올해는 푼타카나에 못 갔어요  하지만 모든 여행 제한에도 불구하고 가까스로 그곳에 도착할 수 있었던 사람들이 있어서 (원격으로) 기쁘네요! 내부에 프리미엄 콘텐츠가 있습니다.
하지만 모든 여행 제한에도 불구하고 가까스로 그곳에 도착할 수 있었던 사람들이 있어서 (원격으로) 기쁘네요! 내부에 프리미엄 콘텐츠가 있습니다.
가을에는 매우 바빠서 더 짧은 형식을 시도하고 싶습니다. 각 큰 주제에는 하나의 "스포트라이트"가 있습니다.  내가 특히 흥미롭다고 생각하는 메인 블록의 작업과 약간 더 짧은 설명이 있는 여러 관련 작업이 있습니다.
내가 특히 흥미롭다고 생각하는 메인 블록의 작업과 약간 더 짧은 설명이 있는 여러 관련 작업이 있습니다.
오늘의 계획:
이 심층 교육 콘텐츠가 도움이된다면 AI 연구 메일 링리스트 구독 새로운 자료를 공개 할 때 경고를받습니다.
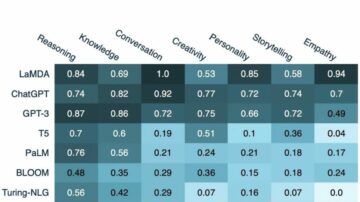
KG-증강 언어 모델: 분류
상황별 언어 모델에서 관계형 세계 지식 표현: 검토 타라 사파비, 다나이 쿠트라
이러한 다이제스트(또는 이전 게시물)의 숙련된 독자라면 모든 컨퍼런스에서 게시되고 매주 arxiv에 업로드되는 수많은 KG 보강 LM을 잘 알고 있을 것입니다. 길을 잃은 것 같다면  — 당신이 유일한 사람은 아니라고 확신합니다.
— 당신이 유일한 사람은 아니라고 확신합니다.
올해는 드디어 사운드 프레임워크 다양한 KG+LM 접근방식의 분류법! 저자는 3가지 대가족을 정의합니다. 1⃣ KG 감독 없음, 클로즈 스타일 프롬프트를 사용하여 LM 매개변수에 인코딩된 지식 조사; 2⃣ 법인 및 ID에 대한 KG 감독; 3⃣ 관계 템플릿 및 표면 양식에 대한 KG 감독.
각 가족에는 몇 개의 가지가 있습니다.  예를 들어 아래에 설명된 4가지 엔터티 인식 모델을 살펴보겠습니다. 다양한 "덜 상징적" 에 “더 상징적”, 일부 LM은 멘션 범위 마스킹, 대조 학습 또는 알려진 어휘의 엔터티 임베딩 융합을 수행합니다. 저자는 프레임워크에 따라 수십 개의 기존 아키텍처를 훌륭하게 분류했으며 이제 훨씬 더 잘 정리된 것처럼 보입니다. 꼭 필요한 작업입니다!
예를 들어 아래에 설명된 4가지 엔터티 인식 모델을 살펴보겠습니다. 다양한 "덜 상징적" 에 “더 상징적”, 일부 LM은 멘션 범위 마스킹, 대조 학습 또는 알려진 어휘의 엔터티 임베딩 융합을 수행합니다. 저자는 프레임워크에 따라 수십 개의 기존 아키텍처를 훌륭하게 분류했으며 이제 훨씬 더 잘 정리된 것처럼 보입니다. 꼭 필요한 작업입니다! 

