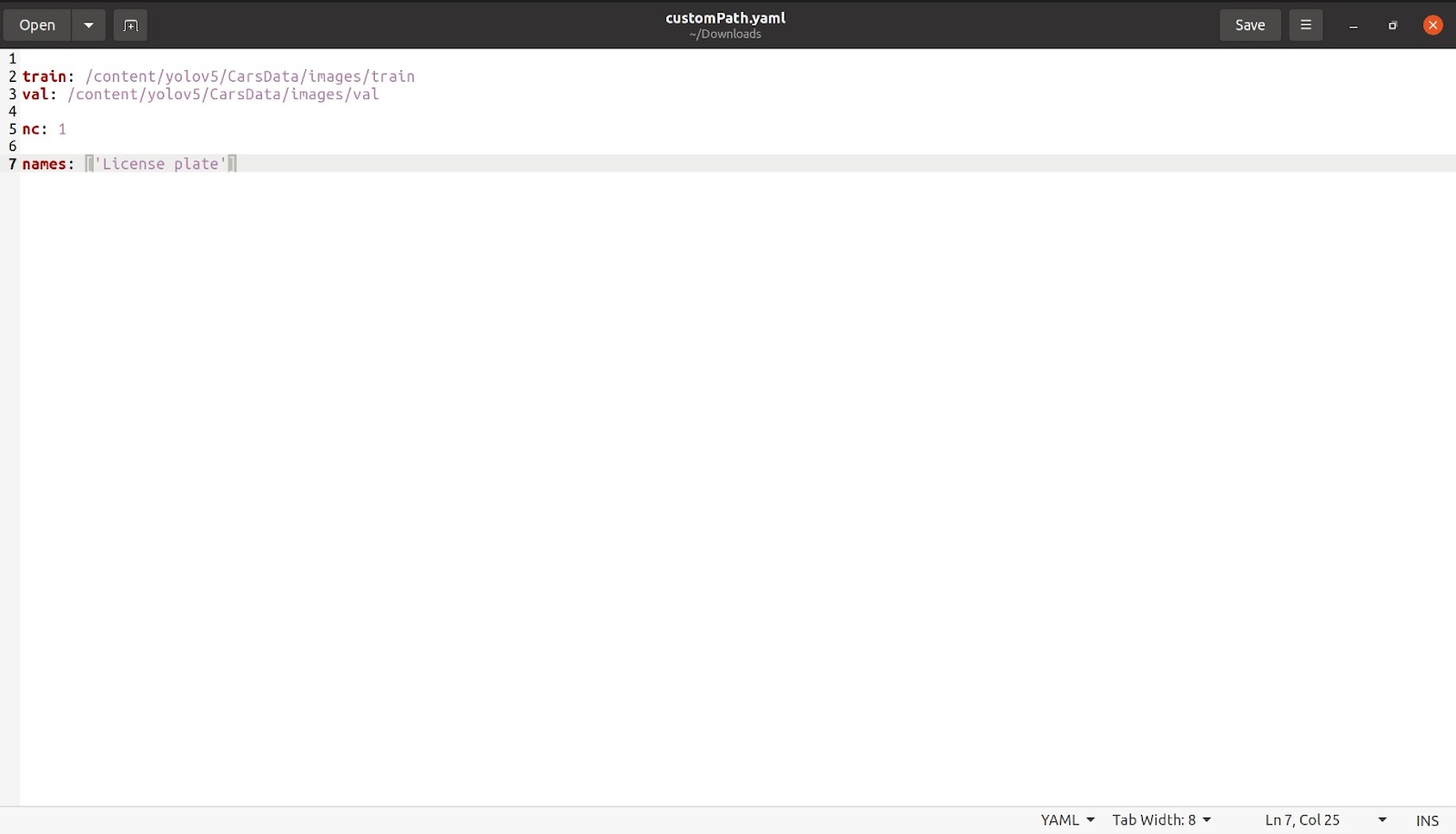
이 파일을 원하는 이름으로 저장하십시오. 나는 파일을 customPath.yaml이라는 이름으로 저장했고 이제 이 파일을 coco128.yaml이 있던 동일한 위치에 있는 colab에 다시 업로드합니다.
