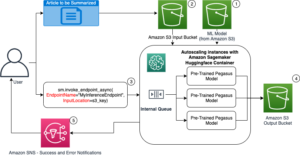
아마존 세이지 메이커 의 제품군을 제공합니다 내장 알고리즘, 사전 훈련 된 모델및 사전 구축된 솔루션 템플릿 데이터 과학자와 머신 러닝(ML) 실무자가 ML 모델 교육 및 배포를 빠르게 시작할 수 있도록 지원합니다. 지도 및 비지도 학습 모두에 이러한 알고리즘과 모델을 사용할 수 있습니다. 표, 이미지, 텍스트 등 다양한 유형의 입력 데이터를 처리할 수 있습니다.
오늘부터 SageMaker는 LightGBM, CatBoost, AutoGluon-Tabular 및 TabTransformer의 XNUMX가지 새로운 내장 테이블 형식 데이터 모델링 알고리즘을 제공합니다. 표 분류 및 회귀 작업 모두에 이러한 인기 있는 최신 알고리즘을 사용할 수 있습니다. 그들은 통해 사용할 수 있습니다 내장 알고리즘 SageMaker 콘솔 및 Amazon SageMaker 점프스타트 내부 UI 아마존 세이지 메이커 스튜디오.
다음은 문서, 예제 노트북 및 소스에 대한 링크와 함께 XNUMX개의 새로운 기본 제공 알고리즘 목록입니다.
| 문서 | 예제 노트북 | 출처 |
| LightGBM 알고리즘 | 리그레션, 분류 | 라이트 GBM |
| CatBoost 알고리즘 | 리그레션, 분류 | 캣부스트 |
| AutoGluon-표 알고리즘 | 리그레션, 분류 | AutoGluon-표 |
| TabTransformer 알고리즘 | 리그레션, 분류 | 탭변환기 |
다음 섹션에서는 각 알고리즘에 대한 간략한 기술 설명과 SageMaker SDK 또는 SageMaker Jumpstart를 통해 모델을 훈련하는 방법의 예를 제공합니다.
라이트 GBM
라이트 GBM GBDT(Gradient Boosting Decision Tree) 알고리즘의 대중적이고 효율적인 오픈 소스 구현입니다. GBDT는 더 단순하고 약한 모델 세트에서 추정의 앙상블을 결합하여 대상 변수를 정확하게 예측하려고 시도하는 지도 학습 알고리즘입니다. LightGBM은 추가 기술을 사용하여 기존 GBDT의 효율성과 확장성을 크게 향상시킵니다.
캣부스트
캣부스트 GBDT 알고리즘의 인기 있는 고성능 오픈 소스 구현입니다. CatBoost에는 두 가지 중요한 알고리즘 발전이 도입되었습니다. 즉, 순서 부스팅의 구현, 기존 알고리즘에 대한 순열 기반 대안, 범주형 기능을 처리하기 위한 혁신적인 알고리즘입니다. 두 기술 모두 현재 존재하는 모든 그래디언트 부스팅 알고리즘 구현에 존재하는 특수한 종류의 표적 누출로 인한 예측 변화를 방지하기 위해 만들어졌습니다.
AutoGluon-표
AutoGluon-표 Amazon에서 개발 및 유지 관리하는 오픈 소스 AutoML 프로젝트로 고급 데이터 처리, 딥 러닝 및 다계층 스택 앙상블을 수행합니다. 텍스트 필드의 특수 처리를 포함하여 강력한 데이터 사전 처리를 위해 각 열의 데이터 유형을 자동으로 인식합니다. AutoGluon은 기성 부스트 트리에서 맞춤형 신경망 모델에 이르기까지 다양한 모델에 적합합니다. 이러한 모델은 새로운 방식으로 앙상블됩니다. 모델은 여러 계층에 쌓이고 원시 데이터가 주어진 시간 제약 내에서 고품질 예측으로 변환될 수 있도록 보장하는 계층 방식으로 훈련됩니다. out-of-fold 예제를 주의 깊게 추적하여 데이터를 다양한 방식으로 분할하여 이 프로세스 전반에 걸쳐 과적합을 완화합니다. AutoGluon은 성능에 최적화되어 있으며 즉시 사용하여 데이터 과학 대회에서 여러 상위 3위 및 10위를 차지했습니다.