몇 개의 짧은 논문은 생물의학 KG로 LM을 강화하는 데 중점을 두고 있으며, 이는 LM에게 도메인별 생물의학을 가르치기 위한 장기적인 노력입니다. 속어. 멩 등 제안 파티션 혼합 (MoP), 기반 LM 어댑터퓨전 LM을 처음부터 사전 교육해야 하는 필요성을 완화하는 기술입니다. MoP는 일반적인 생의학 어휘 및 온톨로지 UMLS 및 SNOMED CT로 교육을 받았습니다. 성 외 문의 "언어 모델이 생의학 지식 기반이 될 수 있습니까?" 참고로 Petroni et al의 유명한 EMNLP'19 논문. 대답은 크게 아니. 저자 디자인 바이오라마, UMLS, CTD 및 Wikidata를 기반으로 구축된 생물의학 지식을 조사하기 위한 벤치마크입니다. 그들은 최신 LM이 해당 프로브에서 10% 미만의 정확도를 얻는다는 사실을 발견했습니다. 따라서 커뮤니티에는 확실히 더 신뢰할 수 있는 것이 필요합니다.
멩 등 제안 파티션 혼합 (MoP), 기반 LM 어댑터퓨전 LM을 처음부터 사전 교육해야 하는 필요성을 완화하는 기술입니다. MoP는 일반적인 생의학 어휘 및 온톨로지 UMLS 및 SNOMED CT로 교육을 받았습니다. 성 외 문의 "언어 모델이 생의학 지식 기반이 될 수 있습니까?" 참고로 Petroni et al의 유명한 EMNLP'19 논문. 대답은 크게 아니. 저자 디자인 바이오라마, UMLS, CTD 및 Wikidata를 기반으로 구축된 생물의학 지식을 조사하기 위한 벤치마크입니다. 그들은 최신 LM이 해당 프로브에서 10% 미만의 정확도를 얻는다는 사실을 발견했습니다. 따라서 커뮤니티에는 확실히 더 신뢰할 수 있는 것이 필요합니다.  .
.
대화형 AI: 환각 그만해, 형제
신경 경로 사냥꾼: 경로 접지를 통한 대화 시스템의 환각 감소 Nouha Dziri, Andrea Madotto, Osmar Zaiane, Avishek Joey Bose 작성
KG 배경을 가진 ConvAI 시스템으로 응답을 생성하는 것은 까다롭습니다. 구성 요소가 많은 파이프라인 시스템에서는 표면 형식(엔티티 이름)을 엄격하게 사용하고 대부분 템플릿에 의존합니다. 템플릿은 지루하다 유지 관리가 거의 불가능합니다. 반면에 GPT-2 및 GPT-2과 같은 e3e 생성 모델은 훨씬 더 고유한 응답을 생성하지만 종종 환각을 일으킬 수 있습니다. 즉, 예상치 못한 잘못된 엔터티 이름을 삽입합니다.
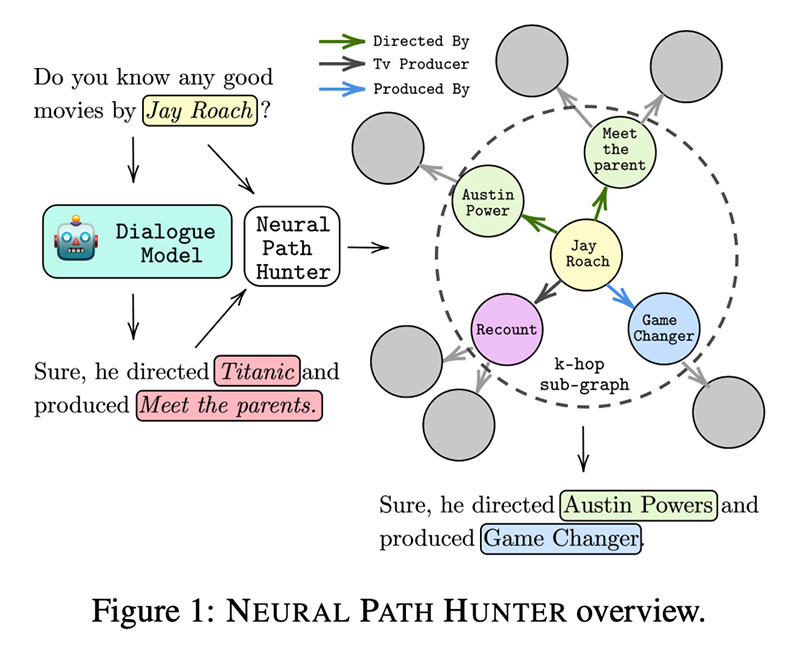
이 작업의 저자는 다음 작업에 착수했습니다. 사냥  KG 감독이 제안하는 환각을 줄이기 위해 신경 경로 헌터. 첫째, 그들은 여러 가지를 공부합니다. 환각의 종류 , 출처(대부분 상위 k 샘플링) 및 이를 정량화하는 방법.