이제 편집 부분이 완료되었으며 모델을 교육할 준비가 되었습니다.
다음 명령을 실행하여 사용자 지정 데이터 세트에 대한 몇 가지 상호 작용에 대해 모델을 교육합니다.
업로드한 파일('customPath.yaml)의 이름을 변경하는 것을 잊지 마십시오. 모델을 학습시키려는 에포크 수를 변경할 수도 있습니다. 이 경우 3 epoch 동안만 모델을 훈련할 것입니다.
5. !python train.py –img 640 –batch 16 –epochs 10 –data /content/yolov5/customPath.yaml –weights yolov5s.pt
폴더를 업로드하는 경로를 기억하십시오. 경로가 변경되면 명령이 전혀 작동하지 않습니다.
이 명령을 실행하면 모델이 학습을 시작하고 화면에 다음과 같은 내용이 표시됩니다.
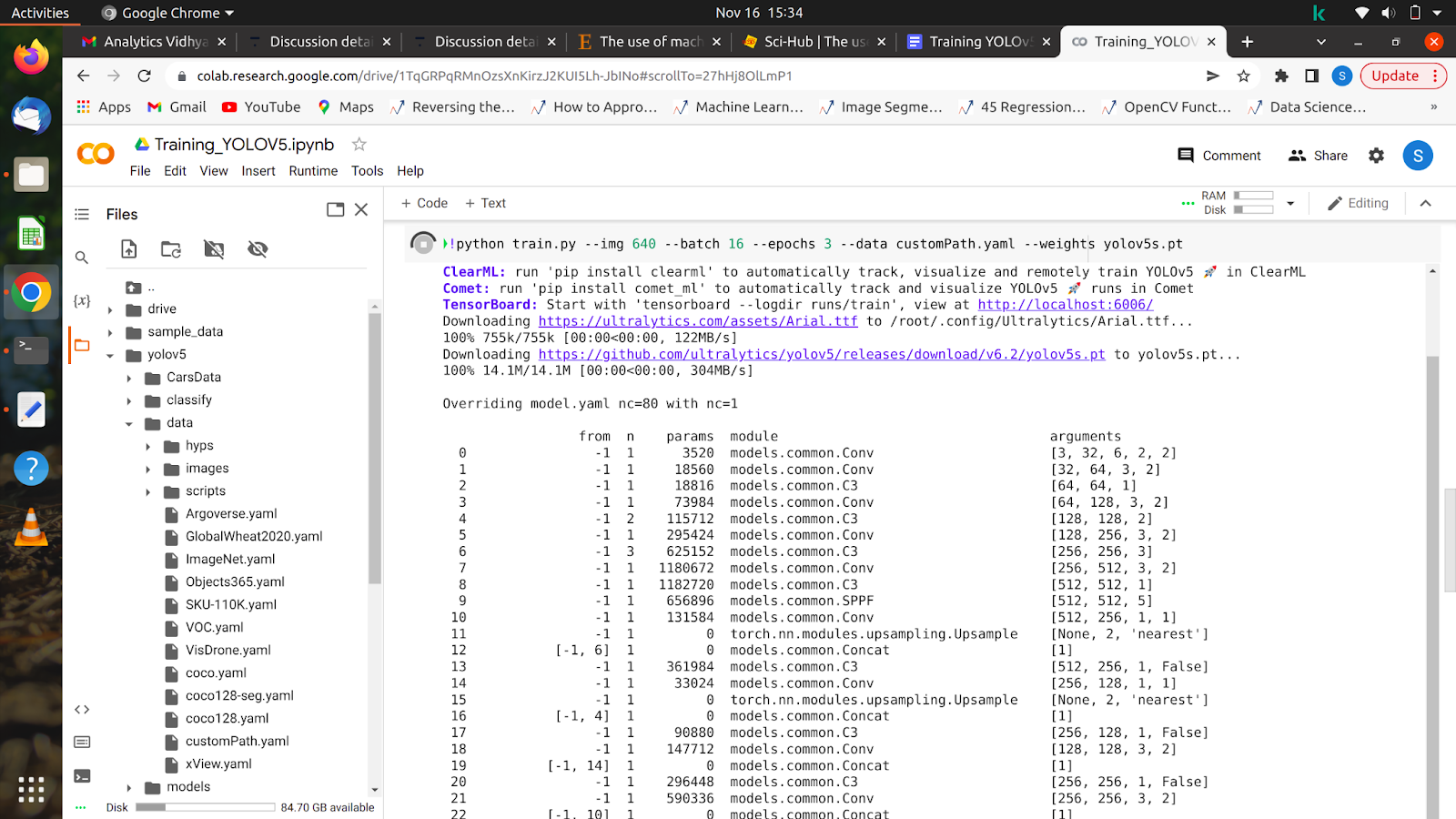
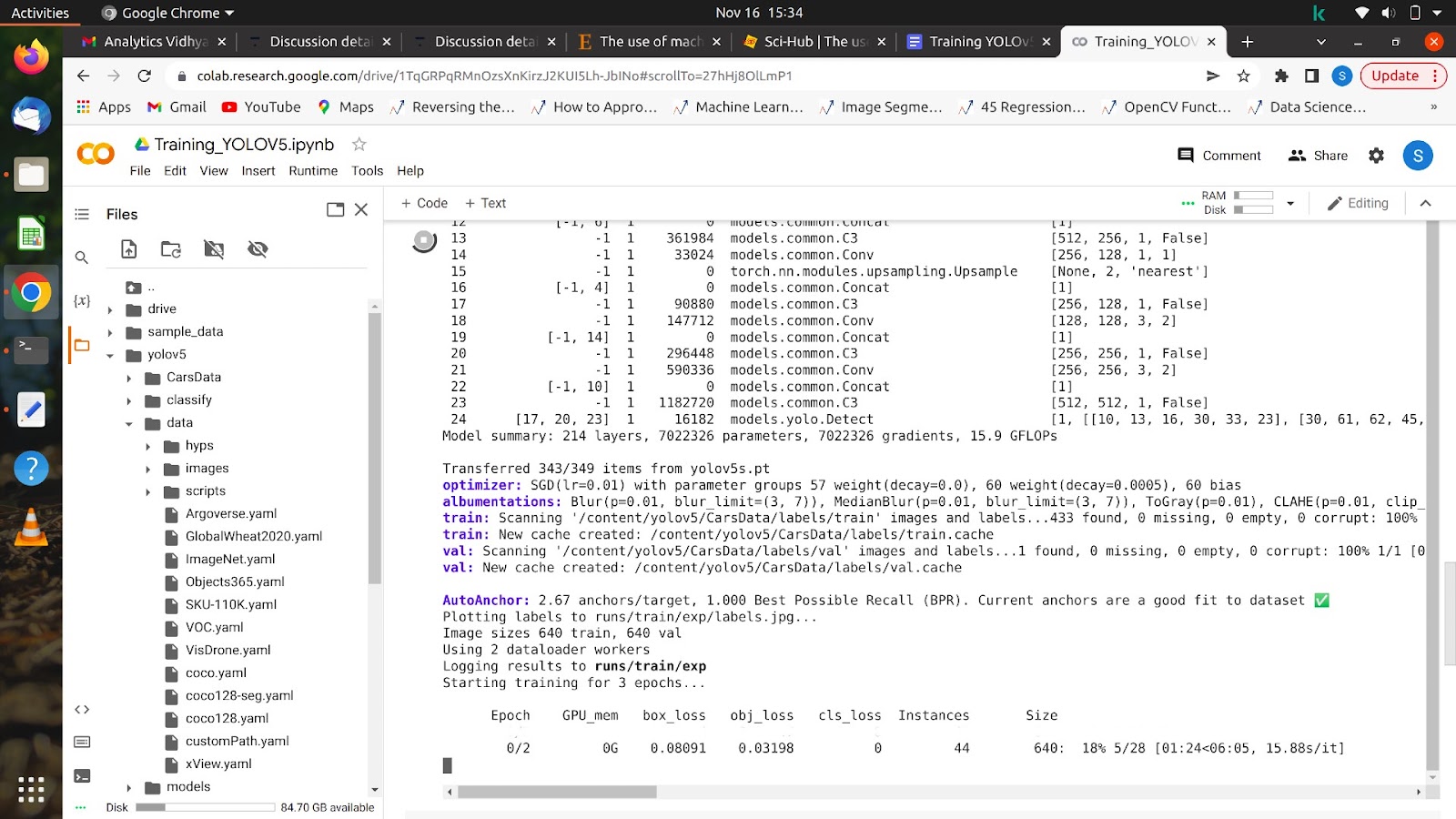
모든 에포크가 완료되면 모델을 모든 이미지에서 테스트할 수 있습니다.