탭변환기
탭변환기 지도 학습을 위한 새로운 심층 테이블 형식 데이터 모델링 아키텍처입니다. TabTransformer는 self-attention 기반 Transformer를 기반으로 합니다. Transformer 레이어는 더 높은 예측 정확도를 달성하기 위해 범주형 기능의 임베딩을 강력한 컨텍스트 임베딩으로 변환합니다. 또한 TabTransformer에서 학습한 상황별 임베딩은 누락 및 잡음이 있는 데이터 기능 모두에 대해 매우 강력하며 더 나은 해석성을 제공합니다. 이 모델은 최근의 제품입니다. 아마존 사이언스 연구 (종이 그리고 공식 블로그 게시물 여기) 다양한 타사 구현과 함께 ML 커뮤니티에서 널리 채택되었습니다(케 라스, 오토글루온,) 및 다음과 같은 소셜 미디어 기능 트윗, 데이터 과학을 향해, 중간 및 카글.
SageMaker 내장 알고리즘의 이점
특정 유형의 문제 및 데이터에 대한 알고리즘을 선택할 때 SageMaker 내장 알고리즘을 사용하는 것이 가장 쉬운 옵션입니다. 그렇게 하면 다음과 같은 주요 이점이 있기 때문입니다.
- 기본 제공 알고리즘은 실험 실행을 시작하기 위해 코딩이 필요하지 않습니다. 제공해야 하는 유일한 입력은 데이터, 하이퍼파라미터 및 컴퓨팅 리소스입니다. 이를 통해 결과 및 코드 변경 추적에 대한 오버헤드를 줄이면서 실험을 더 빠르게 실행할 수 있습니다.
- 기본 제공 알고리즘은 여러 컴퓨팅 인스턴스에 대한 병렬화와 함께 제공되며 모든 적용 가능한 알고리즘에 대한 GPU 지원을 즉시 사용할 수 있습니다(일부 알고리즘은 고유한 제한 사항으로 인해 포함되지 않을 수 있음). 모델을 훈련할 데이터가 많은 경우 대부분의 기본 제공 알고리즘은 수요를 충족하도록 쉽게 확장할 수 있습니다. 이미 사전 훈련된 모델이 있더라도 직접 이식하고 훈련 스크립트를 작성하는 것보다 SageMaker에서 그 결과를 사용하고 이미 알고 있는 하이퍼파라미터를 입력하는 것이 더 쉬울 수 있습니다.
- 결과 모델 아티팩트의 소유자입니다. 해당 모델을 가져와서 SageMaker에서 다양한 추론 패턴에 배포할 수 있습니다(모든 사용 가능한 배포 유형) 및 손쉬운 엔드포인트 확장 및 관리를 제공하거나 필요할 때마다 배포할 수 있습니다.
이제 이러한 내장 알고리즘 중 하나를 훈련하는 방법을 살펴보겠습니다.
SageMaker SDK를 사용하여 내장 알고리즘 훈련
선택한 모델을 훈련하려면 해당 모델의 URI와 훈련 스크립트의 URI, 훈련에 사용되는 컨테이너 이미지를 가져와야 합니다. 고맙게도 이 세 가지 입력은 모델 이름, 버전에만 의존합니다(사용 가능한 모델 목록은 JumpStart 사용 가능한 모델 테이블) 및 학습하려는 인스턴스 유형입니다. 이는 다음 코드 스니펫에 나와 있습니다.
XNUMXD덴탈의 train_model_id 변경 사항 lightgbm-regression-model 회귀 문제를 다루고 있다면. 이 게시물에 소개된 다른 모든 모델의 ID는 다음 표에 나열되어 있습니다.
| 모델 | 문제 유형 | 모델 ID |
| 라이트 GBM | 분류 | lightgbm-classification-model |
| . | 리그레션 | lightgbm-regression-model |
| 캣부스트 | 분류 | catboost-classification-model |
| . | 리그레션 | catboost-regression-model |
| AutoGluon-표 | 분류 | autogluon-classification-ensemble |
| . | 리그레션 | autogluon-regression-ensemble |
| 탭변환기 | 분류 | pytorch-tabtransformerclassification-model |
| . | 리그레션 | pytorch-tabtransformerregression-model |
그런 다음 입력이 어디에 있는지 정의합니다. 아마존 단순 스토리지 서비스 (아마존 S3). 이 예에서는 공개 샘플 데이터 세트를 사용하고 있습니다. 또한 우리는 출력을 어디로 갈 것인지 정의하고 선택한 모델을 훈련하는 데 필요한 하이퍼파라미터의 기본 목록을 검색합니다. 원하는대로 값을 변경할 수 있습니다.