KG 감독이 제안하는 환각을 줄이기 위해 신경 경로 헌터. 첫째, 그들은 여러 가지를 공부합니다. 환각의 종류 , 출처(대부분 상위 k 샘플링) 및 이를 정량화하는 방법.
NPH 자체는 두 가지 모듈로 구성됩니다. 1⃣ 토큰에 대해 이진 분류를 수행하는 비평가(비자기회귀 LM); 2⃣ 엔터티 오류 수정을 위한 엔터티 검색기: 이는 본질적으로 엔터티 임베딩이 GPT에서 제공되고 그래프 구조를 사용하여 CompGCN으로 업데이트되는 엔터티 메모리입니다. 가장 그럴듯한 후보는 DistMult 점수 함수를 적용한 것입니다. 짜잔!
NPH는 사전 훈련된 LM과 짝을 이룰 수 있습니다. 오픈다이얼KG GPT2-KG로 벤치마크, GPT2-KE및 어댑터봇 상당한 감소를 보여  환각과 증가
환각과 증가  신실함 속에서. 사용자 연구에 따르면 인간이 측정한 환각은 NPH 모델에서 최대 2배 감소했습니다.
신실함 속에서. 사용자 연구에 따르면 인간이 측정한 환각은 NPH 모델에서 최대 2배 감소했습니다.
이 맥락에서 또 다른 관련 작업: 호노비치 외 KG 배경 없이 대화 시스템에서 동일한 문제를 연구하고 새로운 벤치마크를 제안합니다. Q² 질문 생성 및 질문 답변의 사실적 일관성을 측정합니다(요청하는 경우 두 Q의 출처).
ConvAI 및 상식 KG에 관심이 있다면 다음의 CLUE(Conversational Multi-Hop Reasoner)를 꼭 확인하세요. Arabshahi, Lee 등라는 개념을 포함하는 if-(상태), then-(행동), 왜냐하면-(목표) 패턴 논리적 규칙과 상징적 추론.
엔터티 연결: 거상의 그림자 속에서
선행 프로브를 이용한 개체 명확화의 강건성 평가: 개체 가림 사례 by 베라 프로바토로바, 스비틀라나 바쿨렌코, 사마르스 바르가브, 에반겔로스 카누라스
언어 작업을 위해 실제 KG를 연결하면 필연적으로 만나게 될 것입니다. 다른 엔티티 정확히 같은 이름  . 안타깝게도 인류는 전 세계 모든 엔터티에 대해 고유한 해시를 사용하지 않으므로 엔터티 명확성은 엔터티 연결의 중요한 단계로 남아 있습니다.
. 안타깝게도 인류는 전 세계 모든 엔터티에 대해 고유한 해시를 사용하지 않으므로 엔터티 명확성은 엔터티 연결의 중요한 단계로 남아 있습니다.

예를 들어 위키데이터는 "Michael Jordan"이라는 항목이 18개 이상. 종종 EL 시스템은 기본 통계 및 인기 점수에 의존하므로 가장 인기 있는 "Michael Jordan 농구 선수"가 덜 눈에 띄는(적어도 대중 문화에서는) 사람들을 압도할 것입니다.