당신은 당신이 저장하고 싶은 것과 싫어하는 것, 번호판이 감지되는 감지 등에 대해 detect.py 파일에서 더 많은 사용자 정의를 할 수 있습니다.
6. !python detector.py –weight /content/yolov5/runs/train/exp/weights/best.pt –source path_of_the_image
이 명령을 사용하여 일부 이미지에서 모델의 예측을 테스트할 수 있습니다.
직면할 수 있는 몇 가지 문제
위에 설명된 단계는 정확하지만 이를 정확히 따르지 않으면 직면할 수 있는 몇 가지 문제가 있습니다.
- 잘못된 경로: 골칫거리이거나 문제가 될 수 있습니다. 이미지를 훈련시키는 과정에서 어딘가 잘못된 경로를 입력했다면 식별이 쉽지 않을 수 있으며, 모델을 훈련시킬 수 없게 됩니다.
- 잘못된 레이블 형식: 이것은 YOLOv5를 교육하는 동안 사람들이 직면하는 광범위한 문제입니다. 이 모델은 모든 이미지에 원하는 형식이 포함된 자체 텍스트 파일이 있는 형식만 허용합니다. 종종 XLS 형식 파일 또는 단일 CSV 파일이 네트워크에 공급되어 오류가 발생합니다. 모든 이미지에 주석을 다는 대신 어딘가에서 데이터를 다운로드하는 경우 라벨이 저장되는 파일 형식이 다를 수 있습니다. 다음은 XLS 형식을 YOLO 형식으로 변환하는 기사입니다. (기사 완료 후 링크).
- 파일 이름을 올바르게 지정하지 않음: 파일 이름을 올바르게 지정하지 않으면 다시 오류가 발생합니다. 폴더 이름 지정 단계에 주의하여 이 오류를 피하십시오.
결론
이번 글에서는 전이학습이 무엇인지, 그리고 사전 훈련된 모델에 대해 알아보았습니다. YOLOv5 모델을 사용하는 시기와 이유, 사용자 지정 데이터 세트에서 모델을 교육하는 방법을 배웠습니다. 우리는 데이터 세트 준비부터 경로 변경, 마지막으로 기술 구현에서 네트워크에 공급하는 모든 단계를 거치고 단계를 철저히 이해했습니다. 또한 YOLOv5를 교육하는 동안 직면하는 일반적인 문제와 그 솔루션을 살펴보았습니다. 이 기사가 사용자 지정 데이터 세트에서 첫 번째 YOLOv5를 훈련하는 데 도움이 되었고 기사가 마음에 드셨기를 바랍니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/02/how-to-train-a-custom-dataset-with-yolov5/
- 1
- 10
- a
- 할 수 있는
- 위의
- 수락
- 에 따르면
- 행위
- 후
- 앞으로
- AI
- All
- 이미
- 금액
- 과
- 아키텍처
- 약
- 기사
- 주의
- 자동적으로
- 가능
- 피하기
- 뒤로
- 기반으로
- 원래
- 전에
- 이하
- 더 나은
- 비트
- 바닥
- 보물상자
- 박스
- 단추
- 주의
- 면밀히
- 케이스
- CD
- 센터
- 과제
- 이전 단계로 돌아가기
- 변경
- 변화
- 검사
- 선택
- 수업
- 수업
- 분류
- 암호
- 왔다
- 댓글
- 공통의
- 커뮤니티
- 진행완료
- 완성
- 복잡한
- 계산
- 혼란
- 이 포함되어 있습니다
- 함유량
- 변하게 하다
- 사자
- 바르게
- 만들
- 만든
- 만들기
- Current
- 관습
- 사용자 정의
- 사용자 정의
- 다크 넷
- 데이터
- 데이터 준비
- 데이터 과학자
- 깊은
- 깊은 학습
- 정의
- 따라
- 탐지 된