마지막으로 SageMaker를 인스턴스화합니다. Estimator 검색된 모든 입력으로 학습 작업을 시작합니다. .fit, 교육 데이터 세트 URI를 전달합니다. 그만큼 entry_point 제공된 스크립트의 이름은 transfer_learning.py (다른 작업 및 알고리즘에 대해서도 동일) 및 다음으로 전달되는 입력 데이터 채널 .fit 이름이 있어야합니다 training.
다음을 사용하여 내장 알고리즘을 훈련할 수 있습니다. SageMaker 자동 모델 튜닝 최적의 하이퍼파라미터를 선택하고 모델 성능을 더욱 향상시킵니다.
SageMaker JumpStart를 사용하여 내장 알고리즘 훈련
SageMaker JumpStart UI를 통해 몇 번의 클릭으로 이러한 내장 알고리즘을 훈련할 수도 있습니다. JumpStart는 그래픽 인터페이스를 통해 다양한 ML 프레임워크 및 모델 허브에서 기본 제공 알고리즘과 사전 훈련된 모델을 훈련 및 배포할 수 있는 SageMaker 기능입니다. 또한 ML 모델과 다양한 기타 AWS 서비스를 연결하여 대상 사용 사례를 해결하는 완전한 ML 솔루션을 배포할 수 있습니다.
자세한 내용은 TensorFlow Hub 및 Hugging Face 모델을 사용하여 Amazon SageMaker JumpStart로 텍스트 분류 실행.
결론
이 게시물에서 우리는 이제 SageMaker에서 사용할 수 있는 테이블 형식 데이터 세트의 ML을 위한 XNUMX가지 강력한 새 내장 알고리즘의 출시를 발표했습니다. 이러한 알고리즘이 무엇인지에 대한 기술적인 설명과 SageMaker SDK를 사용하여 LightGBM에 대한 예제 교육 작업을 제공했습니다.
자신의 데이터 세트를 가져와 SageMaker에서 이러한 새로운 알고리즘을 시도하고 샘플 노트북에서 사용 가능한 기본 제공 알고리즘을 확인하십시오. GitHub의.
저자에 관하여
![]() 황신 박사 Amazon SageMaker JumpStart 및 Amazon SageMaker 내장 알고리즘의 응용 과학자입니다. 그는 확장 가능한 기계 학습 알고리즘 개발에 중점을 둡니다. 그의 연구 관심 분야는 자연어 처리, 표 형식 데이터에 대한 설명 가능한 딥 러닝, 비모수적 시공간 클러스터링에 대한 강력한 분석입니다. 그는 ACL, ICDM, KDD 컨퍼런스 및 Royal Statistical Society: Series A 저널에 많은 논문을 발표했습니다.
황신 박사 Amazon SageMaker JumpStart 및 Amazon SageMaker 내장 알고리즘의 응용 과학자입니다. 그는 확장 가능한 기계 학습 알고리즘 개발에 중점을 둡니다. 그의 연구 관심 분야는 자연어 처리, 표 형식 데이터에 대한 설명 가능한 딥 러닝, 비모수적 시공간 클러스터링에 대한 강력한 분석입니다. 그는 ACL, ICDM, KDD 컨퍼런스 및 Royal Statistical Society: Series A 저널에 많은 논문을 발표했습니다.
![]() Ashish Khetan 박사 Amazon SageMaker JumpStart 및 Amazon SageMaker 기본 제공 알고리즘을 사용하는 수석 응용 과학자이며 기계 학습 알고리즘 개발을 돕습니다. 그는 기계 학습 및 통계적 추론 분야에서 활발한 연구원이며 NeurIPS, ICML, ICLR, JMLR, ACL 및 EMNLP 컨퍼런스에서 많은 논문을 발표했습니다.
Ashish Khetan 박사 Amazon SageMaker JumpStart 및 Amazon SageMaker 기본 제공 알고리즘을 사용하는 수석 응용 과학자이며 기계 학습 알고리즘 개발을 돕습니다. 그는 기계 학습 및 통계적 추론 분야에서 활발한 연구원이며 NeurIPS, ICML, ICLR, JMLR, ACL 및 EMNLP 컨퍼런스에서 많은 논문을 발표했습니다.