 저자는 이 문제를 해결하고 새로운 데이터 세트를 소개합니다. 섀도우링크, 현대 EL 시스템의 혼란 정도를 측정합니다. 가장 높은 F1 점수는 간신히 0.35에 도달하는 것으로 나타났습니다(최근 생성 유형 가장 단단한 부분에서 0.26)을 산출합니다. 모든 시스템은 롱테일 희귀 엔터티에 대한 점수를 포화시키고 더 일반적인 엔터티에도 대처합니다. 주요 과제는 "작업을 어렵게 만드는 것은 모호함과 흔하지 않음의 조합입니다.". 작성자가 데이터 세트를 다음 위치에 업로드하는 것이 좋습니다. HuggingFace 데이터 세트 멋진 프로젝트의 가시성을 높이기 위해
저자는 이 문제를 해결하고 새로운 데이터 세트를 소개합니다. 섀도우링크, 현대 EL 시스템의 혼란 정도를 측정합니다. 가장 높은 F1 점수는 간신히 0.35에 도달하는 것으로 나타났습니다(최근 생성 유형 가장 단단한 부분에서 0.26)을 산출합니다. 모든 시스템은 롱테일 희귀 엔터티에 대한 점수를 포화시키고 더 일반적인 엔터티에도 대처합니다. 주요 과제는 "작업을 어렵게 만드는 것은 모호함과 흔하지 않음의 조합입니다.". 작성자가 데이터 세트를 다음 위치에 업로드하는 것이 좋습니다. HuggingFace 데이터 세트 멋진 프로젝트의 가시성을 높이기 위해  .
.
아로라 외 다른 방향에서 엔티티 연결 문제에 접근하십시오. 주요 아이디어는 참된 이름 엔티티 문서에서(하나씩 처리하지 않고 공동으로 처리) 기간 하급 부분 공간  후보자를 포함한 모든 엔터티의 공간에서(아래의 시각적 예를 확인하세요) 그만큼 고유테마 사전 훈련된 엔터티 임베딩이 있는 경우 접근 방식은 감독되지 않습니다. 작성자는 Wikidata의 영어 하위 집합에 대해 DeepWalk를 사용합니다(또는 단어 임베딩을 시도하지만 제대로 작동하지 않음).
후보자를 포함한 모든 엔터티의 공간에서(아래의 시각적 예를 확인하세요) 그만큼 고유테마 사전 훈련된 엔터티 임베딩이 있는 경우 접근 방식은 감독되지 않습니다. 작성자는 Wikidata의 영어 하위 집합에 대해 DeepWalk를 사용합니다(또는 단어 임베딩을 시도하지만 제대로 작동하지 않음).

개념적으로 비슷한 엔티티 기반 충돌 문제 에 의해 연구된다 롱프레 등, 즉 지식 대체 — 단락의 실제 개체를 무작위로(또는 모순되는 항목으로) 뒤집으면 모델이 답을 변경합니까? 즉, QA 모델은 맥락 읽기 또는 기억된 지식에 의존합니까? 이러한 대체를 통해 QA 모델을 훈련할 때 OOD 일반화를 상당히 높일 수 있다는 것이 밝혀졌습니다!
마지막으로 설문조사를 살펴보겠습니다. 테데스키 외 on "엔터티 연결을 위한 NER: 작동하는 것과 다음 단계". 저자는 EL의 주요 문제를 식별하고 NER 관련 문제를 해결하려고 노력합니다. 네르포엘 사전 훈련된 대규모 LM과 특히 리소스가 부족한 시나리오와 관련된 소규모 모델 간의 성능 격차를 줄이는 것을 목표로 합니다. .

KG건설
나는 여기서 눈길을 끄는 줄을 생각해내지 못했습니다 :/ OpenIE와 KG 건설에 관심이 있다면 다음 문서가 관련이 있을 수 있습니다.
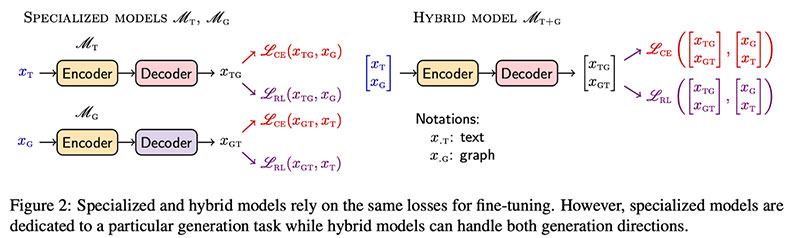
Dognin 등 제안 리젠, LM을 미세 조정하여 Text2Graph 및 Graph2Text 작업을 모두 수행(또는 전문 모델을 미세 조정)하기 위한 접근 방식입니다. 핵심 성분  표준 교차 엔트로피(CE) 외에 RL 손실(Self-Critical Sequence Training)을 추가하고 있습니다. 사전 훈련된 LM에 쉽게 추가할 수 있습니다. 저자는 T5-Large(770M 매개변수) 및 T5-base(220M 매개변수)를 사용해 시도했습니다.