- Detection System
- 대화
- 다른
- 직접
- 디렉토리
- 발견
- 몇몇의
- 하기
- 말라
- 다운로드
- 드라이브
- 마다
- 용이함
- 교육하다
- 유효한
- 효과적으로
- 효율적인
- 엔터 버튼
- 입력 된
- 신기원
- 오류
- 등
- 조차
- 모든
- 정확하게
- 예
- 운동
- 설명
- 설명
- 설명
- 수출
- 엄청나게
- 페이스메이크업
- 직면
- FAST
- 빠른
- 연방 준비 은행
- 먹이
- 를
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 파일
- 최종적으로
- 먼저,
- 처음으로
- 초점
- 따라
- 수행원
- 체재
- 뼈대
- 에
- 장난
- 얻을
- GitHub의
- 주기
- Go
- 가는
- 좋은
- 구글
- GPU
- 머리
- 들었다
- 도움
- 도움
- 여기에서 지금 확인해 보세요.
- 강조
- 고도로
- 때리는
- 기대
- 방법
- How To
- HTTPS
- 거대한
- 생각
- 식별
- 확인
- 영상
- 형상
- 이행
- 중대한
- in
- 처음에는
- 설치
- 를 받아야 하는 미국 여행자
- 상호 작용
- 인터넷
- 참여
- IT
- 알아
- 지식
- 라벨
- 레이블
- 넓은
- 대규모
- 큰
- 레이어
- 리드
- 배우다
- 배운
- 배우기
- 도서관
- 특허
- 라인
- LINK
- 로드
- 보기
- 보고
- 봐라.
- 만든
- 확인
- 유튜브 영상을 만드는 것은
- 두드러진
- 경기
- 문제
- 최대 폭
- 방법
- 방법
- 수도
- 수백만
- 신경
- 모델
- 모델
- 배우기
- 가장
- name
- 이름
- 명명
- 필요
- 필요
- 네트워크
- 네트워크
- 번호
- 대상
- 객체 감지
- ONE
- 최적화
- 선택권
- 주문
- 기타
- 자신의
- 꾸러미
- 패키지
- 부품
- 통로
- 지불
- 사람들
- 수행
- 성능
- 실행할 수 있는
- 수행하다
- 장소
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 예측
- 예측
- 준비
- 너무 이른
- 이전에
- 문제
- 문제
- 방법
- 프로젝트
- 증명 된
- 제공
- 목적
- 파이 토치
- 준비
- 실시간
- 최근
- 권하다
- 세련된
- 제거
- 저장소
- 필요
- 필수
- 요구조건 니즈
- 결과
- 결과
- 달리기
- 같은
- 찜하기
- 절약
- 과학자
- 과학자
- 화면
- 서브
- 껍질
- 영상을
- 표시
- 표시
- 상당한
- 비슷한
- 단순, 간단, 편리
- 간단히
- 이후
- 단일
- So
- 해결책
- 일부
- 무언가
- 어딘가에
- 분열
- 쌓인
- 서
- 스타트
- 시작
- 단계
- 단계
- 구조
- 이러한
- 받아
- 태스크
- 작업
- Technology
- 조건
- test
- XNUMXD덴탈의
- 그들의
- 완전히
- 을 통하여
- 시간
- 시간이 많이 걸리는
- 에
- 함께
- 상단
- Train
- 훈련 된
- 트레이닝
- 이전
- 전송
- 지도 시간
- 일반적으로
- 이해
- 이해 된
- 사용
- 보통
- 확인
- 여러
- 자동차
- 버전
- 웹 사이트
- 웹 사이트
- 주
- 뭐
- 어느
- 동안
- 크게
- 펼친
- 의지
- 없이
- 작업
- 일하는
- 겠지
- 쓰다
- 잘못된
- 얌
- 욜로
- 너의
- 제퍼 넷
- 지퍼