 주앙 모 우라 Amazon Web Services의 AI/ML 전문가 솔루션 아키텍트입니다. 그는 주로 NLP 사용 사례에 중점을 두고 고객이 딥 러닝 모델 교육 및 배포를 최적화하도록 지원합니다. 그는 또한 로우 코드 ML 솔루션과 ML 전문 하드웨어의 적극적인 지지자입니다.
주앙 모 우라 Amazon Web Services의 AI/ML 전문가 솔루션 아키텍트입니다. 그는 주로 NLP 사용 사례에 중점을 두고 고객이 딥 러닝 모델 교육 및 배포를 최적화하도록 지원합니다. 그는 또한 로우 코드 ML 솔루션과 ML 전문 하드웨어의 적극적인 지지자입니다.
- "
- 100
- a
- 달성
- 달성
- 가로질러
- 활동적인
- 추가
- 많은
- 발전하다
- 반대
- 연산
- 알고리즘
- 알고리즘
- All
- 수
- 이미
- 대안
- 아마존
- Amazon Web Services
- 분석
- 발표
- 응용할 수 있는
- 적용된
- 아키텍처
- 지역
- Automatic
- 자동적으로
- 가능
- AWS
- 때문에
- 혜택
- 더 나은
- 부스트
- 증폭
- 보물상자
- 내장
- 주의
- 케이스
- 발생
- 이전 단계로 돌아가기
- 고전적인
- 분류
- 암호
- 코딩
- 단
- 왔다
- 커뮤니티
- 경기
- 계산
- 회의
- 콘솔에서
- 컨테이너
- 만들
- 만든
- 임계
- 현재
- 관습
- 고객
- 데이터
- 데이터 처리
- 데이터 과학
- 취급
- 결정
- 깊은
- 수요
- 시연
- 배포
- 배치
- 전개
- 설명
- 개발
- 개발
- 개발
- 다른
- 도커
- 마다
- 용이하게
- 효율성
- 효율적인
- 종점
- 견적
- 예
- 예
- 현존하는
- 페이스메이크업
- 특색
- 특징
- Fields
- 집중
- 집중
- 수행원
- 프레임 워크
- 에
- 추가
- 게다가
- GPU
- 처리
- 하드웨어
- 신장
- 도움
- 도움이
- 도움이
- 여기에서 지금 확인해 보세요.
- 높은 품질의
- 더 높은
- 고도로
- 방법
- How To
- HTTPS
- 허브
- 영상
- 이행
- 개선
- 포함
- 포함
- 정보
- 고유의
- 혁신적인
- 입력
- 예
- 이해
- 인터페이스
- IT
- 일
- 일지
- 알아
- 언어
- 시작
- 배운
- 배우기
- 모래밭
- 명부
- 상장 된
- 기계
- 기계 학습
- 주요한
- 구축
- 태도
- 미디어
- 매질
- ML
- 모델
- 모델
- 배우기
- 가장
- 여러
- 자연의
- 네트워크
- 최적화
- 최적화
- 선택권
- 기타
- 자신의
- 소유자
- 특별한
- 통과
- 성능
- 인기 문서
- 강한
- 예측
- 예측
- 예측
- 제시
- 문제
- 방법
- 처리
- 프로덕트
- 프로젝트
- 제공
- 제공
- 제공
- 공개
- 출판
- 빨리
- 이르기까지
- 살갗이 벗어 진
- 인정하다
- 지방
- 필요
- 연구
- 자료
- 결과
- 결과
- 달리기
- 달리는
- 같은
- 확장성
- 확장성
- 규모
- 스케일링
- 과학
- 과학자
- 과학자
- SDK
- 선택된
- 연속
- 시리즈 A
- 서비스
- 세트
- 몇몇의
- 변화
- 단순, 간단, 편리
- So
- 사회적
- 소셜 미디어
- 사회
- 해결책
- 솔루션
- 풀다
- 일부
- 특별한
- 전문가
- 스택
- 스타트
- 시작
- 최첨단
- 통계적인
- 아직도
- 저장
- SUPPORT
- 목표
- 대상
- 작업
- 테크니컬
- 기법
- XNUMXD덴탈의
- 타사
- 세
- 을 통하여
- 도처에
- 시간
- 오늘
- 함께
- 추적
- Train
- 트레이닝
- 변환
- 유형
- ui
- 유일한
- 사용
- 사용 사례
- 가치
- 여러
- 버전
- 방법
- 웹
- 웹 서비스
- 뭐
- 이내
- 너의