표준 교차 엔트로피(CE) 외에 RL 손실(Self-Critical Sequence Training)을 추가하고 있습니다. 사전 훈련된 LM에 쉽게 추가할 수 있습니다. 저자는 T5-Large(770M 매개변수) 및 T5-base(220M 매개변수)를 사용해 시도했습니다.  실험적으로, 리젠 Text2Graph WebNLG 기준선(메트릭에 따라 3–10 절대 포인트)보다 크게 향상되고 많은 큰 TekGen 데이터세트 (6M 트레이닝 페어).
실험적으로, 리젠 Text2Graph WebNLG 기준선(메트릭에 따라 3–10 절대 포인트)보다 크게 향상되고 많은 큰 TekGen 데이터세트 (6M 트레이닝 페어).
대시 외 공부하다 정식화 OpenIE의 문제 — 다른 표면 형태를 가진 엔터티가 (뉴욕시, 뉴욕시) 동일한 프로토타입을 참조하십시오. 비감독 방식으로 우리는 IE 시스템이 이러한 언급을 함께 자동으로 클러스터링하기를 원합니다. 방법, 쿠바, VAE(Variational Autoencoders)를 사용하여 클러스터를 식별합니다(엔티티 및 관계는 가우시안에 의해 매개변수화됨). VAE에 대한 표준 외에도 재건 손실, CUVA는 추가로 링크 예측 오프 HolE 채점 기능을 기반으로 합니다.  게다가 저자는 소설을 소개한다. 캐논넬 데이터 세트!
게다가 저자는 소설을 소개한다. 캐논넬 데이터 세트!

KG 질문 답변: 일부 추가  스파클
스파클
중간 질문 분해에서 SPARQLing 데이터베이스 쿼리 by 이리나 사파리나와 안톤 오소킨
불행하게도 *CL 도메인에는 SPARQL 애플리케이션이 그리 많지 않습니다. 나는 그것이 NLP에서 훨씬 더 광범위하게 채택될 가치가 있다고 생각합니다. 멋진 애플리케이션의 지원을 받을 때 — 저는  .
.
대부분의 구조화된 QA 데이터 세트 또는 시맨틱 파싱 대상 SQL을 기본 출력 형식으로 사용하는 데이터 세트. SQL 파이프라인 이외의 삶이 있습니까?
사파리나와 오소킨 1⃣ 먼저 다음을 사용하여 해당 문제에 대한 새로운 모습을 제안합니다. 질문 분해 의미 표현(QDMR) 질문을 구문 독립적인 논리적 형식으로 변환하는 프레임워크; 2⃣ 이 형식은 모든 구조화된 형식으로 변환될 수 있으며 여기서 저자는 SPARQL을 사용하여 그래프 형식으로 데이터베이스를 쿼리하는 것이 훨씬 쉽다는 것을 보여줍니다. 입력 테이블을 RDF로 변환해야 하지만 거미 아주 쉽게 할 수 있습니다.
학습 가능한 모듈에는 다음이 포함됩니다. 쥐 변압기 QDMR 토큰을 생성하는 LSTM 디코더가 있는 인코더. QDMR -> SPARQL은 몇 가지 규칙을 기반으로 하는 직선 트랜스파일입니다. SOTA와 동등한 결과; 코드를 사용할 수 있습니다 ; SPARQL은 SQL보다 더 잘 작동합니다.
SOTA와 동등한 결과; 코드를 사용할 수 있습니다 ; SPARQL은 SQL보다 더 잘 작동합니다.
좋은 논문을 위해 또 무엇이 필요합니까?

또 다른 흥미로운 작품 Das et al의 "지식 기반에 대한 자연어 쿼리에 대한 사례 기반 추론" SPARQL을 다음과 결합 사례 기반 추론 (CBR). CBR은 80년대 전문가 시스템에 뿌리를 두고 있지만 최근 표현 학습의 힘으로 되살아났습니다. 2021년 CBR에 대한 TLDR 설명: 개념적으로 구성 일반화에 가깝습니다. 즉, 몇 가지 기본 예제를 본 후 이전에 본 적이 없는 엔터티에 대해 더 복잡한 쿼리를 구성할 수 있습니다.
아래 예를 살펴보십시오. 입력 쿼리가 있습니다. “호빗에서 김리의 아버지의 형제는 누구입니까?”. 학습 데이터에서 Gimli 또는 Hobbit에 대한 정보가 없을 수 있지만 "상대적으로 유사"할 수 있습니다. 가지 경우 예를 들어 쿼리에 유용한 관계를 찾을 수 있습니다. "찰리 쉰의 아버지는 누구입니까?" Freebase 관계 people.person_parents 및 "리한나의 형제는 누구입니까?" 관계로 people.person.sibling_s . 질문을 위해 그것들을 구성하여 데이터베이스에 대한 SPARQL 쿼리를 구성합니다.
제안 CBR-KBQA 접근 방식은 1⃣ DPR 스타일의 훈련 가능한 신경 검색기(감독은 중첩 관계를 기반으로 함), 2⃣ 선형 변환기(BigBird 사용)를 결합합니다. 연결된 관련 질문과 쿼리는 상당히 길기 때문입니다. 3⃣ 여러 재순위 메커니즘을 사용하여 정리합니다. 예측. 기성품 NER 및 엔터티 연결 모듈을 사용하고 순위 재지정을 위해 사전 훈련된 TransE 관계 임베딩도 사용합니다. CBR-KBQA는 다음을 포함한 여러 KBQA 데이터 세트에서 인상적인 성능을 보여줍니다. CFQ. 작은 메모: 사용 가능한 최상의 SOTA 모델(67.3 MCD-Mean)이 78.1의 마진을 능가하고 벤치마크에 제출되지 않았으며 코드도 아직 사용할 수 없다는 것이 약간 의심스럽습니다.

시 외 다중 홉 QA를 연구하고 엔터티/관계 ID(레이블 형식)와 자연어 설명(텍스트 형식)을 메시지 전파 프레임워크에 통합하도록 제안합니다. 트랜스퍼넷. 평가는 표준 MetaQA, WebQuestionsSP 및 복잡한 웹 질문 데이터 세트에서 수행됩니다.
동일한 작업(이전 작업과 동일한 데이터 세트)에서 올리야 외 대부분의 SOTA QA 모델에는 이미 KG 엔터티에 연결된 텍스트 범위가 필요하며 KG 엔터티의 노드 이웃 기능과 텍스트 범위의 기능을 사용하여 동적 엔터티 순위 재지정으로 이 요구 사항을 우회하려고 합니다.
그게 다야
이 짧은 "premum"이 마음에 드시면 알려주세요.  이전 리뷰에서처럼 너무 많은 텍스트 벽보다 형식이 더 좋습니다! 여기에 시간을 투자해 주셔서 감사합니다. 유용한 정보를 집에 가져가셨기를 바랍니다.
이전 리뷰에서처럼 너무 많은 텍스트 벽보다 형식이 더 좋습니다! 여기에 시간을 투자해 주셔서 감사합니다. 유용한 정보를 집에 가져가셨기를 바랍니다.

이 기사는 원래에 게시되었습니다. 중급 저자의 허락을 받아 TOPBOTS에 다시 게시했습니다.
이 기사가 마음에 드십니까? 더 많은 AI 업데이트에 가입하세요.
더 많은 기술 교육을 발표하면 알려 드리겠습니다.
포스트 EMNLP 2021의 지식 그래프 첫 번째 등장 톱봇.
- '
- "
- 10
- 11
- 2021
- 67
- 7
- 9
- a
- 소개
- 풍부
- 에 따르면
- 동작
- 추가
- 또한
- 주소
- 관리
- 양자
- AI
- 인공 지능 연구
- 조준
- All
- 이미
- 모호
- 분석
- 다른
- 답변
- 어플리케이션
- 어플리케이션
- 적용된
- 적용
- 접근
- 기사
- 작성자
- 자동적으로
- 가능
- 배경
- 농구
- 이하
- 기준
- BEST
- 사이에
- 그 너머
- 가장 큰
- 비트
- 블록
- 사업
- 전화
- 후보자
- 케이스
- 가지 경우
- 도전
- 과제
- 도전
- 이전 단계로 돌아가기
- City
- 분류
- 암호
- 결합
- 왔다
- 공통의
- 커뮤니티
- 복잡한
- 구성 요소들
- 컨퍼런스
- 혼동
- 구조
- 함유량
- 수
- 문화
- 고객
- 고객센터
- 데이터
- 데이터베이스
- 데이터베이스
- 깊은
- 보여
- 의존
- 설명
- DID
- 다른
- 하지 않습니다
- 도메인
- 동적
- 마다
- 용이하게
- 교육
- 교육적인
- 노력
- 고용하다
- 영어
- 엔티티
- 실재
- 특히
- 본질적으로
- 평가
- 이벤트
- 예
- 예
- 흥미 진진한
- 현존하는
- 기대
- 전문가
- 가족
- 가족
- 특징
- 최종적으로
- 재원
- 먼저,
- 초점
- 수행원
- 형태
- 체재
- 양식
- 뼈대
- 에
- 기능
- 갭
- 세대
- 생성적인
- GitHub의
- 골
- 좋은
- 큰
- 행복한
- 데
- 신장
- 여기에서 지금 확인해 보세요.
- 홈
- 기대
- 방법
- How To
- hr
- HTTPS
- 인간성
- 생각
- 확인
- 중대한
- 인상
- 기타의
- 포함
- 증가
- 입력
- 예
- 통합
- 투자
- IT
- 그 자체
- 일
- 키
- 알아
- 지식
- 알려진
- 라벨
- 언어
- 넓은
- 배우기
- 이용약관
- 라인
- 연결
- 런던
- 긴
- 보기
- 과반수
- 확인
- 제작
- 관리
- 관리
- 태도
- 마케팅
- 자료
- 의미
- 측정
- 매질
- 메모리
- 언급하다
- 수도
- 모델
- 모델
- 배우기
- 가장
- 가장 인기 많은
- 즉
- 이름
- 자연의
- 요구
- 뉴욕
- 뉴욕시
- 개념
- NYC
- 온타리오
- 행정부
- 최
- 기타
- 서
- 부품
- 특별히
- 성능
- 사람
- 부디
- 전철기
- 인기 문서
- 인기
- 게시물
- 힘
- 예측
- 프리미엄
- 예쁜
- 너무 이른
- 문제
- 생산
- 프로덕트
- 프로젝트
- 현저한
- 제안
- 문제
- 리더
- 읽기
- 최근
- 최근에
- 권하다
- 감소
- 감소
- 감소
- 관계
- 공개
- 관련된
- 신뢰할 수있는
- 유적
- 보고서
- 대표
- 필요
- 연구
- 리조트
- 결과
- 규칙
- 판매
- 같은
- 규모
- 점수
- 몇몇의
- 그림자
- 짧은
- 기호
- 상당한
- 작은
- So
- 일부
- 무언가
- 스페이스 버튼
- 전문
- 표준
- 주 정부
- 통계
- 구조화
- 교육과정
- 제출
- 감독
- SUPPORT
- 지원
- 표면
- 설문조사
- 체계
- 시스템은
- 목표
- 작업
- 테크니컬
- 템플릿
- XNUMXD덴탈의
- 세계
- 시간
- 오늘
- 함께
- 토큰
- 화제
- 트레이닝
- 변화
- 여행
- Uk
- 유일한
- 업데이트
- 사용
- 여러
- 가시성
- W
- 웹
- 주간
- 뭐
- 누구
- 넓은
- 말
- 작업
- 일
- 세계
- 겠지
- year
- 너의